ASCII、GB2312、GBK、GB18030、Unicode、UTF-8、BIG5 编码详解
“锟斤拷,烫烫烫烫烫~~~~”
当你打开一个文件,发现竟然乱码了;当你下载了一个未引进的国外软件,打开发现也乱码了。
这是怎么回事?
其实我们在生活中遇到的绝大多数乱码问题,都是因为不同的编码字符集导致的。
甚至不少程序猿也深受编码问题的困扰。
例如一个学习Python的新手在用Python2写代码时想输出中文,程序肯定会报出 UnicodeDecodeError 这样的错误。例如一个前端开发工程师写了一个网页用浏览器打开看到的都是些小方框。
事实上Python2不支持中文这个问题只需要在代码中添加一行声明编码方式就解决了。一行代码解决Python2不支持中文字符集
目前,我们比较常见的编码规范有 ascii、gb2312、gbk、gb18030、unicode、utf-8、big5 这7种,它们收纳了不同范围的字符,如果你的文件中包含了某种编码没有收纳的字符,打开当然会乱码。
因此,深入了解编码,弄懂他们的区别、应用场景以及相互间转换的方式,我们将彻底摆脱编码问题带来的种种烦恼。下面,我将从计算机原理开始讲清楚编码的前世今生,并在最后对这几种编码进行总结对比。
一、什么是编码,为什么需要编码
首先,我们从信息(消息)说起。消息以人类可以理解、易懂的表示存在,我们将这种表示称为“明文”(plain text)。比如我们能看懂的汉字、英文、图片等都可以称为明文。
然而,计算机只认识二进制数字,计算机中的所有数据,不论是文字、图片、视频、还是音频文件,本质上都是按照类似 01010101 的二进制存储的,在我们的明文面前它相当于一个文盲。
为了让计算机表示我们能看懂的明文,我们需要将明文表示的消息转成0101这种二进制表示,我们还需要将0101这种二进制表示转回成明文。从明文到二进制的转换称为“编码”,从二进制文本又转回成明文则为“解码”。
在这里,顺便简单解释下为什么计算机只懂二进制:
在计算机电路中,电平只有两种状态,高电平(通电)和低电平(未通电),并规定用1和0表示这两种状态。当多个电平组合在一起,就相当于对多个0、1进行排列组合,假设4个电平为一组,那么就可以表示 24 = 16种不同的状态。
二、 ascii、gb2312、gbk、gb18030、unicode、utf-8、big5 编码的产生和定义
1. ASCII 编码:
定义:
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:28 = 256,所以,ASCII码最多只能表示 256 个符号。
诞生:
计算机只认二进制,如果将八个电平做为一组就可以表示出 28 = 256种不同状态,如果用不同的状态来表示不同的字符,比如将字母“A”用00010001来表示,那么8位电平一共就可以表示256种不同的字符,而英文字母只有26个字符,算上一些特殊符号和数字,其实只要128个状态就已经能够表示了。规定将每个电平称为一个比特位(bit),约定8个比特位构成一个字节(byte),这样计算机就可以用127个不同字节来存储英语的文字,于是ASCII编码就。
扩展ascii码:上面提到其实只要128种状态就能表示所以英文字母和常见符号了,一个字节由8位二进制组成,一共可以表示256种字符,然而才利用一半,为了不浪费,就把剩余没有利用的状态用来表示拉丁文了,遗憾的是它并没有表示汉字,所以初始的ascii编码是不支持中文的。
下图是ASCII编码表示的前128种字符: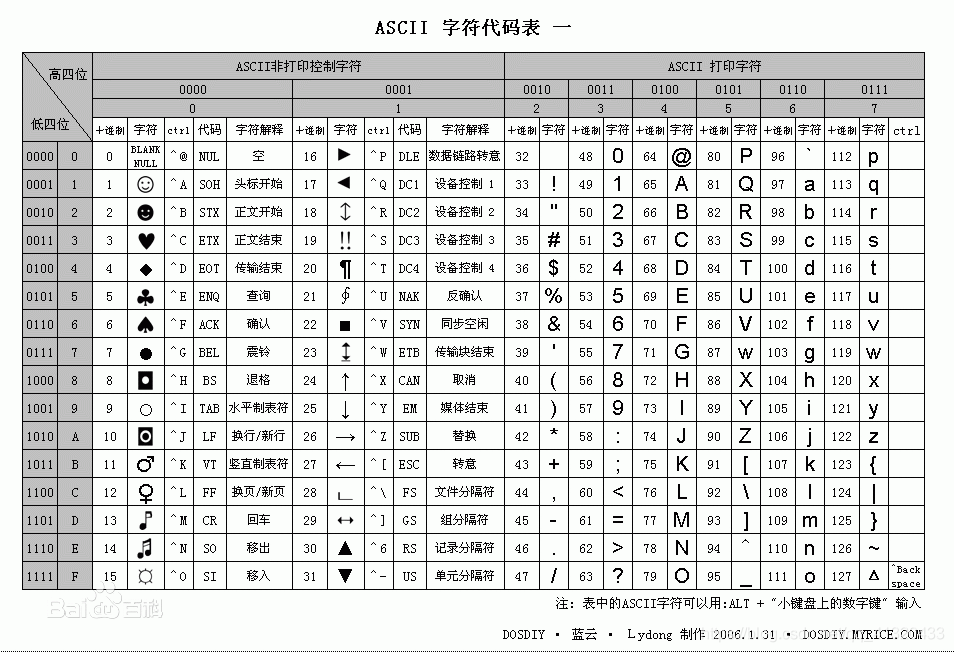
因为ascii编码装不下那么多汉字;最关键的是这是美国人发明的,对他们来讲能编码英文就足够了,何况那时候中国还没有几台计算机呢。
2. GB2312 编码:
定义:
GB2312编码是中华人民共和国国家汉字信息交换用编码,全称《信息交换用汉字编码字符集——基本集》,由国家标准总局发布,1981年5月1日实施,通行于大陆。新加坡等地也使用此编码。GB2312 收录简化汉字及符号、字母、日文假名等共 7445 个图形字符,其中汉字占 6763 个。GB2312规定“对任意一个图形字符都采用两个字节表示,每个字节均采用七位编码表示”,习惯上称第一个字节为“高字节”,第二个字节为“低字节”。
诞生:
当计算机漂洋过海来到中国后,问题来了,计算机不认识中文,当然也没法显示中文;而之前的ascii编码又没有收录汉字,而且一个字节的256种状态都被占满了,真是万恶的帝国主义啊。
无可奈何,中国必须要自己重写一张表来编码咱们的汉字,于是直接生猛地将扩展的第八位(即扩展ascii码)对应的拉丁文全部删掉,规定一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(称为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了;这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。
3. GBK 编码:
定义:
GBK是包括中日韩字符的大字符集合,全国信息技术化技术委员会于1995年12月1日发布的《汉字内码扩展规范》。GBK 向下与 GB2312 完全兼容,向上支持 ISO
10646 国际标准,在前者向后者过渡过程中起到的承上启下的作用。GBK 亦采用双字节表示,总体编码范围为 8140-FEFE之间,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 XX7F 一条线。GBK 共收入 21886 个汉字和图形符号。
GBK 编码区 分成三部分:
-
汉字区,包括:
GBK/2:OXBOA1-F7FE, 收录 GB2312 汉字 6763 个,按原序排列;
GBK/3:OX8140-AOFE,收录 CJK 汉字 6080 个;
GBK/4:OXAA40-FEAO,收录 CJK 汉字和增补的汉字 8160 个。 -
图形符号区,包括:
GBK/1:OXA1A1-A9FE,除 GB2312 的符号外,还增补了其它符号
GBK/5:OXA840-A9AO,扩除非汉字区。 -
用户自定义区:
即 GBK 区域中的空白区,用户可以自己定义字符。
诞生:
尽管GB2312编码可以让计算机读懂表示常用中文字符了,但是中国文化博大精深,汉字太多了,GB2312也不够用,于是又规定:只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。这样扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时GBK又增加了近20000个新的汉字(包括繁体字)和符号。
4. gGB18030 编码:
定义:
2000年的GB18030是取代GBK的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。GB18030 是最新的汉字编码字符集国家标准, 向下兼容 GBK 和 GB2312 标准。
GB18030的编码采用单字节、双字节和4字节方案。其中单字节、双字节和GBK是完全兼容的。4字节编码的码位就是收录了CJK扩展A的6582个汉字。
GB18030编码是一二四字节变长编码。一字节部分从 0x0~0x7F 与 ASCII 编码兼容。 二字节部分, 首字节从 0x81~0xFE,尾字节从 0x40~0x7E 以及 0x80~0xFE, 与 GBK 标准基本兼容。 四字节部分,第一字节从 0x81~0xFE, 第二字节从 0x30~0x39,第三和第四字节的范围和前两个字节分别相同。 四字节部分覆盖了从 0x0080 开始, 除去二字节部分已经覆盖的所有 Unicode码位,也就是说, GB18030 编码在码位空间上做到了与 Unicode 标准一一对应,这一点与 UTF-8编码类似。目前最新的 glibc 2.2.x 系列已经全面支持了 GB18030 Locale 和 GB18030 与 UCS-4之间的编码转换, 也就是说在系统层上 Linux 已经可以支持 GB18030 标准了。
5. Unicode 编码:
定义:
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536。
诞生:
尽管有了ASCII编码,GB2312编码,GBK编码,甚至别的国家也有自己的编码字符集,但是各个国家的标准不同,并不兼容,对于互联网而言,这严重阻碍了各个国家的交流。因此建立一个能统一世界各国语言的编码迫不及待,Unicode便诞生了。
6. UTF-8 编码:
定义:
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部份修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。
诞生:
unicode都一统天下了,为什么还要有一个utf-8的编码呢?
对于英文世界的人来讲,比如要存储字母’A‘,本来用00010001一个字节就可以了,而为了世界和平改用Unicode得用两个字节:00000000 00010001才行。
举个例子:一个用ASCII编码的大小为20G的英文文件,如果改用Unicode编码,文件大小会变成40G!浪费太严重。
基于此,美利坚的科学家们提出了天才的想法:UTF-8编码
它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。
这样显著的好处是,虽然在我们内存中的数据都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf8省空间啦!这也是为什么utf-8是我们的推荐编码方式。
7. BIG5 编码:
定义:
BIG5是通行于台湾、香港地区的一个繁体字编码方案。虽然存在一些瑕疵,但广泛应用于电脑行业,尤其是互联网中,从而成为一种事实上的行业标准。
BIG5 码是双字节编码方案,其中第一个字节的值在 OXAO-OXFE 之间,第二个字节在 OX40-OX7E 和OXA1-OXFE 之间。
BIG5 收录了13461个汉字和符号。
三、对比总结
-
ASCII 收录了所有的字母的大小写,各种符号,拉丁文等共256种。用1个字节代表一个字符。
-
GB2312 收录了简化汉字及符号、字母、日文假名等共 7445 个图形字符,其中汉字占 6763 个。用2个字节表示一个字符,每个字节均采用七位编码表示。
-
GBK 是中文的字符编码,共收入 21886 个汉字和图形符号。用2个字节代表一个字符。
-
GB18030 收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。采用单字节、双字节和四字节三种方式对字符编码。 向下兼容 GBK 和 GB2312 。
-
Unicode 统一了世界各国语言的不同,统一用2个字节代表一个字符,速度快,但浪费空间。可以用在内存处理中,兼容utf-8,gbk,ascii。
-
UTF-8 为了解决Unicode的浪费空间的缺点,规定1个英文字符用1个字节表示,1个中文字符用3个字节表示,节省空间,但速度慢。在硬盘数据传输,网络数据传输时,相比硬盘和网络速度,体现不出来。
-
BIG5 是通行于台湾、香港地区的一个繁体字编码方案,收录了13461个汉字和符号。用2个字节代表一个字符。
-
从ASCII、GB2312、GBK 到GB18030、Unicode、UTF-8,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。
四、编码转换
请参考文章:GBK,Unicode,UTF-8编码的相互转换
最后:
推荐阅读 编码详解(英文):https://diveintopython3.net/strings.html