前言
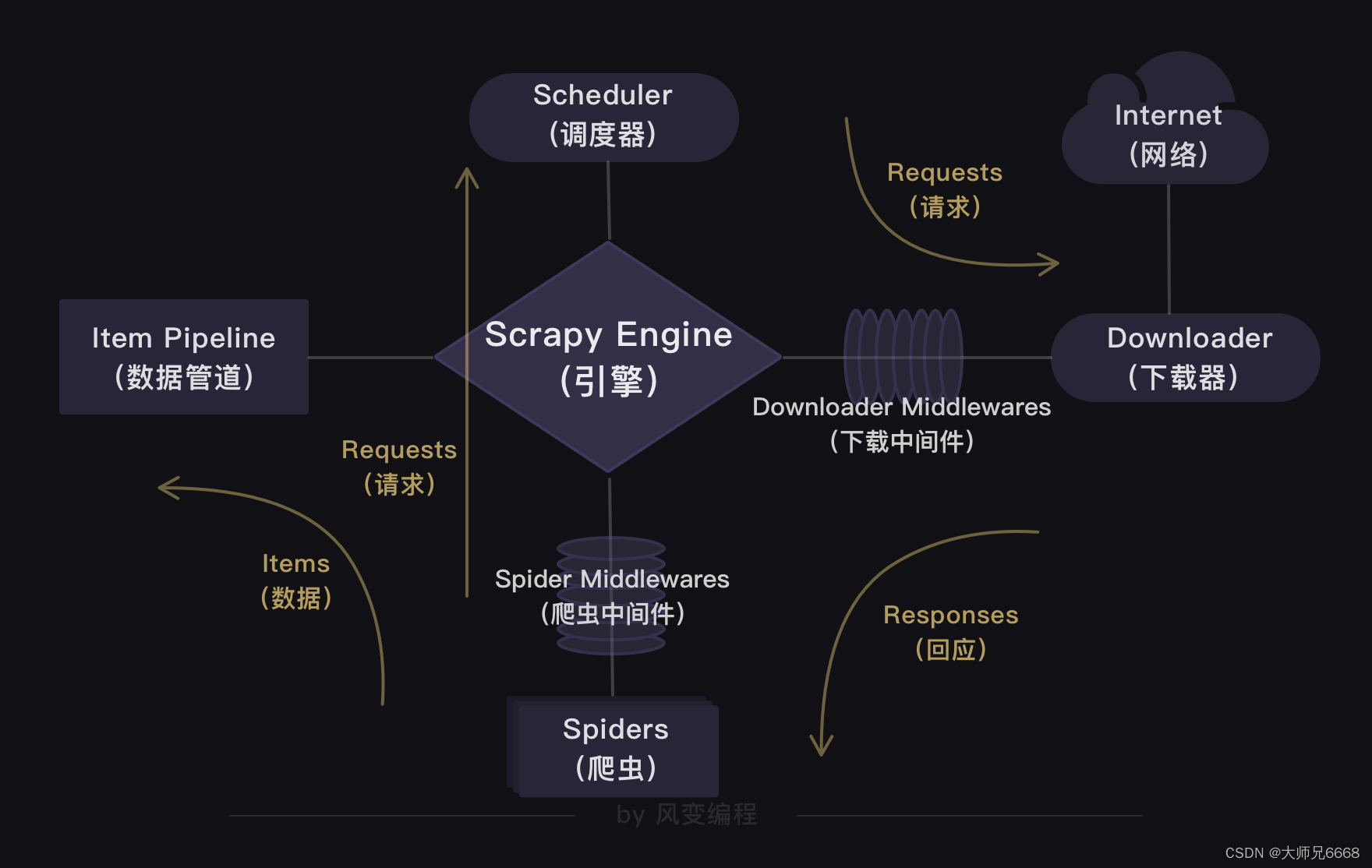
上一关,我们学习了Scrapy框架,知道了Scrapy爬虫公司的结构和工作原理。
在Scrapy爬虫公司里,引擎是最大的boss,统领着调度器、下载器、爬虫和数据管道四大部门。
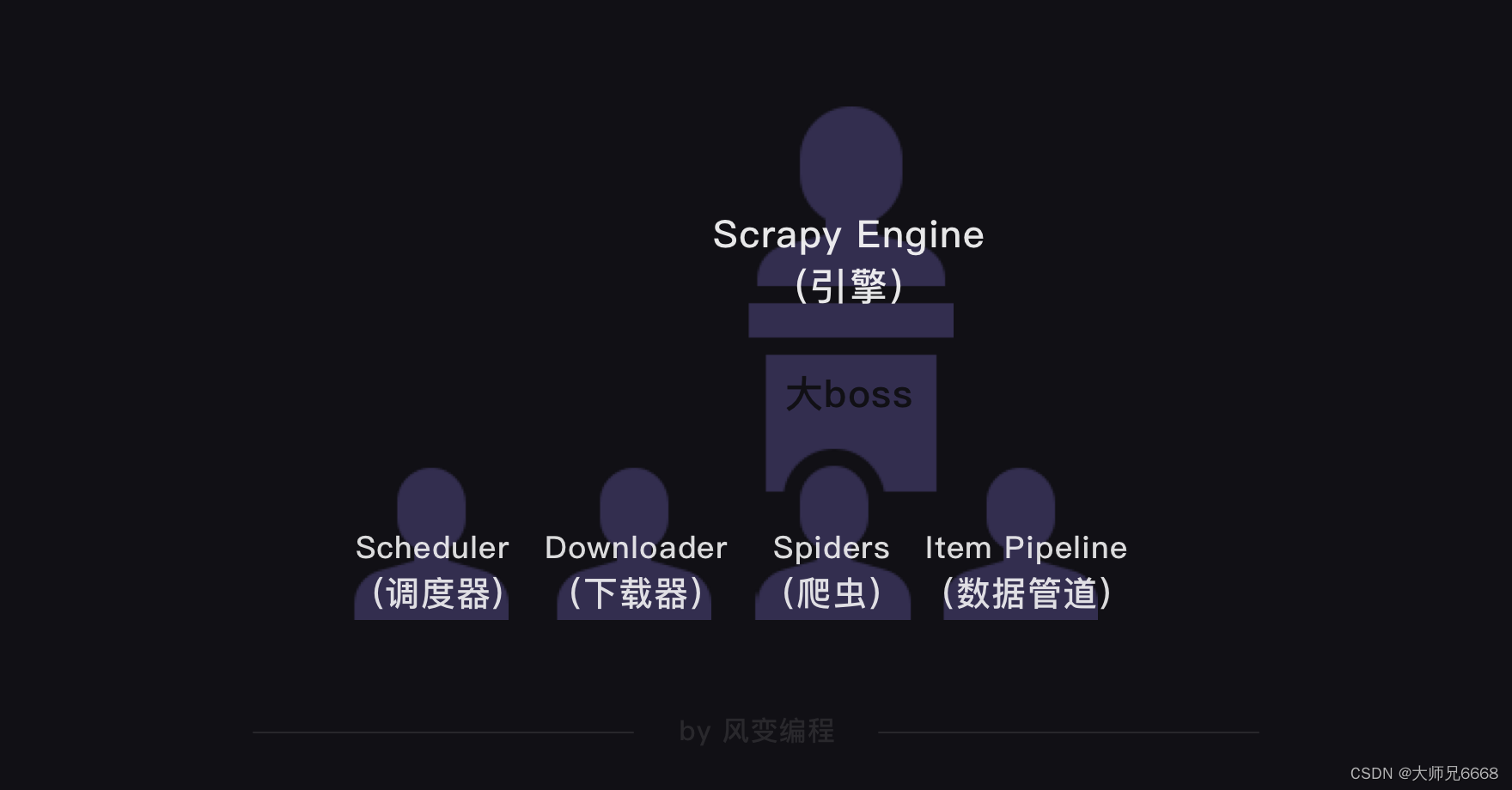
这四大部门都听命于引擎,视引擎的需求为最高需求。
我们还通过实操爬取豆瓣Top250图书的项目,熟悉了Scrapy的用法。
这一关,我会带你实操一个更大的项目——用Scrapy爬取招聘网站的招聘信息。

你可以借此体验一把当Scrapy爬虫公司CEO的感觉,用代码控制并操作整个Scrapy的运行。
那我们爬取什么招聘网站呢?在众多招聘网站中,我挑选了职友集。这个网站可以通过索引的方式,搜索到全国上百家招聘网站的最新职位。
现在,请你用浏览器打开职友集的网址链接(一定要打开哦):
https://www.jobui.com/rank/company/view/beijing/
我用的是北京的页面,大家可以根据自己的需要来进行更换地区。
我们先对这个网站做初步的观察,这样我们才能明确项目的爬取目标。
明确目标
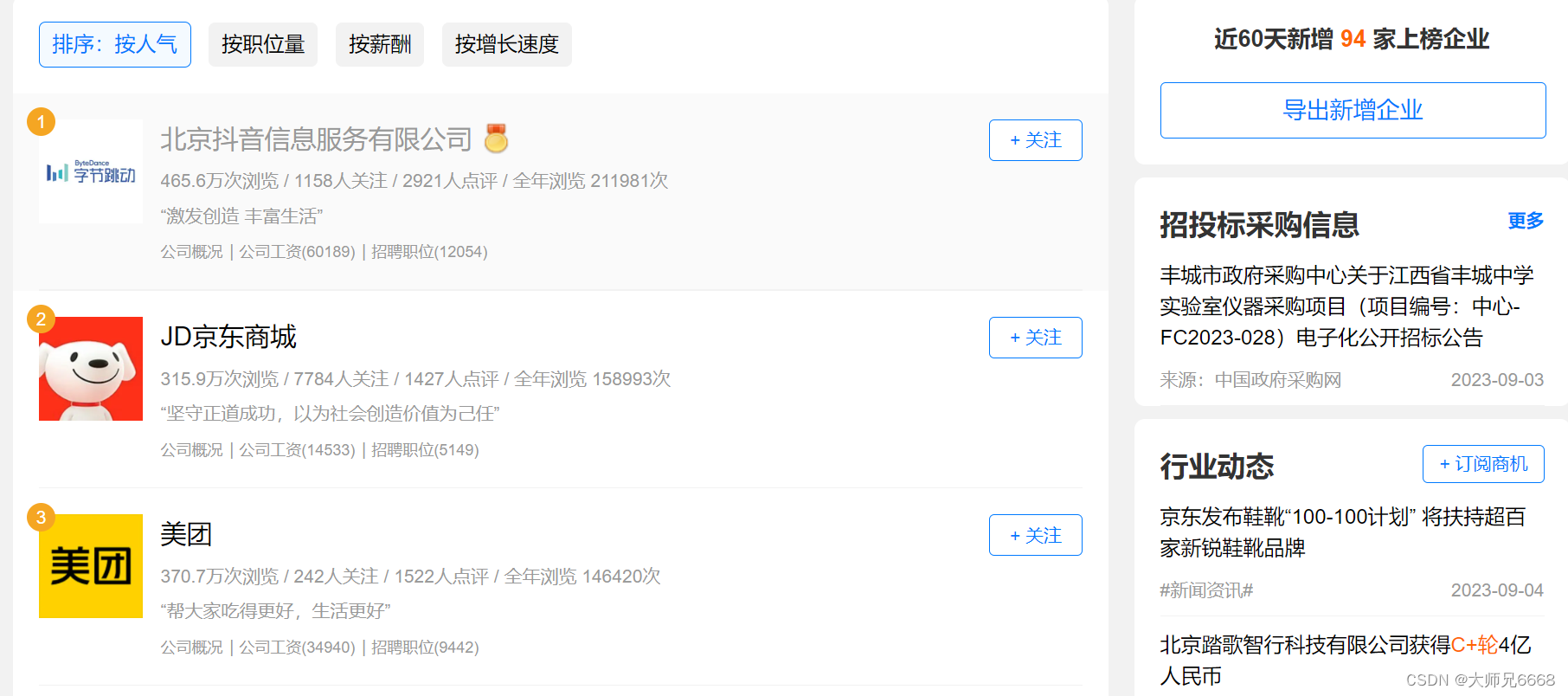
打开网址后,你会发现:这是职友集网站的地区企业排行榜,里面含有本月人气企业榜。
点击【北京痘印信息服务有限公司】,会跳转到这家公司的详情页面,再点击【招聘】,就能看到这家公司正在招聘的所有岗位信息。
初步观察后,我们可以把爬取目标定为:先爬取企业排行榜四个榜单里的公司,再接着爬取这些公司的招聘信息。
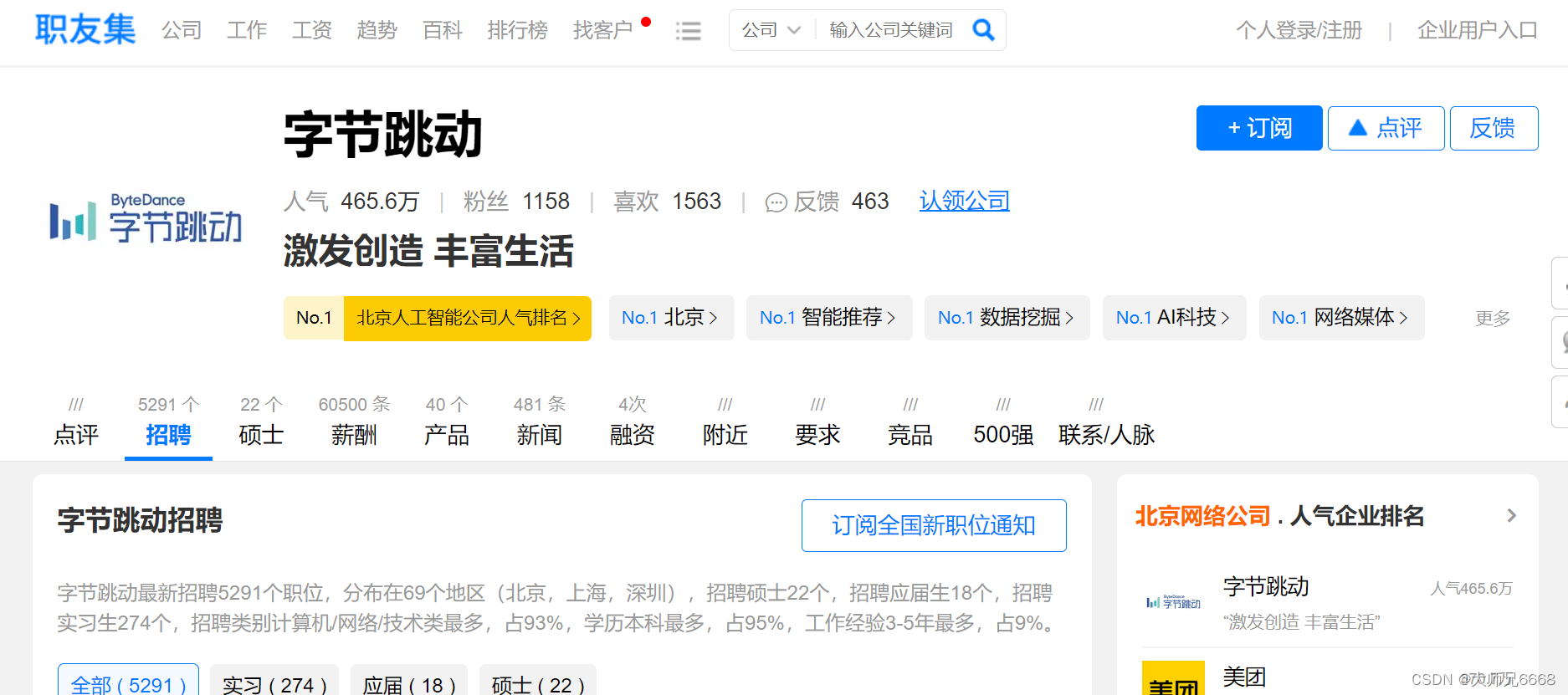
每个榜单有10家公司,四个榜单一共就是40家公司。也就是说,我们要先从企业排行榜爬取到这40家公司,再跳转到这40家公司的招聘信息页面,爬取到公司名称、职位、工作地点和招聘要求。
分析过程
明确完目标,我们开始分析过程。首先,要看企业排行榜里的公司信息藏在了哪里。
企业排行榜的公司信息
请你右击打开“检查”工具,点击Network,刷新页面。点开第0个请求beijing/,看Response,找一下有没有榜单的公司信息在里面。
一找,发现四个榜单的所有公司信息都在里面。说明企业排行榜的公司信息就藏在html里。
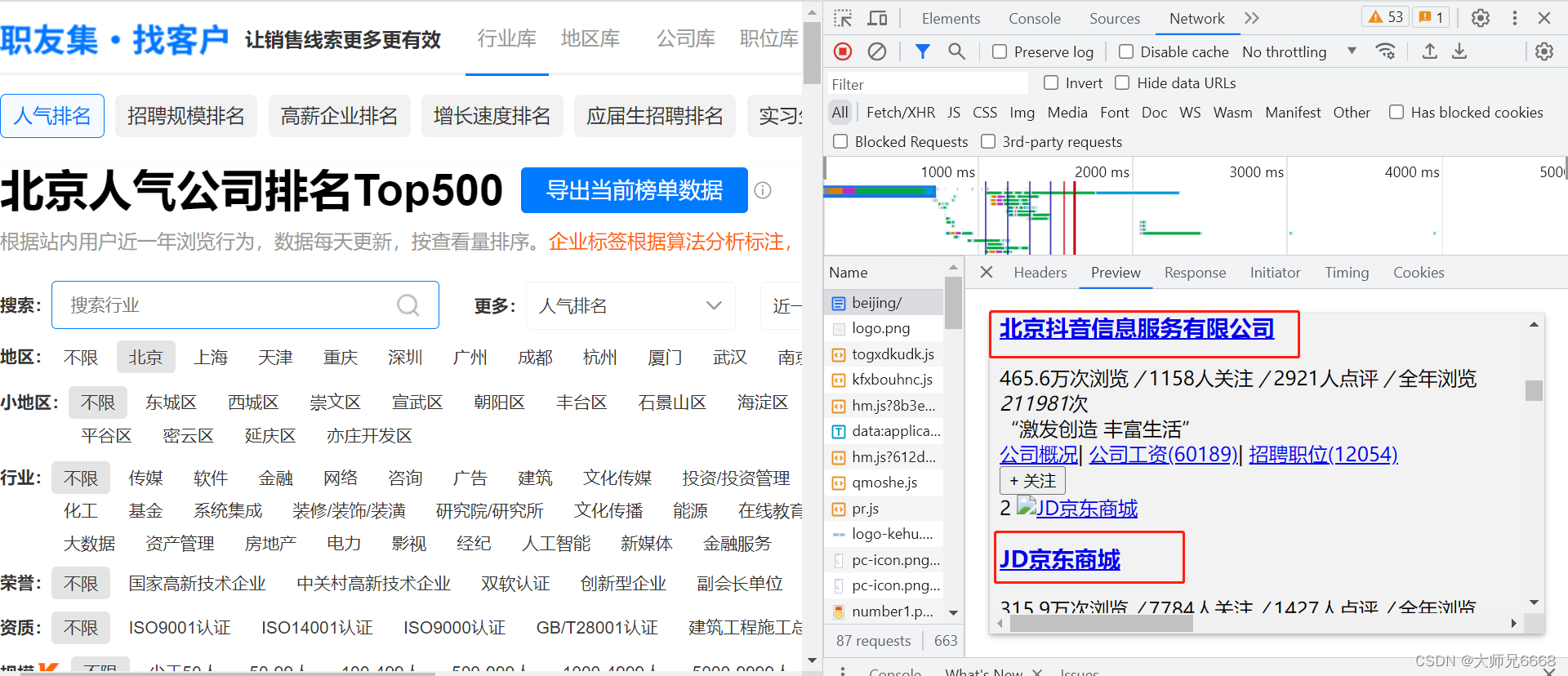
现在请你点击Elements,点亮光标,再把鼠标移到【北京抖音信息服务有限公司】,这时就会定位到含有这家公司信息的<a>元素上。
点击href=“/company/10375749/”,会跳转到字节跳动这家公司的详情页面。详情页面的网址是:
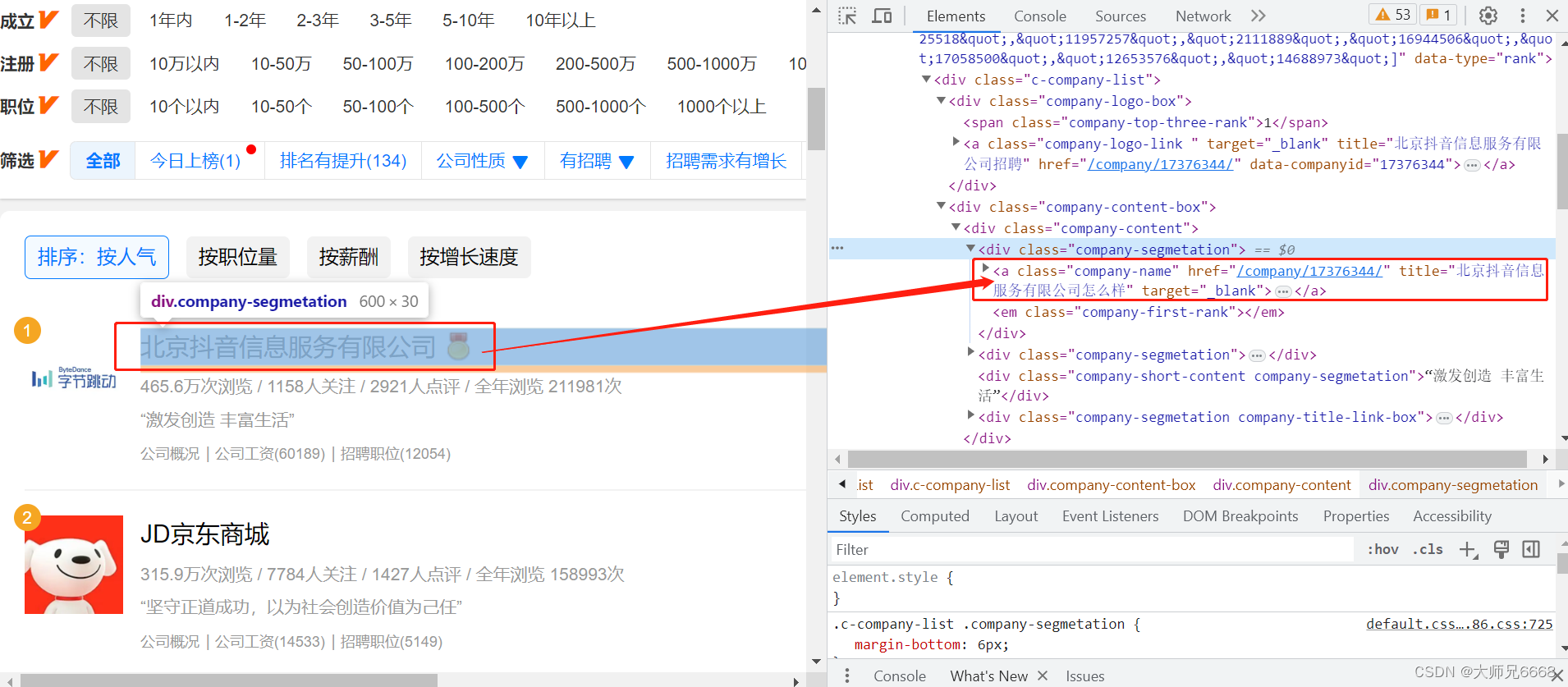
https://www.jobui.com/company/17376344/
我们可以猜到:/company/+数字/应该是公司id的标识。这么一观察,榜单上的公司详情页面的网址规律我们就得出来了。
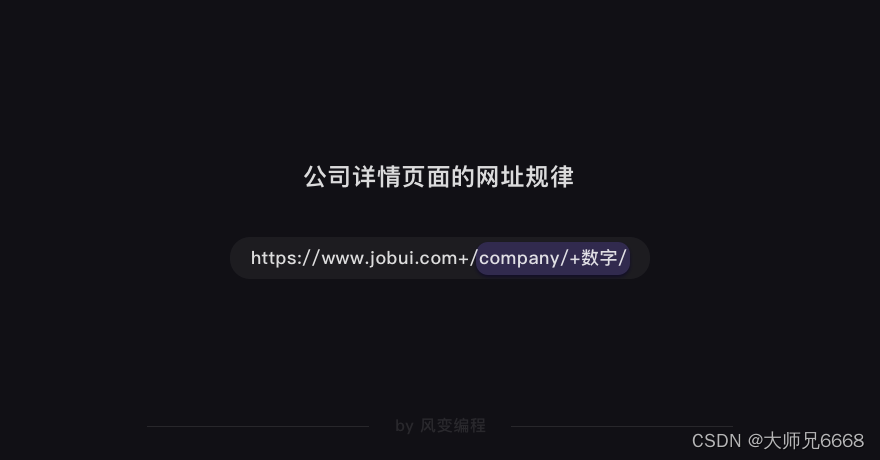
那么,我们只要把<a>元素的href属性的值提取出来,就能构造出每家公司详情页面的网址。
构造公司详情页面的网址是为了后面能获得详情页面里的招聘信息。
现在,我们来分析html的结构,看看怎样才能把<a>元素href属性的值提取出来。
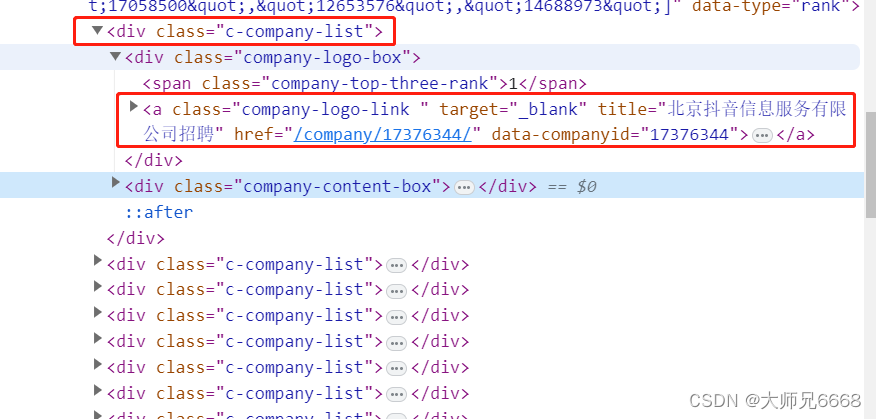
仔细观察html的结构,你会发现,每个公司信息都藏在一个<div class="c-company-list">元素里,这个div标签中包<div class="company-logo-box">和<div class="company-content-box">两个div。
我们想要的<a>标签,就在<div class="company-logo-box">里面。
我们想拿到所有<a>元素href属性的值。我们当然不能直接用find_all()抓取<a>标签,原因也很简单:这个页面有太多的<a>标签,会抓出来很多我们不想要的信息。
一个稳妥的方案是:先抓取最外层的<div>标签,再抓取<div>标签里的<a>元素,最后提取到<a>元素href属性的值。就像剥洋葱,要从最外面的一层开始剥一样。
分析到这里,我们已经知道公司详情页面的网址规律,和如何提取<a>元素href属性的值。
接下来,我们需要分析的就是,每家公司的详情页面。
公司详情页面的招聘信息
我们打开【北京字节跳动科技有限公司】的详情页面,点击【招聘】。这时,网址会发生变化,多了jobs的参数。
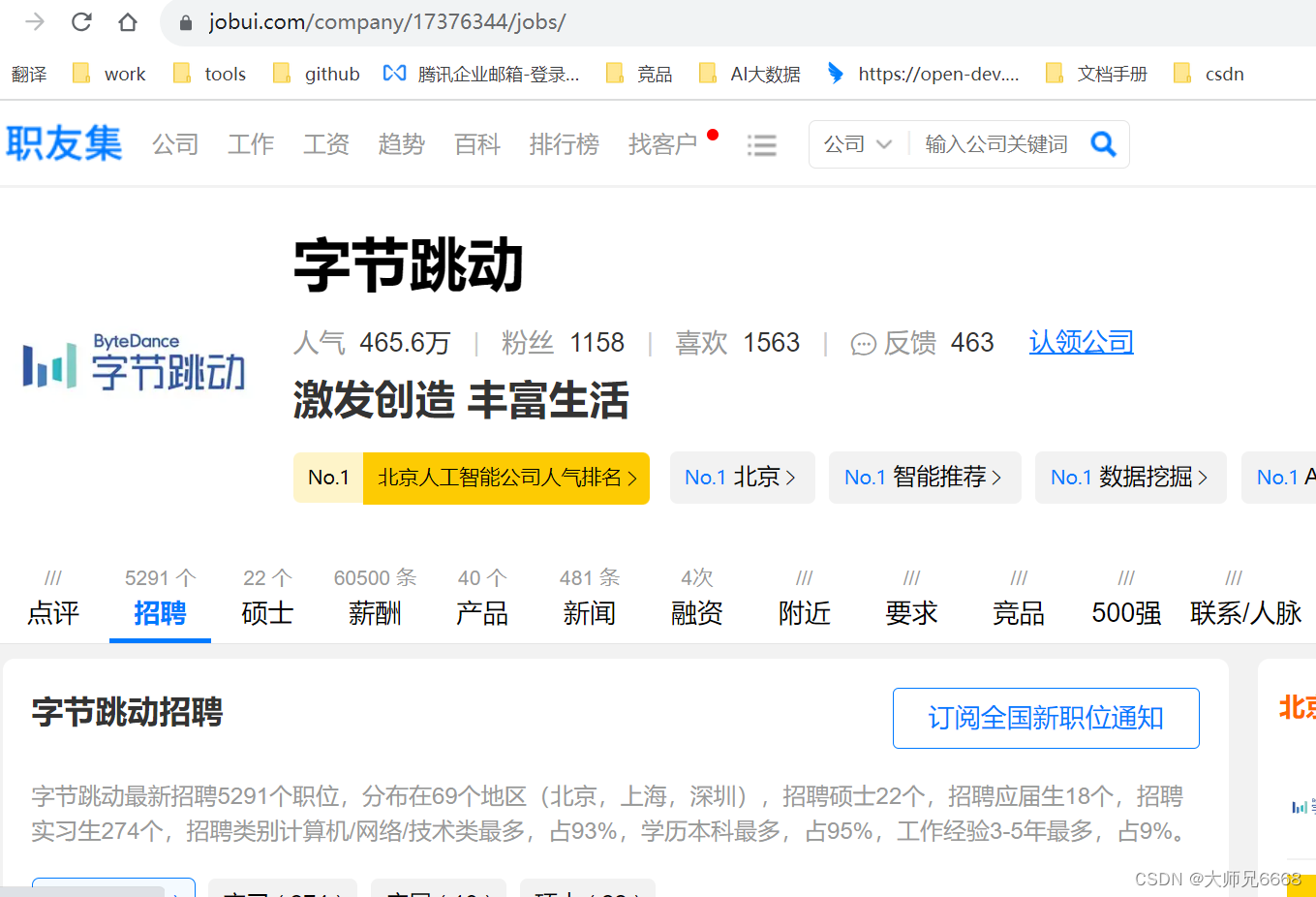
如果你多点击几家公司的详情页面,查看招聘信息,就会知道:公司招聘信息的网址规律也是有规律的。
接着,我们需要找找看公司的招聘信息都存在了哪里。

还是在字节跳动公司的招聘信息页面,右击打开“检查”工具,点击Network,刷新页面。我们点击第0个请求jobs/,查看Response,翻找看看里面有没有这家公司的招聘信息。
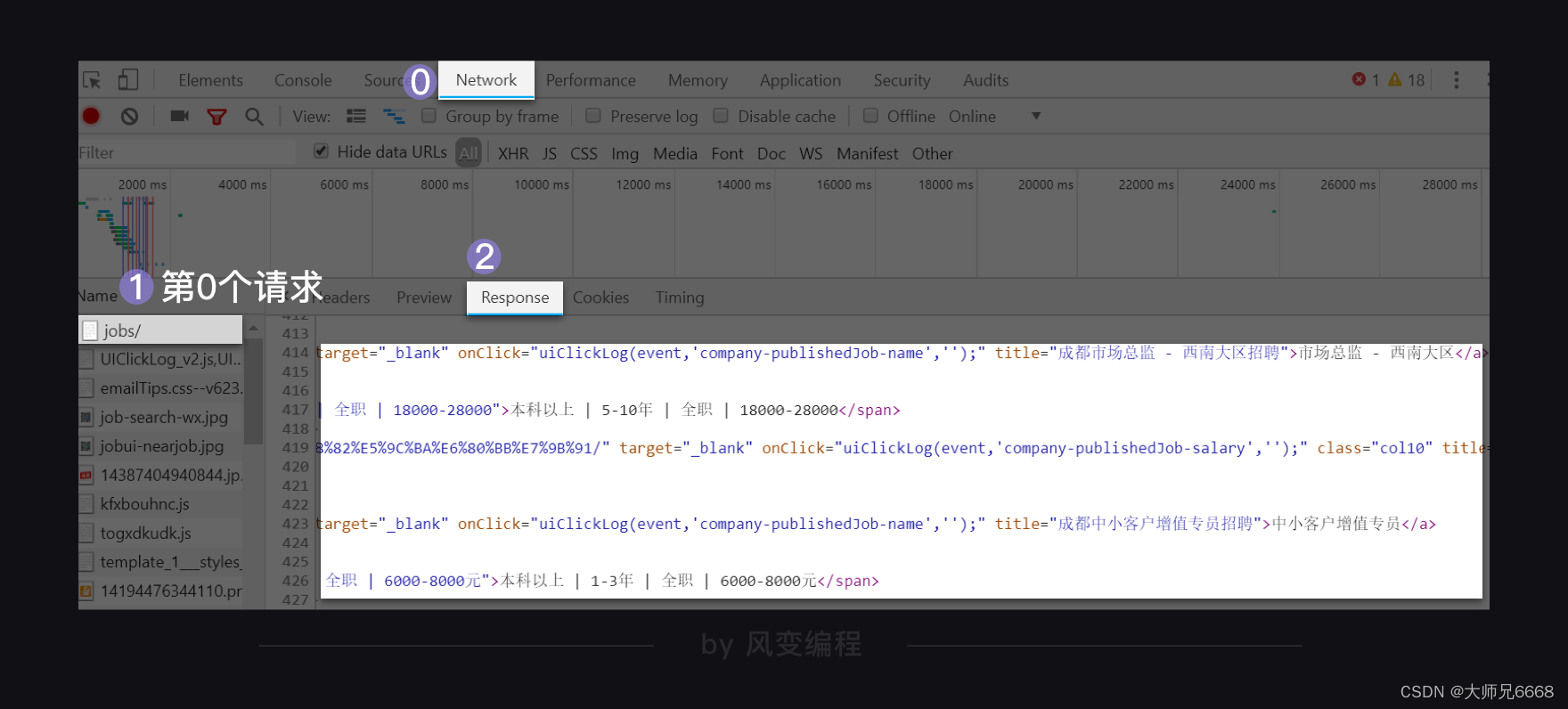
在Response里我们找到了想要的招聘信息。这说明公司的招聘信息依旧是藏在了html里。
接下来,你应该知道要分析什么了吧。
分析的套路都是相同的,知道数据藏在html后,接着是分析html的结构,想办法提取出我们想要的数据。
那就按照惯例点击Elements,然后点亮光标,把鼠标移到公司名称吧。
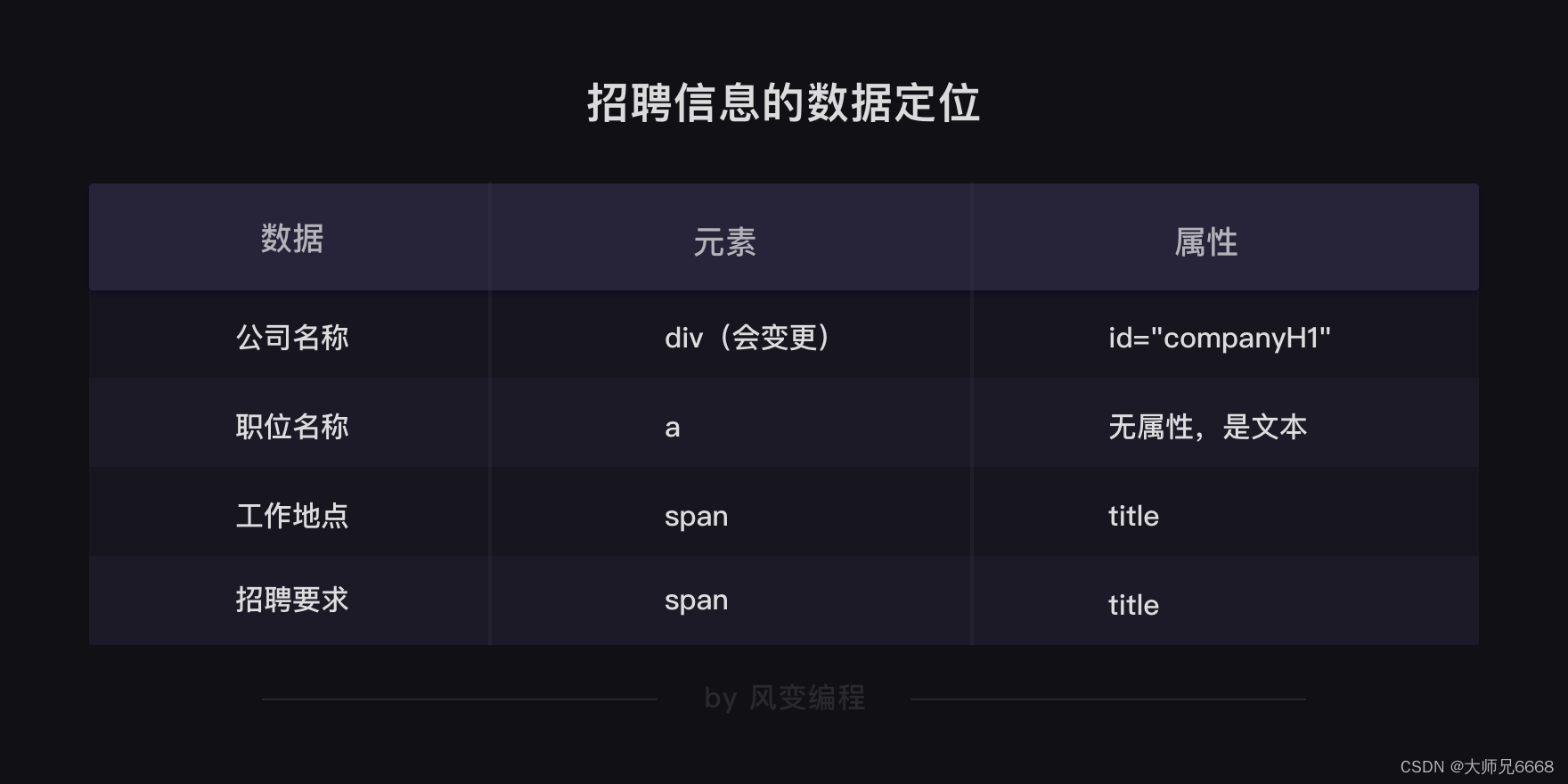
公司名称藏在<div class="company-banner-title">标签下的<a>元素的文本中。按道理来说,我们可以通过class属性,定位到<div>的这个标签,取出<div>标签的文本,就能拿到公司名称。
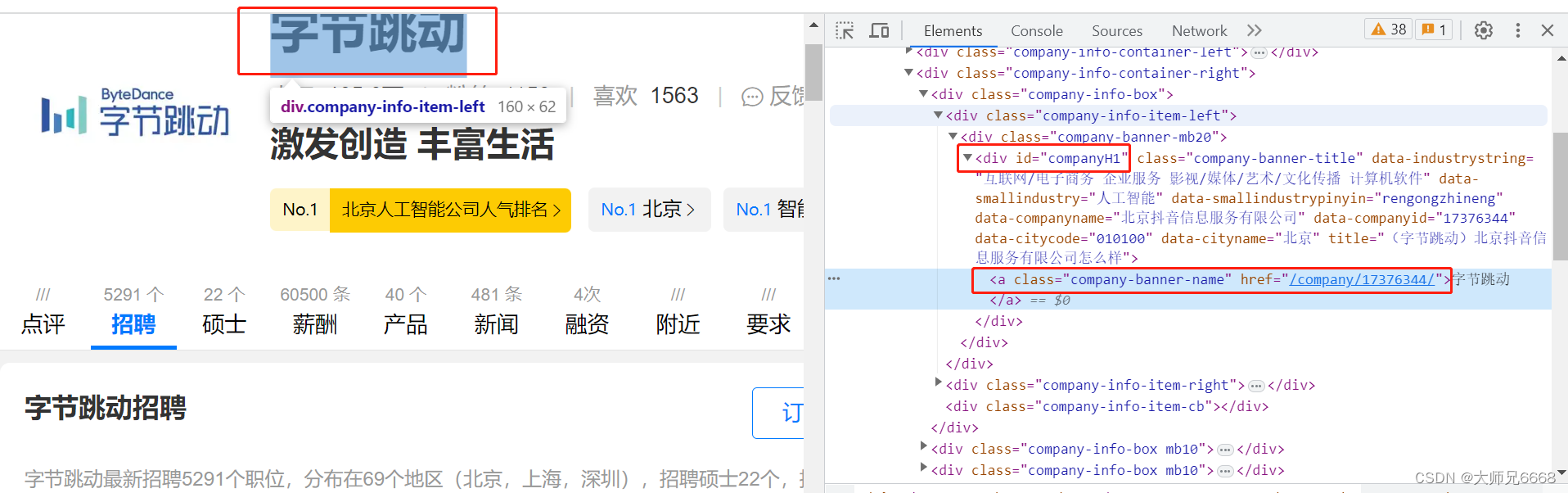
不过经过我几次的操作试验,发现职友集这个网站间隔一段时间就会更换这个标签的名字(可能你此时看到的标签名不一定是
为了保证一定能取到公司名称,我们改成用id属性(id=“companyH1”)来定位这个标签。这样,不管这个标签名字如何更换,我们依旧能抓到它。
下面,再把鼠标移到岗位名称,看看招聘的岗位信息可以怎么提取。
你会发现:每个岗位的信息都藏在一个<div>标签下,职位名称在<a>元素的文本中,工作地点和职位要求在<div class="job-desc">元素中,工作地点在第 1 个<span>标签里,职位要求在第 2 个<span>标签里。
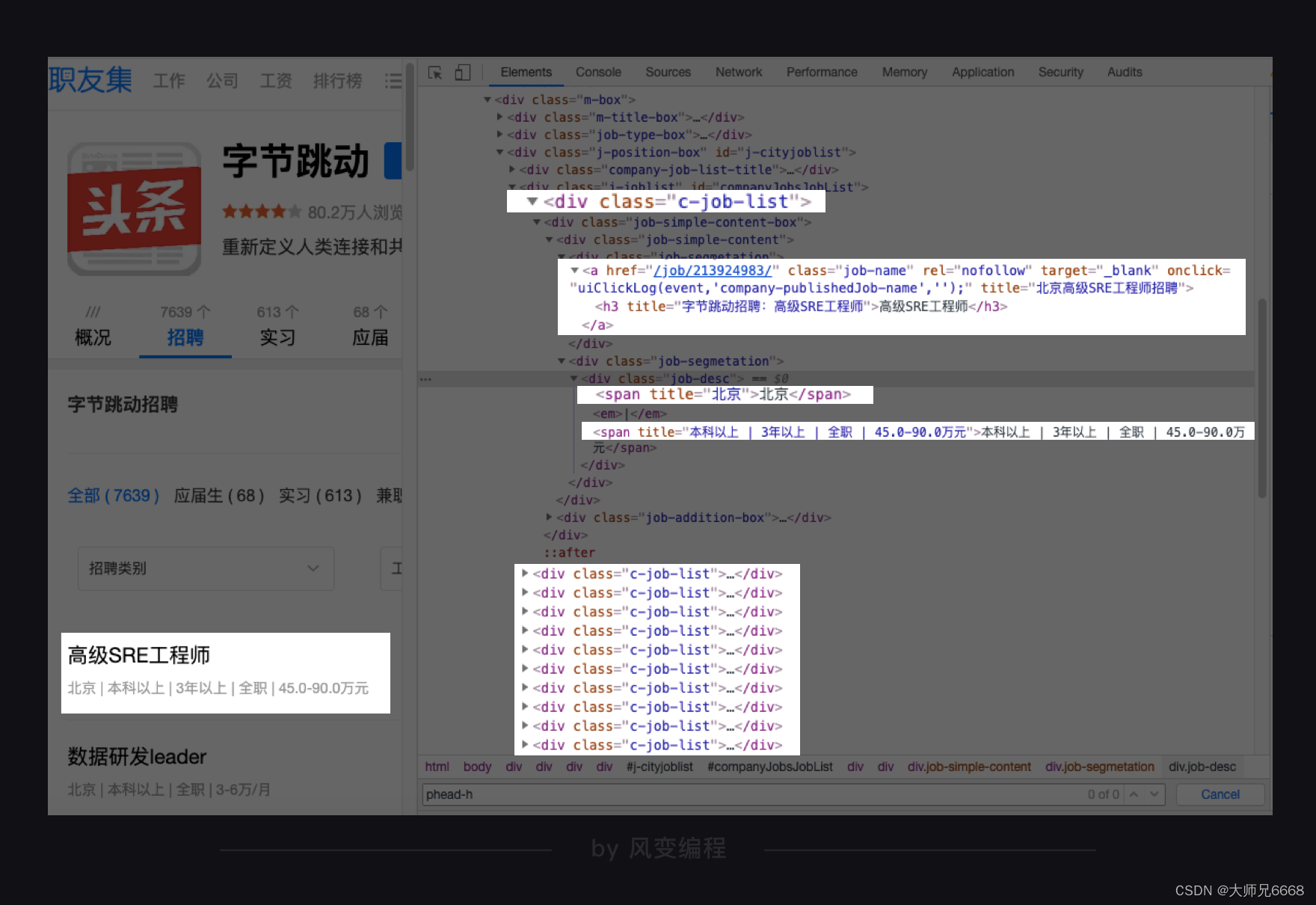
这样分析下来,我们想要的招聘信息,包括公司名称、职位名称、工作地点和职位要求,都定位清楚了。
至此,我们分析完了整个爬取过程,接下来就是代码实现啦。
代码实现
我们按照Scrapy正常的用法一步步来。首先,我们必须创建一个Scrapy项目。

创建项目
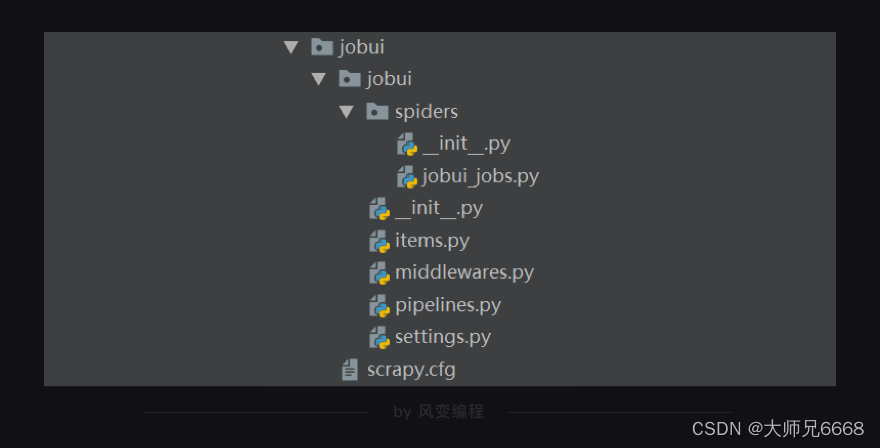
还记得怎么创建吗?打开本地电脑的终端(windows:Win+R,输入cmd;mac:command+空格,搜索“终端”),跳转到你想要保存项目的目录下,输入创建Scrapy项目的命令:scrapy startproject jobui(jobui是职友集网站的英文名,在这里我们把它作为Scrapy项目的名字)。
创建好项目后,你在本地电脑的编译器打开这个Scrapy项目,会看到如下的结构:
定义item
我们刚刚分析的时候,已经确定要爬取的数据是公司名称、职位名称、工作地点和招聘要求。
那么,现在请你写出定义item的代码。
下面,是我写的定义item的代码。
import scrapy
class JobuiItem(scrapy.Item):
#定义了一个继承自scrapy.Item的JobuiItem类
company = scrapy.Field()
#定义公司名称的数据属性
position = scrapy.Field()
#定义职位名称的数据属性
address = scrapy.Field()
#定义工作地点的数据属性
detail = scrapy.Field()
#定义招聘要求的数据属性
创建和编写爬虫文件
定义好item,我们接着要做的是在spiders里创建爬虫文件,命名为jobui_ jobs。
现在,我们可以开始在这个爬虫文件里编写代码。
先导入所需的模块:
import scrapy
import bs4
from ..items import JobuiItem
接下来,是编写爬虫的核心代码。我会先带着你理清代码的逻辑,这样等下你才能比较顺利地理解和写出代码。
在前面分析过程的步骤里,我们知道要先抓取企业排行榜40家公司的id标识,比如字节跳动公司的id标识是/company/17376344/。

再利用抓取到的公司id标识构造出每家公司招聘信息的网址。比如,字节跳动公司的招聘信息网址就是https://www.jobui.com/company/17376344/jobs/
我们需要再把每家公司招聘信息的网址封装成requests对象。这里你可能有点不理解为什么要封装成requests对象,我解释一下。
如果我们不是使用Scrapy,而是使用requests库的话,一般我们得到一个网址,需要用requests.get(),传入网址这个参数,才能获取到网页的源代码。
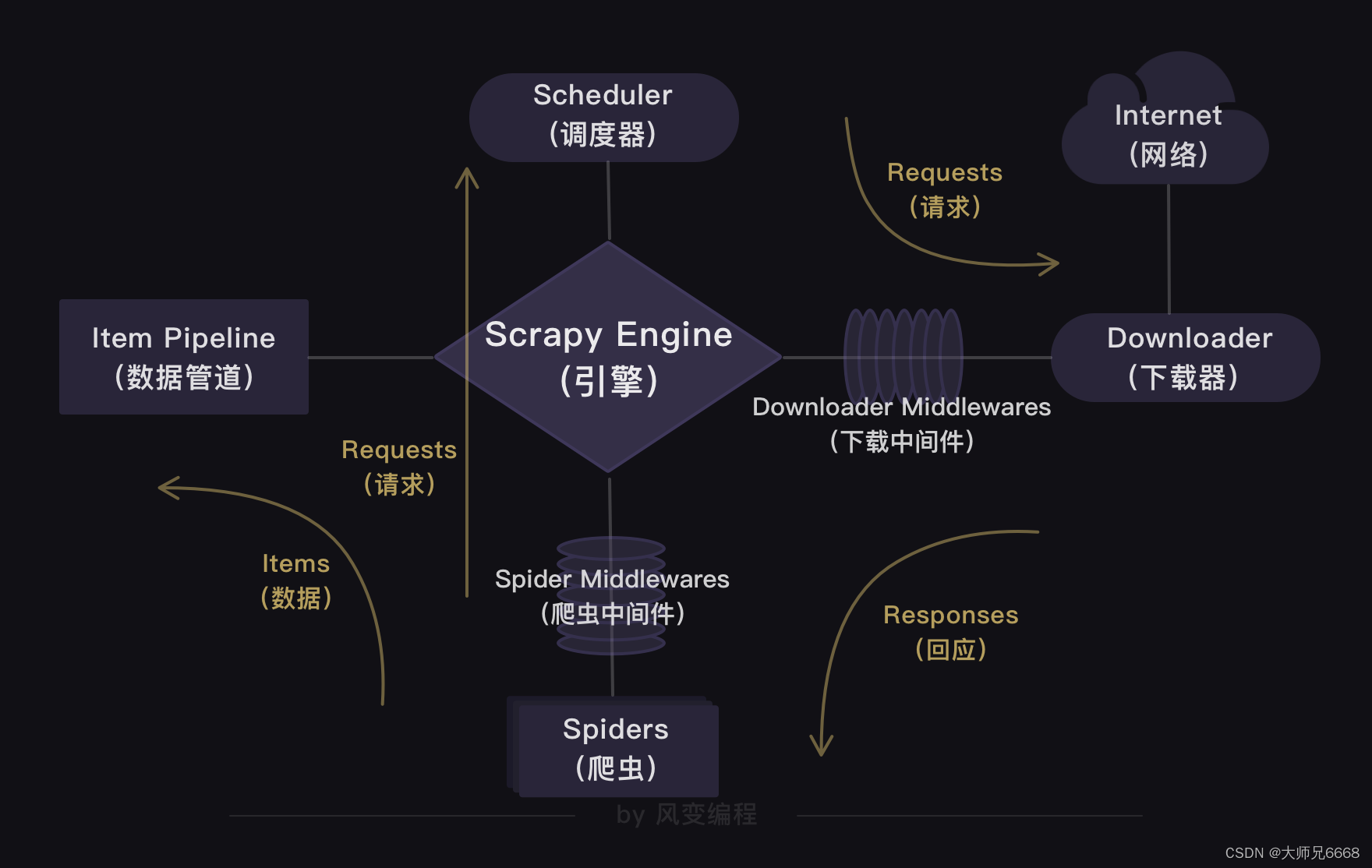
而在Scrapy里,获取网页源代码这件事儿,会由引擎交分配给下载器去做,不需要我们自己处理。我们之所以要构造新的requests对象,是为了告诉引擎,我们新的请求需要传入什么参数。
这样才能让引擎拿到的是正确requests对象,交给下载器处理。
既然构造了新的requests对象,我们就得定义与之匹配的用来处理response的新方法。这样才能提取出我们想要的招聘信息的数据。
好啦,核心代码的逻辑我们理清楚了。
我们接着往下写核心代码。

#导入模块
import scrapy
import bs4
from ..items import JobuiItem
class JobuiSpider(scrapy.Spider):
#定义一个爬虫类JobuiSpider
name = 'jobui'
#定义爬虫的名字为jobui
allowed_domains = ['www.jobui.com']
#定义允许爬虫爬取网址的域名——职友集网站的域名
start_urls = ['https://www.jobui.com/rank/company/view/beijing/']
#定义起始网址——职友集企业排行榜的网址(北京)
def parse(self, response):
#parse是默认处理response的方法
bs = bs4.BeautifulSoup(response.text, 'html.parser')
#用BeautifulSoup解析response(企业排行榜的网页源代码)
company_list = bs.find('div',id="companyList").find_all('div',class_='c-company-list')
#用find_all提取所有<div class="c-company-list">标签
for company in company_list:
#遍历company_list
data = company.find('a')
# 找到其中第一个<a>标签,即<div class="company-logo-box">下的<a>标签
company_id = data['href']
#提取出所有<a>元素的href属性的值,也就是公司id标识
url = 'https://www.jobui.com{id}jobs'
real_url = url.format(id=company_id)
#构造出公司招聘信息的网址链接
第6-13行代码:定义了爬虫类JobuiSpider、爬虫的名字jobui、允许爬虫爬取的域名和起始网址。
剩下的代码,你应该都能看懂。我们用默认的parse方法来处理response(企业排行榜的网页源代码);用BeautifulSoup来解析response;用find_all方法提取数据(公司id标识)。
公司id标识就是<a>元素的href属性的值,我们想要把它提取出来,就得先抓到所有最外层的<div class="c-company-list">标签,再从中抓取<a>元素。
所以这里用了个for循环,把元素的href属性的值提取了出来,并成功构造了公司招聘信息的网址。
代码写到这里,我们已经完成了核心代码逻辑的前两件事:提取企业排行榜的公司id标识和构造公司招聘信息的网址。
接下来,就是构造新的requests对象和定义新的方法处理response。

继续来完善核心代码(请你重点看第30行代码及之后的代码)。
#导入模块
import scrapy
import bs4
from ..items import JobuiItem
class JobuiSpider(scrapy.Spider):
#定义一个爬虫类JobuiSpider
name = 'jobui'
#定义爬虫的名字为jobui
allowed_domains = ['www.jobui.com']
#定义允许爬虫爬取网址的域名——职友集网站的域名
start_urls = ['https://www.jobui.com/rank/company/view/beijing/']
#定义起始网址——职友集企业排行榜的网址
def parse(self, response):
#parse是默认处理response的方法
bs = bs4.BeautifulSoup(response.text, 'html.parser')
#用BeautifulSoup解析response(企业排行榜的网页源代码)
company_list = bs.find('div',id="companyList").find_all('div',class_='c-company-list')
#用find_all提取所有<div class="c-company-list">标签
for company in company_list:
#遍历company_list
data = company.find('a')
# 找到其中第一个<a>标签,即<div class="company-logo-box">下的<a>标签
company_id = data['href']
#提取出所有<a>元素的href属性的值,也就是公司id标识
url = 'https://www.jobui.com{id}jobs'
real_url = url.format(id=company_id)
#构造出公司招聘信息的网址链接
yield scrapy.Request(real_url, callback=self.parse_job)
#用yield语句把构造好的request对象传递给引擎。用scrapy.Request构造request对象。callback参数设置调用parsejob方法。
def parse_job(self, response):
#定义新的处理response的方法parse_job(方法的名字可以自己起)
bs = bs4.BeautifulSoup(response.text, 'html.parser')
#用BeautifulSoup解析response(公司招聘信息的网页源代码)
company = bs.find(id="companyH1").text
#用find方法提取出公司名称
datas = bs.find_all('div',class_="c-job-list")
#用find_all提取<div class_="c-job-list">标签,里面含有招聘信息的数据
for data in datas:
#遍历datas
item = JobuiItem()
#实例化JobuiItem这个类
item['company'] = company
#把公司名称放回JobuiItem类的company属性里
item['position']=data.find('a').find('h3').text
#提取出职位名称,并把这个数据放回JobuiItem类的position属性里
item['address'] = data.find_all('span')[0].text
#提取出工作地点,并把这个数据放回JobuiItem类的address属性里
item['detail'] = data.find_all('span')[1].text
#提取出招聘要求,并把这个数据放回JobuiItem类的detail属性里
yield item
#用yield语句把item传递给引擎
你应该不理解第30行代码:yield scrapy.Request(real_url, callback=self.parse_job)的意思。我跟你解释一下。
scrapy.Request是构造requests对象的类。real_url是我们往requests对象里传入的每家公司招聘信息网址的参数。
callback的中文意思是回调。self.parse_job是我们新定义的parse_job方法。往requests对象里传入callback=self.parse_job这个参数后,引擎就能知道response要前往的下一站,是parse_job()方法。
yield语句就是用来把这个构造好的requests对象传递给引擎。
第34行代码,是我们定义的新的parse_job方法。这个方法是用来解析和提取公司招聘信息的数据。
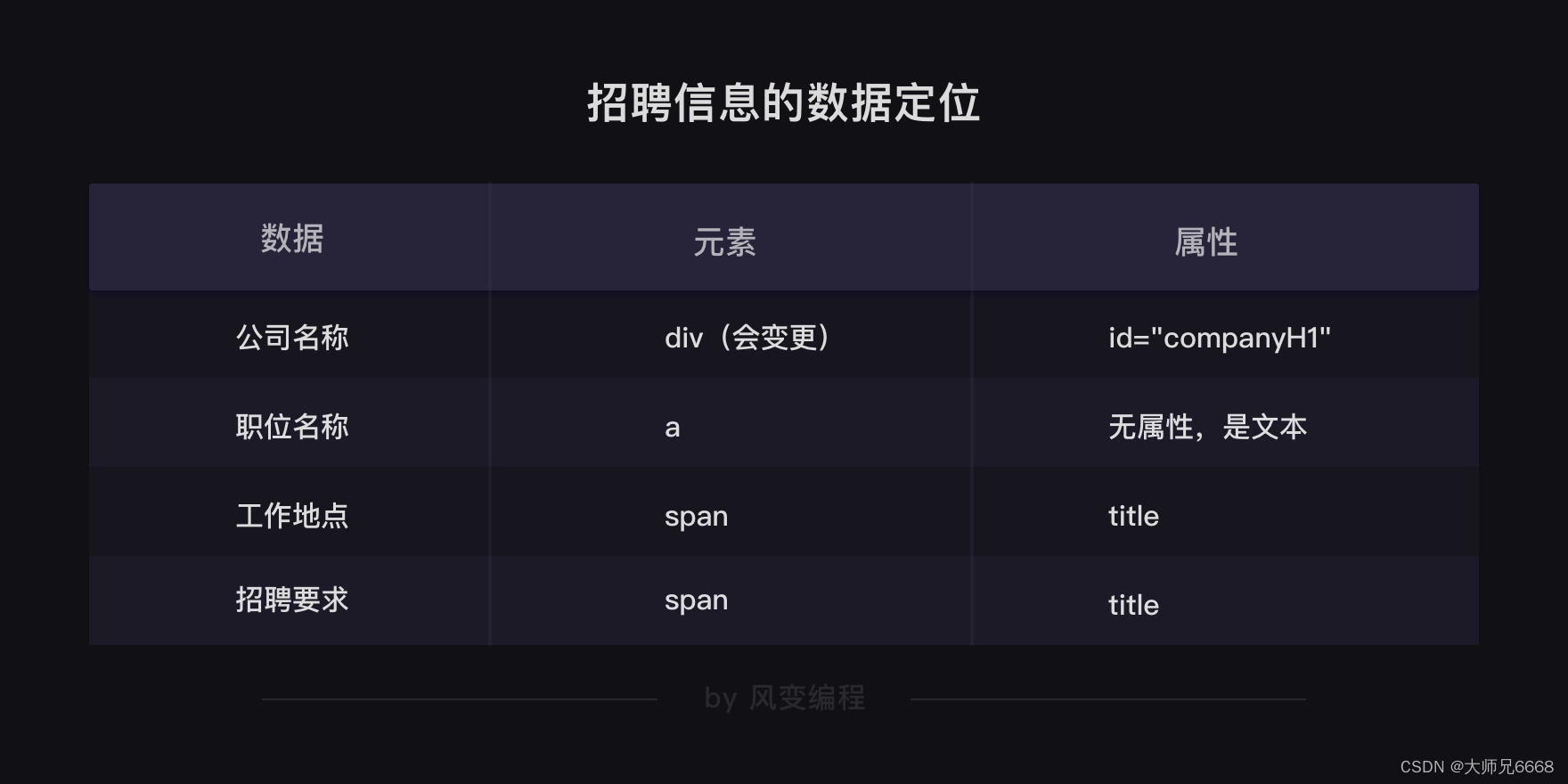
对照下面的招聘信息的数据定位表格,你应该能比较好地理解之后的代码。
上图中的工作地点和招聘要求 的属性,已经修正为了 text 请大家注意。
提取出公司名称、职位名称、工作地点和招聘要求这些数据,并把这些数据放进我们定义好的JobuiItem类里。
最后,用yield语句把item传递给引擎,整个核心代码就编写完啦!ヽ(゚∀゚)メ(゚∀゚)ノ
存储文件
至此,我们整个项目还差存储数据这一步。在第7关,我们学过用csv模块把数据存储csv文件,用openpyxl模块把数据存储Excel文件。
其实,在Scrapy里,把数据存储成csv文件和Excel文件,也有分别对应的方法。我们先说csv文件。
存储成csv文件的方法比较简单,只需在settings.py文件里,添加如下的代码即可。
FEED_URI='./storage/data/%(name)s.csv'
FEED_FORMAT='csv'
FEED_EXPORT_ENCODING='ansi'
FEED_URI是导出文件的路径。‘./storage/data/%(name)s.csv’,就是把存储的文件放到与main.py文件同级的storage文件夹的data子文件夹里。
FEED_FORMAT 是导出数据格式,写csv就能得到csv格式。
FEED_EXPORT_ENCODING 是导出文件编码,ansi是一种在windows上的编码格式,你也可以把它变成utf-8用在mac电脑上。
存储成Excel文件的方法要稍微复杂一些,我们需要先在settings.py里设置启用ITEM_PIPELINES,设置方法如下:
#需要修改`ITEM_PIPELINES`的设置代码:
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'jobui.pipelines.JobuiPipeline': 300,
# }
只要取消ITEM_PIPELINES的注释(删掉#)即可。
#取消`ITEM_PIPELINES`的注释后:
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jobui.pipelines.JobuiPipeline': 300,
}
接着,我们就可以去编辑pipelines.py文件。存储为Excel文件,我们依旧是用openpyxl模块来实现,代码如下,注意阅读注释:
import openpyxl
class JobuiPipeline(object):
#定义一个JobuiPipeline类,负责处理item
def __init__(self):
#初始化函数 当类实例化时这个方法会自启动
self.wb =openpyxl.Workbook()
#创建工作薄
self.ws = self.wb.active
#定位活动表
self.ws.append(['公司', '职位', '地址', '招聘信息'])
#用append函数往表格添加表头
def process_item(self, item, spider):
#process_item是默认的处理item的方法,就像parse是默认处理response的方法
line = [item['company'], item['position'], item['address'], item['detail']]
#把公司名称、职位名称、工作地点和招聘要求都写成列表的形式,赋值给line
self.ws.append(line)
#用append函数把公司名称、职位名称、工作地点和招聘要求的数据都添加进表格
return item
#将item丢回给引擎,如果后面还有这个item需要经过的itempipeline,引擎会自己调度
def close_spider(self, spider):
#close_spider是当爬虫结束运行时,这个方法就会执行
self.wb.save('./jobui.xlsx')
#保存文件
self.wb.close()
#关闭文件
修改设置
在最后,我们还要再修改Scrapy中settings.py文件里的默认设置:添加请求头,以及把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False。
#需要修改的默认设置:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'jobui (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
还有一处默认设置我们需要修改,代码如下:
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 0
我们需要取消DOWNLOAD_DELAY = 0这行的注释(删掉#)。DOWNLOAD_DELAY翻译成中文是下载延迟的意思,这行代码可以控制爬虫的速度。因为这个项目的爬取速度不宜过快,我们要把下载延迟的时间改成0.5秒。
改好后的代码如下:
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.5
修改完设置,我们已经可以运行代码。

温馨提示:由于网站反爬策略升级,如果发现请求的响应结果不是200,那就参照之前的文章来进行解决即可。
代码实操
我带你完成了核心代码的编写,现在是时候到你自己动手编写一遍这个项目的核心代码。
提示1:除了编写核心代码,还要定义item、修改设置和运行Scrapy。
提示2:运行Scrapy的方法,在main.py文件里导入cmdline模块,用execute方法执行终端的命令行:scrapy crawl+项目名
提示3:如果是使用main.py作为入口来进行运行的话,只有main.py文件是能点击运行的。
提示4:存储为csv还是Excel,你可以自己决定。存储为csv只需要更改settings文件,存储为Excel则还需要修改pipelines.py文件。
开始代码实操吧~
怎么样,完成了吗?
不管代码有没有运行成功,我都为你鼓掌!ヾ(o´∀`o)ノ
总结
至此,我们使用Scrapy完成了一个完整项目。它涉及了一个爬虫的全程:获取数据,解析数据,提取数据和存储数据。
但是必须要指出的是,受篇幅所限,还有许多内容没展开讲:Scrapy的自带解析器怎么用?如何带参数请求数据?如何写入cookies?如何发送邮件?如何与selenium联动?如何完成超厉害的分布式爬虫……如是种种。
如是种种,全都讲出来可能还要新增好几个关卡。但是我认为,这不是必要的。
一来,你已经学习过用BS解析数据、带参数请求数据、加入cookies、发邮件、协程……你明白它们的工作原理。
二来,你已经明白Scrapy框架的组成和工作原理。
只要将两者加以组合,辅以练习,就能轻松掌握。
今日的你,只是不知道语法怎么写罢了。而语法问题,是最容易解决的问题,我们可以去阅读官方文档。因为你已具备上述知识,所以这文档读起来也会非常简单。
在下一关,我为你准备了对过往知识的总复习、反爬虫策略汇总、对未来爬虫学习的指引,以及一封书信。
我们下一关见!