1 Reserved Unity内存
1.1 常见的共通性问题
这一部分提到的问题没有特定性,不仅仅出现在一种资源内存中。所以,为了避免赘述,此处统一予以讨论。
1.1.1 序列化信息内存占用
Unity引擎的序列化信息种类繁多,其中最为常见且内存占用较大的为SerializedFile。该序列化信息的内存分配主要是项目通过特定API(WWW.LoadFromCacheOrDownload、CreateFromfile等)加载AssetBundle文件所致。
1.1.2 资源内存占用
主要包括Mesh、AnimationClip、RenderTexture等资源。对于未开启“Read/Write Enable选项的Mesh资源,其内存占用是统计在GFX内存中供GPU使用的,但开启该选项后,网格数据会在ReservedUnity中保留一份,便于项目在运行时对Mesh数据进行实时的编辑和修改。同时,如果研发团队同样开启了纹理资源的“Read/Write Enable” 选项(默认情况下为关闭),则纹理资源同样会在Reserved Unity中保留一份,进而造成其更大的内存占用。
1.1.3 疑似冗余现象
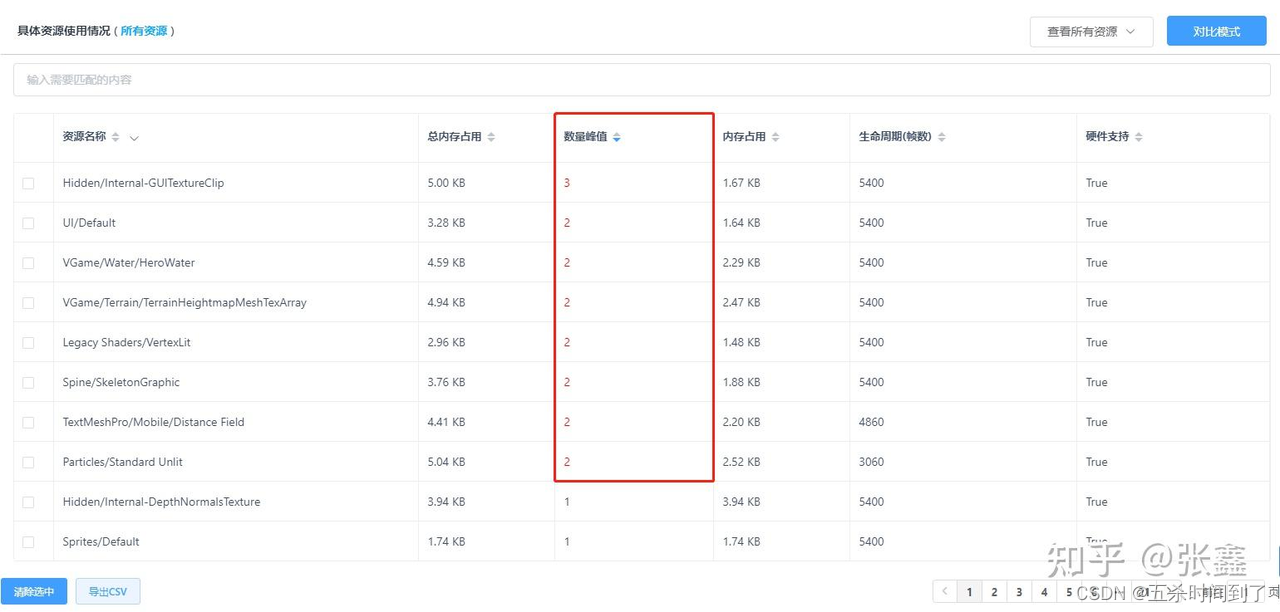
在UWA GOT Online Resource模式报告的具体资源列表(下文简称资源列表)中,我们常能看到某一项资源的数量峰值大于1且被标红。数量峰值同样是资源使用中非常重要的一项指标。所谓“数量峰值”,是指同一资源在同一帧中出现的最大数量。理论上,数量峰值这一参数不应大于1,当数量峰值大于1时,列表中会将其标红,我们称之为疑似冗余资源。
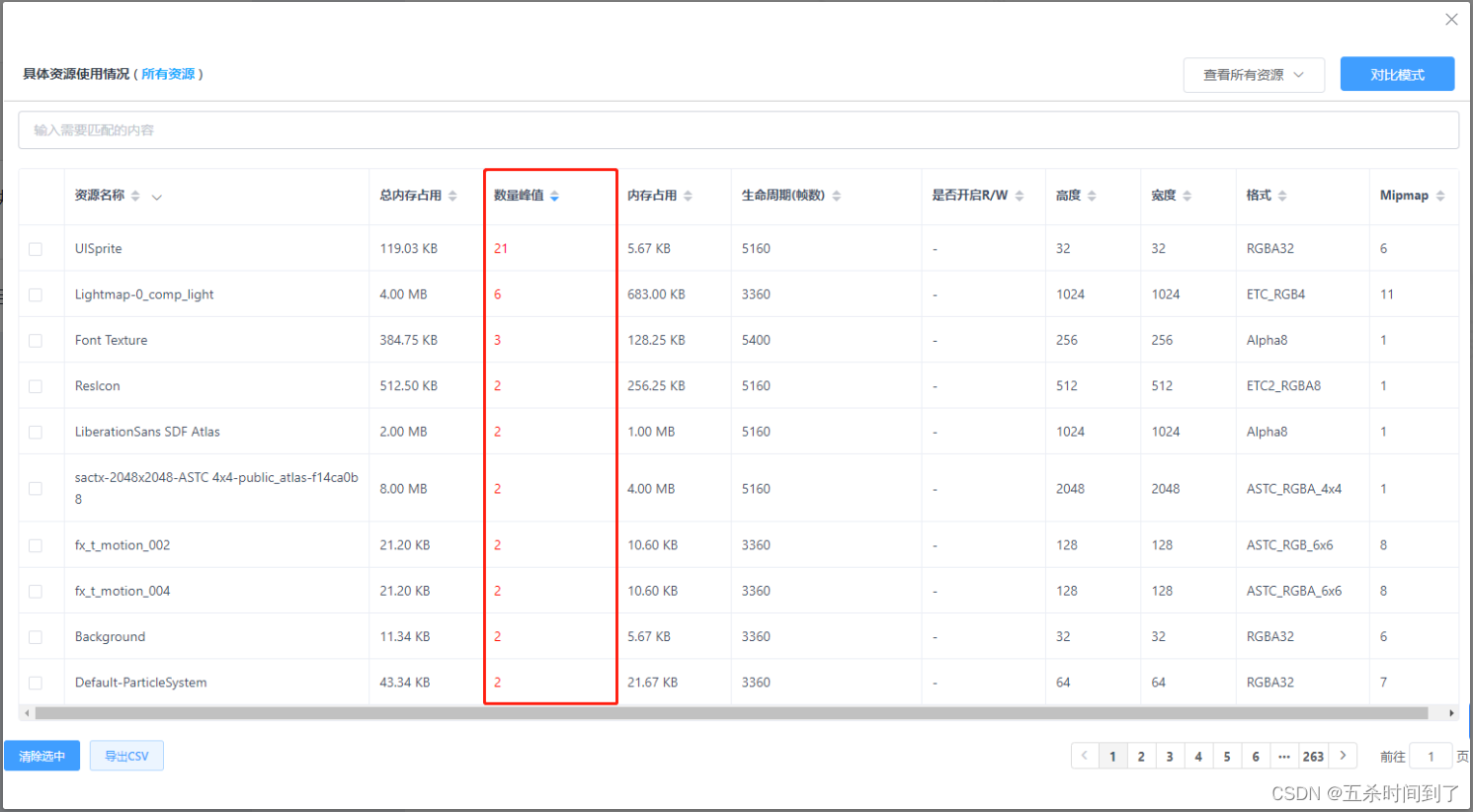
一般情况下,出现这种问题是由AssetBundle资源加载导致的,即在制作AssetBundle文件时,部分共享资源(比如Texture、Mesh等)被同时打入到多份不同的AssetBundle文件中但没有进行依赖打包,从而当加载这些AssetBundle时,内存中出现了多份同样的资源,即资源冗余,建议对其进行严格的检测和完善。
针对排查出的疑似冗余现象,可以使用UWA在线AssetBundle检测工具排査是否确实存在AssetBundle冗余的问题,尽量减少AssetBundle的冗余。建议根据冗余资源的内存大小来决定对冗余问题的优化优先级。
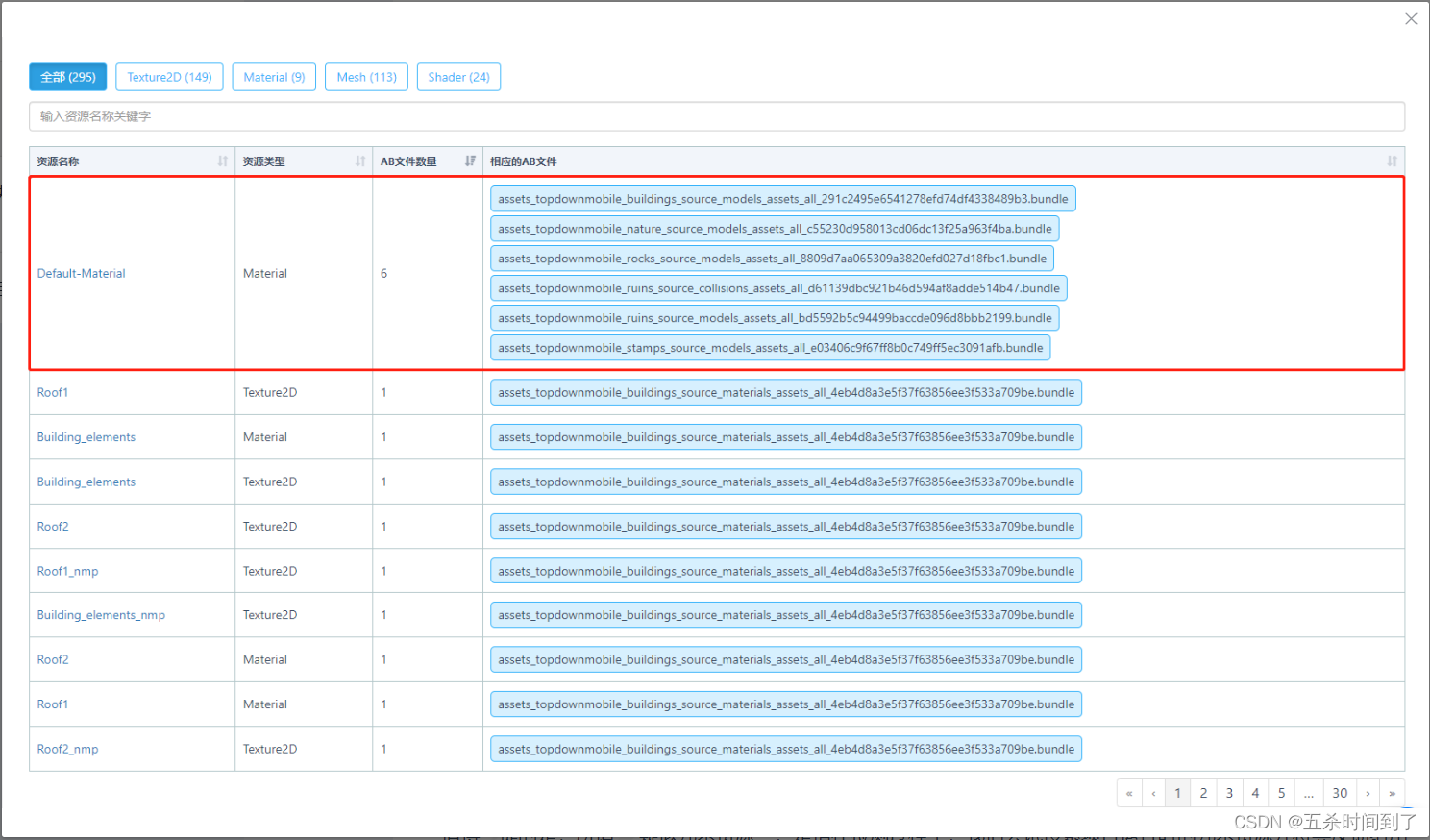
值得一提的是,所谓 “疑似冗余资源”,是指在检测过程中,我们尝试搜索项目运行时的冗余资源并将其反馈给用户。但是,我们并无法保证该项检测的100%正确性。这是因为,我们判断的标准是根据资源的名称、内存占用等属性(因资源类型不同可能有格式、Read/rite、时长等属性,以报告资源列表中呈现的属性为准)而定,当两个资源的名称、内存占用等属性均一致时,我们认为这两个资源可能为同一资源,即其中一个为“冗余” 资源。但项目中确实也存在资源不同但各项属性都相同的情况。因此,我们将通过以上规则提取出的资源归为“疑似冗余资源”。所以,是否确实为冗余资源,还需要结合项目实情和在线AssetBundle检测报告才能下结论
1.1.4 未命名资源
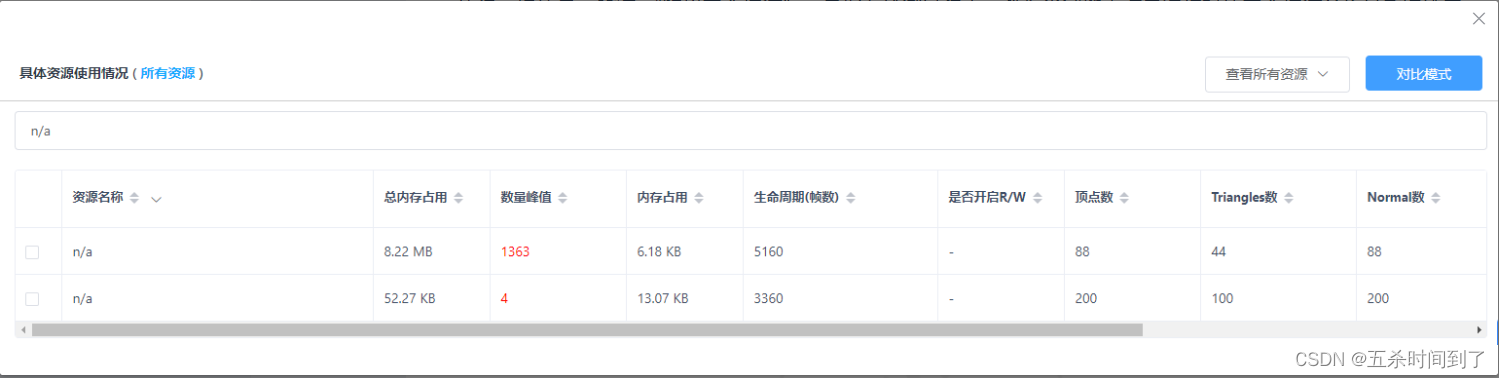
在资源列表中,有时发现存在资源名称为N/A的资源。一般来说名为N/A的资源都是在代码中new出来但是没有予以命名的。建议通过.name方法对这些资源进行命名,方便资源统计和管理,尤其是其中冗余比较严重的或者个别内存占用非常大的N/A资源应予以关注和严格排查。
1.1.5 常驻资源内存占用大
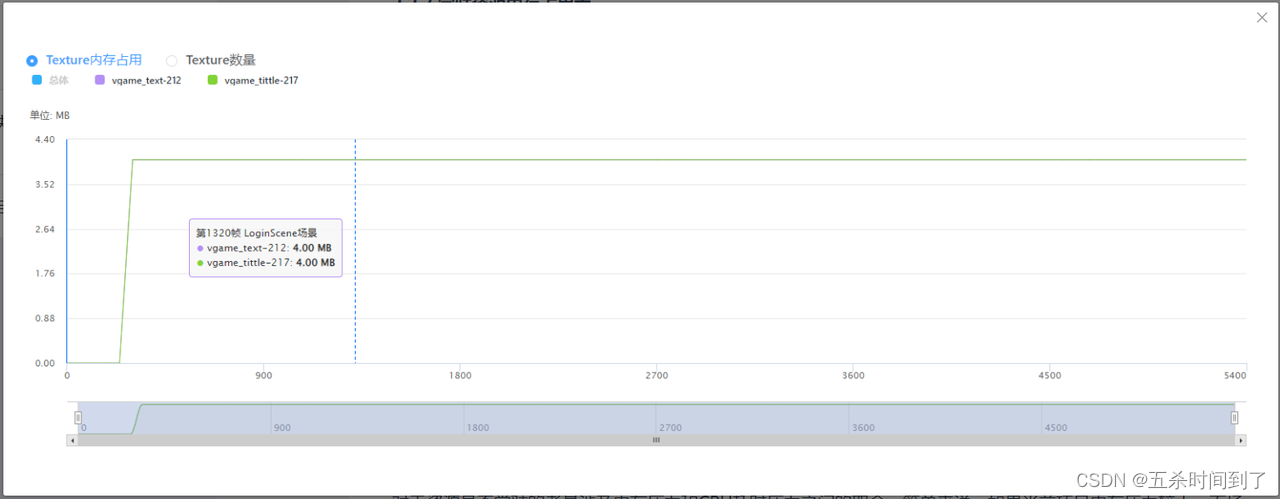
在资源列表中,有时结合资源的生命周期曲线发现,一部分本身内存占用较大的资源在被加载进内存后,驻留在内存中,直到测试流程结束都没有被卸载,可能造成越到游戏后期资源内存占用越大、峰值越高。建议排查这些资源是否有常驻在内存中的必要。如果不再需要被使用,则应检查为什么场景切换时没有卸载:对于持续时间久的单场景中持续驻留的资源,则可以考虑手动卸载。
1.2 纹理资源
1.2.1 纹理格式
纹理格式设置不合理通常是造成纹理资源占据较大内存的主要原因之一。
即便是对于很多已经建立过美术资源标准并统一修改过纹理格式的项目而言,仍然很容易统计到存在大量的RGBA32、ARGB32、RGBA Half、RGB24等格式的纹理资源。
这些格式的纹理不但内存占用较大,还会导致游戏包体较大、加载这些资源的耗时较高、纹理带宽较高等等问题。
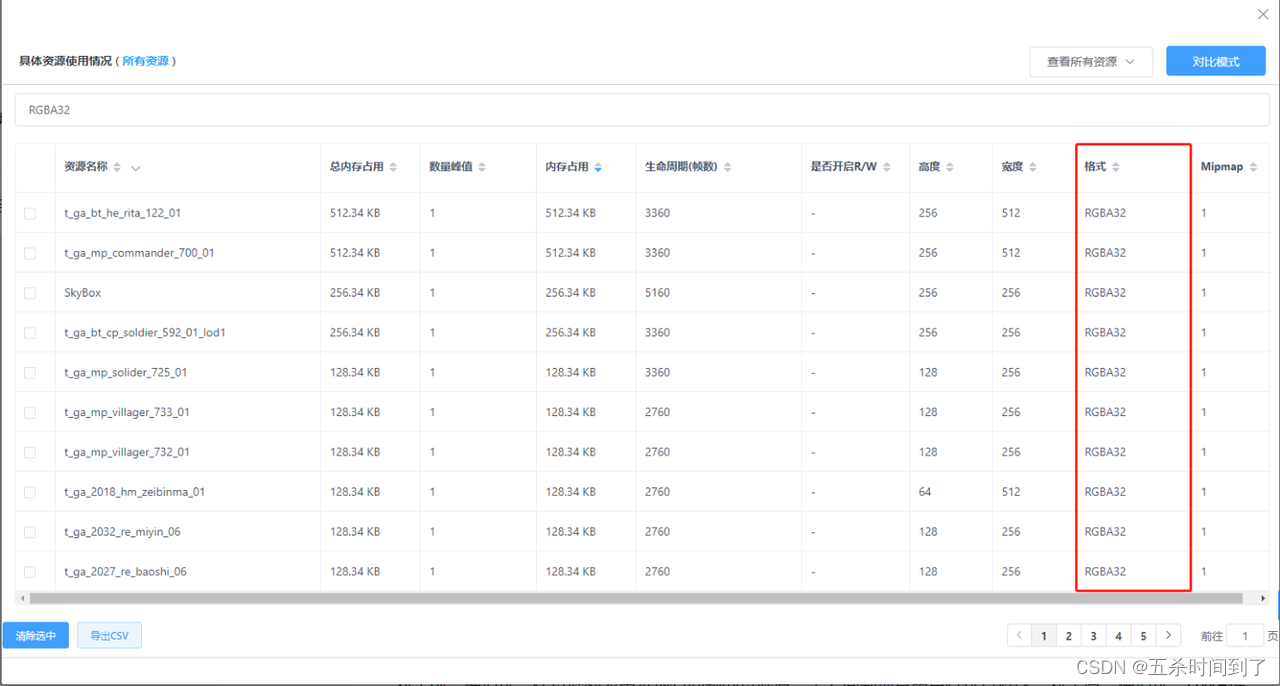
出现这类问题的主要原因:
-
美术命名不规范导致没有被回调函数修改,或者是代码中创建的资源没有设置其纹理格式:
-
硬件或纹理资源本身不支持目标格式纹理,导致被解析为未压缩格式的纹理。
推荐的纹理格式:
-
对 iOS 和 Android 都使用自适应可伸缩纹理压缩 (ATSC)。绝大多数开发目标最低规格设备游戏都支持 ATSC 压缩。
-
适用于面向 A7 设备或更低规格的 iOS 游戏(例如 iPhone 5、5S 等)— 使用 PVRTC
-
适用于面向 2016 之前的设备的 Android 游戏 — 使用 ETC2(Ericsson 纹理压缩)
如果压缩格式(如 PVRTC 和 ETC)的质量不够高,并且目标平台不完全支持 ASTC,请尝试采用 16 位纹理而不是 32 位纹理。
请参阅手册了解有关各平台的推荐纹理压缩格式的更多信息。
1.2.2 分辨率
-
不能让美术人员通过增加纹理大小的方式增加细节,可以选择细节贴图DetailMap或增加高反差保留的方式。
-
对于移动平台来说, 其中最为需要关注的是占据较大分辨率(一般为>1024)的纹理。
-
在不降低视觉效果的情况下尽量减小贴图大小,最好的方式是纹理映射的每一个纹素的大小正好符合屏幕上显示像素的大小,如果纹理小了会造成欠采样,纹理显示模糊,如果纹理大了会造成过采样,纹理显示噪点。 这一点做到完美平衡很难保障
-
可以充分利用Unity编辑器下SceneView->DrawMode->Mipmap来查看在游戏摄像机视角下哪些纹理过采样,哪些纹理欠采样,进而来调整纹理大小。
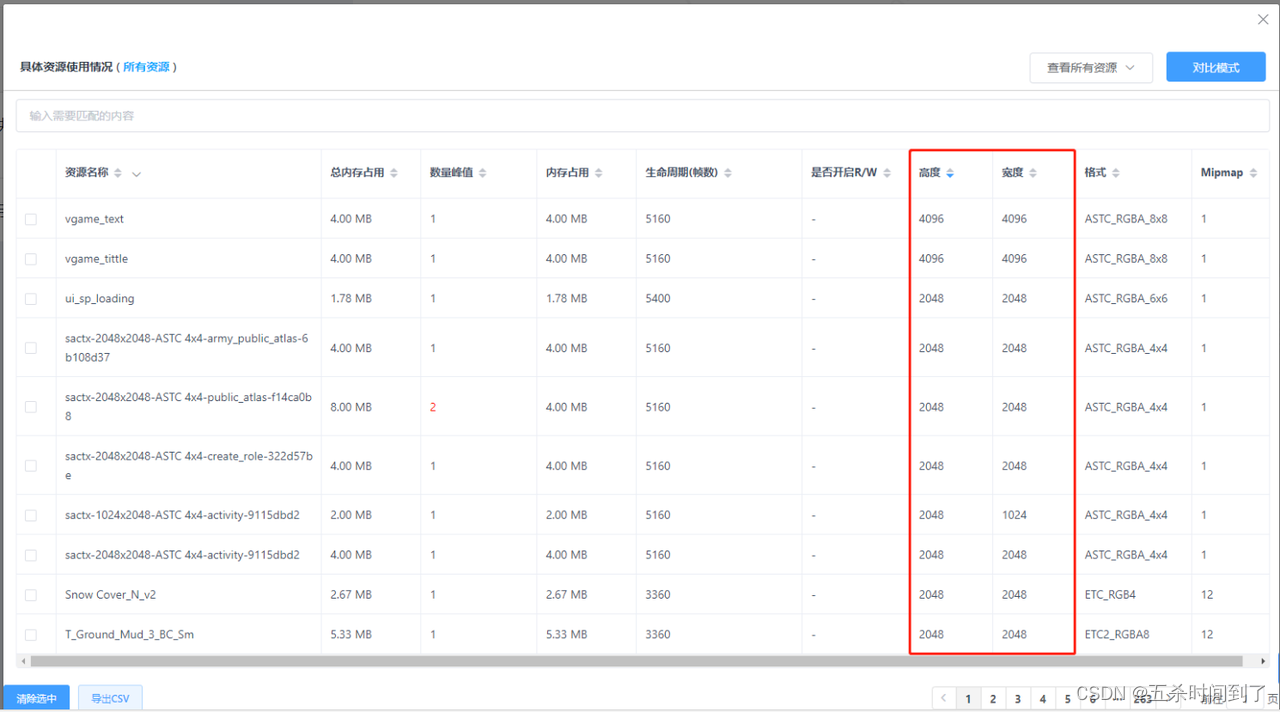
在不同档位的机型上使用不同分辨率大小的纹理资源是非常实用且易操作的分级策略。这一点即便对于图集纹理也同样适用,特别地,Unity针对SpriteAltas提供了Variant功能,可以快捷的复制一份原图集并根据Scale参数降低该变体图集的分辨率,以供较低的分级使用。
1.2.3 禁用Read/Write Enabled
如果启用,此选项在 CPU 和 GPU 可寻址内存中都会创建副本,纹理会占用双倍内存。大多数情况下,应保持此选项为禁用状态。
不需要在运行时进行修改的资源是不需要开启Read/rite Enabled选项的,开发者应排查并关闭不必要的设置从而降低内存开销。
如果要在运行时生成纹理,请通过 Texture2D.Apply 强制执行,并且传入设置为 true 的 makeNoLongerReadable。
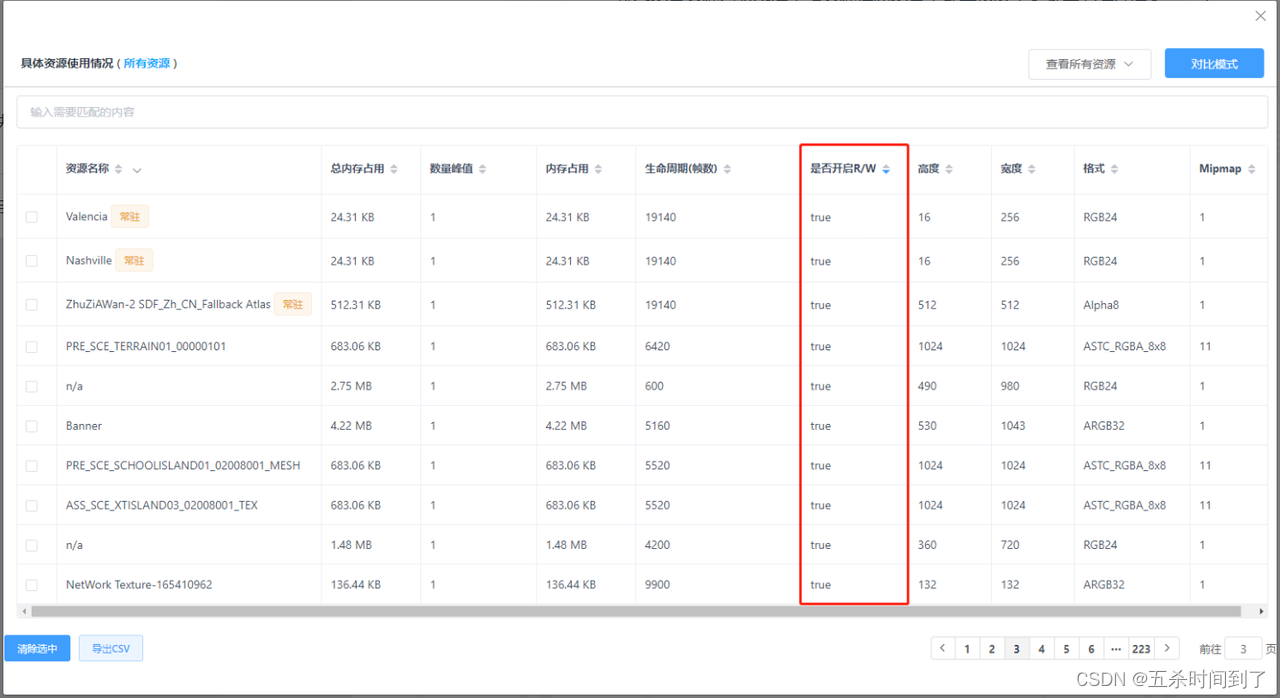
UWA GOT Online Resource模式报告资源列表或是本地资源检测报告
1.2.4 Mipmap
逐级减低分辨率来保存纹理副本。相当于生成了纹理LOD,渲染纹理时,将根据像素在屏幕中占据的纹理空间大小选择合适的Mipmap级别进行采样。
优点:
-
GPU不需要在远距离上对对象进行全分辨率纹理采样,因此可以提高纹理采样性能。
-
解决了远距离下的过采样导致的噪点问题,提高的纹理渲染质量。
缺点:
-
当一张纹理开启Mipmap时,它的内存占用会上升为原始数据的1.33倍。
参数介绍:
-
Border Mip Maps 默认不开启,只有当纹理的是Light Cookies类型时,开启此选项来避免colors bleeding现象导致颜色渗透到较低级别的Mip Level纹理边缘上
-
MipMap Filtering
-
Box 最简单,随尺寸减小,Mipmap纹理变得平滑模糊
-
Kaiser 避免平滑模糊的锐化过滤算法。
-
-
Mip Maps Preserve Coverage 只有需要纹理在开启mipmap后也需要做Alpha Coverage时开启。默认不开启。
-
Fadeout MipMaps 纹理Mipmap随Mip层级淡化为灰色,一般不开启,只有在雾效较大时开启不影响视觉效果。
注意事项:
-
对于在屏幕上大小保持不变的纹理(如 2D 精灵和 UI 图形),Mip Map 不是必需的,对于与摄像机的距离会变化的 3D 模型,请保留 Mip Map为启用状态。
-
如果场景中的3D物体大面积地使用1/2乃至1/4、1/8的Mipmap通道,说明该3D物体使用的纹理分辨率偏高,存在浪费现象。可以改用更低分辨率的纹理。
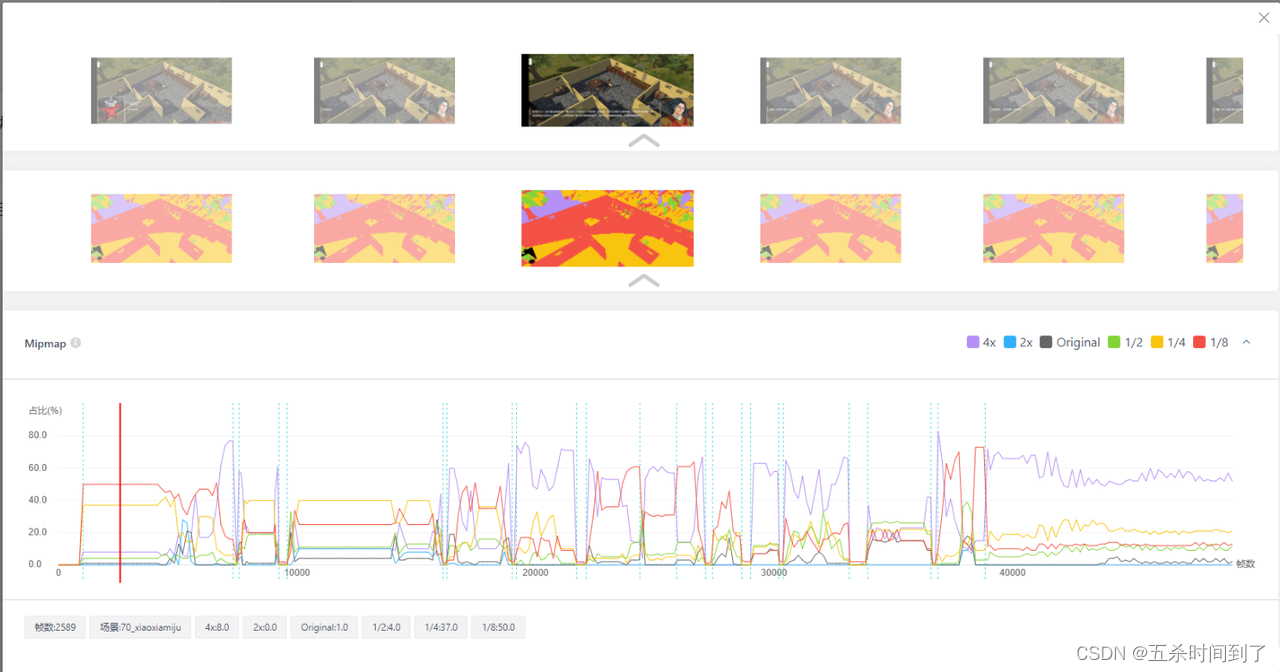
真人真机测试报告中的Mipmap页面
1.2.5 纹理过滤
参数介绍:
-
Nearest Point Filtering(临近点过滤):最简单、计算量最小的纹理过滤形式,但在近距离观察时,纹理会呈现块状。
-
Bilinear Filtering(双线性过滤):会对临近纹素采样并插值化处理,对纹理像素进行着色。双线性过滤会让像素看上去平滑渐变,但近距离观察时,纹理会变得模糊。
-
Trilinear Filtering(三线性过滤):除与双线性过滤相同部分外,还增加了Mipmap等级之间的采样差值混合,用来平滑过度消除Mipmap之间的明显变化。相比双线性过滤GPU渲染带宽将会上升。线性插值采8个采样点(双线性采4个采样点),同样会使Cache Miss的概率变大,从而导致带宽上升,应尽量避免使用三线性过滤。
-
Anisotropic Filtering(各向异性过滤):可以改善纹理在倾斜角度下的视觉效果,更适合用于地表纹理。但会导致GPU渲染带宽上升。其中的原理是,纹理压缩采样时会去读缓存里面的信息,如果没读到就会往离GPU更远的地方去读System Memory,因此所花的时钟周期也就会增多。当开启各向异性导致采样点增多的时候,发生Cache Miss的概率就会变大,从而导致带宽上升的更多在引擎中可以通过脚本关闭纹理资源的各向异性;或者对于需要开启各向异性的纹理,引擎中可以设置其采样次数为1-16,也建议尽量设为较低的值。
注意事项:
-
使用双线性过滤平衡性能和视觉质量。
-
有选择地使用三线性过滤,因为与双线性过滤相比,它需要更多的内存带宽。
-
使用双线性和 2x 各向异性过滤,而不是三线性和 1x 各向异性过滤,因为这样做不仅视觉效果更好,而且性能也更高。
-
保持较低的各向异性级别。仅对关键游戏资源使用高于 2 的级别。
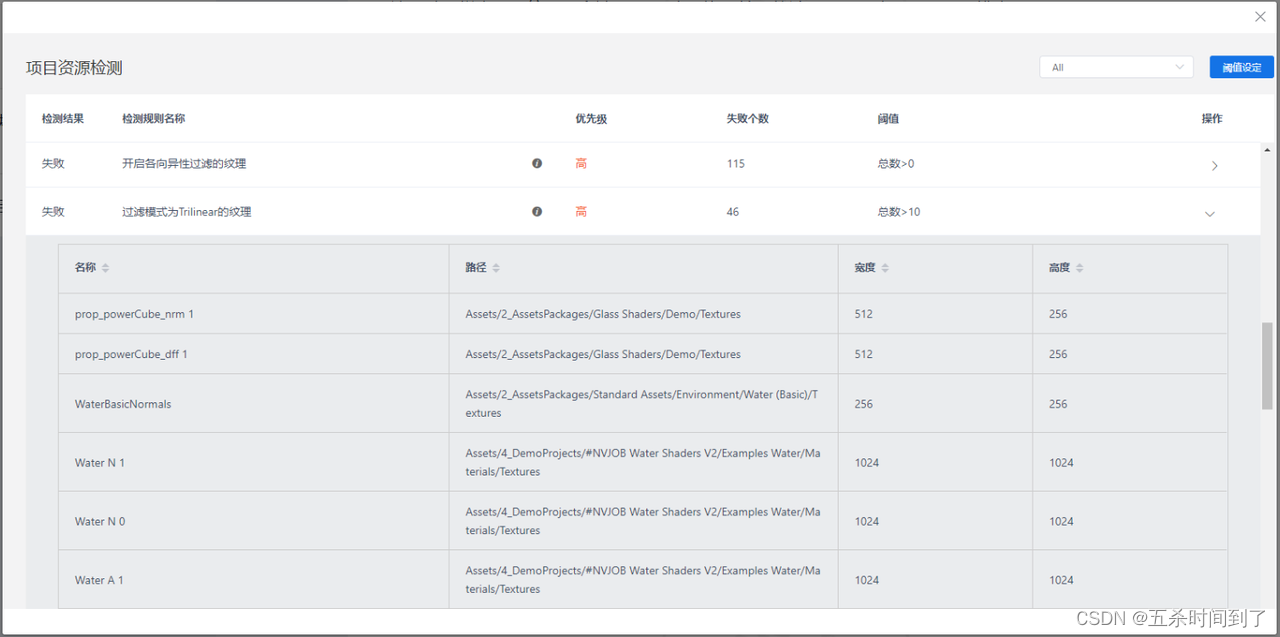
UWA的本地资源检测报告。
1.2.6 纹理图集
优点:
-
采用共同纹理图集的多个静态网格资源可以进行静态合批处理,减少DrawCall调用次数。
-
纹理图集可以减少碎纹理过多,因为他们打包在一个图集里,通过压缩可以更有效的利用压缩,降低纹理的内存成本和冗余数据。
缺点:
-
美术需要合理规划模型,并且要求模型有相同的材质着色器,或需要制作通道图去区分不同材质。制作和修改成本较高。
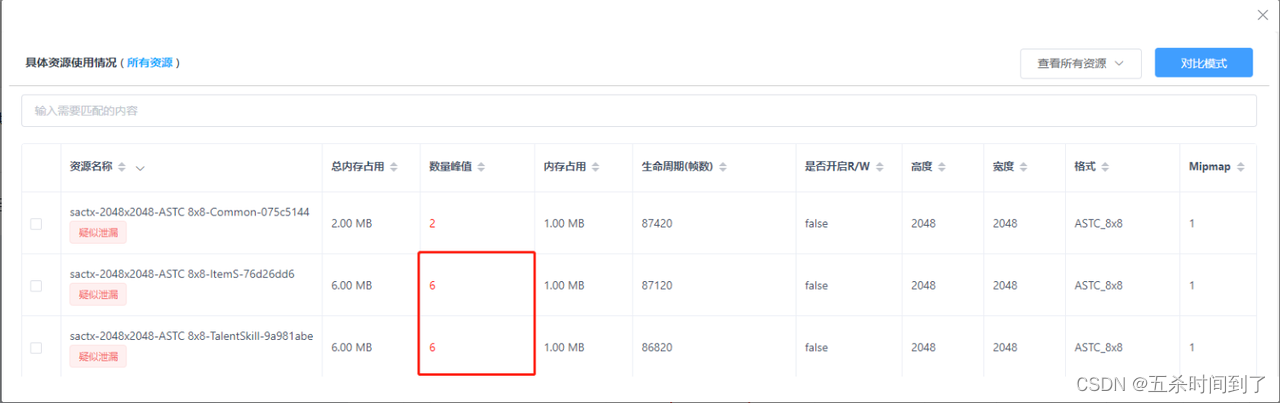
资源列表中有时会出现数量峰值较高的图集纹理,但不一定是冗余。
图集造成内存冗余的原因:
-
大量小图被打包到同一图集中,导致该图集纹理资源设置的最大分辨率(比如2048*2048)装不下这么多小图,该资源就会生成更多的纹理分页来打包这些小图。
-
只要游戏过程中依赖某一张纹理分页中的某一张小图,就会将该资源、也即该资源下所有的分页都全部加载进内存中,一般建议控制到2-3张分页以内较为合理.
-
纹理图集大小设置不合理,图集利用率低
即便不出现上述这个较为极端的现象,很多项目中也会出现“牵一发而动全身”的现象。
为此,在制作打包图集时,严格按照小图的使用场景、分类进行打包是非常重要的策略,选用合适的分辨率从而避免纹理没有被填充满而导致浪费。
1.2.7 使用TextMeshPro情况
TextMeshPro能为U组件提供更好的表现和便利的功能,使得其受到不少开发者的青睐。但使用TMP而产生的TMP字体图集纹理(名称中带有SDF Atlas,格式为Alpha 8的纹理)也有一些坑值得注意。
(1)有时,结合字体资源列表注意到内存中还存在TMP图集纹理对应的.ttf字体文件。说明该TMP字体图集为动态字体。可以考虑在项目开发结束、确保游戏要用到的字符都已添加到动态字体的Altas纹理中后,将动态TMP重新设置为静态TMP,并且解除对.ttf文件的依赖。这样一来,对应的字体资源将不会出现在内存中。不过,如果这种字体还被用作用户输入,则不建议采用此方法。
(2)Atlas字体纹理的分辨率较大。此时建议在引擎中排查字符有没有填满图集纹理,纹理的制作生成是否合理。对于动态TMP,如果没有填满,如只占据了纹理的3/4不到,则可以考虑开启Multi Atlas Textures选项,并设置纹理大小,举例而言就可以使1张4096*4096的纹理变为3张2048*2048的纹理,节省32MB-3*8MB=8MB的空间。
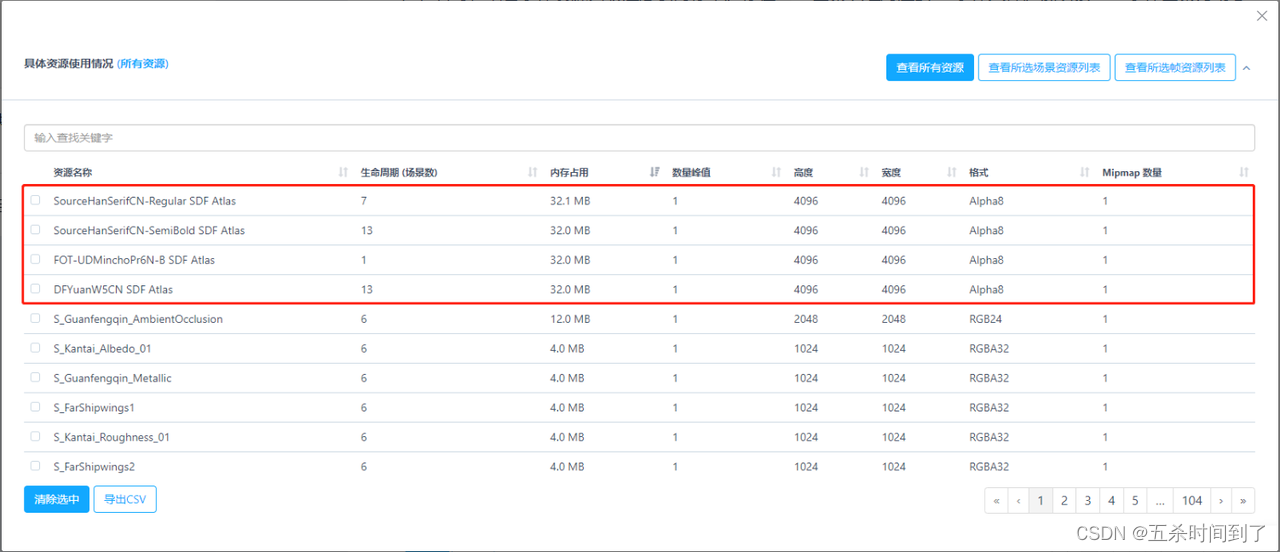
(3)资源列表中有TMP相关的资源(LiberationSans SDF Atlas、EmojiOne),它们都是TMP的默认设置,可以在Project Settings-TextMesh Pro Settings中解除对这些默认资源的依赖,就不会出现在内存中了。由于Multi Atlas Textures是动态TMP的选项,所以(1)、(2)无法同时使用,可以根据项目实情酌情选用。
1.2.8 使用 2 的幂 (POT)
Unity 要求移动端纹理压缩格式(PVRCT 或 ETC)采用 POT 纹理尺寸。
ETC2格式需要对应的纹理分辨率为4的倍数,在对应的纹理开启了Mipmap时更是严格要求其分辨率为2的次幂。否则,该纹理将被解析成未压缩格式。
1.2.9 纹理颜色空间
默认大多数图像处理工具都会使用sRGB颜色空间处理和导出纹理。但如果你的纹理不是用作颜色信息的话,那就不要使用sRGB空间,如金属度贴图、粗糙度贴图、高度图或者法线贴图等。一旦这些纹理使用sRGB空间会造成视觉表现错误。
1.2.10 其他可能有问题的纹理类型
-
大量只有颜色差异的图片
-
UI背景贴图而不采用9宫格缩放的图
-
纯色图没有使用Single Channel
-
不合理的半透明UI,占据大量屏幕区域,造成Overdraw开销
-
大量2D序列帧动画,而且图片大,还不打图集
-
不合理的通道图利用方案
-
大量渐变色贴图,没有采用1像素过渡图,也不采用Single Channel, 粒子特效中较为常见。
1.3 网格资源
1.3.1 顶点和面片数
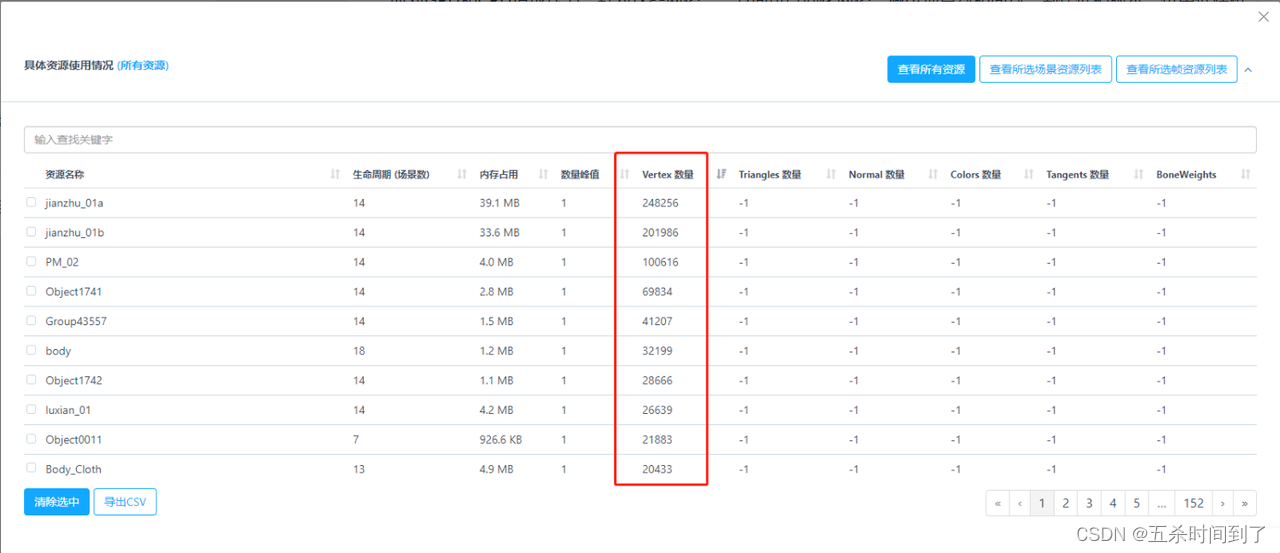
顶点和三角形面片数过多的网格资源不仅会造成较高的内存占用,同时也不利于裁剪,容易增加渲染面数,在渲染时对GPU和CPU造成压力。针对这些网格,一方面可以简化网格,减少顶点数和面数,制作低模版本,供中低端机型分级使用;
而另一方面针对单个顶点数过高的静态网格,比如一些复杂的地形和建筑,可以考虑拆分成若干个重复的小网格重新拼接。只要做好合批操作,就能以付出一点Culing计算耗时为代价,减少同屏渲染面片数。
1.3.2 顶点属性
如果没有统一美术资源标准且在导入时没有进行处理,则项目中的网格很有可能包含大量“多余”的顶点数据。这里的“多余”数据是指网格数据中包含了渲染时Shader中所不需要的数据。举例而言,如果网格数据中含有Position、UV、Normal、Color、Tangent等顶点数据,但其渲染所用的Shader中仅需要Position、UV和Normal,则网格数据中的Color和Tangent则为“多余”数据,从而造成不必要的内存浪费。其中,一个小网格资源带有顶点属性,会使所在的Combined Mesh也带有顶点属性,需要予以注意。
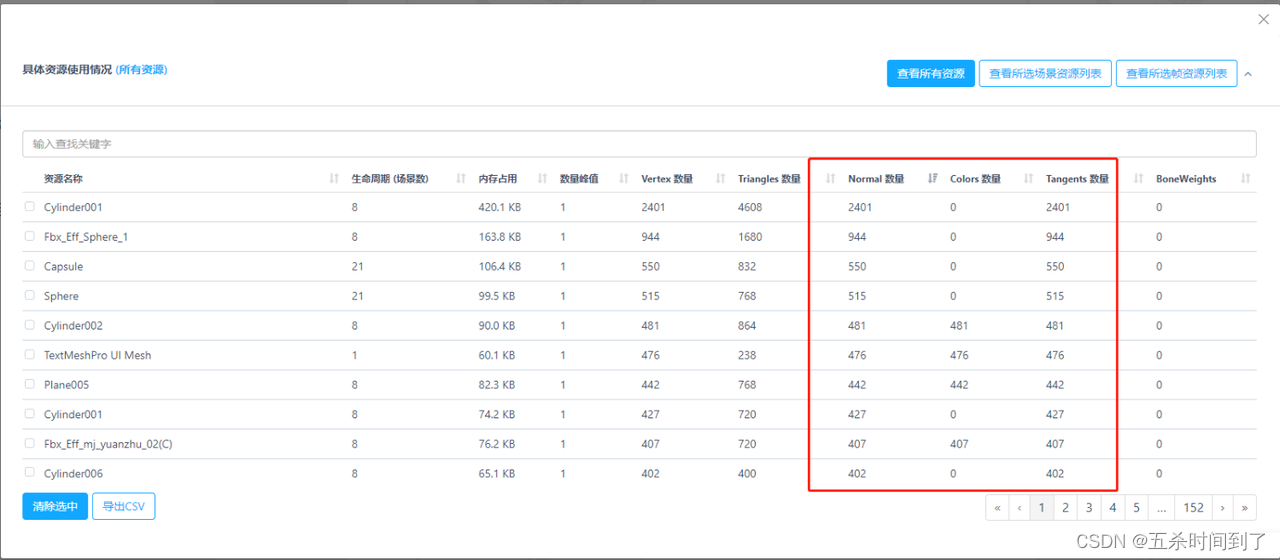
针对这个问题,一个比较简单的方法是,尝试开启“Optimize Mesh Data”选项。该选项位于Player Setting的Other Settings中。勾选后,引擎会在发布时遍历所有的网格数据,将其“多余”数据进行去除,从而降低其数据量大小。但是,需要注意的是,对于在Runtime情况下有修改Material需求的网格,建议研发团队对其进行额外的注意。如果Runtime时需要为某一个GameObject修改更为复杂、需要访问更多顶点属性的Material,则建议先将这些Material挂载在相应的Prefab上再进行发布,以免引擎去除Runtime中会进行使用的网格数据。a
1.3.3 禁用Read/Write Enabled
如果启用此选项,内存中会有重复网格,网格的一个副本在系统内存中,另一个在 GPU 内存中。
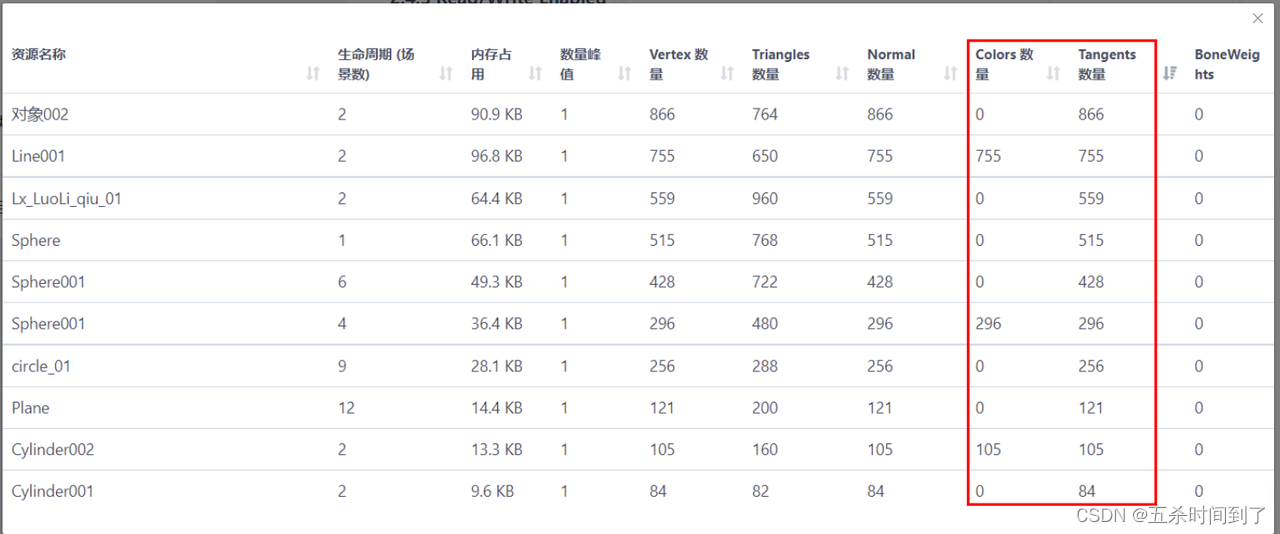
在资源列表中,常常统计到大量顶点属性不显示为-1(或“-”)的网格资源。只有网格资源开启Read/rite时UWA报告才能采集到顶点属性信息。此时,顶点属性不显示为-1,且会使得网格占用内存上升。
一般而言,不需要在CPU端进行修改的网格是不需要开启Read/rite的。可以在编辑器中通过API修改这些网格的Read/Write属性,或者对于FBX中的网格可以直接在Inspector窗口中修改。
大多数情况下,应将其禁用(在 Unity 2019.2 以及更早版本中,此选项默认为选中状态)。
1.3.4 压缩网格
高性能压缩可以减少占用磁盘空间(但不会影响运行时的内存)。请注意,网格量化可能造成不准确,因此应试验不同的压缩级别,从而找到适合模型的压缩级别。
1.3.5 模型导出规范
-
统一计量单位(位置, 旋转, 缩放)
-
导出的网格必须是多边形拓扑网格,不能是贝塞尔曲线、样条曲线、NURBS、NURMS、细分曲面等
-
不建议模型使用到的纹理随模型导出
-
如果你需要导入blend shape normals,必须要指定光滑组smooth groups
-
DCC导出面板设置, 不建议携带场景信息导出,如不建议导出摄像机、灯光、材质等信息,因为这些的信息与Unity内默认都不同。除非你自己为某DCC做过自定义导出插件。
-
Unity 支持多种标准和专有模型文件格式(DCC)。Unity 内部使用 .fbx 文件格式作为其导入链。最佳做法尽可能使用 .fbx 文件格式,并且不应在生产中使用专有文件格式。
1.3.6 原始模型文件对性能的影响点
-
最小化面数,不要使用微三角形,分布尽量均匀
-
合理的网络拓扑和平滑组
-
尽量少的使用材质个数
-
尽可能少的使用蒙皮网格
-
尽可能少的骨骼数量
-
FK与IK节点没分离,IK节点没删除
1.3.7 模型优化选项
-
尽可能的将网格合并到一起,
-
尽可能使用共享材质
-
不要使用网格碰撞体
-
不必要不要开启网格读写
-
使用合理的LOD级别
-
Skin Weights受骨骼影响个过多
-
合理压缩网格
-
不需要rigs和BlendShapes尽量关闭
-
如果可能,禁用法线或切线
-
如果可能,禁用网格的骨骼
1.4 动画资源
动画文件导入设置优化原则
-
效果差异(与原始制作动画差异是否明显)
-
曲线数量(总曲线数量与各种曲线数显,常量曲线比重大更好)
-
动画文件大小(内存占用大于200KB,且时长较短的动画资源就可以被认为是内存占用偏大的动画资源)
1.4.1 Animation Type
参数介绍:
-
None 无动画
-
Legacy 旧版动画,尽量不要用, 性能差
-
Generic 通用骨骼框架
-
Humanoid 人形骨骼框架
选择原则:
-
无动画选择None
-
非人形动画选择Generic
-
人形动画
-
人形动画需要Kinematices或Animation Retargeting功能,或者没有有自定义骨骼对象时选择Humanoid
-
-
其他都选择Generic,在骨骼数差不多的情况下,Generic会比Humanoid省30%甚至更多的CPU的时间。
1.4.2 Anim.Compression(推荐Optimal)
-
Off 不压缩,质量最高,内存消耗最大
-
Keyframe Reduction 减少冗余关键帧,减小动画文件大小和内存大小。
-
Keyframe Reduction and Compression 减小关键帧的同时对关键帧存储数据进行压缩,只影响文件大小。
-
Optimal,仅适用于Generic与Humanoide动画类型,让Unity在数个算法中自动选择
1.4.3 关闭Resample Curves选项
将动画曲线重新采样为四元数数值,并为动画每帧生成一个新的四元数关键帧,仅当导入动画文件包含尤拉曲线时才会显示此选项
官方文档中称开启该选项会有一定的性能提升,但事实上根据《自动化规范Unity资源的实践》中的说法,上文提到的开启Resample Curves的性能提升体现在播放时而非加载时、且效果微乎其微;
反倒是还可能造成错误的动画表现。所以结合实验数据,大部分情况下,这个选项是建议关闭的。
1.4.4 Skin Weights
默认4根骨头,但对于一些不重要的动画对象可以减少到1根,节省计算量
1.4.5 Optimize Bones
建议开启,在导入时自动剔除没有蒙皮顶点的骨骼
1.4.6 Optimize Game Objects
-
在Avatar和Animatior组件中删除导入游戏角色对象的变换层级结构,而使用Unity动画内部结构骨骼,消减骨骼transform带来的性能开销。可以提高角色动画性能, 但有些情况下会造成角色动画错误,这个选项可以尝试开启但要看表现效果而定。
-
注意如果你的角色是可以换装的,在导入时不要开启此选项,但在换装后在运行时在代码中通过调用AnimatorUtility.OptimizeTransformHierarchy接口仍然可以达到此选项效果。
1.4.7 考虑使用API剔除动画资源的Scale曲线和压缩动画的精度
其中,压缩动画精度的做法可以参考《Unity动画文件优化探究》。
1.5 音频资源
对于时长较长的BGM和一些常规的时长较短但内存大的音频资源,有一定的优化空间。
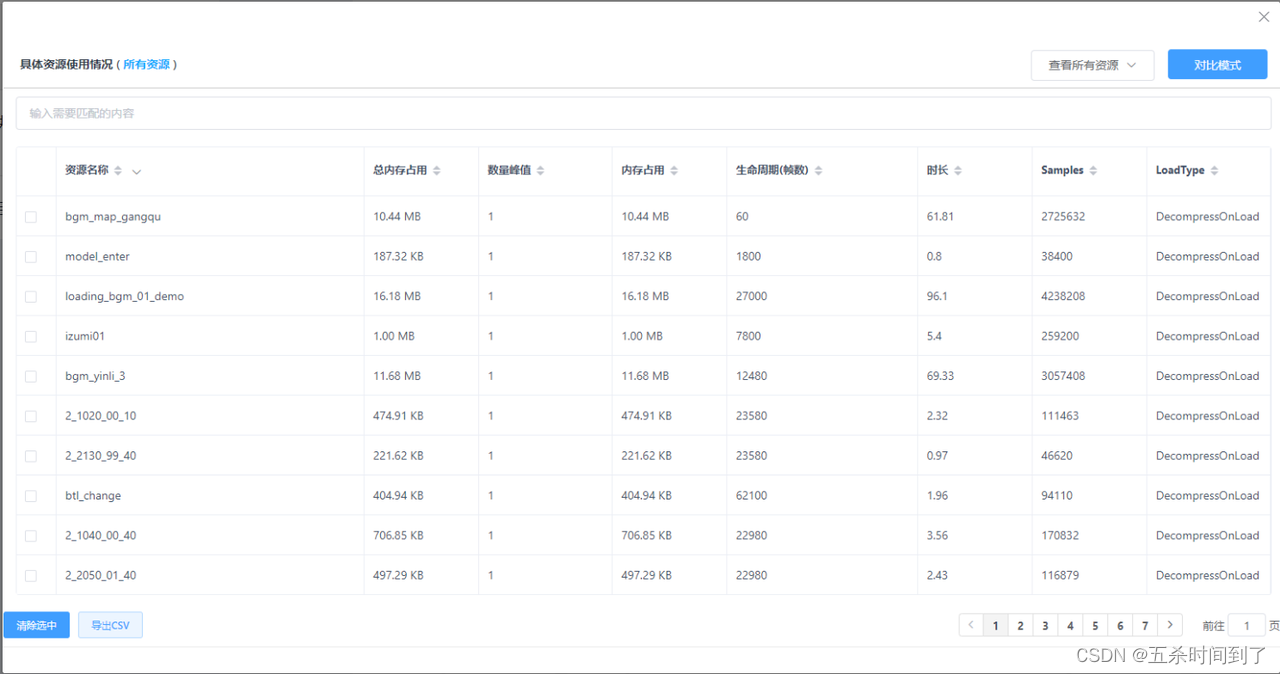
在本地资源检测中包含了“双声道的音频”、“未使用Streaming加载的长音频”、“该音频中使用了Quality过高的Vorbis与MP3压缩”等上文已经提及的检测规则,方便开发者精确定位存在潜在性能问题的音频资源。
以下方法都可以有效减少音频资源内存(其中Streaming可以稳定降至200KB左右),但会造成一定的耗时代价或音质降低,可以酌情选用。
1.5.1 尽量使用单声道声音剪辑
如果要使用 3D 空间音频, 请以单声道 (single channel) 的形式创作声音剪辑,或者启用 Force To Mono 设置。
在运行时定位使用的多声道声音会扁平化为单声道源,因此会增加 CPU 开销和浪费内存。
1.5.2 修改其加载方式(Load Type)
每个剪辑大小的设置都不同。
-
小剪辑 (< 200 kb) 应采用 Decompress on Load。将声音解压缩为原始 16 位 PCM 音频数据,会导致 CPU 开销和内存占用,因此,这仅适用于短声音。
-
中等剪辑 (>= 200 kb) 应保持为 Compressed in Memory。
-
大文件(背景音乐)应设置为 Streaming。虽然会有CPU额外开销,但节省内存并且加载不卡顿。
1.5.3 修改其压缩格式(Compression Format)
对于Compressed In Memory的音频,修改其压缩格式(Compression Format)为压缩率更大的格式;
通过压缩减小剪辑的大小和内存使用量 :
-
对大多数声音使用 Vorbis(或者对不循环的声音使用 MP3)。
-
对常用的短声音使用 ADPCM(如脚步声、枪声)。相比于未压缩的 PCM,这样可以减小文件大小,在播放时又可以很快解码。
移动设备上的音效最高为 22,050 Hz。使用较低设置通常对最终质量影响很小,当然,请使用您自己的耳朵来判断。
1.5.4 调低Quality参数
对于Vorbis、MP3压缩格式的音频,还可以继续调低其Quality参数,进一步压缩其内存。
1.5.5 尽可能使用原始未压缩WAV 文件作为源资源
如果使用任何压缩格式(如 MP3 或 Vorbis),Unity 会将其解压并在构建时重新压缩。这样会导致两个有损通道,从而降低最终质量。
1.5.6 从内存中卸载静音的音频源 (AudioSources)
实现静音按钮时,不要只是将音量设置为 0。可以销毁 AudioSource 组件,从而将其从内存中卸载,这样,播放器不需要过于频繁地切换开关。
1.6 材质资源
材质资源本身内存占用较小,我们一般更加关注如何优化其数量,因为它的数量过多会影响之后会提到的Resource.UnloadUnusedAssets APl的耗时。
材质资源数量过多,往往主要是因为Instance类型的冗余Material资源过多。一般来说,该种情况的出现是因为通过代码访问并修改了meshrender.material的参数,因此Unity引|擎会实例一份新的Material来达到效果,进而造成内存上的冗余。对此,建议通过MaterialPropertyBlock的方式来进行优化,具体相关操作和例子见如下文章《使用MaterialPropertyBlock来替换Material属性操作》。不过这种方法在URP下不适用,会打断SRP Batcher。除此之外,则需要关注和优化非Instance的材质资源的疑似冗余现象, 不再嶅述。
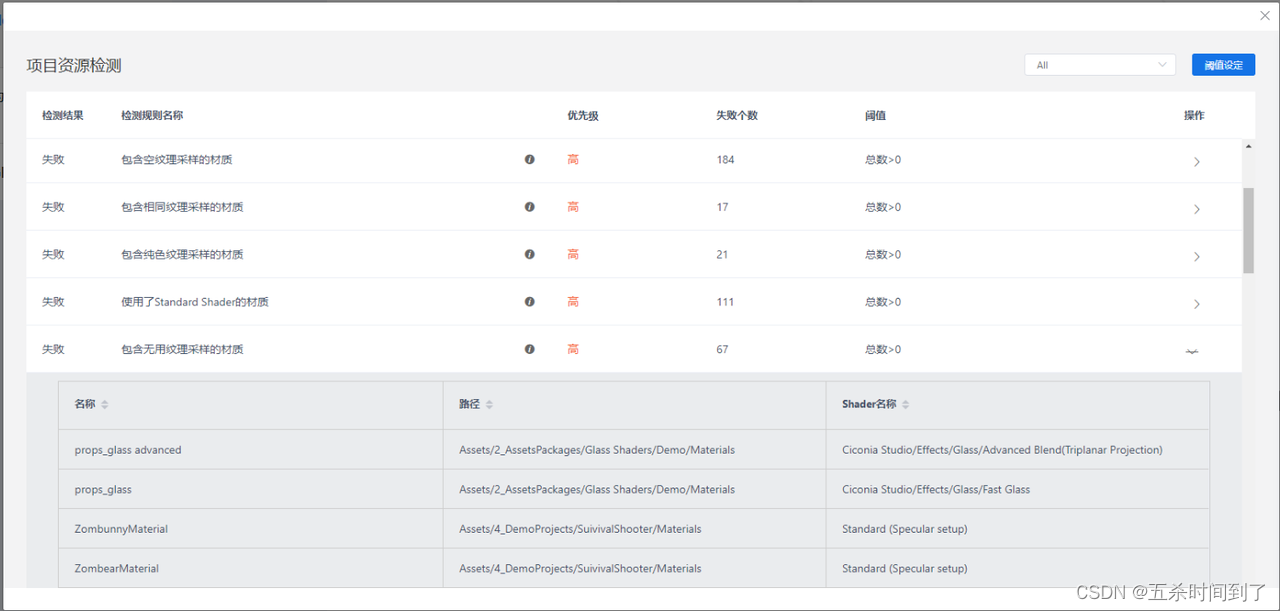
除了数量上的问题外,材质资源往往还涉及到一些纹理采样和Shader使用相关的问题,导致一些额外的内存和GPU性能浪费,而其中比较值得关注的也已经作为检测规则统计在UWA本地资源检测报告中。
对于使用纯色纹理采样的材质,可以将纹理采样替换为一个颜色参数,从而节省一张纹理采样的开销;而对于空纹理采样的材质Unitv会采样内置提供的纹理,但是计算得到的颜色是一个常数,仍然属于浪费;又对于包含无用纹理采样的材质,由于Unitv的机,制,材质球会自动保存其上的纹理采样,即使更换Shader也不会把原来依赖的纹理去除,所以可能会造成误依赖实际不需要的纹理带进包体的情况,从而造成内存的浪费
1.7 Render Texture
1.7.1 渲染分辨率
资源列表中的一些RT资源能反映项目当前的渲染分辨率。对于GPU和渲染模块压力较大的项目,在中低端机型上降低其渲染分辨率是非常直观有效的分级策略。一般低端机型上可以考虑不采用真机分辨率,降到0.8-0.9倍,甚至很多团队会选择0.7倍或720P。
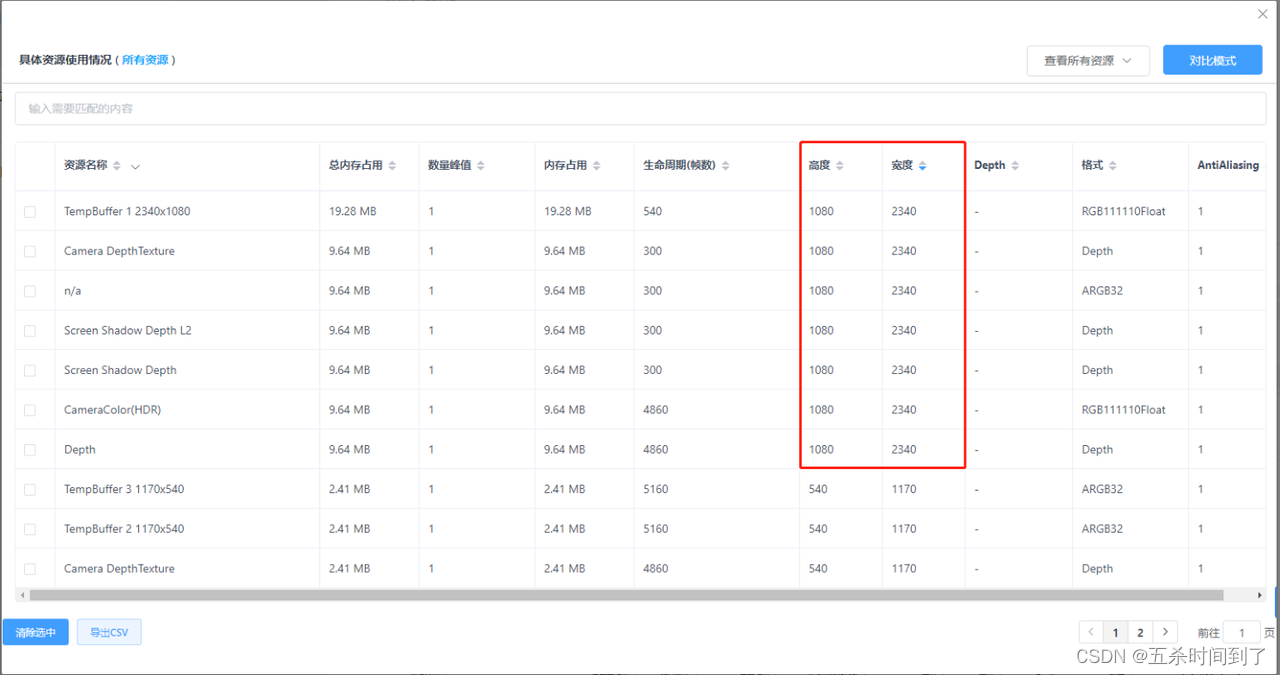
如果一些其他的RT资源分辨率过高也应引起注意,尤其是2048*2048以上的资源。应当排查是否有必要用到如此精细的RT,在低端机上考虑采用更低分辨率的效果。
1.7.2 抗锯齿
资源列表中展示了RT资源的AA倍数。开启多倍AA会使RT占用内存成倍上升,并对GPU造成压力。建议排查是否有必要开启AA,尤其在中低端机上,可以考虑关闭此效果。
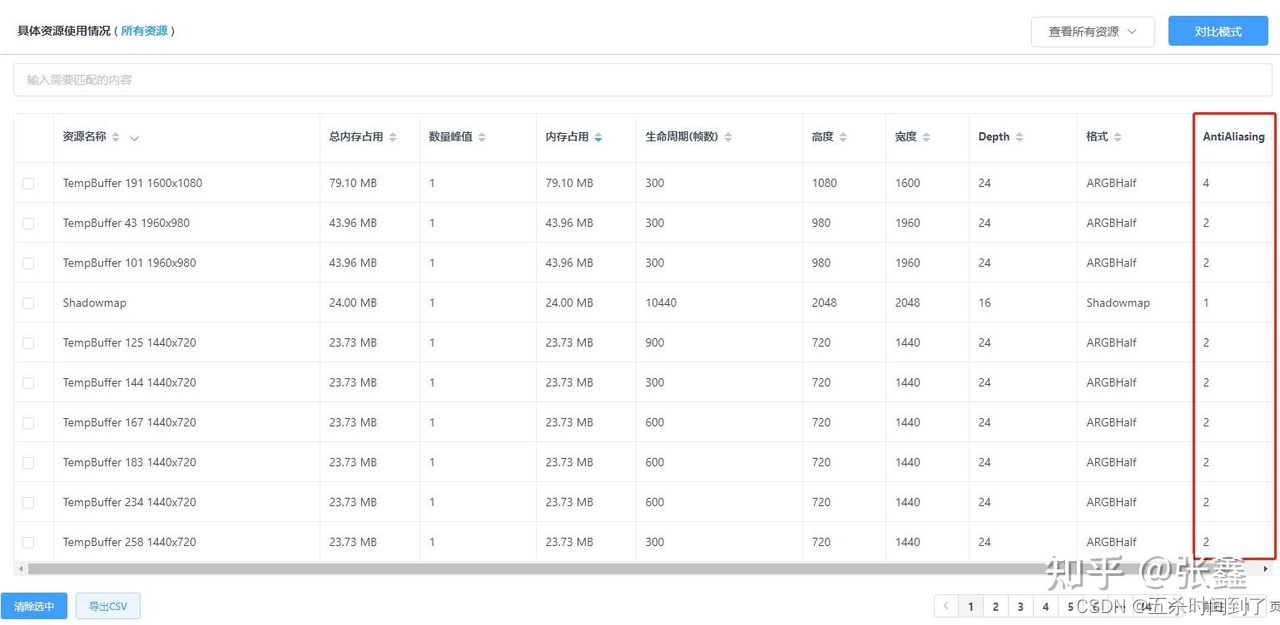
特别的是,在华为部分机型上2倍的AA会失效。即已经造成了性能消耗但没有实际起到抗锯齿效果。
1.7.3 后处理
一些常见的后处理相关的RT(如Bloom、Blur)是从1/2渲染分辨率开始采样,可以考虑改从1/4开始采样、并减少下采样次数,从而节省内存并降低后处理对渲染的压力。
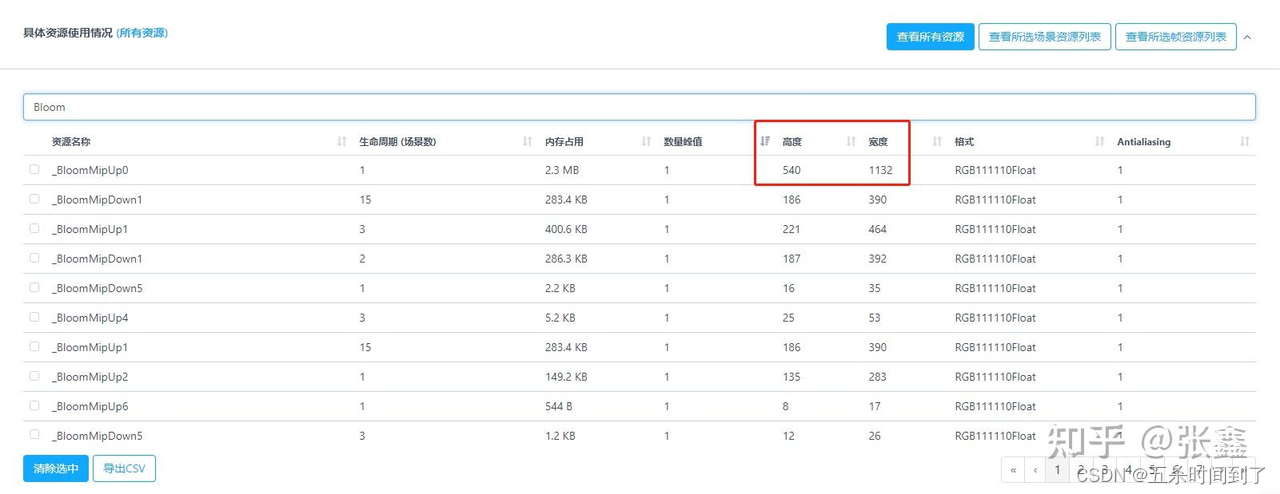
站在性能优化的角度,在中低端机型上甚至最好完全关闭各类后处理。围绕一些常见后处理效果的讨论会在下文GPU部分中进一步展开。
1.7.4 URP下的RT
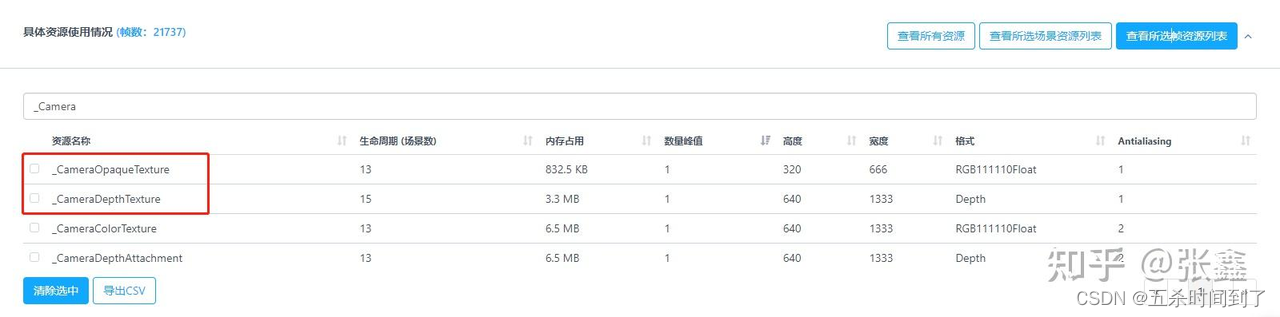
使用URP时,内存中会多出_CameraColorTexture和_CameraDepthAttachment两份RT资源作为渲染目标,而开启URP相机的CopyDepth和CopyColor设置时会额外产生_CameraDepthTexture和_CameraOpaqueTexture作为中间RT。当资源列表中出现这两种RT时,需要排查确实是否用到CopyDepth和CopyColor,否则应予以关闭以避免不必要的浪费。
1.8 Shader资源
1.8.1 ShaderLab
Unity 2019.4.20是Shader内存统计方法的一个转折点。在此之前,Shader的内存主要统计在ShaderLab中,而之后则主要统计在Shader资源自身身上。
对于Unity 2019.4.20之前的版本的项目,查看ShaderLab的内存需要在Unity Profiler中TakeSample。无论是Shader资源本体还是ShaderLab内存占用过高,都要着手于控制Shader的数量和变体数量。
1.8.2 变体数
变体数过多是造成一个Shader资源内存占用过大、占用包体过大的主要原因。在项目迭代中可能会出现已经被弃用或者没有被实际使用到的关键字,导致变体成倍上升;又或者Shader写的比较复杂,其中一些关键字组合永远不会被用到,从而导致很多变体是多余的。UWA的本地资源检测中提供了Shader检测功能,可以看到变体数量,定位变体数过多的Shader资源。
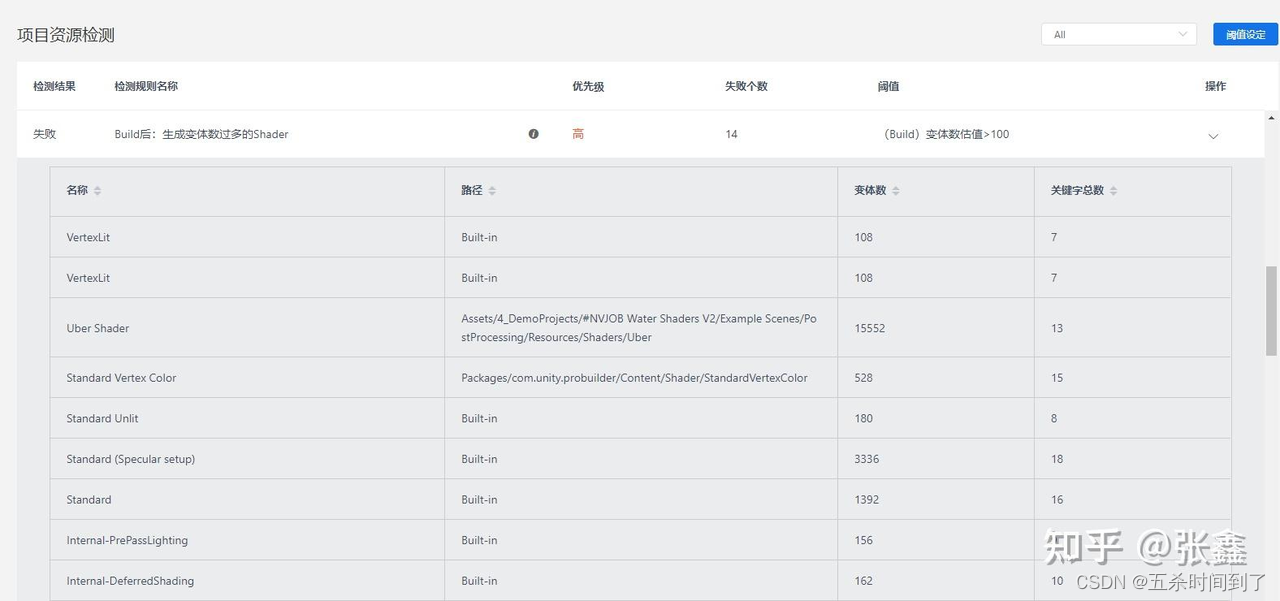
针对上述情况,Unity提供了回调函数,在项目打AssetBundle包或者Build时线剔除用不到的关键字或关键字组合相关的变体。剔除Shader变体的方法可以参考《Stripping scriptable shader variants》。
1.8.3 冗余
Shader冗余尤其需要予以关注,Shader的冗余不光导致内存上升,还可能造成重复解析,即运行时不必要的Shader.Parse和Shader.CreateGPUProgram API调用耗时。
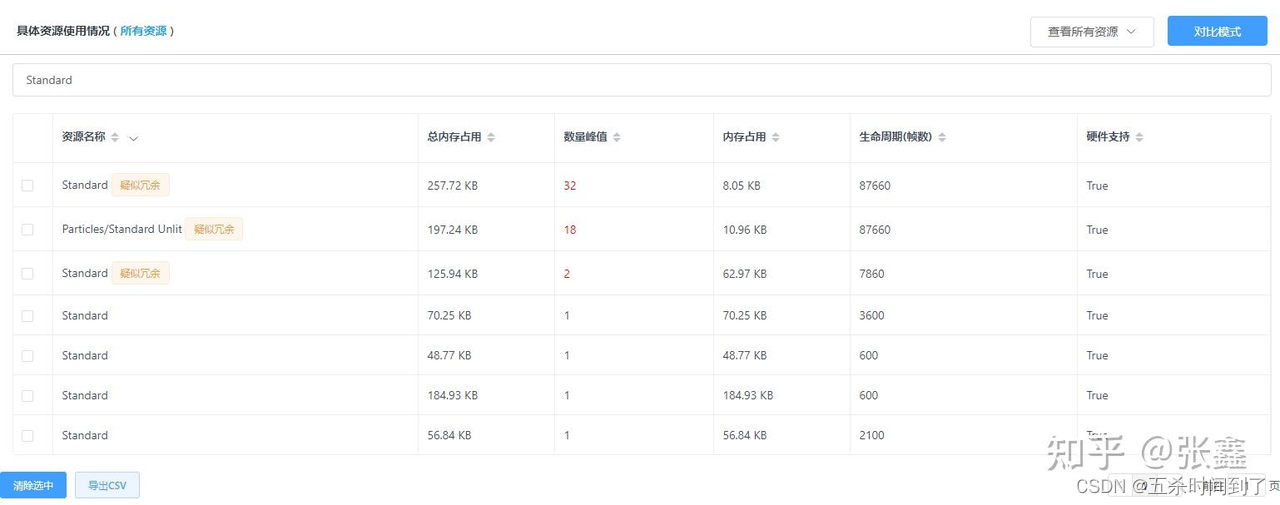
1.8.4 Standard Shader
在资源列表中发现Standard、ParticleSystem/Standard Unlit。这两种Shader变体数量多,其加载耗时会非常高,内存占用也偏大,不建议直接在项目中使用。出现的原因一般是导入的FBX模型中或者Unity自身生成的一些3D对象使用了自带的Default Material,从而依赖了Standard Shader,建议予以排查精简。也可以结合UWA在线AssetBundle检测工具排查是哪个AssetBundle包中哪些资源引用了Standard Shader和ParticleSystem/Standard Unlit。如果确实要使用Standard Shader或ParticleSystem/Standard Unlit,应考虑自己重写一个Shader并只包含自己需要用到的变体。
1.9 字体资源
若单个字体资源内存占用超过10MB,可以认为该字体资源内存偏大。可以考虑使用FontPruner 字体精简工具或其他字体精简工具,对字体进行瘦身,减小内存占用。
我们也需要关注项目中字体数量过多的情况,因为每个Font会对应一个Font Texture字体纹理,所以字体资源数量多了,Font Texture的数量也多了,从而占用较多内存。
1.10 场景资源
-
较少的层级关系将受益于多线程刷新场景中的Transform, 而复杂层级关系会发生不必要的Transform计算以及更多垃圾收集开销。请参阅优化层级关系和此 Unite 报告了解Transform的最佳实践。
-
一些代码生成的游戏对象如果不需要随父节点进行Transform的,一律放到根节点下。
-
尽量使用Prefab节点构建场景,而不是直接创建的GameObject节点
-
避免DontDestroyOnLoad节点下有太多生命周期过长或引用资源过多的复杂节点对象。Additve模式添加的场景要尤为注意。
-
最好为一些需要经常访问的节点添加tag,静态节点一定要添加Static标记。
-
注意:复杂场景中,对于设置好Tag的节点,使用FindGameObjectWithTag方法取查找该节点更高效。
1.11 粒子系统
将资源列表结合粒子系统曲线来看,很多项目的内存中粒子的数量会远远高于实际Playing的粒子数量。
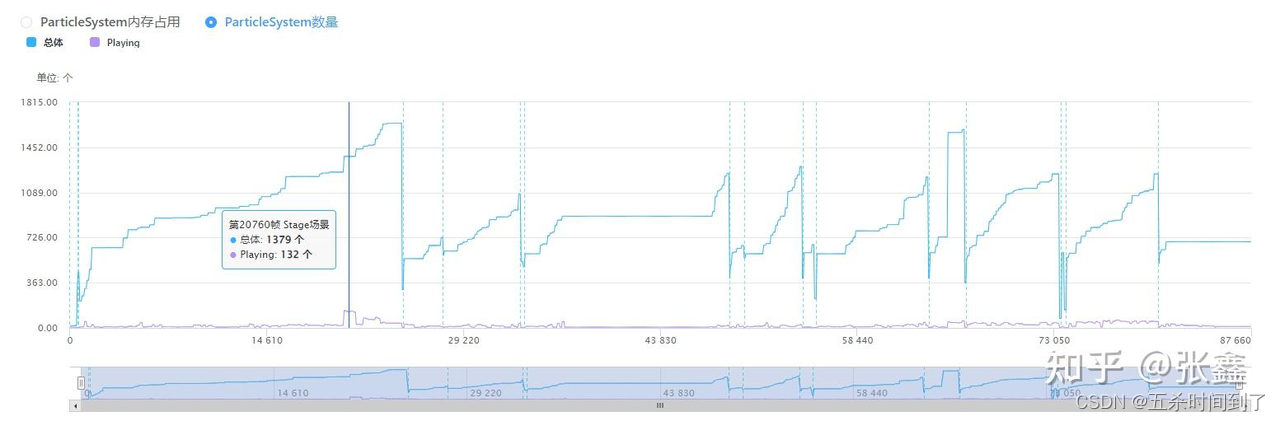
此时一方面需要检查是否是在迭代过程中有被弃用但未删除的粒子资源或制作过程中测试过的组件但未解除依赖;另一方面则可以考虑优化对粒子的缓存策略,减少不必要的粒子缓存。
2 Mono堆内存
Unity 为用户生成的代码和脚本采用了自动内存管理。小块数据(如值类型的局部变量)分配在栈上。大块数据和长期存储分配在托管堆上。
垃圾收集器 (GC) 会定期识别并释放未使用的堆内存。虽然这是自动运行的,但检查堆中所有对象的过程可能导致游戏卡顿或运行缓慢。
优化内存使用量意味着注意何时分配和解除分配堆内存,并尽可能减小垃圾收集的影响。
有关更多信息,请参阅了解托管堆。
2.1 UWA 持续/峰值分配堆栈
在UWA GOT Online Mono模式报告, 堆内存具体分配页面中,可以排查高堆内存分配函数的具体堆栈。我们主要关注两种形式的堆内存分配。

一种是单次过高的堆内存分配。这种峰值一般出现在游戏初期的读表操作导致的大量分配,需要开发者结合具体堆栈信息排查是否合理。而游戏运行过程如果还出现堆内存分配峰值则需要着重关注。
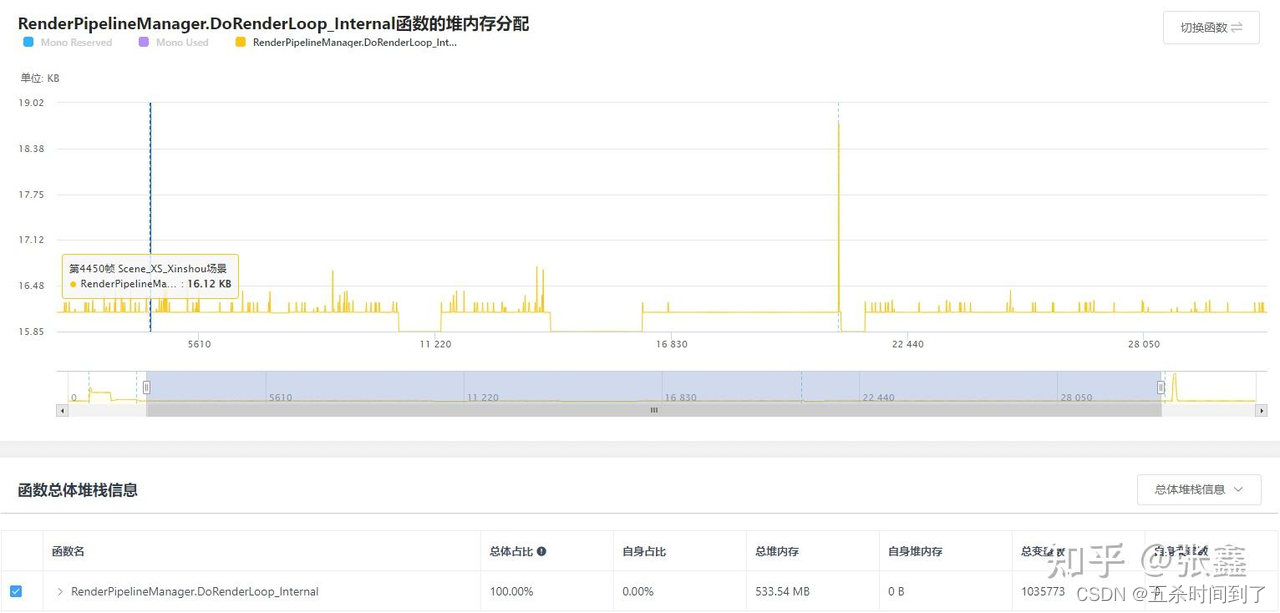
另一种则是持续偏高的堆内存分配。如果项目中存在每帧或者每隔几帧就分配较多堆内存的现象需要引起注意。持续的高堆内存分配会导致GC频率增高,从而在游戏中形成频繁的卡顿,可以结合堆栈排查是什么子节点在持续分配堆内存。
2.2 UWA 内存泄露分析
在UWA GOT Online Mono模式的泄露分析页面中排查项目中各个函数的堆内存驻留情况。选中图表中前后两处采样帧进行比较,就可以从堆栈中查看堆内存驻留情况的变化,查看驻留上升主要是什么堆栈分配造成的。
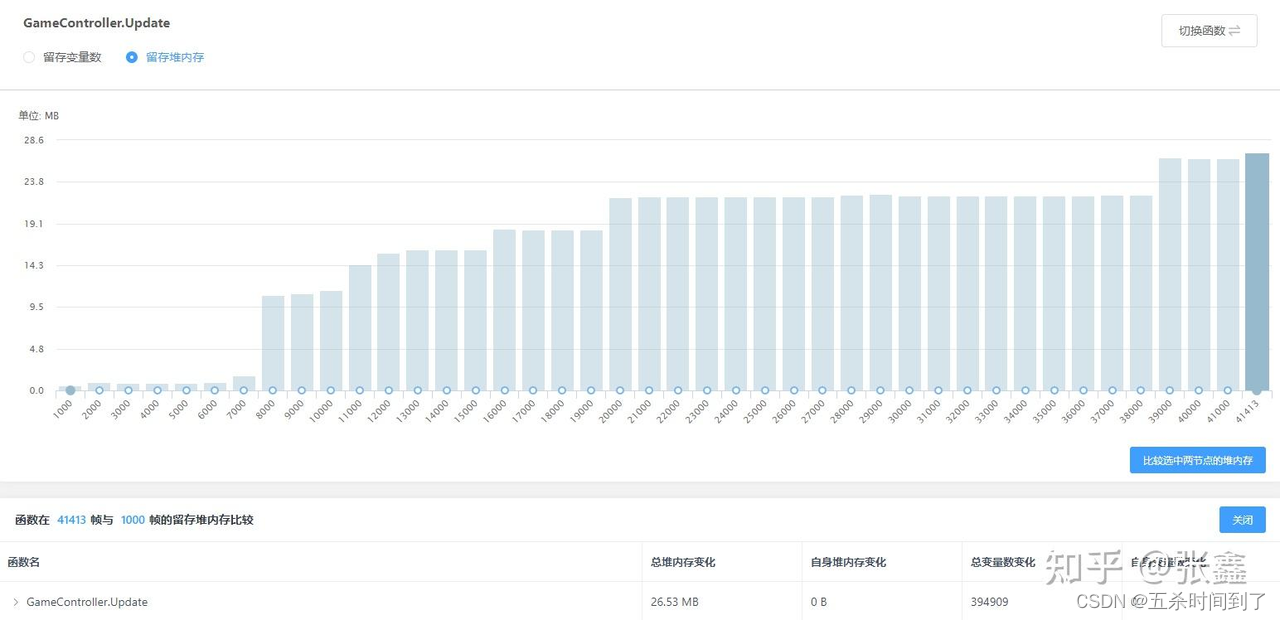
一方面可以避免堆内存持续上升造成泄露的风险,另一方面针对驻留高的函数进行优化,予以及时释放,可以降低单次GC的耗时。我们一般推荐测试GOT Online Mono模式的测试时长尽量长一些,比如1个小时,否则泄露问题往往难以被暴露。
2.3 减少垃圾收集 (GC) 的影响
Unity 使用 Boehm-Demers-Weiser 垃圾收集器,它会停止运行程序代码,并且仅在其完成所有工作后才恢复正常执行。 要注意某些不必要的堆分配,这可能会导致 GC 尖峰 :
-
字符串 :在 C# 中,字符串是引用类型,而不是值类型。减少不必要的字符串创建或操作。避免解析基于字符串的数据文件,例如 JSON 和 XML ;改用 ScriptableObject 或 MessagePack、Protobuf 等格式存储数据。如果需要在运行时构建字符串,请使用 StringBuilder 类。
-
Unity 函数调用 :请注意,某些函数会创建堆分配。缓存数组引用,不要在循环中分配数组。此外,请使用某些避免产生垃圾的函数 ;例如,使用 GameObject.CompareTag 而不是手动将字符串与 GameObject.tag 进行比较 (返回新字符串会产生垃圾)。
-
装箱 :避免传递值类型变量来代替引用类型变量。这会创建临时对象,以及随之而来的潜在垃圾,例如,int i = 123; object o = i 会将值类型隐式转换为类型对象。
-
协程 :虽然 yield 不会产生垃圾,但创建新的 WaitForSeconds 对象会。缓存并重用 WaitForSeconds 对象,而不要在 yield 行中创建它。
-
LINQ 和正则表达式 :它们幕后都会进行装箱,从而产生垃圾。如果性能很重要,请避免使用 LINQ 和正则表达式。如有可能,定时收集垃圾 如果确定垃圾收集冻结不会影响游戏中的某个特定点,则可以使用 System.GC.Collect 触发垃圾收集。 有关在哪些地方可以通过这样做而受益的示例,请参阅了解自动内存管理。 使用增量式垃圾收集器拆分GC 工作负载 增量式垃圾收集使用多个短得多的程序执行中断,而不是单次长时间的中断,将工作负载分布到多个帧上。如果垃圾收集影响了性能,可以尝试启用该选项,看看它能否显著减少 GC 尖峰问题。使用 Profile Analyzer 验证对应用程序的改善。
2.4 如有可能,定时收集垃圾
如果确定垃圾收集冻结不会影响游戏中的某个特定点,则可以使用 System.GC.Collect 触发垃圾收集。
有关在哪些地方可以通过这样做而受益的示例,请参阅了解自动内存管理。
2.5 使用增量式垃圾收集器拆分GC 工作负载
增量式垃圾收集使用多个短得多的程序执行中断,而不是单次长时间的中断,将工作负载分布到多个帧上。如果垃圾收集影响了性能,可以尝试启用该选项,看看它能否显著减少 GC 尖峰问题。使用 Profile Analyzer 验证对应用程序的改善。
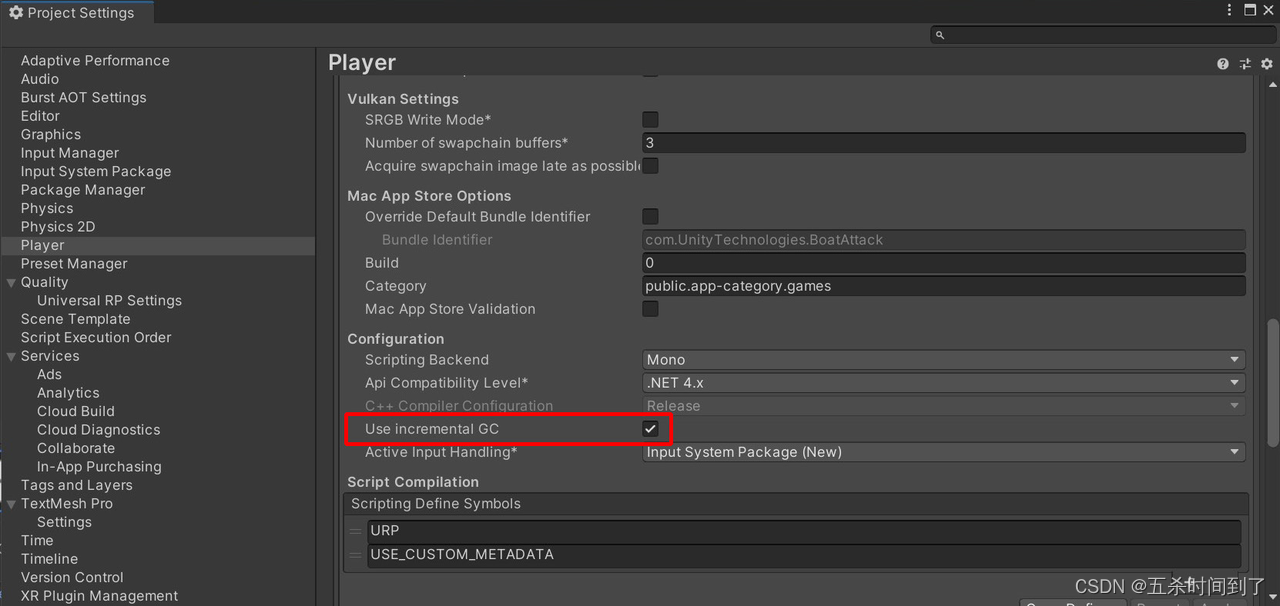
使用增量式垃圾收集器减少 GC 尖峰。
3 其他内存
3.1 Lua内存
UWA GOT Online Lua模式提供了针对Lua脚本语言的性能测试。
其中出现的函数名称格式为:函数名称@文件名:行号。
可以通过报告提供的Lua文件名/行号/函数名来定位CPU耗时的瓶颈函数和CPU耗时峰值的具体原因。Lua函数的命名格式为X@Y:Z,其中X是其函数名,在无法获取时,X会变为默认的unknown;Y是该函数定义的文件位置;Z则是该函数被定义的行号。需要注意的是,当Lua脚本以字节码运行时,该值将始终为0,因此建议在测试时尽可能使用Lua源码来运行。
针对Lua分配的内存,报告中的折线图选取了30帧内的数据最大值作为数据点。根据折线图走势,帮助开发者对项目运行过程中的堆内存分配情况有大致的了解。其中,堆内存的下降意味着发生了一次GC。查看内存具体分配和泄露分析和功能和Mono模式报告大同小异。
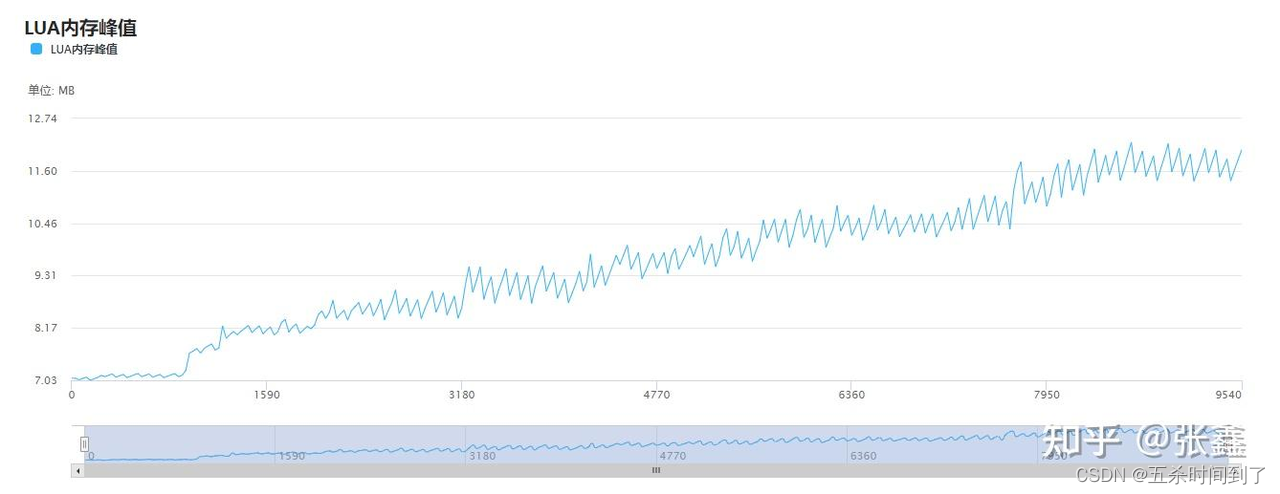
Lua模式报告中还有一个重要功能,即Mono对象引用统计。
从原理层面上,Unity Mono虚拟机中维护了一个对象池,用于链接Unity Object对象和Lua对象。当场景中的Unity Object对象被Destroyed之后,场景中没有了,但是由于Lua层还持有Usedata引用,导致对象池无法释放该Unity Object,如果该对象引用了Texture、Mesh等相关资源,会造成泄露。这时需要将Lua层的相关对象置空(nil),解除引用后,在下一次GC发生后,就可以回收该Unity Object对象。该功能的意义就在于辅助开发者排查此类泄露风险。
报告提供了Mono对象引用柱状图,其中黑色部分表示未被Destroyed的对象数目,由于受到Lua端GC的影响,导致会有一些Destroyed对象。这时候就要注意它是否是趋于稳定的,如果持续上涨就需要引起重视。
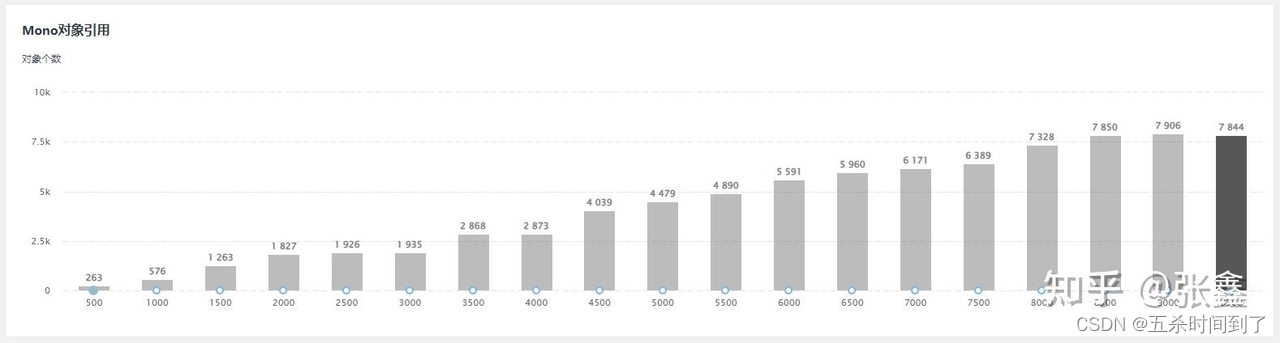
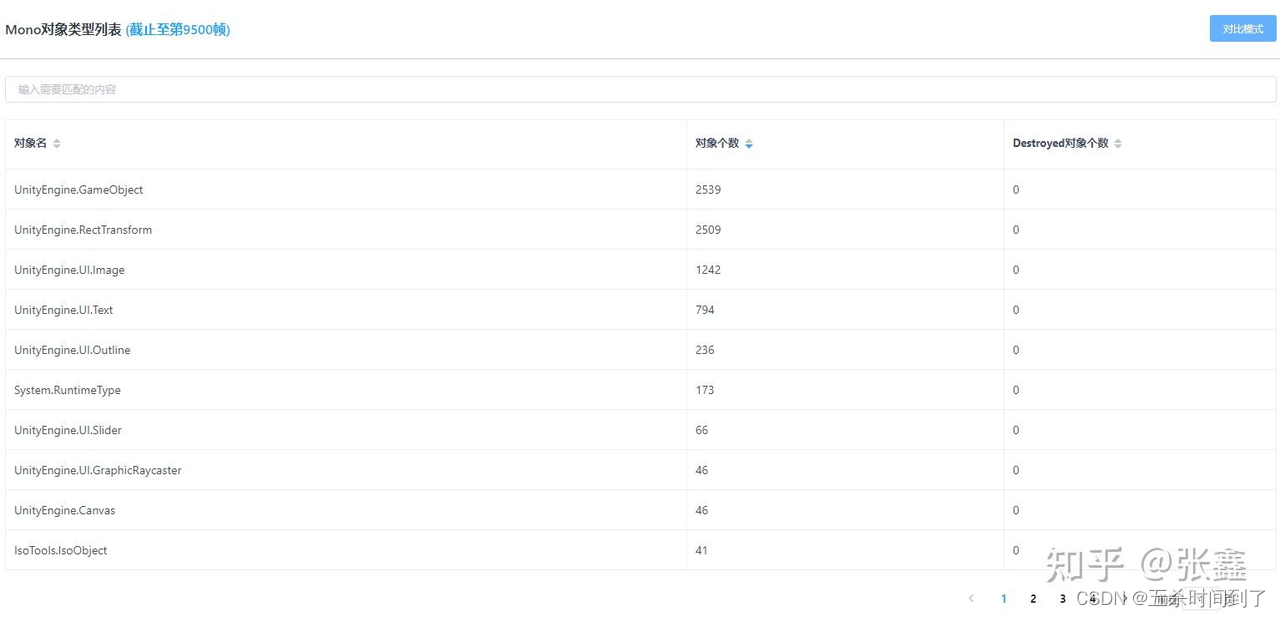
在柱状体选择对应帧后,列表中会显示该帧的Mono对象类型列表。其中:
对象类型:表示Unity Object对象的具体类型;
对象个数:表示这种类型的对象个数;
Destroyed对象个数:表示已经被Destroyed,但Lua层还有相关引用的这种类型的对象个数。需要关注Destroyed对象个数,如果数目较大,C#堆内存存在泄露风险。
3.2 插件和第三方库
Wwise等插件和第三方库的使用相当普遍,但一般无法在运行时定量直观地统计。不过一般它们占用的内存不大,只有在上文这些内存优化点都排查完毕后仍然发现PSS内存和Reserved Total的值之间有加大差距时,再结合插件或第三方库的文档或其开发者提供的方法进行针对性优化,甚至考虑采取性能更优的替代方案。
参考文献: