前言
本文分享YOLO11的模型训练,训练任务包括物体分类、目标检测与跟踪、实例分割 、关键点姿态估计、旋转目标检测等。
安装方式支持:默认的使用pip进行安装;也支持直接调用YOLO11源码,灵活便捷修改源码。
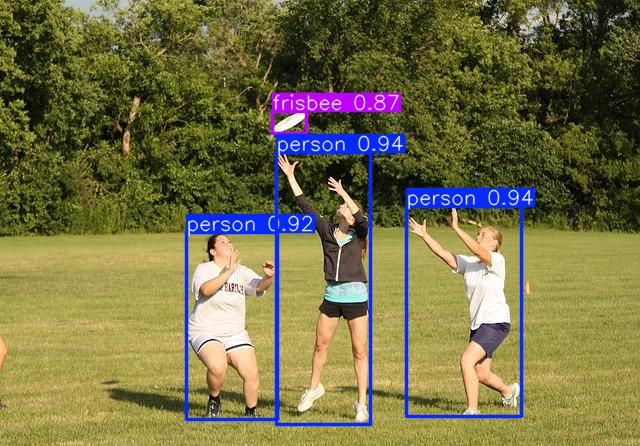
本文推荐在电脑端阅读,大约4万字左右,下面看看YOLO11目标检测的效果:

看看示例分割的效果:

看看关键点姿态估计的效果:

首先安装YOLO11
1、官方默认安装方式
通过运行 pip install ultralytics 来快速安装 Ultralytics 包
安装要求:
- Python 版本要求:Python 版本需为 3.8 及以上,支持 3.8、3.9、3.10、3.11、3.12 这些版本。
- PyTorch 版本要求:需要 PyTorch 版本不低于 1.8。
然后使用清华源,进行加速安装
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/2、直接调用YOLO11源码方式(推荐)
首先到YOLO11代码地址,下载源代码:https://github.com/ultralytics/ultralytics
- 在 GitHub 仓库页面上,用户点击绿色的 "Code" 按钮后,会弹出一个选项框。
- 选择通过 HTTPS 或 GitHub CLI 克隆仓库,也可以点击框中的 "Download ZIP" 按钮,将整个仓库下载为 ZIP 压缩包到本地。
解压ultralytics-main.zip文件,目录结构如下所示
ultralytics-main/
.github/
docker/
docs/
examples/
runs/
tests/
ultralytics/
.gitignore
CITATION.cff
CONTRIBUTING.md
LICENSE
mkdocs.yml
pyproject.toml
README.md
README.zh-CN.md然后在ultralytics同级目录中,添加需要训练的代码(train.py)
以及测试数据的文件夹:datasets,权重文件目录:weights
ultralytics-main/
.github/
datasets/
docker/
docs/
examples/
runs/
tests/
ultralytics/
weights/
.gitignore
CITATION.cff
CONTRIBUTING.md
LICENSE
mkdocs.yml
print_dir.py
pyproject.toml
README.md
README.zh-CN.md
train.pyweights目录可以存放不同任务的权重,比如:yolo11m-cls.pt、yolo11m-obb.pt、yolo11m-pose.pt、yolo11m-seg.pt、yolo11m.pt、yolo11n.pt等。
train.py文件是和ultralytics文件夹同一级目录的
后面可以直接调用ultralytics源代码中的函数、类和依赖库等,如果有需要直接修改ultralytics中的代码,比较方便。
一、YOLO11模型训练——实例分割
1、模型训练简洁版
YOLO11模型训练,整体思路流程:
- 加载模型:使用 YOLO 类指定模型的配置文件
yolo11m-seg.yaml并加载预训练权重yolo11m-seg.pt。 - 执行训练:调用
model.train()方法,指定数据集coco8_lgp.yaml,设置训练轮数为 10,图像大小为 640 像素。 - 保存训练结果:训练完成后,结果保存在
results中,包含损失和精度等信息。
示例代码,如下所示:
from ultralytics import YOLO
# 加载YOLO模型的配置文件,并加载预训练权重文件
model = YOLO("yolo11m-seg.yaml").load("weights/yolo11m-seg.pt")
# 使用coco8_lgp.yaml数据集进行训练,训练10个epoch,并将图像大小设置为640像素
results = model.train(data="coco8_lgp.yaml", epochs=10, imgsz=640)
然后执行程序,开始训练:
Ultralytics 8.3.7 🚀 Python-3.8.16 torch-1.13.1 CPU (unknown)
......
Logging results to runs\segment\train6
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss seg_loss cls_loss dfl_loss Instances Size
1/10 0G 0.6116 2.282 1.139 1.125 13 640: 100%|██████████| 1/1 [00:15<00:00, 15.61s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.62s/it]
all 4 17 0.778 0.963 0.97 0.776 0.778 0.963 0.967 0.691
.....
Epoch GPU_mem box_loss seg_loss cls_loss dfl_loss Instances Size
10/10 0G 0.6489 1.423 0.6046 0.9767 13 640: 100%|██████████| 1/1 [00:13<00:00, 13.47s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.76s/it]
all 4 17 0.836 0.965 0.968 0.753 0.836 0.965 0.963 0.666
10 epochs completed in 0.061 hours.
Optimizer stripped from runs\segment\train6\weights\last.pt, 45.3MB
Optimizer stripped from runs\segment\train6\weights\best.pt, 45.3MB模型结构的配置文件:yolo11m-seg.yaml,模型权重:weights/yolo11m-seg.pt,存放数据集文件:coco8_lgp.yaml;这些后面在详细分析。
训练完成后,能看到runs\segment\train6保存的权重和训练信息
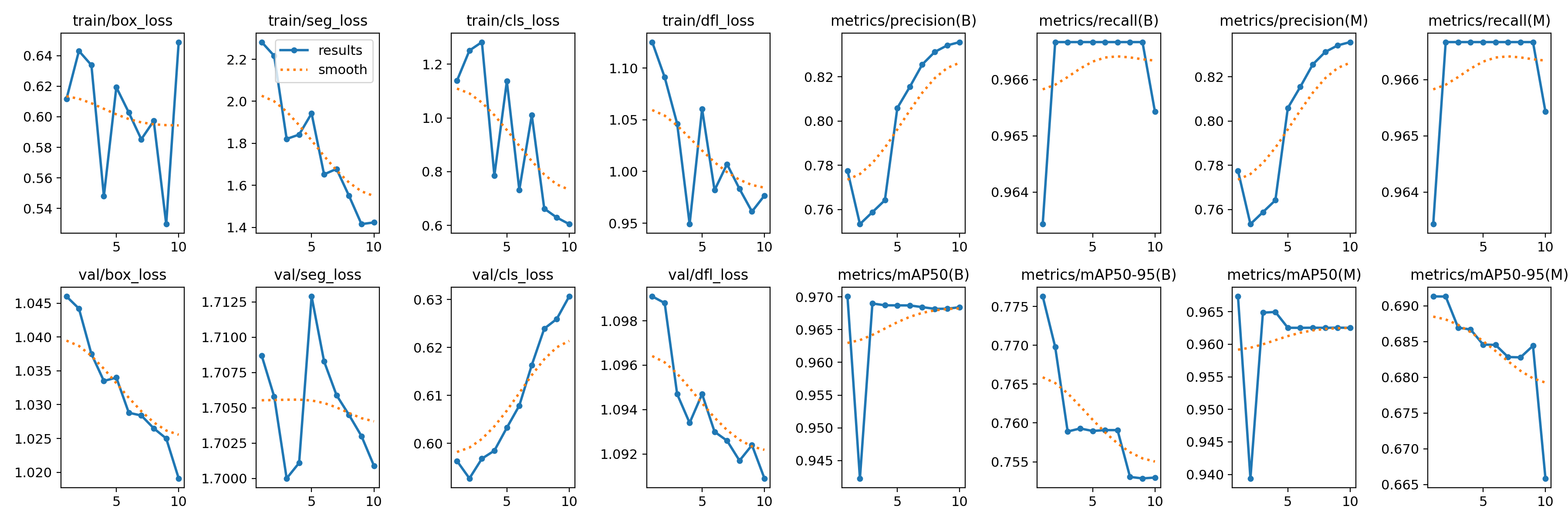
训练图像和标签的示例:

2、详细训练参数版本(重要)
YOLO11模型训练,详细参数版本的思路流程:
- 加载模型:使用 YOLO 类指定模型的配置文件
yolo11s-seg.yaml并加载预训练权重yolo11s-seg.pt。 - 定义训练参数:通过字典
train_params定义了一系列训练参数,涵盖了训练过程中可能涉及的配置项,如数据集路径、训练轮数、图像大小、优化器、数据增强等。 - 执行训练:使用
model.train(**train_params)将定义的训练参数传入模型,开始训练。 - 保存训练结果:训练完成后,结果保存在
results中,包含损失和精度等信息。
示例代码,如下所示:
from ultralytics import YOLO
# 加载预训练的模型
model = YOLO("yolo11s-seg.yaml").load("weights_yolo/yolo11s-seg.pt")
# 定义训练参数,添加默认值、范围和中文注释
train_params = {
'data': "coco8_lgp.yaml", # 数据集配置文件路径,需要自定义修改
'epochs': 10, # 总训练轮次,默认值 100,范围 >= 1
'imgsz': 640, # 输入图像大小,默认值 640,范围 >= 32
'batch': 8, # 批次大小,默认值 16,范围 >= 1
'save': True, # 是否保存训练结果和模型,默认值 True
'save_period': -1, # 模型保存频率,默认值 -1,表示只保存最终结果
'cache': False, # 是否缓存数据集,默认值 False
'device': None, # 训练设备,默认值 None,支持 "cpu", "gpu"(device=0,1), "mps"
'workers': 8, # 数据加载线程数,默认值 8,影响数据预处理速度
'project': None, # 项目名称,保存训练结果的目录,默认值 None
'name': None, # 训练运行的名称,用于创建子目录保存结果,默认值 None
'exist_ok': False, # 是否覆盖已有项目/名称目录,默认值 False
'optimizer': 'auto', # 优化器,默认值 'auto',支持 'SGD', 'Adam', 'AdamW'
'verbose': True, # 是否启用详细日志输出,默认值 False
'seed': 0, # 随机种子,确保结果的可重复性,默认值 0
'deterministic': True, # 是否强制使用确定性算法,默认值 True
'single_cls': False, # 是否将多类别数据集视为单一类别,默认值 False
'rect': False, # 是否启用矩形训练(优化批次图像大小),默认值 False
'cos_lr': False, # 是否使用余弦学习率调度器,默认值 False
'close_mosaic': 10, # 在最后 N 轮次中禁用 Mosaic 数据增强,默认值 10
'resume': False, # 是否从上次保存的检查点继续训练,默认值 False
'amp': True, # 是否启用自动混合精度(AMP)训练,默认值 True
'fraction': 1.0, # 使用数据集的比例,默认值 1.0
'profile': False, # 是否启用 ONNX 或 TensorRT 模型优化分析,默认值 False
'freeze': None, # 冻结模型的前 N 层,默认值 None
'lr0': 0.01, # 初始学习率,默认值 0.01,范围 >= 0
'lrf': 0.01, # 最终学习率与初始学习率的比值,默认值 0.01
'momentum': 0.937, # SGD 或 Adam 的动量因子,默认值 0.937,范围 [0, 1]
'weight_decay': 0.0005, # 权重衰减,防止过拟合,默认值 0.0005
'warmup_epochs': 3.0, # 预热学习率的轮次,默认值 3.0
'warmup_momentum': 0.8, # 预热阶段的初始动量,默认值 0.8
'warmup_bias_lr': 0.1, # 预热阶段的偏置学习率,默认值 0.1
'box': 7.5, # 边框损失的权重,默认值 7.5
'cls': 0.5, # 分类损失的权重,默认值 0.5
'dfl': 1.5, # 分布焦点损失的权重,默认值 1.5
'pose': 12.0, # 姿态损失的权重,默认值 12.0
'kobj': 1.0, # 关键点目标损失的权重,默认值 1.0
'label_smoothing': 0.0, # 标签平滑处理,默认值 0.0
'nbs': 64, # 归一化批次大小,默认值 64
'overlap_mask': True, # 是否在训练期间启用掩码重叠,默认值 True
'mask_ratio': 4, # 掩码下采样比例,默认值 4
'dropout': 0.0, # 随机失活率,用于防止过拟合,默认值 0.0
'val': True, # 是否在训练期间启用验证,默认值 True
'plots': True, # 是否生成训练曲线和验证指标图,默认值 True
# 数据增强相关参数
'hsv_h': 0.015, # 色相变化范围 (0.0 - 1.0),默认值 0.015
'hsv_s': 0.7, # 饱和度变化范围 (0.0 - 1.0),默认值 0.7
'hsv_v': 0.4, # 亮度变化范围 (0.0 - 1.0),默认值 0.4
'degrees': 0.0, # 旋转角度范围 (-180 - 180),默认值 0.0
'translate': 0.1, # 平移范围 (0.0 - 1.0),默认值 0.1
'scale': 0.5, # 缩放比例范围 (>= 0.0),默认值 0.5
'shear': 0.0, # 剪切角度范围 (-180 - 180),默认值 0.0
'perspective': 0.0, # 透视变化范围 (0.0 - 0.001),默认值 0.0
'flipud': 0.0, # 上下翻转概率 (0.0 - 1.0),默认值 0.0
'fliplr': 0.5, # 左右翻转概率 (0.0 - 1.0),默认值 0.5
'bgr': 0.0, # BGR 色彩顺序调整概率 (0.0 - 1.0),默认值 0.0
'mosaic': 1.0, # Mosaic 数据增强 (0.0 - 1.0),默认值 1.0
'mixup': 0.0, # Mixup 数据增强 (0.0 - 1.0),默认值 0.0
'copy_paste': 0.0, # Copy-Paste 数据增强 (0.0 - 1.0),默认值 0.0
'copy_paste_mode': 'flip', # Copy-Paste 增强模式 ('flip' 或 'mixup'),默认值 'flip'
'auto_augment': 'randaugment', # 自动增强策略 ('randaugment', 'autoaugment', 'augmix'),默认值 'randaugment'
'erasing': 0.4, # 随机擦除增强比例 (0.0 - 0.9),默认值 0.4
'crop_fraction': 1.0, # 裁剪比例 (0.1 - 1.0),默认值 1.0
}
# 进行训练
results = model.train(**train_params)
在ultralytics工程中,没有了超参数文件了,需要从model.train( )函数参数设置,所以才会有上面的示例代码。
然后执行程序,开始训练~
这里的训练参数可以再看看官方的:https://docs.ultralytics.com/modes/train/#train-settings
3、模型结构的配置文件
首先分析模型结构的配置文件:yolo11m-seg.yaml,它所在位置是
ultralytics/cfg/models/11/yolo11-seg.yaml
里面有详细的模型结构参数信息
如果需要修改YOLO11的实例分割-模型结构,可以在这个文件进行修改
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n-seg.yaml' will call yolo11-seg.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 355 layers, 2876848 parameters, 2876832 gradients, 10.5 GFLOPs
s: [0.50, 0.50, 1024] # summary: 355 layers, 10113248 parameters, 10113232 gradients, 35.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 445 layers, 22420896 parameters, 22420880 gradients, 123.9 GFLOPs
l: [1.00, 1.00, 512] # summary: 667 layers, 27678368 parameters, 27678352 gradients, 143.0 GFLOPs
x: [1.00, 1.50, 512] # summary: 667 layers, 62142656 parameters, 62142640 gradients, 320.2 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)4、模型权重
然后看看weights/yolo11m-seg.pt,这样就是模型权重的路径,可以根据放置的路径,进行修改。
5、数据集路径
最后看看coco8_lgp.yaml文件,这个是存放数据集的,比较重要。
它所在位置是:ultralytics/cfg/datasets/coco8_lgp.yaml,同级目录下还存在许多数据集配置文件
比如:coco128.yaml、coco.yaml、DOTAv1.5.yaml、VOC.yaml、Objects365.yaml、Argoverse.yaml等等
即下面代码的作用是一样的:
results = model.train(data="coco8_lgp.yaml", epochs=10, imgsz=640)
# results = model.train(data=r"C:/Users/liguopu/Downloads/ultralytics-main/ultralytics/cfg/datasets/coco8_lgp.yaml", epochs=10, imgsz=640)coco8_lgp.yaml这个文件是我自定义的,内容如下:
里面指定了数据集的路径:path: C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-seg,
数据集的路径path,需要根据实际数据路径进行修改
下面看看这个文件的内容:
# Ultralytics YOLO 🚀, AGPL-3.0 license
path: C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-seg # dataset root dir
train: images\train # train images (relative to 'path') 4 images
val: images\val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
# Download script/URL (optional)
download: https://github.com/ultralytics/assets/releases/download/v0.0.0/coco8.zip
二、YOLO11模型训练——目标检测
其实和上面的代码,基本是一样的,只需改变模型权重和吗模型配置文件就可以了。
模型训练简洁版
YOLO11模型训练,整体思路流程:
- 加载模型:使用 YOLO 类指定模型的配置文件
yolo11s.yaml并加载预训练权重yolo11s.pt。 - 执行训练:调用
model.train()方法,指定数据集coco8.yaml,设置训练轮数为 10,图像大小为 640 像素。 - 保存训练结果:训练完成后,结果保存在
results中,包含损失和精度等信息。
示例代码,如下所示:
from ultralytics import YOLO
# 加载YOLO模型的配置文件,并加载预训练权重文件
model = YOLO("yolo11s.yaml").load("weights/yolo11s.pt")
# 使用coco8.yaml数据集进行训练,训练10个epoch,并将图像大小设置为640像素
results = model.train(data="coco8.yaml", epochs=10, imgsz=640)
然后执行程序,开始训练:
Transferred 499/499 items from pretrained weights
Ultralytics 8.3.7 🚀 Python-3.8.16 torch-1.13.1 CPU (unknown)
WARNING ⚠️ Upgrade to torch>=2.0.0 for deterministic training.
engine\trainer: task=detect, mode=train, model=yolo11s.yaml, data=coco8.yaml, epochs=10, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train, exist_ok=False, pretrained=weights/yolo11s.pt, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs\detect\train
Dataset 'coco8.yaml' images not found ⚠️, missing path 'C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8\images\val'
Downloading https://ultralytics.com/assets/coco8.zip to 'C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8.zip'...
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 433k/433k [00:10<00:00, 42.1kB/s]
Unzipping C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8.zip to C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8...: 100%|██████████| 25/25 [00:00<00:00, 1081.86file/s]
Dataset download success ✅ (14.1s), saved to C:\Users\liguopu\Downloads\ultralytics-main\datasets
from n params module arguments
0 -1 1 928 ultralytics.nn.modules.conv.Conv [3, 32, 3, 2]
1 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
2 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
3 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
4 -1 1 103360 ultralytics.nn.modules.block.C3k2 [128, 256, 1, False, 0.25]
5 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
6 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
7 -1 1 1180672 ultralytics.nn.modules.conv.Conv [256, 512, 3, 2]
8 -1 1 1380352 ultralytics.nn.modules.block.C3k2 [512, 512, 1, True]
9 -1 1 656896 ultralytics.nn.modules.block.SPPF [512, 512, 5]
10 -1 1 990976 ultralytics.nn.modules.block.C2PSA [512, 512, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 443776 ultralytics.nn.modules.block.C3k2 [768, 256, 1, False]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 127680 ultralytics.nn.modules.block.C3k2 [512, 128, 1, False]
17 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 345472 ultralytics.nn.modules.block.C3k2 [384, 256, 1, False]
20 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 1511424 ultralytics.nn.modules.block.C3k2 [768, 512, 1, True]
23 [16, 19, 22] 1 850368 ultralytics.nn.modules.head.Detect [80, [128, 256, 512]]
YOLO11s summary: 319 layers, 9,458,752 parameters, 9,458,736 gradients, 21.7 GFLOPs
Transferred 499/499 items from pretrained weights
TensorBoard: Start with 'tensorboard --logdir runs\detect\train', view at http://localhost:6006/
Freezing layer 'model.23.dfl.conv.weight'
train: Scanning C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8\labels\train... 4 images, 0 backgrounds, 0 corrupt: 100%|██████████| 4/4 [00:00<00:00, 88.74it/s]
train: New cache created: C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8\labels\train.cache
val: Scanning C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8\labels\val... 4 images, 0 backgrounds, 0 corrupt: 100%|██████████| 4/4 [00:00<00:00, 124.99it/s]
val: New cache created: C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8\labels\val.cache
Plotting labels to runs\detect\train\labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.000119, momentum=0.9) with parameter groups 81 weight(decay=0.0), 88 weight(decay=0.0005), 87 bias(decay=0.0)
TensorBoard: model graph visualization added ✅
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs\detect\train
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/10 0G 0.7464 1.726 1.177 13 640: 100%|██████████| 1/1 [00:05<00:00, 5.23s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.30s/it]
all 4 17 0.934 0.788 0.935 0.733
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/10 0G 0.8044 1.794 1.126 13 640: 100%|██████████| 1/1 [00:04<00:00, 4.63s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:01<00:00, 1.97s/it]
all 4 17 0.845 0.884 0.962 0.719
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/10 0G 0.8128 1.746 1.216 13 640: 100%|██████████| 1/1 [00:05<00:00, 5.02s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.20s/it]
all 4 17 0.922 0.793 0.934 0.711
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/10 0G 0.8673 1.121 1.161 13 640: 100%|██████████| 1/1 [00:05<00:00, 5.02s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.94s/it]
all 4 17 0.919 0.794 0.934 0.711
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/10 0G 0.7821 1.427 1.17 13 640: 100%|██████████| 1/1 [00:05<00:00, 5.27s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.78s/it]
all 4 17 0.917 0.795 0.934 0.695
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
6/10 0G 0.5842 1.11 1.014 13 640: 100%|██████████| 1/1 [00:05<00:00, 5.54s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.01s/it]
all 4 17 0.908 0.798 0.933 0.696
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
7/10 0G 0.7791 1.15 1.104 13 640: 100%|██████████| 1/1 [00:04<00:00, 4.39s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:01<00:00, 1.81s/it]
all 4 17 0.898 0.8 0.936 0.696
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
8/10 0G 0.8725 1.353 1.201 13 640: 100%|██████████| 1/1 [00:04<00:00, 4.56s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:01<00:00, 1.82s/it]
all 4 17 0.883 0.805 0.933 0.71
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
9/10 0G 0.6213 1.023 1.066 13 640: 100%|██████████| 1/1 [00:04<00:00, 4.51s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:01<00:00, 1.78s/it]
all 4 17 0.878 0.839 0.96 0.712
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/10 0G 0.6774 1.118 1.038 13 640: 100%|██████████| 1/1 [00:04<00:00, 4.54s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:01<00:00, 1.79s/it]
all 4 17 0.814 0.859 0.959 0.647
10 epochs completed in 0.024 hours.
Optimizer stripped from runs\detect\train\weights\last.pt, 19.2MB
Optimizer stripped from runs\detect\train\weights\best.pt, 19.2MB
Validating runs\detect\train\weights\best.pt...
WARNING ⚠️ validating an untrained model YAML will result in 0 mAP.
Ultralytics 8.3.7 🚀 Python-3.8.16 torch-1.13.1 CPU (unknown)
YOLO11s summary (fused): 238 layers, 9,443,760 parameters, 0 gradients, 21.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:01<00:00, 1.54s/it]
all 4 17 0.935 0.788 0.935 0.733
person 3 10 1 0.23 0.804 0.435
dog 1 1 0.963 1 0.995 0.895
horse 1 2 0.925 1 0.995 0.699
elephant 1 2 0.948 0.5 0.828 0.477
umbrella 1 1 0.849 1 0.995 0.995
potted plant 1 1 0.923 1 0.995 0.895
Speed: 3.1ms preprocess, 368.9ms inference, 0.0ms loss, 3.0ms postprocess per image
Results saved to runs\detect\train
PS C:\Users\liguopu\Downloads\ultralytics-main> 训练完成后,能看到runs\detect\train保存的权重和训练信息
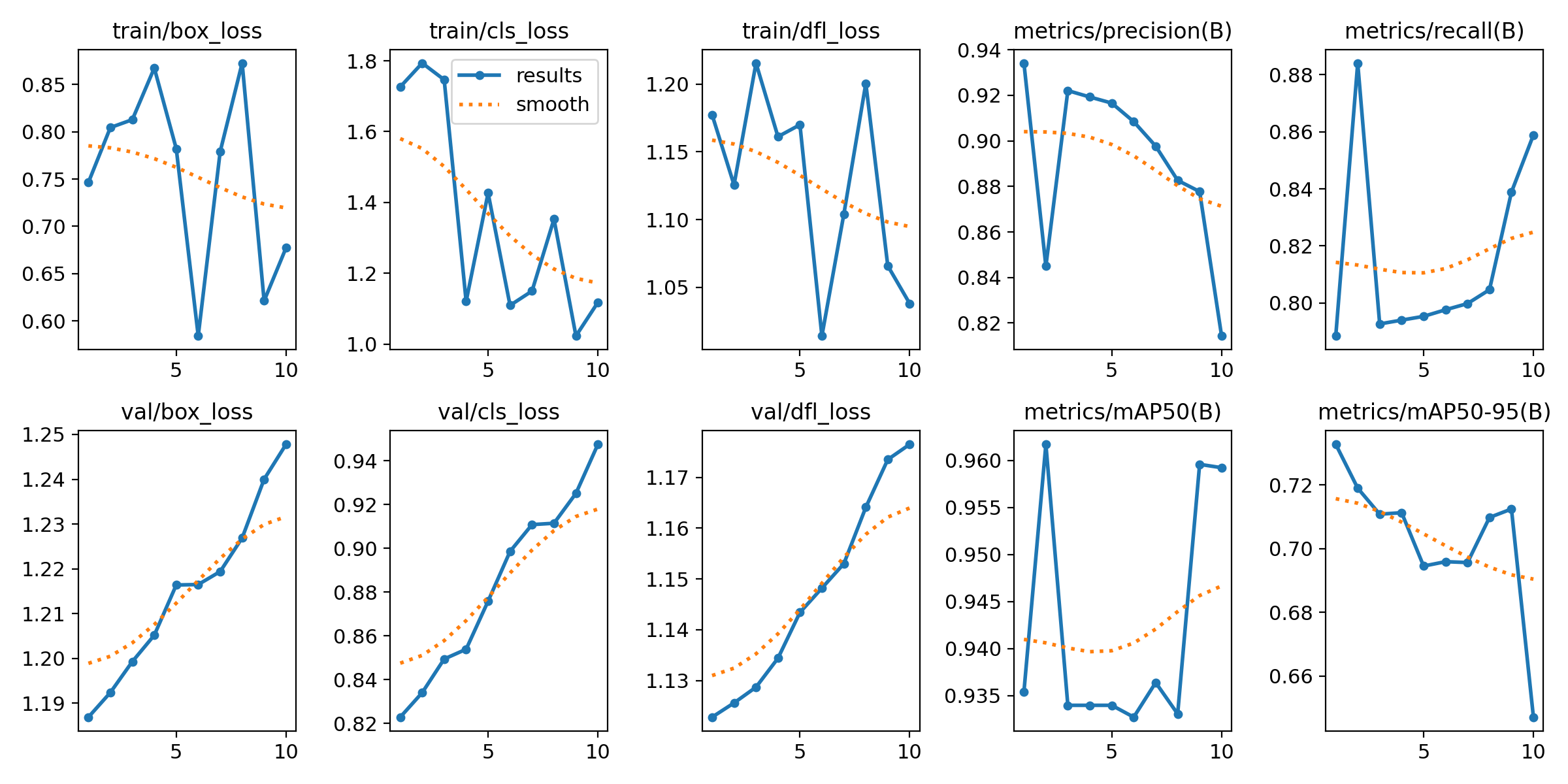
训练图像和标签的示例:

三、YOLO11模型训练——旋转目标检测
其实和上面的代码,基本是一样的,只需改变模型权重和吗模型配置文件就可以了。
模型训练简洁版
YOLO11模型训练,整体思路流程:
- 加载模型:使用 YOLO 类指定模型的配置文件
yolo11s-obb.yaml并加载预训练权重yolo11s-obb.pt。 - 执行训练:调用
model.train()方法,指定数据集dota8.yaml,设置训练轮数为 10,图像大小为 640 像素。 - 保存训练结果:训练完成后,结果保存在
results中,包含损失和精度等信息。
示例代码,如下所示:
from ultralytics import YOLO
# 加载YOLO模型的配置文件,并加载预训练权重文件
model = YOLO("yolo11s-obb.yaml").load("weights/yolo11s-obb.pt")
# 使用dota8.yaml数据集进行训练,训练10个epoch,并将图像大小设置为640像素
results = model.train(data="dota8.yaml", epochs=10, imgsz=640)
然后执行程序,开始训练:
Transferred 535/541 items from pretrained weights
Ultralytics 8.3.7 🚀 Python-3.8.16 torch-1.13.1 CPU (unknown)
WARNING ⚠️ Upgrade to torch>=2.0.0 for deterministic training.
engine\trainer: task=obb, mode=train, model=yolo11s-obb.yaml, data=dota8.yaml, epochs=10, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train, exist_ok=False, pretrained=weights/yolo11s-obb.pt, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs\obb\train
Overriding model.yaml nc=80 with nc=15
from n params module arguments
0 -1 1 928 ultralytics.nn.modules.conv.Conv [3, 32, 3, 2]
1 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
2 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
3 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
4 -1 1 103360 ultralytics.nn.modules.block.C3k2 [128, 256, 1, False, 0.25]
5 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
6 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
7 -1 1 1180672 ultralytics.nn.modules.conv.Conv [256, 512, 3, 2]
8 -1 1 1380352 ultralytics.nn.modules.block.C3k2 [512, 512, 1, True]
9 -1 1 656896 ultralytics.nn.modules.block.SPPF [512, 512, 5]
10 -1 1 990976 ultralytics.nn.modules.block.C2PSA [512, 512, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 443776 ultralytics.nn.modules.block.C3k2 [768, 256, 1, False]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 127680 ultralytics.nn.modules.block.C3k2 [512, 128, 1, False]
17 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 345472 ultralytics.nn.modules.block.C3k2 [384, 256, 1, False]
20 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 1511424 ultralytics.nn.modules.block.C3k2 [768, 512, 1, True]
23 [16, 19, 22] 1 1111392 ultralytics.nn.modules.head.OBB [15, 1, [128, 256, 512]]
YOLO11s-obb summary: 344 layers, 9,719,776 parameters, 9,719,760 gradients, 22.6 GFLOPs
Transferred 535/541 items from pretrained weights
TensorBoard: Start with 'tensorboard --logdir runs\obb\train', view at http://localhost:6006/
Freezing layer 'model.23.dfl.conv.weight'
train: Scanning C:\Users\liguopu\Downloads\ultralytics-main\datasets\dota8\labels\train... 4 images, 0 backgrounds, 0 corrupt: 100%|██████████| 4/4 [00:00<00:00, 83.05it/s]
train: New cache created: C:\Users\liguopu\Downloads\ultralytics-main\datasets\dota8\labels\train.cache
val: Scanning C:\Users\liguopu\Downloads\ultralytics-main\datasets\dota8\labels\val... 4 images, 0 backgrounds, 0 corrupt: 100%|██████████| 4/4 [00:00<00:00, 138.08it/s]
val: New cache created: C:\Users\liguopu\Downloads\ultralytics-main\datasets\dota8\labels\val.cache
Plotting labels to runs\obb\train\labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.000526, momentum=0.9) with parameter groups 87 weight(decay=0.0), 97 weight(decay=0.0005), 96 bias(decay=0.0)
TensorBoard: model graph visualization added ✅
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs\obb\train
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/10 0G 0.7968 4.385 1.142 121 640: 100%|██████████| 1/1 [00:15<00:00, 15.43s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:05<00:00, 5.70s/it]
all 4 8 0.0849 0.75 0.491 0.326
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/10 0G 0.8239 4.402 1.148 124 640: 100%|██████████| 1/1 [00:07<00:00, 7.68s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.94s/it]
all 4 8 0.0863 0.75 0.486 0.322
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/10 0G 0.7333 4.395 1.144 107 640: 100%|██████████| 1/1 [00:07<00:00, 7.14s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.63s/it]
all 4 8 0.0841 0.75 0.484 0.311
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/10 0G 0.7834 4.376 1.167 99 640: 100%|██████████| 1/1 [00:05<00:00, 5.75s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.22s/it]
all 4 8 0.0822 0.75 0.48 0.314
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/10 0G 0.8125 4.363 1.454 84 640: 100%|██████████| 1/1 [00:06<00:00, 6.60s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.45s/it]
all 4 8 0.0691 0.639 0.469 0.295
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
6/10 0G 0.8424 4.348 1.417 125 640: 100%|██████████| 1/1 [00:06<00:00, 6.89s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.89s/it]
all 4 8 0.0527 0.806 0.464 0.287
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
7/10 0G 0.8203 4.349 1.783 123 640: 100%|██████████| 1/1 [00:05<00:00, 5.66s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.61s/it]
all 4 8 0.0532 0.806 0.464 0.288
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
8/10 0G 0.8241 4.314 1.475 98 640: 100%|██████████| 1/1 [00:05<00:00, 5.90s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.19s/it]
all 4 8 0.0842 0.75 0.405 0.288
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
9/10 0G 0.8575 4.347 1.505 116 640: 100%|██████████| 1/1 [00:05<00:00, 5.11s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.69s/it]
all 4 8 0.0864 0.75 0.403 0.282
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/10 0G 0.8994 4.323 1.629 125 640: 100%|██████████| 1/1 [00:05<00:00, 5.21s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.81s/it]
all 4 8 0.0652 0.917 0.397 0.277
10 epochs completed in 0.038 hours.
Optimizer stripped from runs\obb\train\weights\last.pt, 19.9MB
Optimizer stripped from runs\obb\train\weights\best.pt, 19.9MB
Validating runs\obb\train\weights\best.pt...
WARNING ⚠️ validating an untrained model YAML will result in 0 mAP.
Ultralytics 8.3.7 🚀 Python-3.8.16 torch-1.13.1 CPU (unknown)
YOLO11s-obb summary (fused): 257 layers, 9,704,592 parameters, 0 gradients, 22.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/1 [00:00<?, ?it/s]WARNING ⚠️ NMS time limit 2.200s exceeded
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:04<00:00, 4.70s/it]
all 4 8 0.104 0.667 0.509 0.342
baseball diamond 3 4 0 0 0 0
basketball court 1 3 0.2 1 0.533 0.329
soccer ball field 1 1 0.111 1 0.995 0.697
Speed: 1.9ms preprocess, 376.6ms inference, 0.0ms loss, 740.0ms postprocess per image
Results saved to runs\obb\train训练完成后,能看到保存的权重和训练信息
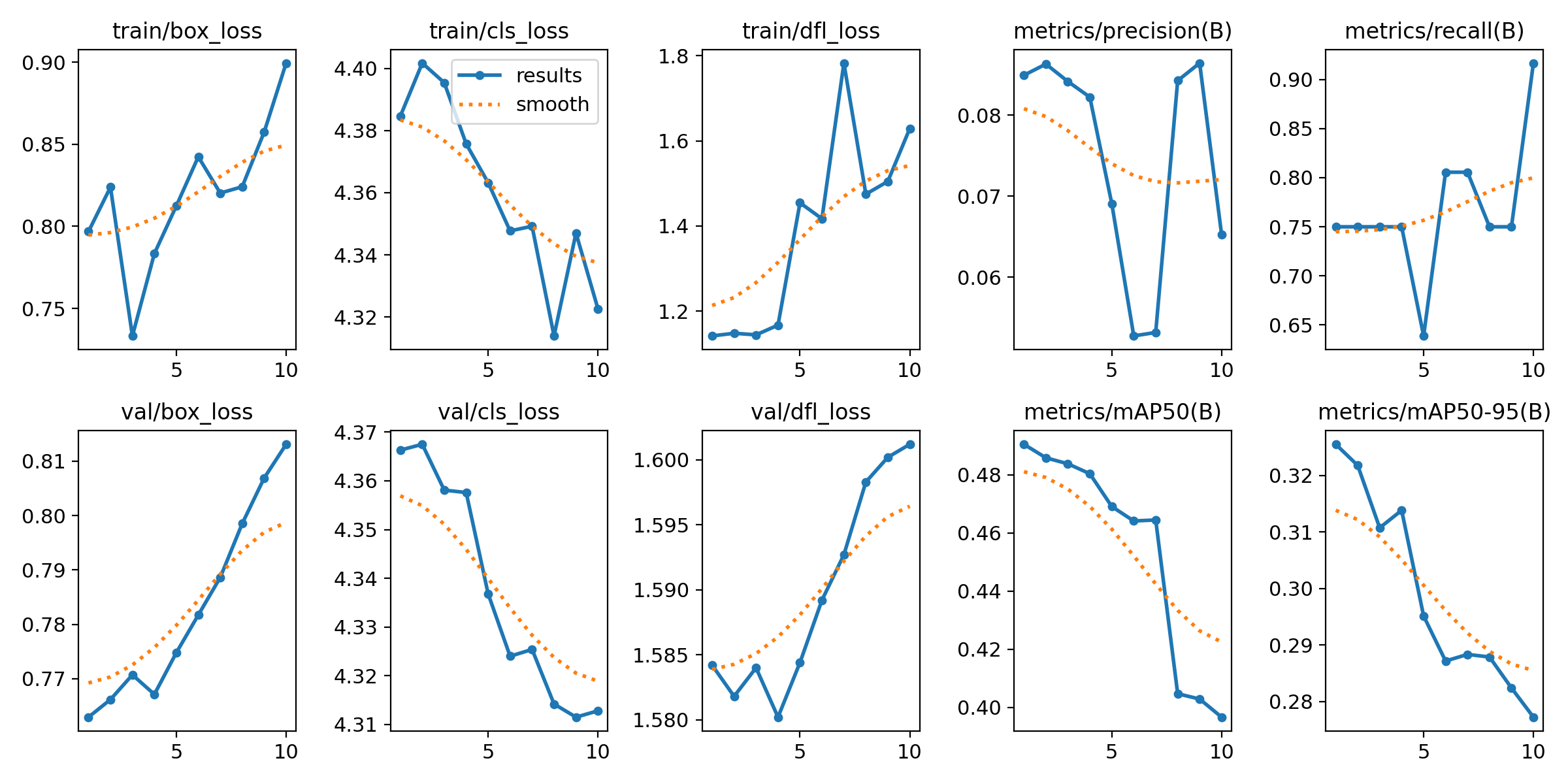
训练图像和标签的示例:

四、YOLO11模型训练——关键点姿态估计
其实和上面的代码,基本是一样的,只需改变模型权重和吗模型配置文件就可以了。
模型训练简洁版
YOLO11模型训练,整体思路流程:
- 加载模型:使用 YOLO 类指定模型的配置文件
yolo11s-pose.yaml并加载预训练权重yolo11s-pose.pt。 - 执行训练:调用
model.train()方法,指定数据集coco8-pose.yaml,设置训练轮数为 10,图像大小为 640 像素。 - 保存训练结果:训练完成后,结果保存在
results中,包含损失和精度等信息。
示例代码,如下所示:
from ultralytics import YOLO
# 加载YOLO模型的配置文件,并加载预训练权重文件
model = YOLO("yolo11s-pose.yaml").load("weights/yolo11s-pose.pt")
# 使用coco8-pose.yaml数据集进行训练,训练10个epoch,并将图像大小设置为640像素
results = model.train(data="coco8-pose.yaml", epochs=10, imgsz=640)
然后执行程序,开始训练:
Transferred 535/541 items from pretrained weights
Ultralytics 8.3.7 🚀 Python-3.8.16 torch-1.13.1 CPU (unknown)
WARNING ⚠️ Upgrade to torch>=2.0.0 for deterministic training.
engine\trainer: task=pose, mode=train, model=yolo11s-pose.yaml, data=coco8-pose.yaml, epochs=10, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train, exist_ok=False, pretrained=weights/yolo11s-pose.pt, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs\pose\train
Dataset 'coco8-pose.yaml' images not found ⚠️, missing path 'C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-pose\images\val'
Downloading https://ultralytics.com/assets/coco8-pose.zip to 'C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-pose.zip'...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 334k/334k [00:03<00:00, 108kB/s]
Unzipping C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-pose.zip to C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-pose...: 100%|██████████| 27/27 [00:00<00:00, 1018.29file/s]
Dataset download success ✅ (5.6s), saved to C:\Users\liguopu\Downloads\ultralytics-main\datasets
Overriding model.yaml nc=80 with nc=1
from n params module arguments
0 -1 1 928 ultralytics.nn.modules.conv.Conv [3, 32, 3, 2]
1 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
2 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
3 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
4 -1 1 103360 ultralytics.nn.modules.block.C3k2 [128, 256, 1, False, 0.25]
5 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
6 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
7 -1 1 1180672 ultralytics.nn.modules.conv.Conv [256, 512, 3, 2]
8 -1 1 1380352 ultralytics.nn.modules.block.C3k2 [512, 512, 1, True]
9 -1 1 656896 ultralytics.nn.modules.block.SPPF [512, 512, 5]
10 -1 1 990976 ultralytics.nn.modules.block.C2PSA [512, 512, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 443776 ultralytics.nn.modules.block.C3k2 [768, 256, 1, False]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 127680 ultralytics.nn.modules.block.C3k2 [512, 128, 1, False]
17 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 345472 ultralytics.nn.modules.block.C3k2 [384, 256, 1, False]
20 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 1511424 ultralytics.nn.modules.block.C3k2 [768, 512, 1, True]
23 [16, 19, 22] 1 1309854 ultralytics.nn.modules.head.Pose [1, [17, 3], [128, 256, 512]]
YOLO11s-pose summary: 344 layers, 9,918,238 parameters, 9,918,222 gradients, 23.3 GFLOPs
Transferred 535/541 items from pretrained weights
TensorBoard: Start with 'tensorboard --logdir runs\pose\train', view at http://localhost:6006/
Freezing layer 'model.23.dfl.conv.weight'
train: Scanning C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-pose\labels\train... 4 images, 0 backgrounds, 0 corrupt: 100%|██████████| 4/4 [00:00<00:00, 111.81it/s]
train: New cache created: C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-pose\labels\train.cache
val: Scanning C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-pose\labels\val... 4 images, 0 backgrounds, 0 corrupt: 100%|██████████| 4/4 [00:00<00:00, 116.71it/s]
val: New cache created: C:\Users\liguopu\Downloads\ultralytics-main\datasets\coco8-pose\labels\val.cache
Plotting labels to runs\pose\train\labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.002, momentum=0.9) with parameter groups 87 weight(decay=0.0), 97 weight(decay=0.0005), 96 bias(decay=0.0)
TensorBoard: model graph visualization added ✅
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs\pose\train
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
1/10 0G 0.9547 1.8 0.3144 2.728 1.214 7 640: 100%|██████████| 1/1 [00:05<00:00, 5.14s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.41s/it]
all 4 14 0.891 0.429 0.709 0.588 1 0.354 0.561 0.315
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
2/10 0G 0.6826 1.566 0.3834 2.278 1.16 7 640: 100%|██████████| 1/1 [00:06<00:00, 6.06s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.42s/it]
all 4 14 0.915 0.5 0.717 0.593 1 0.443 0.562 0.329
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
3/10 0G 0.8437 1.375 0.3163 3.233 1.011 7 640: 100%|██████████| 1/1 [00:05<00:00, 5.30s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.15s/it]
all 4 14 0.786 0.5 0.704 0.568 0.833 0.5 0.531 0.307
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
4/10 0G 0.7555 1.297 0.3225 2.15 1.057 7 640: 100%|██████████| 1/1 [00:06<00:00, 6.90s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.33s/it]
all 4 14 1 0.57 0.748 0.606 0.916 0.5 0.563 0.31
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
5/10 0G 0.6532 1.069 0.276 2.608 0.9624 7 640: 100%|██████████| 1/1 [00:06<00:00, 6.12s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.28s/it]
all 4 14 1 0.624 0.771 0.645 0.901 0.5 0.632 0.335
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
6/10 0G 0.865 1.923 0.268 2.503 1.143 7 640: 100%|██████████| 1/1 [00:05<00:00, 5.51s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.15s/it]
all 4 14 0.948 0.643 0.775 0.652 0.876 0.571 0.642 0.33
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
7/10 0G 0.6749 1.457 0.326 1.908 0.9575 7 640: 100%|██████████| 1/1 [00:05<00:00, 5.49s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.15s/it]
all 4 14 0.957 0.643 0.763 0.643 0.823 0.571 0.644 0.326
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
8/10 0G 0.4598 1.208 0.2935 1.765 0.9645 7 640: 100%|██████████| 1/1 [00:05<00:00, 5.50s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.09s/it]
all 4 14 1 0.641 0.77 0.647 0.832 0.571 0.651 0.338
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
9/10 0G 0.6678 1.003 0.2908 1.754 0.9891 7 640: 100%|██████████| 1/1 [00:05<00:00, 5.70s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.27s/it]
all 4 14 0.906 0.693 0.766 0.647 0.963 0.5 0.649 0.338
Epoch GPU_mem box_loss pose_loss kobj_loss cls_loss dfl_loss Instances Size
10/10 0G 0.8137 1.487 0.2731 2.158 0.8752 7 640: 100%|██████████| 1/1 [00:05<00:00, 5.50s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:02<00:00, 2.16s/it]
all 4 14 0.898 0.63 0.763 0.639 0.967 0.5 0.65 0.329
10 epochs completed in 0.028 hours.
Optimizer stripped from runs\pose\train\weights\last.pt, 20.2MB
Optimizer stripped from runs\pose\train\weights\best.pt, 20.2MB
Validating runs\pose\train\weights\best.pt...
WARNING ⚠️ validating an untrained model YAML will result in 0 mAP.
Ultralytics 8.3.7 🚀 Python-3.8.16 torch-1.13.1 CPU (unknown)
YOLO11s-pose summary (fused): 257 layers, 9,902,940 parameters, 0 gradients, 23.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:01<00:00, 1.88s/it]
all 4 14 1 0.642 0.769 0.646 0.83 0.571 0.651 0.338
Speed: 2.5ms preprocess, 404.4ms inference, 0.0ms loss, 52.5ms postprocess per image
Results saved to runs\pose\train训练完成后,能看到保存的权重和训练信息
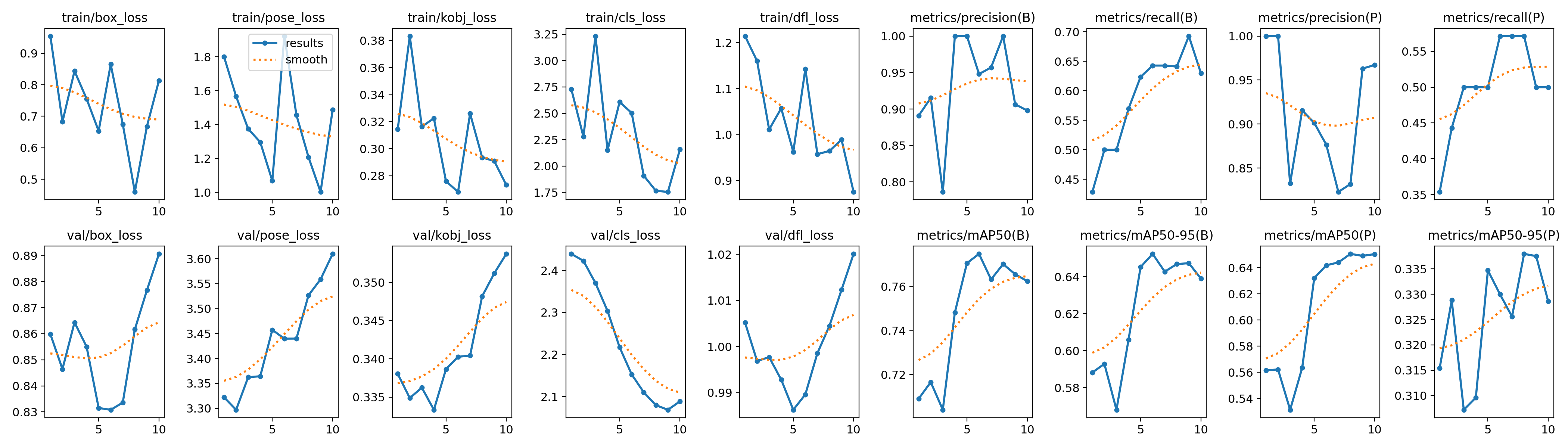
训练图像和标签的示例:

五、YOLO11模型训练——代码浅析
模型训练主要调用model.train( )函数,先看一下这个函数的源代码。代码位置:ultralytics/engine/model.py
该方法主要用于训练模型,支持自定义的训练参数和配置。
trainer(可选): 自定义的BaseTrainer实例。如果未提供,则使用默认的训练逻辑。**kwargs: 提供训练配置的可选参数,比如:data: 数据集配置文件的路径。epochs: 训练的轮次数。batch_size: 训练时的批次大小。imgsz: 输入图像的大小。device: 训练设备(如 'cuda' 或 'cpu')。workers: 数据加载线程的数量。optimizer: 用于训练的优化器。lr0: 初始学习率。patience: 用于早停的轮次等待数量。
def train(
self,
trainer=None,
**kwargs,
):
# 检查模型是否是 PyTorch 模型
self._check_is_pytorch_model()
# 如果当前会话中有 Ultralytics HUB 的加载模型
if hasattr(self.session, "model") and self.session.model.id:
# 如果本地有提供任何参数,发出警告并忽略本地参数,使用 HUB 参数
if any(kwargs):
LOGGER.warning("WARNING ⚠️ 使用 HUB 的训练参数,忽略本地训练参数。")
kwargs = self.session.train_args # 使用 HUB 提供的参数覆盖本地参数
# 检查是否有 pip 更新
checks.check_pip_update_available()
# 处理用户提供的配置文件,加载并解析 YAML 文件
overrides = yaml_load(checks.check_yaml(kwargs["cfg"])) if kwargs.get("cfg") else self.overrides
custom = {
# 如果 'cfg' 包含 'data',优先处理
"data": overrides.get("data") or DEFAULT_CFG_DICT["data"] or TASK2DATA[self.task],
"model": self.overrides["model"],
"task": self.task,
} # 方法默认配置
# 合并最终的训练参数,优先级从左到右
args = {**overrides, **custom, **kwargs, "mode": "train"}
# 如果指定了恢复训练参数,设置检查点路径
if args.get("resume"):
args["resume"] = self.ckpt_path
# 初始化训练器实例,传入合并后的参数和回调函数
self.trainer = (trainer or self._smart_load("trainer"))(overrides=args, _callbacks=self.callbacks)
# 如果不是恢复训练,手动设置模型
if not args.get("resume"):
self.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.model.yaml)
self.model = self.trainer.model
# 将 HUB 会话附加到训练器
self.trainer.hub_session = self.session
# 开始训练
self.trainer.train()
# 训练结束后更新模型和配置
if RANK in {-1, 0}:
ckpt = self.trainer.best if self.trainer.best.exists() else self.trainer.last
self.model, _ = attempt_load_one_weight(ckpt) # 加载最佳或最后的检查点权重
self.overrides = self.model.args # 更新配置
self.metrics = getattr(self.trainer.validator, "metrics", None) # 获取训练指标
return self.metrics # 返回训练的评估指标
方法内部步骤解析
-
配置处理 (
overrides):- 如果用户提供了
cfg文件,该方法加载并解析该文件的内容。否则,使用默认的模型配置参数。 - 定义
custom字典来处理特定任务和数据集的默认配置。
- 如果用户提供了
-
参数合并 (
args):- 将
overrides、custom和kwargs参数合并,优先级从左到右,形成完整的训练参数集。
- 将
-
检查是否恢复训练 (
args.get("resume")):- 如果指定了恢复训练的参数,方法会将
args["resume"]设置为上次的检查点路径。
- 如果指定了恢复训练的参数,方法会将
-
训练器实例化 (
self.trainer = ...):- 使用提供的或默认的
trainer实例进行训练器的初始化,并传递合并后的参数和回调。 - 如果不是恢复训练,会手动设置模型,调用
self.trainer.get_model来获取模型实例。
- 使用提供的或默认的
-
Ultralytics HUB 会话:
- 如果存在 HUB 会话,它将被附加到训练器中。可以处理从检查点恢复训练、与 Ultralytics HUB 集成,并在训练后更新模型和配置。
-
执行训练 (
self.trainer.train()):- 调用
trainer.train()方法开始模型训练。
- 调用
-
更新模型和配置:
- 如果训练完成后,方法会更新模型为最佳检查点 (
self.trainer.best) 或最后的检查点 (self.trainer.last)。 - 重新加载模型权重,并更新
overrides为当前模型的配置参数。 - 返回训练的评估指标。
- 如果训练完成后,方法会更新模型为最佳检查点 (
这个 train 方法为训练提供了高度的灵活性,允许用户使用本地或云端配置来进行训练。
它不仅能处理从检查点恢复训练,还能动态加载或更新模型,并支持不同的训练器和自定义配置,是一个全面的训练管理方法。
模型训练主要调用model.train( )函数,然后这个函数会根据检测任务,来到ultralytics/models/yolo/xxx/train.py中;
比如是目标检测任务,会来到ultralytics/models/yolo/detect/train.py中,然后实例化DetectionTrainer类,进行训练
如果是实例分割任务,会来到ultralytics/models/yolo/segment/train.py中,然后实例化SegmentationTrainer类,进行训练
如果是关键点姿态估计任务,会来到ultralytics/models/yolo/pose/train.py中,然后实例化PoseTrainer类,进行训练
如果是物体分类任务,会来到ultralytics/models/yolo/classify/train.py中,然后实例化ClassificationTrainer类,进行训练
如果是旋转目标检测任务,会来到ultralytics/models/yolo/obb/train.py中,然后实例化OBBTrainer类,进行训练
它们都继承BaseTrainer类,这个基础训练的类是通用的,位置在:ultralytics/engine/trainer.py
下面以目标检测为例子,详细分析一下DetectionTrainer类
下面看看DetectionTrainer类的源代码:
class DetectionTrainer(BaseTrainer):
def build_dataset(self, img_path, mode="train", batch=None):
"""
构建 YOLO 数据集。
参数:
img_path (str): 图像文件夹的路径。
mode (str): 模式,`train` 用于训练,`val` 用于验证,用户可以为每种模式自定义不同的增强方式。
batch (int, optional): 批大小,用于 `rect` 模式。默认为 None。
"""
# 计算步幅,默认为32
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
# 调用构建 YOLO 数据集的函数
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == "val", stride=gs)
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode="train"):
"""构建并返回数据加载器。"""
assert mode in {"train", "val"}, f"模式必须为 'train' 或 'val',而不是 {mode}。"
# 使用 torch_distributed_zero_first 确保只在 DDP 模式下初始化一次 *.cache
with torch_distributed_zero_first(rank):
dataset = self.build_dataset(dataset_path, mode, batch_size)
shuffle = mode == "train"
# 如果是矩形数据集且处于训练模式,禁用数据打乱
if getattr(dataset, "rect", False) and shuffle:
LOGGER.warning("⚠️ 警告: 'rect=True' 与 DataLoader 的 shuffle 不兼容,将 shuffle 设置为 False")
shuffle = False
# 设置工作线程数量
workers = self.args.workers if mode == "train" else self.args.workers * 2
# 返回数据加载器
return build_dataloader(dataset, batch_size, workers, shuffle, rank)
def preprocess_batch(self, batch):
"""预处理图像批次,缩放图像并转换为 float 类型。"""
# 将图像移到指定设备(例如 GPU),并将像素值归一化到 [0, 1] 范围
batch["img"] = batch["img"].to(self.device, non_blocking=True).float() / 255
if self.args.multi_scale:
# 随机调整图像大小(多尺度训练)
imgs = batch["img"]
sz = (
random.randrange(int(self.args.imgsz * 0.5), int(self.args.imgsz * 1.5 + self.stride))
// self.stride
* self.stride
) # 计算新的图像尺寸
sf = sz / max(imgs.shape[2:]) # 缩放因子
if sf != 1:
ns = [
math.ceil(x * sf / self.stride) * self.stride for x in imgs.shape[2:]
] # 计算新的形状,确保步幅为 `gs` 的倍数
# 使用双线性插值调整图像大小
imgs = nn.functional.interpolate(imgs, size=ns, mode="bilinear", align_corners=False)
batch["img"] = imgs
return batch
def set_model_attributes(self):
"""
设置模型属性。
"""
# 附加类别数量到模型
self.model.nc = self.data["nc"]
# 附加类别名称到模型
self.model.names = self.data["names"]
# 附加超参数到模型
self.model.args = self.args
def get_model(self, cfg=None, weights=None, verbose=True):
"""返回一个 YOLO 检测模型。"""
# 初始化检测模型
model = DetectionModel(cfg, nc=self.data["nc"], verbose=verbose and RANK == -1)
# 如果提供了权重,则加载权重
if weights:
model.load(weights)
return model
def get_validator(self):
"""返回 YOLO 模型的验证器。"""
# 定义损失名称
self.loss_names = "box_loss", "cls_loss", "dfl_loss"
# 返回检测验证器
return yolo.detect.DetectionValidator(
self.test_loader, save_dir=self.save_dir, args=copy(self.args), _callbacks=self.callbacks
)
def label_loss_items(self, loss_items=None, prefix="train"):
"""
返回带有标记的训练损失字典。
对于分类任务不需要,但对分割和检测任务是必要的。
"""
# 根据损失名称生成对应的键
keys = [f"{prefix}/{x}" for x in self.loss_names]
if loss_items is not None:
# 将损失值转换为小数点后五位
loss_items = [round(float(x), 5) for x in loss_items]
# 返回标记的损失字典
return dict(zip(keys, loss_items))
else:
return keys
def progress_string(self):
"""返回一个包含训练进度(轮次、GPU 内存、损失、实例数量和图像大小)的格式化字符串。"""
# 生成训练进度字符串
return ("\n" + "%11s" * (4 + len(self.loss_names))) % (
"Epoch",
"GPU_mem",
*self.loss_names,
"Instances",
"Size",
)
def plot_training_samples(self, batch, ni):
"""绘制带有标注的训练样本。"""
# 调用函数绘制图像、标注等信息,并保存结果
plot_images(
images=batch["img"],
batch_idx=batch["batch_idx"],
cls=batch["cls"].squeeze(-1),
bboxes=batch["bboxes"],
paths=batch["im_file"],
fname=self.save_dir / f"train_batch{ni}.jpg",
on_plot=self.on_plot,
)
def plot_metrics(self):
"""绘制训练指标图。"""
# 从 CSV 文件中绘制结果并保存图像
plot_results(file=self.csv, on_plot=self.on_plot)
def plot_training_labels(self):
"""绘制 YOLO 模型的训练标注分布图。"""
# 提取并拼接边界框和类别标签
boxes = np.concatenate([lb["bboxes"] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb["cls"] for lb in self.train_loader.dataset.labels], 0)
# 绘制标注分布图并保存
plot_labels(boxes, cls.squeeze(), names=self.data["names"], save_dir=self.save_dir, on_plot=self.on_plot)
这个代码定义了一个 DetectionTrainer 类,用于基于 YOLO 模型进行目标检测任务的训练,它继承了一个基础训练器类 BaseTrainer。
- 数据管道:该类设置了 YOLO 模型的数据管道,从数据集构建(
build_dataset)到构建数据加载器(get_dataloader)。 - 预处理:图像被预处理、缩放,尤其是在多尺度训练下会动态调整尺寸。
- 模型属性:根据数据集调整模型的类别数量和其他参数。
- 训练监控:通过
label_loss_items、progress_string和plot_training_samples等方法提供训练进度、损失跟踪和可视化。 - 模型加载:
get_model方法允许加载 YOLO 模型,并支持使用预训练权重进行初始化。
YOLO11相关文章推荐:
一篇文章快速认识YOLO11 | 关键改进点 | 安装使用 | 模型训练和推理-CSDN博客
YOLO11模型推理 | 目标检测与跟踪 | 实例分割 | 关键点估计 | OBB旋转目标检测-CSDN博客
分享完成~