Node(工程化)
一、Node是什么
官方对Node.js的定义:Node.js是一个基于V8 JavaScript引擎的JavaScript运行时环境。
- 中文网:https://nodejs.org/zh-cn/
- Node.js基于V8引擎来执行JavaScript的代码
- 在Node.js中我们也需要进行一些额外的操作,比如文件系统读/写、网络IO、加密、压缩解压文件等操作
- 在Chrome浏览器中,还需要解析、渲染HTML、CSS等相关渲染引擎,另外还需要提供支持浏览器操作的API、浏览器自己的事件循环等
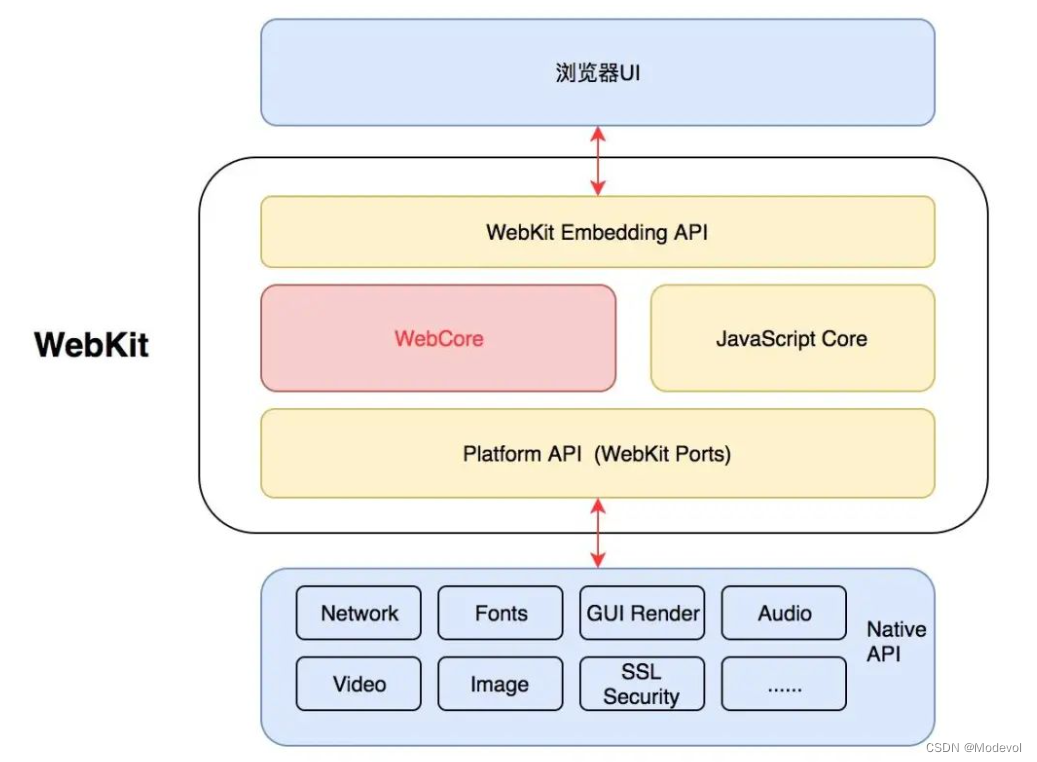
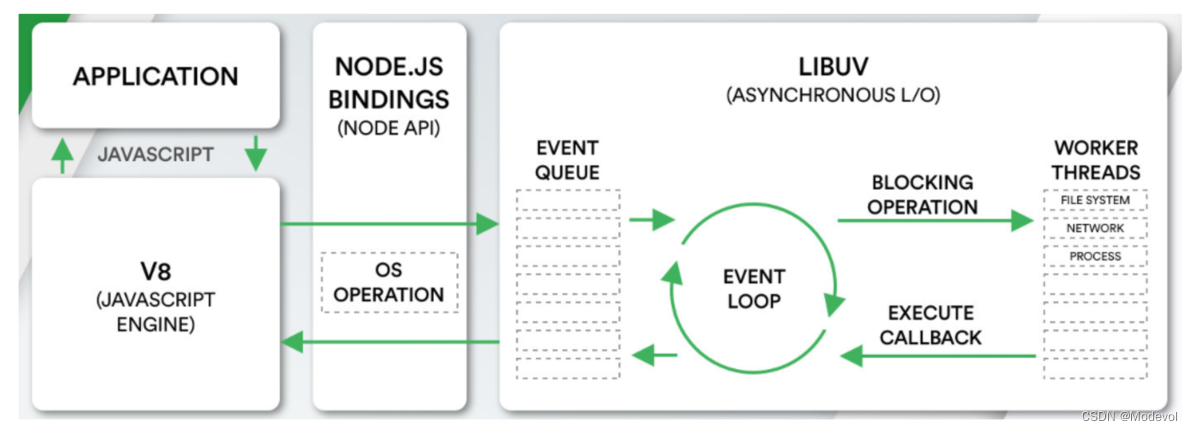
- Node的构架
- 我们编写的JavaScript代码会经过V8引擎,再通过Node.js的Bindings,将任务放到Libuv的事件循环中;
- libuv(Unicorn Velociraptor—独角伶盗龙)是使用C语言编写的库;
- libuv提供了事件循环、文件系统读写、网络IO、线程池等等内容;
Node的应用场景
- 前端开发的库都是以node包的形式进行管理,后面会学习大量的库
- npm、yarn工具成为前端开发使用最多的工具
- 使用Node.js作为web服务器开发、中间件、代理服务器
- 服务端渲染,借助Node.js完成前后端渲染的同构应用
- 使用Node可以编写一些脚本工具
- 使用Electron来开发桌面应用程序,是需要使用Node
- Node也可以开API接口
Node安装和管理
Node.js是在2009年诞生的,目前最新的版本是分别是LTS 16.15.1以及Current 18.4.0
- LTS版本:(Long-term support, 长期支持)相对稳定一些,推荐线上环境使用该版本,建议选择此版本
- Current版本:最新的Node版本,包含很多新特性
- 安装
- 直接下载对应的安装包下载安装
- window选择.msi安装包,Mac选择.pkg安装包
- 安装过程中会配置环境变量
- 会自动安装npm(Node Package Manager)工具
Node的版本工具
可以在电脑上安装不同版本的Node,使用时,可以切换不同的版本。
- nvm:Node Version Manager
- 通过 nvm install latest 安装最新的node版本
- 通过 nvm list 展示目前安装的所有版本
- 通过 nvm use 切换版本
Node环境中运行JS代码
- 两个环境,可以运行JS代码
- 浏览器
- node环境
- (可以通过终端命令node js文件的方式来载入和执行对应的js文件)
- 安装vscode插件,code runner插件来,运行JS代码。
- 传递参数
执行node程序的过程中,可以给node传递一些参数- node index.js env=development wangcai
- 在程序中通过process内置对象可以获取到传递的参数
- 在process内置对象的argv属性中存储着我们写的参数
// 03-运行代码传递参数.js
let a = 110;
let b = 220;
console.log(a+b);
console.log(process.argv[2]);
console.log(process.argv[3]);
console.log(process.argv[4]);
Node的全局对象
Node中给我们提供了一些全局对象,方便我们进行一些操作
- 全局对象实际上是模块中的变量,只是每个模块都有,看来像是全局变量
包括:__dirname、__filename、exports、module、require()- __dirname
获取当前文件所在的路径,不包括后面的文件名 - __filename
获取当前文件所在的路径和文件名称,包括后面的文件名称 - process对象
process提供了Node进程中相关的信息,如Node的运行环境、参数信息等 - console对象
提供了简单的调试控制台,在前面讲解输入内容时已经学习过了 - 定时器函数
- setTimeout
- setInterval
- setImmediate,与setTimeout(callback, 0)是有区别的,在事件环阶段会讲
- process.nextTick,添加到下一次tick队列中(微任务)
- process对象
process提供了Node进程中相关的信息,如Node的运行环境、参数信息等
- __dirname
// D:\录课\20220606\17-工程化之node\code\01-node初识
// console.log(__dirname);
// D:\录课\20220606\17-工程化之node\code\01-node初识\05-全局对象.js
// console.log(__filename);
// process 是进程的意思
// process.argv 得到运行JS文件,传递的参数
// console.log(process.argv);
// 定时器
// console.log("start...");
// // Immediate 立即的意思 宏任务
// setImmediate(()=>{
// console.log("setImmediate...");
// })
// console.log("end...");
console.log("start...");
setImmediate(()=>{
console.log("setImmediate...");
})
// 微任务
process.nextTick(()=>{
console.log("nextTick...");
})
console.log("end...");
global对象
global是一个全局对象,事实上前面我们提到的process、console、setTimeout等都有被放到global中
- 在新的标准中还有一个globalThis,也是指向全局对象的
- 类似于浏览器中的window
- 在浏览器中,全局变量都是在window上的,比如有document、setInterval、setTimeout、alert、console等
- 在Node中,我们也有一个global属性,并且看起来它里面有很多其他对象
- 浏览器中var声明的全局变量,会挂载到window上,node中var声明的变量,不会挂载到global上
// 在浏览器环境中有一个window
// 在node环境中是没有window
// console.log(window);
// 在node环境有,也有一个全局对象,是global
// console.log(global);
// 为了统一,提出了一个叫globalThis关键字
// globalThis在node环境中代表global
// globalThis在浏览器环境中代表window
// console.log(globalThis === global); // true
var a = 110;
// 在node环境中定义的全局变量,并不会挂载到global上
console.log(global.a);
内置模块path
- Linux和window上的路径时不一样的
- window上会使用 \ 或者 \ 来作为文件路径的分隔符,当然目前也支持 /
- Linux,Unix操作系统上使用 / 来作为文件路径的分隔符
- 如果我们在window上使用 \ 来作为分隔符开发了一个应用程序,要部署到Linux就可以出现问题
- 为了屏蔽他们之间的差异,在开发中对于路径的操作我们可以使用 path 模块
- path模块用于对路径和文件进行处理,提供了很多方法
常见API- dirname:获取文件的父文件夹
- basename:获取文件名
- extname:获取文件扩展名
- path.join:路径的拼接
- path.resolve:把一个路径或路径片段的序列解析为一个绝对路径
二、JS模块化开发
什么是模块化开发
模块化(组件化)指的就是将一个大的功能拆分为一个一个小的模块,通过不同的模块的组合来实现一个大功能。
- 在node中一个 js 文件就是一个模块
- 模块内部代码对于外部来说都是不可见的,可以通过两种方式向外部暴露
- 优点:1.复用性 2.维护性
早期使用IIFE解决命名冲突问题,但也有新的问题
- 第一,我必须记得每一个模块中返回对象的命名,才能在其他模块使用过程中正确的使用
- 第二,代码写起来混乱不堪,每个文件中的代码都需要包裹在一个匿名函数中来编写;
- 第三,在没有合适的规范情况下,每个人、每个公司都可能会任意命名、甚至出现模块名称相同的情况;
// a.js
// let name = "wc";
// let age = 18;
// function sum(){
// return 110
// }
let moduleA = (function(){
let name = "wc";
let age = 18;
function sum(){
return 110
}
return {
name,
age,
sum
}
}())
// b.js
// let name = "xq";
// let age = 28;
// function sum(){
// return 220
// }
let moduleB = (function(){
let name = "xq";
let age = 28;
function sum(){
return 220
}
return {
name,
age,
sum
}
}())
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<!-- 一个script标签就是一个代码段 -->
<script src="./a.js"></script>
<!-- b.js中的数据,污染了a.js中的数据 -->
<script src="./b.js"></script>
<script>
// 下面的代码段可以使用上在的代码段提供的数据
console.log(moduleA.name);
console.log(moduleA.age);
console.log(moduleB.name);
console.log(moduleB.age);
</script>
</body>
</html>
JavaScript社区为了解决上面的问题,涌现出一系列好用的规范,接下来我们就学习具有代表性的一些规范
- AMD、CMD、CommonJS
- JavaScript本身,直到ES6(2015)才推出了自己的模块化方案
CommonJS和Node
CommonJS是一个规范,简称为CJS,Node是CommonJS在服务器端一个具有代表性的实现
- CommonJS是规范,Node在服务器端实现了这个规范
- Browserify是CommonJS在浏览器中的一种实现
- webpack打包工具具备对CommonJS的支持和转换
CommonJS规范要求
- 在Node中每一个js文件都是一个单独的模块
- 模块中包括CommonJS规范的核心变量:exports、module.exports、require,使用这些变量来方便的进行模块化开发
- exports和module.exports可以负责对模块中的内容进行导出
- require函数可以帮助我们导入其他模块(自定义模块、系统模块、第三方库模块)中的内容
导出
exports导出
- exports是一个对象,我们可以在这个对象中添加很多个属性,添加的属性会导出
- 另外一个文件中可以导入,require通过各种查找方式,最终找到了exports这个对象,将这个exports对象赋值给一个变量
module.exports导出
- CommonJS中是没有module.exports的概念的
- 但是为了实现模块的导出,Node中使用的是Module的类,每一个模块都是Module的一个实例,也就是module
- 所以在Node中真正用于导出的其实根本不是exports,而是module.exports,module才是导出的真正实现者
- 之所以exports也可以导出,是因为module对象的exports属性是exports对象的一个引用
- 就是说 module.exports = exports = main中的bar
require函数解析
require是一个函数,可以帮助我们引入一个文件(模块)中导出的对象
- 模块在被第一次引入时,模块中的js代码会被运行一次
- 模块被多次引入时,会缓存,最终只加载(运行)一次
- 深度优先算法进行加载
情况一:X是一个Node核心模块,比如path、http
- 直接返回核心模块,并且停止查找
情况二:X是以 ./ 或 …/ 或 /(根目录)开头的
- 第一步:将X当做一个文件在对应的目录下查找
- 如果有后缀名,按照后缀名的格式查找对应的文件
- 如果没有后缀名,会按照如下顺序
- 1,直接查找文件X
- 2,查找X.js文件
- 3,查找X.json文件
- 4,查找X.node文件
- 第二步:没有找到对应的文件,将X作为一个目录
- 查找目录下面的index文件
- 1,查找X/index.js文件
- 2,查找X/index.json文件
- 3,查找X/index.node文件
- 查找目录下面的index文件
- 如果没有找到,那么报错:not found
情况三:直接是一个X(没有路径),并且X不是一个核心模块
- 会在用户电脑上查找这个第三方模块,会在多个地方查找,如果找不到,就报错
CommonJS规范缺点
CommonJS加载模块是同步的
- 同步的意味着只有等到对应的模块加载完毕,当前模块中的内容才能被运行
- 在服务器不会有什么问题,因为服务器加载的js文件都是本地文件,加载速度非常快
- 所以它应用在浏览器,同步的就意味着后续的js代码都无法正常运行,即使是一些简单的DOM操作
- 所以在浏览器中,我们通常不使用CommonJS规范
- 早期为了可以在浏览器中使用模块化,通常会采用AMD或CMD
- 但是目前一方面现代的浏览器已经支持ES Modules,AMD和CMD已经使用非常少了
ESModule用法详解
ECMA推出自己的模块化系统,弥补了JavaScript没有模块化
- CommonJS、AMD、CMD等,仅仅是JS社区的规范,并不是官方的
- 采用ES Module将自动采用严格模式:use strict
ES Module模块采用export和import关键字来实现模块化
- export负责将模块内的内容导出
- import负责从其他模块导入内容
浏览器中演示ES6的模块化开发(需要在服务器端来测试)
<script src="./modules/foo.js" type="module"></script>
<script src="main.js" type="module"></script>
exports关键字
- export关键字将一个模块中的变量、函数、类等导出
- 方式一:在语句声明的前面直接加上export关键字
- 方式二:将所有需要导出的标识符,放到export后面的 {}中(这里的 {}里面 不是ES6的对象字面量的增强写法,{}也不是表示一个对象的)
- 方式三:导出时给标识符起一个别名,通过as关键字起别名
import关键字
- import关键字负责从另外一个模块中导入内容
- 方式一:import {标识符列表} from ‘模块’,这里的{}也不是一个对象,里面只是存放导入的标识符列表内容
- 方式二:导入时给标识符起别名,通过as关键字起别名
- 方式三:通过 * 将模块功能放到一个模块功能对象(a module object)上
export和import结合使用
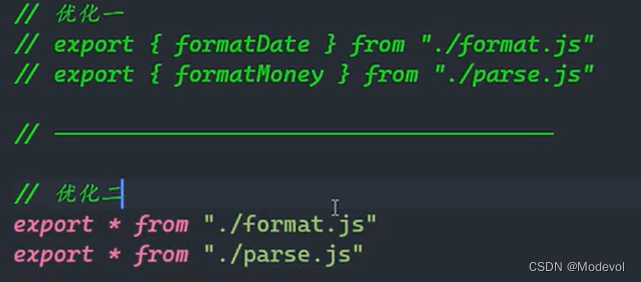
在开发和封装一个功能库时,通常我们希望将暴露的所有接口放到一个文件中,这样方便指定统一的接口规范,也方便阅读
default用法
默认导出(default export)
- 默认导出export时可以不需要指定名字
- 在导入时不需要使用 {},并且可以自己来指定名字
- 在一个模块中,只能有一个默认导出(default export)
import函数
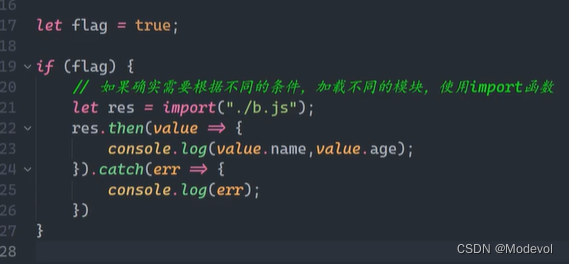
通过import加载一个模块,是不可以在其放到逻辑代码中的,ES Module在被JS引擎解析时,就必须知道它的依赖关系,这个时候js代码没有任何的运行,所以无法在进行类似于if判断中根据代码的执行情况
动态的来加载某一个模块
- 如果根据不同的条件,动态来选择加载模块的路径
- 使用 import() 函数来动态加载
- import函数返回一个Promise,可以通过then获取结果
总结
<!--
commonjs规范
1)只要是一个文件,都是一个模块,模块与模块之间天生隔绝,天生就不会相互污染。
2)你定义的模块中有数据,你想让别人使用,你需要把数据导出去。
3)你想用别人的模块,你需要导入
导出方案一、
exports.name=lc
exports.age=18
导出方案二、
moudle.exports.name=lc
moudle.exports.age=18
//在源码中,exports和moudle.exports指向了同一个对象,执行同一个堆
//exports=moudle.exports
导出方案三、(常用
moudle.exports={
name,age
}
导入
通过require导入
模块分三类
1)自定义模块,a.js
require('./a.js')必须以./或../开头
2)系统模块 node中提供好的模块,不需要下载,也叫核心模块
require("http") require("path") 不能以./或../打头
3)第三方模块
npm install jquery
第三方模块, 不能以./或../打头
-->
<!--
ES6Module规范
规范:
1)每一个文件,都是一个模块,模块与模块之间天生隔离
2)你想让别人使用你的数据,你就需要导出去
2)你想用别人的数据,你就是导进来
导出方案一、
通过export导出数据,导出的是标识符
export let name = lc;
export let age = 18;
导出方案二、批量导出
let name=lc;
let age=18;
//导出的是标识符列表
export{
name,age
}
导入
导入是通过import xx form xx
如果是自定义模块,也是必须以./或../打头
import 后面的 { }不是结构赋值,{}中放标识符
node使用的是commonjs规范
在node环境中直接使用es6规范就直接报错,node不认识
import { name, age } from "./a.js"
导入时起别名:import { name as username, age as userage } from "./a.js"
//使用时用别名
需要在浏览器运行,type='module'告诉浏览器开启模块化
需要使用live server,http:
导出方式三、默认导出
如果一个模块中,只有一个数据,可以使用默认导出
导出的话,是通过 export default
export default obj
默认导入
导入时,不需要写标志符列表{}
improt 后面写一个变量名,变量名是它导出的数据
变量名随便写
import xxx from "./a.js"
当多个文件时,可以建个index.js导出文件
export * from "./formatTime.js"
export * from "./formatMoney.js"
在main.js导入
import { formatTime, formatMoney, a, b, c } from "./tools/index.js"
注意:improt不能写在条件中,只能位于一个模块的最面的
可以用improt()方法
if(true){
let res= import("./a.js")
res.then(value=>{
console.log(1111)
}).
catch(err=>{
console.log(222)
})
}
//此处的await在最新的语法中,不需要写async
if(true){
try{
let res=await import("./a.js")
console.log(1111)
}catch(err=>{
console.log(222)
})
}
-->
三、包管理工具
----------------------------------
自己生成package.json文件:
通过npm init -y
后面安装的第三方依赖,都会记录到这个配置文件中,安装:npm i jquery
看一下配置文件: dependencies依赖的意思
"dependencies": {
"jqeury": "^0.0.1-security"
}
npm i jquery 这样安装,安装的是一个生产依赖
----------------------------------
依赖分两类:
1)生产依赖(安装到项目中):
开发项目过程中和项目上线,都需要的依赖
npm i jquery
npm i vue -S 指定是生产依赖
npm i react --save 指定是生产依赖
2)开发依赖(安装到项目中):
只在开发项目过程中使用的依赖
npm i less -D 指定开发依赖
npm i sass --save-dev 指定开发依赖
----------------------------------
全局安装一些依赖(全局依赖,工具),这些依赖是安装到电脑上的,当成一个工具使用的:
npm i nrm -g -g表示全局安装 说白了,就是安装一个工具
nrm工具:换源
上面通过npm i xxx 下载的依赖是从国外下载的,可能会被墙掉。nrm就是用来换下载源
nrm ls 查看都有哪些下载源
nrm use taobao 就可以把下载源切换到国内的taobao
----------------------------------
npm包管理工具
- Node Package Manager,也就是Node包管理器,也是一个应用程序
- Node.js 的包基本遵循 CommonJS 规范,将一组相关的模块组合在一起,形成一个完整的工具
- npm属于node的一个管理工具,安装Node时,已帮我们安装好了
- 通过 NPM 可以对 Node 的工具包进行搜索、下载、安装、删除、上传。借助别人写好的包,可以让我们的开发更加方便
- where npm 该命令可以查看 npm 安装的位置
- 一般在搜索工具包的时候,会到 https://npmjs.org 搜索
- 安装一个包时其实是从registry(NPM仓库)上面下载的包
- 发布自己的包其实是发布到registry(NPM仓库)上面的
package配置文件
一个项目,有非常多的包,我们需要通过一个配置文件(package.json)来管理这些包
- 每一个项目都会有一个对应的配置文件,无论是前端项目(Vue、React)还是后端项目(Node)
- 配置文件会记录着你项目的名称、版本号、项目描述,项目所依赖的其他库的信息和依赖库的版本号
生成配置文件
- 方式一:npm init –y
- 方式二:通过脚手架创建项目,脚手架会帮助我们生成package.json
{
"name": "1-npm", #包的名字(注意生成的包名不能使用中文,大写 !!! 不能使用 npm 作为包的名字)
"version": "1.0.0", #包的版本
"description": "", #包的描述
"main": "index.js", #包的入口文件
"scripts": { #脚本配置
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "", #作者
"license": "ISC" #版权声明
}
package.json常见的属性
- name是项目的名称,必填
- version是当前项目的版本号,必填
- description是描述信息,很多时候是作为项目的基本描述
- author是作者相关信息(发布时用到)
- license是开源协议(发布时用到)
- http://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html(关于开源证书扩展阅读)
- private属性记录当前的项目是否是私有的,当值为true时,npm是不能发布它的,这是防止私有项目或模块发布出去的方式
- main属性,设置程序的入口,实际上是找到对应的main属性查找文件的
- scripts属性用于配置一些脚本命令,以键值对的形式存在,配置后我们可以通过 npm run 命令的key来执行这个命令
- npm start和npm run start 它们是等价的,对于常用的 start、 test、stop、restart可以省略掉run直接通过 npm start等方式运行;
- dependencies属性
- dependencies属性是指定无论开发环境还是生成环境都需要依赖的包
- 项目实际开发用到的一些库模块vue、vuex、vue-router、react、react-dom、axios等
- devDependencies属性
- 在生成环境是不需要的,比如webpack、babel等
- 通过 npm install webpack --save-dev,将它安装到devDependencies属性中
依赖的版本管理(版本规范是X.Y.Z)
- X主版本号(major):当你做了不兼容的 API 修改(可能不兼容之前的版本)
- Y次版本号(minor):当你做了向下兼容的功能性新增(新功能增加,但是兼容之前的版本)
- Z修订号(patch):当你做了向下兼容的问题修正(没有新功能,修复了之前版本的bug)
- x.y.z:表示一个明确的版本号
- ^x.y.z:表示x是保持不变的,y和z永远安装最新的版本
- ~x.y.z:表示x和y保持不变的,z永远安装最新的版本
- package-lock.json 是包版本的锁文件,专门来固定包的版本的,不要手动修改
npm install(安装npm包分两种情况)
- 搜索包: npm search jquery (npm s jquery)
- 全局安装(global install): npm install webpack -g
- 全局安装是直接将某个包安装到全局
- 全局安装命令在任意的命令行下, 都可以执行
- 全局命令的安装位置 C:\Users\你的用户名\AppData\Roaming\npm\node_modules
- 通常使用npm全局安装的包都是一些工具包:yarn、webpack等
- 全局安装axios之后并不能让我们在所有的项目中使用 axios等
- 局部安装(local install): npm install webpack
- 项目安装会在当前目录下生成一个 node_modules 文件夹
- 局部安装分为开发时依赖和生产时依赖
- npm install(i) axios 默认安装开发和生产依赖
- npm install(i) axios --save(-S) 生产依赖
- npm install(i) webpack --save-dev(-D) 开发依赖
- npm install(i) 安装package.json中的依赖包
- npm install(i) --production // 只安装 dependencies 中的依赖
- npm remove jquery 移除包
换源
- 某些情况下我们没办法很好的从 https://registry.npmjs.org下载下来一些需要的包
- 查看npm镜像 npm config get registry
- 设置npm镜像 npm config set registry https://registry.npm.taobao.org
npm其他命令之卸载某个依赖包
- npm uninstall package
- npm uninstall package --save-dev
- npm uninstall package -D
npm其他命令之清除缓存
- npm cache clean
npm更多命令
- https://docs.npmjs.com/cli-documentation/cli
yarn、cnpm、npx
yarn是由Facebook、Google、Exponent 和 Tilde 联合推出了一个新的 JS 包管理工具
- yarn 是为了弥补 早期npm 的一些缺陷而出现的
- 早期的npm存在很多的缺陷,比如安装依赖速度很慢、版本依赖混乱等等一系列的问题
- 从npm5版本开始,进行了很多的升级和改进,但是依然很多人喜欢使用yarn
- yarn 安装 npm install yarn -g
- yarn 修改仓库地址 yarn config set registry https://registry.npm.taobao.org
yarn 的相关命令
1) yarn --version 检测是否安装成功
2) yarn init 初始化,生成package.json
3) yarn global add package 全局安装
4) yarn global remove less 全局删除
5) yarn add package 局部安装
6) yarn add package --dev (相当于npm中的-D)
7) yarn remove package 删除局部包文件
8) yarn list 列出已经安装的包名 用的很少
9) yarn info packageName 获取包的有关信息 几乎不用
10) yarn 安装package.json中的所有依赖
不想修改npm原本从官方下载包的渠道,可以使用cnpm,并且将cnpm设置为淘宝的镜像
- npm install -g cnpm --registry=https://registry.npm.taobao.org
- cnpm config get registry
npx工具
- npx是npm5.2之后自带的一个命令,使用它来调用项目中的某个模块的指令
- npx的原理非常简单,它会到当前目录的node_modules/.bin目录下查找对应的命令
局部命令的执行
- 方式一:在终端中使用如下命令(在项目根目录下) ./node_modules/.bin/webpack --version
- 方式二:修改package.json中的scripts “webpack”: “webpack --version”
- 方式三:使用npx npx webpack --version
发布自己的开发包
流程
- 修改为官方的地址 ( npm config set registry https://registry.npmjs.org/ )
- 创建文件夹,并创建文件 index.js, 在文件中声明函数,使用 module.exports 暴露
- npm 初始化工具包,package.json 填写包的信息 (越复杂越容易提上去)
- 账号npm注册(激活账号),完成邮箱验证
- 命令行下 『npm login』 填写相关用户信息 (一定要在包的文件夹下运行)
- 命令行下『 npm publish』 提交包 👌
- npm 有垃圾检测机制,如果名字简单或做测试提交,很可能会被拒绝提交,可以尝试改一下包的名称来解决这个问题
四、网络理论
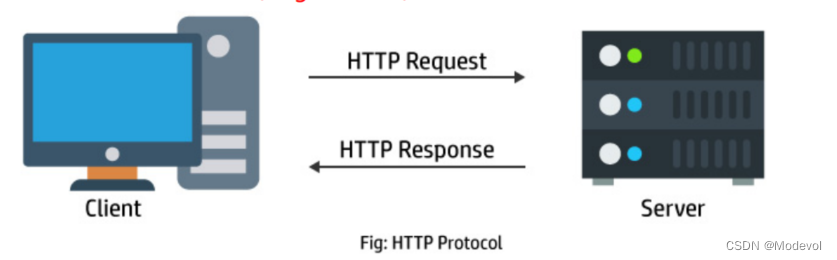
客户端和服务器
- 客户端: Client 客户所使用的电脑中安装的应用程序。
- 服务端: Server 存放网页,客户端程序,数据处理程序,数据库的电脑。
- 客户端(网页浏览器、网络爬虫或者其它的工具)作用
- 发起一个HTTP请求到服务器上指定端口(默认端口为80)
- 我们称这个客户端为用户代理程序(user agent)
- 服务端作用
- 响应的服务器上存储着一些资源,比如HTML文件和图像
- 我们称这个响应服务器为源服务器(origin server)
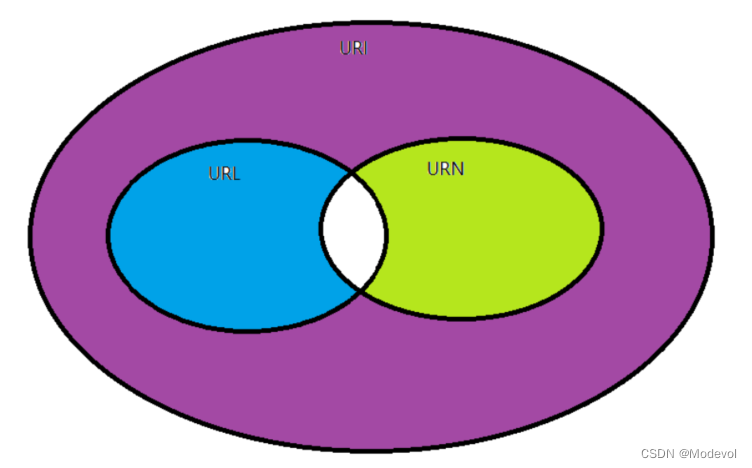
URI
URI
- Uniform Resource Identifier 统一资源标识符,用来唯一标识一个资源
URL
- Uniform Resource Locator 统一资源定位符,用来唯一标识一个资源
- URL也可以用来标识一个资源,而且它还可以指明如何定位资源
URN
- Uniform Resource Name 统一资源命名 通过名字表示资源
URL肯定是一个URI,URI并不一定是URL,也有可能是URN,URL与URN是URI的子集
URL作用
- 资源标识
- 有定位资源的功能
- 指明了获取资源所采用的协议
URL格式
- 协议名称 + 主机名称 + 端口号 + 路径 + 文件 + 查询所需的字符串 + HASH
- http:// baidu.com :80 /01/index.html ?a=1&b=2 #abc
- scheme:// host port path filename ?query hash
在浏览器地址栏输入一个URL到,到看到一张网页,发生了什么?
1)DNS解析: 得到IP地址
2)IP地址: 找到服务器
3)端口: 找到对应的服务器 80 web服务 网页服务
BS架构和CS架构
BS架构
- Browser/Server(浏览器/服务器), 利用浏览器去呈现界面,浏览器提供浏览器所需要的数据
- 优点:无需安装客户端软件,只需要有浏览器,无需升级客户端。
- 缺点:浏览器的兼容性可能有问题,功能性相对弱一点,安全性弱,交互性弱。
CS架构
- Client/Server 将应用程序放到一个软件中,可以是Android也可以是iOS,服务器给客户端软件提供它需要的数据。
- 优点:界面丰富,交互性强,响应速度快,安全性强。
- 缺点:开发成本高,需要下载安装,维护成本高,升级麻烦。
购买云服务器和域名
服务器分类
- 实体服务器:自己购买服务器。
- 云服务器:阿里云,华为云,JD云…
域名分类
- 通用类
- .com 工商金融企业
- .com.cn 公司
- .gov 政府
- .net 提供互联网网络服务机构
- .org 各类组织机构
- .edu 教育机制
- 国家地区分类
- .cn 中国
- .ca 加拿大
- .uk 英国
- .jp 日本
- 域名级别
- 顶级域名(一级域名) baiu.com 一般我们买的是一级域名,在一级域名下可以配 置N个二级域名
- 二级域名 zhidao.baidu.com image.baidu.com wenku.baidu.com tieba.baidu.com
- 三级域名 sport.news.baidu.com
- www.baidu.com 也是所谓的二级域名
www: world Wide Web 万维网
- Internet,叫因特网。这个因特网中提供非常多的服务,如www网页服务,ftp文件传输服务,E-mail电子邮件服务,Telnet远程登录服务…,www是浏览器访问网页的服务,所以说,很早之前,所有的网站主页域名前面都会加上www。后来,可以配置二域名和三级域名,不同的域名,就可以对应不同的业务,而业务处理任务会分配到不同的服务器,所以,不再需要使用www来标注主页了。但是加上www,已经成为一种习惯了,所以现在,很多网站都还会做DNS解析www,说到底还是尊重用户习惯。国外的网站基本上都不会使用www。
DNS解析
DNS:Domain Name Server(域名服务器)
- 作用:域名与对应的IP转化的服务器
- DNS中保存了一张域名与对应的IP地址的表,一个域名对应一个IP地址,一个IP地址可以对应多个域名
- 根据域名,通过DNS解析就可以得到一个IP 地址。就可以找到对应的服务器
IP地址和端口号
IP:Internet Protocol Address 互联网协议地址 IP地址
- 作用:分配给用户上网使用的互联网协议
- 分类:IPv4 IPv6
根据IP地址,就可以找到对应的服务器,服务器上可以提供N种服务器,你需要哪种服务呢?就需要根据端口号,来区分你需要哪种服务。
- 端口号范围:0~65535 0~1024是系统使用的 1025~65535之间
- 知名端口号:
- http协议下:80
- https协议下:443
- mysql: 3306
- FTP协议下:20 21…
TCP连接
TCP:transmission Control Protocol 传输控制协议
- 特点:在收发数据之前,必须建立可靠的连接。TCP就是可靠连接。UDP不可靠连接。
- 建立连接基础:三次握手
- 应用场景:HTTP请求(HTTP请求就是基于TCP的),FTP文件传输,邮件发送
- 优点:速度慢,稳定,重传机制
- 缺点:效率低,占用资源,容易被攻击
TCP 三次握手理解 (双方确认)(面试题)**
- TCP是一个端到端的 可靠 面相连接的协议
- HTTP基于传输层TCP协议不用担心数据传输的各种问题(当发生错误时,可以重传)
- 根据IP,找到对应的服务器,发起TCP的三次握手
- 如果没有三次握手,会浪费TCP服务器进程所在主机的很多资源。
关闭TCP连接四次挥手的理解 (客气挽留) - 不能直接一次性断开连接(双方知晓), 万一还有什么数据没有传完, 造成数据的丢失!
三次握手和四次挥手
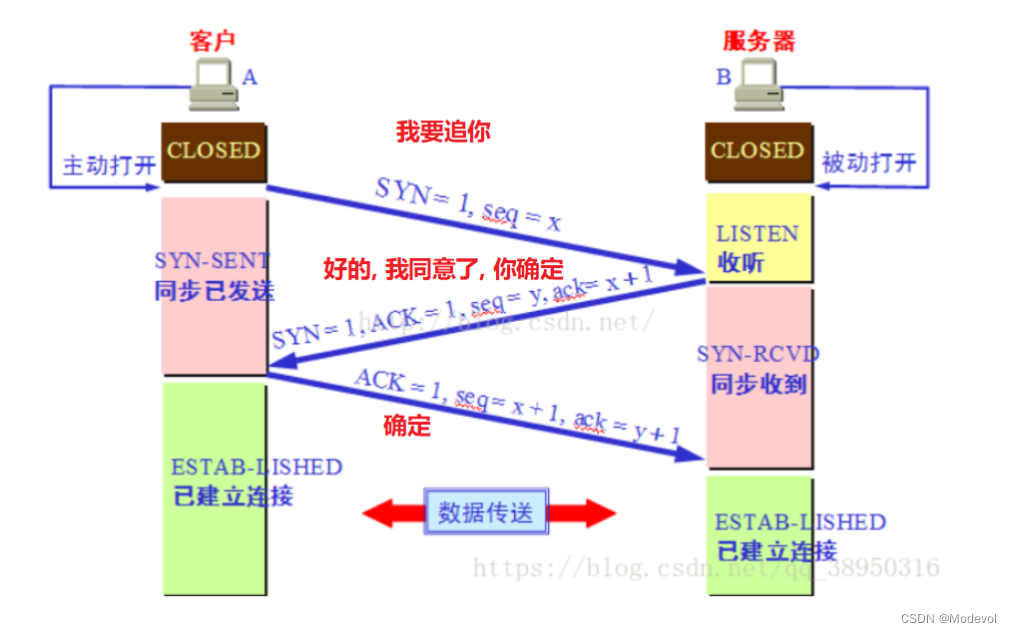
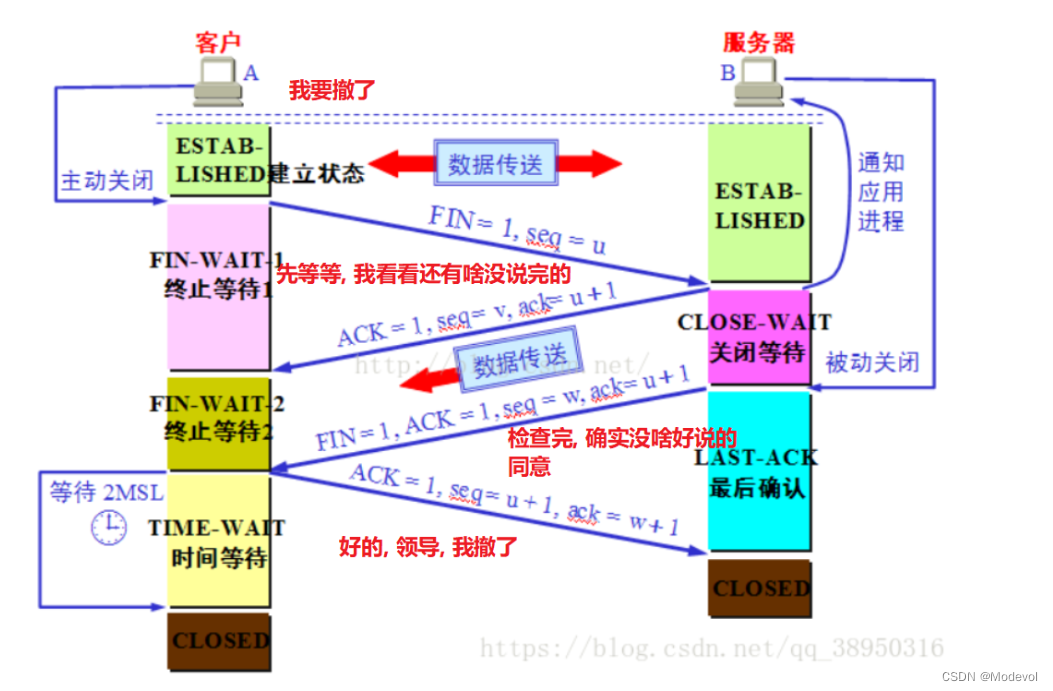
建立连接 => 三次握手 (双方确认)
(1) 服务器啊, 我是浏览器, 我要和你建立连接
(2) 服务器看到了, 好的, 那么建立连接吧, 我准备好了, 你确定吗?
(3) 浏览器: 是的, 我确定!
连接就建立成功,三次握手 = 连接的发起 + 双方的确认
断开连接 => 四次挥手 (客气挽留)
(1) 一方A发起断开连接的消息
(2) 另一方B会确认收到断开的需求, 但是会要求等一等, 确认是否数据传输完毕
(3) B当确认完之后, 确实数据都传完了, 告知A, 连接可以断开了
(4) A确认收到消息, 告知B, 我要走了
HTTP的概念(掌握)
HTTP:HyperText Transfer Protocol 超文本传输协议:
- 客户端和与服务器之间传递数据的规范
- HTTP请求:按照HTTP协议(规则),由客户端(浏览器)向服务器发出请求
- HTTP响应:按照HTTP协议(规则),由服务器给出响应
HTTPS: HyperText Transfer Protocol Secure 超文本传输安全协议。
- HTTP的安全版本(安全的基础是SSL/TLS)
- SSL: Secure Sockets Layer 安全套接层
- TLS:transport Layer Security 传输层安全
- 就是为了网络通信提供的一种安全协议,对网络连接进行加密
HTTP和HTTPS的区别
- HTTP是不安全 HTTPS可以防止攻击
- HTTP协议传输的内容是明文,直接在TCP连接上传递,客户端和服务器都无法验证对方的身份
- HTTPS协议的传输内容都是被SSL/TLS加密,且运行在SSL/TLS,SSL/TLS运行在TCP连接上,所以传递的数据是安全
HTTP报文(背会)
HTTP是基于TCP通信协议来传递数据。通过一个可靠的连接来交换信息。在交换信息之前,客户端和服务器之间需要有规则。
HTTP通信包含两部分
- HTTP请求 Request
- HTTP响应 Response
在HTTP请求和HTTP响应中,都包含了HTTP报文,报文也是一块数据,在客户端与服务器之间发送的数据块。这些报文也是在客户端与服务器之间流行。所以HTTP报文也叫报文流。

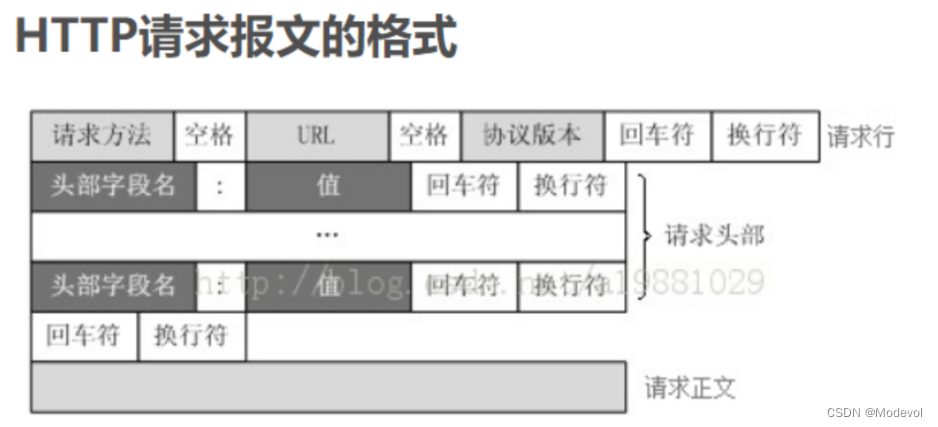
HTTP请求报文组成部分
- 对报文进行描述的起始行
- HTTP各种头(header),也叫http报文头,不同的头含义是不一样的
- 请求体(请求正文)(可选的),就是客户端给服务器的数据
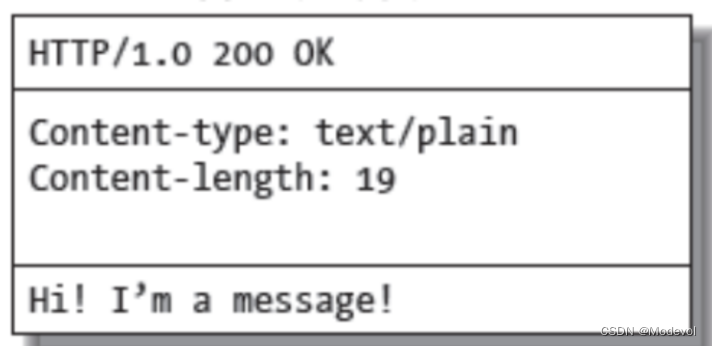
HTTP响应报文组成部分 - 响应行(起始行) HTTP/1.0 200表示状态码 OK叫状态描述符
- 响应头 header
- 响应体 服务器给客户端响应的数据

HTTP协议版本(掌握)
- HTTP/0.9
- 仅支持GET请求
- 仅能请求HTML资源
- 发布于1991年
- HTTP/1.0
- 增加了POST请求和HEAD请求
- 支持多种数据格式的请求和访问
- 添加了缓存的功能
- 增加了状态码,内容编码
- 浏览器的每次请求都需要与服务器建立一个TCP连接,请求处理完成后立即断开TCP连接,每次建立连接增加了性能损耗
- 也就是说早期的HTTP1.0是不支持长连接(持久化连接)的,只支持串行连接
- 后期的HTTP1.0添加了Connection:keep-alive字段,开始支持持久化连接
- 发布于1996年
- HTTP/1.1(目前使用最广泛的版本)
- 采用持久连接(Connection: keep-alive),多个请求可以共用同一个TCP连接
- 增加PUT/PATC/OPTION/DELETE等请求方式
- 增加了host字段,指定服务器域名
- 增加了100状态码,支持只发送头信息
- 支持内容传递,只传递一部分和文件断点继传
- 发布于1997年;
- HTTP/2.0
- 增加了双工模式 客户端同时发送N个请求,服务器同时处理N个请求
- 服务器推送 服务器可以主动推送数据给客户端
- 发布于2015年
HTTP的请求方式
- GET:GET 方法请求一个指定资源的表示形式,使用 GET 的请求应该只被用于获取数据。
- HEAD:HEAD 方法请求一个与 GET 请求的响应相同的响应,但没有响应体。比如在准备下载一个文件前,先获取文件的大小,再决定是否进行下载;
- POST:POST 方法用于将实体提交到指定的资源。
- PUT:PUT 方法用请求有效载荷(payload)替换目标资源的所有当前表示;
- DELETE:DELETE 方法删除指定的资源;
- PATCH:PATCH 方法用于对资源应部分修改;
- CONNECT:CONNECT 方法建立一个到目标资源标识的服务器的隧道,通常用在代理服务器,网页开发很少用到。
- TRACE:TRACE 方法沿着到目标资源的路径执行一个消息环回测试。
在开发中使用最多的是GET、POST请求
GET,POST,PUT,DELETE就是CRUD,就是增删改查。
GET和POST - GET主要是用来获取数据
- GET也可以传递数据给服务器,通过查询字符串,就是在URL中把数据扔给服务器
- POST可以对数据进行添加,删除,修改,数据是放在FormData
GET和POST区别(面试题)
- post更安全:get请求是把数据放在url,每个人都可以看到,相对来说,不安全。
- get请求,数据放在url,url的长度是有限,get请求传递给服务器的数据大小是有限的
- post请求,传递给服务器的数据理论上来说是无限的
- get请求只能发送ASCII字符数据,post请求能发送更多的数据类型
- post比get速度慢,post接收数据之前会先将请求头发送给服务器确认,然后发送数据
- get请求会进行数据缓存,post没有
GET过程
- 第三次握手,浏览器确认并发送请求头和数据
- 服务器返回200 OK响应
POST过程
- 第三次握手,浏览器确认并发送post请求头
- 服务器返回状态码100后,continue响应
- 浏览器开始扔数据到服务器
- 服务器返回200 OK响应
Request Header
在request对象的header中也包含很多有用的信息,客户端会默认传递过来一些信息
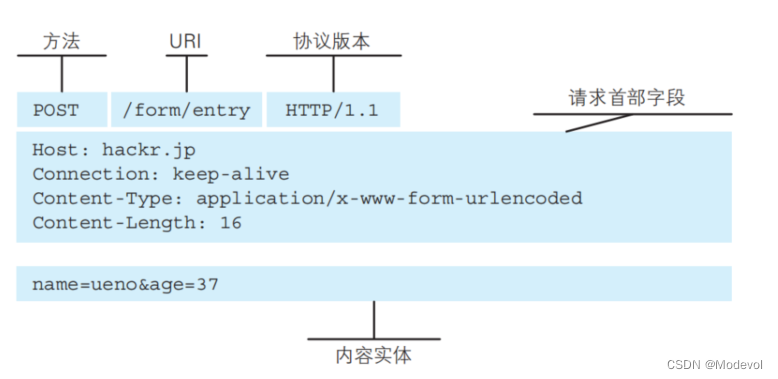
content-type是这次请求携带的数据的类型
- application/x-www-form-urlencoded:表示数据被编码成以 ‘&’ 分隔的键 - 值对,同时以 ‘=’ 分隔键和值
- application/json:表示是一个json类型;
- text/plain:表示是文本类型;
- application/xml:表示是xml类型;
- multipart/form-data:表示是上传文件;
content-length
- 文件的大小长度
keep-alive
- http是基于TCP协议的,但是通常在进行一次请求和响应结束后会立刻中断
- 在http1.0中,如果想要继续保持连接
- 浏览器需要在请求头中添加 connection: keep-alive
- 服务器需要在响应头中添加 connection:keey-alive
- 当客户端再次放请求时,就会使用同一个连接,直接一方中断连接
- 在http1.1中,所有连接默认是 connection: keep-alive的
- 不同的Web服务器会有不同的保持 keep-alive的时间
- Node中默认是5s中
accept-encoding
- 告知服务器,客户端支持的文件压缩格式,比如js文件可以使用gzip编码,对应 .gz文件
accept - 告知服务器,客户端可接受文件的格式类型
user-agent - 客户端相关的信息
HTTP Request Header 请求头
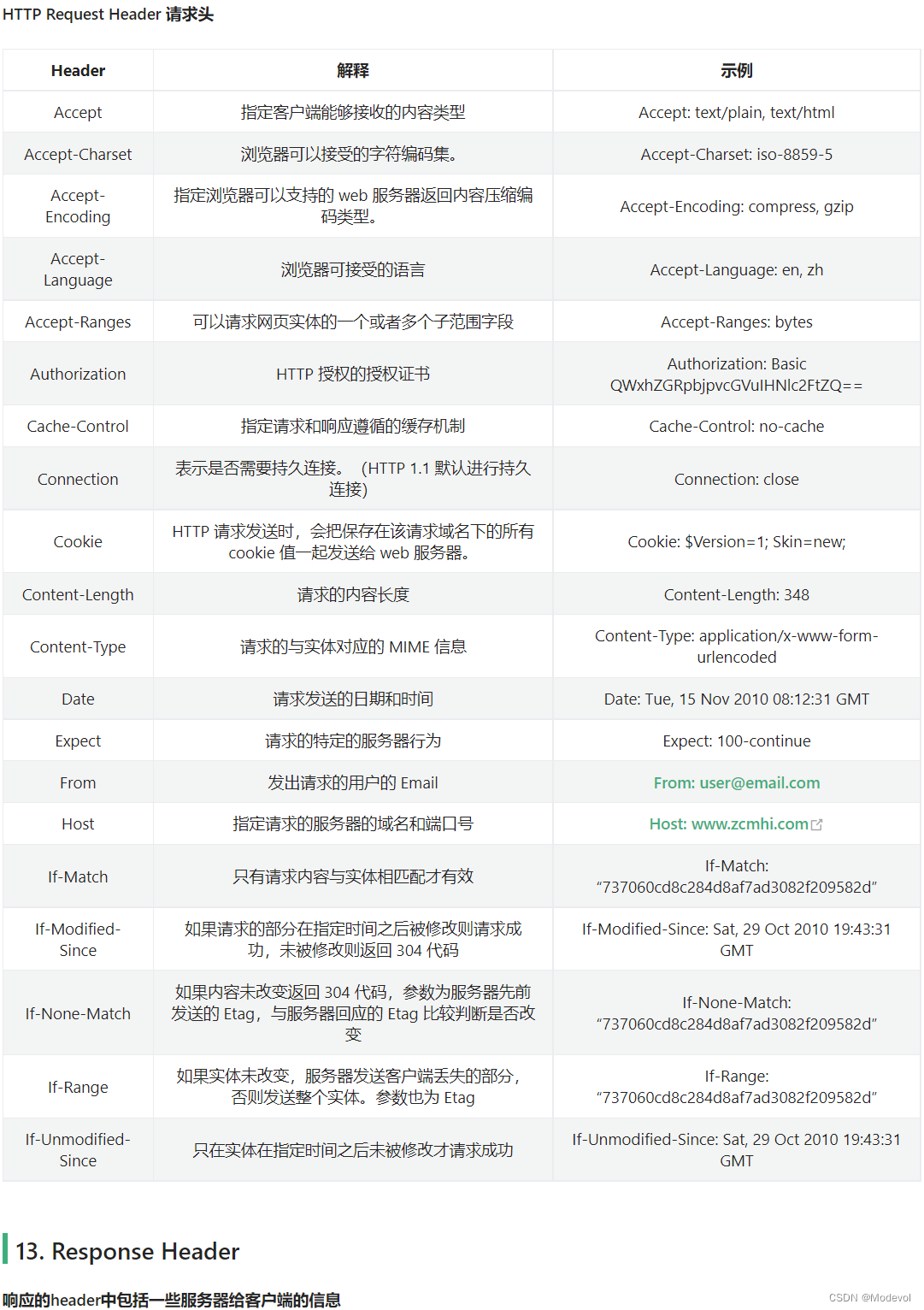
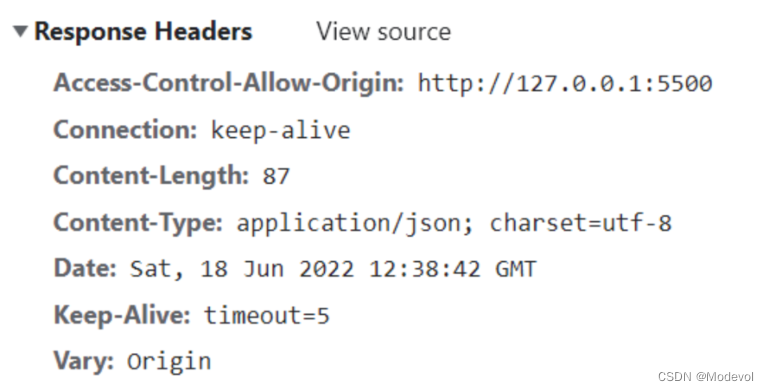
Response Header
响应的header中包括一些服务器给客户端的信息
CSDN响应头
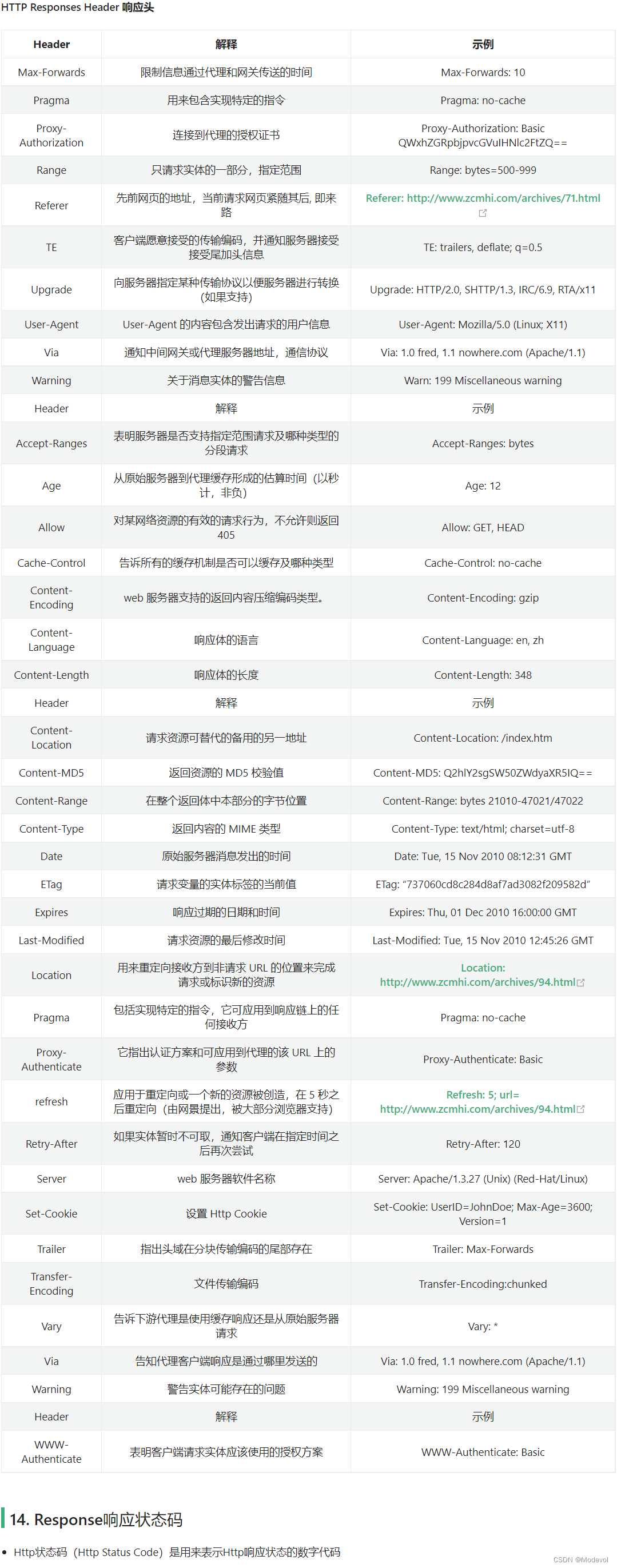
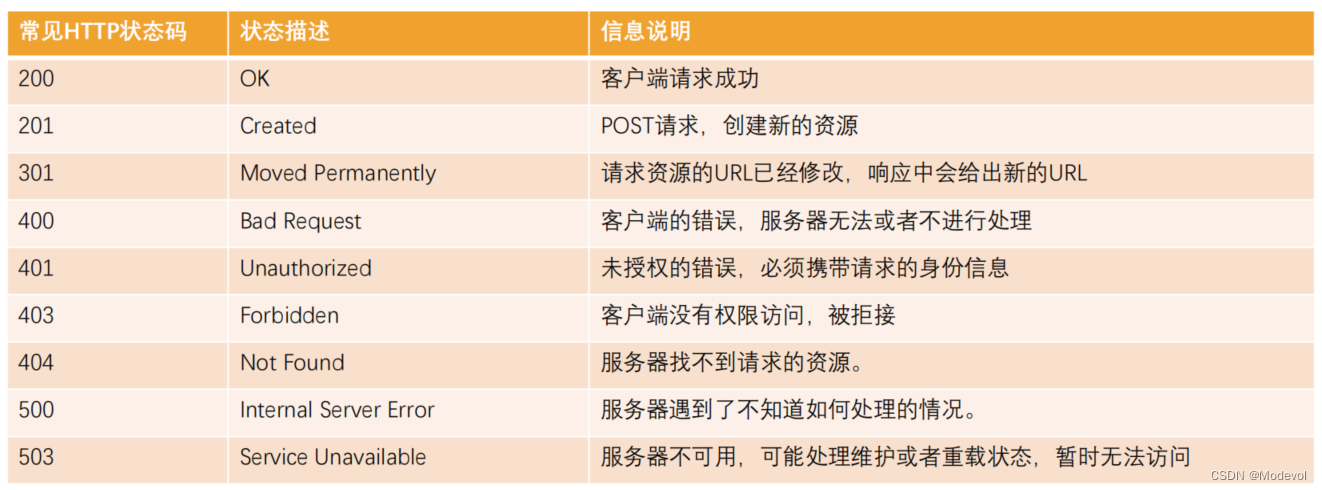
Response响应状态码
- Http状态码(Http Status Code)是用来表示Http响应状态的数字代码
- Http状态码非常多,可以根据不同的情况,给客户端返回不同的状态码
- MDN响应码解析地址:https://developer.mozilla.org/zh-CN/docs/web/http/status
HTTP状态码列表:
HTTP状态码列表
同源策略(掌握)
同源策略:Same Origin Policy SOP 是浏览器的策略
- 同源策略(Same-Origin Policy)最早由 Netscape 公司提出,是浏览器的一种安全策略
- 规定:只允许两个页面有相同的源时,一个页面才可以去访问另一个页面中的数据。
- 源:说白了,就是指域名 相同的源指的是有相同的域名
- 换句话说,jd.com不能去获取taobao.com下面的数据
有一个这样的域名:http://www.wangcai.com
* http://zhidao.wangcai.com 不同源
* http://www.wangcai.com:8080 不同源
* https://www.wangcai.com 不同源
* http://www.wangcai.com/phone/index.html 同源
* http://www.wangcai.com/phone/huawei/index.html 同源
总结
- 源:协议 + 域名 + 端口
- 同源:相同的协议 && 相同域名 && 相同的端口
- 不同源:不同的协议 || 不同的域名 || 不同的端口
不受同源策略的限制
- 资源的引入 如:img标签的src link标签的href script标签的src
- 页面中的超连接 a标签中的href
- 表单的提交
- 重定向页面
ajax受同源策略影响
五、KOA框架
KOA简介与入门
Koa 是⼀个新的 web 框架,由 Express 幕后的原班⼈⻢打造, 致⼒于成为web 应⽤和 API 开发领域中的⼀个更⼩、更富有表现⼒、更健壮的基⽯。 通过利⽤ async 函数,Koa 帮你丢弃回调函数,并有⼒地增强错误处理。 Koa并没有捆绑任何中间件, ⽽是提供了⼀套优雅的⽅法,帮助您快速⽽愉快地编写服务端应⽤程序。
// 写后端代码,node代码,koa代码,使用的模块化是commonjs规范
// 框架:
// 学习框架,就是学习规则,学习规范,要求你需要在合适的位置写合适的代码
// 等待框架去调用
// 下面的一片代码的作用是为了创建一台服务器
// 我们写的这个服务器,位于我们自己的电脑上
// 这个服务器对应的IP是:127.0.0.1
// 这个IP对应的域名是loalhost
let Koa = require("koa")
// Koa是一个构造器 new Koa得到一个对象app
let app = new Koa();
// 中间件 use表示使用中间件 里面的回调函数会自动执行
app.use(async ctx => {
// ctx是上下文
// ctx.body = "hello kao"是给浏览器响应一个hello koa
ctx.body = "hello kao"
})
// 我这个服务器监听的端口是3000
// 如果动了服务器代码,需要重新启动服务
// 按ctrl不动,按两次C,就可以关掉服务器
app.listen(3000, () => {
console.log("server is running on 3000");
})
// 服务器运行来了,可以使用浏览器得服务器发送请求
// 有一个工具,叫postman,这个postman也可以向服务器发送请求
步骤
- 创建文件夹 codekao
- 进入文件夹,生成项目配置文件 npm init -y
- .安装koa: npm i [email protected] -S
- 在codekao文件夹下,创建 01-搭建koa服务器.js
const Koa = require('koa');
const app = new Koa();
app.use(async ctx => {
ctx.body = 'Hello World';
});
app.listen(3000);
- 运行代码:node 01-搭建koa服务器.js
- 通过浏览器或postman访问之:
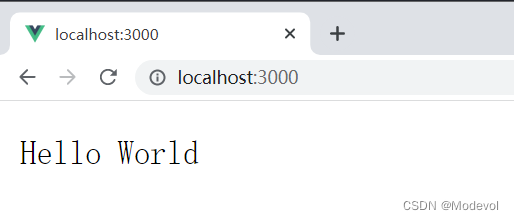
中间件机制
https://juejin.cn/post/7022870597860327437
中间件就是 匹配路由之前 或者 匹配路由完成后 做的一系列的操作,我们就可以把它叫做中间件。
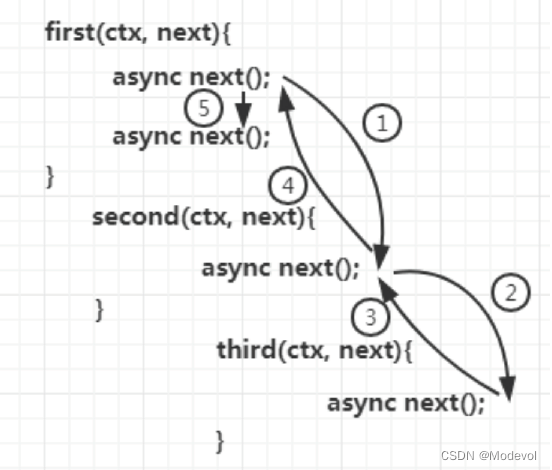
// 中间件函数建议使用异步函数
// 参数1 ctx是上下文 是一个对象 这个对象中提供了很多API
// ctx.body = "hello koa" 用来给客户响应数据的
// 参数2 next 控制是否执行下一个中间件
const Koa = require('koa');
const app = new Koa();
// logger
app.use(async (ctx, next) => {
console.log(1);
await next();
console.log(5);
const rt = ctx.response.get('X-Response-Time ');
console.log(`${ctx.method} ${ctx.url} -${rt}`);
});
// x-response-time
app.use(async (ctx, next) => {
const start = Date.now();
console.log(2);
await next();
console.log(4);
const ms = Date.now() - start;
ctx.set('X-Response-Time', `${ms}ms`);
});
// response
app.use(async ctx => {
console.log(3);
ctx.status = 200; //设置响应状态码
ctx.type = 'html'; //等价于ctx.set('Content-Type ','text / html ')
ctx.body = 'Hello World'; //设置响应体
});
app.listen(3000); //语法糖 等同于http.createServer(app.callback()).listen(3000)
打印结果: 1 2 3 4 5
结论: 当请求开始时先通过X-Response-Time 和logger 中间件, 然后继续交给response 中间件,当⼀个中间件调⽤next() 则该函数暂停执⾏并将控制权传递给定义的下个中间件. 当在response 中间件执⾏后, 下游没有更多的中间件. 这个时候每个中间件恢复其上游⾏为
错误监听
- 常⻅抛出异常和错误类型
- 代码语法不规范造成的JS报错异常
- 程序运⾏中发⽣的⼀些未知异常
- HTTP错误
- ⾃定义的业务逻辑错误
添加error全局事件侦听器
const Koa = require('koa');
const app = new Koa();
// app.use(async ctx => {
// ctx.body = 'hello world'
// })
// 触发错误 koa帮咱们做了处理
app.use(async (ctx, next) => {
throw new Error('未知错误');
})
//全局错误处理 后台打印
app.on('error', err => {
console.log('全局错误处理', err.message)
})
app.listen(3000);
错误处理中间件
const Koa = require('koa');
const app = new Koa();
// 错误处理中间件
app.use(async (ctx, next) => {
try {
await next();
} catch (error) {
// 给⽤户显示状态码
ctx.status = error.statusCode || error.status || 500;
//如果是ajax请求,返回的是json错误数据
ctx.type = 'json';
// 给⽤户显示
ctx.body = {
ok: 0,
message: error.message
};
// 系统⽇志
ctx.app.emit('error', error, ctx);
}
})
// 触发错误 koa帮咱们做了处理
app.use(async (ctx, next) => {
throw new Error('未知错误');
})
// response
//....
//全局错误处理 后台打印
app.on('error', err => {
console.log('全局错误处理', err.message)
})
app.listen(3000);
注意: 每次修改了服务器代码,都需要重新启动服务器,为了方便,可以全局安装nodemon。
- 全局安装:npm i nodemon -g
koa-logger处理⽇志
- 安装: npm i [email protected]
- 在控制台可以更加细致看到错误信息
const Koa = require('koa');
const app = new Koa();
const logger = require('koa-logger')
app.use(logger())
app.use(async (ctx, next) => {
throw new Error('未知错误');
})
// 全局的事件监听器
app.on('error', (err) => {
console.log('全局错误处理:', err.message, err.status, err.data)
})
app.listen(3000, () => {
console.log('3000端口被监听了~~')
})
koa-erros处理错误
- 安装: npm i [email protected]
- 在控制台可以更加细致看到错误信息
const Koa = require('koa')
const onerror = require('koa-onerror')
const app = new Koa()
const logger = require('koa-logger')
app.use(logger())
onerror(app)
// koa的中间件
app.use(async (ctx, next) => {
// ctx.throw()相当于是一个中间件
ctx.throw(401, '未授权', {
data: '你瞅瞅'
})
// ctx.body = 'wc' //设置响应体
/*
等价
const err = new Error('未授权');
err.status = 401;
err.expose = true;
throw err;
*/
})
app.use(async (ctx) => {
ctx.body = '错误处理中间件'
})
// 全局的事件监听器
app.on('error', (err) => {
console.log('全局错误处理:', err.message, err.status, err.data)
})
app.listen(3000, () => {
console.log('3000端口被监听了~~')
})
koa-log4处理⽇志
koa-log4 ⽐较好⽤的node环境下处理⽇志处理的模块, koa-log4 在 log4js-node 的基础上做了⼀次包装,是 koa 的⼀个处理⽇志的中间件,此模块可以帮助你按照你配置的规则分叉⽇志消息。
操作步骤:
- 在根⽬录下新建 logger/ ⽬录
- 在 logger/ ⽬录下新建 logs/ ⽬录,⽤来存放⽇志⽂件
- 在 logger/ ⽬录下新建 index.js ⽂件
- 安装: npm i [email protected]
- logger目录下的index.js代码(大家直接copy)如下:
const path = require('path')
const log4js = require('koa-log4')
log4js.configure({
appenders: {
// 访问级别
access: {
type: 'dateFile',
// 生成文件的规则
pattern: '-yyyy-MM-dd.log',
// 文件名始终以日期区分
alwaysIncludePattern: true,
encoding: 'utf-8',
// 生成文件路径和文件名
filename: path.join(__dirname, 'logs', 'access')
},
application: {
type: 'dateFile',
pattern: '-yyyy-MM-dd.log',
alwaysIncludePattern: true,
encoding: 'utf-8',
filename: path.join(__dirname, 'logs', 'application')
},
out: {
type: 'console'
}
},
categories: {
default: {
appenders: ['out'],
level: 'info'
},
access: {
appenders: ['access'],
level: 'info'
},
application: {
appenders: ['application'],
level: 'WARN'
}
}
})
// // 记录所有访问级别的日志
// exports.accessLogger = () => log4js.koaLogger(log4js.getLogger('access'))
// // 记录所有应用级别的日志
// exports.logger = log4js.getLogger('application')
module.exports = {
// 记录所有访问级别的日志
accessLogger: () => log4js.koaLogger(log4js.getLogger('access')),
// 记录所有应用级别的日志
logger: log4js.getLogger('application')
}
- 访问级别的,记录⽤户的所有请求,作为koa的中间件,直接使⽤便可。
- 应⽤级别的⽇志,可记录全局状态下的 error ,修改 app.js 全局捕捉异常
修改对应的代码如下
const Koa = require('koa')
const onerror = require('koa-onerror')
const {
accessLogger,
logger
} = require('./logger')
const app = new Koa()
onerror(app)
app.use(accessLogger())
// koa的中间件
app.use(async (ctx, next) => {
// ctx.throw()相当于是一个中间件
ctx.throw(401, '未授权', {
data: '你瞅瞅'
})
// ctx.body = 'wc' //设置响应体
/*
等价
const err = new Error('未授权');
err.status = 401;
err.expose = true;
throw err;
*/
})
// app.use(async ctx => {
// ctx.body = 'Hello World';
// });
// 全局的事件监听器
app.on('error', (err) => {
logger.error(err)
})
app.listen(3000, () => {
console.log('3000端口被监听了~~')
})
路由中间件koa-router
- 安装: npm i @koa/[email protected]
- 使⽤: 新建router/index.js和router/users.js
router/index.js中代码如下:
// 首页模块
// 购物车模块
const Router = require("@koa/router")
const router = new Router();
// 配置路由
// get表示客户端,需要发送get请求
// 通过浏览器地址栏发送的请求,就是get请求
router.get("/home", (ctx, next) => {
ctx.body = "欢迎访问首页面"
})
router.get("/home/news", (ctx, next) => {
ctx.body = "首页面的新闻列表"
})
module.exports = router;
router/user.js中代码如下:
// 用户管理模块
// 导入路由模块 Router就是路由器的意思
const Router = require("@koa/router")
// 创建一个路由对象
const router = new Router();
// 把公共部分抽离出去
router.prefix("/user")
// 路由本身就是一个特殊的中间件
// 当客户端访问/user/list 由后面的中间件处理
router.get("/list", (ctx, next) => {
ctx.body = "用户列表"
})
// 路由:就是一个URL对应的一个响应(资源)
router.get("/add", (ctx, next) => {
ctx.body = "添加用户"
})
module.exports = router;
入口文件中导⼊并注册,如下:
const Koa = require("koa")
const user = require("./router/user.js")
const index = require("./router/index.js")
const app = new Koa();
// 注册用户模块路由
app.use(user.routes())
user.allowedMethods();
// 注册首页模块路由
app.use(index.routes())
index.allowedMethods();
app.listen(3000, () => {
console.log("server is running on 3000~");
})
get请求
let Router = require("@koa/router")
let router = new Router();
router.prefix("/user")
// 客户端给服务器发送请求,可以传递参数
// get传递参数有两种形式
//访问http://localhost:3000/user/3?name=wc
// 1)通过?传参 query传参 /user/del?name=wc&age18
// ? name = wc & age18 查询字符串,就是用来给服务器传递的参数
router.get("/del", (ctx, next) => {
// ctx.query 就可以获取到get请求,通过?传递过来的参数 或 通过query传递过过来的参数
console.log(ctx.query);
ctx.body = "删除用户"
})
// 还有一种传参的方式
//访问http://localhost:3000/users/3/1
// 1)params传参 /:id 表示动态参数 不是写死的
// /add/:id 叫动态路由
router.get("/add/:id/:score", (ctx, next) => {
console.log(ctx.params);
ctx.body = "增加用户"
})
module.exports = router;
post请求
- post解析请求的参数需要下载 koa-bodyParser
- 安装:npm i [email protected]
let Router = require("@koa/router")
let router = new Router();
router.prefix("/user")
// router.post 用来处理前端的post请求
// 浏览器的地址栏,不能发送post请求,只能发送get请求
// 需要使用postman来测试
// 404 表示前端去访问后面某个路由,后面没有这个路由,得到404状态码
// post请求,如何给后端传递参数?
// post请求,需要把传递参数放到请求体中,在postman中不要选错了。
// 在postman中,选择body选项,在body选项下面,选择x-www-form-urlencoded,不要选错
// 其它的选择先不用管
// 如果得到post请求传递过来的参数?
// 答:安装 body-parser ,通过body-parser去获取数据,
// 安装:npm i koa - [email protected]
// 安装完后,还需要在入口中配置
// 配置完毕后,通过ctx.reqeust.body,可以获取前端传递过来的数据
router.post("/add", (ctx, next) => {
console.log(ctx.request.body);
ctx.body = "增加用户666"
})
module.exports = router;
// 入口 js
let Koa = require("koa")
let bodyparser = require("koa-bodyparser")
let user02 = require("./router/user02.js")
let app = new Koa();
// 使用bodyparser
app.use(bodyparser())
// 注册路由
app.use(user02.routes())
user02.allowedMethods();
app.listen(3000, () => {
console.log("server is running on 3000");
})
由于浏览器地址栏,只能发送get请求,要发送post请求,需要使用postman,如下:
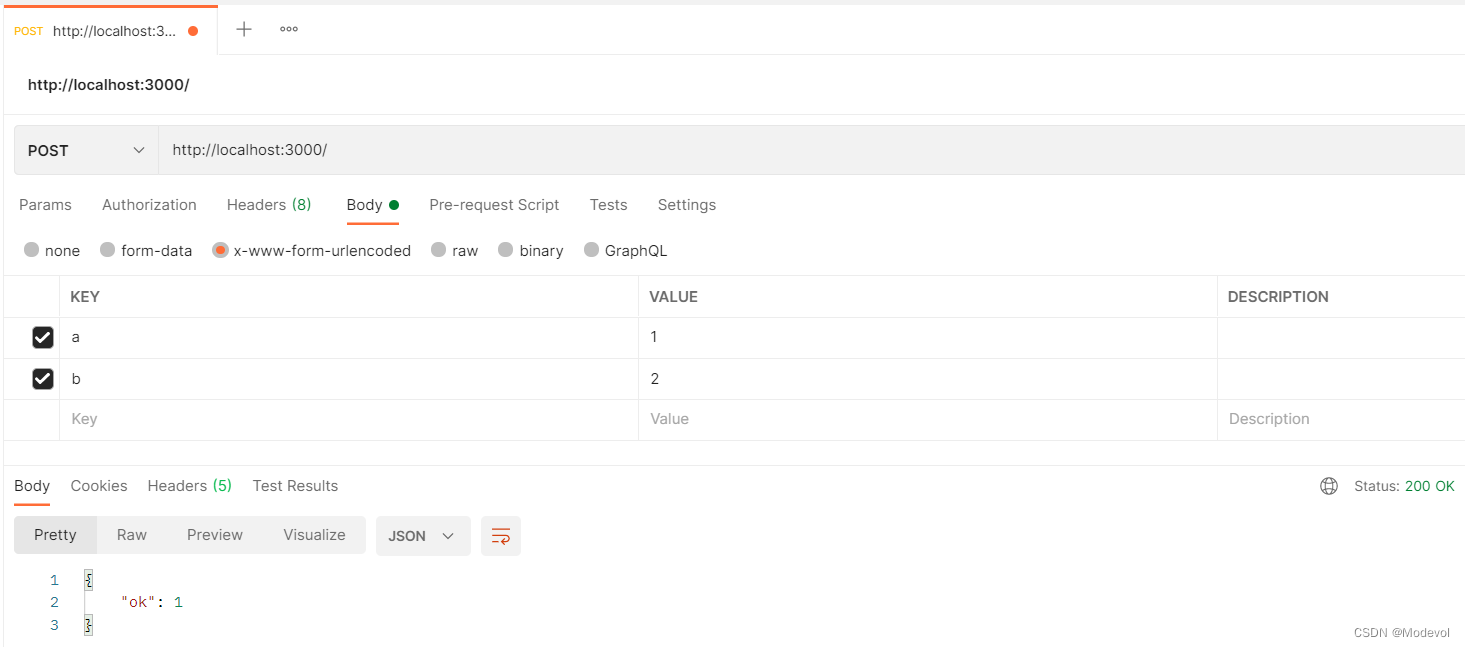
重定向
let Router = require("@koa/router")
let router = new Router();
router.prefix("/user")
// 当用户直接访问/user/ 时,怎么办?
// 当访问/user/时,我们可以重定向现到/user/list 重新指定访问
// 状态码是200表示成功的请求
// 302表示重定向 不同的状态码有不同的含义
router.get("/", (ctx, next) => {
// 当访问/user/时,redirect表示重定向
ctx.redirect("/user/list")
})
router.get("/list", (ctx, next) => {
ctx.body = "用户列表"
})
// 如果服务器中的代码出问题,状态码是500
router.get("/add", (ctx, next) => {
// throw new Error("出错了")
ctx.body = "增加用户"
})
module.exports = router;
静态资源托管
- 安装:npm i [email protected]
- 静态资源都放在根目录的public目录下面
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<link rel="stylesheet" href="./css/index.css">
</head>
<body>
<h1>今天学习Koa,感觉非常爽~</h1>
</body>
</html>
/* index.css */
h1 {
color: red;
}
配置
const Koa = require('koa')
const index = require('./router/index')
const users = require('./router/user')
const bodyParser = require('koa-bodyparser')
const static = require('koa-static');
const app = new Koa()
app.use(bodyParser());
app.use(static(__dirname + '/public'))
// 注册路由
app.use(index.routes())
index.allowedMethods()
app.use(users.routes())
users.allowedMethods()
app.listen(3000, () => {
console.log('3000端口被监听了~~')
})
效果
// 把我们之前写的一个静态网页放到koa服务器中
let Koa = require("koa")
let static = require("koa-static")
let app = new Koa();
// [email protected] 托管静态资源
// 说白了,就是把前面学习的静态网页放到服务器
// 安装:npm i [email protected]
// __dirname 是node提供的全局变量,直接使用,表示不文件所有的目录
app.use(static(__dirname, "./public"))
app.listen(3000, () => {
console.log("server is running on 3000");
})
六、鉴权
三种常⻅鉴权⽅式:Session/Cookie、Token+jwt、OAuth
Session/Cookie
cookie和session都是用来跟踪浏览器用户身份的会话方式
https://zhuanlan.zhihu.com/p/504924068
cookie
Http协议是⼀个⽆状态的协议,服务器不会知道到底是哪⼀台浏览器访问了它,因此需要⼀个标识⽤来让服务器区分不同的浏览器。cookie就是这个管理服务器与客户端之间状态的标识。cookie的原理是,浏览器第⼀次向服务器发送请求时,服务器在response头部设置Set-Cookie字段,浏览器收到响应就会设置cookie并存储,在下⼀次该浏览器向服务器发送请求时,就会在request头部⾃动带上Cookie字段,服务器端收到该cookie⽤以区分不同的浏览器。当然,这个cookie与某个⽤户的对应关系应该在第⼀次访问时就存在服务器端,这时就需要session了。
cookie的基本使用:
const Koa = require('koa');
const app = new Koa();
app.use(async ctx => {
// 需要在服务端种植一个cookie,种到了浏览器的时面
// 后面,每一次请求,浏览器都会带上这个cookie
// 默认情况下,会话结束,cookie就死了
// ctx.cookies.set("usrename", "wangcai");
// 活7天 设置cookie的生存时间
ctx.cookies.set("usrename", "wangcai", {
maxAge: 60000 * 60 * 24 * 7
});
// 获取浏览器带过来的cookie
console.log("获取cookie:", ctx.cookies.get("usrename"));
ctx.body = 'Hello World';
});
app.listen(3000);
使用cookie记录一次的访问时间,代码如下:
const Koa = require('koa');
const app = new Koa();
app.use(async ctx => {
// 获取cookie 第1次获取不到,值是und
let last = ctx.cookies.get("last")
// 第1次访问服务器 需要种植一个cookie
ctx.cookies.set("last", new Date().toLocaleString(), {
maxAge: 60000 * 60 * 24 * 356
});
if (last) {
ctx.body = `你上一次访问的时间是:${last}`
} else {
// 第1次访问
ctx.body = `这是你第1次访问本网站`
}
});
app.listen(3000);
session
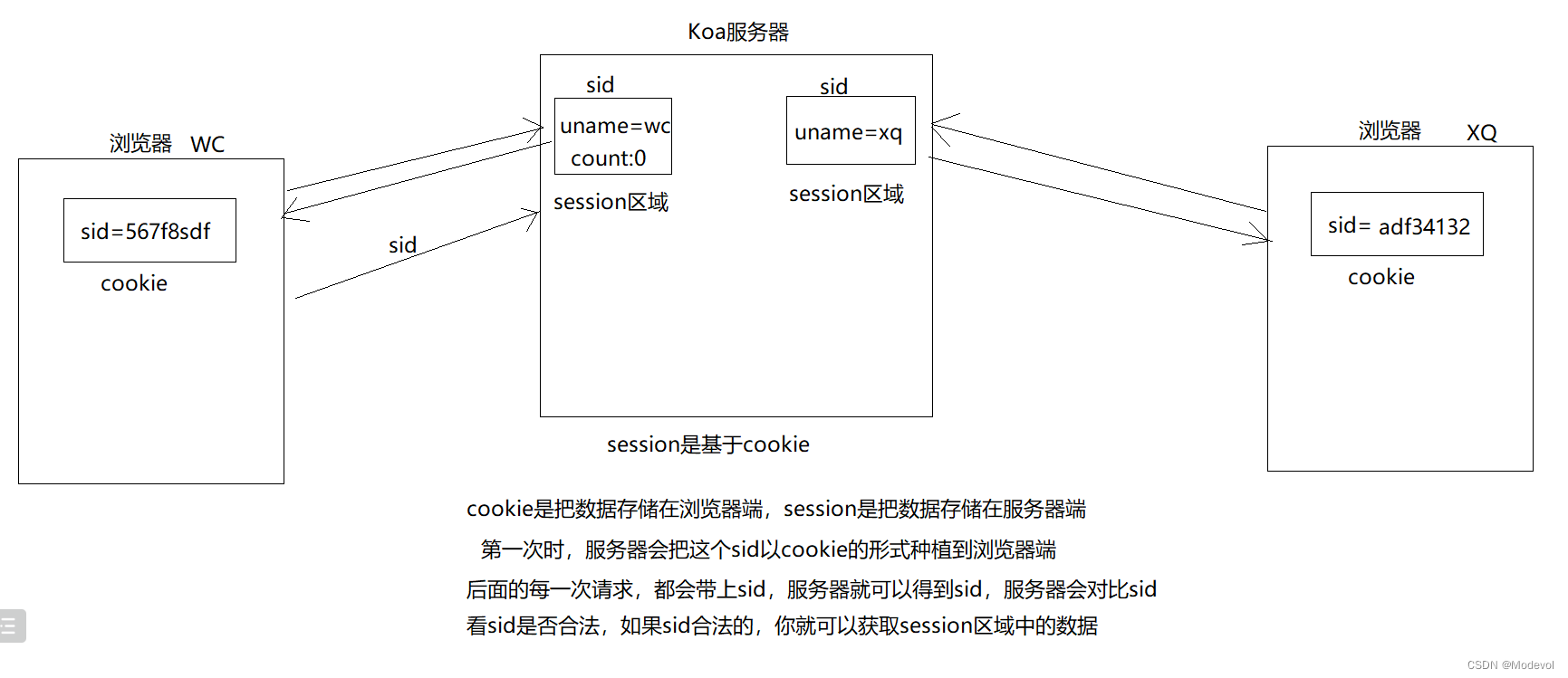
session是会话的意思,浏览器第⼀次访问服务端,服务端就会创建⼀次会话,在会话中保存标识该浏览器的信息。它与cookie的区别就是session是缓存在服务端的,cookie 则是缓存在客户端,他们都由服务端⽣成,为了弥补Http协议⽆状态的缺陷。
基于session-cookie的身份认证
原理
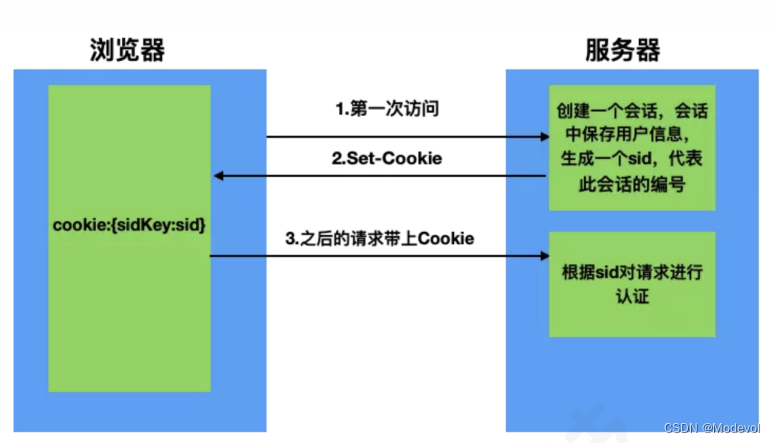
- 服务器在接受客户端⾸次访问时在服务器端创建seesion,然后保存seesion(我们可以将seesion保存在内存中,也可以保存在redis中,推荐使⽤后者),然后给这个session⽣成⼀个唯⼀的标识字符串,然后在响应头中种下这个唯⼀标识字符串。
- 签名。这⼀步通过秘钥对sid进⾏签名处理,避免客户端修改sid。(⾮必需步骤)
- 浏览器中收到请求响应的时候会解析响应头,然后将sid保存在本地cookie中,浏览器在下次http请求的 请求头中会带上该域名下的cookie信息。
- 服务器在接受客户端请求时会去解析请求头cookie中的sid,然后根据这个sid去找服务器端保存的该客户端的session,然后判断该请求是否合法
安装和应⽤
- 安装:npm i [email protected]
- 快速搭建app应⽤
基于session实现网站访问次数统计
let Koa = require("koa")
const session = require('koa-session');
let app = new Koa()
// 对cookie进行加密签名
app.keys = ['some secret hurr'];
// 对session进行配置,了解
const CONFIG = {
key: 'sid',
maxAge: 86400000, // sid的有效期,默认是1天
httpOnly: true, // 仅仅是服务器端修改cookie
signed: true, // 签名cookie
}
app.use(session(CONFIG, app))
app.use(async (ctx, next) => {
// 浏览器有一个默认行为,它会请求favicon.ico
// 服务器判断出请求favicon.ico,直接结束
if (ctx.path === '/favicon.ico') return;
// 第1次访问时,n是0,但是此时给session中存储了一个count,值是1
// 第2次访问时,n是1,但是此时给sesion中存储的count变成了2
let n = ctx.session.count || 0;
ctx.session.count = ++n
ctx.body = `这是你第${n}访问本网站~`
})
app.listen(3000, () => {
console.log("server is running on 3000");
})
浏览器效果如下:
cookie和session的区别
1. 存储位置不同
- cookie的数据信息存放在客户端浏览器上。
- session的数据信息存放在服务器上
2. 存储容量不同
- 单个cookie保存的数据<=4KB,一个站点最多保存20个Cookie。
- 对于session来说并没有上限,但出于对服务器端的性能考虑,session内不要存放过多的东西,并且设置session删除机制。
3. 存储方式不同
- cookie中只能保管ASCII字符串,并需要通过编码方式存储为Unicode字符或者二进制数据。
- session中能够存储任何类型的数据,包括且不限于string,integer,list,map等。
4. 隐私策略不同
- cookie对客户端是可见的,别有用心的人可以分析存放在本地的cookie并进行cookie欺骗,所以它是不安全的。
- session存储在服务器上,对客户端是透明对,不存在敏感信息泄漏的风险。
5. 有效期上不同
- 开发可以通过设置cookie的属性,达到使cookie长期有效的效果。
- session依赖于名为JSESSIONID的cookie,而cookie JSESSIONID的过期时间默认为-1,只需关闭窗口该session就会失效,因而session不能达到长期有效的效果。
6. 服务器压力不同
- cookie保管在客户端,不占用服务器资源。对于并发用户十分多的网站,cookie是很好的选择。
- session是保管在服务器端的,每个用户都会产生一个session。假如并发访问的用户十分多,会产生十分多的session,耗费大量的内存。
7. 浏览器支持不同
- 假如客户端浏览器不支持cookie:
+ cookie是需要客户端浏览器支持的,假如客户端禁用了cookie,或者不支持cookie,则会话跟踪会失效。关于WAP上的应用,常规的cookie就派不上用场了。
+ 运用session需要使用URL地址重写的方式。一切用到session程序的URL都要进行URL地址重写,否则session会话跟踪还会失效。
- 假如客户端支持cookie:
+ cookie既能够设为本浏览器窗口以及子窗口内有效,也能够设为一切窗口内有效。
+ session只能在本窗口以及子窗口内有效。
8. 跨域支持上不同
- cookie支持跨域名访问。
- session不支持跨域名访问。
基于session实现⽤户鉴权
实现三个接口如下:
let Router = require("@koa/router")
let router = new Router();
router.prefix("/user")
// 登录接口
router.post("/login", (ctx, next) => {
// post请求,想去获取用户名和密码
// 配置koa-bodyparser
// 获取:ctx.request.body
let body = ctx.request.body;
// console.log("body:", body); // { user: '123', pwd: 'abc' }
// 把用户名存储在session区域中
// 现在,你要知道,在session区域中,存储了用户信息,用户信息仅仅有一个用户名
ctx.session.userinfo = body.user;
// 这个响应的是纯文本的字符串
// ctx.body = "登录成功"
ctx.body = {
ok: 1,
message: "登录成功"
}
})
// 获取用户信息
// 现在获取用户信息这个接口,需要身份认证
// 如果说有100个接口,都需要身份认证,可以把这一套逻辑抽离出去
// router.get("/getUser", (ctx, next) => {
// if (ctx.session.userinfo) {
// ctx.body = {
// ok: 1,
// message: "获取用户信息成功",
// userinfo: ctx.session.userinfo
// }
// } else {
// ctx.body = {
// ok: 0,
// message: "获取用户信息失败,请先登录",
// }
// }
// })
router.get("/getUser", require("../middleware/auth.js"), (ctx, next) => {
ctx.body = {
ok: 0,
message: "获取用户信息成功",
userinfo: ctx.session.userinfo
}
})
// 退出登录接口
router.post("/logout", (ctx, next) => {
if (ctx.session.userinfo) {
delete ctx.session.userinfo
}
ctx.body = {
ok: 1,
message: "退出登录成功"
}
})
// 获取个人收藏数据
// 要求,你访问此接口,也需要登录
router.get("/getLike", require("../middleware/auth.js"), (ctx, next) => {
ctx.body = {
ok: 0,
message: "获取个人收藏数据成功",
}
})
module.exports = router;
封装auth验证
// auth就是身份认证的意思
module.exports = async (ctx, next) => {
if (ctx.session.userinfo) {
await next()
} else {
ctx.body = {
ok: 0,
message:"身份认证失败"
}
}
}
入口JS配置如下:
let Koa = require("koa")
const session = require('koa-session');
let bodyparser = require("koa-bodyparser")
let user06 = require("./router/user06.js")
let app = new Koa()
// keys作用:用来对cookie进行签名
app.keys = ['some secret hurr'];
// 鉴权:
// 身份认证
// 登录接口,登录成功后,可以获取用户信息
// 退出登录,如果退出了,不能获取用户信息
// 有些接口,只能在登录的情况下,才能访问,如:获取用户信息也是一个接口
// 这就是所谓的身份认证,身份认证就是鉴权
// session鉴权 后面还会去学习JWT鉴权
// 对session进行配置,了解
const SESSON_CONFIG = {
key: 'wc', //设置cookie的key名字
maxAge: 86400000, //有效期,默认是一天
httpOnly: true, //仅服务端修改
signed: true, //签名cookie
}
app.use(session(CONFIG, app))
// 使用bodyparser
app.use(bodyparser())
// 注册路由
app.use(user06.routes())
user06.allowedMethods();
app.listen(3000, () => {
console.log("server is running on 3000");
})
postman测试如下:
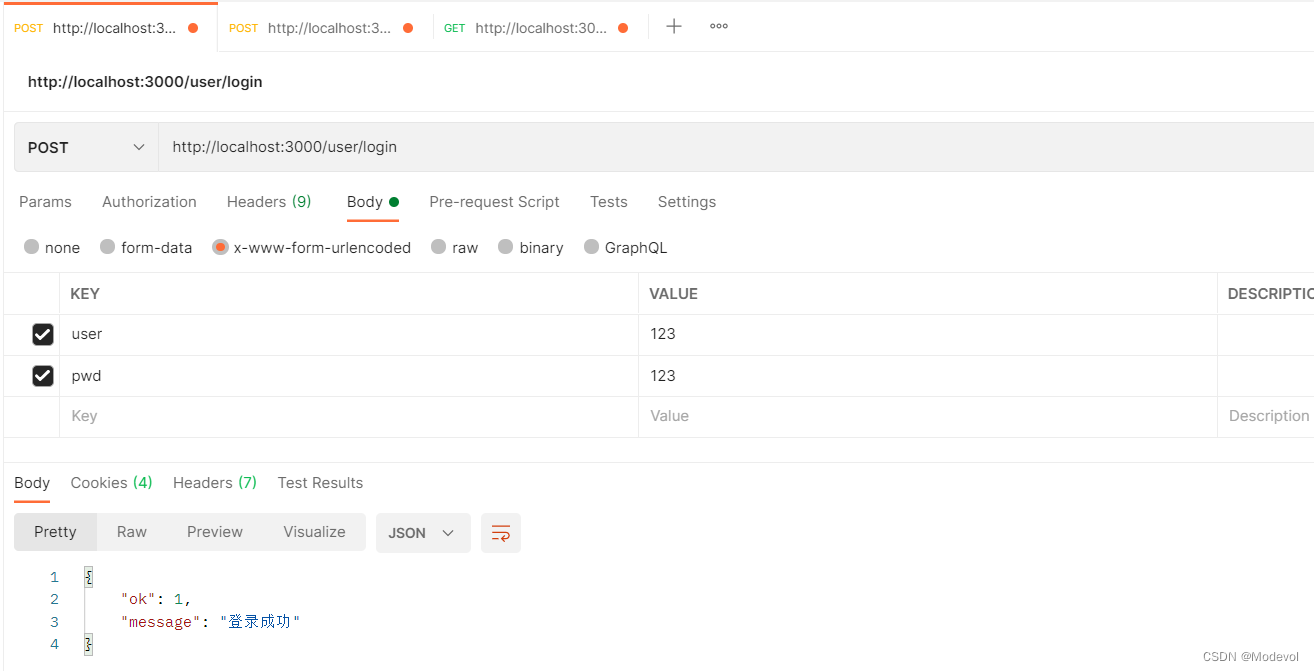
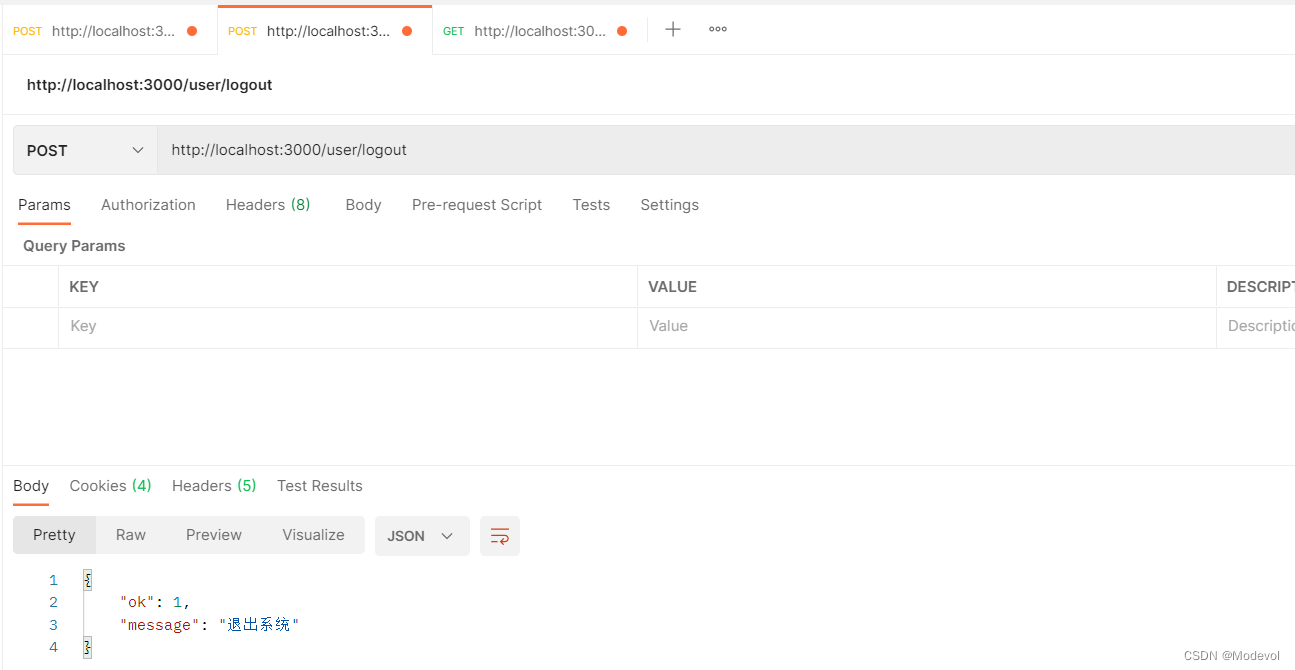
当访问/getUser路由的时候需要守卫中间件 在项目根目录下,创建middleware/auth.js,代码如下:
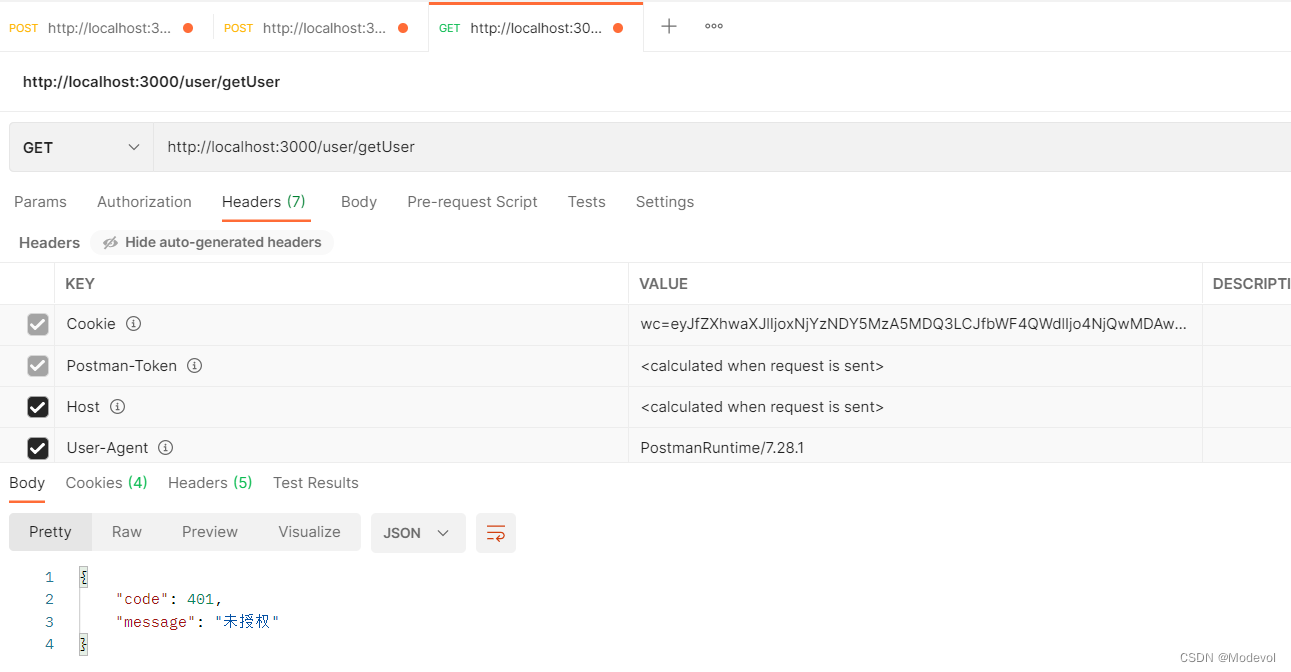
module.exports = async (ctx, next) => {
if (ctx.session.userinfo) {
await next()
} else {
ctx.body = {
code: 401,
message: '未授权',
}
}
}
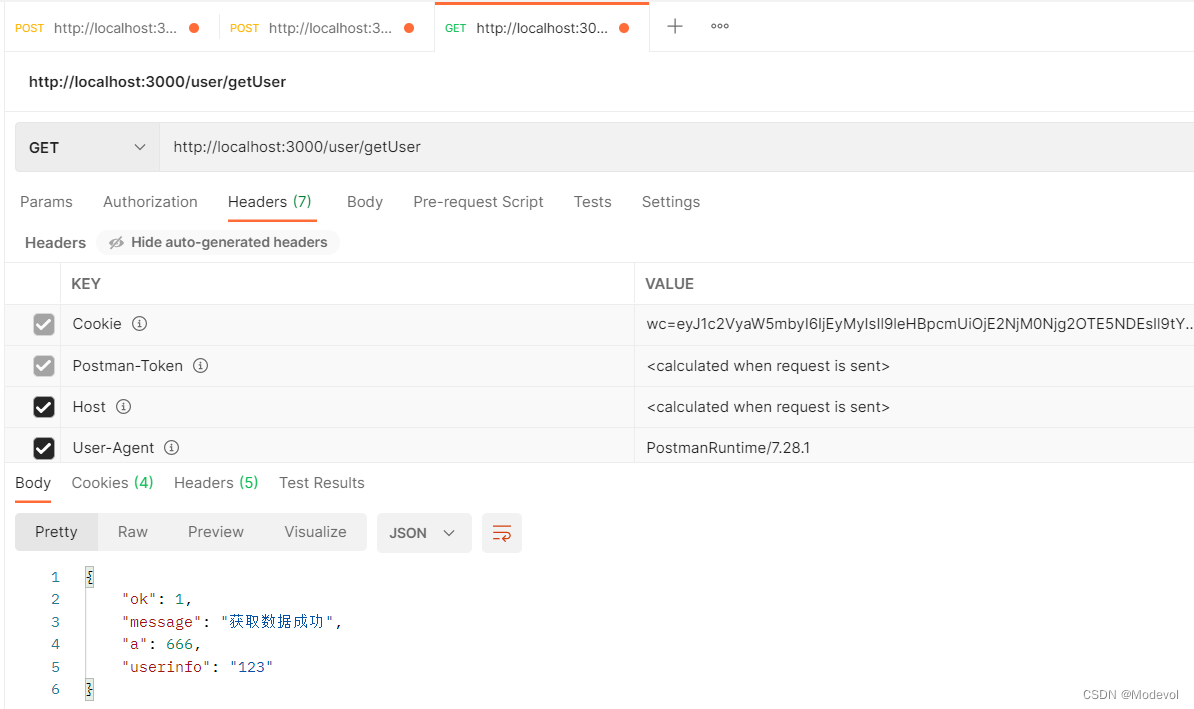
获取用户信息时,添加守卫,如下:
// 获取用户信息接口
router.get('/getUser', require('../middleware/auth'), async (ctx, next) => {
// console.log(ctx.session.userinfo);
ctx.body = {
ok: 1,
message: '获取数据成功',
a: 666,
userinfo: ctx.session.userinfo
}
})
Token+JWT认证
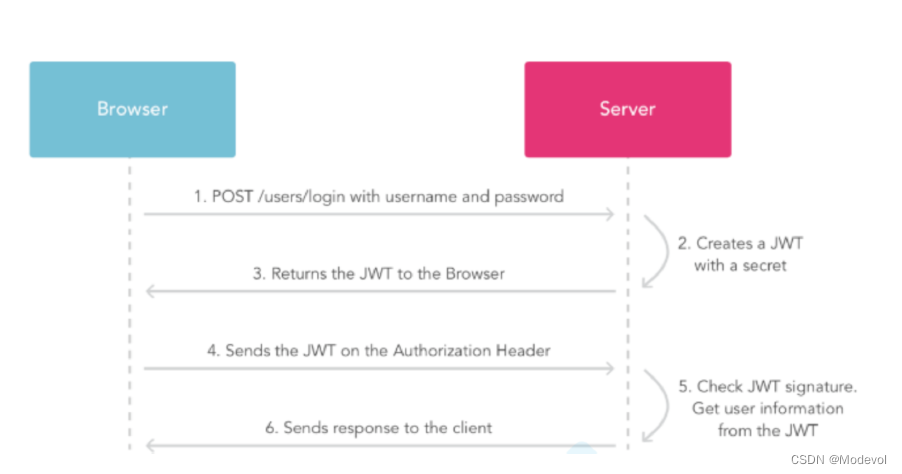
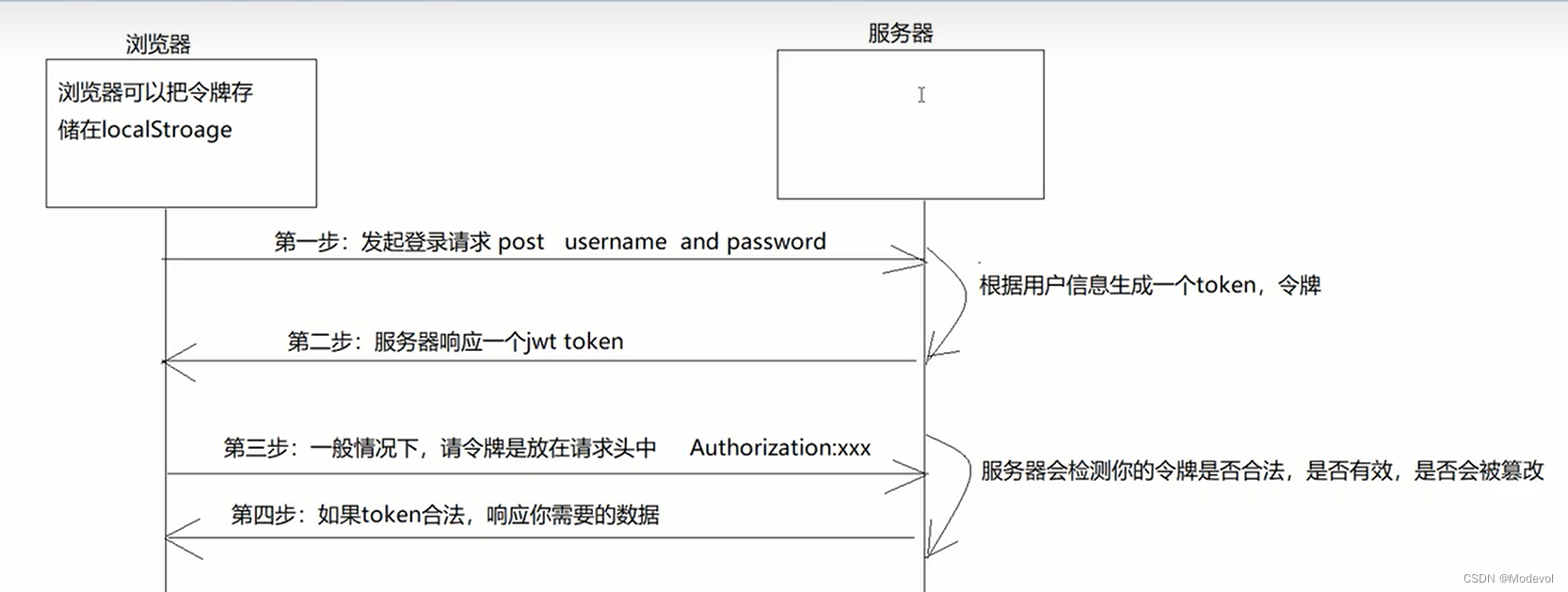
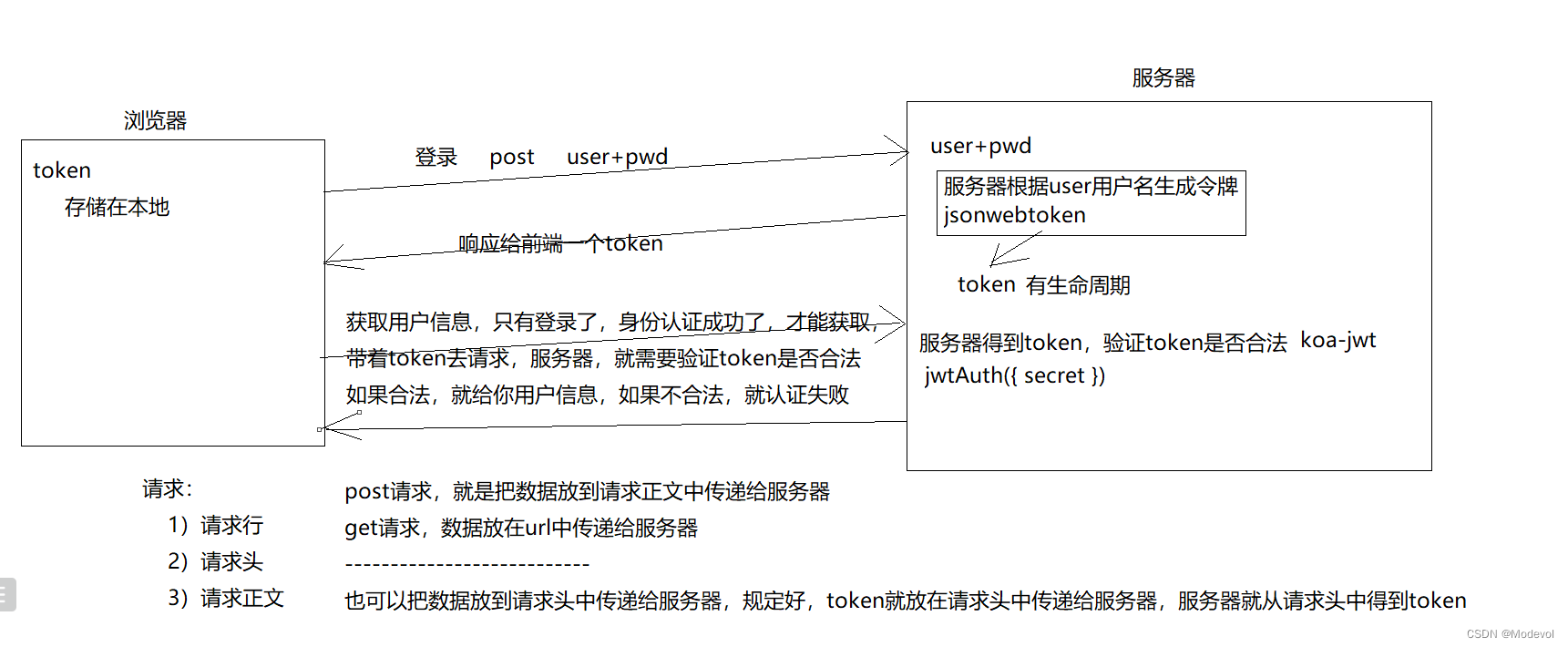
安装
- npm i [email protected] 说明:jwt中间件
- npm i [email protected] 说明:⽤于⽣成token下发给浏览器, 在koa2以后的版本不再提供jsonwebtoken的⽅法, 所以需要另外安装
在user.js中配置如下:
let Router = require("@koa/router")
let jwt = require("jsonwebtoken")
const jwtAuth = require("koa-jwt")
let router = new Router();
router.prefix("/user")
// jwt+token鉴权
// 生成token需要指定一个密钥,需要保存好,不能让别知道
// 后面还需要验证token是否合法,也需要这个secret
const secret = "fdsfsadfas234412dffsadffasdf3"
// 登录接口
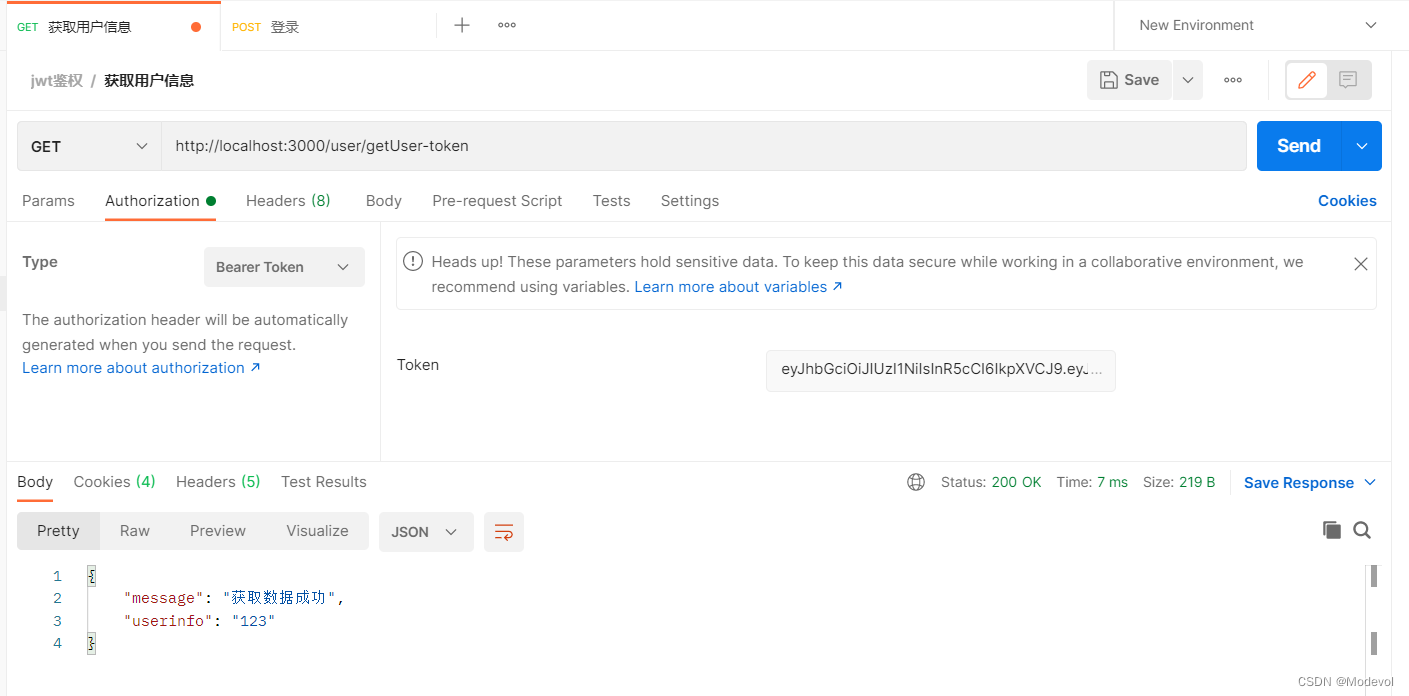
router.post("/login", (ctx, next) => {
// 1)得到用户信息 userinfo是用户名
let userinfo = ctx.request.body.user;
// 2)根据用户信息(用户名),生成token
let token = jwt.sign({
data: userinfo, // 最好不要放敏感数据
// 生成的令牌是有有效期 exp设置令牌的有效期
exp: Math.floor(Date.now() / 1000) + 60 * 60 // 1个小时后,token失效了
}, secret);
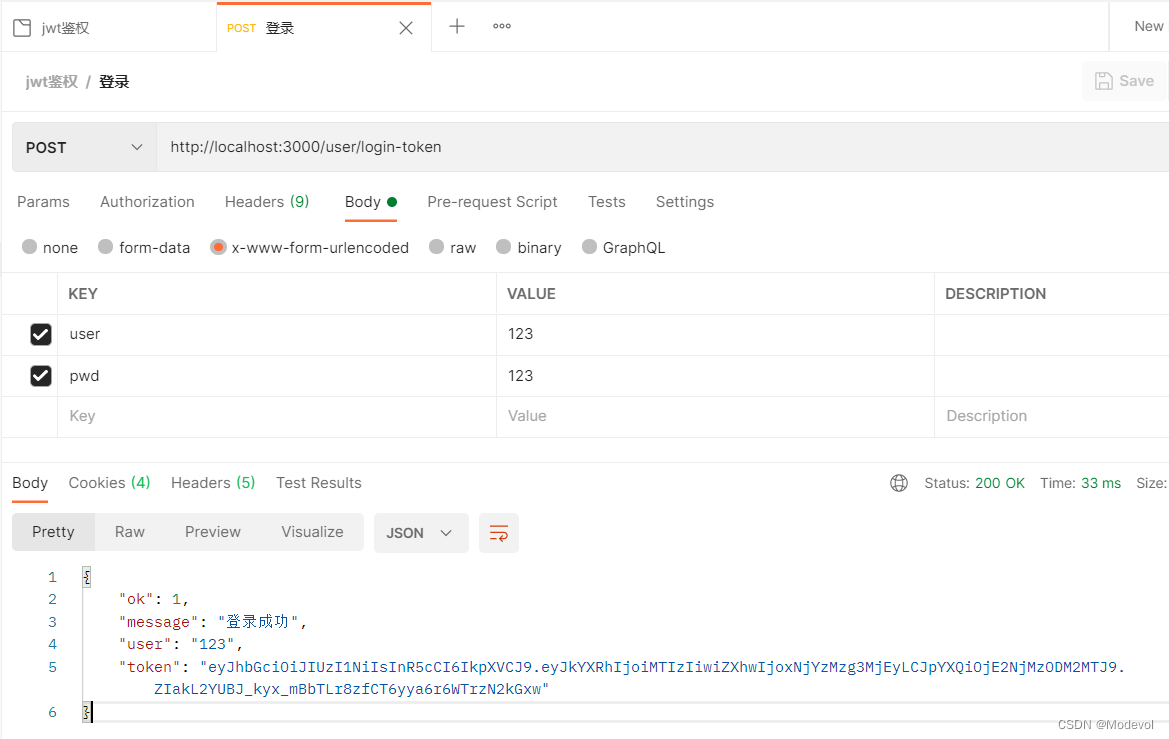
console.log("token:", token);
ctx.body = {
ok: 1,
message: "登录成功",
user: userinfo,
token: token
}
})
// 获取用户信息
// 获取用户信息,需要前端传递一个token
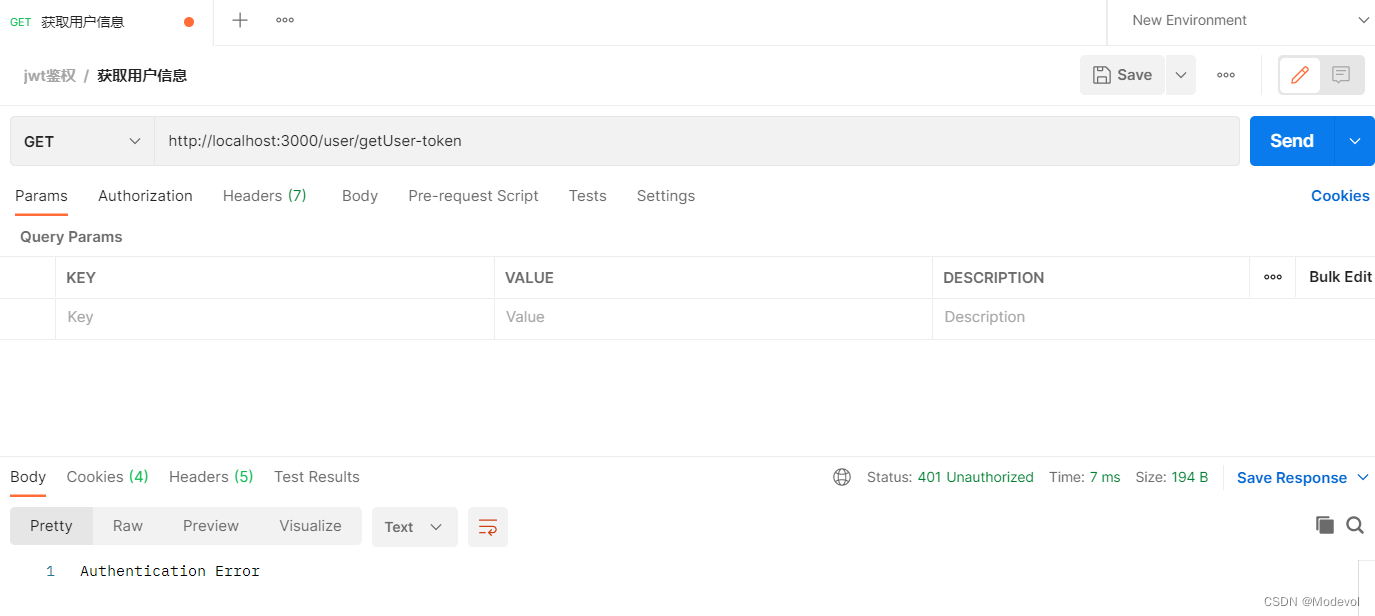
// token需要放在请求头
// 如果没有带信息,报错:Authentication Error
router.get("/getUser",
jwtAuth({ secret }),//对传入令牌进行校验
(ctx, next) => {
ctx.body = {
ok: 1,
message: "获取用户信息成功",
userinfo: ctx.state.user.data
}
})
// 退出登录接口
// 退出登录,保需要在前端把token销毁就OK
router.post("/logout", (ctx, next) => {
ctx.body = {
ok: 1,
message: "退出登录成功"
}
})
module.exports = router;
入口JS如下:
let Koa = require("koa")
let bodyparser = require("koa-bodyparser")
let user07 = require("./router/user07.js")
let app = new Koa()
// 使用bodyparser
app.use(bodyparser())
// 注册路由
app.use(user07.routes())
user07.allowedMethods();
app.listen(3000, () => {
console.log("server is running on 3000");
})
2.
3.
总结
//鉴权
就是身份验证
登录匹配相关信息,匹配成功登录成功,登陆成功后就可以获取用户相关的信息
注销。
//cookie
1.客户端发送请求到服务端(比如登录请求)。
2.服务端响应客户端,并在响应头中设置 Set-Cookie。
3.客户端收到该请求后,如果服务器给了 Set-Cookie,那么下次浏览器就会在请求头中自动携带 cookie。
4.客户端发送其它请求,自动携带了 cookie,cookie 中携带有用户信息等。
5.服务端接收到请求,验证 cookie 信息
//session
1. 服务器在接受客户端⾸次访问时在服务器端创建seesion,然后保存seesion(我们可以将seesion保存在内存中,也可以保存在redis中,推荐使⽤后者),然后给这个session⽣成⼀个唯⼀的标识字符串,然后在响应头中种下这个唯⼀标识字符串。
2. 签名。这⼀步通过秘钥对sid进⾏签名处理,避免客户端修改sid。(⾮必需步骤)
3. 浏览器中收到请求响应的时候会解析响应头,然后将sid保存在本地cookie中,浏览器在下次http请求的 请求头中会带上该域名下的cookie信息。
4. 服务器在接受客户端请求时会去解析请求头cookie中的sid,然后根据这个sid去找服务器端保存的该客户端的session,然后判断该请求是否合法
B)说一下,session鉴权的流程?自己整理一下session鉴权流程
1.登录接口
post请求,获取用户信息,把用户名存在session中。
2.获取用户信息接口
验证,session有用户信息,就把该用户信息给浏览器
3.退出登录
把session用户名删掉。
4.入口js配置
//利用keys对cookie进行签名
// 对session进行配置
const SESSON_CONFIG = {
key: 'wc', //设置cookie的key名字
maxAge: 86400000, //有效期,默认是一天
httpOnly: true, //仅服务端修改
signed: true, //签名cookie
}
C)说一下,jwt鉴权的流程?自己整理一下jwt鉴权流程
1.登录接口
1)得到用户信息
let userinfo = ctx.request.body.user;
2)服务器根据用户名生成相应令牌jsonwebtoken
let token = jwt.sign({
data: userinfo, // 最好不要放敏感数据
exp: Math.floor(Date.now() / 1000) + 60 * 60 // 1个小时后,token失效了
}, secret);
3)响应给前端一个token,把token放在浏览器数据库里面
2.获取信息
token需要放在请求头中,去后台验证是否合法,合法解析出对应信息给前端
3.退出登录
在前端把token销毁
4.入口js
七、RestfulAPI和KOA其它内容
设计Restful API
Representational State Transfer翻译过来是"表现层状态转化”, 它是一种互联网软件的架构原则。因为符合REST风格的Web API设计,就称它为Restful API,RESTful是目前最流行的API规范,适用于Web接口规范的设计。让接口易读,且含义清晰。本文将介绍如何设计易于理解和使用的API,并且借助Docker api的实践说明。
URL 设计
动词+宾语
- 它的核心思想就是客户端发出的数据操作指令都是「动词+宾语」的结构,比如GET /articles这个命令,GET是动词,/articles是宾语。
- 动词通常来说就是五种HTTP方法,对应我们业务接口的CRUD操作。而宾语就是我们要操作的资源,可以理解成面向资源设计。我们所关注的数据就是资源。
- GET: 读取资源
- POST: 新建资源
- PUT: 更新资源
- PATCH: 资源部分数据更新
- DELETE: 删除资源
正确的例子
- GET /zoos: 列出所有动物园
- POST /zoos: 新建一个动物园
- GET /zoos/id: 获取某个指定动物园的信息
- PUT /zoos/id: 更新某个指定动物园的信息(提供该动物园的全部信息)
- PATCH /zoos/id: 更新某个指定动物园的信息(提供该动物园的部分信息)
- DELETE/zoos/id: 删除某个动物园
- GET /zoos/id/animals: 列出某个指定动物园的所有动物
- DELETE/zoos/id/animals/id: 删除某个指定动物园的指定动物
动词的覆盖
有些客户端只能使用GET和POST这两种方法。服务器必须接受POST模拟其他三个方法(PUT、PATCH、DELETE)。这时,客户端发出的 HTTP请求,要加上X-HTTP-Method-Override属性,告诉服务器应该使用哪一个动词,覆盖POST 方法。
宾语必须是名词
就是API的url,是HTTP动词作用的对象,所以应该是名词。例如/books这个URL就是正确的,而下面的URL不是名词,都是错误的写法。如下:
GET / getAllUsers ? name = wc
POST / createUser
POST / deleteUSer
复数名词
URL是名词,那么是使用复数还是单数? 没有统一的规定,但是我们通常操作的数据多数是一个集合,比如GET/books , 所以我们就使用复数。统一规范,建议都使用复数URL,比如获取id =2的书GET /books/2要好于GET/book/2 。
避免出现多级URL
有时候我们要操作的资源可能是有多个层级,因此很容易写多级URL,比如获取某个作者某种分类的文章。
GET / authors / 2 / categories / 2 // 获取作者ID=2获取分类=2的文章
这种URL不利于拓展,语义也不清晰更好的方式就是除了第一级,其他级别都是通过查询字符串表达。正确方式:
GET / authors / 2 ? categories = 2
查询已发布的文章
错误写法: GET / artichels / published
正确写法: GET / artichels ? published = true
过滤信息
状态码如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数, 过滤返回结果。
下面是一些常见的参数。
- ?limit=10: 指定返回记录的数量
- ?offset=10: 指定返回记录的开始位置。
- ?page=2&per_page=100: 指定第几页,以及每页的记录数。
- ?sortby=name&order=asc: 指定返回结果按照哪个属性排序,以及排序顺序。
- ?animal_type_id=1: 指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoo/ID/animals 与GET /animals?zoo-id=ID的含义是相同的。推荐后者,避免出现多级URL。
状态码必须精确
客户端的请求,服务求都必须响应,包含HTTP状态码和数据。
HTTP状态码就是一个三位数,分成五个类别。
-
1xx︰相关信息
-
2xx: 操作成功,200状态码表示操作成功,但是不同的方法可以返回更精确的状态码。
- GET: 200 OK
- POST: 201 Created
- PUT: 200 OK
- PATCH: 200 OK
- DELETE: 204 No Content
-
3xx: 重定向
-
4xx︰客户端错误,4xx状态码表示客户端错误,主要有下面几种。
- 400 Bad Request:服务器不理解客户端的请求,未做任何处理。
-401 Unauthorized:用户未提供身份验证凭据,或者没有通过身份验证。
-403 Forbidden:用户通过了身份验证,但是不具有访问资源所需的权限。 - 404 Not Found:所请求的资源不存在,或不可用。
- 405 Method Not Allowed:用户已经通过身份验证,但是所用的HTTP方法不在他的权限之内。
- 410 Gone:所请求的资源已从这个地址转移,不再可用。
- 415 Unsupported Media Type:客户端要求的返回格式不支持。比如,API只能返回JSON格式,但是客户端要求返回XMIL格式。
- 422 Unprocessable Entity :客户端上传的附件无法处理,导致请求失败。
- 429 Too Many Requests:客户端的请求次数超过限额。
- 400 Bad Request:服务器不理解客户端的请求,未做任何处理。
-
5xx: 服务器错误,5xx状态码表示服务端错误。一般来说,API不会向用户透露服务器的详细信息,所以只要两个状态码就够了。
- 500 lnternal Server Error:客户端请求有效,服务器处理时发生了意外。
- 503 Service Unavailable:服务器无法处理请求,一般用于网站维护状态。
服务器响应
-
不要返回纯文本 API返回的数据格式,不应该是纯文本,而应该是一个JSON对象,因为这样才能返回标准的结构化数据。所以,服务器回应的HTTP头的Content-Type属性要设为application/json 。客户端请求时,也要明确告诉服务器,可以接受JSON格式,即请求的HTTP头的ACCEPT属性也要设成 application/json。下面是一个例子。
-
发生错误的时候,不要返回200状态码 有一种不恰当的做法是,即使发生错误,也返回200状态码,把错误信息放在数据体里面,就像下面这样。
HTTP / 1.1200 OK
Content - Type: application / json
{
"status": "fail",
"msg": "错误"
}
上面代码中,解析数据体以后,才能得知操作失败。这种做法实际上取消了状态码,这是完全不可取的。正确的做法是,状态码反映发生的错误,具体的错误信息放在数据体里面返回。下面是正确方式:
HTTP / 1.1 400 Bad Request
Content - Type: application / json
{
"status": "fail",
"msg": "错误"
}
Restful API案例
// router/user.js
let Router = require("@koa/router")
let captcha = require("trek-captcha")
let router = new Router();
router.prefix("/user")
// 当成数据库中的数据
let users = [
{ id: 1, name: "malu", age: 18 },
{ id: 2, name: "wangcai", age: 28 },
];
// 如果前端没有传递过来了一个姓名,获取所有用户信息
// 或
// 如果前端传递过来了一个姓名,那就根据姓名获取某个用户的信息
// get请求传参:1)query 2)params
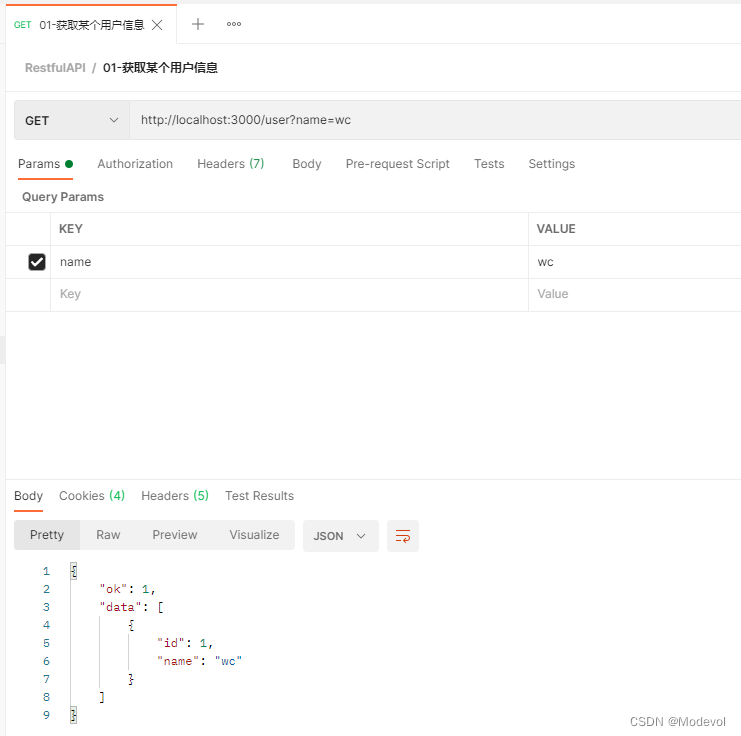
router.get("/", async (ctx, next) => {
let name = ctx.query.name;
let data = users;
if (name) {
data = users.filter(u => u.name == name)
}
ctx.body = {
ok: 1,
data
}
})
// 根据ID获取某个用户的信息
// get请求传参:1)query 2)params
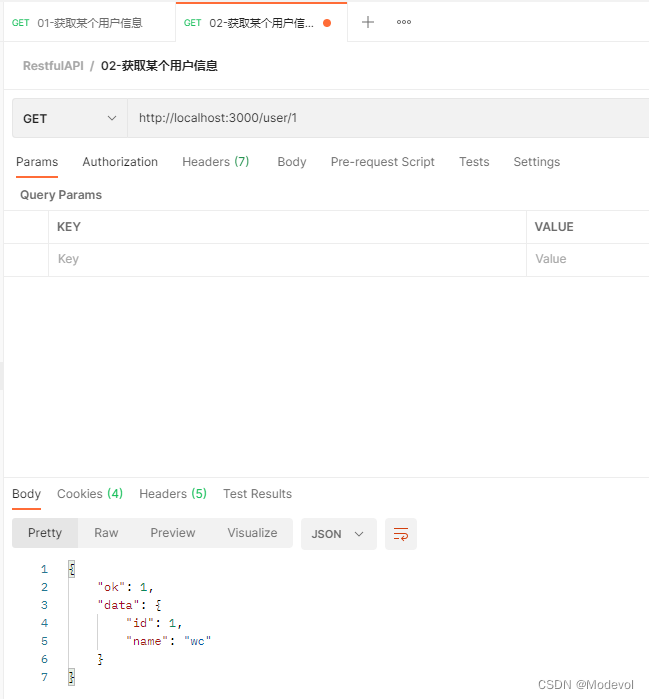
router.get("/:id", ctx => {
let id = ctx.params.id;
// console.log(id);
// 前端传递给后端的数据是一个字符串
// console.log(typeof id);
let data = users;
if (id) {
// +id +"001" +就是把一个string类型转成number类型
data = users.filter(u => u.id === +id)
}
ctx.body = {
ok: 1,
data
}
})
// 添加用户
router.post("/", ctx => {
let name = ctx.request.body.username;
let age = ctx.request.body.userage;
let id = users.length + 1;
let user = { id, name, age };
users.push(user);
ctx.body = {
ok: 1,
msg: "添加用户成功"
}
})
// 删除某个用户
// /:id params传参
router.delete("/:id", ctx => {
let id = +ctx.params.id;
// 根据id找到当前用户的索引
let idx = users.findIndex(u => u.id === id);
// 没有找到就返回-1
if (idx > -1) {
users.splice(idx, 1)
}
ctx.body = {
ok: 1,
msg: "删除用户成功"
}
})
// 修改用户
router.put("/", ctx => {
// put请求传递的参数获取方式和post是一样的
let id = +ctx.request.body.id;
let idx = users.findIndex(u => u.id === id);
if (idx > -1) {
users[idx].name = ctx.request.body.username
users[idx].age = ctx.request.body.userage
}
ctx.body = {
ok: 1,
msg: "修改用户成功"
}
})
// 不管是前端,还是后端
// 前期写业务:增删改查
// CRUD
module.exports = router;
入口JS如下:
const Koa = require('koa')
const index = require('./router/index')
const users = require('./router/user')
const bodyParser = require('koa-bodyparser')
const app = new Koa()
app.use(bodyParser());
// 注册路由
app.use(index.routes())
index.allowedMethods()
app.use(users.routes())
users.allowedMethods()
app.listen(3000, () => {
console.log('3000端口被监听了~~')
})
postman效果如下:
KOA其它知识
解决跨域
安装: npm i koa2-cors
const koa = require('koa');
const cors = require('koa2-cors');
const app = new koa();
app.use(cors());
文件上传
安装: npm i [email protected]
// router/index.js
const Router = require('@koa/router');
const multer = require('koa-multer')
// 配置 磁盘存储
// diskStorage dist是硬盘的意思 Storage是存储的意思
const storage = multer.diskStorage({
// 文件保存路径
destination: function(req, file, cb) {
cb(null, 'public/upload')
},
// 修改文件名称
filename: function(req, file, cb) {
// 获取后缀名
const filterFormat = file.originalname.split('.')
cb(null, Date.now() + '.' + filterFormat[filterFormat.length - 1])
},
})
//加载配置
const upload = multer({
storage
})
const router = new Router();
router.prefix('/user')
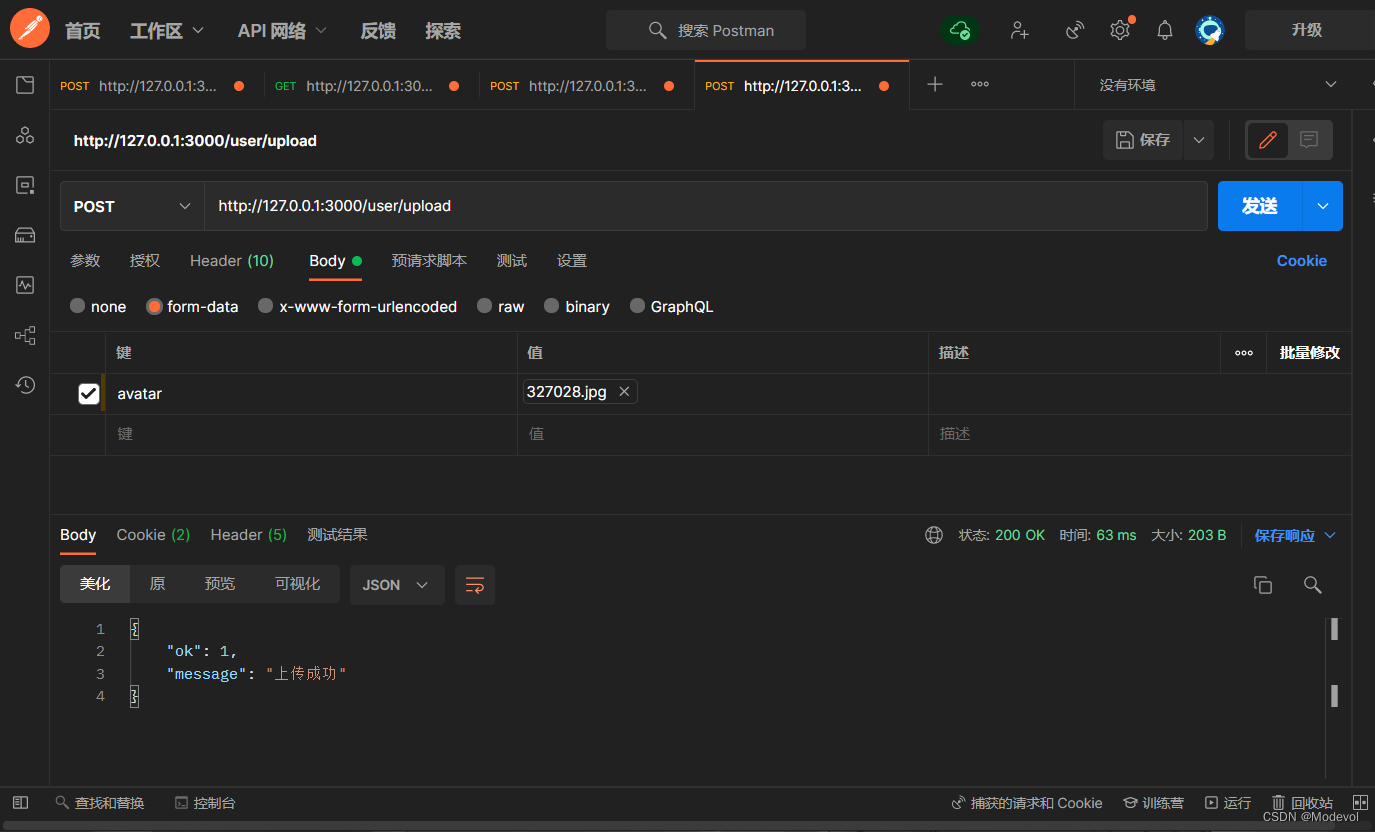
router.post('/upload', upload.single('avatar'), (ctx, next) => {
// file 是avatar文件的信息
// ctx.req.body 文本域的数据 如果存在
console.log(ctx.req.file.filename)
ctx.body = {
ok: 1,
message: "上传成功"
}
})
module.exports = router;
postman中测试如下:
表单验证
安装: npm i [email protected]
// router/index.js
const Router = require('@koa/router');
const bouncer = require('koa-bouncer')
const router = new Router();
router.prefix('/user')
// 表单验证
router.post('/', async (ctx, next) => {
console.log(ctx.request.body)
// ctx.request.body {uname,pwd1,pwd2}
try {
/*
ctx.validateBody('username')
.required('Username is required')
.isString()
.trim()
.isLength(3, 15, 'Username must be 3-15 chars');
*/
ctx
.validateBody('uname')
.required('用户名是必须的')
.isString()
.trim()
.isLength(4, 8, '用户名必须是4~8位')
ctx
.validateBody('email')
.optional()
.isString()
.trim()
.isEmail('非法的邮箱格式')
ctx
.validateBody('pwd1')
.required('密码是必填项')
.isString()
.trim()
.isLength(6, 16, '密码必须是6~16位')
ctx
.validateBody('pwd2')
.required('密码是必填项')
.isString()
.trim()
.eq(ctx.vals.pwd1, '两次密码不一致')
console.log(ctx.vals)
ctx.body = {
code: 1,
}
} catch (error) {
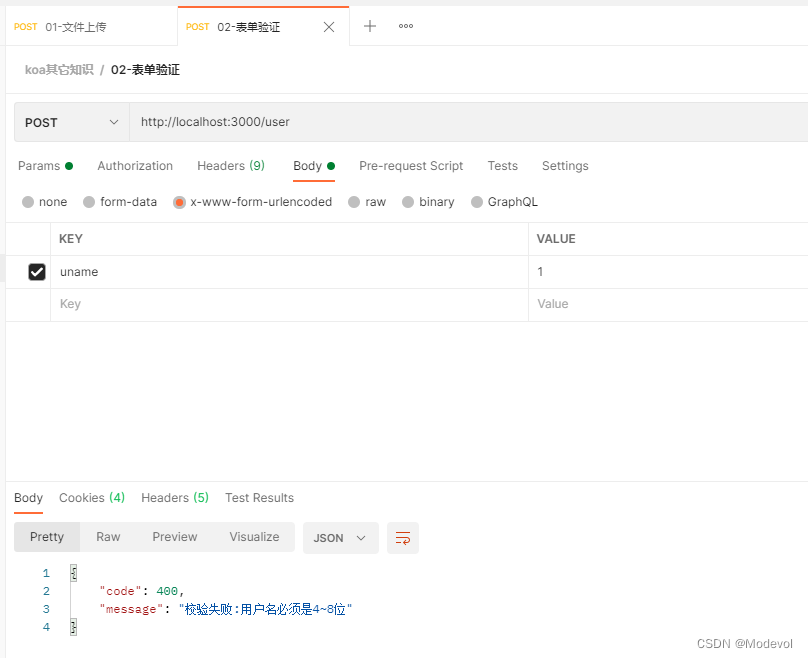
// 校验异常
if (error instanceof bouncer.ValidationError) {
console.log(error)
ctx.status = 400
ctx.body = {
code: 400,
message: '校验失败:' + error.message,
}
return
}
throw error
}
})
module.exports = router;
入口JS如下:
const Koa = require('koa')
const index = require('./router/index')
const users = require('./router/user')
const bodyParser = require('koa-bodyparser')
const static = require('koa-static');
const bouncer = require('koa-bouncer');
const app = new Koa()
// 使用校验中间件
app.use(bouncer.middleware());
app.use(bodyParser());
app.use(static(__dirname + '/public'))
// 注册路由
app.use(index.routes())
index.allowedMethods()
app.use(users.routes())
users.allowedMethods()
app.listen(3000, () => {
console.log('3000端口被监听了~~')
})
postman中测试如下:
图形验证码
安装: npm i [email protected]
// router/index.js
const Router = require('@koa/router');
const bouncer = require('koa-bouncer')
const catpcha = require('trek-captcha')
const router = new Router();
router.prefix('/user')
// 图形验证码
router.get('/captcha', async (ctx, next) => {
const {
token,
buffer
} = await catpcha({
size: 4
});
console.log(data); //{buffer:图片,token:'dbpwt'}
// ctx.state.bufferToken = token
//token的作用 前端输入完验证码与此时的token做对比
ctx.body = buffer;
})
module.exports = router;
入口JS:
const Koa = require('koa')
const index = require('./router/index')
const users = require('./router/user')
const bodyParser = require('koa-bodyparser')
const static = require('koa-static');
const bouncer = require('koa-bouncer');
const app = new Koa()
app.use(bouncer.middleware());
app.use(bodyParser());
app.use(static(__dirname + '/public'))
// 注册路由
app.use(index.routes())
index.allowedMethods()
app.use(users.routes())
users.allowedMethods()
app.listen(3000, () => {
console.log('3000端口被监听了~~')
})
在postman中测试如下:
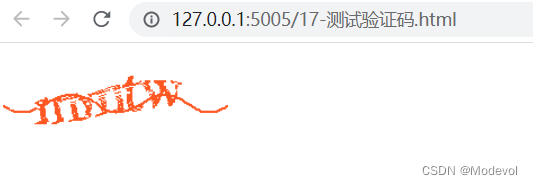
使用img标签,使用验证码如下:
<!-- http:// 必须要写,之前不写,是由于浏览器或postman自动生成 -->
<img src="http://localhost:3000/user/captcha" alt="">
八、此页面所有依赖
//dependencies属性是指定无论开发环境还是生成环境都需要依赖的包
//devDependencies生产依赖
总结安装依赖
npm init –y 生成配置文件
npm i koa@2.13.4 -S koa
npm i @koa/router@10.1.1 路由中间件koa-router
npm i koa-bodyparser@4.3.0 post请求
npm i koa-session@6.2.0 session
npm i koa-jwt@4.0.3 jwt中间件
npm i jsonwebtoken@8.5.1 ⽤于⽣成token下发给浏览器
npm i koa-static@5.0.0 静态资源托管
npm i koa2-cors 解决跨域
npm i koa-multer@1.0.2 文件上传
npm i koa-bouncer@6.0.0 表单验证
npm i trek-captcha@0.4.0 图形验证码
npm i koa-logger@3.2.1 koa-logger处理⽇志
npm i koa-onerror@4.2.0 koa-erros处理错误
npm i koa-log4@2.3.2 koa-log4处理⽇志
npm i express@4.17.3 express
npm i mongodb@4.4.0 mongodb
npm i mongoose@6.2.4 mongoose
monogodb原⽣驱动( npm i )
"dependencies": {
"express": "^4.17.3",
"mongodb": "^4.4.0",
"mongoose": "^6.2.4",
"sequelize": "^6.17.0"
}
班级学生管理(npm i)
"dependencies": {
"@koa/router": "^10.1.1",
"express": "^4.17.3",
"koa": "^2.13.4",
"koa-bodyparser": "^4.3.0",
"koa-static": "^5.0.0",
"mongodb": "^4.4.0",
"mongoose": "^6.2.4",
"sequelize": "^6.17.0"
}
后台管理系统(依赖)
bcrypt 对数据进⾏加盐
下载 bcrypt 包时,请先全局下载 node-gyp 包,npm i node-gyp -g
jsonwebtoken JSON WEB令牌实现
koa-jwt Koa JWT身份验证中间件
koa-bouncer Koa路由的参数验证库
basic-auth Nodejs基本身份验证解析器
mongoose MongoDB DOM框架
redis ⾼性能Redis客户端。
moment 解析,验证,操作和显示⽇期时间库
本地访问地址
localhost
127.0.0.1