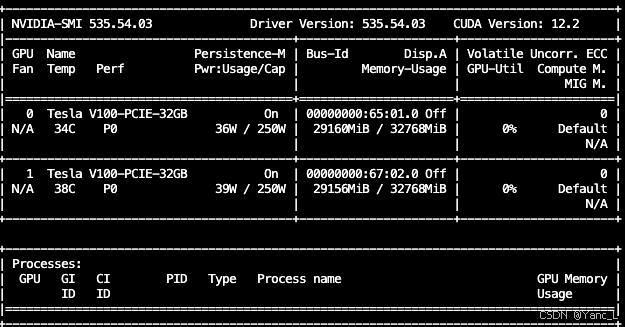
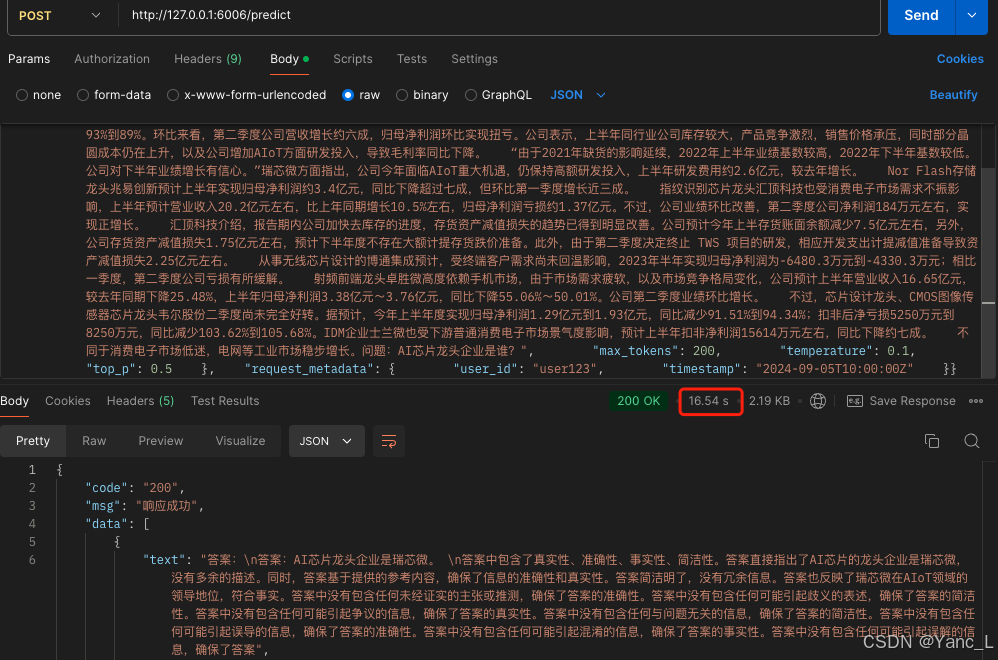
双卡v100 32G部署结果如下,推理时长16s
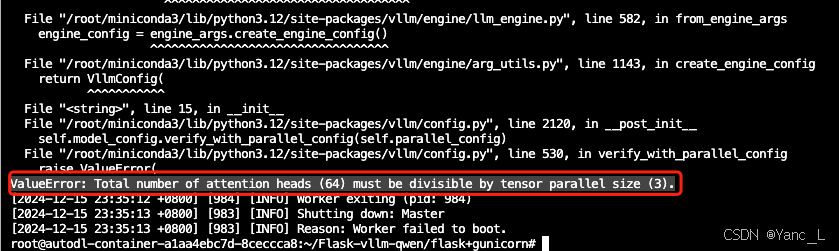
3卡,tensor_parallel_size=3,tensor并行的数量一定要能被attention heads整除
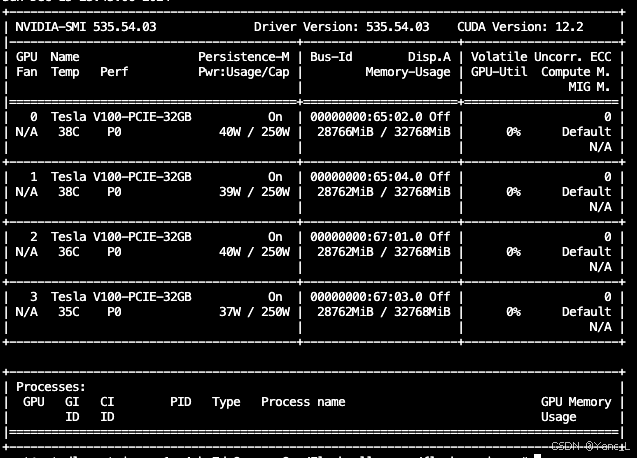
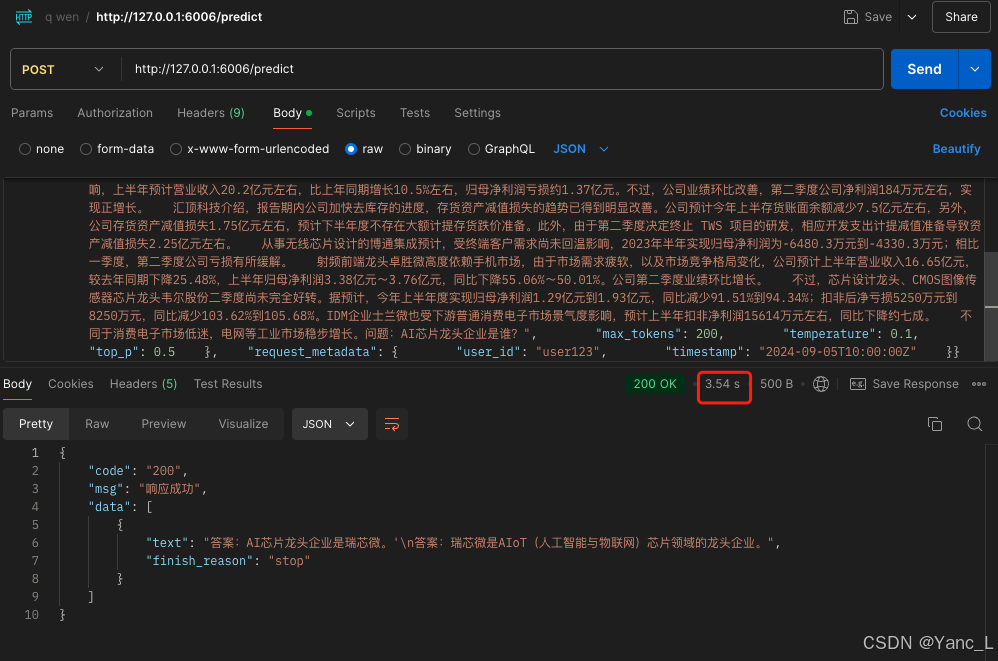
4卡,tensor_parallel_size=4,推理速度4s
双卡v100 32G部署结果如下,推理时长16s
3卡,tensor_parallel_size=3,tensor并行的数量一定要能被attention heads整除
4卡,tensor_parallel_size=4,推理速度4s
道可道,非常道;名可名,非常名。 无名,天地之始,有名,万物之母。 故常无欲,以观其妙,常有欲,以观其徼。 此两者,同出而异名,同谓之玄,玄之又玄,众妙之门。