SSD: Single Shot MultiBox Detector(单步多框检测器)论文综述
SSD算法是在YOLO的基础上改进的单阶段方法,通过融合多个feature map上的BB,在提高速度的同时提高了检测的精度,性能超过了YOLO和Faster-rcnn(大目标条件)。
单步算法,无需proposal,类似一个优化了的rpn网络。
从每个fm(feature map)上的每个像素点都输出一组不同大小、不同高宽比的默认BB(bounding box)。测试阶段,每个默认BB都输出每个类别物体是否出现的得分,同时调整BB的大小位置以更好的包裹物体。而且此网络混合不同分辨率的fm的预测以更好的检测不同大小的物体。
效果:
300300输入:59fps, 74%mAP(VOC)/
512512输入:76.9%mAP。
1、概要
目前主流检测网络套路:预设BB,然后对BB重采样(resample)修正,并且应用一个分类器分类,如faster r-cnn。这种套路一般能保证准确率,但最大的问题:慢!faster r-cnn才7fps。
本文所提网络SSD没有重采样,当可以做到和有重采样的网络一样准,并且速度快。快的原因就是没有提poposal这一步,也没有后续的重采样像素或特征这一步。
本文主要贡献:
1) 提出SSD,比yolo快,准,和faster r-cnn差不多准。
2) SSD的核心是在一系列默认BB上、用小的滤波器预测分类得分和框的偏移
3) 为了提高预测准确度,对不同尺度的特征图上的不同尺度的bb(anchor box)都做预测, 并且根据高宽比来区分。
4) 能够端到端训练,即使在低分辨率的输入也能有高准确率,达到速度与准确率的权衡。
5) 在速度和准确度上都做了实验,并与其他模型对比。
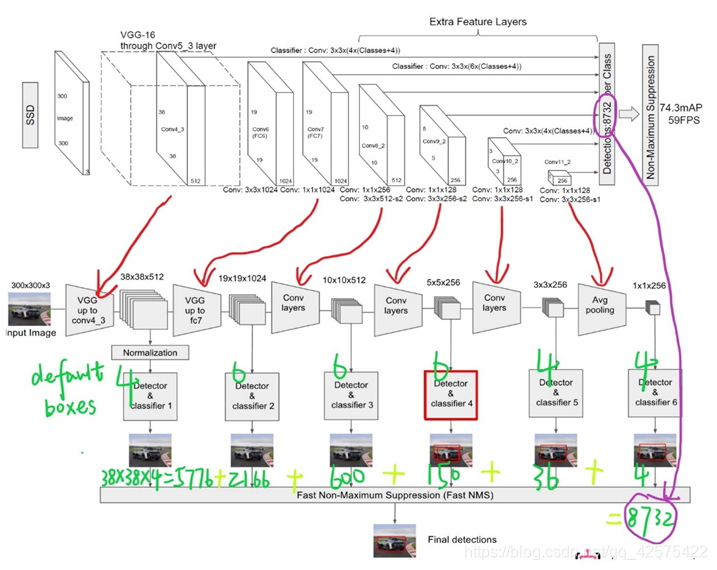
2 SSD
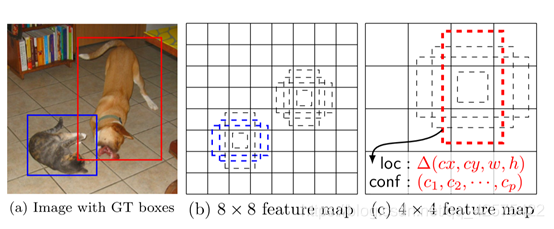
1)只有一张输入图片如(a)图。
2)每个输入在不同层产生不同大小的fm, 如(b)(c)。
3)每个fm中的每个像素点都有一系列默认框(default box类似anchor box),每个默认框上都做框修正和所有分类得分的预测。
4)训练阶段,首先把默认框映射到标签框。如把fm中猫狗所对应的框映射到输入图片上的框,模型损失是定位损失和分类损失取权重相加。
2.1 模型
主干网络是经过修剪的VGG16,用于产生不同尺度的fm,在主干网络上加入了一些辅助结构来产生预测,辅助结构有如下特征:
1) 在多尺度的fm上做预测。在修剪过的主干网络后加入卷积层,
2) 卷积预测。每一张fm用一组卷积核器做预测,如一张mnp的fm(p是通道数),可以用33p的卷积核预测分类得分或者是对默认框(相对于fm上的默认框)修正,对比yolo这一步是在中间用全卷积而非全连接。
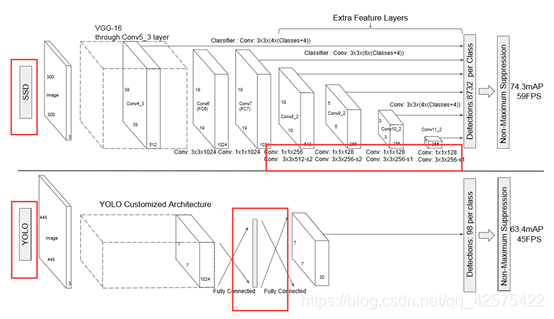
3) 默认框与高宽比。每个fm中的每个像素点有默认的k给框,每个框计算共计c中类别的得分,及4个框修正值。这样每个位置共计有(c+4)k个滤波器??,每张fm共产生(c+4)kmn个输出值。这与faster r-cnn中anchor boxes很类似,只不过是应用于多尺度的fm上。
2.2 训练
SSD与带proposal的模型训练的最大不同点在于,ssd需要把标签框映射到每一层的fm上去。一旦这种映射完成,就可以做端到端的应用损失函数和反响传播了。
匹配策略:
训练期间我们要确定哪个默认框对应到哪个标签框,然后相应的训练网络。
1) 每一个标签框都为之选择在位置、高宽比、尺度不同的一组默认框。先把标签框对应到与之jaccard overlap(在multiBox中所提到,推测即iou)最大的那个默认框上去。
2) 然后把剩余没有配对的默认框与任意一个标签狂尝试配对,只要两者之间的iou大于阈值(0.5)即可。
3) 配对到标签框的默认框认为是positive,没有配对的就是negative.
训练目标函数:
定位损失和分类损失的加权和。N为标签框所匹配的默认框数,如果N为0,取loss为0。
是一个表示第i个默认框和第j个标签框(类别号为p)的标识。
分类损失:
在验证集上取1。
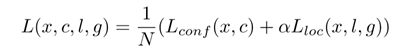
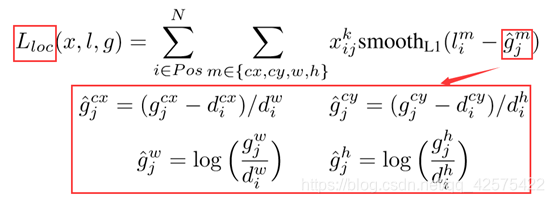
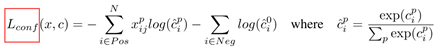
为默认框设置大小和高宽比:
用了m个fm做预测(不同层),最底层的fm的scale值Smin=0.2, 最高层Smax=0.9,其他第k层计算公式:
根据不同的高宽比1、2、3、1/2、1/3 (表示为ar)确定每层默认框的宽w和高度h:
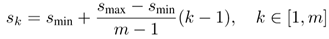
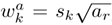
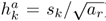
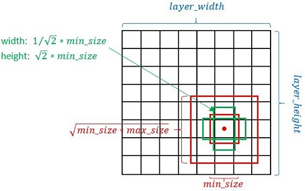
疑问:狗匹配到了44的fm中的box, 但是在88的fm中却没匹配不到任何框。能匹配到为什么默认框尺度不一样就匹配不到狗的框??
Hard negative mining:
训练时大部分默认框都是负样本,会给模型性能带来巨大影响,针对此问题,并不对所有的负样本都训练,而是根据最高分类得分进行排序,选最高的一批,这样使得正负样本比例得分为3:1。
数据增强:原图,随机分割等多种
3 实验结果
主干网络:VGG16,经过在ILSVC上预训练,把fc6和fc7转换成卷积层,从fc6和fc7下采样,把pool5从22 s2装换成33 s1,用atrous算法来填充holes.除去dropout layers 及fc7层,SGD:lr:0.001, 0.9momentum, 0.0005weight decay, bt:32.
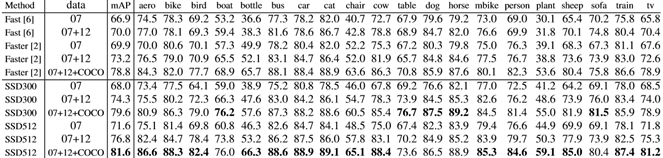
结果表明:
对小物体识别效果很差,因为高层基本没有小物体的信息。
对动物类别容易弄混,可能是由于多雷被共享位置。
模型分析(消融实验):
1) 数据增强很有用(1、5列)。
疑问:为什么分类时有feature pooling步骤(对目标平移有鲁棒性)使得数据增强对Faster r-cnn系列获益更少??
2) 高宽比为1/2 2和1/3 3有对检测有一定提高(对比2、3、5列)。因为这两种box可以在一定程度上正大较大和较小的BB,可以更加准确的检测较大和较小的目标,且VOC
上的目标一般比较大。
3) Atrous算法可以轻微提高算法性能但其主要作用时用来提速,论文中表明可提速20%。主要原因是该算法可以获得更大fm和接收场,但是SSD本身利用了多个fm来获取BB,BB的多样性已经够多了,故由于fm的扩大二多得到的BB可能时重复的,并没有起到提升检测性能的作用。
4) 不同分辨率的多输出层使得性能更好。在是否忽略靠边界的框时发现,若忽略,则比较粗糙的fm(即fm下采样到很小的层)会大幅影响性能。


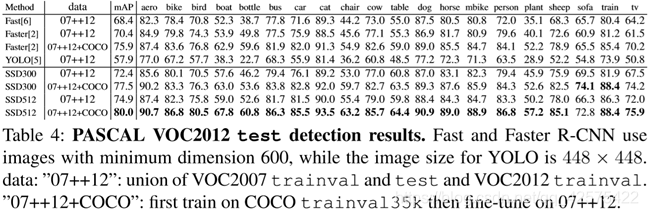
3.3 pascal voc2012
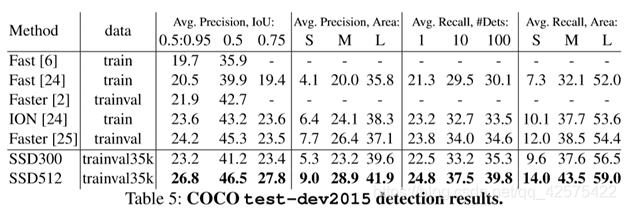
3.4 coco表现
3.7测试阶段
用了NMS, 阈值0.45, 每张图片保留前200个检测结果??
5 分析ssd快的原因
1) 单步网络,只需一个阶段就能输出结果,肯定快。而faster r-cnn是两步网络,虽然BB少很多,但是需要大量的前向推理和反向推理(训练1阶段),而且需要交替训练两个网络。
2) Yolo虽然看起来比ssd简单,但是yolo中含有大量的全连接层,而SSD讲VGG中的全连接层换成了卷积层,所有层都是卷积层。
3) 用latrous算法,提速20%。
4) Ssd中设置了输入图片大小,将不同大小的图片裁剪成300300和500500,而faster r-cnn是1000*600左右的,在输入上就少了很多计算。
6 ssd算法的优缺点
优点:速度快过yolo,精度超过faster r-cnn(一定条件下,对于稀疏场景的大目标而言)。
缺点:
1) 需要人工设置默认框的大小(min_size, max_size和高宽比),每一层的默认框的大小和形状都不一样,导致调试过程很依赖经验。而yolo2使用了聚类找出了anchor box的形状,可直接套用在ssd上。
2) 对小物体识别较差,faster r-cnn在小物体上效果更优。