DBNet 文本分割网络
论文:https://arxiv.org/pdf/1911.08947
源码:https://github.com/MhLiao/DB.
=转载需表明出处=
网络结构图
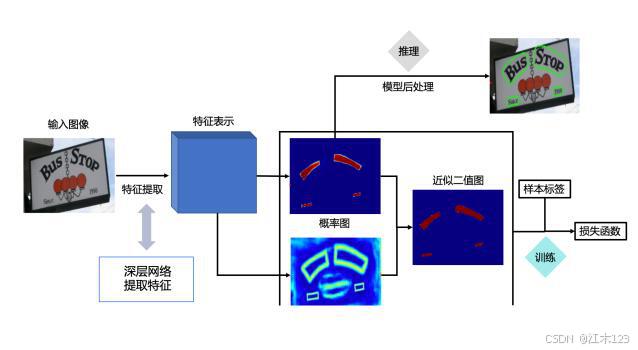
本人总结的论文贡献
1.sigmod计算得到的是概率值,需要阈值去筛选,所以本文训练了一个分支是阈值图,这样就不用人为固定阈值。但是作者更进了一步,即后处理也不需要用到阈值图,所以他的二值化是优化版的sigmod函数,也可以说二值化是可微的二值化函数
2.作者将二值化操作融入到分割网络进行联合优化(这里应该就是指DB操作,因为标准二值化不可微,sigmod又是概率值,但是作者提出所谓的DB,实际是sigmod的变种函数),目的是结合阈值图更好的训练得到概率图,最终概率图与二值化图基本无差别,推理过程只需要概率图。
3.推理过程并不需要DB操作,不需要额外的时间、内存成本
(这块自己也绕了很久,关于本人对论文的理解如有不当,希望大家指正。)
方法
- 将图像送入特征金字塔结构的主干网络(backbone)
- 将主干网络每一层的输出上采样到上一层的尺寸进行融合得到特征F
- F特征用于预测概率图P和阈值图T(probability map P and the threshold map T)
- 训练过程通过P和T得到近似二值化图(DB)
- 传统二值化计算 ,不可微
* DB二值化
- 可以发现可微二值化就是一个近似sigmod
- k为放大因子,经验设置为50
- 传统二值化计算 ,不可微
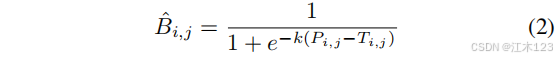
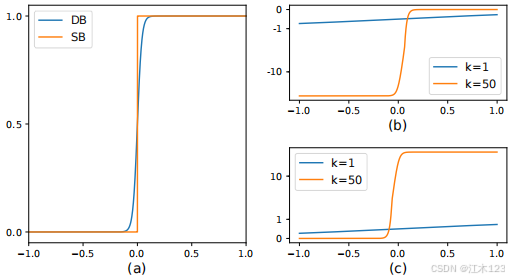
- 如图(a),可微二值化是对标准二值化的一个近似结果
- 带有自适应阈值的可微分二值化不仅可以区分文本区域和背景,还可以分离紧密连接的文本实例。(这里有点牵强,即使不加入自适应阈值根据本人经验来看也是可以实现的,只是加入可能提升了一定的性能)
- k值作为经验值不做研究,那么作者DB中(P-T)的理论依据如图(b)和(c),损失函数是二分类交叉熵,分别对应正负样本的损失函数如下
x = Pi,j −Ti,j .求导:
x<0 => L+ x>0 => L-
根据图(b)(c)我们就轻易发现,预测错误的区域梯度非常大,同时可以解释k取50的作用和意义。
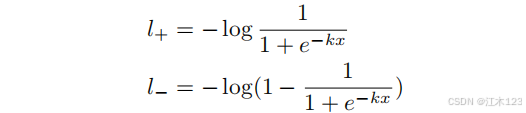
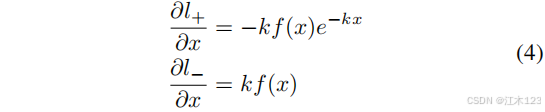
- 可变形卷积
- 提升感受野,对于宽高比极端的文本有利
- 数据集标签制作
- 收缩和外扩标签
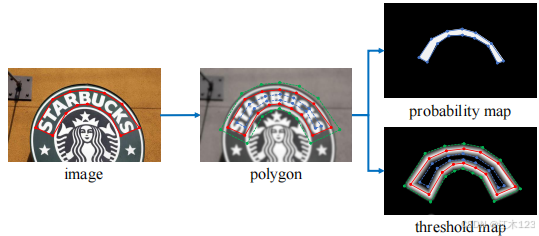
- 为了增大相邻文字之间的间距,缓解文字离得太近或者部分重叠的情况。概率图(probability map)的制作会在原始多边形的基础上,使用Vatti clipping(1992)算法,向内收缩D的距离
r收缩比=0.4,A表示原始多边形的面积,L表示原始多边形的周长,如下所示
- 阈值图(threshold map)在多边形的基础上,分别向内收缩D距离形成蓝色多边形,向外扩张D距离形成绿色多边形。蓝色多边形和绿色多边形之间的像素形成阈值图。然后计算图内每个像素离最近的边(蓝色边,绿色边)的归一化距离,形成最终的阈值图。阈值图看起来中间像素亮,边缘像素暗。
- 根据本人理解,可以如下类比,两边值小,中间值大
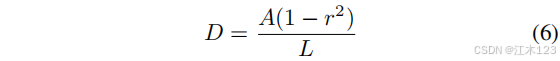
损失
a=1.0
β=10
Ls:概率图(probability map)loss,采用二分类交叉熵损失
Lb:二值图(binary map)loss,采用二分类交叉熵损失
Lt:阈值图(threshold map)loss,采用L1损失
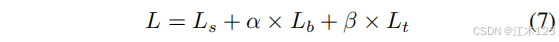
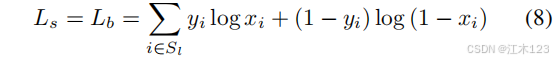
推理处理

- 通过概率图映射成二值化图(恒定阈值0.2),这里就又绕回去了这和直接使用sigmod然后给定阈值有区别嘛?有待考证。
- 对收缩区域扩展回去,得到最终二值化图
总结
- 通过训练作者得到结论,在推理时使用概率图和DB后的近似二值图对最后的检测结果基本一致,所以为提高效率选择使用概率图和固定阈值直接生成结果,作者固定阈值0.2本人推测是根据训练的动态阈值图得到的规律吧。
- 总之作者的一些训练策略值得我们借鉴,后续有深入的理解在进行进一步补充。