初始Redis
Redis自此开始,希望善始善终
文章目录
一、计算机基础常识
1、磁盘与内存
数据最早是保存在文件中的,如何进行文件数据查询?在 Linux 操作系统中,可以通过 grep、awk 等命令进行查看;也可以通过 Java 语言写一个程序,实现基于 I/O 流的读取查找
在此存在一个基本的 I/O 常识:
数据是存放在磁盘,对于磁盘查询数据的 I/O 速度有两个指标
- 寻址:ms(毫秒级)
- 带宽:G(单位时间的 I/O 速度)
如果数据 load 到内存,基于内存进行数据 I/O 的啥时候,速度指标
- 寻址:ns(纳秒级)(秒–> 毫秒 --> 微秒 --> 纳秒),所以内存的寻址时间是磁盘的数十万倍
- 带宽:很高,因为内存是直接通过 I/O 总线与 CPU 打交道的
2、I/O Buffer:4K
我们知道磁盘的两个基本常识:1、扇区;2、磁道
扇区:在磁盘中保存数据的时候,整个磁盘会分为一个个小的存储单元,称之为扇区。每个扇区 512 byte大小,如果数据都以扇区为K检索单元,则一个 1TB 的数据将会分为很多个很多个扇区,由此带来一个问题——索引成本变大
所以实际在硬件中存在 4K 对齐——每次在读取数据的时候,并不是按照扇区 512 byte 读取,而是每次最少读取 4K 数据,以 4K 大小划分磁盘,因此以 4K 为存储单元维护索引的成本就变小
随着文件变大,读取文件的速度回收到硬盘的限制,速度必然变慢,这称之为 I/O 瓶颈,这是硬件级别的、目前不可逾越的问题,因此诞生了数据库
3、Data page:4K
在数据库层面存储数据的时候,数据都是按照 Data page 来存放,每个 Data page 的大小为 4K,数据库会为每一个Data Page做一个编号
进行数据查询的时候,每次最少读取一个 Data Page ,大小刚好对应于磁盘的缓冲页大小,所以数据库每次读取数据刚好对应一次磁盘 I//O ,不会产生 I/O 浪费
但是如果只是在数据库里面建表,那么每次读取数据的时候,要一个个遍历每个 Data page 小格子,走的仍然是全量的磁盘 I/O ,和上面磁盘查询数据相同,效率很低
为了使查询某个指定的 Data page 中的数据的速度变快,在数据库层面可以使用索引
4、索引
索引仍然是按照 Data page 来组织,大小也是 4K,使用索引在根据某一个字段查询数据的时候,不需要全量 I/O 查询,可以直接定位到数据所在的 Data page,全量遍历的速度与此相比就和乌龟一样慢
所以在关系型数据库中建表的时候,必须给出 schema,每一列的数据类型就确定了,则每一列所占字节的宽度就定死了。假设一行记录共 10 个字段,这样在插入数据的时候,如果只给了其中几个字段的值,其余列我们就可以根据数据类型直接开辟相同大小空间,并赋零值占位
这样做有什么好处呢?好处就是当需要对这些空字段进行增删改的时候,不需要移动数据,直接在对应的位置上进行复写即可,省却了大量的数据移动的开销
但是索引和记录一样都是数据,也是需要存储在硬盘当中的,由于和内存相比磁盘的速度实在是太慢了,所以真正进行查询的时候,需要在内存中组织一棵 B+ 树
5、B+树
B+树的每一个叶子节点都是 4K 大小的小格子,B+树的所有的树干是在内存里的(也就是区间和偏移),此时用户的查询 SQL 语句中的 while 条件只要命中了索引,那么查询在 B+ 树中会走树干,最终查询到某一个叶子,在根据叶子中的信息找到磁盘中的缓存页,最终只需要进行一次磁盘 I/O 就可以找到所需要的记录
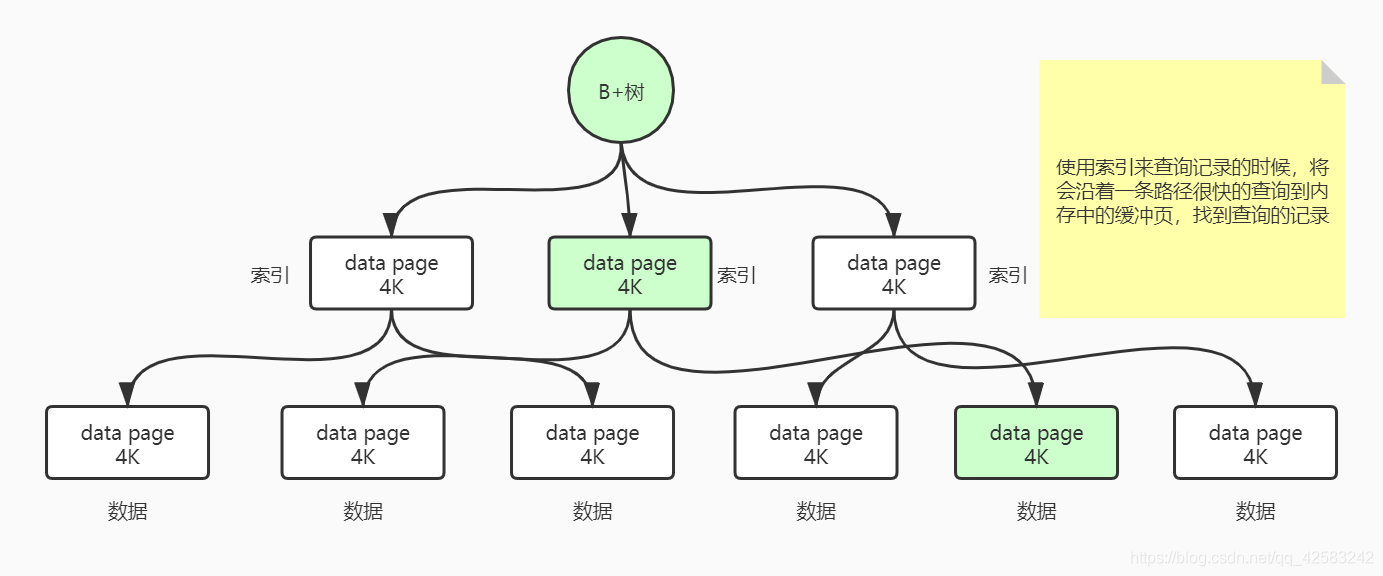
使用索引能够定向的,沿着一条路径很快的查询到数据
为什么在内存中使用 B+ 树?
索引和记录作为数据,利用磁盘存储量大和持久性的特点,都存放在磁盘中;内存速度快但是容量小,所以在内存中内存中只存放了树干,也就是区间和偏移量,使用一种数据结构 B+ 树来加快查询的速度,这样充分发挥了磁盘容量大和内存速度快的特点
这样使数据分而治之,而且查询极快,最终的目的就是减少 IO 的流量,减少寻址的过程
如果数据库中的表很大,行很多,性能就会降低?如果面试这样问,应该怎么答?