C#深度神经网络
文章目录
前言
现在AI这么流行想必大家都听说过,卷积神经网络(CNN)、深度神经网络(DNN),大多数实现都是采用的python,不得不说python是真的火。TensorFlow.NET是由SciSharp STACK开源社区团队的贡献,它为TensorFlow提供了.NET Standard , 以C#实现完整的Tensorflow API,允许.NET开发人员使用跨平台的.NET Standard框架开发、训练和部署机器学习模型。SciSharp STACK 目前包含几个流行项目: BotSharp(AI机器人平台框架),NumSharp(数值计算库),TensorFlow.NET (深度学习库),Pandas.NET (数据处理库),SharpCV(图形图像处理库),可以完全脱离Python环境使用,目前已经被微软ML.NET官方的底层算法集成,并被谷歌写入TensorFlow官网教程推荐给全球开发者。本文主要讲TensorFlow.NET的使用,废话不多说咱们开始吧。
以下是本篇文章正文内容,下面案例可供参考
专业术语讲解
模型[Model]
模型是指使用大规模数据和强大的计算能力训练出来的“大参数”模型,这些模型通常具有高度的通用性和泛化能力也可以简单理解为就是数学表达式,或者多个数学表达式的组合,可以应用于自然语言处理、图像识别、语音识别等领域。大模型可以分为大语言模型、视觉大模型、多模态大模型和基础大模型。
举个例子:
a=Xc+b,这个二元一次方程就是一个模型,c是我们的数据(已知),a是我们的预期结果(已知),而我们用大量的数据去训练模型,这个训练过程其实就是在用已知的c,a去求X和b这两个参数(c是我们的数据本身,a是c数据的标签)。
向量[Vector]
是一种特殊的矩阵,它只有一维,通常表示为一列或一行数字。向量通常用来表示神经网络的输入数据、输出数据。其实就可以理解为C#中的List<>和Arry[];
List<int> Data=new List<int>();
Data.add(0);
Data.add(1);
矩阵[Matrix]
矩阵是二维的数学结构,通常用来表示线性变换和线性方程组。一个矩阵由行和列组成,矩阵通常用于表示神经网络的权重或特征映射。相当于是二位向量。其实也可以理解为就是一个二维数组
int[,] array1 = new int[3, 2] { { 1, 2 }, { 3, 4 }, { 5, 6 } };
张量[Tensor]
张量可以表示在多个向量空间及其对偶空间的笛卡尔积中的线性关系。换句话说,张量是可以用来描述多线性函数的多维数组,它可以是一个标量(0 维张量)、向量(1 维张量)、矩阵(2 维张量)或更高维度的数组。用上面代码举例,这个2就可以理解为二维张量
下面是C#中的三维数组,仔细看代码里的3就是它的张量。

int[,,] array3D = new int[2, 3, 2]
{
{
{1, 2}, {3, 4}, {5, 6}
},
{
{7, 8}, {9, 10}, {11, 12}
}
};
批量大小(Batch Size)
批量大小是每次迭代训练时用到的样本数量。较大的批量大小可以加速训练过程,但可能会导致内存消耗过大;而较小的批量大小可以减少内存消耗,但可能会增加训练时间。
迭代次数(Epochs)
迭代次数指定了模型训练时遍历整个训练数据集的次数。增加迭代次数可以使模型更充分地学习训练数据,但也可能导致过拟合。过拟合是指在机器学习过程中,模型在训练数据上表现良好,但在测试数据上表现不佳的现象。这通常是因为模型过于复杂,学习了训练数据中的噪声或细节,而这些噪声或细节在测试数据中并不存在。
交叉熵[Cross Entropy]
交叉熵[shāng](Cross Entropy) 是信息论中的一个重要概念,主要用于度量两个概率分布之间的差异性信息。在机器学习中,交叉熵常被用作损失函数,用于评估模型的预测结果与实际标签之间的差异
交叉熵的定义如下:
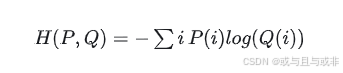
其中,P(i) 是真实数据的概率分布,Q(i) 是模型预测的概率分布,i 表示样本的索引或类别。交叉熵的值越小,表示两个概率分布越接近,模型的预测结果越准确。
在分类问题中,常用的交叉熵损失函数是针对目标类别是一个类别分布的情况,通常用于多分类问题。对于每一个样本,真实标签是一个以 one-hot 编码表示的向量,其中只有一个元素为 1,其余元素为 0。模型的输出通常是一个概率分布,表示每个类别的概率。交叉熵损失函数衡量了模型输出的概率分布与真实标签之间的差异性。
在深度学习中,交叉熵通常与 softmax 激活函数结合使用,softmax 函数将模型的输出转换为一个概率分布,然后计算交叉熵损失。通过最小化交叉熵损失,我们可以训练模型以更准确地预测数据的类别。
那么什么是损失函数呢?a=Xc+b是我们的模型,也就是目标函数,最开始的时候我们不知道X和b到底是多少,那就随便给一个值,然后把x输入进去,计算得到a’,然而a才是我们的正确值,所以我们就需要计算a与a’之间的差异,看看此时随便给的这个X和b到底是不是最优解,到底还差多少,所以训练过程也可以看做是寻求损失函数最小值的过程
训练流程
通常在人工智能领域做数据训练会经过一下几个步骤:
- 收集数据(数据领域的事,不讨论)
- 数据清洗(数据领域的事,不讨论)
- 数据特征提取(深度学习中非必要,机器学习中必要,属于特征工程,在此不讨论)
- 数据预处理(数据打标签,数据转换,标准化/归一化等等)
- 选择模型
- 模型训练&模型调参
数据预处理
在数据预处理这个阶段,有三个主要的工作:
数据打标签
因为做分类和回归,都是属于监督学习,监督学习就需要告诉机器这条数据对应的结果是什么,比如你要让机器学会认识苹果,香蕉,番茄这些食物,每类食物收集了100张图片,每一张图片就要提前打好标签(这张是苹果,这张是香蕉…苹果,香蕉这些分类就是数据标签)。
数据转换
计算机是不认识图片的,也不认识文字,计算机能够识别的只有0,1,2,3…这些数值,但是我们任何一个业务都不可能用单纯的单个阿拉伯数字表示。所以我们必须把图片,文子转换成张量。图片转张量可以用TensorFlow库里封装好的代码直接转,至于文字也可以用很多开源模型直接做Embedding。对于上面打标签的例子,假设我们的分类就是【苹果,香蕉,番茄】三个分类,那么苹果这个标签可以表示为[1,0,0],香蕉表示为[0,1,0],番茄表示为[0,0,1]。如果还是不懂,可以网上搜索一下one-hot独热编码。
标准化/归一化
归一化(Normalization):将数据缩放到 [0, 1] 的范围内。标准化(Standardization):将数据转换为均值为 0,标准差为 1 的标准正态分布。
这样做的原因一是因为归一化和标准化可以加速模型的收敛速度,特别是对于使用梯度下降等优化算法的模型而言,可以减少参数更新的时间和次数。二是因为可以降低模型对特征尺度的敏感性,如果特征具有不同的尺度,模型可能会更关注具有较大尺度的特征,而忽略具有较小尺度的特征。通过归一化和标准化,可以确保所有特征对模型的影响都是相似的。因为我们输入的x是一个张量,如果一个张量里面某个数字是10000,某个数字是0.1那么在计算时这个0.1的数字相对于10000来说,对整个模型的影响就会很小。
选择模型
模型都是现成的,不需要各位技术爱好者去从0写算法模型,那是数学家的事,我们只需要用就行,在本篇文章中我们选择使用DNN模型,直接从TensorFlow库里面拿来用就好了
模型训练&模型调参
超参数
正如上文中提到的 a=Xc+b这个模型,X和b都是属于模型的自身参数,求得X和b的最终值是训练的主要目的。但是如何更好的求得X和b,在训练过程中我们还需要人为的调整修改另一类参数,这类参数叫超参数,换句话说,超参数是在训练模型之前设置的参数,用于指定模型的结构、学习策略和优化算法等方面的配置,上面所说的:批量大小、迭代次数都是超参数;还有很多其他的超参数,这些参数都需要再模型训练过程中不断的反复调整,使得最终的X和b达到最准确的效果。
常用的超参数
- 学习率(Learning Rate):控制每次梯度更新时模型参数调整的步长。学习率过高可能导致模型难以收敛甚至发散,过低则会导致模型收敛慢或陷入局部最优
- 批大小(Batch Size):每次迭代中用于更新模型的数据样本数量。较大的批大小可以加速训练,但可能导致模型收敛到较差的局部最优解;较小的批大小可能会导致训练不稳定
- 动量(Momentum):用于加速模型训练过程中的收敛,同时有助于克服局部最优解。动量通常与学习率一起使用
- 迭代次数(Epochs):整个训练集通过模型的次数。较小的迭代次数可能导致模型欠拟合,较大的迭代次数可能导致模型过拟合
- 正则化参数(Regularization Parameters):用于防止模型过拟合,包括L1和L2正则化的系数以及dropout的概率等。L1正则化通过惩罚模型参数的绝对值减少模型复杂度,L2正则化通过惩罚参数的平方值来防止过拟合
- 优化器选择(Optimizer):常见的优化器包括SGD(随机梯度下降)、Adam、RMSprop等。不同的优化器有不同的超参数,例如SGD中的学习率和Adam中的学习率和动量参数
- 损失函数选择(Loss Function):用于量化模型预测与真实值之间的差距。不同的机器学习任务可能需要不同类型的损失函数,例如交叉熵损失函数用于分类任务,均方误差损失函数用于回归任务
- 神经网络结构(Neural Network Architecture):包括网络中的层数、每层的神经元数量等。这些参数需要根据具体任务和数据来调整
- 树的深度(Tree Depth):在决策树、随机森林等算法中,控制树的最大深度。较深的树更容易过拟合训练数据,较浅的树可能欠拟合
- 叶子节点最小样本数(Min Samples Split / Min Samples Leaf):决策树或基于树的模型在创建分支或叶子节点时的最小样本数。限制树的分支深度,减少过拟合
- K值(K in K-Nearest Neighbors):在K近邻算法中,选择的最近邻点的数量。较大的K值会增加模型的平滑性,减小噪声,但可能会欠拟合;较小的K值更灵活,但容易过拟合
- 核函数类型和参数(Kernel Function and Parameters):在支持向量机(SVM)中,核函数决定将输入数据映射到高维空间的方式。常见核函数包括线性核、多项式核、径向基核(RBF)等。参数如C值和Gamma值影响模型的分类边界
选择合适的超参数可以通过实验和调整来实现最佳性能。常见的超参数调优方法包括网格搜索、随机搜索和贝叶斯优化等
梯度下降
梯度下降法其实就是一种寻找损失函数最小值的方法。
首先要明白什么是梯度,从数学上讲,梯度(Gradient)是指一个多元函数在某一点上的导数或偏导数。梯度表明函数在某一点上变化最快的方向和速率。他是一个向量(有大小,有方向)。
假设模型f(x)=Wx+b,损失函数为g(x)(g(x)可以为任意函数,但里面肯定包含了W和b),梯度下降法是如何更新W和b的呢?
计算梯度
首先,计算损失函数 g(x) 关于模型参数 W 和 b 的偏导数,即损失函数的梯度 ∇g(W,b)。
更新参数
使用梯度 ∇g(W,b) 来更新模型参数 W 和 b。更新规则通常是按照梯度的反方向调整参数值,以使得损失函数减小。常用的更新规则如下:
W:=W−η⋅∇g(W,b)
b:=b−η⋅∇g(W,b)
其中,η 是学习率(超参数,需要预先定义好),控制更新的步长大小。
重复迭代
重复以上步骤,直到满足停止条件(如达到最大迭代次数、损失函数收敛等)。
C# 代码实现
用到的包
- SciSharp.TensorFlow.Redist
- TensorFlow.NET
以下是一个使用 TensorFlow.NET 在 C# 中创建简单线性回归模型的示例代码:


using TensorFlow;
using static TensorFlow.Binding;
public class LinearRegression {
public static void Main() {
// 创建 TensorFlow 计算图
using (var graph = tf.Graph()) {
// 设置为默认计算图
ops.ControlDependencies(graph.AsDefault());
// 随机生成一些数据用于拟合
var rng = new Random();
int n_samples = 100;
float noise = 0.1f;
var x_data = tf.constant(Enumerable.Range(0, n_samples).Select(i => (float)(i * rng.NextDouble())).ToArray());
var y_data = tf.constant(Enumerable.Range(0, n_samples).Select(i => (float)(i * 0.1 + rng.NextDouble() * noise)).ToArray());
// 设置模型的参数
var W = tf.Variable(tf.random_uniform(shape: new TensorShape(1, 1), minval: 0, maxval: 1));
var b = tf.Variable(tf.zeros(new TensorShape(1, 1)));
// 构建模型
var y = tf.add(tf.matmul(x_data, W), b);
// 定义损失函数和优化器
var loss_mse = tf.reduce_mean(tf.square(y - y_data), name: "loss");
var optimizer = tf.train.GradientDescentOptimizer(0.3f);
var train_op = optimizer.minimize(loss_mse);
// 初始化变量
var init = tf.global_variables_initializer();
// 开始训练模型
using (var session = new TFSession(graph)) {
session.run(init);
for (int i = 0; i < 1000; i++) {
session.run(train_op);
if (i % 100 == 0) {
var loss_value = session.run(loss_mse);
Console.WriteLine($"Step {i}, Loss: {loss_value}");
}
}
// 输出模型参数
Console.WriteLine($"W: {session.run(W)}, b: {session.run(b)}");
}
}
}
}
总结
总的来说.net 在人工智布局方面并不怎么好,如果真的想要学习人工智能还是建议用python和C++。
本文参考文章:
一归AI
哆啦AI-Dorai
AI学习记录