这篇文章主要记录如何使用PaddlePaddle Fluid搭建对抗神经网络来生成手写数字图像集。
环境:ubuntu18.04
python版本:python2.7
目录
训练与预测
导入所需模块
创建一个文件并导入需要的python模块
#coding:utf-8
'''
created on Fabruary 15 18:01 2019
@author:lhy
'''
import numpy as np
import paddle
import paddle.fluid as fluid
import matplotlib.pyplot as plt
import time
其中matplotlib模块是为了保存图片到本地,time模块是为了记录一个pass使用的时间。
定义生成器和判别器
生成器
生成图片的对抗神经网络由生成器和判别器组合,生成器的作用是根据输入通过全连接和转置卷积等生成假图片,并让假图片尽量满足判别器的判断,让判别器认为假图片是真图片。判别器不断增强自身的判别能力,生成器不断生成越来越逼真的图片,来让判别器认为生成器的假图片是真图片,以此来欺骗判别器。其中,fluid.unique_name.guard()函数是为了初始化参数名称的时候统一名称,同样名字的参数在不同网络中默认规定是同一个参数。在使用这个网络的时候name一样就保证使用了同一套参数,同理,Generator()函数传入的name不一样,使用的参数也会不一样。这个函数的传参规定了网络中所有参数开头的名称。
生成器的网络结构如下:
#手写数字生成器,输入张量通过全连接和转置卷积和批标准化得到新的张量,转置卷积就是卷积的逆过程
def Generator(y,name='G'):
#定义一个转置卷积层
def deconv(input,num_filters,filter_size=5,stride=2,dilation=1,padding=2,output_size=None,act=None):
return fluid.layers.conv2d_transpose(input=input,num_filters=num_filters,output_size=output_size,filter_size=filter_size,stride=stride,dilation=dilation,padding=padding,act=act)
#fluid.unique_name.guard()函数是为了初始化参数名称的时候统一名称,同样名字的参数在不同网络中属于一个参数,则在使用这个网络的时候保证用的同一套参数,而且这个函数的传参可以规定网络中所有参数开头的名称
with fluid.unique_name.guard(name+'/'):
#第一组全连接层的批标准化层
y=fluid.layers.fc(y,size=2048)
y=fluid.layers.batch_norm(y)
#第二组全连接层和BN层
y=fluid.layers.fc(y,size=128*7*7)
y=fluid.layers.batch_norm(y)
#调整形状
y=fluid.layers.reshape(y,shape=(-1,128,7,7))
#第一组转置卷积
y=deconv(input=y,num_filters=128,act='relu',output_size=[14,14])
#第二组转置卷积,因为是灰度图片,所以最后的num_filter为1通道
y=deconv(input=y,num_filters=1,act='tanh',output_size=[28,28])
return y
判别器
通过判别器来判断输入的图片是真实图片还是生成器生成的假图片。判别器在训练真实数据集的时候,尽量让其输出为1,而在训练生成器生成的假图片时,尽量让输出为0,以上两个过程更新的参数只有判别器的参数,而没有更新生成器的参数。经过判别器训练后,将生成器生成的假图片通过判别器,并让判别器的label规定为1,则在保证判别器参数不变的情况下,训练更新生成器的参数,更新的方向是让生成器生成的图片越来越靠近真实图片,假图片经过判别器输出的结果越来越靠近1,也就是通过这样不断给生成器压力,以至于真实到连判别器都无法判断这是真实图像还是假图片。
判别器的网络结构如下:
#判别器,用来判断是mnist数据集还是Generator产生的数据,是mnist的话输出概率为1,是生成的话输出概率为0
def Discriminator(images,name='D'):
#定义一个卷积池化组
def conv_pool(input,num_filters,act=None):
#使用fluid中已经定义好的网络,卷积池化组
return fluid.nets.simple_img_conv_pool(input=input,filter_size=5,num_filters=num_filters,pool_size=2,pool_stride=2,act=act)
with fluid.unique_name.guard(name+'/'):
y=fluid.layers.reshape(x=images,shape=[-1,1,28,28])
#第一层卷积池化层
y=conv_pool(input=y,num_filters=64,act='leaky_relu')
#第二层卷积池化层
y=conv_pool(input=y,num_filters=128)
#回归层
y=fluid.layers.batch_norm(input=y,act='leaky_relu')
#全连接加回归层
y=fluid.layers.fc(input=y,size=1024)
y=fluid.layers.batch_norm(input=y,act='leaky_relu')
#最后一个层进行输出
y=fluid.layers.fc(input=y,size=1,act='sigmoid')
return y
定义训练程序Program
定义四个Program,前三个分别用于训练判别器识别生成器的图片、训练判别器识别真实图片、训练生成器生成符合判别器的图片。最后一个Program用于初始化参数。使用一个初始化Progarm,则参数是可以共享的,在训练的时候选择需要训练的参数进行训练。
#创建判别器D用于识别生成器G生成的假图片
train_d_fake=fluid.Program()
#创建判别器D识别真实图片程序
train_d_real=fluid.Program()
#创建生成器G生成符合判别器D的程序
train_g=fluid.Program()
#创建一个共同的一个初始化程序
startup=fluid.Program()
噪声维度、获取参数
我们设定噪声维度用来初始化生成图片。获取program中的独立参数,在训练时只训练独立参数。目的是当训练判别器识别真实图片时、或者当识别生成的图片时、他们二者相互不影响,并且不影响生成器的参数,同理在更新生成器模型参数时,不要更新判别器的模型参数。
#产生的噪声维度
z_dim=100
#为了不让一个program更新参数时影响到其他的program的参数,所以我们每次更新参数时需要获取独立参数
#从progarm中获取prefix开头的参数名字,在参数更新时只对这一部分的参数尽行更新
def get_params(program,prefix):
all_params=program.global_block().all_parameters()
return [t.name for t in all_params if t.name.startswith(prefix)]
定义三种情况的损失函数和优化器
训练判别器识别真实图片
定义一个训练器用来识别真实图片,使用的损失函数是fluid.layers.sigmoid_cross_entropy_with_logits(),函数的作用是对于给定的logits计算sigmoid的交叉熵。而sigmoid损失函数多用于分类任务上的概率误差,他们的类别是相互不排斥的,所以无论真实图片的标签是什么,都不会影响模型识别为真实图片,这里更新的参数只有判别器模型的参数,用Adam优化器。
#训练判别器D识别真实的图片,而且将真实图片识别出的label规定为1
with fluid.program_guard(train_d_real,startup):
#创建读取真实数据集的图片,并且设置真实图片的label为1
real_image=fluid.layers.data('image',shape=[1,28,28])
ones=fluid.layers.fill_constant_batch_size_like(real_image,shape=[-1,1],dtype='float32',value=1)
#使用判别器D来判断真实图片的概率
p_real=Discriminator(real_image)
#获取损失函数
real_cost=fluid.layers.sigmoid_cross_entropy_with_logits(p_real,ones)
real_avg_cost=fluid.layers.mean(real_cost)
#获取判别器D的参数
d_params=get_params(train_d_real,'D')
#创建优化方法
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=2e-4)
#只优化这个判别器使用到的参数d_params
optimizer.minimize(real_avg_cost,parameter_list=d_params)
训练判别器识别假图片(生成的图片)
这里使用噪声的维度进行输入,判别器识别的是生成器生成的图片。同样,需要更新的参数还是判别器模型的参数。
# 训练判别器D识别生成器G生成的图片为假图片,并且将生成器生成的图片的label规定为0
with fluid.program_guard(train_d_fake,startup):
#创建读取假图片的data层,并且规定假图片的label为0
z=fluid.layers.data(name='z',shape=[z_dim,1,1])
zeros=fluid.layers.fill_constant_batch_size_like(z,shape=[-1,1],dtype='float32',value=0)
#使用判断器D判断生成器D生成的假图片的概率
p_fake=Discriminator(Generator(z))
#定义损失函数
fake_cost=fluid.layers.sigmoid_cross_entropy_with_logits(p_fake,zeros)
fake_avg_cost=fluid.layers.mean(fake_cost)
#获取判别器D的参数
d_params=get_params(train_d_fake,"D")
#创建优化方法
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=2e-4)
optimizer.minimize(fake_avg_cost,parameter_list=d_params)
训练生成器生成图片
损失函数和优化方法和上面都一样,但是要更新的参数是生成器的模型参数。
#训练生成器G生成符合判别器标准的假图片
with fluid.program_guard(train_g,startup):
#data层接受噪声生成的向量,也就是假图片,label为1
z=fluid.layers.data(name='z',shape=[z_dim,1,1])
ones=fluid.layers.fill_constant_batch_size_like(z,shape=[-1,1],dtype='float32',value=1)
#生成图片
fake=Generator(z)
#克隆出一个预测程序
infer_program=train_g.clone(for_test=True)
#将生成的假图片通过判别器,获得真假图片的概率
p=Discriminator(fake)
#获取损失函数
g_cost=fluid.layers.sigmoid_cross_entropy_with_logits(p,ones)
g_avg_cost=fluid.layers.mean(g_cost)
#因为只对生成器进行参数更新,获取生成器的参数
g_params=get_params(train_g,'G')
#只训练生成器G
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=2e-4)
optimizer.minimize(g_avg_cost,parameter_list=g_params)
训练并预测
通过正则分布来生成假的图片输入。
#通过噪声进行数据进行数据生成
def z_reader():
while True:
yield np.random.normal(0.0,1.0,(z_dim,1,1)).astype('float32')#返回一个标准化正则分布的向量
#因为这里设置的均值为0,标准差为1,是标准化的正则分布,所以说np.random.randn(size)对应于np.random.normal(loc=0,scale=1,size)
读取真实图片的数据集,去除label中的数据。
#读取真实数据集mnist中的数据图片,去除label数据
def mnist_reader(reader):
def r():
for img,label in reader():
yield img.reshape(1,28,28)
return r
保存生成的图片到本地。
#将预测好的图片保存到本地目录
def show_image_grid(images,pass_id=None):
for i ,image in enumerate(images[:64]):#保存64张照片看看效果
plt.imsave("images%d/test_%d.png"%(pass_id,i),image[0])
将真实数据和噪声生成的数据生成reader()
#生成真实图片的reader
mnist_generator=paddle.batch(paddle.reader.shuffle(mnist_reader(paddle.dataset.mnist.train()),30000),batch_size=128)
#生成假图片的reader,返回的是一个生成器
z_generator=paddle.batch(z_reader,batch_size=128)()
创建执行器,初始化参数。
#创建一个执行器,一如既往地用CPU进行训练,虽然我知道训练速度很慢,但是虚拟机没有装CUDA
place=fluid.CPUPlace()
#place=fluid.CUDAPlace(0)
exe=fluid.Executor(place)
#初始化参数
exe.run(startup)
获取需要测试的噪声数据,用这些数据进行预测。
#测试噪声数据
test_z=np.array(next(z_generator))#通过next方法读取生成器中返回的数据
开始训练:
#开始训练
for pass_id in range(5):
start_time=time.time()
for i,real_image in enumerate(mnist_generator()):
#训练判别器D识别生成器G生成的假图片
r_fake=exe.run(program=train_d_fake,fetch_list=[fake_avg_cost],feed={'z':np.array(next(z_generator))})
#训练判别器D识别真实的图片
r_real=exe.run(program=train_d_real,fetch_list=[real_avg_cost],feed={'image':np.array(real_image)})
#训练生成器G生成符合判别器D的标准图片
r_g=exe.run(program=train_g,fetch_list=[g_avg_cost],feed={'z':np.array(next(z_generator))})
print("Pass:%d,fake_avg_cost:%f,real_acg_cost:%f,g_avg_cost:%f"%(pass_id,r_fake[0][0],r_real[0][0],r_g[0][0]))
#测试生成的图片
r_i=exe.run(program=infer_program,fetch_list=[fake],feed={'z':test_z})
#存储生成的图片
show_image_grid(r_i[0],pass_id)
end_time=time.time()
one_pass_time=end_time-start_time
print("This pass has taken %fs"%(one_pass_time))
运行结果
输出信息
Pass:0,fake_avg_cost:0.754691,real_acg_cost:0.388661,g_avg_cost:0.648452
This pass has taken 1423.093183s
Pass:1,fake_avg_cost:0.745169,real_acg_cost:0.389193,g_avg_cost:0.630191
This pass has taken 1395.344459s
Pass:2,fake_avg_cost:0.735933,real_acg_cost:0.364998,g_avg_cost:0.654820
This pass has taken 1408.409146s
Pass:3,fake_avg_cost:0.775802,real_acg_cost:0.370385,g_avg_cost:0.647010
This pass has taken 1391.969991s
Pass:4,fake_avg_cost:0.718073,real_acg_cost:0.376971,g_avg_cost:0.667307
This pass has taken 1397.473701s
一个pass要了1400秒。。。
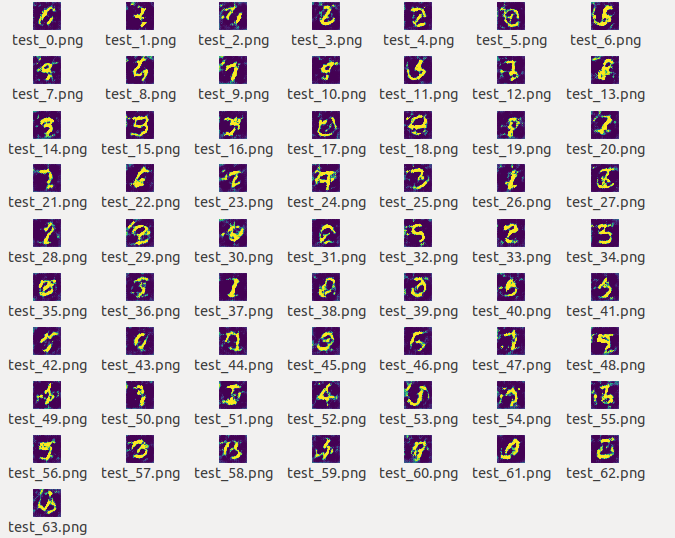
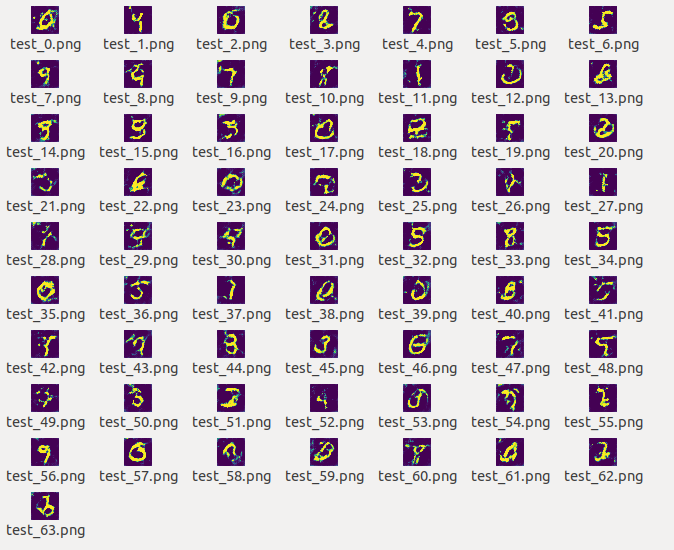
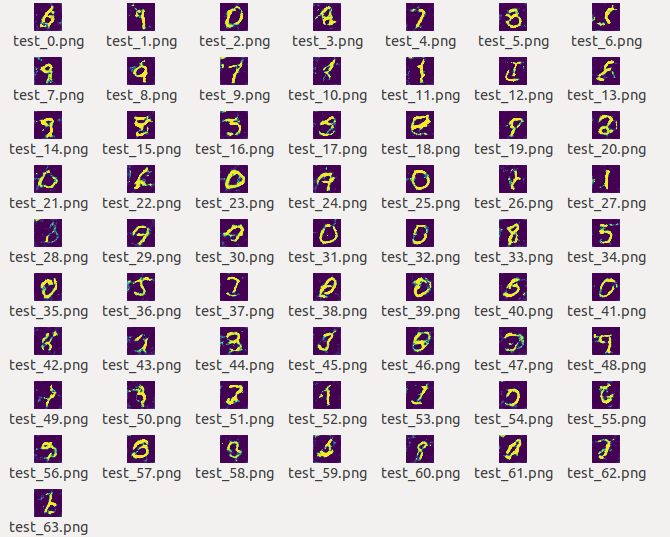
生成的图片
以下按照顺序贴出1-5个pass生成的图片。
第一个pass结束:
第二个pass结束:
第三个pass结束:
第四个pass结束:
第五个pass结束:
可以看到,生成的图片清晰度和轮廓随着pass的增加越来越好。


全部代码
#coding:utf-8
'''
created on Fabruary 15 18:01 2019
@author:lhy
'''
import numpy as np
import paddle
import paddle.fluid as fluid
import matplotlib.pyplot as plt
import time
#手写数字生成器,输入张量通过全连接和转置卷积和批标准化得到新的张量,就是卷积的逆过程
def Generator(y,name='G'):
#定义一个转置卷积层
def deconv(input,num_filters,filter_size=5,stride=2,dilation=1,padding=2,output_size=None,act=None):
return fluid.layers.conv2d_transpose(input=input,num_filters=num_filters,output_size=output_size,filter_size=filter_size,stride=stride,dilation=dilation,padding=padding,act=act)
#fluid.unique_name.guard()函数是为了初始化参数名称的时候统一名称,同样名字的参数在不同网络中属于一个参数,则在使用这个网络的时候保证用的同一套参数,而且这个函数的传参可以规定神经网络中参数开头的名称
with fluid.unique_name.guard(name+'/'):
#第一组全连接层的批标准化层
y=fluid.layers.fc(y,size=2048)
y=fluid.layers.batch_norm(y)
#第二组全连接层和BN层
y=fluid.layers.fc(y,size=128*7*7)
y=fluid.layers.batch_norm(y)
#调整形状
y=fluid.layers.reshape(y,shape=(-1,128,7,7))
#第一组转置卷积
y=deconv(input=y,num_filters=128,act='relu',output_size=[14,14])
#第二组转置卷积
y=deconv(input=y,num_filters=1,act='tanh',output_size=[28,28])
return y
#判别器,用来判断是mnist数据集还是Generator产生的数据,是mnist的话输出概率为1,是生成的话输出概率为0
def Discriminator(images,name='D'):
#定义一个卷积池化组
def conv_pool(input,num_filters,act=None):
#使用fluid中已经定义好的网络,卷积池化组
return fluid.nets.simple_img_conv_pool(input=input,filter_size=5,num_filters=num_filters,pool_size=2,pool_stride=2,act=act)
with fluid.unique_name.guard(name+'/'):
y=fluid.layers.reshape(x=images,shape=[-1,1,28,28])
#第一层卷积池化层
y=conv_pool(input=y,num_filters=64,act='leaky_relu')
#第二层卷积池化层
y=conv_pool(input=y,num_filters=128)
#回归层
y=fluid.layers.batch_norm(input=y,act='leaky_relu')
#全连接加回归层
y=fluid.layers.fc(input=y,size=1024)
y=fluid.layers.batch_norm(input=y,act='leaky_relu')
#最后一个层进行分类输出
y=fluid.layers.fc(input=y,size=1,act='sigmoid')
return y
#创建判别器D用于识别生成器G生成的假图片
train_d_fake=fluid.Program()
#创建判别器D识别真实图片程序
train_d_real=fluid.Program()
#创建生成器G生成符合判别器D的程序
train_g=fluid.Program()
#创建一个共同的一个初始化程序
startup=fluid.Program()
#产生的噪声维度
z_dim=100
#为了不让program更新参数时影响到其他的program的参数,所以我们每次更新参数时需要获取独立参数
#从progarm中获取prefix开头的参数名字,在参数更新时只对这一部分的参数尽行更新
def get_params(program,prefix):
all_params=program.global_block().all_parameters()
return [t.name for t in all_params if t.name.startswith(prefix)]
#训练判别器D识别真实的图片,而且将真实图片识别出的label规定为1
with fluid.program_guard(train_d_real,startup):
#创建读取真实数据集的图片,并且设置真实图片的label为1
real_image=fluid.layers.data('image',shape=[1,28,28])
ones=fluid.layers.fill_constant_batch_size_like(real_image,shape=[-1,1],dtype='float32',value=1)
#使用判别器D来判断真实图片的概率
p_real=Discriminator(real_image)
#获取损失函数
real_cost=fluid.layers.sigmoid_cross_entropy_with_logits(p_real,ones)
real_avg_cost=fluid.layers.mean(real_cost)
#获取判别器D的参数
d_params=get_params(train_d_real,'D')
#创建优化方法
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=2e-4)
#只优化这个判别器使用到的参数d_params
optimizer.minimize(real_avg_cost,parameter_list=d_params)
# 训练判别器D识别生成器G生成的图片为假图片,并且将生成器生成的图片的label规定为0
with fluid.program_guard(train_d_fake,startup):
#创建读取假图片的data层,并且规定假图片的label为0
z=fluid.layers.data(name='z',shape=[z_dim,1,1])
zeros=fluid.layers.fill_constant_batch_size_like(z,shape=[-1,1],dtype='float32',value=0)
#使用判断器D判断生成器D生成的假图片的概率
p_fake=Discriminator(Generator(z))
#定义损失函数
fake_cost=fluid.layers.sigmoid_cross_entropy_with_logits(p_fake,zeros)
fake_avg_cost=fluid.layers.mean(fake_cost)
#获取判别器D的参数
d_params=get_params(train_d_fake,"D")
#创建优化方法
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=2e-4)
optimizer.minimize(fake_avg_cost,parameter_list=d_params)
#训练生成器G生成符合判别器标准的假图片
with fluid.program_guard(train_g,startup):
#data层接受噪声生成的向量,也就是假图片,label为1
z=fluid.layers.data(name='z',shape=[z_dim,1,1])
ones=fluid.layers.fill_constant_batch_size_like(z,shape=[-1,1],dtype='float32',value=1)
#生成图片
fake=Generator(z)
#克隆出一个预测程序
infer_program=train_g.clone(for_test=True)
#将生成的假图片通过判别器,获得真假图片的概率
p=Discriminator(fake)
#获取损失函数
g_cost=fluid.layers.sigmoid_cross_entropy_with_logits(p,ones)
g_avg_cost=fluid.layers.mean(g_cost)
#因为只对生成器进行参数更新,获取生成器的参数
g_params=get_params(train_g,'G')
#只训练生成器G
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=2e-4)
optimizer.minimize(g_avg_cost,parameter_list=g_params)
#通过噪声进行数据进行数据生成
def z_reader():
while True:
yield np.random.normal(0.0,1.0,(z_dim,1,1)).astype('float32')#返回一个标准化正则分布的向量
#因为这里设置的均值为0,标准差为1,所以是标准化的正则分布,所以说np.random.randn(size)对应于np.random.normal(loc=0,scale=1,size)
#读取真实数据集mnist中的数据图片,去除label数据
def mnist_reader(reader):
def r():
for img,label in reader():
yield img.reshape(1,28,28)
return r
#将预测好的图片保存到本地目录
def show_image_grid(images,pass_id=None):
for i ,image in enumerate(images[:64]):#保存64张照片看看效果
plt.imsave("images%d/test_%d.png"%(pass_id,i),image[0])
#生成真实图片的reader
mnist_generator=paddle.batch(paddle.reader.shuffle(mnist_reader(paddle.dataset.mnist.train()),30000),batch_size=128)
#生成假图片的reader,返回的是一个生成器
z_generator=paddle.batch(z_reader,batch_size=128)()
#创建一个执行器,一如既往地用CPU进行训练,虽然我知道训练速度很慢,但是虚拟机没有CUDA
place=fluid.CPUPlace()
#place=fluid.CUDAPlace(0)
exe=fluid.Executor(place)
#初始化参数
exe.run(startup)
#测试噪声数据
test_z=np.array(next(z_generator))#通过next方法读取生成器中返回的数据
#开始训练
for pass_id in range(5):
start_time=time.time()
for i,real_image in enumerate(mnist_generator()):
#训练判别器D识别生成器G生成的假图片
r_fake=exe.run(program=train_d_fake,fetch_list=[fake_avg_cost],feed={'z':np.array(next(z_generator))})
#训练判别器D识别真实的图片
r_real=exe.run(program=train_d_real,fetch_list=[real_avg_cost],feed={'image':np.array(real_image)})
#训练生成器G生成符合判别器D的标准图片
r_g=exe.run(program=train_g,fetch_list=[g_avg_cost],feed={'z':np.array(next(z_generator))})
print("Pass:%d,fake_avg_cost:%f,real_acg_cost:%f,g_avg_cost:%f"%(pass_id,r_fake[0][0],r_real[0][0],r_g[0][0]))
#测试生成的图片
r_i=exe.run(program=infer_program,fetch_list=[fake],feed={'z':test_z})
#存储生成的图片
show_image_grid(r_i[0],pass_id)
end_time=time.time()
one_pass_time=end_time-start_time
print("This pass has taken %fs"%(one_pass_time))