情感分类是一个大领域具体研究的话还需要细分,在对数据分析方面有较强的实用价值。目前有传统方法和深度学习方法,我主要针对深度学习方法进行学习,深度学习方法需要大量数据,在缺乏数据的情况下,预训练的词向量可以作为模型输入,文中提到了中英两个预训练词向量的下载地址,可以一试。本文没有多少新知识。

- 情感分析旨在让机器具备像人一样的情感理解和表达能力。
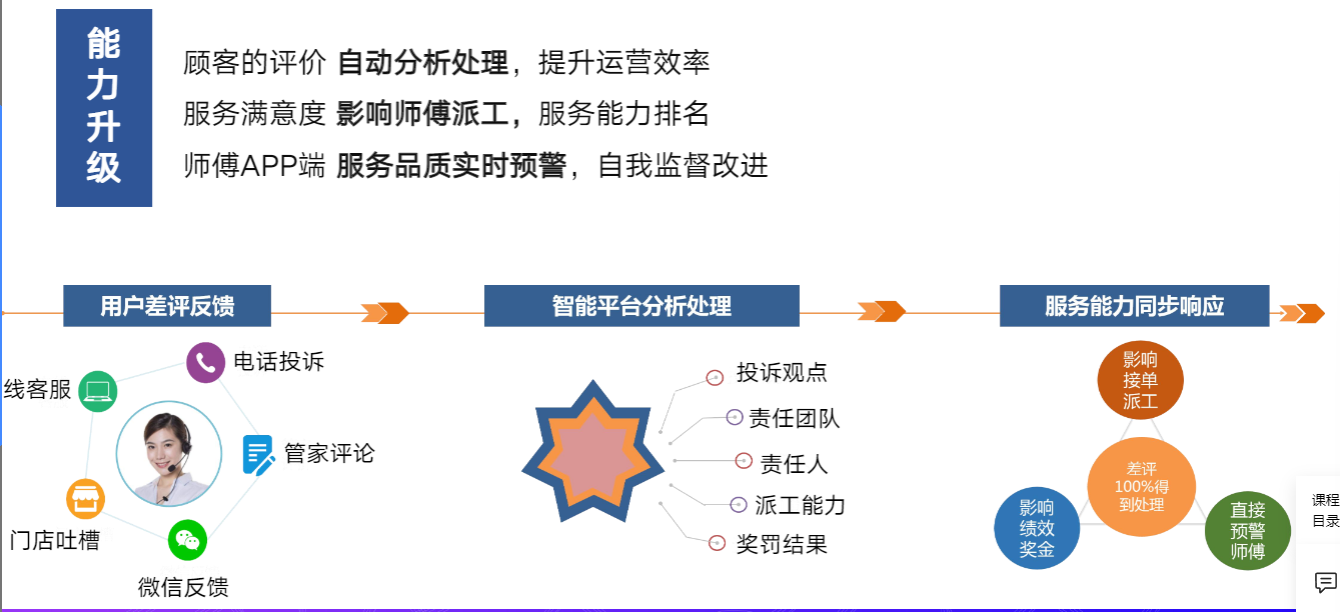
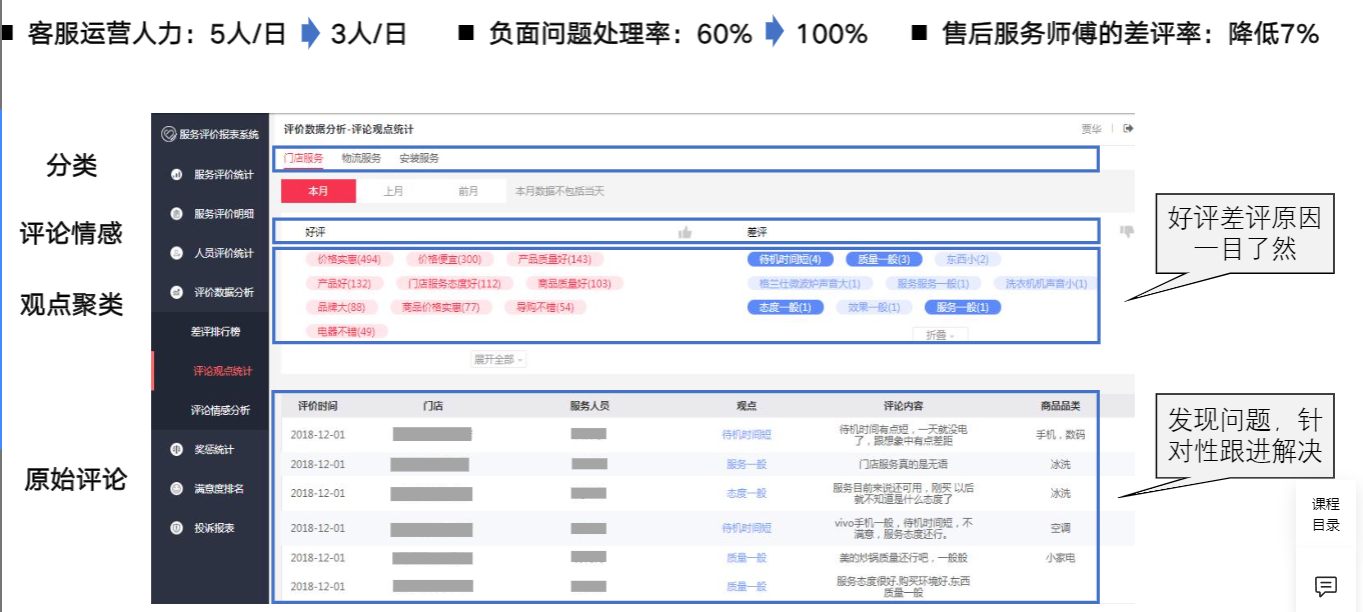
- 应用案例:国美评论智能分析平台
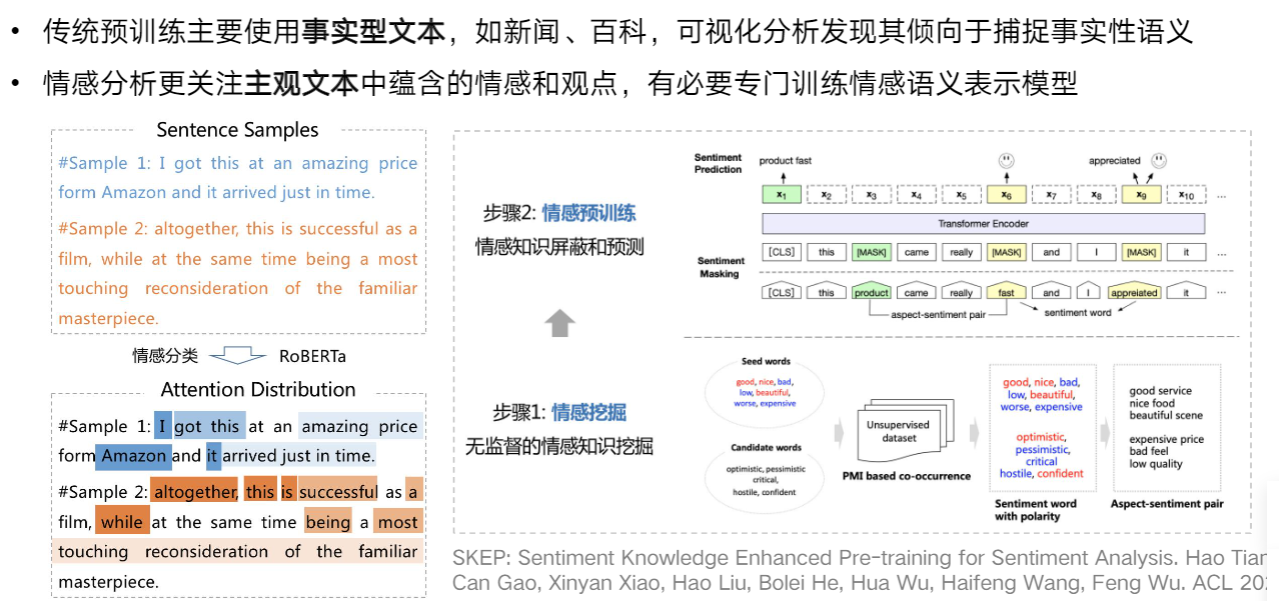
- SKEP:情感知识增强的预训练模型,传统预训练主要适用事实型文本,倾向于捕捉事实性语义,情感分析更关注文本中蕴含的情感和观点,有必要专门训练情感语义表示模型
目录
1.3.3 电影评论(用户评分与文本是否一致)预测股票(通过文本预测情感级别)电商评论(通过评论判断目标是否符合需求)舆情分析(分析舆情中不同情绪的比重,对产品的评价进行分析)
1 情感分析定义及应用
1.1 概述
文本情感分类又称意见挖掘、倾向性分析等。也就是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。文本情感分类重点强调文本的倾向性分析。包括句子级别的情感分类和基于目标的情感分类。
情感分析旨在让机器具备像人一样的情感理解和表达能力。
社交媒体、自媒体、线上服务等迅速发展,产生了海量主观评论数据,提供了广阔的研究和应用场景。

1.2 意义
在生活中,你可以根据朋友问问题的语气来判断他的情绪,是无聊、生气或者好奇。即使在纯文字的聊天中,也可以根据顾客的用词和标点判断他是否愤怒。要让计算机真正理解人类日常交流用语,单单了解单词的定义是远远不够的,计算机还要理解人类的情感,只有这样才能最终理解人每天的交流方式。
1.3 应用
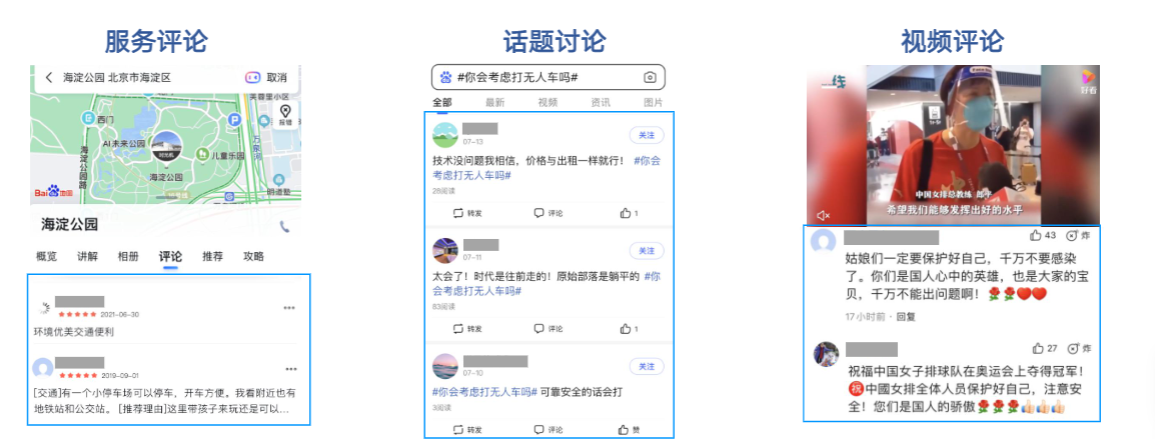
1.3.1 服务评论分析
- 舆情分析、POI分析等相关应用
- 企业升级商品口碑分析等相关应用

1.3.2 应用案例:国美评论智能分析平台
1.3.3 电影评论(用户评分与文本是否一致)预测股票(通过文本预测情感级别)电商评论(通过评论判断目标是否符合需求)舆情分析(分析舆情中不同情绪的比重,对产品的评价进行分析)
1.4 技术发展趋势:深度学习、预训练成为主流

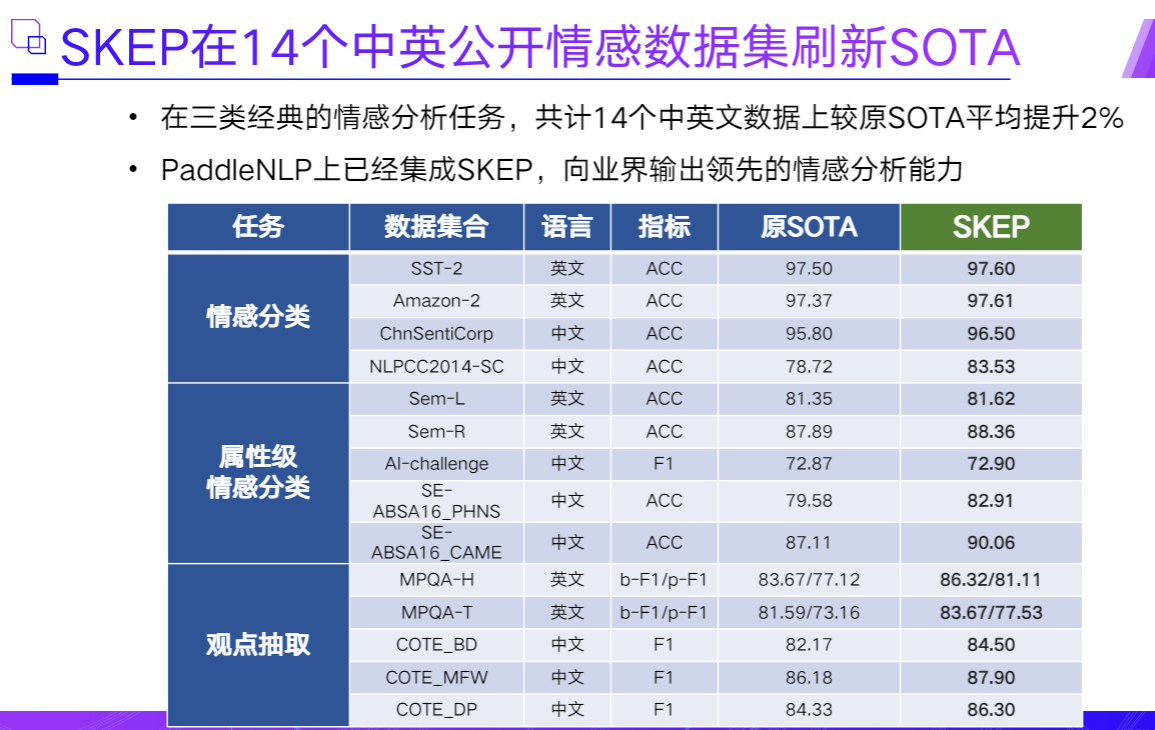
1.4.1 SKEP:情感知识增强的预训练模型
1.5 情感分析项目实践
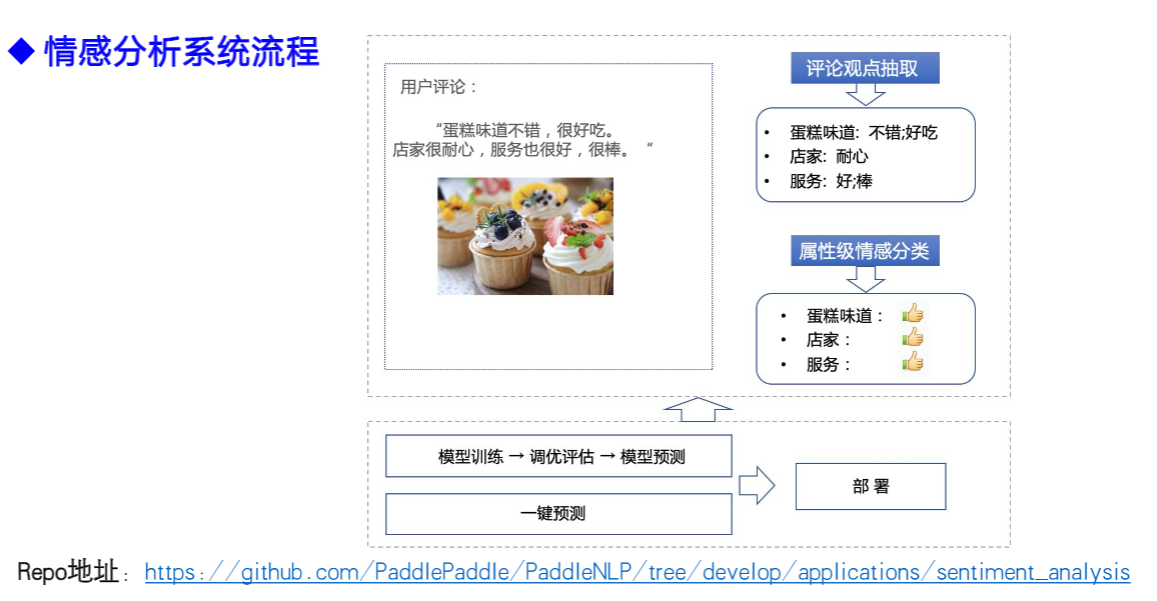
1.5.1 情感分析系统流程
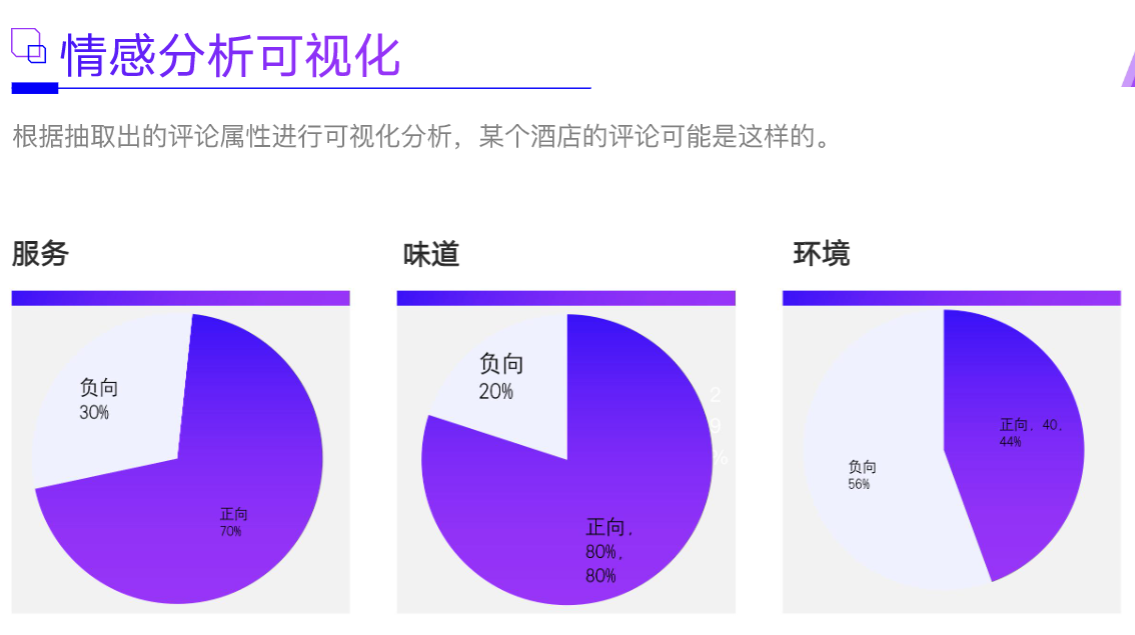
1.5.2 项目特色

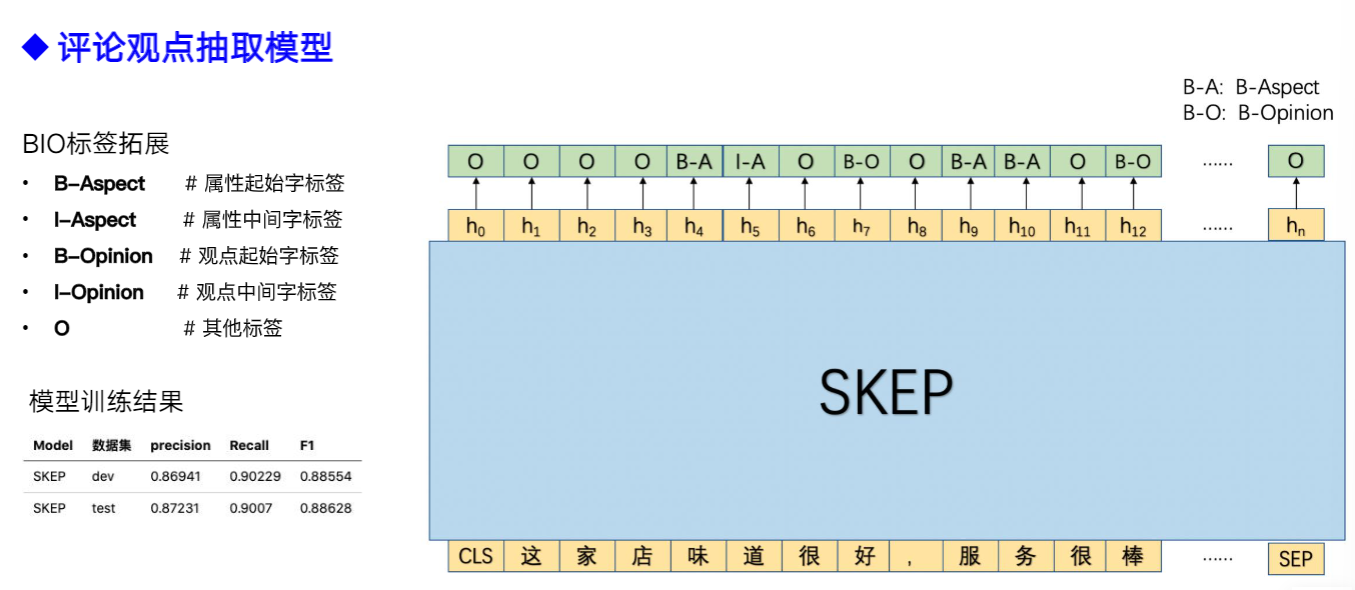
1.5.3 情感分析技术方案

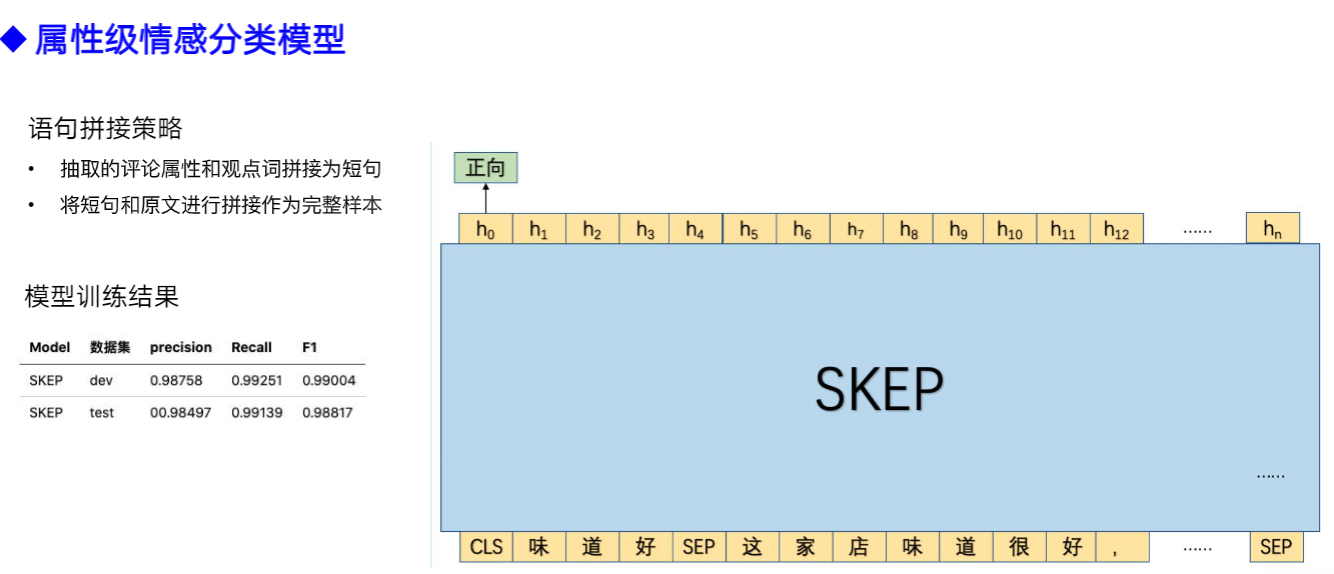

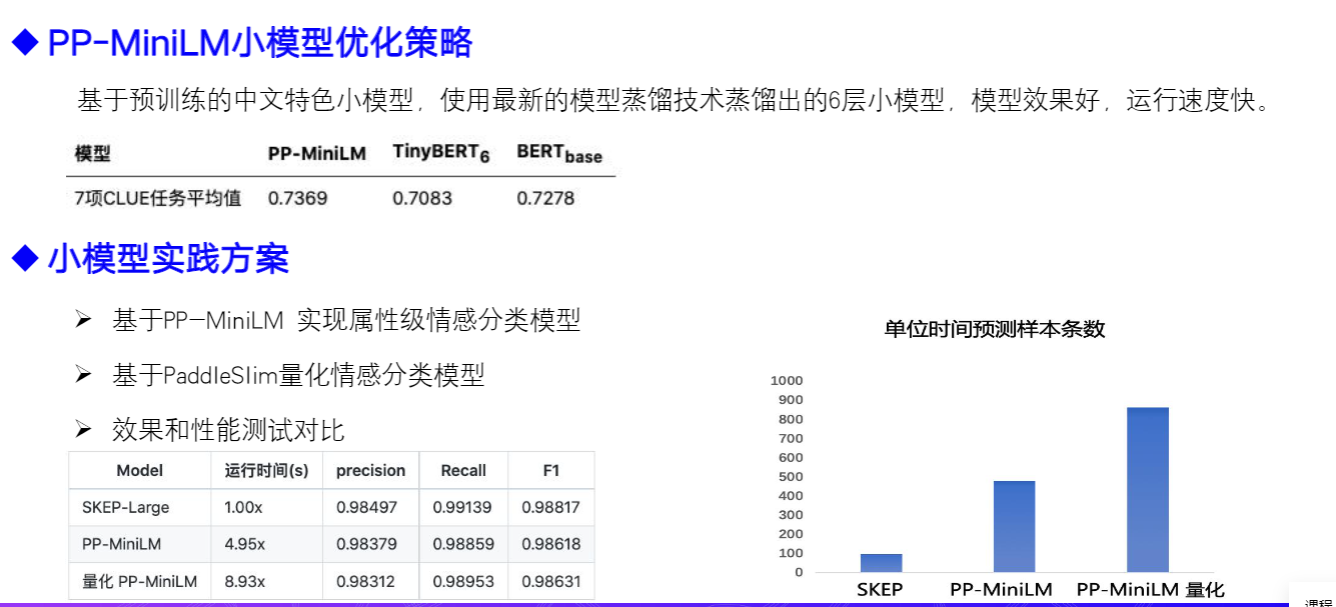
1.5.4 核心代码解读
2、句子级别的情感分类
任务定义
输入是一个句子的集合(可用词袋模型也可以用s2s模型)、输出一个可能的情感类别

数据集介绍
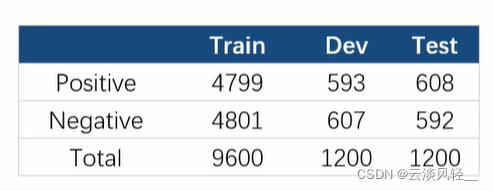
1、ChnSentiCorp(二分类情感分析中文数据集,包含酒店、笔记本和书籍的网购评论。主要评测指标为准确率=预测正确的样本个数/总样本个数)初学者友好的数据集,可以试试不同模型在这个数据集上的准确率。提供了验证集,可用于控制模型训练。选取最优的参数
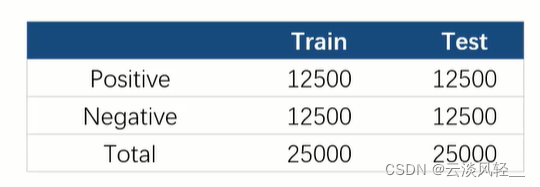
2、IMDB(二分类情感分析英文数据集,包含50000条电影评论。主要评测指标为准确率=预测正确的样本个数/总样本个数)
步骤

- 基于词表的方法,如图中例,不论正向或逆向都可能导致分词错误
- 后提出了基于语言模型的分词方法,利用语言模型的统计信息来找到概率最大的切分路径,各种路径的好坏程度可以通过概率求解
- 后提出了基于序列标注的分词方法,需要有充分的训练集,是一种机器学习的方法
jieba分词
- 中文分词工具
- 三种模式:精确模式、全模式和搜索引擎模式
- 可进行词性标注
- 可加入自定义词典,支持多语言,简体繁体
- 全模式:把句子中所有可以成词的词语都扫描出来,但不能解决歧义
- 精确模式:将句子精确的切开,适合文本分析
- 搜索引擎模式:在精确模式的基础,对长词再次切分,可以提高召回率,适用于搜索引擎分词

主要思想是针对步骤1输入句子的每一个分词结果都输出一个对应的词性,jieba分词是可以打标签的。动词名词形容词是情感分类任务比较有用的特征,可以重点提取这些词性的词作为模型的输入,来训练情感分类的模型。

主要思想是对文本进行情感词类匹配,匹配出的情感词可以通过不同的方式来汇总情感词,进行最终的评分得到文本的情感倾向。这些情感词可以手动构造也可以下载(知网提供了情感词的词典,中英文,包括从评价情感主张程度等不同方面的,这也就是细粒度划分了)jieba可以自定义词典,导入、构造或者修改。
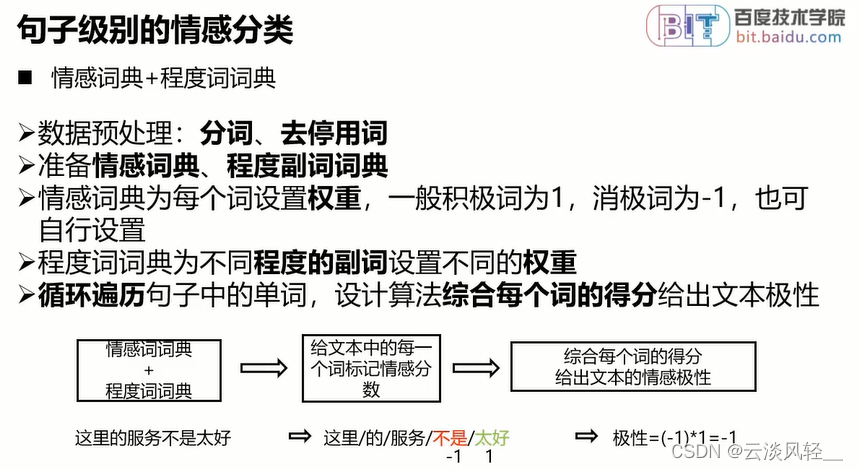
- 这个模型由情感词典和程度词词典构成,先分词去停用词(哈工大的停用词词表)。
- 准备情感词词典、程度副词词典(网络可下载的,也可以进行手动标注)。
- 程度副词的情况来判断权重,若尾部有叹号,情绪加强需要特殊处理
- 循环遍历这个综合得分,可以加权求和,积极词得分求和 - 消极词得分求和,符号的处理方式也会对结果产生改变
句子级别情感分类上的模型和方法
1、机器学习

可以直接调用其中的方法
2、深度学习

深度学习方法与传统方法相比确实提高了性能,但是也存在缺点(缺乏大规模数据时),所以我们一般使用预训练好的词向量(word2vec,ELMo训练出来的词向量都可以在网络上下载,地址如下)作为神经网络的输入
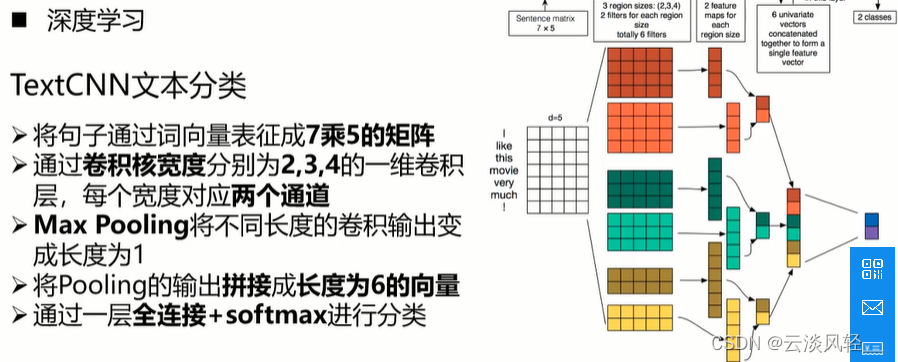
采用CNN进行文本编码,后续接分类器来实现文本分类问题。
图中例:d=5是wordembedding的维度是5,一维卷积(窗口大小*词向量维度),maxpooling来选择最显著的词做下一步的操作,全连接层,最后得到分类结果
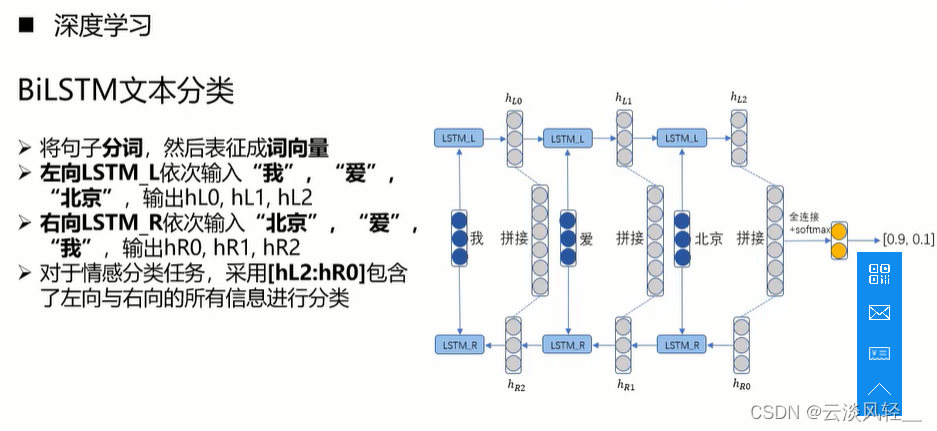
也可以采用RNN循环神经网络,可以弥补卷积神经网络中卷积核大小固定导致的网络无法确定当前词与距离较远词之间的关系,可以更好的捕捉长距离依赖的问题,在各种NLP任务中RNN确实能更好的表达上下文的信息。
如上图,每个LSTM隐藏层都会输出维度是3的向量,拼接两个对应位置的LSTM输出得到维度是6的向量,有了结果拼接的向量之后,通过averagepooling或attention的机制可以对语义向量进行加权求和、求平均等操作,句子的语义表示输入全连接层,接一个softmax函数实现情感分类。

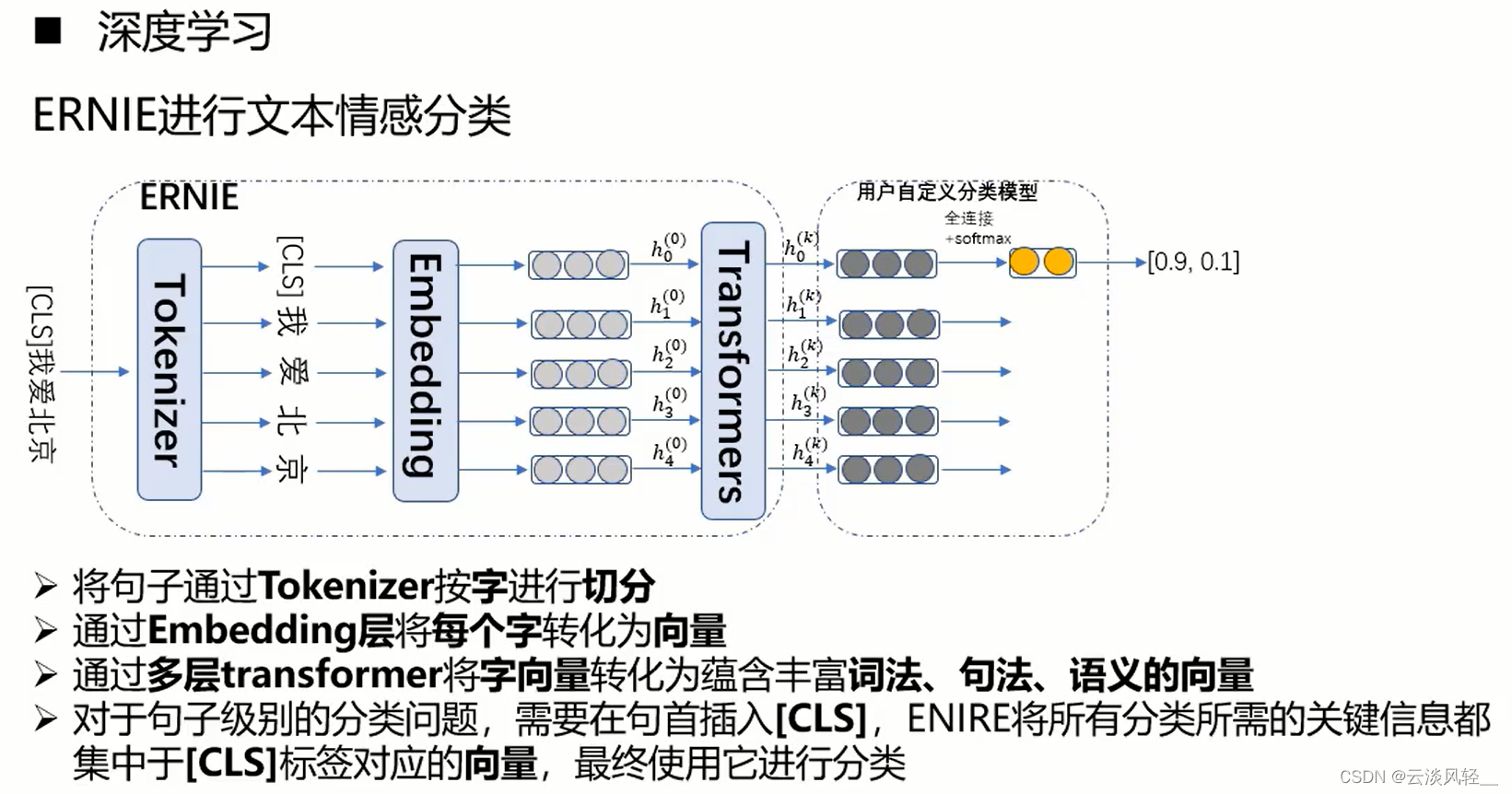
如上图,分词、变词向量、转为新词向量、记得插入特殊标记