点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达数据集
我们将使用狗与猫数据集(有免费许可证),你可以在以下链接中找到:https://www.kaggle.com/datasets/biaiscience/dogs-vs-cats。
这些数据集可以免费使用。我将向你展示如何创建一个模型来解决这个二分类任务,以及使用它对新图像进行推理。
下载此数据集的第一件事是使用凭据访问Kaggle,然后下载Kaggle。你可以通过单击“创建新API token”按钮获得的json文件。
首先,我们需要编写代码,允许我们上传个人Kaggle token,并下载数据集。
%%capture
!pip install kaggle
#upload your tokn
from google.colab import files
import time
uploaded = files.upload()
time.sleep(3)
#download directly from kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle competitions download "dogs-vs-cats"现在我们需要将下载的文件夹解压到一个新文件夹中,我们将为该文件夹命名data。接下来,我们还将分别解压test和train这两个子文件夹。
import zipfile
#root directory
data_zip = "/content/dogs-vs-cats.zip"
data_dir = "./data"
data_zip_ref = zipfile.ZipFile(data_zip,"r")
data_zip_ref.extractall(data_dir)
#test
test_zip = "/content/data/test1.zip"
test_dir = "./data"
test_zip_ref = zipfile.ZipFile(test_zip,"r")
test_zip_ref.extractall(test_dir)
#train
train_zip = "/content/data/train.zip"
train_dir = "./data"
train_zip_ref = zipfile.ZipFile(train_zip,"r")
train_zip_ref.extractall(train_dir)构造并填充子文件夹
为了方便数据集的管理,我们创建了一个易于管理的文件夹结构。
目标是有一个名为training的文件夹,其中包含子文件夹dog和cat,其中显然包含各自宠物的所有图像。
对验证文件夹也应该做同样的事情。
import os
import glob
dat_dir = "/content/data"
#create training dir
training_dir = os.path.join(data_dir,"training")
if not os.path.isdir(training_dir):
os.mkdir(training_dir)
#create dog in training
dog_training_dir = os.path.join(training_dir,"dog")
if not os.path.isdir(dog_training_dir):
os.mkdir(dog_training_dir)
#create cat in training
cat_training_dir = os.path.join(training_dir,"cat")
if not os.path.isdir(cat_training_dir):
os.mkdir(cat_training_dir)
#create validation dir
validation_dir = os.path.join(data_dir,"validation")
if not os.path.isdir(validation_dir):
os.mkdir(validation_dir)
#create dog in validation
dog_validation_dir = os.path.join(validation_dir,"dog")
if not os.path.isdir(dog_validation_dir):
os.mkdir(dog_validation_dir)
#create cat in validation
cat_validation_dir = os.path.join(validation_dir,"cat")
if not os.path.isdir(cat_validation_dir):
os.mkdir(cat_validation_dir)现在,我们只需要打乱数据并填充这些新创建的子文件夹。
import shutil
split_size = 0.80
cat_imgs_size = len(glob.glob("/content/data/train/cat*"))
dog_imgs_size = len(glob.glob("/content/data/train/dog*"))
for i,img in enumerate(glob.glob("/content/data/train/cat*")):
if i < (cat_imgs_size * split_size):
shutil.move(img,cat_training_dir)
else:
shutil.move(img,cat_validation_dir)
for i,img in enumerate(glob.glob("/content/data/train/dog*")):
if i < (dog_imgs_size * split_size):
shutil.move(img,dog_training_dir)
else:
shutil.move(img,dog_validation_dir)让我们绘制一些图像示例。
import matplotlib.pyplot as plt
import numpy as np
import cv2
from IPython.core.pylabtools import figsize
samples_dog = [os.path.join(dog_training_dir,np.random.choice(os.listdir(dog_training_dir),1)[0]) for _ in range(8)]
samples_cat = [os.path.join(cat_training_dir,np.random.choice(os.listdir(cat_training_dir),1)[0]) for _ in range(8)]
nrows = 4
ncols = 4
fig, ax = plt.subplots(nrows,ncols,figsize = (10,10))
ax = ax.flatten()
for i in range(nrows*ncols):
if i < 8:
pic = plt.imread(samples_dog[i%8])
ax[i].imshow(pic)
ax[i].set_axis_off()
else:
pic = plt.imread(samples_cat[i%8])
ax[i].imshow(pic)
ax[i].set_axis_off()
plt.show()
创建数据加载器
现在我们要做三件事:
让我们使用compose方法预处理数据,这是一种简单的方法,可以将多个预处理函数(如归一化和数据增强)应用于数据集。
让我们使用ImageFolder创建pytorch数据集。如果子目录结构定义良好(如我们的例子),PyTorch会自动推断类。
使用DataLoader批量分割数据。
import torch
import torchvision
from torchvision import datasets, transforms
traindir = "/content/data/training"
testdir = "/content/data/validation"
#transformations
train_transforms = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
])
test_transforms = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
])
#datasets
train_data = datasets.ImageFolder(traindir,transform=train_transforms)
test_data = datasets.ImageFolder(testdir,transform=test_transforms)
#dataloader
trainloader = torch.utils.data.DataLoader(train_data, shuffle = True, batch_size=16)
testloader = torch.utils.data.DataLoader(test_data, shuffle = True, batch_size=16)训练步长函数
训练步骤通常由三部分定义:模型、优化器和损失函数。
让我们编写一个函数,返回train_step函数。这样,我们就不必一次又一次地重写相同的代码!
def make_train_step(model, optimizer, loss_fn):
def train_step(x,y):
#make prediction
yhat = model(x)
#enter train mode
model.train()
#compute loss
loss = loss_fn(yhat,y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
#optimizer.cleargrads()
return loss
return train_step构建模型
在解决大多数Kaggle任务时,你并不是从头开始编写网络,而是使用一个预训练好的称为base_model的模型,并使其拟合手头的任务。
我们想要做的是通过添加其他Dense层组成头部来拟合它。在我们的例子中,最后一个Dense层将由单个神经元组成,该神经元将使用Sigmoid激活函数,因此我们的输出概率为0或1(猫或狗)。
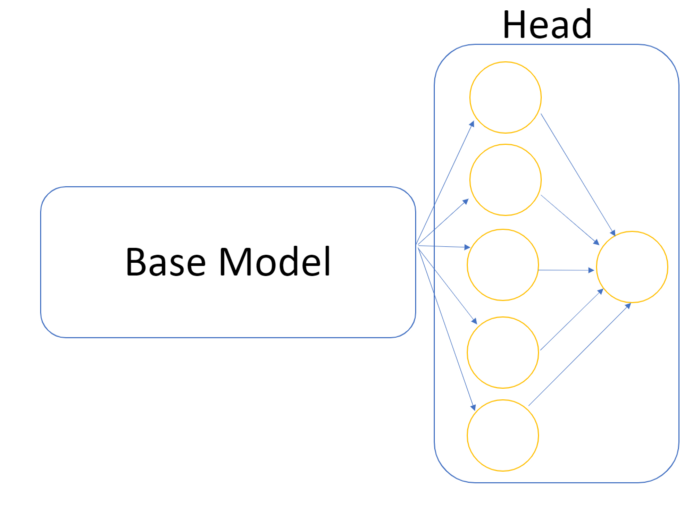
我们必须小心不要训练之前已经训练过的基本模型。
让我们下载一个预训练模型(resnet)并冻结所有参数。然后,我们将更改最后一个线性层,以便将模型自定义为二分类器。模型和数据必须在同一设备(GPU)上。
from torchvision import datasets, models, transforms
import torch.nn as nn
device = "cuda" if torch.cuda.is_available() else "cpu"
model = models.resnet18(pretrained=True)
#freeze all params
for params in model.parameters():
params.requires_grad_ = False
#add a new final layer
nr_filters = model.fc.in_features #number of input features of last layer
model.fc = nn.Linear(nr_filters, 1)
model = model.to(device)我们现在需要定义损失、优化器和train_step。
from torch.nn.modules.loss import BCEWithLogitsLoss
from torch.optim import lr_scheduler
#loss
loss_fn = BCEWithLogitsLoss() #binary cross entropy with sigmoid, so no need to use sigmoid in the model
#optimizer
optimizer = torch.optim.Adam(model.fc.parameters())
#train step
train_step = make_train_step(model, optimizer, loss_fn)训练模型
让我们写下我们的训练和评估阶段。我们还将实现早停策略,并在每个阶段保存最佳模型。
%%capture
!pip install tqdm
from tqdm import tqdm
losses = []
val_losses = []
epoch_train_losses = []
epoch_test_losses = []
n_epochs = 10
early_stopping_tolerance = 3
early_stopping_threshold = 0.03
for epoch in range(n_epochs):
epoch_loss = 0
for i ,data in tqdm(enumerate(trainloader), total = len(trainloader)): #iterate ove batches
x_batch , y_batch = data
x_batch = x_batch.to(device) #move to gpu
y_batch = y_batch.unsqueeze(1).float() #convert target to same nn output shape
y_batch = y_batch.to(device) #move to gpu
loss = train_step(x_batch, y_batch)
epoch_loss += loss/len(trainloader)
losses.append(loss)
epoch_train_losses.append(epoch_loss)
print('\nEpoch : {}, train loss : {}'.format(epoch+1,epoch_loss))
#validation doesnt requires gradient
with torch.no_grad():
cum_loss = 0
for x_batch, y_batch in testloader:
x_batch = x_batch.to(device)
y_batch = y_batch.unsqueeze(1).float() #convert target to same nn output shape
y_batch = y_batch.to(device)
#model to eval mode
model.eval()
yhat = model(x_batch)
val_loss = loss_fn(yhat,y_batch)
cum_loss += loss/len(testloader)
val_losses.append(val_loss.item())
epoch_test_losses.append(cum_loss)
print('Epoch : {}, val loss : {}'.format(epoch+1,cum_loss))
best_loss = min(epoch_test_losses)
#save best model
if cum_loss <= best_loss:
best_model_wts = model.state_dict()
#early stopping
early_stopping_counter = 0
if cum_loss > best_loss:
early_stopping_counter +=1
if (early_stopping_counter == early_stopping_tolerance) or (best_loss <= early_stopping_threshold):
print("/nTerminating: early stopping")
break #terminate training
#load best model
model.load_state_dict(best_model_wts)由于我们从一个预训练的模型开始,并且我们的二分类任务非常简单,因此你很快就会拥有一个能够非常准确地对数据集中的图像进行分类的模型。
推理
现在,你可以使用该模型预测新图像的标签!
import matplotlib.pyplot as plt
def inference(test_data):
idx = torch.randint(1, len(test_data), (1,))
sample = torch.unsqueeze(test_data[idx][0], dim=0).to(device)
if torch.sigmoid(model(sample)) < 0.5:
print("Prediction : Cat")
else:
print("Prediction : Dog")
plt.imshow(test_data[idx][0].permute(1, 2, 0))
inference(test_data)结论
我们已经成功构建了一个图像分类器,用于在图像中识别猫和狗。
在本文中开发了与Tensorflow相同的分类器后,发现Tensorflow可以更快地用于这个简单的项目。但看来,Pytorch的优点是对从数据预处理到模型训练的各个步骤进行更精细的控制。
感谢阅读!
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~