爬虫基本套路
- 基本流程
- 目标数据
- 来源地址
- 结构分析
- 具体数据在哪(网站 还是APP)
- 如何展示的数据、
- 实现构思
- 操刀编码
- 基本手段
- 破解请求限制
- 请求头设置,如:useragent为有效客户端
- 控制请求频率(根据实际情境)
- IP代理
- 签名/加密参数从html/cookie/js分析
- 破解登录授权
- 请求带上用户cookie信息
- 破解验证码
- 简单的验证码可以使用识图读验证码第三方库
- 破解请求限制
- 解析数据
- HTML Dom 解析
- 正则匹配,通过正则表达式来匹配想要爬取的数据,如:有些数据不是在 html 标签里,而是在 html 的 script 标签的 js 变量中
- 使用第三方库解析 html dom ,比较比较喜欢类 jQuery 的库
- 数据字符串
- 正则匹配(根据情景使用)
- 转JSON/XML 对象进行解析
- HTML Dom 解析
第一个爬虫程序
怎样扒网页呢?
其实就是根据 URL 来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释踩呈现出来的,实质它是一段 HTML 代码,加 js、CS ,如果把网页比作一个人,那么HTML 便是他的骨架,JS 便是他的肌肉,CSS 便是他的衣服,所以最重要的部分是存在于HTML 中的,下面写个例子:
# urllib
from urllib.request import urlopen
url = 'http://www.baidu.com/'
# 发送请求,并将结果返回给resp
resp = urlopen(url)
print(resp.read().decode())
常见的方法
- request.urlopen(url,data,timeout)
- 第一个参数url 即为URL ,第二个参数 data 是访问 URL 时要传送的数据,第三个timeout 是设置超时时间。
- 第二三个参数是可以不传送的,data 默认为空 None,timeout 默认为 socket._GLOBAL_DEFAULT_TIMEOUT
- 第一个参数URL 是必须要传送的,在这个例子里面我们传送了百度的URL,执行 urlopen方法之后,返回一个 response对象,返回信息便保存在这里面。
- response.read()
- read() 方法就是读取文件里面的全部内容,返回 bytes 类型
- response.getcode()
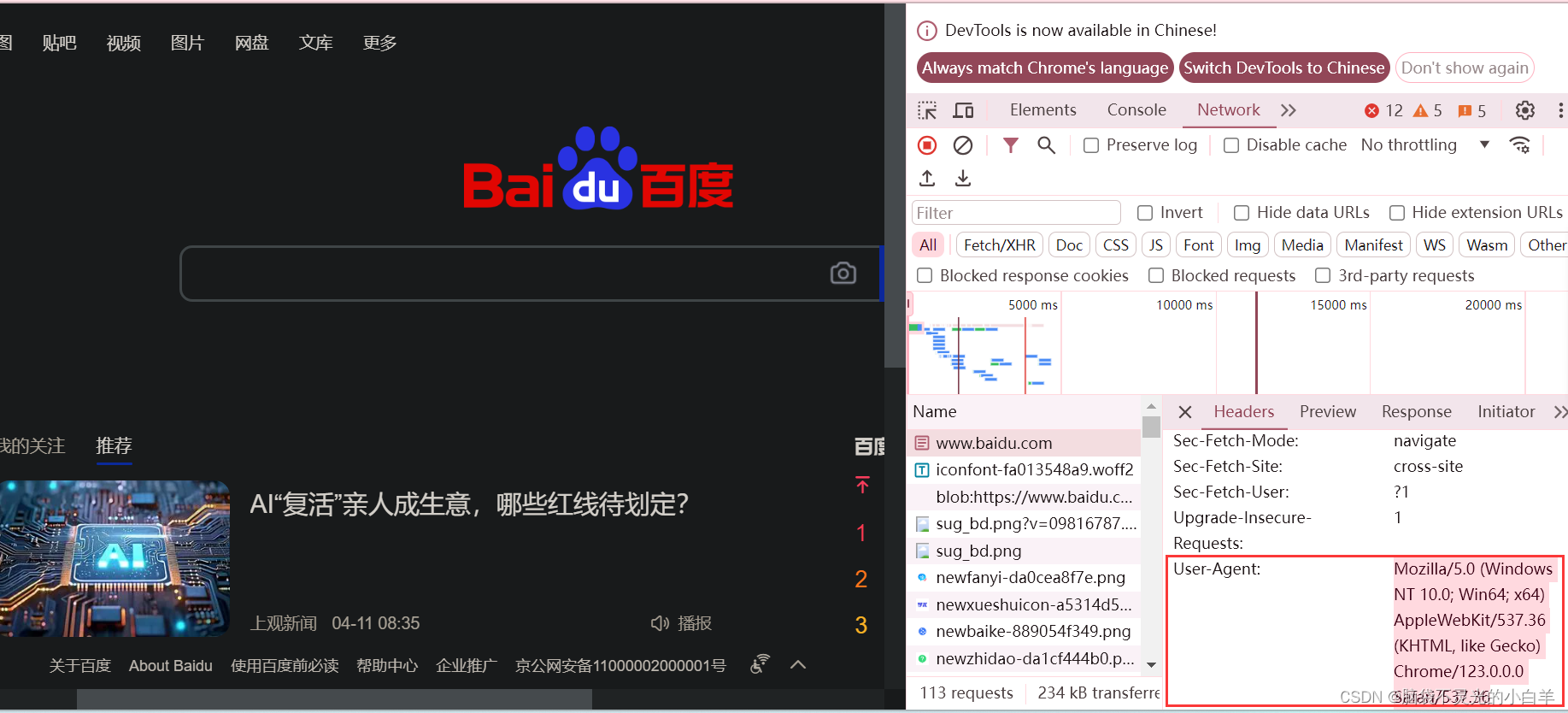
- 返回 HTTP 的响应码,成功返回 200
- response.geturl()
- 返回世界数据的实际URL ,防止重定向问题
- response.info()
- 返回服务器响应的HTTP报头
请求响应对象的使用
# urllib
from urllib.request import urlopen
url = 'http://www.baidu.com/'
# 发送请求,并将结果返回给resp
resp = urlopen(url)
# 读取数据
print(resp.read().decode())
# 为了判断是否要处理请求的结果
print(resp.getcode())
# 为了记录访问记录,避免2次访问,导致出现重复数据
print(resp.geturl())
# 响应头的信息,取到里面有用的数据
print(resp.info())
Request 对象与动态UA的使用
其实上面的 urlopen 参数可以传人一个 request 请求,它其实就是一个 Request 类的实例,构造时需要传入 Url,Data 等等的内容。比如上面的两行代码,我们可以这么改写
推荐大家这样写:
from urllib.request import urlopen
from urllib.request import Request
# 引入动态UA pip install Fake-userAgent
from fake_useragent import UserAgent
ua = UserAgent()
url = 'http://www.baidu.com'
headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'
'User-Agent': ua.chrome
}
request = Request(url, headers=headers)
response = urlopen(request)
print(response.getcode())
Get 请求的使用
大部分被传输到浏览器的 html,images,js,css,…都是通过GET方法发出请求的,它是获取数据的主要方法
Get 请求的参数都是在url 中体现的,如果有中文,需要转码,这时我们可使用
- urllib.parse.quote()
from urllib.request import urlopen,Request
from fake_useragent import UserAgent
from urllib.parse import quote
args = input('请输入要搜索的内容:')
ua = UserAgent()
url = f'https://www.baidu.com/s?wd={quote(args)}'
headers = {
'User-Agent': ua.chrome
}
req = Request(url, headers=headers)
resp = urlopen(req)
print(resp.read().decode())
- urllib.parse.urlencode()
from urllib.request import urlopen,Request
from fake_useragent import UserAgent
# from urllib.parse import quote
from urllib.parse import urlencode
args = input('请输入要搜索的内容:')
prams = {
'wd': args
}
print(urlencode(prams))
ua = UserAgent()
url = f'https://www.baidu.com/s?{urlencode(prams)}&rsv_spt=1&rsv_iqid=0xb71d5f9700144b33&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=8&rsv_sug1=2&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&prefixsug=%25E5%25A4%25A9%25E6%25B0%2594&rsp=5&inputT=1411&rsv_sug4=2294'
headers = {
'User-Agent': ua.chrome
}
req = Request(url, headers=headers)
resp = urlopen(req)
print(resp.read().decode())
58同城车辆练习
from urllib.request import Request,urlopen
from fake_useragent import UserAgent
from urllib.parse import quote
from time import sleep
args = input('请输入品牌:')
for page in range(1, 4):
url = f'https://qd.58.com/sou/pn{page}/?key={quote(args)}'
sleep(1)
print(url)
headers = {
'User-Agent': UserAgent().chrome
}
req = Request(url, headers=headers)
resp = urlopen(req)
# print(resp.read().decode())
print(resp.getcode())
Post请求的使用
Request请求对象的里面有data参数,它就是用在POST里的,我们要传送的数据就这这个参数data,data是一个字典,里面要匹配键值对。
发送请求/响应headers头的含义:

from urllib.request import Request,urlopen
from fake_useragent import UserAgent
from urllib.parse import urlencode
url = 'https://zs.kaipuyun.cn/search5/search/s'
headers = {
'User-Agent': UserAgent().chrome
}
args = {
'searchWord': '人才',
'siteCode': 'N000026543',
'column': '%E5%85%A8%E9%83%A8',
'pageSize': 10
}
f_data = urlencode(args)
# 如果传送了 data参数,就会成为POST请求
req = Request(url, headers=headers, data=f_data.encode())
resp = urlopen(req)
print(resp.read().decode())
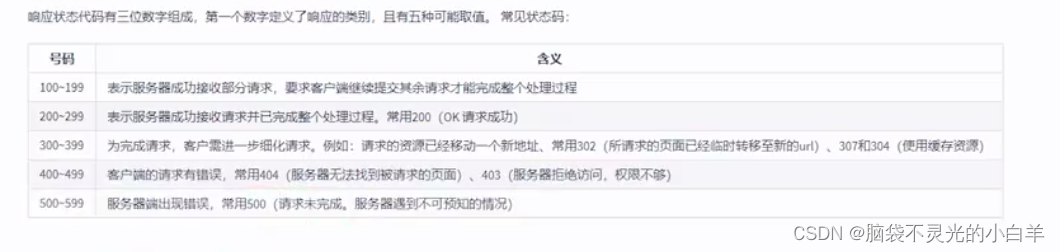
响应的编码
动态页面的数据获取
from urllib.request import Request,urlopen
from fake_useragent import UserAgent
url = 'https://m.hupu.com/api/v2/search2?keyword=%E8%94%A1%E4%BA%AE&puid=0&type=posts&topicId=0&page=2'
headers = {
'User-Agent': UserAgent().chrome
}
req = Request(url, headers=headers)
resp = urlopen(req)
print(resp.read().decode())
'''
静态
访问地址栏里的数据就可以获取到想要的数据
动态
访问地址栏里的数据获取不到想要的数据
解决方案:抓包
打开浏览器的开发者工具- network-xhr,找到可以获取到数据的url访问即可
'''
请求SSL证书验证
如果网站的SSL证书是经过CA认证的,则能够正常访问,如:https://www.baidu.com/等…
如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,比如浏览器在访问12306网站
先看没有忽略SSL证书验证的错误的
import urllib.request
import ssl
#处理HTTPS请求 SSL证书验证 ``忽略认证 比如12306 网站
url = "https://www.12306.cn/mormhweb/"
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"}
request = urllib.request.Request(url, headers=headers)
res = urllib.request.urlopen(request)
# 会报错
# ssl.CertificateError: hostname 'www.12306.cn' doesn't match either of 'webssl.
import urllib.request
# 1. 导入Python SSL处理模块
import ssl
urllib2 = urllib.request
# 2. 表示忽略未经核实的SSL证书认证
context = ssl._create_unverified_context()
url = "https://www.12306.cn/mormhweb/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib2.Request(url, headers = headers)
# 3. 在urlopen()方法里 指明添加 context 参数
response = urllib2.urlopen(request, context = context)
print(response.read().decode())
# 部分服务器会拦截网络爬虫,公司局域网也会,用手机开个热点就可以了
简洁快速的方法:
from urllib.request import urlopen
import ssl
url = "https://www.12306.cn/mormhweb/"
ssl._create_default_context = ssl._create_unverified_context
resp = urlopen(url)
print(resp.read().decode('utf-8')
opener的使用
from urllib.request import Request,build_opener
from fake_useragent import UserAgent
from urllib.request import HTTPHandler
url = 'http://httpbin.org/get'
headers = {'User-Agent': UserAgent().chrome}
req = Request(url, headers=headers)
handler = HTTPHandler(debuglevel=1)
opener = build_opener(handler)
resp = opener.open(req)
print(resp.read().decode())
代理的使用
from urllib.request import Request,build_opener
from fake_useragent import UserAgent
from urllib.request import ProxyHandler
url = 'http://httpbin.org/get'
headers = {'User-Agent': UserAgent().chrome}
req = Request(url, headers=headers)
# 创建一个可以使用的控制器
# handler = ProxyHandler({'type':'ip'})
handler = ProxyHandler({'http': '123.171.42.171:8888'})
# 传递到opener
opener = build_opener(handler)
resp = opener.open(req)
print(resp.read().decode())
Cookie的使用
为什么要使用Cookie呢?
Cookie,指某些网站为了辨别用户身份,进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密)比如说有些网站需要登录后才能访问某个页面,在登陆之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
from urllib.request import Request,build_opener
from fake_useragent import UserAgent
from urllib.parse import urlencode
from urllib.request import HTTPCookieProcessor
login_url = 'https://www.kuaidaili.com/login/'
args = {
'username': 'zs',
'passwd': '123456'
}
headers = {
'User-Agent': UserAgent().chrome
}
req = Request(login_url, headers=headers, data=urlencode(args).encode())
# 创建一个可以保存Cookie的控制对象
handler = HTTPCookieProcessor()
# 构造发送请求的对象
opener = build_opener(handler)
# 登录
resp = opener.open(req)
print(resp.read().decode())
Cookie 的文件保存与使用
from urllib.request import Request,build_opener
from fake_useragent import UserAgent
from urllib.parse import urlencode
from urllib.request import HTTPCookieProcessor
from http.cookiejar import MozillaCookieJar
# 保存Cookie
def get_cookie():
url = 'https://www.kuaidaili.com/login/'
args = {
'username': 'zs',
'passwd': '123456'
}
headers = {
'User-Agent': UserAgent().chrome
}
req = Request(url, headers=headers, data=urlencode(args).encode())
cookie_jar = MozillaCookieJar()
# 创建一个可以保存Cookie的控制对象
handler = HTTPCookieProcessor(cookie_jar)
# 构造发送请求的对象
opener = build_opener(handler)
resp = opener.open(req)
# print(resp.read().decode())
cookie_jar.save('cookie.txt', ignore_discard=True,ignore_expires=True)
# 读取Cookie
def use_cookie():
url = 'https://www.kuaidaili.com/usercenter'
headers = {
'User-Agent': UserAgent().chrome
}
req = Request(url, headers=headers)
cookie_jar = MozillaCookieJar()
cookie_jar.load('cookie.txt', ignore_discard=True,ignore_expires=True)
handler = HTTPCookieProcessor(cookie_jar)
opener = build_opener(handler)
resp = opener.open(req)
print(resp.read().decode())
if __name__=='__main__':
# get_cookie()
use_cookie()
urlerror的使用
首先解释下 URLError可能产生的原因:
- 网络无连接,即本机无法上网
- 连接不到特定的服务器
- 服务器不存在
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from urllib.error import URLError
url = 'https://www.baidu.com/srgdgf/e465/'
headers = {
'User-Agent': UserAgent().chrome
}
req = Request(url, headers=headers)
try:
resp = urlopen(req)
print(resp.read().decode())
except URLError as e:
print(e)
if e.args:
print(e.args[0].errno)
print('爬取完成')
requests的使用
pip安装
pip install requests
基本使用
req = requests.get('http://www.baidu.com')
req = requests.post('http://www.baidu.com')
req = requests.put('http://www.baidu.com')
req = requests.delete('http://www.baidu.com')
req = requests.head('http://www.baidu.com')
req = requests.option('http://www.baidu.com')
get 请求
import requests
def no_args():
url = 'http://www.baidu.com/'
resp = requests.get(url)
print(resp.text)
def use_args():
url = 'http://www.baidu.com/'
args = {
'wd': '熊猫'
}
resp = requests.get(url, params=args)
print(resp.text)
if __name__ == '__main__':
use_args()
post 请求
import requests
url = 'https://www.21wecan.com/rcwjs/searchlist.jsp'
args = {
'searchword': '人才'
}
resp = requests.post(url, data=args)
print(resp.text)
代理的使用
import requests
from fake_useragent import UserAgent
url = 'http://httpbin.org/get'
headers = {'User-Agent': UserAgent().chrome}
'''
免费代理
"type":"type://ip:port"
私有代理
"type":"type://username:password@ip:port"
'''
proxy = {
'http': 'http://110.18.152.229:9999'
}
resp = requests.get(url,headers=headers,proxies=proxy)
print(resp.text)
cookie的使用
import requests
from fake_useragent import UserAgent
from urllib.request import HTTPCookieProcessor
login_url = 'https://www.kuaidaili.com/login/'
args = {
'username': 'zs',
'passwd': '123456'
}
headers = {
'User-Agent': UserAgent().chrome
}
session = requests.Session()
resp = session.post(login_url,data=args,headers=headers)
print(resp.text)
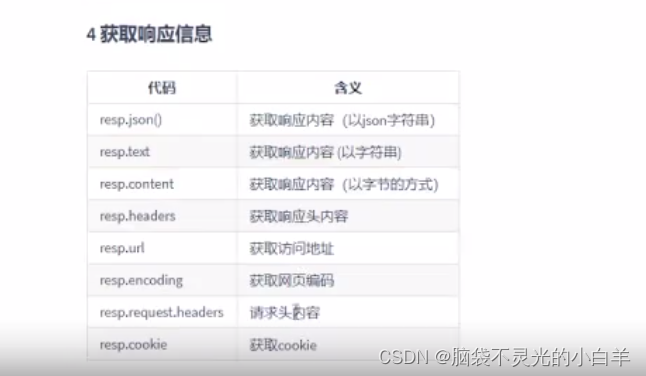
获取响应信息
re 的使用
import re
str = 'I study python every_day'
# 从头开始匹配,如果有的匹配不上就不会返回数据
print('---------match(规则,从哪个字符串匹配)--------------')
m1 = re.match(r'I', str)
m2 = re.match(r'\w', str)
m3 = re.match(r'\s', str)
m4 = re.match(r'\D', str)
m5 = re.match(r'I (study)', str)
print(m1.group(1))
re 提取腾讯新闻数据
import requests
from fake_useragent import UserAgent
import re
url = 'https://sports.qq.com/'
headers = {
'User-Agent': UserAgent().chrome
}
resp = requests.get(url, headers=headers)
# print(resp.text)
regx = f'<li><a target="_blank" href=".+?" class=".*?">(.+?)</a></li>'
datas = re.findall(regx, resp.text)
for d in datas:
print(d)
bs4 (BeautifulSoup)的使用
安装
pip install bs4
pip install lxml
使用
from bs4 import BeautifulSoup
html =
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title id="title">Title</title>
</head>
<body>
<div class="info" float="left"> 你好 </div>
<div class="info" float="right">
<span>Good Good Study</span>
<a href="www.baidu.com"></a>
<strong><!--这是个注释--></strong>
</div>
</body>
</html>
'''
soup = BeautifulSoup(html, 'lxml')
print('--------获取标签------------') # 只会获取第一个标签
print(soup.title)
print(soup.div)
print(soup.span)
print('--------获取属性------------')
print(soup.div.attrs)
print(soup.div.get('class'))
print(soup.div['float'])
print(soup.a.get('href'))
print('--------获取内容------------')
print(soup.title.string)
print(soup.title.text)
print(type(soup.title.string))
print(type(soup.title.text))
print('--------获取注释------------')
print(type(soup.strong.string))
print(soup.strong.prettify())
print('--------find_all()------------')
print(soup.find_all('div'))
print(soup.find_all(id='title'))
print(soup.find_all(class_='info'))
print(soup.find_all(attrs={'float': 'right'}))
print(soup.find_all('div', attrs={'float': 'left'}))
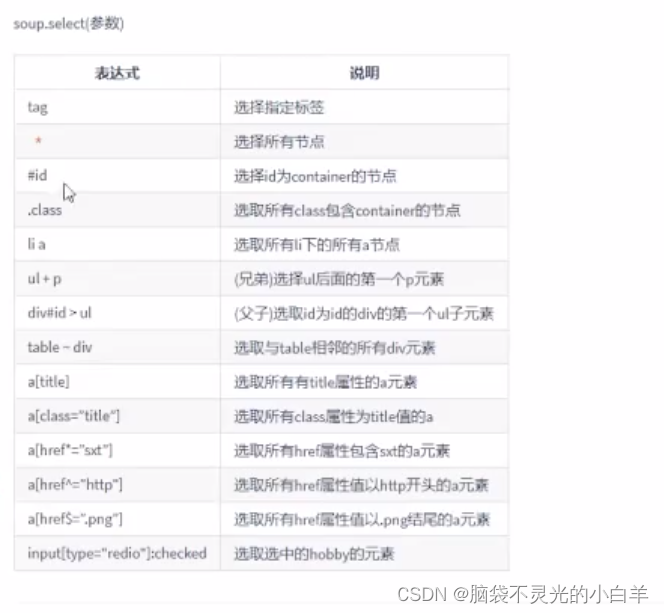
print('--------css选择器------------') # 也是获取多个内容
print(soup.select('div'))
print(soup.select('#title'))
print(soup.select('.info'))
print(soup.select('div > span'))
print(soup.select('div.info > a'))
pyquery 的使用
安装
pip install pyquery
import requests
from fake_useragent import UserAgent
from pyquery import PyQuery as pq
url = 'https://www.qidian.com/all/'
headers = {'User-Agent': UserAgent().chrome}
resp = requests.get(url, headers=headers)
# 构造Pyquery对象
doc = pq(resp.text)
all_a = doc('[data-eid="qd_B58"]')
print(all_a)
for i in range(len(all_a)):
print(all_a.eq(i).text())
print('-------------------------')
for a in all_a:
print(a.text)
xpath的使用
from fake_useragent import UserAgent
import requests
from lxml import etree
from time import sleep
for i in range(1, 6):
print(f'-------正在获取第{i}页数据----------')
url = f'https://www.zongheng.com/rank?details.html?=rt=1&d=1&p={i}'
headers = {'User-Agent': UserAgent().chrome}
resp = requests.get(url,headers=headers)
# 构造etree对象
e = etree.HTML(resp.text)
names = e.xpath('//div[@class="book--hover-box"]/p/span/text()')
for name in names:
print(name)
sleep(1)
jsonpath的使用
安装
pip install jsonpath
jsonpatn 与 xpath 语法对比:

import json
from jsonpath import jsonpath
# 示例 JSON 数据
data = '''
{
"商店":{
"书籍":[{
"分类":"惊悚",
"作者":"R.L.斯坦",
"书名":"鸡皮疙瘩",
"价格":18.95
},{
"分类":"冒险",
"作者":"J.K.罗琳",
"书名":"哈利波特与火焰杯",
"书号":"ND-2131-34421",
"价格":52.99
},{
"分类":"科幻",
"作者":"刘慈欣",
"书名":"三体",
"价格":65.35
},{
"分类":"科幻",
"作者":"刘慈欣",
"书名":"流浪地球",
"价格":32.99
}]
}
}
'''
# 解析 JSON 数据
json_data = json.loads(data)
# 进行 JSONPath 查询
titles = jsonpath(json_data, "$.商店.书籍[*].书名")
# 打印匹配结果
for title in titles:
print(title)
爬虫多线程的使用:
from queue import Queue
from threading import Thread
from fake_useragent import UserAgent
import requests
from time import sleep
class MyThread(Thread):
def __int__(self):
Thread.__init__(self)
def run(self):
while not url_queue.empty():
url = url_queue.get()
headers = {'User-Agent': UserAgent().chrome}
print(url)
resp = requests.get(url, headers=headers)
# print(resp.json())
for d in resp.json().get('data'):
print(f'tid:{d.get("tid")} topic:{d.get("topicName")}content:{d.get("content")}')
sleep(3)
if resp.status_code == 200:
print(f'成功获取第{i}页数据')
if __name__ == '__main__':
url_queue = Queue()
for i in range(1, 11):
url = f'https://www.hupu.com/home/v1/news?pageNo={i}&pageSize=50'
url_queue.put(url)
for i in range(2):
t1 = MyThread()
t1.start()
爬虫多进程的使用:
from multiprocessing import Manager
from multiprocessing import Process
from fake_useragent import UserAgent
import requests
from time import sleep
def spider(url_queue):
while not url_queue.empty():
try:
url = url_queue.get(timeout=1)
headers = {'User-Agent': UserAgent().chrome}
print(url)
resp = requests.get(url, headers=headers)
# print(resp.json())
# for d in resp.json().get('data'):
# print(f'tid:{d.get("tid")} topic:{d.get("topicName")}content:{d.get("content")}')
sleep(3)
# if resp.status_code == 200:
# print(f'成功获取第{i}页数据')
except Exception as e:
print(e)
if __name__ == '__main__':
url_queue = Manager().Queue()
for i in range(1, 11):
url = f'https://www.hupu.com/home/v1/news?pageNo={i}&pageSize=50'
url_queue.put(url)
all_process = []
for i in range(2):
p1 = Process(target=spider,args=(url_queue,))
p1.start()
all_process.append(p1)
[p.join() for p in all_process]
多进程池的使用
from multiprocessing import Pool,Manager
from time import sleep
def spider(url_queue):
while not url_queue.empty():
try:
url = url_queue.get(timeout=1)
print(url)
sleep(3)
except Exception as e:
print(e)
if __name__ == '__main__':
url_queue = Manager().Queue()
for i in range(1, 11):
url = f'https://www.hupu.com/home/v1/news?pageNo={i}&pageSize=50'
url_queue.put(url)
pool = Pool(3)
pool.apply_async(func=spider,args=(url_queue,))
pool.apply_async(func=spider,args=(url_queue,))
pool.apply_async(func=spider,args=(url_queue,))
pool.close()
pool.join()
爬虫协程的使用
安装
pip install aiohttp
import aiohttp
import asyncio
async def first():
async with aiohttp.ClientSession() as session: # aiohttp.ClientSession() == import requests 模块
async with session.get('http://httpbin.org/get') as resp:
rs = await resp.text()
print(rs)
# header
headers = {'User-Agent':'aaaaaaa123'}
async def test_header():
async with aiohttp.ClientSession(headers=headers) as session: # aiohttp.ClientSession() == import requests 模块
async with session.get('http://httpbin.org/get') as resp:
rs = await resp.text()
print(rs)
# 参数传递
async def test_params():
async with aiohttp.ClientSession(
headers=headers) as session: # aiohttp.ClientSession() == import requests 模块
async with session.get('http://httpbin.org/get',params={'name':123}) as resp:
rs = await resp.text()
print(rs)
# cookie
async def test_cookie():
async with aiohttp.ClientSession(
headers=headers,cookies={'token':'123id'}) as session: # aiohttp.ClientSession() == import requests 模块
async with session.get('http://httpbin.org/get',params={'name':123}) as resp:
rs = await resp.text()
print(rs)
# 代理
async def test_proxy():
async with aiohttp.ClientSession(
headers=headers,cookies={'token':'123id'}) as session: # aiohttp.ClientSession() == import requests 模块
async with session.get('http://httpbin.org/get',params={'name':123},proxy = 'http://name:pwd@ip:port') as resp:
rs = await resp.text()
print(rs)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(test_cookie())