论文链接
开源代码链接
论文阅读
摘要
Abstract—Leveraging vast training data (SA-1B), the foundation Segment Anything Model (SAM) proposed by Meta AI Research exhibits remarkable generalization and zero-shot capabilities. Nonetheless, as a category-agnostic instance segmentation method, SAM heavily depends on prior manual guidance involving points, boxes, and coarse-grained masks. Additionally, its performance on remote sensing image segmentation tasks has yet to be fully explored and demonstrated. In this paper, we consider designing an automated instance segmentation approach for remote sensing images based on the SAM foundation model, incorporating semantic category information. Inspired by prompt learning, we propose a method to learn the generation of appropriate prompts for SAM input. This enables SAM to produce semantically discernible segmentation results for remote sensing images, which we refer to as RSPrompter. We also suggest several ongoing derivatives for instance segmentation tasks, based on recent developments in the SAM community, and compare their performance with RSPrompter. Extensive experimental results on the WHU building, NWPU VHR-10, and SSDD datasets validate the efficacy of our proposed method. Our code is accessible at https://kyanchen.github.io/RSPrompter.
摘要-利用大量训练数据(SA-1B),Meta-AI Research提出的基础分段任意模型(SAM)具有显著的泛化能力和零样本能力。尽管如此,作为一种类别不可知的实例分割方法,SAM在很大程度上依赖于之前涉及点、框和粗粒度掩码的手动指导。此外,它在遥感图像分割任务中的性能还有待充分探索和证明。在本文中,我们考虑设计一种基于SAM基础模型的遥感图像自动实例分割方法,结合语义类别信息。受即时学习的启发,我们提出了一种方法来学习SAM输入的适当提示的生成。这使得SAM能够为遥感图像产生语义上可辨别的分割结果,我们称之为RSPrompter。根据最近的发展,我们还根据SAM社区的最新发展,提出了几个正在进行的衍生工具,例如分割任务,并将其性能与RSPrompter进行了比较。

引言
Deep learning algorithms have exhibited remarkable potential in instance segmentation for remote sensing images, demonstrating their ability to extract deep, discernible features from raw data [16–19]. Presently, the primary instance segmentation algorithms comprise two-stage R-CNN series algorithms (e.g., Mask R-CNN [20], Cascade Mask R-CNN [21], Mask Scoring R-CNN [22], HTC [23], and HQ-ISNet [1]), as well as one-stage algorithms (e.g., YOLACT [24], BlendMask [25], EmbedMask [26], Condinst [27], SOLO [28], and Mask2former [29]). However, the complexity of remote sensing image backgrounds and the diversity of scenes limit the generalization and adaptability of these algorithms.Therefore, devising instance segmentation models capable of
深度学习算法在遥感图像分割方面表现出了显著的潜力,证明了它们从原始数据中提取深层可辨别特征的能力[16-19]。目前,主要实例分割算法包括两阶段R-CNN系列算法(例如,Mask R-CNN[20]、Cascade Mask R-CNN[21]、Mask Scoring R-CNN[22]、HTC[23]和HQ ISNet[1]),以及一阶段算法(例如YOLACT[24]、BlendMask[25]、EmbedMask[26]、Condinst[27]、SOLO[28]和Mask2former[29])。然而,遥感图像背景的复杂性和场景的多样性限制了这些算法的通用性和适应性。
In recent years, substantial progress has been made in foundation models, such as GPT-4 [30], Flamingo [31], and SAM [32], significantly contributing to the advancement of human society. Despite remote sensing being characterized by its big data attributes since its inception [11, 33], foundation models tailored for this field have not yet emerged. In this paper, our primary aim is not to develop a universal foundation model for remote sensing, but rather to explore the applicability of the SAM segmentation foundation model from the computer vision domain to instance segmentation in remote sensing imagery. We anticipate that such foundation models will foster the continued growth and progress of the remote sensing field
近年来,基础模型取得了实质性进展,如GPT-4[30]、Flamingo[31]和SAM[32],为人类社会的进步做出了重大贡献。尽管遥感自诞生以来就以其大数据属性为特征[11,33],但为该领域量身定制的基础模型尚未出现。在本文中,我们的主要目的不是开发一个通用的遥感基础模型,而是探索SAM分割基础模型从计算机视觉领域到遥感图像实例分割的适用性。我们预计,这些基础模型将促进遥感领域的持续增长和进步。
Since SAM is a category-agnostic segmentation model, the deep feature maps of the image encoder are unlikely to contain rich semantic category information. To overcome this, we extract features from the intermediate layers of the encoder to form the input of the prompter, which generates prompts containing semantic category information. Secondly, SAM prompts include points (foreground/background points), boxes, or masks. Considering that generating point coordinates requires searching in the original SAM prompt’s manifold, which greatly limits the optimization space of the prompter, we further relax the representation of prompts and directly generate prompt embeddings, which can be understood as the embeddings of points or boxes, instead of the original coordinates. This design also avoids the obstacle of gradient flow from high-dimensional to low-dimensional and then back to high-dimensional features, i.e., from high-dimension image features to point coordinates and then to positional encodings.
由于SAM是一个类别不可知的分割模型,图像编码器的深度特征图不太可能包含丰富的语义类别信息。为了克服这一点,我们从编码器的中间层提取特征,以形成提示器的输入,提示器生成包含语义类别信息的提示。其次,SAM提示包括点(前景/背景点)、框或掩膜。考虑到生成点坐标需要在原始SAM提示的流形中搜索,这大大限制了提示器的优化空间,我们进一步放宽了提示的表示,直接生成提示嵌入,可以理解为点或框的嵌入,而不是原始坐标。这种设计还避免了从高维到低维再回到高维特征的梯度流障碍,即从高维图像特征到点坐标然后再到位置编码。
本文还对 SAM 模型社区中当前进展和衍生方法进行了全面的调查和总结。这些主要包括基于 SAM 骨干网络的方法、将 SAM 与分类器集成的方法和将 SAM 与检测器结合的技术。
相关工作
基于深度学习的实例分割
The objective of instance segmentation is to identify the location of each target instance within an image and provide a corresponding semantic mask, making this task more challenging than object detection and semantic segmentation [18, 38]. Current deep learning-based instance segmentation approaches can be broadly categorized into two-stage and single-stage methods. The former primarily builds on the Mask R-CNN [20] series, which evolved from the two-stage Faster R-CNN [39] object detector by incorporating a parallel mask prediction branch. As research advances, an increasing number of researchers are refining this framework to achieve improved performance. PANet [16] streamlines the information path between features by introducing a bottom-up path based on FPN [40]. In HTC [23], a multi-task, multi-stage hybrid cascade structure is proposed, and the spatial context is enhanced by integrating the segmentation branch, resulting in significant performance improvements over Mask R-CNN and Cascade Mask R-CNN [21]. The Mask Scoring R-CNN [22] incorporates a mask IoU branch within the Mask R-CNN framework to assess segmentation quality. The HQ-ISNet [1] introduces an instance segmentation method for remote sensing imagery based on Cascade Mask R-CNN, which fully leverages multi-level feature maps and preserves the detailed information contained within high-resolution images
实例分割的目标是识别图像中每个目标实例的位置,并提供相应的语义掩码,这使得该任务比目标检测和语义分割更具挑战性[18,38]。目前基于深度学习的实例分割方法大致可分为两阶段和单阶段方法。前者主要建立在Mask R-CNN[20]系列的基础上,该系列由两级Faster R-CNN[39]目标检测器演变而来,加入了并行掩模预测分支。随着研究的进展,越来越多的研究人员正在改进这个框架以提高性能。PANet[16]通过引入基于FPN的自下而上路径,简化了特征之间的信息路径[40]。在HTC[23]中,提出了一种多任务、多阶段的混合级联结构,并通过整合分割分支来增强空间语境,使得性能比Mask R-CNN和cascade Mask R-CNN有了明显的提高[21]。Mask Scoring R-CNN[22]在Mask R-CNN框架中加入了一个Mask IoU分支来评估分割质量。HQ-ISNet[1]引入了一种基于Cascade Mask R-CNN的遥感图像实例分割方法,该方法充分利用了多层次特征图,并保留了高分辨率图像中包含的详细信息
Though two-stage methods can yield refined segmentation results, achieving the desired latency in terms of segmentation speed remains challenging. With the growing popularity of single-stage object detectors, numerous researchers have endeavored to adapt single-stage object detectors for instance segmentation tasks. YOLACT [24], for example, approaches the instance segmentation task by generating a set of prototype masks and predicting mask coefficients for each instance.CondInst [27] offers a fresh perspective on the instance segmentation problem by employing a dynamic masking head.This novel approach has outperformed existing methods like Mask R-CNN in terms of instance segmentation performance.SOLO [28] formulates the instance segmentation problem as predicting semantic categories and generating instance masks for each pixel in the feature map. With the widespread adoption of Transformers [41], DETR [42] has emerged as a fully 3 end-to-end object detector. Drawing inspiration from the task modeling and training procedures used in DETR, Maskformer [43] treats segmentation tasks as mask classification problems, but it suffers from slow convergence speed. Mask2former [29] introduces masked attention to confine cross-attention to the foreground region, significantly improving network training speed
虽然两阶段方法可以产生精确的分割结果,但在分割速度方面实现所需的延迟仍然具有挑战性。随着单阶段目标检测器的日益普及,许多研究人员致力于将单阶段目标检测器用于实例分割任务。例如,YOLACT[24]通过生成一组原型掩码并预测每个实例的掩码系数来处理实例分割任务。CondInst[27]通过使用动态掩蔽头,为实例分割问题提供了一个新的视角。这种新颖的方法在实例分割性能方面优于现有的方法,如Mask R-CNN。
SOLO[28]将实例分割问题表述为预测语义类别并为特征图中的每个像素生成实例掩码。随着变压器[41]的广泛采用,DETR[42]已经成为一个完整的端到端对象检测器。Maskformer[43]从DETR中使用的任务建模和训练过程中获得灵感,将分割任务视为掩模分类问题,但其收敛速度较慢。Mask2former[29]引入了屏蔽注意,将交叉注意限制在前景区域,显著提高了网络的训练速度
Prompt Learning
For many years, machine learning tasks primarily focused on fully supervised learning, where in task-specific models were trained solely on labeled examples of the target task [63, 64]. Over time, the learning of these models has undergone a significant transformation, shifting from fully supervised learning to a “pre-training and fine-tuning” paradigm for downstream tasks. This allows models to utilize the general features obtained during pre-training [65–68]. As the field has evolved, the “pre-training and fine-tuning” approach is being increasingly replaced with a “pre-training and prompting” paradigm [61, 62, 69–72]. In this new paradigm, researchers no longer adapt the model exclusively to downstream tasks but rather redesign the input using prompts to reconstruct downstream tasks to align with the original pre-training task
多年来,机器学习任务主要集中于完全监督学习,其中特定于任务的模型仅在目标任务的标记示例上进行训练[63,64]。随着时间的推移,这些模型的学习经历了重大转变,从完全监督学习转变为下游任务的“预训练和微调”范式。这允许模型利用预训练期间获得的一般特征[65-68]。随着该领域的发展,“预训练和微调”方法正日益被“预训练和提示”范式所取代[61,62,69 - 72]。在这个新范式中,研究人员不再将模型专门用于下游任务,而是使用提示重新设计输入,以重构下游任务,使其与原始的预训练任务保持一致。
Prompt learning can help reduce semantic differences (bridging the gap between pre-training and fine-tuning) and prevent overfitting of the head. Since the introduction of GPT-3 [55], prompt learning has progressed from traditional discrete [71] and continuous prompt construction [61, 72] to largescale model-oriented in-context learning [31], instructiontuning [73–75], and chain-of-thought approaches [76–78].Current methods for constructing prompts mainly involve manual templates, heuristic-based templates, generation, word embedding fine-tuning, and pseudo tokens [71, 79]. In this paper, we propose a prompt generator that generates SAMcompatible prompt inputs. This prompt generator is categoryrelated and produces semantic instance segmentation results
提示学习有助于减少语义差异(弥合预训练和微调之间的差距),并防止头部过拟合。自从引入GPT-3[55]以来,提示学习已经从传统的离散[71]和连续提示构建[61,72]发展到大规模的面向模型的上下文学习[31]、指令调整[73-75]和思维链方法[76-78]。目前构建提示符的方法主要包括手动模板、启发式模板、生成、词嵌入微调和伪标记[71,79]。在本文中,我们提出了一个生成sam兼容提示输入的提示生成器。这个提示生成器与类别相关,并产生语义实例分割结果。
方法
In this section, we will present our proposed RSPrompter, a learning-to-prompt method based on the SAM framework for remote sensing image instance segmentation. We will cover the following aspects: revisiting SAM, incorporating simple extensions to tailor SAM for the instance segmentation task, and introducing both anchor-based and query-based RSPrompter along with their respective loss functions
在本节中,我们将介绍我们提出的RSPrompter,这是一种基于SAM框架的遥感图像实例分割学习提示方法。我们将介绍以下几个方面:重新审视SAM,结合简单的扩展来为实例分割任务定制SAM,介绍基于锚点和基于查询的RSPrompter及其各自的损失函数。
1、重新审视SAM
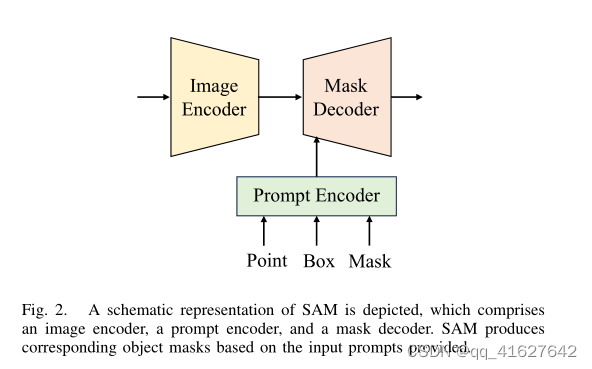
SAM is an interactive segmentation framework that generates segmentation results based on given prompts, such as foreground/background points, bounding boxes, or masks. It comprises three main components: an image encoder (Φi-enc), a prompt encoder (Φp-enc), and a mask decoder (Φm-dec). SAM employs a pre-trained Masked AutoEncoder (MAE) [60] based on Vision Transformer (ViT) [80] to process images into intermediate features, and encodes the prior prompts as embedding tokens. Subsequently, the cross-attention mechanism within the mask decoder facilitates the interaction between image features and prompt embeddings, ultimately resulting in a mask output. This process can be illustrated in Fig. 2 and expressed as:
SAM是一个交互式分割框架,它根据给定的提示(如前景/背景点、边界框或掩码)生成分割结果。它由三个主要组件组成:图像编码器(Φi-enc)、提示编码器(Φp-enc)和掩码解码器(Φm-dec)。SAM采用基于视觉转换器(Vision Transformer, ViT)[80]的预训练掩码自动编码器(mask AutoEncoder, MAE)[60]将图像处理成中间特征,并将先前的prompt编码为嵌入Tokens。随后,掩码解码器内部的交叉注意机制促进了图像特征与提示嵌入之间的交互,最终产生掩码输出。该过程如图2所示,表示为:
描述了SAM的示意图,它包括一个图像编码器、一个提示编码器和一个掩码解码器。SAM根据提供的输入提示生成相应的对象掩码。
where I ∈ RH×W ×3 represents the original image, Fimg ∈ Rh×w×c denotes the intermediate image features, {p} encompasses the sparse prompts including foreground/background points and bounding boxes, and Tprompt ∈ Rk×c signifies the sparse prompt tokens encoded by Φp-enc. Additionally, Fc-mask ∈ Rh×w×c refers to the representation from the coarse mask, which is an optional input for SAM, while Tout ∈ R5×c consists of the pre-inserted learnable tokens representing four different masks and their corresponding IoU predictions. Finally, M corresponds to the predicted masks.In this task, diverse outputs are not required, so we directly select the first mask as the final prediction
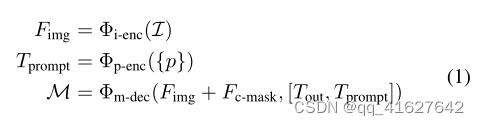
其中 I ∈ R H × W × 3 \mathcal{I} \in \mathbb{R}^{H \times W \times 3} I∈RH×W×3表示原始图像, F img ∈ R h × w × c F_{\text {img }} \in \mathbb{R}^{h \times w \times c} Fimg ∈Rh×w×c表示中间图像特征,{p}包含包括前景/背景点和边界框的稀疏提示, T prompt ∈ R k × c T_{\text {prompt }} \in \mathbb{R}^{k \times c} Tprompt ∈Rk×c表示 Φ p -enc \Phi_{\mathrm{p} \text {-enc }} Φp-enc 编码的稀疏提示令符。此外, F c-mask ∈ R h × w × c F_{\text {c-mask }} \in \mathbb{R}^{h \times w \times c} Fc-mask ∈Rh×w×c是来自粗掩码的表示,这是SAM的可选输入,而 T out ∈ R 5 × c T_{\text {out }} \in \mathbb{R}^{5 \times c} Tout ∈R5×c由预插入的可学习令牌组成,表示四个不同的掩码及其相应的IoU预测。最后,M对应于预测掩码。在这个任务中,不需要不同的输出,所以我们直接选择第一个掩码作为最终预测。
2、SAM实例分割的扩展
We have conducted a survey within the SAM community and, in addition to the RSPrompter proposed in this paper, have also introduced three other SAM-based instance segmentation methods for comparison, as shown in Fig. 3 (a), (b), and ©, to assess their effectiveness in remote sensing image instance segmentation tasks and inspire future research. These methods include: an external instance segmentation head, classifying mask categories, and using detected object boxes, which correspond to Fig. 3 (a), (b), and ©, respectively. In the following sections, we will refer to these methods as SAMseg, SAM-cls, and SAM-det, respectively
我们在SAM社区内进行了调查,除了本文提出的RSPrompter之外,我们还介绍了另外三种基于SAM的实例分割方法进行比较,如图3 (a)、(b)和©所示,以评估它们在遥感图像实例分割任务中的有效性,并为未来的研究提供启发。这些方法包括:外部实例分割头、对掩码类别进行分类、使用检测到的目标框,分别对应图3 (a)、(b)、©。在接下来的部分中,我们将分别将这些方法称为SAMseg、SAM-cls和SAM-det。
Fig. 3. From left to right, the figure illustrates SAM-seg, SAM-cls, SAM-det, and RSPrompter as alternative solutions for applying SAM to remote sensing image instance segmentation tasks. (a) An instance segmentation head is added after SAM’s image encoder. (b) SAM’s “everything” mode generates masks for all objects in an image, which are subsequently classified into specific categories by a classifier. © Object bounding boxes are first produced by an object detector and then used as prior prompts input to SAM to obtain the corresponding masks. (d) The proposed RSPrompter in this paper creates category-relevant prompt embeddings for instant segmentation masks. The snowflake symbol in the figure signifies that the model parameters in this part are kept frozen.
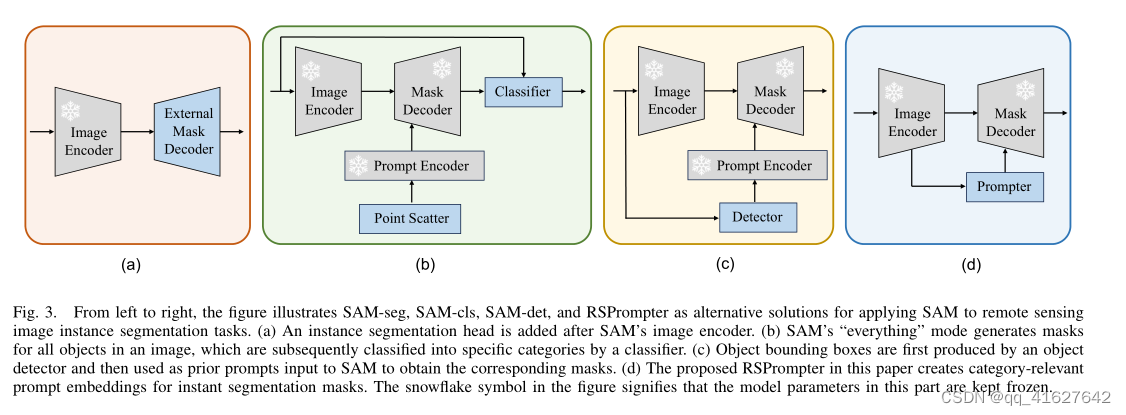
图3。从左到右,该图说明了SAM seg、SAM cls、SAM det和RSPrompter作为将SAM应用于遥感图像实例分割任务的替代解决方案。(a) 在SAM的图像编码器之后添加了一个实例分割头。(b) SAM的“一切”模式为图像中的所有对象生成掩码,这些对象随后由分类器分类为特定类别。(c) 对象边界框首先由对象检测器产生,然后用作SAM的先前提示输入以获得相应的掩码。(d) 本文中提出的RSpromoter为即时分割掩码创建了与类别相关的提示嵌入。图中的雪花符号表示该部分中的模型参数保持冻结状态。
1)SAM-seg:
In SAM-seg, we make use of the knowledge present in SAM’s image encoder while maintaining the cumbersome encoder frozen. We extract intermediatelayer features from the encoder, conduct feature fusion using convolutional blocks, and then perform instance segmentation tasks with existing instance segmentation heads, such as Mask R-CNN [20] and Mask2Former [29]. This process can be described using the following equations:
在SAM-seg中,我们利用SAM图像编码器中存在的知识,同时保持笨重的编码器冻结。我们从编码器中提取中间层特征,使用卷积块进行特征融合,然后使用现有的实例分割头(如Mask R-CNN[20]和Mask2Former[29])执行实例分割任务。这个过程可以用下面的方程来描述:
where {Fi} ∈ Rk×h×w×c, i ∈ {1, · · · , k} represents multilayer semantic feature maps from the ViT backbone. DownConv refers to a 1 × 1 convolution operation that reduces channel dimensions, while [·] denotes concatenation alongside the channel axis. FusionConv is a stack of three convolutional layers with 3×3 kernels and a ReLU activation following each layer. Φext-dec represents the externally inherited instance segmentation head, such as Mask R-CNN [20] and Mask2Former [29]. It is important to note that the image encoder remains frozen, and this training method does not utilize multi-scale loss supervision, as in Mask R-CNN and Mask2Former
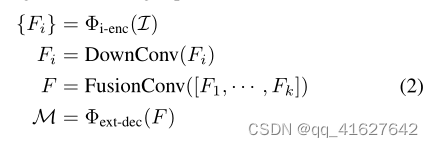
其中 { F i } ∈ R k × h × w × c , i ∈ { 1 , ⋯ , k } \left\{F_i\right\} \in \mathbb{R}^{k \times h \times w \times c}, i \in\{1, \cdots, k\} {Fi}∈Rk×h×w×c,i∈{1,⋯,k}表示来自ViT主干的多层语义特征映射。DownConv指的是一个1 × 1的卷积操作,它减少了通道的尺寸,而[·]表示沿着通道轴进行串联。FusionConv是一个由三个卷积层组成的堆栈,每个层都有3×3内核和一个ReLU激活。 Φ ext-dec \Phi_{\text {ext-dec }} Φext-dec 表示外部继承的实例分割头,如Mask R-CNN[20]和Mask2Former[29]。值得注意的是,图像编码器保持冻结状态,并且这种训练方法不像在Mask R-CNN和Mask2Former中那样使用多尺度损失监督。
2) SAM-cls:
In SAM-cls, we first utilize the “everything” mode of SAM to segment all potential instance targets within the image. Internally, this is achieved by uniformly scattering 5 points throughout the image and treating each point as a prompt input for an instance. After obtaining the masks of all instances in the image, we can assign labels to each mask using a classifier. This process can be described as follows:
在SAM-cls中,我们首先利用SAM的“一切”模式来分割图像中所有潜在的实例目标。在内部,这是通过在整个图像中均匀散射5个点并将每个点视为实例的提示输入来实现的。在获得图像中所有实例的掩码后,我们可以使用分类器为每个掩码分配标签。这个过程可以描述如下:
where (xi, yj) represents the point prompt. For every image, we consider 32 × 32 points to generate category-agnostic instance masks. Φext-cls denotes the external mask classifier, and c(i,j) refers to the labeled category. For convenience, we directly use the lightweight ResNet18 [68] to label the masks.It performs classification by processing the original image patch cropped by the mask. When cropping the image, we first enlarge the crop box by 2 times and then blur non-mask areas to enhance the discriminative capability. To achieve better performance, the mask’s classification representation could be extracted from the image encoder’s intermediate features, but we chose not to follow that approach for the sake of simplicity in our paper. Alternatively, a pre-trained CLIP model can be leveraged, allowing SAM-cls to operate in a zero-shot regime without additional training.

式中**(xi, yj)表示点提示符**。对于每张图像,我们考虑32 × 32个点来生成与类别无关的实例掩码。 Φ ext-cls \Phi_{\text {ext-cls }} Φext-cls 为外部掩码分类器,c(i,j)为标注的类别。为了方便,我们直接使用轻量级的ResNet18[68]来标记掩膜。该算法通过处理掩模裁剪后的原始图像片段来进行分类。在裁剪图像时,我们首先将裁剪框放大2倍,然后对非蒙版区域进行模糊处理,以增强图像的分辨能力。为了获得更好的性能,可以从图像编码器的中间特征中提取掩码的分类表示,但为了简单起见,我们在本文中没有采用这种方法。或者,可以利用预训练的CLIP模型,允许SAM-cls在没有额外训练的情况下在零射击状态下操作。
3) SAM-det:
The SAM-det method is more straightforward to implement and has gained widespread adoption in the community. First, we train an object detector to identify the desired targets in the image, and then input the detected bounding boxes as prompts into SAM. The entire process can be described as follows:
SAM-det方法更容易实现,并且在社区中得到了广泛的采用。首先,我们训练一个目标检测器来识别图像中的目标,然后将检测到的边界框按照提示输入到SAM中。整个过程可以描述如下:
where bi represents bounding boxes detected by the external pre-trained object detector, Φext-det. Here, we employ Faster R-CNN [39] as the detector.

其中bi表示外部预训练对象检测器检测到的边界框,Φext-det。在这里,我们采用Faster R-CNN[39]作为检测器。
RSPrompter
1) Overview:
The proposed RSPrompter’s structure is illustrated in Fig. 3 (d). Suppose we have a training dataset, i.e., Dtrain = {(I1, y1), · · · , (IN , yN )}, where Ii ∈ RH×W ×3 denotes an image, and yi = {bi, ci, mi} represents its corresponding ground-truth annotations, including the coordinates of n object bounding boxes (bi ∈ Rni×4), their associated semantic categories (ci ∈ Rni×C), and binary masks (mi ∈ Rni×H×W ). Our objective is to train a prompter for SAM that can process any image from a test set (Ik ∼ Dtest), simultaneously localizing the objects and inferring their semanticcategories and instance masks, which can be expressed as follows:
本文提出的RSPrompter的结构如图3 (d)所示。假设我们有一个训练数据集,即
D
train
=
{
(
I
1
,
y
1
)
,
⋯
,
(
I
N
,
y
N
)
}
\mathcal{D}_{\text {train }}=\left\{\left(\mathcal{I}_{1}, y_{1}\right), \cdots,\left(\mathcal{I}_{N}, y_{N}\right)\right\}
Dtrain ={(I1,y1),⋯,(IN,yN)},其中
I
i
∈
R
H
×
W
×
3
\mathcal{I}_{i} \in \mathbb{R}^{H \times W \times 3}
Ii∈RH×W×3表示图像,
y
i
=
{
b
i
,
c
i
,
m
i
}
y_{i}=\left\{b_{i}, c_{i}, m_{i}\right\}
yi={bi,ci,mi}表示其对应的ground-truth注释,包括n个对象边界框(bi∈Rni×4)的坐标,它们相关联的语义类别(ci∈Rni×C)和二进制掩码(mi∈Rni×H×W)。我们的目标是为SAM训练一个提示器,该提示器可以处理来自测试集(Ik ~ Dtest)的任何图像,同时定位对象并推断其语义类别和实例掩码,可以表示为:
where the image is processed by the frozen SAM image encoder to generate Fimg ∈ Rh×w×c and multiple intermediate feature maps {Fi} ∈ Rk×h×w×c. Fimg is used by the SAM decoder to obtain prompt-guided masks, while Fi is progressively processed by an efficient feature aggregator (Φaggregator) and a prompt generator (Φprompter) to acquire multiple groups of prompts (Tj ∈ Rkp×c, j ∈ {1, · · · , Np}) and corresponding semantic categories (cj ∈ RC, j ∈ {1, · · · , Np}). kp defines the number of prompt embeddings needed for each mask generation. We will employ two distinct structures to design the prompt generator, namely anchor-based and query-based.

其中,图像经过冻结后的SAM图像编码器处理,生成
F
img
∈
R
h
×
w
×
c
F_{\text {img }} \in \mathbb{R}^{h \times w \times c}
Fimg ∈Rh×w×c和多个中间特征映射
{
F
i
}
∈
R
k
×
h
×
w
×
c
,
i
∈
{
1
,
⋯
,
k
}
\left\{F_i\right\} \in \mathbb{R}^{k \times h \times w \times c}, i \in\{1, \cdots, k\}
{Fi}∈Rk×h×w×c,i∈{1,⋯,k}。SAM解码器使用
F
img
F_{\text {img }}
Fimg 获得提示引导的掩码,而Fi由高效的特征聚合器(Φaggregator)和提示生成器(Φprompter)逐步处理,获得多组提示
(
T
j
∈
R
k
p
×
c
,
j
∈
{
1
,
⋯
,
N
p
}
)
\left(T_{j} \in \mathbb{R}^{k_{p} \times c}, j \in\left\{1, \cdots, N_{p}\right\}\right)
(Tj∈Rkp×c,j∈{1,⋯,Np})和相应的语义类别
(
c
j
∈
R
C
,
j
∈
{
1
,
⋯
,
N
p
}
)
\left(c_{j} \in \mathbb{R}^{\mathcal{C}}, j \in\left\{1, \cdots, N_{p}\right\}\right)
(cj∈RC,j∈{1,⋯,Np})。KP定义了每个掩码生成所需的提示嵌入的数量。我们将采用两种不同的结构来设计提示生成器,即基于锚点的和基于查询的。
It is important to note that Tj only contains foreground target instance prompts, with the semantic category given by cj. A single Tj is a combination of multiple prompts, i.e., representing an instance mask with multiple point embeddings or a bounding box. For simplicity, we will omit the superscript k when describing the proposed model.
重要的是要注意,Tj只包含前台目标实例提示,其语义类别由cj给出。单个Tj是多个提示的组合,即,用多个点嵌入或一个边界框表示一个实例掩码。为简单起见,在描述所建议的模型时,我们将省略上标k。
2) Feature Aggregator:
SAM is a category-agnostic segmentation model based on prompts. To obtain semantically relevant and discriminative features without increasing the computational complexity of the prompter, we introduce a lightweight feature aggregation module. This module learns to represent semantic features from various intermediate feature layers of the SAM ViT backbone, as depicted in Fig. 4. The module can be described recursively as follows:
SAM是一种基于提示的分类无关的分割模型。为了在不增加提示器计算复杂度的情况下获得语义相关和判别特征,我们引入了一个轻量级的特征聚合模块。该模块学习表示来自SAM ViT主干的各种中间特征层的语义特征,如图4所示。
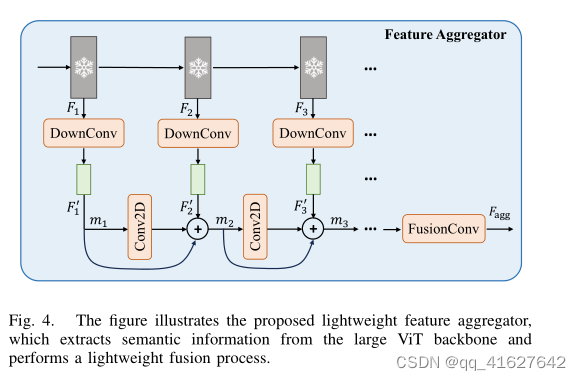
该模块可以递归地描述如下:
where Fi ∈ Rh×w×c and F ′i ∈ R h 2 × w 2 × c 16 indicate the SAM backbone’s features and down-sampled features generated by ΦDownConv. This process first employs a 1 × 1 Convolution ReLU block to reduce the channels from c to c 16, followed by a 3 × 3 Convolution-ReLU block with a stride of 2 to decrease the spatial dimensions. Since we believe that only coarse information about the target location is necessary, we boldly further reduce the spatial dimension size to minimize computational overhead. ΦConv2D denotes a 3×3 ConvolutionReLU block, while ΦFusionConv represents the final fusion convolutional layers comprising two 3 × 3 convolution layers and one 1×1 convolution layer to restore the original channel dimensions of SAM’s mask decoder
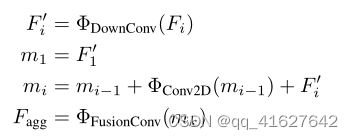
式中, F i ∈ R h × w × c , F i ′ ∈ R h 2 × w 2 × c 16 F_{i} \in \mathbb{R}^{h \times w \times c},F_{i}^{\prime} \in \mathbb{R}^{\frac{h}{2} \times \frac{w}{2} \times \frac{c}{16}} Fi∈Rh×w×c,Fi′∈R2h×2w×16c表示SAM主干的特征和由ΦDownConv生成的下采样特征。该过程首先使用1 × 1的卷积- relu块将通道从c减少到c/16,然后使用3 × 3的卷积- relu块,步幅为2,以减少空间维度。由于我们认为只有关于目标位置的粗略信息是必要的,因此我们大胆地进一步减小空间维度大小以最小化计算开销。ΦConv2D表示3×3卷积relu块,ΦFusionConv表示最终的融合卷积层,包括两个3×3卷积层和一个1×1卷积层,以恢复SAM掩码解码器的原始信道尺寸。
3) Anchor-based Prompter:
Upon obtaining the fused semantic features, we can employ the prompter to generate prompt embeddings for the SAM mask decoder. In this section, we introduce the anchor-based approach for generating prompt embeddings.
3)基于锚点的提示器:在获得融合的语义特征后,我们可以使用提示器为SAM掩码解码器生成提示嵌入。在本节中,我们将介绍用于生成提示嵌入的基于锚点的方法。
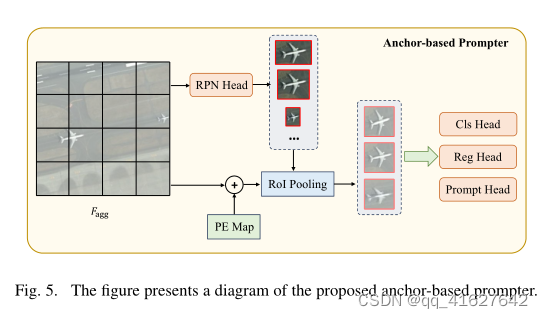
Architecture: First, we generate candidate object boxes using the anchor-based Region Proposal Network (RPN). Next, we obtain the individual object’s visual feature representation from the positional encoding feature map via RoI Pooling [20], according to the proposal. From the visual feature, we derive three perception heads: the semantic head, the localization head, and the prompt head. The semantic head determines a specific object category, while the localization head establishes the matching criterion between the generated prompt representation and the target instance mask, i.e., greedy matching based on localization (Intersection over Union, or IoU). The prompt head generates the prompt embedding required for the SAM mask decoder. The entire process is illustrated in Fig. 5 and can be represented by the following equation:
架构:首先,我们使用基于锚点的区域建议网络(RPN)生成候选对象盒。接下来,我们通过RoI Pooling[20]从位置编码特征映射中获得单个物体的视觉特征表示。从视觉特征出发,我们得到了三个感知头:语义头、定位头和提示头。语义头确定具体的对象类别,而定位头建立生成的提示表示与目标实例掩码之间的匹配标准,即基于定位的贪婪匹配(Intersection over Union,或IoU)。提示头生成SAM掩码解码器所需的提示嵌入。整个过程如图5所示
可以用下式表示:
To align the embeddings from SAM’s prompt encoder with the generated prompt embeddings, we use sine functions to directly generate high-frequency information rather than predicting it through the network. This is because neural networks have difficulty predicting high-frequency information.The effectiveness of this design has been confirmed through subsequent experiments.
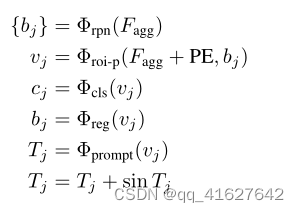
为了将SAM的提示编码器的嵌入与生成的提示嵌入对齐,我们使用正弦函数直接生成高频信息,而不是通过网络预测。这是因为神经网络难以预测高频信息。通过后续的实验验证了该设计的有效性。
Loss Function: In the anchor-based prompter, the primary framework adheres to the structure of Faster R-CNN [39]. The various losses incorporated within this model include binary classification loss and localization loss for the RPN network, classification loss for the semantic head, regression loss for the localization head, and segmentation loss for the frozen SAM mask decoder. Consequently, the overall loss can be expressed as follows:
Loss Function:在基于锚点的提示器中,主框架遵循Faster R-CNN的结构[39]。该模型中包含的各种损失包括RPN网络的二进制分类损失和定位损失、语义头的分类损失、定位头的回归损失和冻结SAM掩码解码器的分割损失。因此,总损失可表示为:
where Lcls represents the Cross-Entropy loss calculated between the predicted category and the target, while Lreg denotes the SmoothL1 loss computed based on the predicted coordinate offsets and the target offsets between the ground truth and the prior box. Furthermore, Lseg indicates the binary cross-entropy loss between the SAM-decoded mask and the target instance mask label, where the matching criteria are determined by the IoU of the boxes. The indicator function 1 is employed to confirm a positive match. Lastly, Lrpn signifies the region proposal loss.
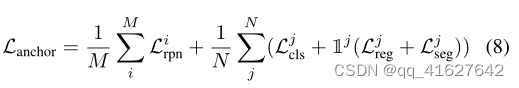
其中Lcls表示预测类别与目标之间计算的Cross-Entropy loss, Lreg表示根据预测坐标偏移量和ground truth与prior box之间的目标偏移量计算的SmoothL1 loss。此外,Lseg表示sam解码的掩码和目标实例掩码标签之间的二进制交叉熵损失,其中匹配标准由框的IoU确定。指示器函数1用于确认正匹配。最后,Lrpn表示区域建议损失。
4) Query-based Prompter:
基于查询的提示器:
基于锚点的提示器过程相对复杂,涉及到利用方框信息进行掩码匹配和监督训练。为了简化这一过程,我们提出了一个以最优传输为基础的基于查询的提示器。
Architecture: The query-based prompter primarily consists of a lightweight Transformer encoder and decoder internally. The encoder is employed to extract high-level semantic features from the image, while the decoder is utilized to transform the preset learnable query into the requisite prompt embedding for SAM via cross-attention interaction with image features. The 7 entire process is depicted in Fig. 6, as follows:
架构:基于查询的提示器主要由一个轻量级的Transformer编码器和内部解码器组成。编码器用于从图像中提取高级语义特征,解码器通过与图像特征的交叉注意交互,将预设的可学习查询转换为SAM所需的提示嵌入。整个过程如图6所示,
如下图所示:
where
P
E
∈
R
h
×
w
×
c
\mathrm{PE} \in \mathbb{R}^{h \times w \times c}
PE∈Rh×w×crefers to the positional encoding, while Fquery ∈ RNp×c represents the learnable tokens, which are initialized as zero. Φmlp-cls constitutes an MLP layer employed to obtain class predictions (C ∈ RNp×C). Meanwhile, Φmlp-prompt comprises a two-layer MLP designed to acquire the projected prompt embeddings (T ∈ RNp×kp×c). Np denotes the number of prompt groups, i.e., the number of instances. kp defines the number of embeddings per prompt, i.e., the number of prompts necessary to represent an instance target. Furthermore, ΦT-enc and ΦT-dec symbolize the Transformer encoder and decoder, respectively.
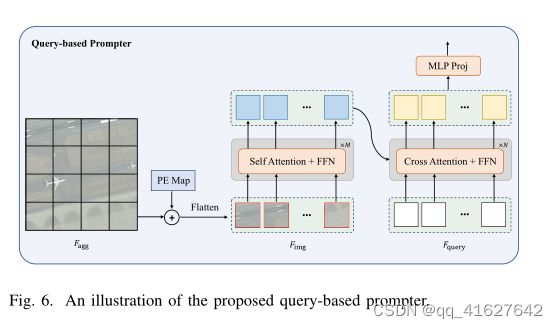

其中 P E ∈ R h × w × c \mathrm{PE} \in \mathbb{R}^{h \times w \times c} PE∈Rh×w×c表示位置编码, F query ∈ R N p × c F_{\text {query }} \in \mathbb{R}^{N_{p} \times c} Fquery ∈RNp×c表示可学习token,初始化为0。Φmlp-cls构成一个MLP层,用于获得类预测 ( C ∈ R N p × C ) \left(C \in \mathbb{R}^{N_{p} \times \mathcal{C}}\right) (C∈RNp×C)。同时,Φmlp-prompt包含一个两层MLP,用于获取投影提示嵌入( ( T ∈ R N p × k p × c ) \left(T \in \mathbb{R}^{N_{p} \times k_{p} \times c}\right) (T∈RNp×kp×c))。Np表示提示组的个数,即实例数。KP定义每个提示符的嵌入数量,即表示实例目标所需的提示符数量。此外,ΦT-enc和ΦT-dec分别表示Transformer编码器和解码器。
Loss Function: The training process for the query-based prompter primarily involves two key steps: (i) matching Np masks, decoded by the SAM mask decoder, to K ground-truth instance masks (typically, Np > K); (ii) subsequently conducting supervised training using the matched labels. While executing optimal transport matching, we define the matching cost, taking into account the predicted category and mask, as detailed below:
损失函数:基于查询的提示符的训练过程主要包括两个关键步骤:(i)匹配由SAM掩码解码器解码的Np掩码与K个真值实例掩码(通常Np > K);(ii)随后使用匹配的标签进行监督培训。在执行最优传输匹配时,考虑到预测的类别和掩码,我们定义匹配成本,具体如下:
where ω represents the assignment relationship, while ˆyi and yi correspond to the prediction and the label, respectively. We employ the Hungarian algorithm [81] to identify the optimal assignment between the Np predictions and K targets. The matching cost considers the similarity between predictions and ground-truth annotations. Specifically, it incorporates the class classification matching cost (Lcls), mask cross-entropy cost (Lseg-ce), and mask dice cost (Lseg-dice).
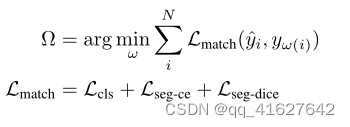
式中,ω表示赋值关系,@ yi和@ yi分别对应预测和标签。我们使用匈牙利算法[81]来确定Np预测和K目标之间的最优分配。匹配成本考虑了预测和真值注释之间的相似性。具体来说,它结合了类分类匹配代价(Lcls)、掩码交叉熵代价(Lseg-ce)和掩码骰子代价(Lseg-dice)。
Once each predicted instance is paired with its corresponding ground truth, we can readily apply the supervision terms.These primarily comprise multi-class classification and binary mask classification, as described below:
一旦每个预测实例与其相应的基础真值配对,我们就可以很容易地应用监督项。这些主要包括多类分类和二进制掩码分类,如下所述:
where Lcls denotes the cross-entropy loss computed between the predicted category and the target, while Lseg signifies the binary cross-entropy loss between the SAM decoded mask and the matched ground-truth instance mask. Additionally, 1 represents the indicator function.
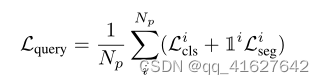
其中Lcls表示预测类别与目标之间计算的交叉熵损失,Lseg表示SAM解码掩码与匹配的真值实例掩码之间的二进制交叉熵损失。其中,1表示指标函数。
实验结果及分析
implementation Details
The proposed method concentrates on learning to prompt remote sensing image instance segmentation using the SAM foundation model. In our experiments, we employ the ViTHuge backbone of SAM, unless otherwise indicated
该方法着重于学习基于SAM基础模型的遥感图像实例分割。在我们的实验中,除非另有说明,否则我们使用SAM的ViTHuge主干。
1) Architecture Details:
The SAM framework generates various segmentations for a single prompt; however, our method anticipates only one instance mask for each learned prompt. Consequently, we select the first mask as the final output. For each group of prompts, we set the number of prompts to 4, i.e., kp = 4. In the feature aggregator, to reduce computation costs, we use input features from every 3 layers after the first 8 layers of the backbone, rather than from every layer. For the anchor-based prompter, the RPN network originates from Faster R-CNN [39], and other hyperparameters in the training remain consistent. For the querybased prompter, we employ a 1-layer transformer encoder and a 4-layer transformer decoder, implementing multi-scale training for category prediction from the outputs of the decoder at 4 different levels. However, we do not apply multi-scale training to instance mask prediction in order to maintain efficiency. We determine the number of learnable tokens based on the distribution of target instances in each image, i.e., Np = 90, 60, 30 for the WHU, NWPU, and SSDD datasets, respectively.
1)架构细节:SAM框架为单个提示符生成各种分段;然而,我们的方法仅为每个学习提示预测一个实例掩码。因此,我们选择第一个掩码作为最终输出。对于每组提示,我们将提示的数量设置为4,即kp = 4。在特征聚合器中,为了降低计算成本,我们在主干的前8层之后每3层使用输入特征,而不是每一层使用输入特征。对于基于锚点的提示器,RPN网络来源于Faster R-CNN[39],训练中的其他超参数保持一致。对于基于查询的提示器,我们使用了一个1层变压器编码器和一个4层变压器解码器,从解码器的输出在4个不同的级别上实现多尺度训练来预测类别。然而,为了保持效率,我们没有将多尺度训练应用于实例掩码预测。我们根据每个图像中目标实例的分布来确定可学习令牌的数量,即对于WHU、NWPU和SSDD数据集,Np分别= 90,60,30。
2) Training Details:
During the training phase, we adhere to the image size of 1024 × 1024, in line with SAM’s original input. Concurrently, we utilize horizontal flipping to augment the training samples, without implementing any additional enhancements. Other comparative methods also follow the same settings unless specified otherwise. We only train the parameters of the prompter component while maintaining the parameters of other parts of the network as frozen. During the testing phase, we predict up to 100 instance masks per image for evaluation purposes.
2)训练细节:在训练阶段,我们坚持图像大小为1024 × 1024,与SAM的原始输入一致。同时,我们利用水平翻转来增强训练样本,而不实现任何额外的增强。除非另有说明,其他比较方法也遵循相同的设置。我们只训练提示器组件的参数,而保持网络其他部分的参数为冻结状态。在测试阶段,我们预测每个图像最多有100个实例掩码用于评估目的。
For optimization, we employ the AdamW optimizer with an initial learning rate of 2e − 4 to train our model. We set the mini-batch size to 24. The total training epochs are 700/1000 for the WHU dataset and 1500/2500 for both the NWPU and SSDD datasets (RSPrompter-anchor/RSPrompterquery). We implement a Cosine Annealing scheduler [92] to decay the learning rate. Our proposed method is developed using PyTorch, and we train all the extra-designed modules from scratch
为了优化,我们使用初始学习率为2e−4的AdamW优化器来训练我们的模型。我们将小批量大小设置为24。WHU数据集的总训练epoch为700/1000,总训练epoch为1500/2500NWPU和SSDD数据集(RSPrompter-anchor/RSPrompterquery)的。我们实现了余弦退火调度器[92]来衰减学习率。我们提出的方法是使用PyTorch开发的,我们从头开始训练所有额外设计的模块。
Comparison with the State-of-the-Art
In this section, we compare our proposed method with several other state-of-the-art instance segmentation methods.These include multi-stage approaches such as Mask R-CNN [20], Mask Scoring (MS) R-CNN [22], HTC [23], Instaboost [87], PointRend [88], SCNet [90], CA TNet [5], and HQISNet [1], as well as single-stage methods like SOLO [28], SOLOv2 [89], CondInst [27], BoxInst [91], and Mask2Former [29]. Among these, SOLOv2 [89], CondInst [27], BoxInst [91], and Mask2Former [29] are filter-based methods, while CA TNet [5] and HQ-ISNet [1] are Mask R-CNN-based remote sensing instance segmentation methods. For extending instance segmentation methods on SAM, we carry out SAM-seg (Mask R-CNN) and SAM-seg (Mask2Former) for SAM-seg with Mask R-CNN and Mask2Former heads and training regimes.SAM-cls is considered a minimalistic instance segmentation method that leverages the “everything” mode of SAM to obtain all instances in the image and employs a pre-trained ResNet18 [68] to label all instance masks. SAM-det denotes the first training of a Faster R-CNN [39] detector to acquire boxes and subsequently generating corresponding instance masks by SAM with the box prompts. RSPrompter-query and RSPrompter-anchor respectively represent the query-based and anchor-based promoters. All the cited methods are implemented following the official publications using PyTorch
在本节中,我们将我们提出的方法与其他几种最先进的实例分割方法进行比较。这些方法包括多阶段方法,如Mask R-CNN[20]、Mask Scoring (MS) R-CNN[22]、HTC[23]、Instaboost[87]、PointRend[88]、SCNet[90]、CA TNet[5]和HQISNet[1],以及单阶段方法,如SOLO[28]、SOLOv2[89]、CondInst[27]、BoxInst[91]和Mask2Former[29]。其中,SOLOv2[89]、CondInst[27]、BoxInst[91]、Mask2Former[29]是基于滤波器的方法,CA TNet[5]、HQ-ISNet[1]是基于Mask r- cnn的遥感实例分割方法。为了在SAM上扩展实例分割方法,我们对SAM-seg进行了SAM-seg (Mask R-CNN)和SAM-seg (Mask2Former)面具R-CNN和面具2前领导和培训制度。SAM-cls被认为是一种极简的实例分割方法,它利用SAM的“一切”模式来获取图像中的所有实例,并使用预训练的ResNet18[68]来标记所有实例掩码。SAM-det表示对Faster R-CNN[39]检测器进行第一次训练,获取方框,随后由SAM根据方框提示生成相应的实例掩码。RSPrompter-query和RSPrompter-anchor分别表示基于查询的启动子和基于锚的启动子。所有引用的方法都是根据使用PyTorch的官方出版物实现的。
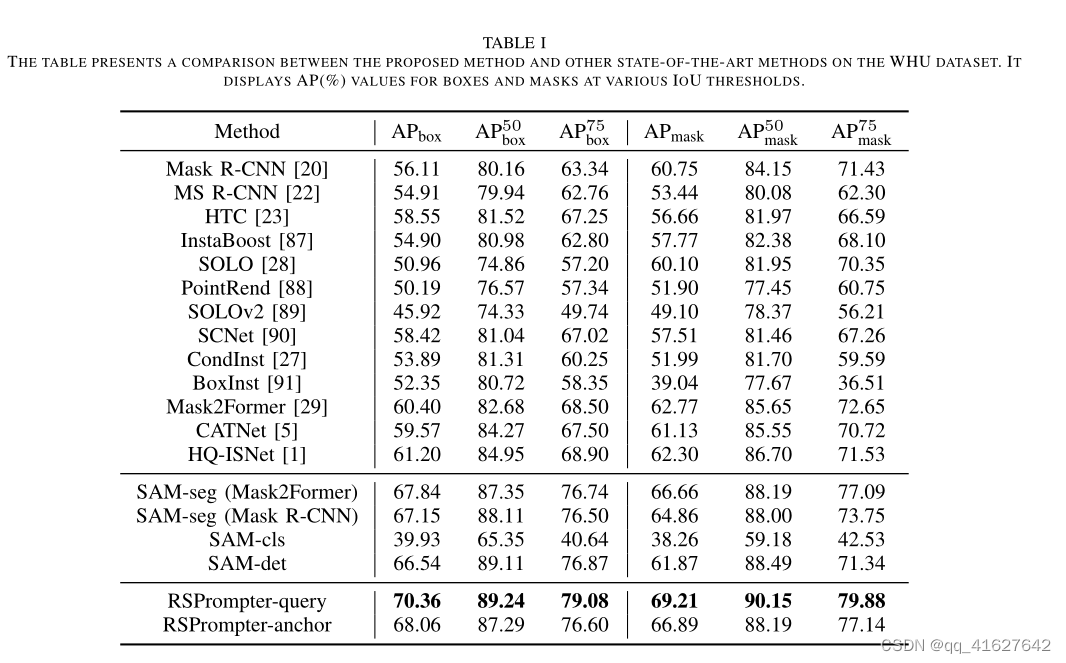
Quantitative Results on the WHU Dataset: The results of RSPrompter in comparison to other methods on the WHU dataset are presented in Tab. I, with the best performance highlighted in bold. The task involves performing single-class instance segmentation of buildings in optical RGB band remote sensing images. RSPrompter-query attains the best performance for both box and mask pre dictions, achieving APbox and APmask values of 70.36/69.21.Specifically, SAM-seg (Mask2Former) surpasses the original Mask2Former (60.40/62.77) with 67.84/66.66 on APbox and APmask, while SAM-seg (Mask R-CNN) exceeds the original Mask R-CNN (56.11/60.75) with 67.15/64.86. Furthermore, both RSPrompter-query and RSPrompter-anchor improve the performance to 70.36/69.21 and 68.06/66.89, respectively, outperforming SAM-det, which carries out detection before segmentation.
1、在WHU数据集上的定量结果:
RSPrompter与其他方法在WHU数据集上的对比结果如表I所示。表现最好的用粗体标出。该任务涉及对光学RGB波段遥感图像中的建筑物进行单类实例分割。RSPrompter-query在box和mask预测方面都获得了最佳性能,实现了APbox和APmask值为70.36/69.21。其中,SAM-seg (Mask2Former)在APbox和APmask上以67.84/66.66超越了原来的Mask2Former (60.40/62.77), SAM-seg (Mask R-CNN)以67.15/64.86超越了原来的Mask R-CNN(56.11/60.75)。此外,RSPrompter-query和RSPrompter-anchor的性能分别提高到70.36/69.21和68.06/66.89,优于先检测再分割的SAM-det。
这些观察结果表明,学习到提示的方法有效地将SAM用于光学遥感图像的实例分割任务。此外,他们还证明,在广泛的数据集上训练的SAM主干,即使在完全冻结的情况下(如SAM-seg所示),也可以提供有价值的实例分割指导。
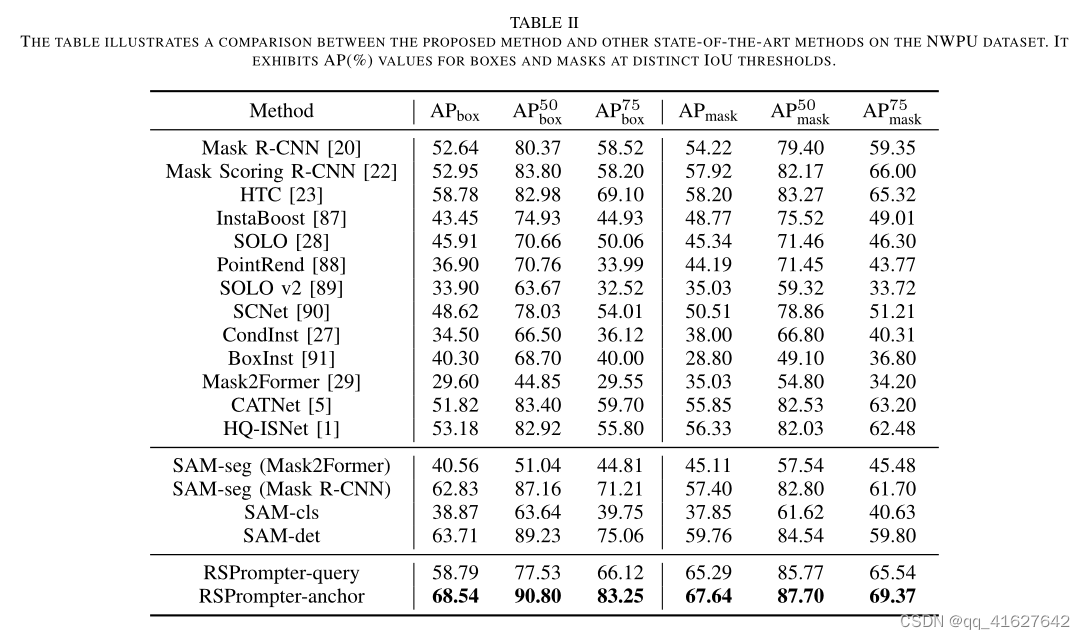
2) Quantitative Results on NWPU Dataset:
We conduct comparison experiments on the NWPU dataset to further validate RSPrompter’s effectiveness. Unlike the WHU dataset,his one is smaller in size but encompasses more instance categories, amounting to 10 classes of remote sensing objects.The experiment remains focused on optical RGB band remote sensing image instance segmentation. Tab. II exhibits the overall results of various methods on this dataset.
- NWPU数据集上的定量结果:我们在NWPU数据集上进行对比实验,进一步验证RSPrompter的有效性。与世界卫生组织的数据集不同,虽然尺寸较小,但包含了更多的实例类别,总共有10类遥感对象。实验的重点是光学RGB波段遥感图像的实例分割。选项II展示了该数据集上各种方法的总体结果。
It can be observed that RSPrompter-anchor, when compared to other approaches, generates the best results on box and mask predictions (68.54/67.64). In comparison to Mask RCNN-based methods, single-stage methods display a substantial decline in performance on this dataset, particularly the Transformer-based Mask2Former. This may be because the dataset is relatively small, making it challenging for singlestage methods to achieve adequate generalization across the full data domain, especially for Transformer-based methods that require a large amount of training data. Nonetheless, it is worth noting that the performance of SAM-based SAM-seg (Mask2Former) and RSPrompter-query remains impressive. The performance improves from 29.60/35.02 for Mask2Former to 40.56/45.11 for SAM-seg (Mask2Former) and further to 58.79/65.29 for RSPrompter-query.
可以观察到,与其他方法相比,RSPrompter-anchor在框和掩码预测上的结果最好(68.54/67.64)。与基于Mask rcnn的方法相比,单阶段方法在该数据集上的性能明显下降,特别是基于transformer的Mask2Former。这可能是因为数据集相对较小,使得单阶段方法在整个数据领域实现充分的泛化具有挑战性,特别是对于需要大量训练数据的基于transformer的方法。尽管如此,值得注意的是,基于sam的SAM-seg (Mask2Former)和RSPrompter-query的性能仍然令人印象深刻。性能从Mask2Former的29.60/35.02提高到SAM-seg (Mask2Former)的40.56/45.11,再到RSPrompter-query的58.79/65.29。
These findings imply that SAM, when trained on a large amount of data, can exhibit significant generalization ability on a small dataset. Even when there are differences in the image domain, SAM’s performance can be enhanced through the learning-to-prompt approach.
这些发现表明,当在大量数据上进行训练时,SAM可以在小数据集上表现出显著的泛化能力。即使在图像域存在差异时,SAM的性能也可以通过“学习到提示”的方法得到提高。
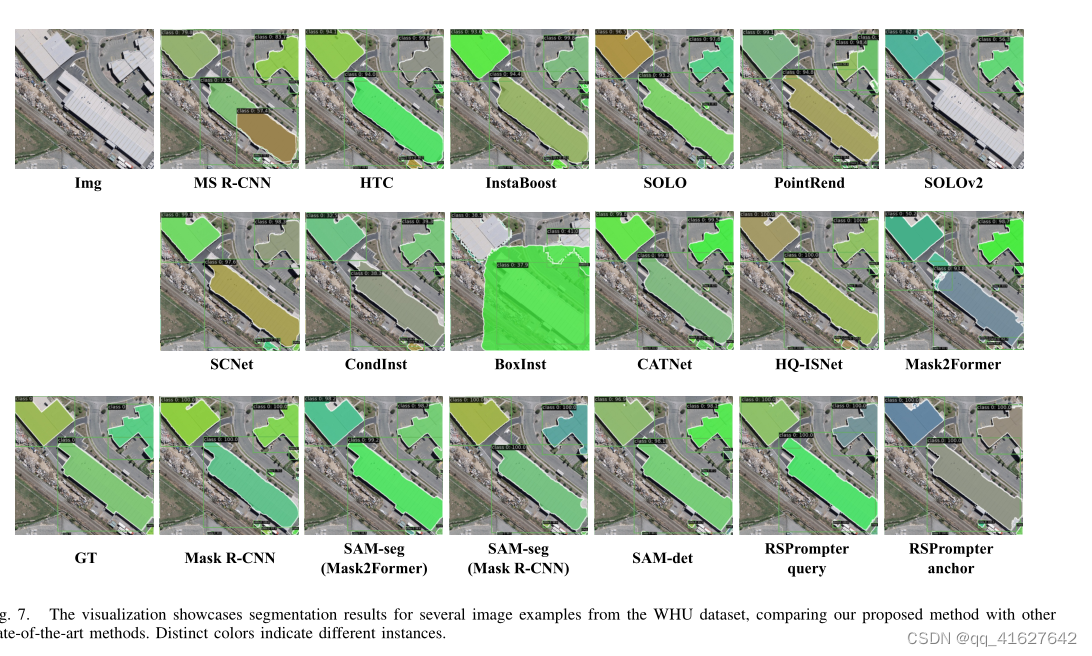
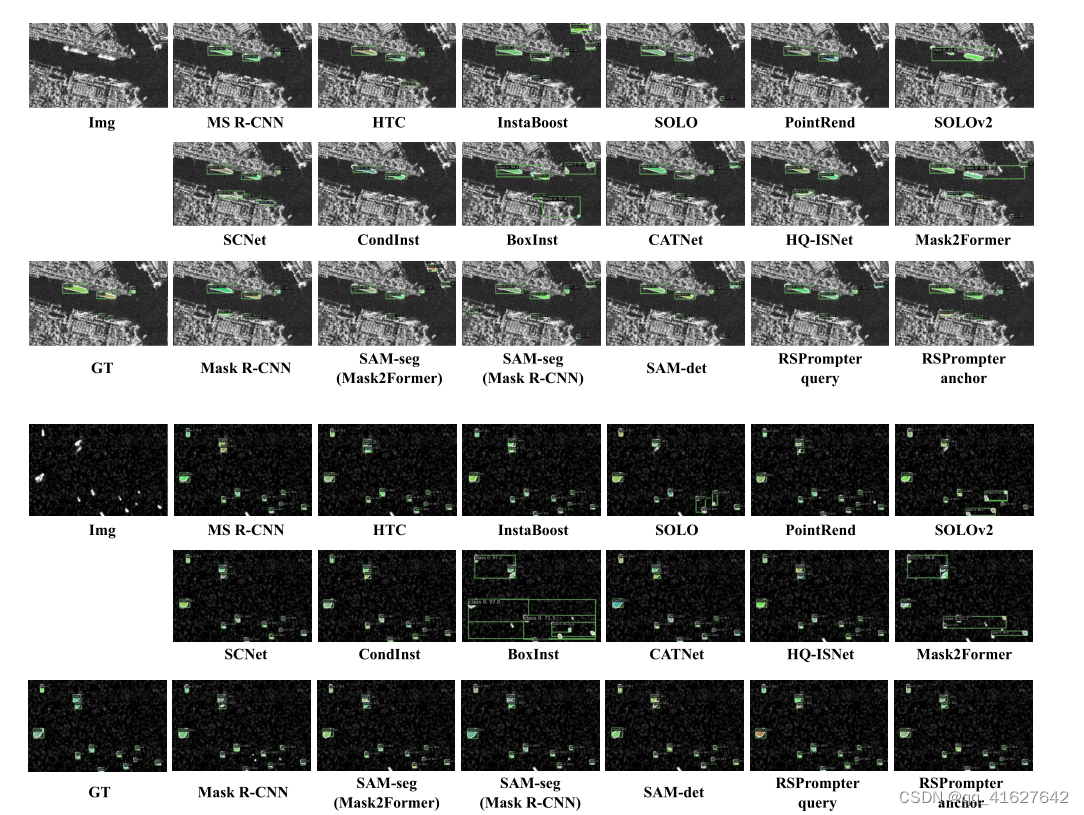
4) Qualitative Visual Comparisons:
To facilitate a more effective visual comparison with other methods, we present a qualitative analysis of the segmentation results obtained from SAM-based techniques and other state-of-the-art instance segmentation approaches. Fig. 7, 8, and 9 depict sample segmentation instances from the WHU dataset, NWPU dataset, and SSDD dataset, respectively. It can be observed that the proposed RSPrompter yields notable visual improvements in instance segmentation. Compared to alternative methods, the RSPrompter generates superior results, exhibiting sharper edges, more distinct contours, enhanced completeness, and a closer resemblance to the ground-truth references
4)定性视觉比较:为了便于与其他方法进行更有效的视觉比较,我们对基于sam的技术和其他最先进的实例分割方法获得的分割结果进行了定性分析。图7、图8和图9分别描述了WHU数据集、NWPU数据集和SSDD数据集的样本分割实例。可以观察到,所提出的RSPrompter在实例分割方面产生了显着的视觉改进。与其他方法相比,RSPrompter产生了更好的结果,显示出更清晰的边缘,更明显的轮廓,增强的完整性,并且更接近于真实参考