LLMs:《Scaling Laws for Precision精度感知的缩放定律》翻译与解读
导读:这篇论文研究了低精度训练和推理对大型语言模型(LLM)的影响。通过大量的实验,建立了精度感知型缩放定律,为低精度训练和推理提供了理论指导,并指出了现有实践中的一些潜在问题,例如盲目追求极低精度训练和过度训练带来的负面影响。 论文的贡献在于它系统地研究了精度、参数量和数据量之间的复杂相互作用,为未来的 LLM 训练和部署提供了重要的参考。
>> 背景痛点:
● 现有缩放定律的不足:现有的 LLM 缩放定律主要关注模型参数量和数据集大小,忽略了训练和推理精度对模型性能和成本的影响。
● 低精度训练和推理的趋势:LLM 训练和推理正朝着低精度方向发展(例如 BF16、FP8、甚至更低的精度),但缺乏对低精度下性能和成本权衡的系统性研究。
● 低精度带来的挑战:研究低精度下的缩放定律具有挑战性,因为既要考虑低精度训练和量化的具体实现细节,又要找到普适的函数形式。
>> 具体的解决方案:论文提出了一个统一的缩放定律,该定律能够预测在不同训练和推理精度下,模型的损失情况。这个定律考虑了以下几个方面:
● 训练精度:模型权重、激活值和键值缓存(attention)的训练精度 (Pw, Pa, Pkv)。
● 推理精度:模型权重的后训练量化精度 (Ppost)。
● 模型参数量:模型参数数量 N。
● 数据集大小:数据集大小 D(以 token 计)。
>> 核心思路步骤:论文通过以下步骤建立了精度感知型缩放定律:
● 后训练量化 (PTQ) 的缩放定律:研究了 BF16 训练模型在进行 PTQ 后,损失的下降情况。发现随着训练数据量的增加,PTQ 造成的损失增加,甚至可能导致额外的数据反而有害。建立了 PTQ 损失下降与模型参数量 N、数据量 D 和量化精度 Ppost 之间的函数关系。
● 量化训练的缩放定律:研究了在训练过程中量化权重、激活值和键值缓存对模型损失的影响。发现这些量化操作的影响近似独立且可乘性,可以定义一个“有效参数量” Neff 来反映这些影响。建立了模型损失与 Neff、数据量 D 和训练精度 Pw, Pa, Pkv 之间的函数关系。
● 统一缩放定律:将 PTQ 的缩放定律和量化训练的缩放定律结合起来,建立了一个统一的函数形式,该函数形式能够预测在不同训练和推理精度下,模型的损失情况。 这个统一的函数形式考虑了训练精度对 PTQ 损失下降的影响。
>> 优势:
● 统一性:将训练和推理过程中的精度影响统一到一个函数形式中。
● 可预测性:能够准确预测不同精度设置下的模型损失。
● 可解释性:提出的函数形式具有较好的可解释性,能够反映训练和推理精度对模型性能的影响机制。
>> 结论和观点:
● 后训练量化:过度训练的模型对后训练量化更敏感。存在一个临界数据量,超过该数据量后,增加训练数据反而会降低推理性能。
● 量化训练:量化权重、激活值和键值缓存的影响是独立且可乘的。计算最优的训练精度通常与计算预算无关,但如果模型大小受限,则计算最优精度会随着计算预算缓慢增加。 16 位精度可能并非最优,而过低精度(低于 4 位)则需要不成比例地增加模型大小才能保持性能。
● 统一缩放定律:提出了一个统一的缩放定律,该定律能够准确预测不同训练和推理精度下的模型损失,并揭示了训练精度对 PTQ 损失下降的影响。
目录
《Scaling Laws for Precision》翻译与解读
《Scaling Laws for Precision》翻译与解读
| 地址 | |
| 时间 | 2024年11月7日 |
| 作者 | 哈佛大学、斯坦福大学、麻省理工学院、Databricks、卡耐基梅隆大学 |
Abstract
| Low precision training and inference affect both the quality and cost of language models, but current scaling laws do not account for this. In this work, we devise "precision-aware" scaling laws for both training and inference. We propose that training in lower precision reduces the model's "effective parameter count," allowing us to predict the additional loss incurred from training in low precision and post-train quantization. For inference, we find that the degradation introduced by post-training quantization increases as models are trained on more data, eventually making additional pretraining data actively harmful. For training, our scaling laws allow us to predict the loss of a model with different parts in different precisions, and suggest that training larger models in lower precision may be compute optimal. We unify the scaling laws for post and pretraining quantization to arrive at a single functional form that predicts degradation from training and inference in varied precisions. We fit on over 465 pretraining runs and validate our predictions on model sizes up to 1.7B parameters trained on up to 26B tokens. | 低精度的训练和推理不仅会影响语言模型的质量和成本,但目前的缩放定律并未考虑到这一点。在这项工作中,我们为训练和推理设计了“精度感知”的缩放定律。我们提出,在低精度下进行训练会降低模型的“有效参数数”,使我们能够预测在低精度下训练和后向量化所产生的额外损失。 >> 对于推理,我们发现随着模型在更多数据上训练,训练后量化带来的退化会增加,最终使额外的预训练数据变得有害。 >> 对于训练,我们的缩放定律使我们能够预测具有不同部分的模型在不同精度下的损失,并建议在较低精度下训练更大的模型可能是计算最优的。 我们统一了后训练和预训练量化的缩放定律,得到了一个单一的函数形式,可以预测不同精度的训练和推理的退化。我们对超过465个预训练运行进行了拟合,并验证了我们对模型大小的预测,在多达26B个令牌上训练了多达1.7B个参数。 |
1、Introduction
| Scale has emerged as a central driver of progress in deep learning [Brown, 2020]. Key work on scaling [Kaplan et al., 2020, Hoffmann et al., 2022] studied tradeoffs between model/dataset size to balance performance and compute. However, the precision in which models are trained and served is an important third factor that contributes to both cost and performance. Deep learning is trending towards lower precision: current frontier models like the Llama-3 series are trained in BF16 [Dubey et al., 2024], and there is widespread effort to move the pretraining paradigm to FP8 [Micikevicius et al., 2022]. The next generation of hardware will support FP4, and advances in weight-only quantization have led to training in binary and ternary at scale [Ma et al., 2024, Wang et al., 2023]. How far will these paradigms go? Specifically, we ask: What are the tradeoffs between precision, parameters, and data?How do they compare for pretraining and inference? | 规模已经成为深度学习进步的核心驱动力[Brown, 2020]。缩放的关键工作[Kaplan et al., 2020, Hoffmann et al., 2022]研究了模型/数据集大小之间的权衡,以平衡性能和计算。然而,模型训练和服务的精确度是影响成本和性能的第三个重要因素。深度学习正趋向于低精度:目前的前沿模型,如lama-3系列是在BF16中训练的[Dubey等人,2024],并且有广泛的努力将预训练范式转移到FP8 [micicikevicius等人,2022]。下一代硬件将支持FP4,仅权重量化方面的进步导致了二进制和三元制的大规模训练[Ma等人,2024,Wang等人,2023]。这些范例能走多远?具体来说,我们的问题是: 精度、参数和数据之间的权衡是什么?它们在预训练和推理方面是如何比较的? |
| Studying scaling in precision is challenging because work on scaling laws generally aims to drop fine-grained implementation details in pursuit of universal functional forms while work on quantization generally does the opposite, focuses on the details: how quantization is done, with what type, to what part of the model. In seeking a balance, we consider a variety of plausible functional forms, and choose one that abstracts implementation details of quantization away from loss scaling, allowing us to predict loss scaling in many situations of practical interest. This functional form that posits bit precision and parameter count interchangeably contribute to a model’s “effective parameter count,” Neff, and implementation details like which parts of a model are quantized to what precision, interact with loss scaling only through their effect on this quantity. Overall, we study the scaling of the effects of precision on loss as we vary data and parameters, both during and after training. We first study how the degradation induced by post-train quantiza-tion scales with parameters and data. We find that the degradation increases with data, so that for a fixed model, training on additional data after a certain point can be actively harmful if the model will be quantized after training. We then shift our focus to quantized training, examining both the quantization-aware-training (weights only) and low-precision training (weights, activations, at-tention all quantized) settings. Our scaling laws for pretraining suggest that the compute-optimal pretraining precision is in general independent of compute budget. Surprisingly, however, this inde-pendence ceases to be true if model size is constrained, in which case the compute-optimal precision grows slowly in compute. | 研究精确的缩放是具有挑战性的,因为缩放定律的工作通常旨在放弃细粒度的实现细节,以追求通用的功能形式,而量化工作通常相反,专注于细节:量化是如何完成的,用什么类型,到模型的哪一部分。在寻求平衡的过程中,我们考虑了各种可能的函数形式,并选择了一种抽象量化实现细节的函数形式,使我们能够在许多实际情况下预测损失缩放。这种假设比特精度和参数计数可互换的函数形式有助于模型的“有效参数计数”Neff,以及实现细节,如模型的哪些部分被量化到什么精度,仅通过它们对该数量的影响与损失缩放相互作用。 总的来说,我们研究了在训练期间和训练后,当我们改变数据和参数时,精度对损失的影响的缩放。我们首先研究了训练后量化引起的退化如何随参数和数据的变化而变化。我们发现退化随着数据的增加而增加,因此对于一个固定的模型,如果在训练后对模型进行量化,那么在某一点之后对额外的数据进行训练可能是积极有害的。然后,我们将注意力转移到量化训练上,检查量化感知训练(仅权重)和低精度训练(权重、激活、注意力全部量化)设置。我们的预训练缩放定律表明,计算最优预训练精度通常与计算预算无关。然而,令人惊讶的是,如果模型大小受到限制,这种独立性就不再成立,在这种情况下,计算最优精度在计算中增长缓慢。 |
| In all, we pretrain a suite of 465 language models in 3 to 16 bit precisions, as well as post-train quantize each to multiple precisions. For a language model with N parameters, trained on D tokens with training precision Ptrain, and post-train weight precision Ppost, we ultimately find a unified scaling law that takes the following form: where A, B, E, α, β are positive fitted constants, and δPTQ refers to the loss degradation induced by post-training quantization before inference. Altogether, our results for post-train quantization illustrate how more pretraining FLOPs do not always lead to better models at inference-time, and our results for low-precision pretraining suggest that both the standard practice of training models in 16-bit, and the race to extremely low (sub 4-bit) pretraining precision, may be suboptimal. | 总之,我们以3到16位精度预训练了一套465种语言模型,并将每个模型的训练后量化为多个精度。对于一个有N个参数,训练精度为Ptrain,训练后权值精度为Ppost的语言模型,我们最终找到了一个统一的标度律,其形式如下: 其中,A、B、E、α、β为正拟合常数,δPTQ为推理前训练后量化引起的损失退化。总之,我们的训练后量化结果表明,在推理时,更多的预训练FLOPs并不总是导致更好的模型,我们的低精度预训练结果表明,16位训练模型的标准实践和极低(低于4位)预训练精度的竞争都可能是次优的。 |
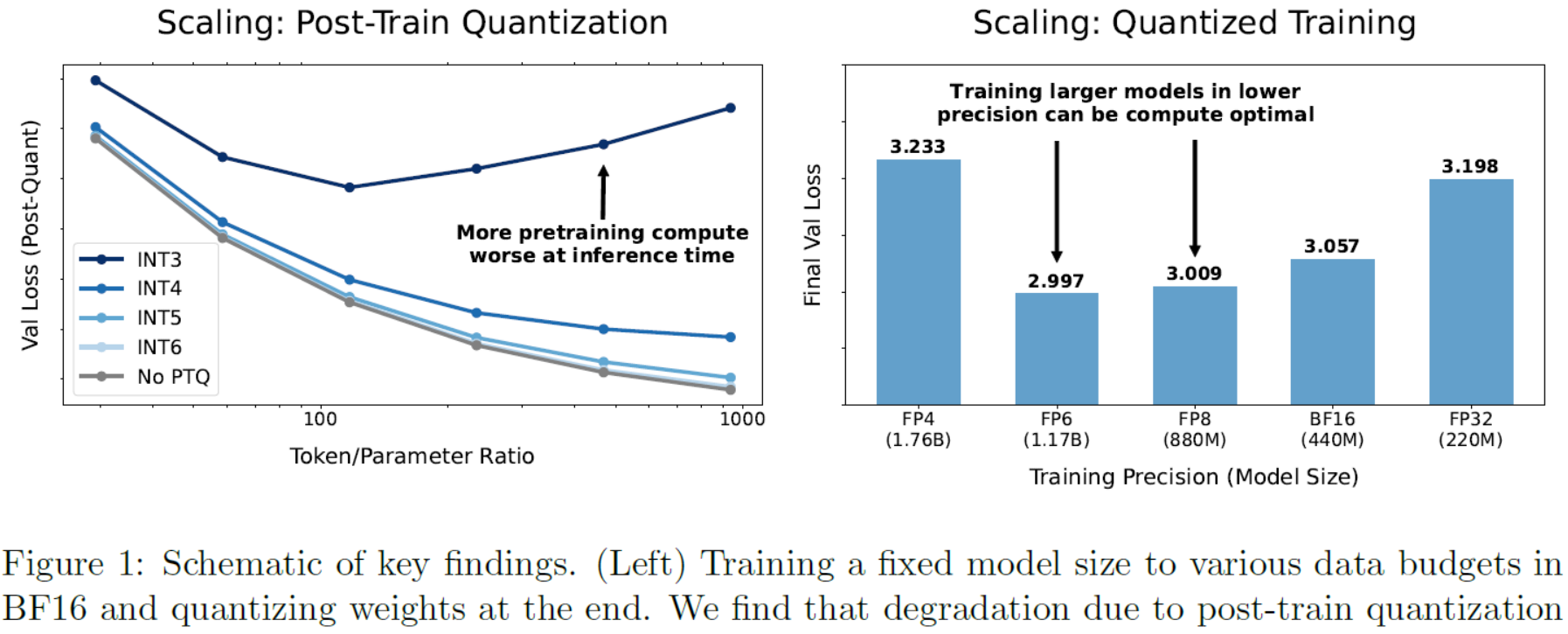
Figure 1: Schematic of key findings. (Left) Training a fixed model size to various data budgets in BF16 and quantizing weights at the end. We find that degradation due to post-train quantization increases with tokens seen during pretraining, so that eventually additional pretraining data can be harmful. (Right) Our scaling suggests training larger models in lower precision can be compute-optimal according to the cost model in Section 4.3. Weights, activations, attention quantized, all models trained on the same data budget, details in Appendix H.图1:主要发现的示意图。(左)在BF16中对各种数据预算训练一个固定的模型大小,最后量化权重。我们发现,由于训练后量化的退化随着预训练期间看到的token而增加,因此最终额外的预训练数据可能是有害的。(右)我们的缩放表明,根据第4.3节中的成本模型,以较低精度训练较大的模型可以是计算最优的。权重,激活,注意力量化,在相同数据预算上训练的所有模型,详细信息见附录h主要发现的示意图.
6 Conclusion and Limitations
| We find that the common inference-time technique of post-train quantization can incur large degra-dation at very high data budgets, demonstrating a striking example of how more pretraining com-pute does not always imply stronger models at inference-time. Seeking better data scaling, we study quantization-aware and low precision training. We find that parameters and bit precision are well modeled as interchangeably controlling an “effective parameter count” of the model allows us to predict finite-precision loss effects accurately during both training and inference. The re-sulting scaling law makes surprising predictions that we qualitatively validate on language models pretrained from scratch with up to 1.7B parameters. | 我们发现,在非常高的数据预算下,常见的训练后量化推理时间技术可能会导致严重的退化,这表明更多的预训练计算并不总是意味着在推理时间更强的模型。为了更好地扩展数据,我们研究了量化感知和低精度训练。我们发现参数和位精度可以很好地互换建模,控制模型的“有效参数计数”使我们能够在训练和推理期间准确预测有限精度的损失效应。由此产生的缩放定律做出了令人惊讶的预测,我们对从头开始训练的、具有高达1.7B个参数的语言模型进行了定性验证。 |
| There are limitations to our analysis. First, we use a fixed architecture throughout to examine the effects of precision, parameters, and tokens in a controlled manner. In contrast, low precision training often involves architectural tweaks [Ma et al., 2024, Zhu et al., 2024] that can close much of the gap from a vanilla full precision model. Second, while compute costs do scale linearly with precision, the gains from halving precision are usually less than 2x due to systems overhead. Third, we only consider loss scaling without downstream model evaluations. We emphasize that the trends we find aim to be suggestive rather than prescriptive, and hope future work can more comprehensively examine these effects at larger model scale. In all, we find that the effects of precision on loss are predictable and consistent, with important and surprising implications. | 我们的分析有局限性。首先,我们自始至终使用固定的体系结构,以受控的方式检查精度、参数和令牌的影响。相比之下,低精度训练通常涉及架构调整[Ma等人,2024,Zhu等人,2024],这可以缩小与vanilla全精度模型的很大差距。其次,虽然计算成本确实与精度呈线性增长,但由于系统开销,精度减半的收益通常小于2倍。第三,我们只考虑损失缩放而不考虑下游模型评估。我们强调,我们发现的趋势旨在提示而不是规定性,并希望未来的工作可以在更大的模型尺度上更全面地检查这些影响。总之,我们发现精确度对损失的影响是可预测和一致的,具有重要和令人惊讶的含义。 |