引言
我在上一篇博客总结了网络威胁情报(CTI)技战术(TTPs)分析的背景、内容并提供了一个端到端的识别方法。聪明的小伙伴可能就要说了,这个端到端的方法没办法定位到TTPs出现的位置呀。所以在这篇博客里面,我提供另外几种解决"Where and What"问题的TTPs抽取思路。
问题定义
因为涉及到识别和定位TTPs,这个任务本质上是一个可解释的神经网络思想——就是说我不仅仅需要解释我能够从网络威胁情报中识别到TTPs,还应该给予一种解释神经网络决策过程的方法,使得使用者能够一下get到我的思路,甚至约束、改进我的思路。因此,我们的目标变成了实现一个可解释的从CTI获取TTPs的方法。
可解释神经网络
在提出我们自己的方法前,我们需要了解一下市面上常见的解释模型有哪些。经过调研我们发现主要有几种思路:
- 事后解释-LIME:LIME是一种事后的解释技术:就是说我先有个训练好的模型,然后通过LIME对该模型解释。LIME依托于一种简单的思想,就是我给定一个例子,LIME通过生成许许多多的类似例子,放到该模型中预测,获得一系列伪标注的数据;然后他训练一个线性分类器( Y = X ⋅ W Y=X\cdot W Y=X⋅W)去拟合这个伪标注数据集,获得各部分属性的重要性权重。
- 事后解释-SHAP:SHAP是另一种对给定模型的解释方法。与LIME方法不同,他是依据游戏贡献对各种属性和属性值进行积分,来判断属性的重要性。简单来讲,他认为预测值概率 Y Y Y是基础概率 Y ‾ \overline{Y} Y和各种输入特征 X i ∈ X X_i\in X Xi∈X通过条件概率转移方法 f ( ⋅ ) f(\cdot) f(⋅)获得的概率之和( Y = Y ‾ + f ( X 1 ) + ⋯ + f ( X N ) Y=\overline{Y}+f(X_1)+\cdots+f(X_N) Y=Y+f(X1)+⋯+f(XN))。通过不停修正 f ( ⋅ ) f(\cdot) f(⋅)获得最终的解释。
- 事中解释-注意力机制:注意力机制通过模仿人类眼球的聚焦动作对数据添加softmax激活的掩码,实现对关键特征的增强和对无关数据的隐藏。他对模型的解释结果一般直接是在原图像或者文本上加上热力图获得人工认可。
- 事中解释-对抗学习:对抗学习通过模仿原始输入的分布生成混淆样本,带入判别器进行判别验证数据质量。所以也有研究者,例如YOLOv4也提出通过混淆原始输入的特征验证特征的作用。因此也可以作为解释方法
经过上述对比,最总我们选择采用注意力机制作为解释的框架,因为他比较方便形成一套端到端的方法。
注意力机制方法框架
我们对CTI-TTPs关键信息首次的尝试是使用注意力机制实现TTPs定位。该框架的提出目标是实现CTI-TTPs抽取的特征解释
代码&数据&词嵌入&预训练模型地址
https://github.com/MuscleFish/SeqMask
论文
@article{10.1093/comjnl/bxac172,
author = {Ge, Wenhan and Wang, Junfeng},
title = "{SeqMask: Behavior Extraction Over Cyber Threat Intelligence Via Multi-Instance Learning}",
journal = {The Computer Journal},
year = {2022},
month = {11},
abstract = "{Identification and extraction of Tactics, Techniques and Procedures (TTPs) for Cyber Threat Intelligence (CTI) restore the full picture of cyber attacks and guide the analysts to assess the system risk. Existing frameworks can hardly provide uniform and complete processing mechanisms for TTPs information extraction without adequate knowledge background. A multi-instance learning approach named SeqMask is proposed in this paper as a solution. SeqMask extracts behavior keywords from CTI evaluated by the semantic impact, and predicts TTPs labels by conditional probabilities. Still, the framework has two mechanisms to determine the validity of keywords. One using expert experience verification. The other verifies the distortion of the classification effect by blocking existing keywords. In the experiments, SeqMask reached 86.07\\% and 73.99\\% in F1 scores for TTPs classifications. For the top 20\\% of keywords, the expert approval rating is 92.20\\%, where the average repetition of keywords whose scores between 100\\% and 90\\% is 60.02\\%. Particularly, when the top 65\\% of the keywords were blocked, the F1 decreased to about 50\\%; when removing the top 50\\%, the F1 was under 31\\%. Further, we also validate the possibility of extracting TTPs from full-size CTI and malware whose F1 are improved by 2.16\\% and 0.81\\%.}",
issn = {0010-4620},
doi = {10.1093/comjnl/bxac172},
url = {https://doi.org/10.1093/comjnl/bxac172},
note = {bxac172},
eprint = {https://academic.oup.com/comjnl/advance-article-pdf/doi/10.1093/comjnl/bxac172/47411184/bxac172.pdf},
}
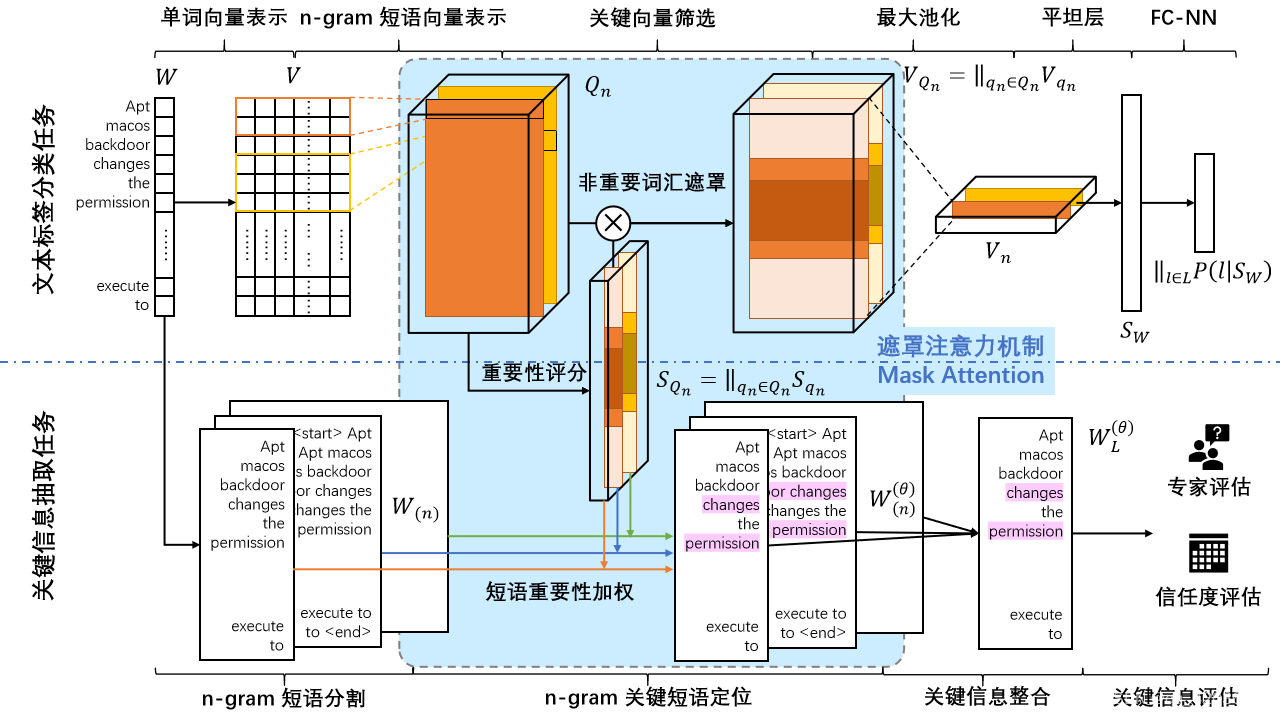
遮罩注意力机制
由于我们的目标是从CTI中识别并定位TTPs,因此需要考虑设计注意力去除噪声保留特征。如果采用原始基于QKV的多头注意力机制。由于Q的加入和多个注意力,虽然会提高识别准确率,但是会使得解释质量下降。例如在下图的翻译中,出现了好几个注意力的热力图,你选择相信哪一个?因此从直觉上,我们希望考虑单个单词的贡献或者2-3个词组成的词组的贡献而不是一大坨奇奇怪怪的注意力。
基于这种想法,我们对经过处理的词向量加入被我们称为遮罩注意力的机制完成重要性划分。该机制首先依赖n-gram机制将语句划分为词或者词组的形式形成语义向量 X X X,然后进行重要性度量,并经过softmax激活形成遮罩。
重要性度量主要考虑了三种方式:
- (Simple vector) SV_Mask-简单的特征加权求和: K = X ⋅ W k K=X\cdot W_k K=X⋅Wk
- (Middle point) MP_Mask-基于中心点的距离度量: K = ( b − ∣ X − X C ∣ p ) ⋅ W k K=(b-\vert X-X_C\vert^p)\cdot W_k K=(b−∣X−XC∣p)⋅Wk
- (Area range) AR_Mask-基于强边界约束的距离度量: K = ( b − ( ∣ X − X min ∣ + ∣ X max − X ∣ ) p ) ⋅ W k K=(b-(\vert X-X_{\min}\vert+\vert X_{\max}-X \vert)^p)\cdot W_k K=(b−(∣X−Xmin∣+∣Xmax−X∣)p)⋅Wk
其中强边界是具备完整的上界限约束和下界限约束的,而中心点没有。
利用三种距离度量获得的分数使用softmax激活: A = s o f t m a x ( K ) = exp ( K i ) ∑ j exp ( K j ) A=softmax(K)=\frac{\exp(K_i)}{\sum_j \exp(K_j)} A=softmax(K)=∑jexp(Kj)exp(Ki),并和 V = X ⋅ W v V=X\cdot W_v V=X⋅Wv点乘获得掩码特征: S = A ⊙ V S=A\odot V S=A⊙V,
分类器
分类器采用简单的CNN网络: f ( X ) = σ ( M L P ( M a x P o o l ( C o n v 1 d ( S ) ) ) ) f(X)=\sigma({\rm MLP}({\rm MaxPool}({\rm Conv1d}(S)))) f(X)=σ(MLP(MaxPool(Conv1d(S))))实现TTPs预测
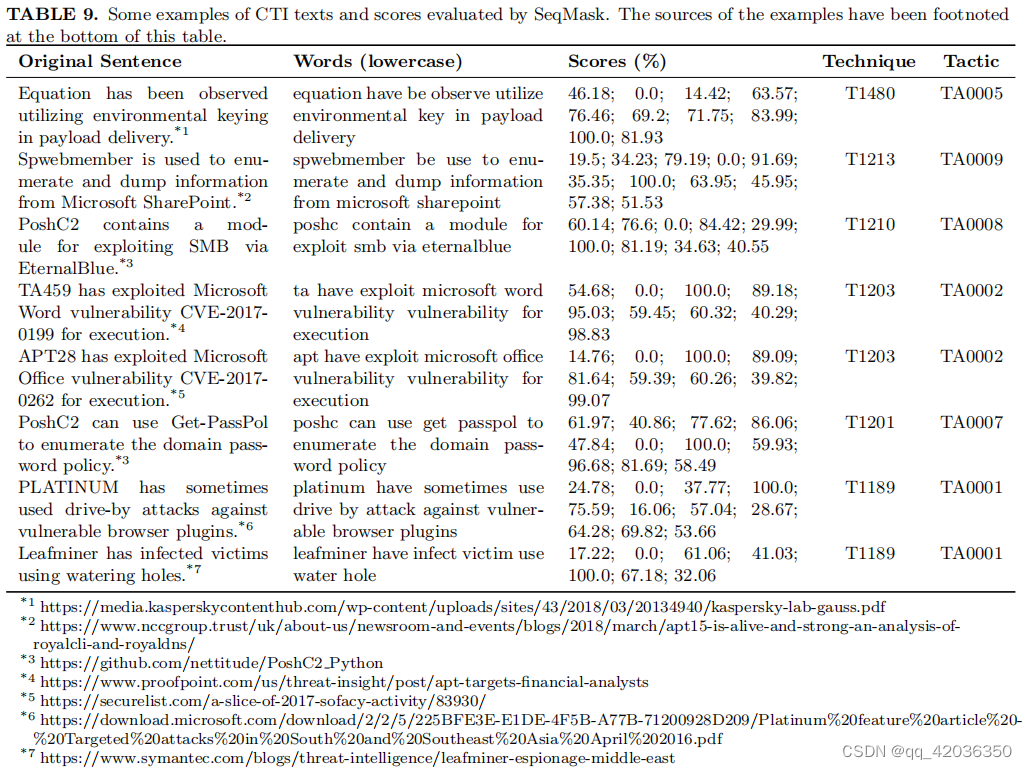
关键词分数结果
下表反映了我们的方法对一些些CTI文本的处理结果。
关键词评估函数
对于关键词的评价采取了两种策略:专家评估和置信度评估。专家评估没啥好说的,就是找一群专家人工看模型抽取的东西正不正确。
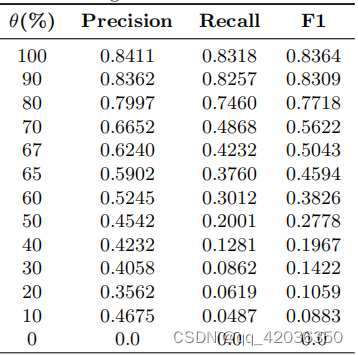
置信度评估是我们提出的一个自监督方法。假设模型抽取了一堆TTPs的证据,每个证据都有一个重要性得分 A A A。我不是需要验证A合不合理吗,那我就选择一个百分比阈值 θ \theta θ,切断 A A A,使得只有低于 θ \theta θ的文本得以保留,高的都删掉。因为理论上高分数的文本肯定重要,那我就不要这部分的文本,我看看剩下的文本还能不能出TTPs。如果可以出,那么说明余下的还有证据,如果出不了了,那么余下的就都是噪声了
上表是结果,我们发现当
θ
=
67
%
\theta=67\%
θ=67%的时候,F1会掉到50%左右(和猜的概率没两样),那么至少说明证据基本上集中到前1/3的位置。
对抗学习方法框架
上述注意力框架是一种软注意力的TTPs特征关注度。所谓“软”是指其抽取的关键词边界过于模糊,例如在Table9中的第一句话,“in, been”等关键词也被赋予了较高的分数。这是不可被接受的。
因此,在我们提供的第二套框架里,我们将会尽可能屏蔽无意义词汇的重要性,剩下 “充分必要” 的TTPs证据。
代码&数据&词嵌入&预训练模型地址
https://github.com/MuscleFish/SATG
论文
@article{GE2023103369,
title = {Explainable cyber threat behavior identification based on self-adversarial topic generation},
journal = {Computers & Security},
volume = {132},
pages = {103369},
year = {2023},
issn = {0167-4048},
doi = {https://doi.org/10.1016/j.cose.2023.103369},
url = {https://www.sciencedirect.com/science/article/pii/S0167404823002791},
author = {Wenhan Ge and Junfeng Wang and Tongcan Lin and Binhui Tang and Xiaohui Li},
keywords = {Cyber threat intelligence, Tactics, Techniques and procedures, Explainable artificial intelligence, Self-Adversarial training, Topic generation and classification},
abstract = {Cyber Threat Intelligence (CTI) provides ample evidence and information regarding the detection of cyber attack activities. Existing methods employ CTI reports to extract Tactics, Techniques and Procedures (TTPs) for attack detection. Nevertheless, these methods are challenged in providing necessary and sufficient evidentiary support for recognition decisions, making it difficult for human operators to comprehend and accept the decision-making process. This paper proposes a topic prototype-based explainable TTPs classification approach, which provides accurate boundaries for key evidences to justify the results of TTPs classification. The proposed method introduces a self-adversarial framework for obtaining necessary and sufficient evidence for TTPs classification. The framework consists of an evidence generator and a TTPs classifier discriminator. The evidence generator utilizes a topic prototype-based keyword importance filtering method to extract evidence from CTI text while removing noise, resulting in an evidence set and a perturbation set. Subsequently, the impact of the evidence set and the perturbation set on TTPs classification is assessed using our siamese discriminator. The discriminator is specifically trained to ensure that only the elements belonging to the evidence set are accurately classified as TTPs information. The experiments primarily test the necessity and sufficiency of TTPs and evidence. In the sufficiency evaluations, classical deep learning methods are used for TTPs classification to verify the accuracy of the results, where the proposed method improves the Micro F1 scores by 0.16% to 6.63% and Macro F1s by 0.26% to 6.85%. To prove necessity, various case-based explainable methods are used to measure the completeness of CTI evidence. The results shows that the proposed method is able to obtain more stable prediction, more reasonable evidence sets, and more significant boundaries.}
}
我们为我们的第二代方法取名为SATG(Self-Adversial Topic Generation,自对抗主题生成)。该方法的原理是将对比学习和对抗学习结合起来。通过将原本的CTI文本划分为正相关关键词和负相关噪声,实现TTPs可信识别。
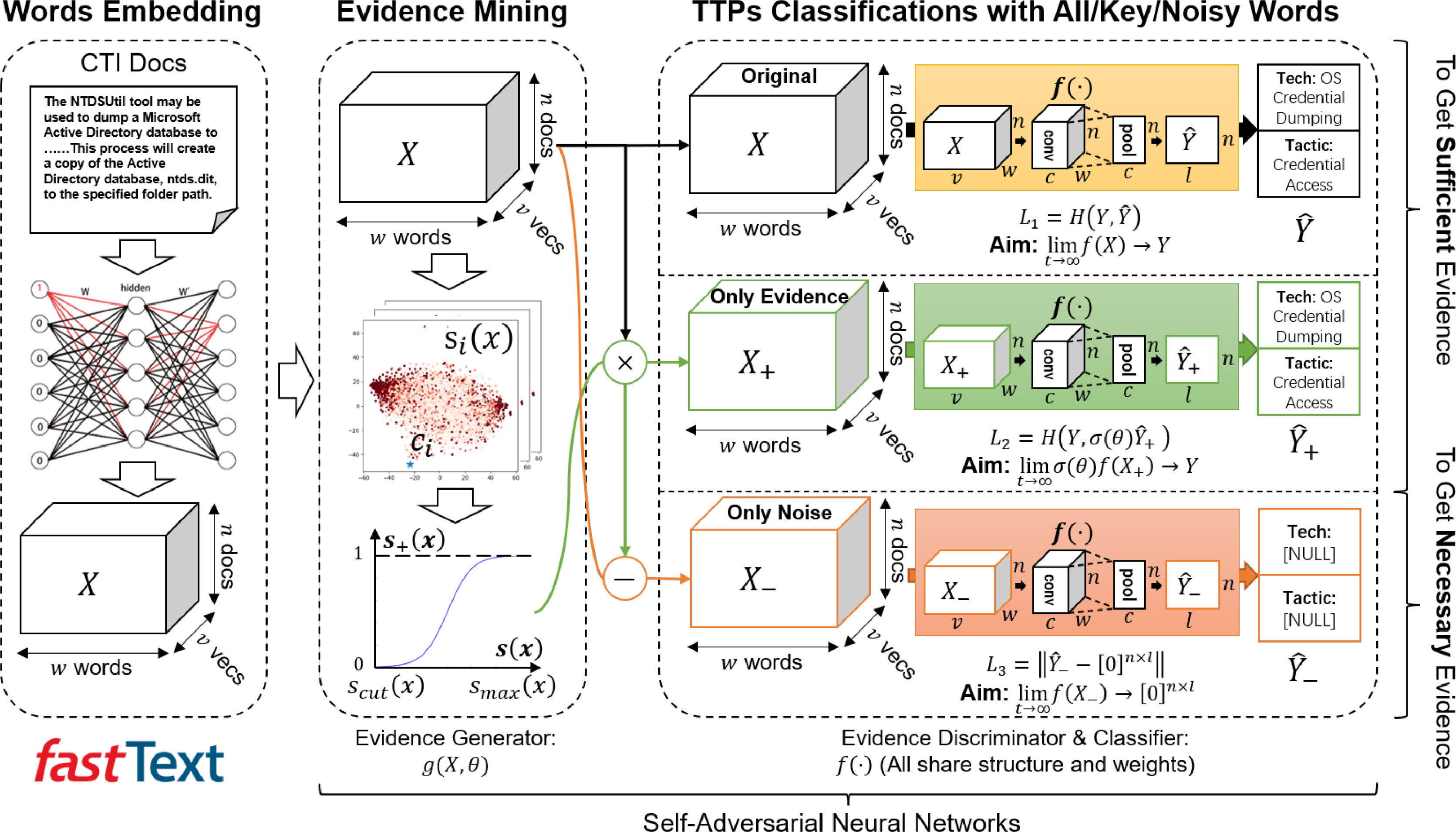
具体而言,首先我们通过SeqMask的遮罩注意力机制生成的CTI文本的关键词分数: S ( X ) = − ∥ ( X − X C ) ⊗ W C ∥ p S(X)=-\Vert(X-X_C)\otimes W_C\Vert_p S(X)=−∥(X−XC)⊗WC∥p。其次确定一个分割阈值 θ \theta θ获得分割分数 S c u t ( X , θ ) S_{cut}(X,\theta) Scut(X,θ),使得低于该阈值的分数所对应的词向量成为噪声 X − X_- X−,高于阈值的文本保留为TTPs关键词 X + X_+ X+。 S c u t ( X , θ ) S_{cut}(X,\theta) Scut(X,θ)的生成可以是两种思路,其一是我取前 ( 1 − θ ) ∣ X ∣ (1-\theta)|X| (1−θ)∣X∣个词,另一个是我取分数高于 θ % \theta\% θ%的词。该阈值分数的生成过程如下
S c u t ( X , θ ) = { m i n ∣ X ∣ ( T o p k = ( 1 − θ ) ∣ X ∣ ( S ( X ) ) ) 取前 ( 1 − θ ) ∣ X ∣ 个词 θ m a x ∣ X ∣ ( S ( X ) ) + ( 1 − θ ) m i n ∣ X ∣ ( S ( X ) ) 取分数高于 θ % 的词 S_{cut}(X,\theta)=\left\{ \begin{array}{ll} min_{|X|}(Top_{k=(1-\theta)|X|}(S(X))) & 取前(1-\theta)|X|个词 \\ \theta max_{|X|}(S(X))+(1-\theta)min_{|X|}(S(X)) & 取分数高于\theta\%的词 \end{array} \right. Scut(X,θ)={min∣X∣(Topk=(1−θ)∣X∣(S(X)))θmax∣X∣(S(X))+(1−θ)min∣X∣(S(X))取前(1−θ)∣X∣个词取分数高于θ%的词
事实上关键词 X + X_+ X+和噪声 X − X_- X−可以通过使用掩码矩阵遮盖 X X X得到。因此,我们只需要保证 X + X_+ X+的掩码 S + S_+ S+对 S ( X ) < S c u t ( X , θ ) S(X)<S_{cut}(X,\theta) S(X)<Scut(X,θ)的 X X X全部为0,而对 S ( X ) ≥ S c u t ( X , θ ) S(X)\geq S_{cut}(X,\theta) S(X)≥Scut(X,θ)的 X X X取 ( 0 , 1 ] (0,1] (0,1]即可选出 X + X_+ X+。而对噪声 X − X_- X−,只需要使用 X − X + X-X_+ X−X+即可获得。因此我们设计了如下的掩码生成机制:
S + ( X , θ ) = σ ( 2 d × s n o r m ( X , θ ) − d ) , w h e r e s n o r m ( X , θ ) = S ( X ) − S c u t ( X , θ ) m a x ∣ X ∣ ( S ( X ) ) − S c u t ( X , θ ) S_+(X,\theta)=\sigma(2d\times s_{norm}(X,\theta)-d), where~s_{norm}(X,\theta)=\frac{S(X)-S_{cut}(X,\theta)}{max_{|X|}(S(X))-S_{cut}(X,\theta)} S+(X,θ)=σ(2d×snorm(X,θ)−d),where snorm(X,θ)=max∣X∣(S(X))−Scut(X,θ)S(X)−Scut(X,θ)
在该机制中, σ \sigma σ是sigmoid激活函数, d d d是放大倍率,一般取4.0~6.0,以保障 S ( X ) ≥ S c u t ( X , θ ) S(X)\geq S_{cut}(X,\theta) S(X)≥Scut(X,θ)的 X X X的 S + ( X , θ ) S_+(X,\theta) S+(X,θ)能够快速接近于1,而不是慢悠悠变化到1。如果 S ( X ) < S c u t ( X , θ ) S(X)<S_{cut}(X,\theta) S(X)<Scut(X,θ),可以发现 s n o r m ( X , θ ) s_{norm}(X,\theta) snorm(X,θ)是负的,在sigmoid激活以后该 S + ( X , θ ) < σ ( − d ) S_+(X,\theta)<\sigma(-d) S+(X,θ)<σ(−d),由于 d d d取4.0~6.0,所以此时 S + ( X , θ ) ≈ 0 S_+(X,\theta)\approx 0 S+(X,θ)≈0。相反,如果 S ( X ) ≥ S c u t ( X , θ ) S(X)\geq S_{cut}(X,\theta) S(X)≥Scut(X,θ),则此时 σ ( − d ) ≤ S + ( X , θ ) ≤ σ ( d ) \sigma(-d)\leq S_+(X,\theta)\leq\sigma(d) σ(−d)≤S+(X,θ)≤σ(d),符合值域 ( 0 , 1 ] (0,1] (0,1]。
则关键词 X + X_+ X+和噪声 X − X_- X−为:
X + = S + ( X , θ ) ⊗ X , X − = X − X + X_+=S_+(X,\theta)\otimes X, X_- = X-X_+ X+=S+(X,θ)⊗X,X−=X−X+
由于我们现在由三种输入了:原始 X X X,关键词 X + X_+ X+和噪声 X − X_- X−。我们希望原始 X X X和关键词 X + X_+ X+能够正常预测TTPs,而噪声 X − X_- X−只能预测空值。在这种结果下就可以说明关键词 X + X_+ X+对TTPs分类有用,是充分条件。同时我们也希望筛选阈值 θ \theta θ足够高,以获得尽可能少的关键词 X + X_+ X+,体现关键词 X + X_+ X+的必要性。因此,我们设计了如下损失函数。
L 1 = B C E ( f ( X ) , Y ) L 2 = B C E ( θ f ( X + ) , Y ) L 3 = ∥ f ( X − ) ∥ 2 L = L 1 + L 2 + L 3 L_1=BCE(f(X), Y) \\ L_2=BCE(\theta f(X_+), Y) \\ L_3=\Vert f(X_-)\Vert_2 \\ L = L_1+L_2+L_3 L1=BCE(f(X),Y)L2=BCE(θf(X+),Y)L3=∥f(X−)∥2L=L1+L2+L3
其中, B C E ( ⋅ ) BCE(\cdot) BCE(⋅)是二元交叉熵, f ( ⋅ ) f(\cdot) f(⋅)是分类方法。 L 1 L_1 L1是传统的多标签分类的算是函数,目标是确保 f ( ⋅ ) f(\cdot) f(⋅)对TTPs分类有效。 L 2 L_2 L2对 f ( X + ) f(X_+) f(X+)先进行 θ \theta θ加权后进行二元交叉熵计算,当且仅当 θ \theta θ够高且 f ( X + ) f(X_+) f(X+)接近于 Y Y Y时,可以获得相对较低的损失。 L 3 L_3 L3保证噪声 X − X_- X−的预测结果 f ( X − ) f(X_-) f(X−)接近于空或全零。最终损失是三者之和
CTI-TTPs解释
| Model | RawPOS | encodes | credit | card | data | it | collected | from | the | victim | with | XOR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LIME | 0.12 | 0.11 | 0.39 | 0.06 | 0.35 | 0.22 | 0.18 | 0.0 | 0.60 | 0.22 | 0.28 | 0.20 |
| SHAP | 0.16 | 0.57 | 0.59 | 0.18 | 0.53 | 0.31 | 0.15 | 0.09 | 0.12 | 0.07 | 0.16 | 0.53 |
| SeqMask | 0.90 | 0.91 | 0.92 | 0.38 | 0.40 | 0.03 | 0.83 | 0.22 | 0.03 | 0.63 | 0.05 | 0.50 |
| SATG | 0.39 | 0.90 | 0.76 | 0.89 | 0.68 | 0.0 | 0.85 | 0.0 | 0.0 | 0.59 | 0.0 | 0.86 |
上述文本选自CTI,其TTPs为:T1560: Archive Collected Data (收集数据)和T1132: Data Encoding(数据加密)。可以发现SATG几乎抽取了所有的关键信息,而对噪声的关注度均接近于0
事实上,我们也对比了ChatGPT和我们的模型对真实的CTI片段的抽取结果:
- 输入文本:
The encoded VBScript uses a file extension which is not associated, by default, as being a VBScript file.
The extensions.domx and.lgx have been observed.
The shellcode is responsible for adding a new file association for the file extension which specifies that they should be interpreted as an encoded VBScript.
Finally, the shellcode executes the encoded VBScript file which will extract the encrypted files from the binary blob, show the decoy document (if there is one), and execute the malware.
- ChatGPT回复:
{
"Question": "The following paragraph contains which ATT&CK V8 techniques and tactics (!importantly, I mean version 8)? Please give me their IDs and your explanations.",
"TTPs": [
"T1059.001 (Command-Line Interface)",
"T1059.005 (Visual Basic Scripting)",
"T1036 (Masquerading)"
],
"Reasons": [
"The first sub-technique, T1059.001, involves the use of command-line interfaces to execute commands and scripts.",
"In this case, the shellcode is executing the encoded VBScript file using the command-line interface.",
"The second sub-technique, T1059.005, involves the use of Visual Basic Scripting to execute scripts.",
"In this case, the encoded VBScript file is being used to extract the encrypted files from the binary blob, show the decoy document, and execute the malware.",
"Additionally, the use of a new file association for the file extension (.domx and.lgx) is a technique under the tactic ”Defense Evasion” known as ”Masquerading” or ”File Masquerading” in the MITRE ATT&CK framework version 8.",
"This technique is used to evade detection by disguising the file as a different file type."
]
}
- SATG输出
{
"TTPs": [
{
"name": "T1027 (Obfuscated Files or Information)",
"score": 0.9578
},
{
"name": "T1036 (Masquerading)",
"score": 0.8536
},
{
"name": "T1059 (Command and Scripting Interpreter)",
"score": 0.3116
}
],
"Top-5 Words (S+(X)>0.9)": [
["VBScript (0.9687)", "encoded (0.9660)", "file (0.9619)", "associated (0.9592)", "extension (0.9590)"],
["lgx (0.9411)", "domx (0.9263)", "observed (0.9250)", "extension (0.9015)"],
["shellcode (0.9707)", "VBScript (0.9693)", "encoded (0.9668)", "responsible (0.9664)", "file (0.9628)"],
["shellcode (0.9591)", "binary (0.9569)", "VBScript (0.9559)", "malware(0.9522)", "encrypted (0.9512)"]
]
}
结果显示,我们的方法和 ChatGPT 都从源文本中提取出了 T1036(伪装)技术。两种方法的主要分歧集中在描述主要指的是 "执行 "还是 “防御规避”。ChatGPT 认为,由于全文频繁使用 "脚本 "一词,它与 "执行 "的关系更为密切。虽然我们的方法也选取了 "shellcode "和 “VBScript”,并给 T1059 打出了 0.3116 的分数,但我们还是选择了强调 "lgx "和 “domx”,以突出信息混淆的特点。从人的角度来看,这段描述中语句的含义接近于执行,但段落的整体描述更接近于混淆。同时,我们发现在 ChatGPT 的回复中,T1059.001 技术对应的名称是 “命令行界面”,这与 ATT&CK 在其网站上给出的名称 "PowerShell "不符。因此,我们相信我们提出的方法可以对 CTI 进行令人信服的 TTP 分析。
模型准确性提升
由于分类器 f ( ⋅ ) f(\cdot) f(⋅)是不固定的,所以我们实验了多种不同的搭配。从下表结果看,我们的方法对绝大多数基本人工智能方法由准确率提升的效果,尤其是对简单的模型效果提升更加。说明对抗性的关键词抽取有助于TTPs的精细化分类。
| f ( ⋅ ) f(\cdot) f(⋅) | 战术Macro-F1 | 战术Micro-F1 | 技术Macro-F1 | 技术 Micro-F1 |
|---|---|---|---|---|
| CNN | +0.0539 | +0.0256 | +0.0671 | +0.0339 |
| TCN | +0.0413 | +0.0117 | +0.0685 | +0.0617 |
| Attention | +0.0282 | +0.0098 | +0.0343 | +0.0344 |
| Attention-CNN | -0.0037 | +0.0016 | +0.0491 | +0.0218 |
| RNN | +0.0261 | +0.0191 | +0.0556 | +0.0663 |
| RCNN | +0.0085 | +0.0076 | +0.0026 | +0.0099 |
现有问题&挑战
- 如何构造轻量化的模型解释方法:不论是SeqMask还是SATG,方法本身的模型趋向于越来越复杂,有没有一种方法能够又提供解释,又轻量,又准确?可能可以从CRP+RelMax入手?
- 如何构造全局解释方法:不论是SeqMask(评分层可解释,但其他层不透明)还是SATG(TTPs关键词筛选透明,但是 f ( ⋅ ) f(\cdot) f(⋅)不透明),都只能提供基于案例的解释,有没有可能构造模型整体决策过程都是透明的解释方法?可能可以从ICCNN上入手?
- 如何构造0样本解释方法:不论是SeqMask还是SATG都是全监督方法,需要先验知识支撑解释,有没有方法可以通过对比已有数据,不要人工标签辅助,还能进行TTPs分类和关键词抽取?