最近在学习 RL ,不得不先接触一下“ 马尔可夫决策过程 ”,这里找到了 David Silver 的课程: UCL Course on RL
(http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html),这里我将按课程 PPT 中的顺序讲述我的理解已经如何用代码实现相应的计算过程。
目录
二、马尔可夫报酬过程(Markov Reward Process)
三、马尔可夫决策过程(Markov Decision Process)
四、最优值函数(Optimal Value Function)
一、马尔可夫过程(Markov Process)
(一)MDPs论述
马尔可夫决策过程形式化地描述了强化学习的环境 ,这里的环境是完全可见的,例如,当前的状态完全描述了这个过程。几乎所有的 RL 问题都可以形式化地表示为 MDPs 。
(二)马尔科夫特性
“ The future is independent of the past given the present ”,也就是说对当前而言,未来与过去是毫无关系的。马尔可夫状态定义如下图1 :

图1:马尔科夫状态
上诉定义的意思是:当前状态的前提下,下个状态发生的概率 = 当前状态及其之前所有状态的前提下,下一个状态发生的概率。可以理解为,当前状态已经包含了历史所有信息。
(三)状态转移矩阵
定义了一个从当前马尔可夫状态 
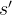

同时定义了一个从所有当前状态 

这个很好理解,比如 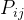
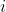
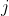
(四)马尔可夫过程
马尔可夫过程是一个无记忆的随机过程,例如一个满足马尔可夫特性的随机状态序列 

图2:马尔科夫过程
马尔可夫过程(又叫马尔可夫链)是一个元组 

(五)样例
David Silver 给出了一个研究生的例子,如图3 :

图3:研究生马尔科夫链
可以看出从 
- ...


同时,从图3 中我们也可以得到状态转移概率矩阵

这里需要注意的一点是,作者认为 David Silver 的课程 PPT 这里存在一点问题,即 
截止到这里的内容比较容易理解,就不过多赘述了,下面开始详述马尔可夫报酬过程。
二、马尔可夫报酬过程(Markov Reward Process)
(一)马尔可夫报酬过程
马尔可夫报酬过程是具有价值的马尔可夫链,定义如下图4 :

图4:马尔可夫报酬过程
这里增加了报酬函数 

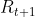


图5:研究生马尔可夫报酬过程
(二)回报
这里我先用语言描述一下马尔可夫决策过程的回报。首先我们设想一下,现在我们处于“ 大学生 ”状态,之后可能的状态有“ 读研 ”和“ 找工作 ”,选择不同的“ 状态 ”将会有不同的“ 未来 ”,未来的“ 收入 ”当然也就有所区别了。现在我们假设选择了“ 读研 ”,以经济学中“ 折现 ”的概念来理解未来的“ 收入 ”,我们现在的选择其实已经一定程度上转换成了“ 一定折扣的未来收入 ”。这就是所谓的回报,用公式表示如下图6 :

图6:回报
这里的 return 
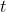
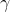
(三)值函数
就上诉回报内容,值函数 

图7:值函数
(四)样例
这里以 


- ...


这里读者可能会想,每一个状态的马尔可夫链不是无数个吗,给定一个马尔可夫链求
(五)MRPs的Bellman等式
计算过程如下,读者就自行理解吧!

然后给出了值函数

为了理解这个公式,直接给出一张图8 :

图8:Bellman Equation for MRPs
这里需要注意一点,作者认为 David Silver 的课程 PPT 中 
解释一下吧,图8 中,状态 

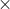

下面给个例子来简单描述一下这个计算过程,如图9 :

图9:值函数的计算
这张图中描述了值函数
读者可能又有疑问,要计算状态
这里给出两种解决方法:
- Bellman等式
- Bellman等式的矩阵形式
(六)Bellman等式
迭代法就是我们令最初的值函数全部为 0 ,通过多次迭代,使得迭代次数达到指定值或者值函数趋于稳定,这里就直接放代码啦!
"""这是MRP迭代过程"""
# 迭代
def next_v(_lambda, r_list, old_v_list, weight_list):
new_v_list = []
for j in range(len(old_v_list)):
if j != len(old_v_list) - 1:
j_sum = .0
# 与当前状态相接的后续状态的值函数相应的状态转移概率的求和的折扣
for k in range(len(weight_list[j])):
j_sum += weight_list[j][k][0] * old_v_list[weight_list[j][k][1]]
# 当前状态在下一阶段的报酬
new_v_list.append(r_list[j] + _lambda * j_sum)
# Sleep状态无后续状态,故直接赋值0
new_v_list.append(0.0)
return new_v_list
if __name__ == '__main__':
# γ
my_lambda = 1
# 报酬顺序:Class 1、Class 2、Class 3、Pass、Pub、Facebook、Sleep,分别对应0, 1, 2, 3, 4, 5, 6
# 后续顺序皆与此相同
my_r_list = [-2., -2., -2., 10., 1., -1., 0.]
# 初始化值函数
my_old_v_list = [0, 0, 0, 0, 0, 0, 0]
# 状态转移概率(这里没有用概率矩阵,方法有点笨,读者可以用矩阵来表示)
# 这里以[[0.5, 1], [0.5, 5]]为例解释一下,该列表记录Class 1的状态:
# [0.5, 1]表示以0.5的概率转移到Class 2
# [0.5, 5]表示以0.5的概率转移到Facebook
my_weight_list = [[[0.5, 1], [0.5, 5]],
[[0.8, 2], [0.2, 6]],
[[0.6, 3], [0.4, 4]],
[[1, 6]],
[[0.2, 0], [0.4, 1], [0.4, 2]],
[[0.1, 0], [0.9, 5]],
[[0, 0]]]
my_new_v_list = []
# 指定迭代次数
for i in range(100):
my_new_v_list = next_v(my_lambda, my_r_list, my_old_v_list, my_weight_list)
# 用新生成的值函数列表替换旧的值函数列表
my_old_v_list = my_new_v_list
print(my_new_v_list)
运行结果与图9 近似,通过增加迭代次数可提高结果准确性:
[-12.418287702397645, 1.4703089405374907, 4.3371337110593915, 10.0, 0.8410368812854547, -22.318009521720207, 0.0]
四舍五入:
[-12, 1.5, 4.3, 10, 0.8, -22, 0]
(七)Bellman等式的矩阵形式
将 Bellman 等式用矩阵形式表示出来,并进行线性变换:

我们可以看到值函数 
给出代码:
import numpy as np
# γ
_lambda = 1
# 状态转移概率矩阵
p = [[0, 0.5, 0, 0, 0, 0.5, 0],
[0, 0, 0.8, 0, 0, 0, 0.2],
[0, 0, 0, 0.6, 0.4, 0, 0],
[0, 0, 0, 0, 0, 0, 1],
[0.2, 0.4, 0.4, 0, 0, 0, 0],
[0.1, 0, 0, 0, 0, 0.9, 0],
[0, 0, 0, 0, 0, 0, 0]]
# 报酬矩阵
r = [[-2],
[-2],
[-2],
[10],
[1],
[-1],
[0]]
# 单位矩阵
i = [[1, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 1]]
p_mat = np.matrix(p)
r_mat = np.matrix(r)
i_mat = np.matrix(i)
# Bellman等式的矩阵形式
v_mat = (i_mat - _lambda * p_mat).I * r_mat
# v_mat = np.dot(np.linalg.inv(i_mat - p_mat), r_mat)
print(v_mat)
通过这种方法计算得到的结果较第一种方法准确,结果如下:
[[-12.54320988]
[ 1.45679012]
[ 4.32098765]
[ 10. ]
[ 0.80246914]
[-22.54320988]
[ 0. ]]四舍五入:
[[-13 ]
[ 1.5]
[ 4.3]
[ 10 ]
[ 0.8]
[-23 ]
[ 0 ]]
三、马尔可夫决策过程(Markov Decision Process)
(一)马尔可夫决策过程
马尔可夫决策过程是伴有决策的的马尔可夫报酬过程,给出定义如下图10 :

图10:马尔可夫决策过程
简单来说,马尔可夫决策过程就是比马尔可夫报酬过程多了一个有限动作集 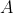

这里给出研究生马尔可夫决策过程,如下图11 :

图11:研究生马尔可夫决策过程
需要注意的一点是,作者认为如上图11 David Silver 的课程 PPT 中红框标注的部分,应该标为 Pass 。因为原先状态图中,旁边的状态为 Pass ,而且同样都是 Study 动作,报酬不同有点不合理,“课程通过 ”可能才配得上报酬 10 吧,哈哈!
这里结构上与图3 存在明显的不同就是取消了状态 Pub ,变成了现在的动作 Pub ,然后该动作可以将 Class 3 状态转移到 Class 1、 Class 2、 Class 3,这里这样修改是为了下面更具普遍性的说明,可以说 David Silver 也是别有用心呀。
(二)策略
policy 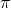

图12:策略π
理解起来也很简单, 

我们再来看看状态转移概率 


我用白话解释一下:执行动作 Study,以 Class 1 状态到Class 2 状态为例计算 




(三)值函数
现在就出现了两种值函数:状态值函数和动作值函数,定义如下图13 ,就不过多解释啦:

图13:状态值函数和动作值函数
展示一个使用 Bellman 等式计算的样例,图14 :

图14:Bellman 等式计算的样例
这里直接给出 Bellman 等式的矩阵形式:

同样的需要状态转移概率矩阵 

(四)Bellman等式的矩阵形式
根据图11 ,可得到如下状态转移概率矩阵:

每个状态转移的平均报酬可如下计算:

可以计算出报酬

然后就可以计算值函数啦!这里分别给出使用 Bellman 等式和 Bellman 等式的矩阵表示的代码,建议读者使用 Bellman 等式的矩阵表示代码。
- Bellman 等式
"""这是MDP迭代过程"""
def next_v(pi, r_list, old_v_list, weight_list):
new_v_list = []
for j in range(len(old_v_list)):
if j != len(old_v_list) - 1:
j_sum = .0
for k in range(len(weight_list[j])):
if type(weight_list[j][k][0]) is not list:
j_sum += pi * (r_list[weight_list[j][k][1]] + old_v_list[weight_list[j][k][0]])
else:
m_sum = .0
for m in range(len(weight_list[j][k][0])):
m_sum += old_v_list[weight_list[j][k][0][m][0]] * weight_list[j][k][0][m][1]
j_sum += pi * (r_list[weight_list[j][k][1]] + m_sum)
new_v_list.append(j_sum)
new_v_list.append(0.0)
return new_v_list
if __name__ == '__main__':
my_pi = 0.5
# 报酬顺序:study pass pub facebook quit sleep
my_r_list = [-2., 10., 1., -1., 0., 0.]
my_old_v_list = [0, 0, 0, 0, 0]
my_weight_list = [[[1, 0], [3, 3]],
[[2, 0], [4, 5]],
[[[[0, 0.2], [1, 0.4], [2, 0.4]], 2], [4, 1]],
[[0, 4], [3, 3]],
[]]
my_new_v_list = []
# my_new_v_list = next_v(my_pi, my_r_list, my_old_v_list, my_weight_list)
for i in range(100):
my_new_v_list = next_v(my_pi, my_r_list, my_old_v_list, my_weight_list)
my_old_v_list = my_new_v_list
print(my_new_v_list)
结果:
[-1.3076923099959044, 2.6923076920317515, 7.384615384159404, -2.3076923112229597, 0.0]
四舍五入:
[-1.3, 2.7, 7.4, -2.3, 0.0]
- Bellman 等式的矩阵表示
import numpy as np
# π、γ
_pi = 0.5
_lambda = 1
p = [[0, _pi, 0, _pi, 0],
[0, 0, _pi, 0, _pi],
[_pi*0.2, _pi*0.4, _pi*0.4, 0, _pi],
[_pi, 0, 0, _pi, 0],
[0, 0, 0, 0, 0]]
r = [[_pi*-2 + _pi*-1],
[_pi*-2 + _pi*0],
[_pi*1 + _pi*10],
[_pi*0 + _pi*-1],
[0]]
i = [[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 0, 1]]
p_mat = np.matrix(p)
r_mat = np.matrix(r)
i_mat = np.matrix(i)
v_mat = (i_mat - _lambda * p_mat).I * r_mat
# v_mat = np.dot(np.linalg.inv(i_mat - p_mat), r_mat)
print(v_mat)
结果:
[[-1.30769231]
[ 2.69230769]
[ 7.38461538]
[-2.30769231]
[ 0. ]]四舍五入:
[[-1.3]
[ 2.7]
[ 7.4]
[-2.3]
[ 0. ]]
四、最优值函数(Optimal Value Function)
注意,这里求解的 MDP 状态值函数,每个状态的回报是根据转移概率计算的平均回报,这称为贝尔曼期望方程(Bellman Expectation Equation)。而在强化学习中,通常是选取使得价值最大的动作执行,这种解法称为最优值函数(Optimal Value Function),得到的解不再是期望值函数,而是理论最大值函数。此时相当于策略 π 已经改变,且非线性,线性方程组不再适用,需要通过数值计算的方式求出。通常的做法是设置状态值函数 

这里给出计算 
"""这是OVF迭代过程"""
def next_v(pi, r_list, old_v_list, weight_list):
new_v_list = []
for j in range(len(old_v_list)):
if j != len(old_v_list) - 1:
max_list = []
for k in range(len(weight_list[j])):
if type(weight_list[j][k][0]) is not list:
max_list.append(pi * (r_list[weight_list[j][k][1]] + old_v_list[weight_list[j][k][0]]))
else:
m_sum = .0
for m in range(len(weight_list[j][k][0])):
m_sum += old_v_list[weight_list[j][k][0][m][0]] * weight_list[j][k][0][m][1]
max_list.append(pi * (r_list[weight_list[j][k][1]] + m_sum))
new_v_list.append(max(max_list))
new_v_list.append(0.0)
return new_v_list
if __name__ == '__main__':
my_pi = 1
# study pass pub facebook quit sleep
my_r_list = [-2., 10., 1., -1., 0., 0.]
my_old_v_list = [0, 0, 0, 0, 0]
my_weight_list = [[[1, 0], [3, 3]],
[[2, 0], [4, 5]],
[[[[0, 0.2], [1, 0.4], [2, 0.4]], 2], [4, 1]],
[[0, 4], [3, 3]],
[]]
my_new_v_list = []
# my_new_v_list = next_v(my_pi, my_r_list, my_old_v_list, my_weight_list)
for i in range(100):
my_new_v_list = next_v(my_pi, my_r_list, my_old_v_list, my_weight_list)
my_old_v_list = my_new_v_list
print(my_new_v_list)
结果:
[6.0, 8.0, 10.0, 6.0, 0.0]
结果如下图15 所示:

图15:最优值函数
写到这里有点累了,具体公式读者就看 PPT 吧,这里讲一个简单的计算最优动作值函数 

图16:最优动作值函数
最优值函数我们已经用代码算出来了,计算最优动作值函数
更多内容大家自己阅读 PPT 吧,内容以上传到我的博客。