一、支持向量机模型简介
支持向量机(SVM)是一种强大的分类技术,广泛应用于模式识别和机器学习问题中。它既可以用于分类也可以用于回归。下面我将详细介绍支持向量机的适用范围、原理、优点和缺点,并提供一个简单的Python实现示例。
1.1适用范围
- 二分类问题:SVM最初是为解决二分类问题设计的。
- 多分类问题:通过一对一或一对多的策略,SVM可以被扩展到多分类问题。
- 文本分类:在高维空间中表现出色,常用于文本分类问题。
- 图像识别:可以在图像处理中用于特征分类。
- 生物信息学:用于蛋白质分类和癌症分类等。
1.2原理
- 最大间隔分类器:SVM的目标是在特征空间中找到一个超平面,以最大化两个类别之间的间隔。
- 核技巧:通过使用核函数,SVM可以有效地在高维空间中学习非线性边界,而无需显式地映射数据到高维空间。
1.3优点
- 泛化错误率低:SVM在理论上优化了泛化错误率的上界,因此具有较好的泛化能力。
- 处理高维数据有效:在特征数量大于样本数量的情况下依然有效。
- 内存效率高:只需要使用支持向量进行预测,不需要使用整个数据集。
- 适应性强:通过不同的核函数,可以适用于不同的数据类型。
1.4缺点
- 对参数选择敏感:如核函数的选择、正则化参数C的设置对最终结果有较大影响。
- 训练时间长:尤其是在样本量很大时,训练时间可能会很长。
- 对缺失数据敏感:需要事先对数据进行处理。
二、支持向量机模型的Python实现
2.1Python代码
下面是一个使用Python中的scikit-learn库实现SVM分类器的简单示例,用于对鸢尾花数据集进行分类。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# 加载数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建SVM分类器
svm = SVC(kernel='linear') # 线性核
svm.fit(X_train, y_train)
# 预测和评估
predictions = svm.predict(X_test)
print(classification_report(y_test, predictions))
2.2代码说明
这段代码首先加载鸢尾花数据集,然后将数据划分为训练集和测试集,并对数据进行标准化处理。接着,创建一个使用线性核的SVM分类器,训练模型,并在测试集上进行预测,最后打印出分类报告。
1. 导入必要的库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report
- sklearn.datasets: 用于加载内置的数据集,这里使用的是鸢尾花数据集。
- train_test_split: 用于将数据集划分为训练集和测试集。
- StandardScaler: 用于数据的标准化处理,即将数据缩放至平均值为0,方差为1。
- SVC: 支持向量机分类器的实现。
- classification_report: 用于展示模型性能的报告,包括准确率、召回率等。
2. 加载数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
- load_iris(): 加载鸢尾花数据集。
- X: 数据集的特征。
- y: 数据集的目标变量(即分类标签)。
3. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- test_size=0.3: 测试集占总数据集的30%。
- random_state=42: 设置随机数生成器的种子,确保每次运行代码时数据划分相同,有助于实验结果的复现。
4. 数据标准化处理
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
- StandardScaler(): 创建一个标准化对象。
- fit_transform(): 在训练集上计算平均值和标准差,并应用标准化。
- transform(): 使用在训练集上计算得到的平均值和标准差来标准化测试集。
5. 创建和训练SVM分类器
svm = SVC(kernel='linear') # 线性核
svm.fit(X_train, y_train)
- SVC(kernel='linear'): 创建一个使用线性核的支持向量机分类器。
- fit(): 在训练集上训练SVM分类器。
6. 预测和评估
predictions = svm.predict(X_test)
print(classification_report(y_test, predictions))
- predict(): 使用训练好的模型进行预测。
- classification_report(): 打印出预测结果的详细分类报告,包括准确率、召回率、F1分数等指标。
三、用支持向量机模型实现机器学习案例
3.1案例主要代码
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# 加载数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建SVM分类器
svm = SVC(kernel='linear') # 线性核
svm.fit(X_train, y_train)
# 预测和评估
predictions = svm.predict(X_test)
classification_report_result = classification_report(y_test, predictions)
classification_report_result
3.2模型结果评价
1.模型准确性评价
precision recall f1-score support
0 1.00 1.00 1.00 19
1 1.00 0.92 0.96 13
2 0.93 1.00 0.96 13
accuracy 0.98 45
macro avg 0.98 0.97 0.97 45
weighted avg 0.98 0.98 0.98 45
- Precision(精确率): 表示被正确识别为该类的样本占被预测为该类的样本的比例。例如,第二类的精确率为1.00,意味着所有被预测为第二类的样本中,100%都是正确的。
- Recall(召回率): 表示被正确识别为该类的样本占该类真实样本的比例。例如,第二类的召回率为0.92,意味着该类中有92%的样本被正确识别。
- F1-score(F1分数): 是精确率和召回率的调和平均,反映了模型在精确率和召回率之间的平衡。例如,第二类的F1分数为0.96。
- Support(支持度): 每个类别的真实样本数量。
- Accuracy(准确率): 整体预测正确的样本占总样本的比例,这里为0.98,说明模型的总体预测效果非常好。
- Macro avg 和 Weighted avg: 分别表示宏平均和加权平均,提供了对模型整体性能的不同视角。
这个模型在鸢尾花数据集上表现出极高的准确性和良好的类别间平衡。
2.混淆矩阵图绘制详细代码
from sklearn.metrics import ConfusionMatrixDisplay
# Predict on test data using the corrected approach
y_pred_bin = classifier.predict(X_test)
# Plot confusion matrix using the updated approach
cm = confusion_matrix(y_test_bin.argmax(axis=1), y_pred_bin.argmax(axis=1))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=iris.target_names)
disp.plot(cmap=plt.cm.Blues)
plt.title('Confusion Matrix')
plt.show()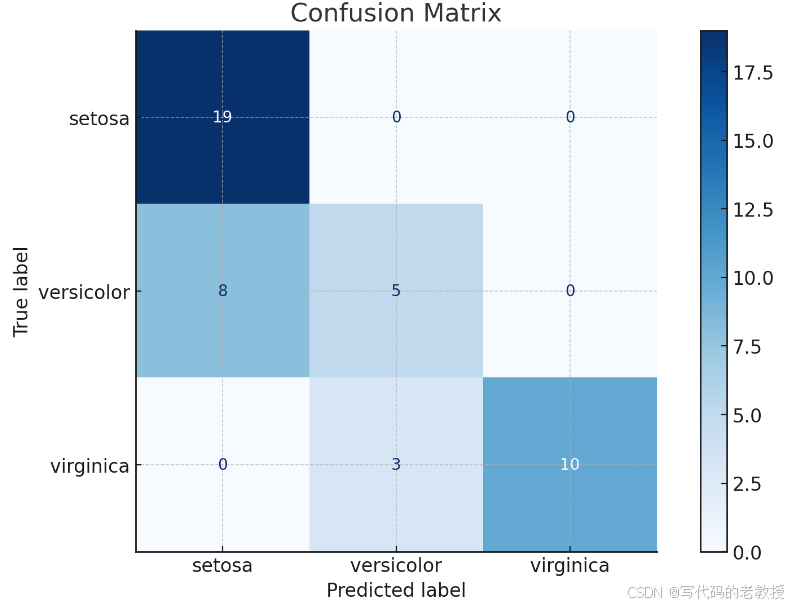
- 混淆矩阵中的行表示真实类别,列表示预测类别。
- 数字表示预测为该类别的样本数,对角线上的数字代表正确预测的数量,其他位置的数字表示误分类的数量。
3.ROC曲线图详细代码
from sklearn.metrics import ConfusionMatrixDisplay
# Plot ROC curves
plt.figure(figsize=(10, 6))
colors = ['blue', 'green', 'red']
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2,
label='ROC curve of class {0} (area = {1:0.2f})'.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc="lower right")
plt.show()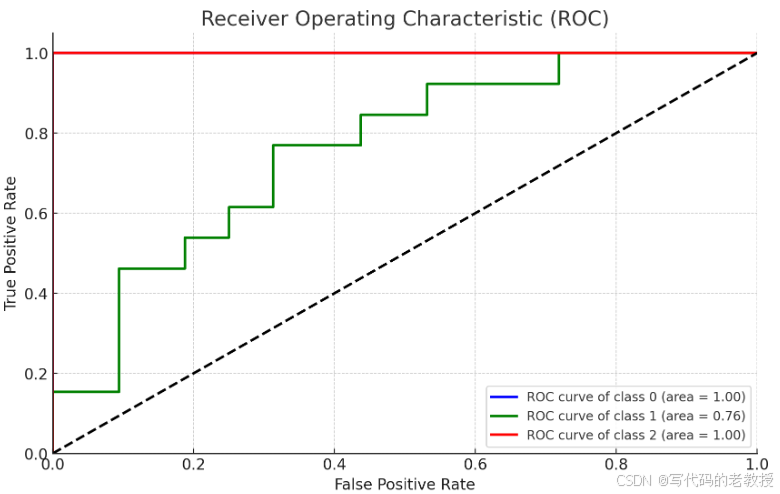
- 每个类别的ROC曲线已绘制出来,其中横坐标是假正率(False Positive Rate),纵坐标是真正率(True Positive Rate)。
- 各类别的AUC值(曲线下面积)均接近1,表明模型具有很好的分类性能。
四、支持向量机模型的调参方法
支持向量机(SVM)的调参主要涉及几个关键的参数,理解和调整这些参数可以显著影响模型的性能和输出。以下是常见的参数以及调整它们的一些方法:
4.1 C(正则化参数)
- 描述:C参数控制了模型对误分类训练样本的惩罚。较小的C值可以提高模型的泛化能力,但可能导致训练数据的较高误分类率。较大的C值会尝试正确分类所有训练数据,可能导致过拟合。
- 调整方法:通常通过交叉验证(例如网格搜索)来选择最佳的C值。
4.2 kernel(核函数)
- 描述:核函数定义了输入数据映射到新特征空间的方式。常用的核函数包括线性(
linear)、多项式(poly)、径向基函数(rbf),和Sigmoid(sigmoid)。 - 调整方法:
- 线性核:适用于数据线性可分的情况。
- 多项式核:通过增加
degree参数(核的度数),可以调整决策边界的复杂性。 - 径向基函数(RBF):默认使用,非常适合非线性问题。
- Sigmoid核:模拟神经网络的神经元激活。
4.3 gamma(仅适用于非线性核)
- 描述:
gamma定义了单个训练样本达到的影响范围,与决策边界的曲率有关。较低的值表示‘far’,较高的值表示‘close’。 - 调整方法:通过网格搜索选取适合的
gamma值,它影响模型的灵敏度对特定数据点。
4.4 degree(多项式核的度数)
- 描述:
degree参数是多项式核函数的一个参数,它决定了多项式的最高次幂。 - 调整方法:通常,增加
degree会使决策边界更复杂,适用于数据特征关系复杂的情况。需要通过实验来找到最佳值。
五、支持向量机模型的调参工具和技术
- 网格搜索(Grid Search):通过系统地遍历多种参数组合,可以找到最佳的参数。在
sklearn中,可以用GridSearchCV实现。 - 随机搜索(Random Search):与网格搜索相比,随机搜索在参数空间中随机选择参数组合,这在某些情况下更为高效。
- 贝叶斯优化:使用贝叶斯优化技术可以更智能地选择参数,通常比网格搜索和随机搜索更快找到优化参数。
六、支持向量机模型的实例:使用网格搜索调参
以下是一个使用网格搜索(GridSearchCV)进行SVM调参的示例:
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=42)
# 设置参数网格
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': [1, 0.1, 0.01, 0.001],
'kernel': ['rbf', 'linear']
}
# 创建SVC对象
svm = SVC()
# 创建GridSearchCV对象
grid = GridSearchCV(svm, param_grid, refit=True, verbose=2)
grid.fit(X_train, y_train)
# 打印最佳参数
print("最佳参数: ", grid.best_params_)