R-CNN(论文)
Introduction
-
SIFT/HOG都使用了局部方向直方图,因此缺乏对层次性多个阶段任务的识别能力
-
R-CNN通过多层卷积网络,可以对图像区域进行分类,从而输出分类边界框和分割蒙版
-
R-CNN相比低级图像特征可以获得更好的分类结果,在多个种类的物体上都有好的表现
-
物体检测里的两个挑战:定位技术,数据(有效的标签数据较少)
-
定位技术(Localization):
-
operating within the “recognitin using regions” paradigm
-
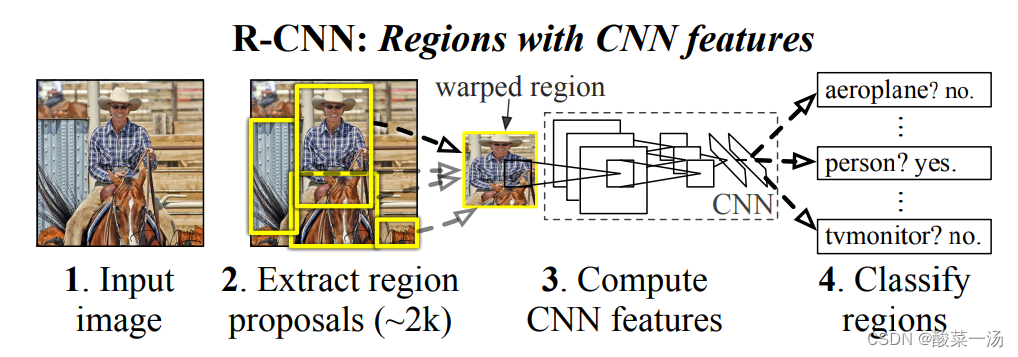
测试阶段有2000左右的独立候选区域,每个勾选区域输出定长的CNN特征(忽略每个区域的形状),每个候选区域由线性SVM进行分类
-
R-CNN结构示意
-
-
-
数据方面的挑战
-
使用非监督的预训练,结束后有监督的进行微调(Fine-Tuning,FT)
-
使用ILSVRC监督预训练,再使用小数据集微调
-
fine-tuning可以使结果上升8个百分点
-
Object detection with R-CNN
-
构成模块:
-
生成候选区
-
提取定长特征的大型CNN网络
-
线性SVM
-
-
模块设计:
-
候选区:
-
selective search
-
-
特征提取
-
4096维
-
input 227*227,RGB,5个卷积层2个全连接层
-
-
-
Test-time detection
-
NMS去除重复区域(Intersection-over-union, IoU)
-
-
Training
-
Supervised pre-training
-
ILSVRC 2012数据集
-
不使用bounding box和标签
-
分类效果接近AlexNet
-
-
Domain-specific fine-tuning
-
候选区
-
SGD训练CNN参数,学习率0.001(初始化的1/10)
-
ImageNet最后的分类层换为随机初始化的21(20+1)的分类层
-
每个候选区>=0.5的IoU是正样例
-
均匀采样32个正样例和96个background构建128的mini-batch
-
-
Object category classiers
-
IoU 0.3去除一些只包含一部分样例的图片(车的一部分,算车还是negative)
-
Hard Negative Minning
-
-
Fast R-CNN(论文地址)
Intorduction
-
Object detectin的挑战:
-
大量的候选区
-
获得位置是大致的,需要进一步优化
-
R-CNN
-
多个步骤
-
在候选区调整ConvNet
-
SVM
-
生成bounding-box
-
-
训练成本大
-
慢
-
-
SPPNet
-
R-CNN基础上共享计算,feature map
-
-
Advantage
-
high quality
-
single-stage training,using multi-task loss
-
training can update all network layers
-
No disk storage is required for feature caching
-
Architecture and training
-
Architecture
-
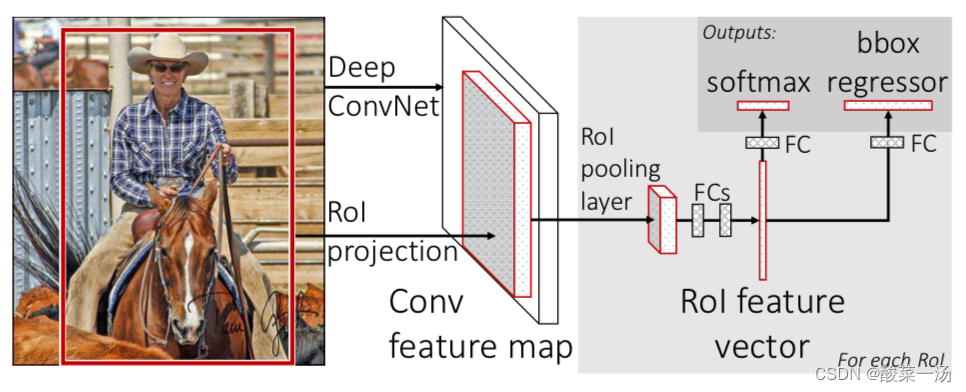
输入:完整图像+候选区域集合
-
首先:处理整张图像获得卷积feature map
-
然后:RoI pooling(从每一个候选区提取定长的feature map)
-
输出层:
-
背景
-
four real-valued numbers for each of the K object classes
-
each set of 4 values encodes refined bounding-box positions for one of the K classes
-
-
-
优化的bounding-box
-
-
Initializing from pre-trained networks
-
Fine-tuning for detection
-
feature sharing during training
-
SGD mini-batch,按层次进行
-
先采样N个图像
-
然后每张图采样R/N个RoIs
-
来自同一张图像的RoIs在前后向传播中共享计算(?)和缓存
-
-
-
-
Multi-task loss
-
有两个输出层
-
一个输出离散的概率分布(softmax)
-
bounding-box regression offset
-
-