yolo简介
YOLO:通过卷积神经网络,和全卷积、9类别的输出格式,实现只需读取原图一次就能实现“多类别多目标”的一种端到端模型
其名字的意思为You Only Look Once,你只用看一次
何为端到端模型:
输入到输出之间没有任何预处理,直接由输入得到输出的模型
输出格式的不同:
MTCNN:(左上X,左上Y,右下X,右下Y)
YOLO: (中心X,中心Y,宽 ,高 )
这样的格式有利于后续作为全卷积输出时,输出结果的反算

YOLO找目标的方式:
①把图片等分为网格,找每一个网格里有无“中心点”
②在中心点网格中,推算宽高大小
————————————————————————————————————————————
网络结构
darknet53 + 三重输出层:
由特征提取能力很强的darknet53作为主干网络(其内部由残差+卷积下采样组成)
加上三层侦测网络组成。
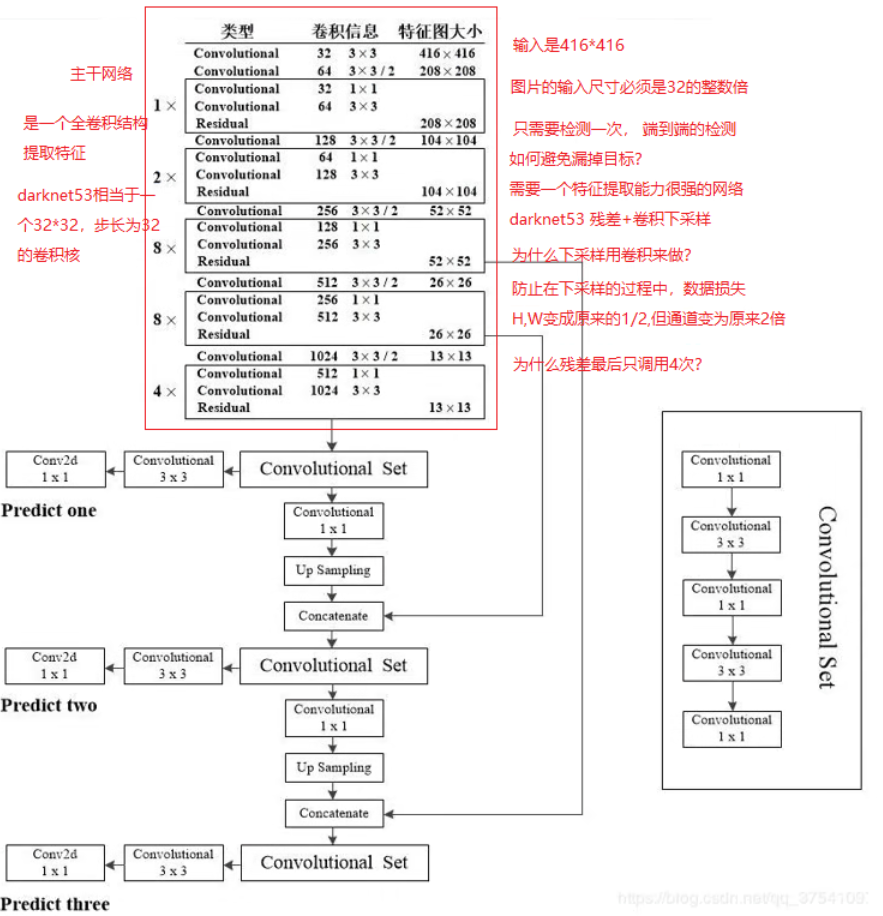
①特征提取网络(darknet):
结构上的特点:
1→2→8→8→4的结构保证了它的特征提取强度。但这也让其等价于一个32*32的卷积核,要求输入图片的大小必须为32的倍数
注意:最后一层的由8到4是因为此时特征图已经过小,继续深度卷积会导致特征丢失过多
同时在监测大目标时,会进行一次上采样,保证识别能力
②侦测网络:
侦测网络的三个输出,分别对应不同大小的目标(大目标、中目标、小目标)
YOLO快的原因也在于此:
所有目标大小只有三种:大、中、小目标
所有形状只有三种:正方形、躺长方形、立长方形

如此组合便有9种组合框
这九种框的具体形状、大小由kmeans算法(一种机器学习算法,用于聚类)对标签中所有目标点进行聚类计算,找出3种最普遍出现的形状,来作为网络的三种输出形状
③kmeans的优化:
由于默认的kmeans使用欧式距离(绝对距离)来计算聚类结果,这导致它在离原点越远的地方偏移量越大。
为了避免这种问题,我们最终使用**(1 - IOU)**(IOU表示框与框之间的重合部分,重合部分越大,相似度越大)来进行聚类计算,这可以使聚类结果更有代表性
————————————————————————————————————————————
监测思路
YOLO解决多分类的方式:
改变输出结构为:
[N 3 15 H W]
即
[N 三种形状 (置信度、位置{偏移量}*4、分类数{10}) H W]
至此,便将图片分为了由三种大小,三种形状组成的网格。我们将在这9组网格中找出目标
①找出目标所在位置:
输出结构的0维度即为置信度©,它代表当前网格中“有待分类物体的可能性”。
我们取出出网格这一部分中,大于90%(0.9)的所有网格索引,便可找到所有目标网格
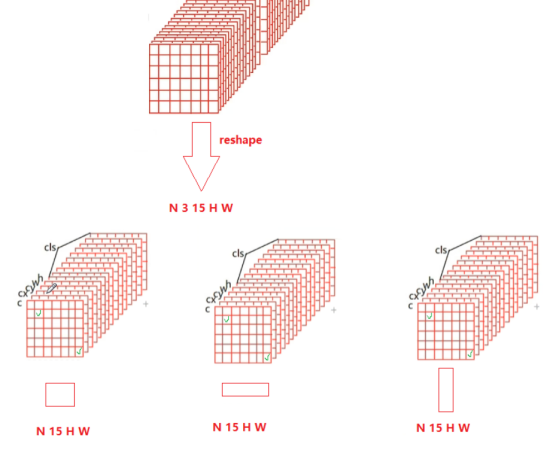
②中心点位置的反算:
找到目标所在网格后,此网格索引对应的1、2维度的数据,即是中心点位置的偏移量(cx, cy)
将此偏移量 * 网格的单位长度(由缩放比例决定),即可算出实际中心点位置
③宽高偏移量的特殊处理:
首先,由于计算结果是输出权重,而权重的分布是“正态分布”,是有正有负的!但宽高偏移量是只有正数的
为了避免此问题,在标签上将正确结果先对数化,将其定义域从(±∞)变为(0,+∞)即
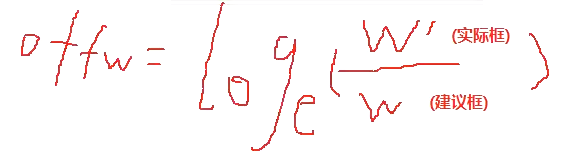
再在侦测时,把输出结果指数化还原

核心思路:先对数化解决正负分布问题,再在输出时将结果指数化还原
④输出结果:
通过上述三步,获取到以下信息:
- 目标形状(由输出层位置决定)
- 中心点位置(由缩放比例 * 张量所在索引决定)
- 宽高(由形状 * 偏移量决定)
即可确定目标位置
————————————————————————————————————————————
更新迭代
上述实现均为YOLOv3版本,后续版本中有部分做了优化
YOLOv4
- 马赛克增强:把多张训练图片合在一起,成为一张新图片,这张图片的目标位置也会重新计算,极大地增强了已有数据集
- 更换激活函数为Mish:一种将ReLU 和 tanh融合的激活函数。
强强联合,同时弥补了ReLU多阶导数=0 、tanh的激活能力较弱的问题。
Mish替换了所有的LeakyReLU,使YOLO的基础结构CBL(conv + batchNormal + LReLU)全部变为CBM(conv + batchNormal + Mish) - 更改损失函数为DIoU loss:将偏移量的损失函数从MSE变为DIOU loss——以外接矩形的大小 & 中心点间的欧氏距离来计算损失——来优化偏移量的精度。
- 结构变化——SPP(空间金字塔池化)【重要】: 先对一张图,进行不同大小的池化三次。再concat在通道层面连接起来。
注意:放在模型前面时,是没有增加感受野的功能的;必须放在模型后面。 用于提取特征,如果放在前面就只能提取原图了
YOLOv5
- Focus(类似空洞卷积): 相当于切片操作,把图片缩小为原来的一半,通道变深。用于增加感受野