CoCoNet: Coupled Contrastive Learning Network with Multi-level Feature Ensemble for Multi-modality Image Fusion
CoCoNet:用于多模态图像融合的耦合对比学习网络与多级特征集成
Jinyuan Liu; Runjia Lin;Guanyao Wu;Risheng Liu;Zhongxuan;Luo Xin Fan
更多TPAMI,IJCV,TMI等顶刊文章欢迎关注我们的微信公众号,每天带你阅读最新顶刊论文

摘要:红外和可见光图像融合的目标是通过结合不同传感器的互补信息来提供一张信息丰富的图像。现有的基于学习的融合方法尝试构建各种损失函数以保留互补特征,却忽视了两种模态之间的相互关系,导致融合结果中出现冗余甚至无效信息。此外,大多数方法专注于通过增加网络深度来加强网络,而忽略了特征传递的重要性,导致重要信息退化。为了缓解这些问题,我们提出了一种耦合对比学习网络,称为CoCoNet,以端到端的方式实现红外和可见光图像融合。具体来说,为了同时保留两种模态的典型特征并避免在融合结果中出现伪影,我们在损失函数中开发了一种耦合对比约束。在融合图像中,其前景目标/背景细节部分在表示空间中被拉近到红外/可见光源,并从可见光/红外源推开。我们进一步利用图像特性提供数据敏感的权重,使我们的损失函数与源图像建立更可靠的关系。我们还建立了一个多级注意力模块,以学习丰富的层次化特征表示,并在融合过程中全面传递特征。我们还将提出的CoCoNet应用于不同类型的医学图像融合,例如磁共振成像、正电子发射断层扫描图像和单光子发射计算机断层扫描图像。广泛的实验表明,我们的方法在主观和客观评估下都达到了最先进的性能,特别是在保留显著目标和恢复重要纹理细节方面。
关键词:图像融合,红外和可见光图像,无监督学习,对比学习
1 引言
多传感器图像可以从同一场景获取互补和全面的信息,以更好地进行视觉理解和场景感知,这突破了单传感器成像的限制。通过结合不同传感器的重要信息,生成了用于后续图像处理或决策的合成图像。特别是,红外和可见光图像融合(IVIF)是计算机视觉社区中不可或缺的分支。生成的融合结果已被广泛用于后续应用,包括目标检测、行人再识别、语义分割和军事监控。可见光传感器通过反射光线提供高空间分辨率的背景细节。然而,由于照明条件差或伪装条件,目标无法清晰地看到。相比之下,红外传感器通过物体发出的有区别的热辐射成像,对挑战性条件免疫,并且可以全天候工作。因此,将红外和可见光图像融合成一张同时保留双方重要信息的单一图像是值得的。

在过去的几年中,提出了许多实现IVIF的方法。根据它们采用的理论,这些方法可以分为五类,包括基于多尺度变换的方法、基于稀疏表示的方法、基于子空间分解的方法、基于混合的方法、基于优化模型的方法等。这些方法中的一些致力于设计各种特征变换以学习更好的特征表示。其他人则试图发现适当的融合规则。然而,这些方法依赖于手工设计的方式,通常耗时且费力。最近,研究人员将卷积神经网络(CNN)引入了IVIF领域,并取得了最先进的性能。一般来说,基于深度学习的方法可以分为三类,即基于自编码器的方法、端到端CNN基方法和基于生成对抗网络的方法。这些现有的基于学习的方法已经取得了先进的性能,但几个未解决的问题需要进一步关注。首先,由于缺乏标记的融合图像进行监督,将CNN用于IVIF是具有挑战性的。现有的方法试图通过设计各种损失函数来解决这个问题,以惩罚输入和融合图像之间的差异,导致融合结果中出现大量冗余信息。其次,为了融合双方的相应特征,现有的方法依赖于在损失函数中调整权衡参数。这导致融合性能不平衡且费力。第三,现有的基于学习的方法引入了跳跃连接,以减少融合过程中的梯度消失和特征退化。然而,融合结果仍然遭受重要信息丢失的困扰。
在本文中,为了解决上述问题,我们提出了一种用于融合红外和可见光图像的多级特征集成耦合对比学习网络,称为CoCoNet。首先,我们开发了一种耦合对比学习方案,以指导模型区分显著的互补特征,即可见光中的显著目标和纹理细节。这使得模型能够从每种模态中提取并融合所需的特征。其次,应用了一种测量机制来计算源图像的比例重要性,以生成数据驱动的权重。然后,这些生成的权重被应用于我们的损失函数,以替代手动设计的权衡参数。在这种设计下,模型可以生成适应特定源图像的融合图像。此外,设计了一个多级注意力模块(MAM),以学习丰富的层次化特征表示,并确保这些特征在融合过程中得到充分利用。实验表明,CoCoNet可以推广用于融合不同类型的医学图像,例如磁共振成像(MRI)和单光子发射计算机断层扫描(SPECT)图像,旨在同时保留MRI图像中的解剖信息和SPECT图像中的功能性信息。我们的贡献有三个方面:
-
鉴于IVIF的主要基石,即在保留两种模态的互补信息的同时消除冗余,我们引入了耦合对比约束来实现这一目标,并将其无缝集成到损失函数中。
-
我们提出了一种数据驱动机制来计算信息保留度,以增强源图像和融合结果之间的强度和细节一致性。这种方法减少了在损失函数中进行劳动密集型手动参数化的需求,并有助于适应源图像特征。
-
通过设计一个多级注意力模块(MAM),我们的网络能够学习丰富的层次化特征表示,并有效避免在融合过程中的特征退化。
广泛的定性和定量实验在多个数据集上证明了我们方法的优越性,超过了九种最先进的IVIF方法。此外,CoCoNet还能够扩展到医学图像,并取得了优越的性能。
2 相关工作
在这一部分,我们简要回顾了传统的融合方法和基于深度学习的融合方法。此外,还介绍了深度学习中注意力机制和对比学习的应用。
2.1 多模态图像融合方法
2.1.1 红外和可见光图像融合
传统融合方法在过去几十年中被广泛提出和应用。这些方法可以根据其底层理论分为六个主要组:基于多尺度变换(MST)的方法、基于稀疏表示(SR)的方法、基于显著性的方法、基于子空间的方法、基于模型的方法和混合模型等。基于MST的方法在红外和可见光图像融合(IVIF)领域特别流行,并展示了出色的融合性能。这些方法的目标是设计各种变换工具,如小波变换、非子采样轮廓变换、轮廓变换、基于边缘保持滤波器的变换和基于Retinex理论的变换,以在不同尺度上提取特征。然后使用特定的融合规则合并这些特征,并通过反转应用的变换获得最终的融合结果。例如,Li等人(2013)在IVIF任务中应用了引导滤波器,得到了视觉上令人愉悦的融合结果,最小化了噪声干扰。为了在融合结果中保留丰富的细节,Meng等人(2017)基于NSCT和目标区域检测引入了一种IVIF方法。与具有预定义基函数的基于MST的融合方法不同,基于SR的方法旨在从高质量的自然图像中构建一个过度完整的字典。学习到的字典可以稀疏地表示红外和可见光图像,可能增强最终融合结果的表示。Kim等人(2016)提出了一种基于块聚类的方法,实现了引人注目的融合性能,并在学到的字典中去除了冗余。
显著性方法计算以自下而上的方式吸引视觉注意力的显著像素。Ma等人设计了一个滚动引导滤波器,将源图像分解为基础层和细节层,使用视觉显著性图和加权最小二乘优化来合并这些层。基于子空间的方法将高维源图像投影到低维子空间中,以捕获内在结构。像主成分分析(PCA)、独立成分分析(ICA)和强度-色调-饱和度(IHS)这样的技术就属于这一类。Bavirisetti使用四阶偏微分方程来分解图像,然后使用PCA合并分解的细节信息,将丰富的信息传递给融合结果。基于模型的方法也已经被引入到IVIF中。Ma等人首次基于总变分提出了一种IVIF方法,同时保留了红外图像的强度信息和可见光图像的详细信息。最近,Liu等人提出了一种双层优化方法用于IVIF和医学图像融合,使用数据驱动的权重在模型中替代手工设计的参数,进一步提高了融合性能。
尽管传统方法有其优点,但手工设计的特征提取器和手动设计的融合规则使这些方法越来越复杂,导致耗时的过程和有限的融合性能。为了解决这个问题,Liu等人通过结合MST和改进的SR引入了一个统一的融合框架;MST用于分解源图像,SR用于获得融合系数。
深度学习基础的融合方法
深度学习技术由于其强大的非线性拟合能力,在各种任务中取得了显著进步。早期的IVIF方法只使用深度学习进行特征提取或生成权重图。然而,整个过程仍然在传统的优化模型下,这限制了融合性能。最近,一些利用自编码器架构的学习基础方法被提出。预训练的自编码器被用来实现特征提取和特征重建,在其中手动设计了融合规则。
自编码器基础的方法已经被引入到IVIF中。Li和Wu首次通过在编码器部分集成一个密集块,引入了一个自编码器网络用于IVIF,允许全面的特征提取。他们在融合层使用加法和l1-范数规则来生成融合结果。考虑到重要信息经常从网络中退化,Liu等人采用了不同的接收膨胀卷积来从多尺度角度提取特征,然后通过边缘注意力机制合并这些提取的特征。
大量的基于生成对抗网络(GAN)的融合方法已经被提出,由于GAN强大的无监督分布估计能力。Ma等人首次建立了可见图像和融合结果之间的对抗游戏,以增强纹理细节。然而,他们只使用了可见光图像的信息,因此在融合结果上失去了目标的对比度或轮廓。为了改善这个问题,他们后来引入了一个双判别器GAN,其中红外和可见光图像都参与了网络,从而显著提高了融合性能。Li等人引入了一个端到端的GAN模型,集成了多类分类约束。Liu等人设计了一个具有一个生成器和双判别器的融合网络。通过在他们的判别过程中引入一个显著性掩模,它可以保留来自红外的靶心结构信息和来自可见光的纹理细节。
此外,越来越多的研究人员专注于设计通用图像融合网络。Zhang等人引入了一个统一的融合网络,用于以高效率实现各种图像融合任务。该网络只需要在一种类型的融合数据集上进行训练,并调整融合规则以面对其他类型的融合任务。Zhang和Ma引入了挤压和分解的思想到图像融合领域,结合梯度和强度信息构建了一个通用的损失函数,并提出了一个通用融合网络。为了在单个模型中实现多个融合任务,Xu等人提出了一个新的融合网络,克服了训练阶段的存储和计算问题或灾难性遗忘。
最近,由于在自然语言处理领域提出后,transformer受到了广泛关注。后来,Dosovitskiy等人提出了用于图像分类的Vision Transformer(ViT)。这些在计算机视觉其他领域的成功例子激发了基于transformer的方法在图像融合领域的广泛发展。VS等人率先提出了一个图像融合transformer模型,可以同时使用局部信息和长距离信息,这弥补了CNN模型提取全局上下文信息能力的不足。transformer更有效地融合了不同模态的互补信息。Ma等人提出了一种通用融合方法,它可以保留源模态中最大强度的像素,实际上的意图是保留来自热图像的前景目标和来自可见光图像的背景纹理,因为它们确实是每种模态中像素强度较高的区域。此外,最近在扩散模型的进展也为IVIF提供了新的视角。
2.1.2 医学图像融合
与IVIF类似,现有的MIF的传统方法大致可以分为两类:基于多尺度变换的和基于稀疏表示的医学图像融合。MST在医学图像融合领域也是常用的手段。与IVIF中的MST相比,它们的处理流程相似,但细节不同。在医学领域,常见的多尺度变换方法通常使用不同的小波来变换域。例如,Yang等人使用轮廓小波域进行医学图像融合,提出了一种基于轮廓波特征的对比度测量方法,以选择适合人类视觉系统的部件,并进一步通过组合各种融合规则提高融合图像的质量。在医学图像的稀疏表示领域,Liu和Wang提出了一种自适应稀疏表示模型,该模型丢弃了冗余字典以学习紧凑的子字典。源图像块从子字典中自适应地选择特征,以实现减少计算成本并有效减少伪影的效果。Liu等人将形态主成分分析和卷积稀疏表示整合到一个统一的优化框架中,并实现了稳定的可视化效果。
随着深度学习在其他图像融合领域的广泛应用,一些通用融合框架也将医学图像融合作为它们的分支任务。Xu和Ma提出了一种无监督增强医学图像融合网络,以保留表面和深层约束信息。

2.2 深度学习中的注意力机制
起源于自然语言处理(NLP)的注意力机制已成功应用于基于CNN的计算机视觉任务,如显著性目标检测、语义分割、图像增强和图像恢复。这种机制受到人类生物视觉系统专注于感兴趣区域(ROI)的能力的启发,同时忽略不太重要的信息。
在探索前景和背景区域中的显著信息的背景下,Zhang等人引入了双边注意力网络(BiANet)用于RGB-D显著性目标检测任务。该网络利用互补的注意力机制来细化前景和背景区域之间不确定的细节。Liu等人提出了一个用于多曝光图像融合的分层注意力引导模块,使网络能够在极端曝光区域捕获最重要信息。
2.3 对比学习
对比学习在自监督学习领域引起了广泛关注。与其他依赖固定目标的技术不同,对比学习旨在通过使用正样本和负样本来最大化互信息。目标是训练模型使锚点样本更接近正样本,同时远离负样本。
这种方法已应用于各种高级和低级视觉任务,如目标检测、图像去雾、图像超分辨率和多曝光图像融合,实现了最先进的性能。在这项研究中,我们展示了对比学习在学习显著目标和纹理细节的表示以促进有效融合的应用。
3 提出的方法
在这一部分,我们首先描述CoCoNet的动机,然后介绍设计的损失函数,即耦合对比约束和自适应学习损失。接下来,详细介绍网络架构和多级特征集成模块。最后,我们描述了将CoCoNet扩展到医学图像融合的细节。
3.1 动机
我们认为IVIF的目标是在去除两种模态中的冗余信息的同时保留互补信息。然而,没有监督信号作为IVIF任务的明确指导。为了解决这个问题,现有的工作只设计了损失函数中的结构或像素级项,这并不能确保模型被有效特征优化。因此,融合结果中的目标/细节通常包含不愉快的伪影。在这项研究中,我们认为源图像对中存在内在特征指导,即红外中的显著热目标和可见光中的丰富纹理细节。通过手动先验的参与,我们设计了两个基于对比学习的损失项,以对显著目标和生动纹理施加显式约束。此外,大多数融合方法使用跳跃连接来避免融合过程中的信息丢失。然而,这些直接的跳跃连接也可能引入未经筛选的信息,给融合图像带来噪声。此外,损失函数中手工设计的权衡超参数通常难以调整,对模型对特定数据的灵活性构成潜在威胁。因此,我们引入了一个耦合对比学习网络来缓解这些问题。通过详细构建损失函数中的耦合对比约束和自适应权重,我们能够融合最显著的信息,并自动确定它们在损失函数中的个体权重。还结合了一个多级注意力模块来学习全面的特征表示。
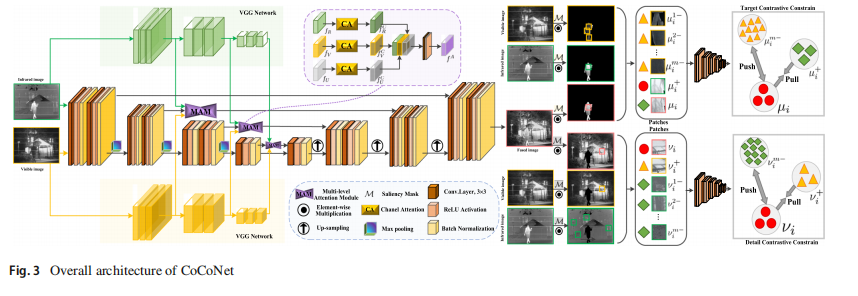
3.2 提出的CoCoNet
3.2.1 耦合对比学习
受到对比学习先前工作的启发,我们提出了一种基于两对约束的IVIF的耦合对比正则化,即目标约束和细节约束。应用对比学习的核心在于确定如何构建正负样本对。对于一幅红外图像,其前景显著的热目标比其余部分更受关注。同样,在可见光图像中,背景生动的纹理细节比其暗淡的前景部分更受追捧。我们利用这一先验来构建对比对,以便我们的模型可以学习区分高像素强度的显著目标和背景文本细节。
为了提高前景显著性,称为目标约束,正样本和负样本应该是 I R ⊙ M IR \odot M IR⊙M 和 I V ⊙ M IV \odot M IV⊙M,其中M表示前景的显著掩模,M代表背景的显著掩模(M = 1 − M)。这个目标的损失函数公式如下:
L i r = ∑ i = 1 N w i ∥ μ i − μ i + ∥ 1 ∑ m = 1 M ∥ μ i − μ m − i ∥ 1 , L_{ir} = \sum_{i=1}^{N} w_i\frac{ \| \mu_i - \mu_{i+} \|_1} {\sum_{m=1}^{M} \| \mu_i - \mu_{m-i} \|_1}, Lir=i=1∑Nwi∑m=1M∥μi−μm−i∥1∥μi−μi+∥1,
其中N和M分别是VGG层数和每个正样本的负样本数。 μ i \mu_i μi 表示融合图像的前景特征,定义为 G i ( I F ⊙ M ) Gi(IF \odot M) Gi(IF⊙M)。 μ i + \mu^+_i μi+ 和 μ m u i − \mu^{mu^-_i} μmui− 是正样本和负样本,分别公式化为 μ i + = G i ( I R ⊙ M ) \mu^+_i = Gi(IR \odot M) μi+=Gi(IR⊙M), μ i m − = G i ( I V m ⊙ M ) \mu^{m−}_i = Gi(I^m_V \odot M) μim−=Gi(IVm⊙M)。
对于背景部分,我们希望保留来自可见光图像的更生动的细节,将红外图像的背景视为负样本,同时将可见光图像的背景视为正样本。细节约束的目标函数可以表示为:
L v i s = ∑ i = 1 N w i ∥ ν i − ν i + ∥ 1 ∑ m = 1 M ∥ ν i − ν i m − ∥ 1 , L_{vis} = \sum_{i=1}^{N} w_i \frac{\| \nu_i - \nu_{i+} \|_1 }{\sum_{m=1}^{M} \| \nu_i - \nu_{i m-} \|_1}, Lvis=i=1∑Nwi∑m=1M∥νi−νim−∥1∥νi−νi+∥1,
其中 v i v_i vi损失和强度相似性损失。 L S L_S LS 通过结构相似性指数度量(SSIM)来衡量,公式如下:
L S = σ a ( 1 − S ( I V , I F ) ) + σ b ( 1 − S ( I R , I F ) ) , L_S = \sigma^a(1 - S(I_V, I_F)) + \sigma^b(1 - S(I_R, I_F)), LS=σa(1−S(IV,IF))+σb(1−S(IR,IF)),
其中 S ( ⋅ ) S(\cdot) S(⋅) 表示 SSIM 值。 L N L_N LN 用于加强强度分布差异的约束,公式如下:
L N = γ a ∥ I V − I F ∥ 2 + γ b ∥ I R − I F ∥ 2 , L_N = \gamma^a \| I_V - I_F \|^2 + \gamma^b \| I_R - I_F \|_2, LN=γa∥IV−IF∥2+γb∥IR−IF∥2,
其中 ∥ ⋅ ∥ 2 \| \cdot \|_2 ∥⋅∥2 是均方误差(MSE)。在上述方程中, σ \sigma σ 和 γ \gamma γ 是两对比例权重,用于平衡可见图像和红外图像的比例。
我们设计了一个自适应损失来考虑数据特征,通过优化图像特定的权重 σ \sigma σ 和 γ \gamma γ。一方面,我们希望融合图像能保留显著的纹理。平均梯度(AG)被应用于优化 SSIM 损失的权重参数 σ \sigma σ:
AG = G ( I F ) = 1 H W ∑ ∥ ∇ h I F ∥ 1 + ∥ ∇ v I F ∥ 1 , \text{AG} = G(I_F) = \frac{1}{HW} \sum \| \nabla_h I_F \|_1 + \| \nabla_v I_F \|_1, AG=G(IF)=HW1∑∥∇hIF∥1+∥∇vIF∥1,
其中 ∇ h I F \nabla_hIF ∇hIF 和 ∇ v I F \nabla_vIF ∇vIF 分别表示融合图像的水平和垂直方向的一阶微分。H 和 W 分别是高度和宽度。 ∥ ⋅ ∥ 1 \| \cdot \|_1 ∥⋅∥1 表示 ℓ 1 \ell_1 ℓ1 范数。
另一方面,为了融合高对比度的图像,图像熵(EN)被用来更新 MSE 损失的权重参数 γ \gamma γ:
EN = E ( I F ) = − ∑ x = 0 L − 1 p x log 2 p x , \text{EN} = E(I_F) = -\sum_{x=0}^{L-1} p_x \log_2 p_x, EN=E(IF)=−x=0∑L−1pxlog2px,
其中 L 表示给定图像的灰度级别, p x p_x px 是像素位于相应灰度级别的概率。
因此,结合上述所有限制,我们给出了以下损失函数来指导学习过程:
L total = L P + L i r + L v i s , L_{\text{total}} = L_P + L_{ir} + L_{vis}, Ltotal=LP+Lir+Lvis,
其中 L P L_P LP 是自适应损失, L i r L_{ir} Lir 和 L v i s L_{vis} Lvis 分别是两对对比损失。
3.3 网络架构
如图3所示,每个卷积块由两组3×3卷积层组成,随后是批量归一化和LeakyReLU。来自每个深度层的特征图可以表示为
f
U
0
,
f
U
1
,
f
U
2
,
f
U
3
f_{U0}, f_{U1}, f_{U2}, f_{U3}
fU0,fU1,fU2,fU3,分别来自具有32、64、128、256通道的层。对于多级注意力模块,我们选择两个预训练权重的 VGG-19 作为我们的主干。它分别以可见光图像和红外图像作为输入,尝试充分利用源图像的高级特征。
为了将更多高级特征融入融合图像,我们提出了一个多级注意力模块(MAM),以实现来自源图像的全面特征表示。基于获得的特征 f U , f R , f V f_U, f_R, f_V fU,fR,fV,首先执行通道注意力:
f U C = C A ( f U ) , f U C = C A ( f R ) , f U C = C A ( f V ) , f_{U}^C = CA(f_U), f_{U}^C = CA(f_R),f_{U}^C= CA(f_V), fUC=CA(fU),fUC=CA(fR),fUC=CA(fV),
其中 CA 表示通道注意力。
为了融合这些特征,我们对每组特征应用卷积操作:
f
A
1
=
Conv
(
Concat
(
f
U
1
C
,
f
R
1
C
,
f
V
1
C
)
)
,
…
,
f_{A1} = \text{Conv}(\text{Concat}(f_{U1}^C, f_{R1}^C, f_{V1}^C)), \ldots,
fA1=Conv(Concat(fU1C,fR1C,fV1C)),…,
f
A
n
=
Conv
(
Concat
(
f
U
n
C
,
f
R
n
C
,
f
V
n
C
)
)
,
f_{An} = \text{Conv}(\text{Concat}(f_{Un}^C, f_{Rn}^C, f_{Vn}^C)),
fAn=Conv(Concat(fUnC,fRnC,fVnC)),
其中 Conv 表示具有3×3核的卷积层,Concat 表示连接。
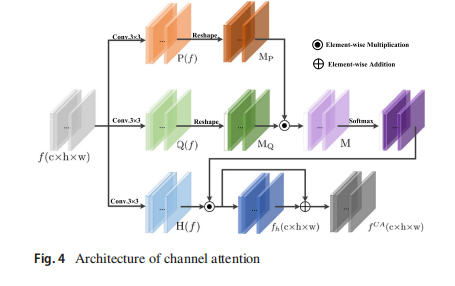
通道注意力的详细架构如图4所示。给定一个维度为 R C × H × W R^{C×H×W} RC×H×W 的特征 f,我们首先使用卷积层生成三个分量 P ( f ) P(f) P(f), Q ( f ) Q(f) Q(f), H ( f ) H(f) H(f),并将 P ( f ) P(f) P(f), Q ( f ) Q(f) Q(f) 从 R C × H × W R^{C×H×W} RC×H×W 重塑为 R C × H W R^{C×HW} RC×HW,获得 M P M_P MP, M Q M_Q MQ。然后在 M P M_P MP 和 M Q M_Q MQ 的转置上应用矩阵乘法,然后通过 softmax 层计算注意力特征图 M ∈ R C × C M ∈ R^{C×C} M∈RC×C。此后,在 H ( f ) H(f) H(f)的转置和 M 之间执行矩阵乘法。最后,结果被重塑并加回到源图像 H ( f ) H(f) H(f)。
3.4 扩展到医学图像融合
在这一部分,我们将 CoCoNet 扩展到医学图像融合,例如 MRI 和 PET 图像融合,MRI 和 SPECT 图像融合。PET 和 SPECT 图像被视为伪彩色图像。我们首先将它们转换为彩色图像,然后分别应用 CoCoNet 融合 MRI 图像和 PET 和 SPECT 图像的强度部分。
3.4.1 医学图像融合背景
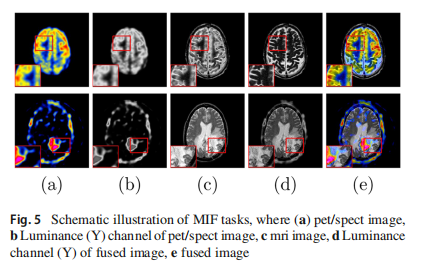
随着临床需求的快速发展,过去几十年来引入了一系列医学成像技术,如 X 射线、计算机断层扫描(CT)、MRI、PET 和 SPECT。每种成像技术都有其优点和局限性。例如,X 射线是一种极高频率、短波长和高能量的电磁波,具有很强的穿透力,已广泛用于诊断或手术前的透视。与传统的 X 射线摄影相比,CT 可以检测到骨骼密度的微小差异,具有高分辨率,但在表示组织特征方面有限。MRI 不仅可以显示器官的形态结构,还可以显示某些器官的功能条件和生化信息。然而,MRI 在详细描绘软组织活动方面存在不足。相比之下,PET 和 SPECT 是功能性成像方式,根据人体组织活动强度的差异显示差异,基于聚集浓度的差异。显然,每种成像方式都有其特点和固有缺陷。将不同模态图像的优势结合起来,为临床诊断提供信息丰富、互补的融合图像是有益的。近年来,一系列混合成像技术,如 CT-MRI、MRI-PET 和 MRI-SPECT,已经成为我们日常生活的一部分。在本文中,我们以两个典型的医学图像融合示例,MRI-PET 和 MRI-SPECT,应用 CoCoNet 来解决这些问题。PET 和 SPECT 图像色彩丰富但分辨率不足,提供功能和代谢信息,广泛用于分析器官的功能或代谢条件。另一方面,MRI 图像可以更好地描绘器官的软组织结构,并且通常具有高空间分辨率。因此,通过整合每种模态图像的优势,我们可以获得具有互补和全面信息的单一图像。通常,如图5a所示,PET 和 SPECT 以伪彩色显示,其中颜色代表功能信息。对于融合图像,颜色信息应与 PET 或 SPECT 图像对齐。为了实现这一点,我们使用 YCbCr 颜色空间将 PET 和 SPECT 图像解耦为三个通道。然后我们使用 Y 通道(亮度通道,如图5b所示)与 MRI 图像融合。PET 和 SPECT 使用 Y 通道的强度信息来表示特征分布,类似于红外图像,而 MRI 图像如图5c所示,具有丰富的纹理和组织细节,类似于可见光图像。因此,MIF 和 IVIF 具有相似的目标,即减少融合图像和相应模态的空间细节失真和颜色强度失真。通过 Y 通道和 MRI 图像获得融合图像(图5d)后,另外两个通道保持不变以恢复颜色信息,如图5e所示。
3.4.2 CoCoNet 在医学图像融合中的应用
基于MRI序列和功能序列(例如PET和SPECT)的独特特性,我们同样可以应用所提出的耦合对比学习来整合不同医学模态中的理想特征。我们首先需要分别定义MRI和功能(即PET/SPECT)模态的特征兴趣点。MRI序列富含软组织结构信息,为大脑骨架提供清晰的指示。为了更好地保留来自MRI图像的显著结构信息,同时融合反映器官或组织代谢活动的功能性信息,以及受体的功能和分布。
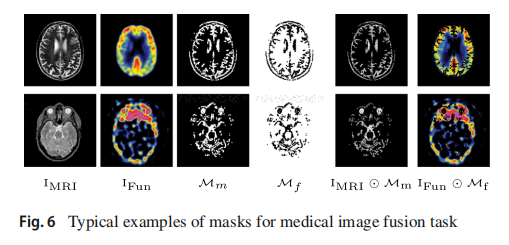
具体来说,为了从双方结合有用的特征,我们提出施加MRI分割掩膜及其反向版本在MRI序列和功能序列上,以便对我们想要提取的特征进行更好的约束。对于融合图像,我们希望其显著区域与对应的MRI图像相似,但与功能对应区域不太相似。同样,我们期望融合图像中的其他区域更接近功能序列,在潜在特征空间中与MRI对应区域的距离更远。
实际上,融合MRI和功能序列的一个常见问题是,MRI中的纹理细节往往会在与其功能对应区域融合后被覆盖,从而被削弱。为了部分缓解这个问题,我们的显著掩膜首先通过分割MRI图像来生成,按照Li和Chi(2005)的研究,记为[ M_m = M ],如图6所示。我们期望融合图像在被[ M_m ]掩膜遮盖的区域下,与MRI序列相似,以保留软组织纹理。同时,根据对比学习,相同区域中的功能序列作为负样本,有助于强调MRI特征。这个过程可以描述如下:
L mri = ∑ i = 1 N w i ∥ μ i − μ i + ∥ 1 ∑ m = 1 M ∥ μ i − μ m − i ∥ 1 , L_{\text{mri}} = \sum_{i=1}^{N} w_i \frac{\| \mu_i - \mu_{i+} \|_1}{ \sum_{m=1}^{M} \| \mu_i - \mu_{m-i} \|_1}, Lmri=i=1∑Nwi∑m=1M∥μi−μm−i∥1∥μi−μi+∥1,
其中N和M分别是VGG层数和每个正样本的负样本数。 μ i \mu_i μi表示融合图像的MRI结构特征,定义为 G i ( I F ⊙ M m ) G_i(I_F \odot M_m) Gi(IF⊙Mm)。 μ i + \mu_{i+} μi+和 μ m − i \mu_{m-i} μm−i是正样本和负样本,分别公式化为 μ i + = G i ( I MRI ⊙ M m ) \mu_{i}^+ = G_i(I_{\text{MRI}} \odot M_m) μi+=Gi(IMRI⊙Mm), μ m − i = G i ( I Fun m ⊙ M m ) \mu_{m-}^i = G_i(I^m_{\text{Fun}} \odot M_m) μm−i=Gi(IFunm⊙Mm)。
相反,功能序列可以提供丰富的受试者功能活动强度信息,例如血流。为了保留来自功能序列的最有利特征,我们首先反转MRI分割掩膜 M m M_m Mm以得到 M f = 1 − M m M_f = 1 - M_m Mf=1−Mm。然后 M f M_f Mf被施加在功能序列上以提取包含受试者代谢信息的最有信息量的特征。融合图像在掩膜 M f M_f Mf下的区域应该与功能图像一致,与MRI图像不太相似。这整个过程可以利用以下给出的双对比学习基础损失函数来建模:
L fun = ∑ i = 1 N w i ∥ ν i − ν i + ∥ 1 ∑ m = 1 M ∥ ν i − ν m − i ∥ 1 , L_{\text{fun}} = \sum_{i=1}^{N} w_i \frac{\| \nu_i - \nu_{i+} \|_1}{{ \sum_{m=1}^{M} \| \nu_i - \nu_{m-i} \|_1}}, Lfun=i=1∑Nwi∑m=1M∥νi−νm−i∥1∥νi−νi+∥1,
其中 ν i \nu_i νi表示融合图像的功能性特征,定义为 G i ( I F ⊙ M f ) . v i + G_i(I_F \odot M_f).v^+_i Gi(IF⊙Mf).vi+。 v i + v^+_i vi+和 v i m − v^{m-}_i vim−是正样本和负样本,分别公式化为 v i m − = G i ( I M R I m ⊙ M f ) v^{m-}_i= G_i(I^m_{MRI} \odot M_f) vim−=Gi(IMRIm⊙Mf), ν i m − i = G i ( I MRI m ⊙ M f ) \nu^{m-i}_i = G_i(I^m_{\text{MRI}} \odot M_f) νim−i=Gi(IMRIm⊙Mf)。
4 实验
4.1 实验设置
4.1.1 数据集
我们使用公开可用的TNO 1和RoadScene数据集来评估我们的方法。这些数据集的详细情况如下所述。TNO数据集是用于红外和可见光图像融合的广泛使用的数据集。我们采用TNO作为基准来训练我们的网络,因为它拥有高质量的图像和独特的场景。RoadScene数据集包含221对代表性图像,这些图像包含真实驾驶场景(例如,车辆、行人和道路标志),它们是从真实的驾驶视频中收集而来,分辨率并不统一。

4.1.2 训练细节
我们的整个融合框架在TNO数据集上通过两个阶段进行训练:训练和微调。整体训练策略可以在算法1中找到。在训练阶段,只有自适应损失被用来更新网络参数(即,对比约束在此阶段不涉及)。具体来说,自适应因子 s i g m a a , b sigma_a,b sigmaa,b和 γ a , b \gamma_a,b γa,b首先通过测量图像对的平均梯度和熵来计算,注意这不会网络参数。之后,网络受到自适应损失的惩罚。关于数据预处理和其他超参数,我们选择了46对图像并将它们转换为灰度图像。为了充分利用每个图像的梯度和熵进行自适应训练损失,从源图像中裁剪了1410张64×64大小的图像补丁,这使得网络能够更好地感知微妙的梯度和熵。然后,训练补丁被标准化到[-1, 1]并输入到我们的网络中。Adam被选为优化器,学习率设置为0.0001,批量大小为30。在微调阶段,自适应损失和对比约束都参与更新网络权重,如算法1所示。此步骤使用的数据仅包括来自TNO的18张带有显著性掩膜的图像。与前一阶段一样,裁剪了1410张64×64大小的图像。对于对比约束损失,我们使用一个正样本和三个负样本(一个与正补丁相对应,另外两个从其他负补丁中随机选择)。网络更新了5个周期,优化器、学习率和批量大小设置与第一阶段相同。调整参数[ \alpha ]被设置为经验值20。融合性能在训练周期的可视化说明如图7所示。同样,为了训练我们的医学成像模型,需要两个阶段:训练和微调。从Atlas2数据集中选择了2662个PET补丁和4114个SPECT补丁图像。所有图像都被裁剪成64×64大小,并标准化到[-1, 1]作为训练集。我们在两个阶段都选择Adam作为优化器,学习率设置为0.0001。在训练阶段,模型训练了3个周期,批量大小为30。在微调阶段,模型训练了1个周期,批量大小为10。自适应损失和对比损失设置与IVIF任务相同。调整参数 α \alpha α设置为20。
4.1.3 评估指标
为定量评估图像融合的性能,本文选取了六个常用的图像质量评价指标,包括熵(EN)、平均梯度(AG)、空间频率(SF)、标准差(SD)、差异相关性之和(SCD)和视觉信息保真度(VIF)。以下是这些指标的详细说明:

熵 (EN)
熵用于衡量图像中包含的信息丰富程度,值越大表示融合策略的效果越好。计算公式为:
EN
=
−
∑
x
=
0
L
−
1
p
x
log
2
p
x
\text{EN} = -\sum_{x=0}^{L-1} p_x \log_2 p_x
EN=−x=0∑L−1pxlog2px
其中[ L ]表示给定图像的灰度级数,[ p_x ]是像素位于对应灰度级的概率。
平均梯度 (AG)
平均梯度衡量融合图像的梯度信息,可以反映图像的细节。计算公式为:
AG
=
1
H
W
∑
h
∑
w
∥
∇
h
I
F
∥
1
+
∥
∇
v
I
F
∥
1
\text{AG} = \frac{1}{HW} \sum_h \sum_w \| \nabla_h IF \|_1 + \| \nabla_v IF \|_1
AG=HW1h∑w∑∥∇hIF∥1+∥∇vIF∥1
其中[ \nabla_h IF ]和[ \nabla_v IF ]分别代表融合图像的水平和垂直方向的一阶微分。[ H ]和[ W ]分别为图像的高度和宽度。
空间频率 (SF)
空间频率反映图像中灰度变化的指标,值越高表示图像具有更丰富的纹理细节。基于水平和垂直梯度信息获得,其数学表达式如下:
S
F
=
H
2
+
V
2
SF = \sqrt{H^2 + V^2}
SF=H2+V2
其中[ H ]和[ V ]为:
H
=
1
M
N
∑
i
=
1
M
∑
j
=
2
N
∣
I
F
(
i
,
j
)
−
I
F
(
i
,
j
−
1
)
∣
2
H = \sqrt{\frac{1}{MN} \sum_{i=1}^{M} \sum_{j=2}^{N} |IF(i, j) − IF(i, j − 1)|^2}
H=MN1i=1∑Mj=2∑N∣IF(i,j)−IF(i,j−1)∣2
V
=
1
M
N
∑
i
=
2
M
∑
j
=
1
N
∣
I
F
(
i
,
j
)
−
I
F
(
i
−
1
,
j
)
∣
2
V = \sqrt{ \frac{1}{MN} \sum_{i=2}^{M} \sum_{j=1}^{N} |IF(i, j) − IF(i − 1, j)|^2}
V=MN1i=2∑Mj=1∑N∣IF(i,j)−IF(i−1,j)∣2
M
M
M和
N
N
N为估计图像的宽度和高度。
标准差 (SD)
标准差用来衡量图像是否包含丰富的信息和高对比度。值越大表示图像包含更多的特征。计算公式为:
SD
=
1
M
N
∑
i
=
1
M
∑
j
=
1
N
∣
I
F
(
i
,
j
)
−
μ
∣
2
\text{SD} = \frac{1}{MN} \sum_{i=1}^{M} \sum_{j=1}^{N} |I_F(i, j) − \mu|^2
SD=MN1i=1∑Mj=1∑N∣IF(i,j)−μ∣2
其中[ \mu ]为平均像素值。
差异相关性之和 (SCD)
基于图像相关性的指标,首先定义源图像[ IX ]和融合图像[ IF ]的相关性如下:
r
(
I
X
,
I
F
)
=
∑
i
=
1
M
∑
j
=
1
N
(
I
X
(
i
,
j
)
−
I
X
ˉ
)
(
I
F
(
i
,
j
)
−
I
F
ˉ
)
∑
i
=
1
M
∑
j
=
1
N
(
I
X
(
i
,
j
)
−
I
X
ˉ
)
2
∑
i
=
1
M
∑
j
=
1
N
(
I
F
(
i
,
j
)
−
I
F
ˉ
)
2
r(I_X, I_F) = \frac{\sum_{i=1}^{M} \sum_{j=1}^{N}(I_X(i, j) − \bar{I_X})(I_F(i, j) − \bar{IF})}{\sqrt{\sum_{i=1}^{M} \sum_{j=1}^{N}(IX(i, j) − \bar{IX})^2} \sqrt{\sum_{i=1}^{M} \sum_{j=1}^{N}(IF(i, j) − \bar{IF})^2}}
r(IX,IF)=∑i=1M∑j=1N(IX(i,j)−IXˉ)2∑i=1M∑j=1N(IF(i,j)−IFˉ)2∑i=1M∑j=1N(IX(i,j)−IXˉ)(IF(i,j)−IFˉ)
融合图像与源图像的差异定义为[ DV_{F} ]和[ DR_{F} ],它们分别是源图像与差异图像之间的相关性。SCD定义为:
SCD
=
r
(
I
V
,
D
V
,
F
)
+
r
(
I
R
,
D
R
,
F
)
\text{SCD} = r(I_V, D_{V,F}) + r(I_R, D_{R,F})
SCD=r(IV,DV,F)+r(IR,DR,F)
视觉信息保真度 (VIF)
VIF基于图像的保真度来评估图像质量,决定图像是否视觉友好。它评估从源图像融合的有效信息量。值越大表示质量越好。VIF定义为:
VIF
(
I
V
,
I
R
,
I
F
)
=
∑
b
FVID
s
,
b
(
I
V
,
I
R
,
I
F
)
∑
b
FVID
s
,
b
(
I
V
,
I
R
,
I
F
)
\text{VIF}(I_V, I_R, I_F) = \frac{\sum_{b} \text{FVID}_{s,b}(I_V, I_R, I_F)}{\sum_{b} \text{FVID}_{s,b}(I_V, I_R, I_F)}
VIF(IV,IR,IF)=∑bFVIDs,b(IV,IR,IF)∑bFVIDs,b(IV,IR,IF)
其中
t
e
x
t
F
V
I
D
s
,
b
text{FVID}_{s,b}
textFVIDs,b是有失真的融合视觉信息,
FVIND
n
,
s
,
b
\text{FVIND}_{n,s,b}
FVINDn,s,b是无失真的融合视觉信息,在第
b
b
b块,第
s
s
s子带。
4.2 IVIF的结果与分析
在TNO上的质量比较
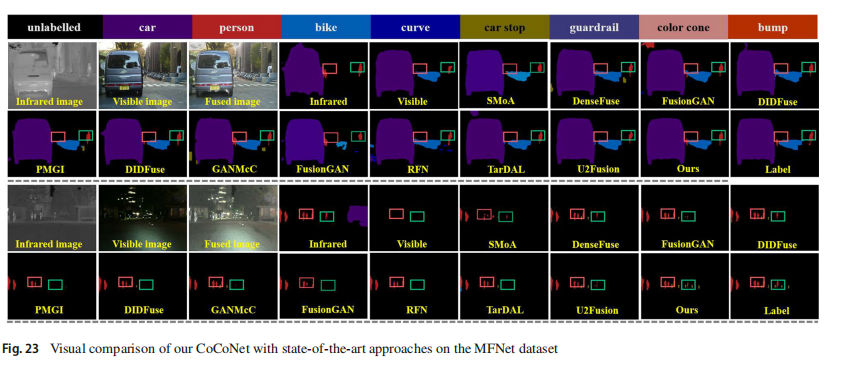
在图8中,我们将我们的CoCoNet与DenseFuse、FusionGAN、PMGI、DIDFuse、GANMcC、RFN、MFEIF、U2Fusion、SwinFusion、SDNet、SMoA和TarDAL等几种现有的最先进方法在TNO数据集上的样本进行了比较。由于我们提出的对比学习,总体上,我们的结果显示更高的对比度,前景目标更加明亮(例如,树木、叶子和被红绿框框住的前景对象)。图片中第一张图示中,显著的对象(被红框框住)更清晰、更明显,这归功于从多级注意力机制中提取的红外对比和语义特征。DenseFuse和DIDFuse也能给出清晰的热特征,然而它们的图像不够亮,从而导致最终视觉效果的下降。FusionGAN和RFN未能提供清晰目标(他们的结果中的人看起来模糊)。另一方面,我们也能保留来自可见光图像的生动纹理细节。如第二张对比图中所示,红框展示了叶子的丰富和清晰细节,而FusionGAN、DIDFuse和SMoA提供的详细纹理几乎没有。综合来看,我们提出的方法在红外目标和可见光特征的质量方面达到最佳平衡,并且以自然的方式融合了两种模态。尽管DenseFuse和FusionGAN也能产生相对理想的前景目标,但它们未能提供清晰的背景信息,它们的图像往往暗淡或模糊。总之,CoCoNet在显著性和细节生动性方面取得了最佳平衡。

在RoadScene上的质量比较
我们还在图9上展示了我们的方法和现有技术在典型真实驾驶场景(例如道路、符号标志和行人)上的视觉比较。一般来说,所有这些方法都可以在一定程度上将源图像中的热辐射和纹理结构细节融合起来。然而,RFN和FusionGAN倾向于有模糊的边缘。我们的方法、TarDAL和SDNet都产生了视觉友好的融合图像,其中我们的显著目标(即被红框框住的行人)更加明亮和显眼。不幸的是,RFN未能像其他方法那样结合尽可能多的红外信息,这导致它们的物体不够清晰。另一方面,CoCoNet在生动的结构细节方面也取得了最佳性能。在第二张对比图中,可以看到被绿框标记的卡车即使在相对低光场景中也呈现出更好的纹理。然而,FusionGAN和PMGI无法解决这样的问题,它们在框内区域显得黑暗和模糊。我们将此归功于所提出的多级注意力机制,其中我们融合了更多的高级特征,并重新排列了不同特征通道的重要性。因此,我们的图像更锐利、更清晰。尽管TarDAL也能提供高质量的融合结果,但输出往往会受到光晕的影响,从而降低可见性。总的来说,我们已经在道路场景中达到了顶级,我们的方法在各种场景中更加稳健。

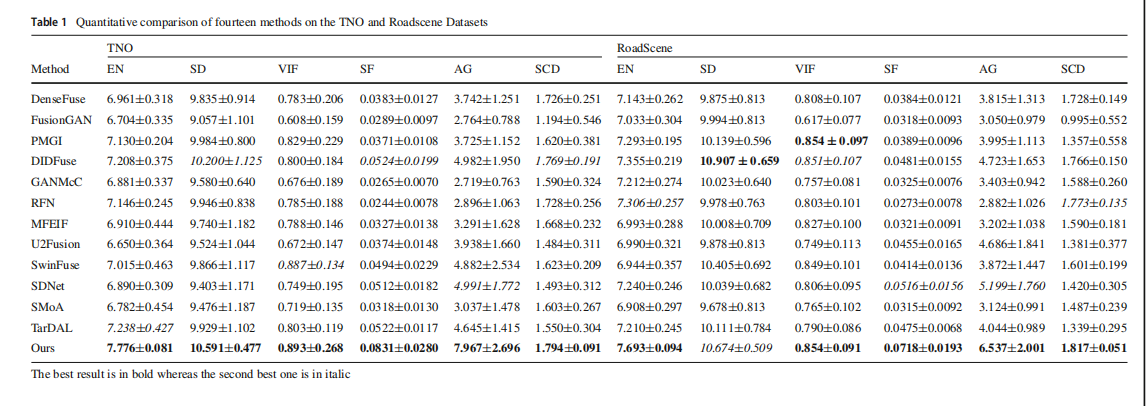
在TNO上的数量比较
我们在图10中提供了所有方法在上述部分讨论的几个重要指标上的评价结果。显然,在TNO数据集上,我们在所有六个指标上都取得了最高结果,这表明所提出的CoCoNet能够充分利用源图像中的重要特征。此外,在表1中,我们还展示了每个指标的平均值和标准差,以展示我们的总体性能。对于TNO数据集,值得注意的是,在SF和AG上,我们比排名第二的最佳方法高出58%的得分。这进一步证明,由于所提出的自适应学习,我们能够生成具有更多灰度级别、因此更具有信息性的图像。DIDFuse在SD和SCD方面也取得了相对优秀的结果。TarDAL在EN上取得了令人满意的结果。
在RoadScene上的数量比较
我们可以处理的不仅仅是军事场景,还有复杂的驾驶场景。由于对比学习,融合图像包含具有高对比度的独特灰度级别。图10还在RoadScene数据集的第二行显示了数量比较。总的来说,我们在EN、SF、AG、SCD上取得了最佳结果,并在SD上取得了最先进水平的结果。表1列出了所有方法的评估。这展示了我们的方法可以从源图像中融合最有效的信息,我们的可见性和清晰度也是最高水平的。值得一提的是,所提出的CoCoNet在SF上比排名第二的SDNet高出58%,这表明即使在复杂的真实场景中,我们的结果也包含了更多具有丰富特征的信息,这归功于自适应学习策略。

4.3 消融研究
在这一部分,我们讨论了CoCoNet中不同模块的必要性。
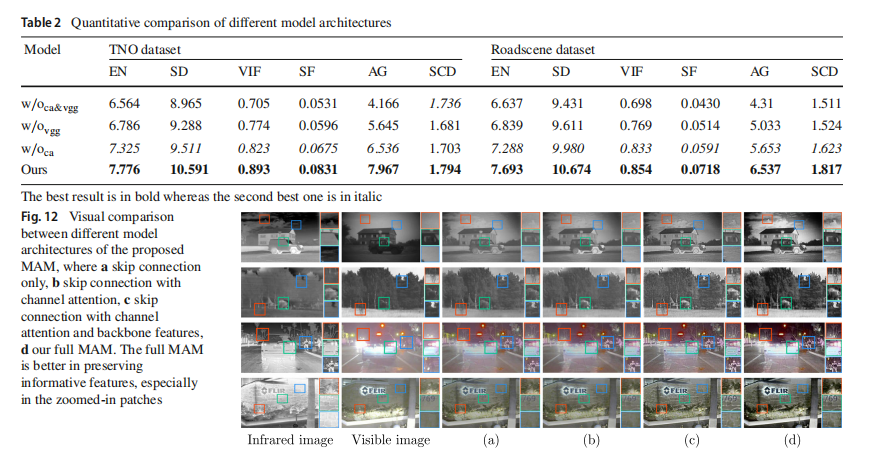
多级注意力模块(MAM)的有效性
为了消融使用多级注意力机制的影响,我们移除了来自预训练VGG主干的特征、通道注意力或两者,分别生成了MAM的三个变体。在图11中,我们展示了这些变体以及我们完整的MAM,其中(a)移除了通道注意力和预训练VGG主干,(b)只移除了预训练主干,©只从MAM中移除了通道注意力,(d)是我们完整的MAM。数值结果在表2中报告,其中w/oca&vgg、w/ovgg、w/oca和ours分别对应前述的(a)、(b)、©和(d)。值得注意的是,移除预训练VGG特征会导致在TNO和RoadScene数据集上的指标显著下降,这证明了从预训练主干中提取的高级特征的重要性。为了证明通道注意力的重要性,我们也注意到从w/oca&vgg到w/o vgg和从w/oca到ours在EN、SF、SD和VIF上的性能提升。这表明通道注意力重新排列了从两种模态获得的不同通道的权重,有利于融合图像的整体纹理细节。此外,还提供了w/oca&vgg到ours的视觉比较图,如图12所示。显然,通过添加预训练VGG特征,融合图像的锐度大大提升。因此,列(d)和列©比(b)和(a)要清晰得多,例如,绿色框中指示的字母在列©和(d)中更清晰,全局结构信息也更明显。通过重新组织特征通道,通道注意力使我们的网络能够进一步去除不需要的噪声并保留更丰富的细节,这在列©和(d)之间的差异中得到体现。
来自VGG的特征的消融
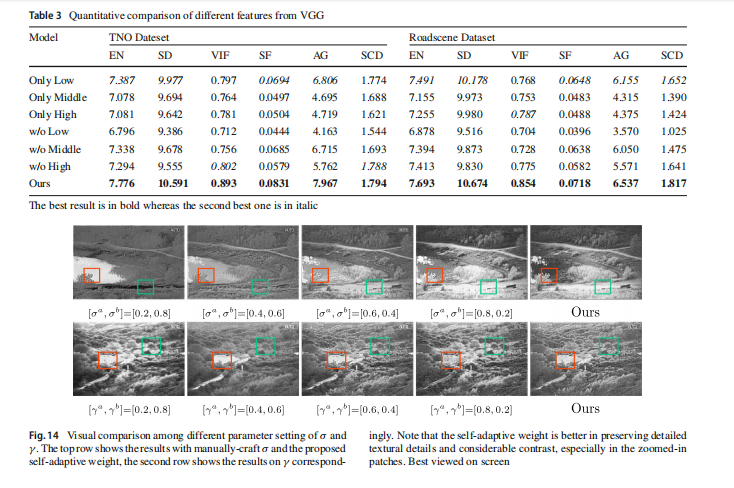
考虑到VGG提取的低/中/高级别特征(64/128/256通道)具有不同的特性,我们创建了六个新的变体进行实验,包括仅包含低/中/高级别特征的变体,以及不包含它们的变体。图13提供了视觉比较图像。可以观察到,特征在两个数据集中显示出相似的趋势。低级特征通常对图像中的边缘和颜色信息有很强的响应。不包含低级特征的变体丢失了大量细节信息并产生颜色偏差。不包含中级别和高级别特征的变体与完整模型相比表现出一些退化。在仅包含一种特征的变体中,仅包含低级特征的变体在可视化效果上表现相对较好,而仅包含高级特征的变体则具有出色的整体对比度。完整模型的融合结果保持了丰富的细节信息(如上图中的树枝和下图中的灌木丛),同时也实现了显著的个体突出和场景的高对比度。表3提供了两个数据集上的定量比较结果。仅包含最低级别特征的变体在大多数指标上获得了第二名,而不包含最低级别特征的变体表现最差。这表明低级特征提供了更多的边缘和颜色信息,从而更好地描述了图像。在低级特征的基础上,添加中/高级特征实际上产生了负面影响。所提出的完整方法,整合了所有级别的特征,在所有指标上都取得了最佳性能。

自适应学习的有效性
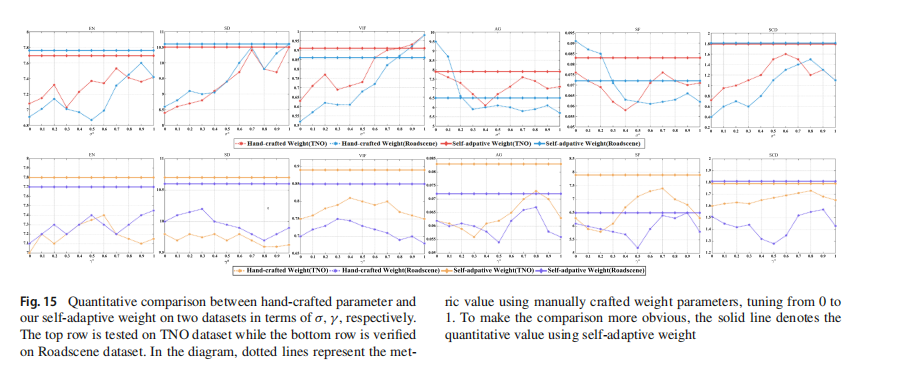
在TNO和RoadScene数据集上进行了额外的实验,以验证所提出的自适应学习的有效性。在图14中,我们可视化了几种手工设计的训练权重和基于源图像内部特性的自适应权重的性能。具体来说,
σ
\sigma
σ和
γ
\gamma
γ分别是SSIM和MSE的权重。我们展示了采用几种可能的固定权重组合(例如,
σ
a
\sigma_a
σa从0到1变化,同时确保
σ
a
\sigma_a
σa和
σ
b
\sigma_b
σb的和为1)的融合结果,与自适应策略(最后一列所示)进行比较。如图14所示,自适应方式实现了更高的对比度,通过使用平均梯度和熵信息,强调了显著的热目标和来自可见光图像的生动细节,如绿色和红色框所示。草的细节更清晰,像素更明亮,建筑物结构保持了精细的边缘。总的来说,自动学习到的权重可以生成具有更好全局对比度的图像。此外,我们在图15中进一步绘制了定量结果,以证明我们的有效性。第一行的结果报告了当
σ
\sigma
σ固定在0到1之间的某个值时,六个指标的性能,而
γ
\gamma
γ是自适应的。同样,在第二行,
γ
\gamma
γ是手工设计的,而
σ
\sigma
σ是基于源图像学习的。我们注意到,对于SSIM和MSE权重,手工设计的方式在大多数情况下无法适应各种图像的特性,因此在六个评估指标上的得分较低。在TNO数据集上,我们的策略在SCD上比固定SSIM权重高出约0.2个百分点,这高于最佳手工设计权重。尽管在某些点上手工设计权重优于我们(例如,当
σ
\sigma
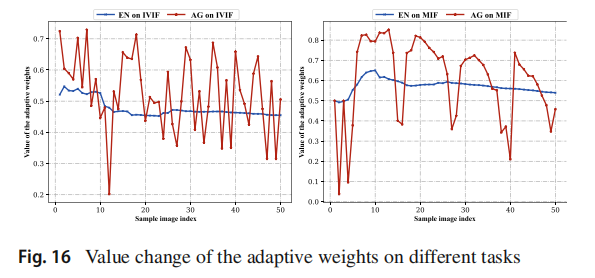
σ设置为0.8时,固定权重在VIF上略优于我们),但我们通过使用单一图像本身的特性来生成更高质量的图像,这对具有不同特性的源图像是稳健的。在图16中,我们可视化了从TNO和MRI-PET数据集中随机选择的50对图像的特定权重值。
σ
\sigma
σ线和
γ
\gamma
γ线在两个数据集上都波动,这表明了模态之间独特结构的动态性质。这进一步证明了在我们的损失设置下,固定的
σ
\sigma
σ和
γ
\gamma
γ权重不能完全利用源图像的结构信息/像素分布进行融合。
对比学习的有效性
为了进一步验证所提出的对比正则化的有效性,我们进行了实验,视觉比较可以在图17中找到,其中(a)表示没有目标和细节约束的结果,列(b)表示只有目标约束的结果,列©表示只有细节约束的结果。为了更好地展示对比正则化中样本选择的重要性,在列(d)中,我们使用不相对应的样本(即,图像块是从整个数据集中随机选择的)进行对比。完整的对比学习在列(e)中给出。显然,缺乏红外和可见光的对比会带来不需要的噪声到融合结果中,导致边缘模糊(例如,在列(a)中,红框中的树的细节不够清晰,有噪声像素)。在列(b)中,我们展示了只使用红外正则化的结果。尽管显著的热目标得到了增强,我们仍然注意到可见光细节的图像质量下降,使得很难呈现生动的纹理信息。这证明,在可见光部分去除正则化可能会损害融合过程中的纹理细节。在列©中,我们展示了只使用可见光约束的结果,通过去除红外增强。显然,由于缺乏足够的红外特征指导,热目标(例如,绿色框中指示的站立的人)在不可见的细节上很丰富,但不够明亮。基于列(d)的结果,我们认为补丁采样在对比正则化中是最重要的。在没有正确指导的情况下,融合图像会降级,其像素变暗且不够清晰,例如,人不够亮,图像总体上显得模糊。总之,目标和细节约束都不可或缺,以实现我们最初的目标,即结合红外图像中的显著热目标和可见光图像中生动的背景细节。
不同掩膜的分析
我们以不同的方式生成了
M
M
M,以研究
M
M
M对所提出方法的影响。所有三种掩膜在图18的第一行中显示。
T
M
T_M
TM是由人类检测算法Montabone和Soto根据显著性机制引导生成的特征权重图。在实践中,我们设置了一个阈值来转换它,因为它最初不是一个0-1掩膜。
U
M
U_M
UM来自一个无监督的显著性检测器,它也标记了红外图像中室温突出显示的门。我们使用这三种不同的掩膜进行融合,结果在图18的第二行中显示。从视觉角度看,不同的掩膜并不影响所提出方法的可视化特征(如真实细节和高对比度)。所提出方法的性能几乎独立于我们如何获得掩膜。

4.4 计算复杂性分析
除了定性和定量分析之外,模型大小和运行速度在实际应用中也非常重要。因此,我们验证了所提出模型的内存消耗和计算效率。注意,这部分显示的结果可能由于运行平台、超参数等不同设置与原论文略有不同。具体来说,FLOPs和训练参数是通过设置输入尺寸为64×64来计算的。对于运行时间,我们选择了TNO中的十张64×64尺寸的图像来计算平均时间。表4显示了几个最先进方法之间的模型大小、FLOPs和运行时间的定量结果。我们的模型除了比SDNet和MFEIF慢之外,比其他所有方法都快。尽管由于它们的框架简单,我们在速度上慢了一些,但我们的模型仍然实现了不到0.1秒的运行时间,这比DenseFuse和U2Fusion快两倍,比PMGI快三倍,比FusionGAN、GANMcC和RFN快四倍。此外,尽管我们的CoCoNet比FusionGAN更复杂,我们仍然享有更快的速度,这证明了所提出架构的优势。特别地,MAM模块需要大量参数来计算和整合多级特征,以实现更好的特征提取和传输。尽管去除MAM模块可以在一定程度上减轻计算复杂性,但它可能会在融合过程中丢失一些重要信息,导致融合结果的细节丢失或目标模糊。


4.5 局限性
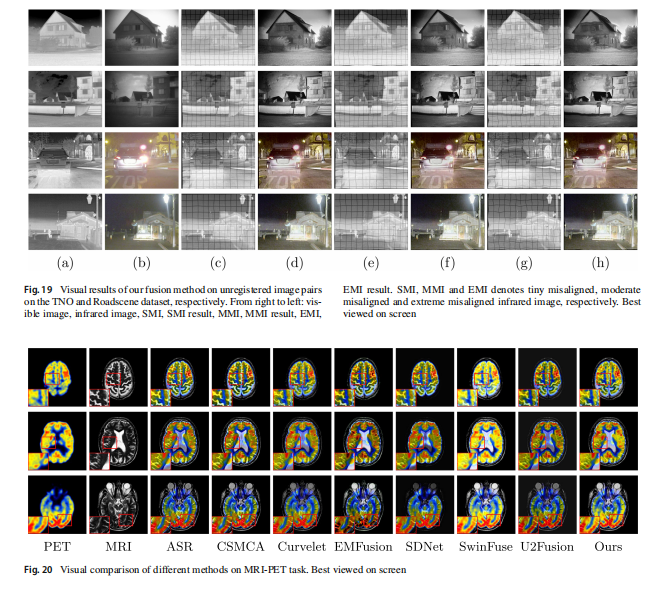
在大多数现实场景中,获取像素级对齐的红外和可见光图像对是非常具有挑战性的。现有工作通过引入额外的配准模块来缓解这一问题。为了讨论融合这些轻微不对齐图像对的影响,我们首先通过在TNO、Roadscene数据集上执行不同程度的随机仿射和弹性平移(即小、中、大)来合成这些轻微不对齐的源图像。然后我们使用提出的方法来合并这些不对齐的源图像。视觉结果如图19所示,注意我们的方法可以处理轻微不对齐的图像,保留了大部分重要信息。然而,当像素偏差显著时,融合结果上会出现光晕和伪影。
4.6 MIF上的結果與分析
我们将提出的方法与一些现有的最先进方法进行了比较,包括三种传统方法(即基于自适应稀疏表示的ASR、基于卷积稀疏表示和形态主成分分析的CSMCA,以及基于轮廓波变换的Curvelet),三种基于CNN的方法(即EMFusion、SDNet和U2Fusion)和基于transformer的SwinFuse。由于SwinFusion只能处理MRI-PET图像对,所以其结果只参与了MRI-PET融合任务的比较。
4.6.1 MRI-PET融合任务
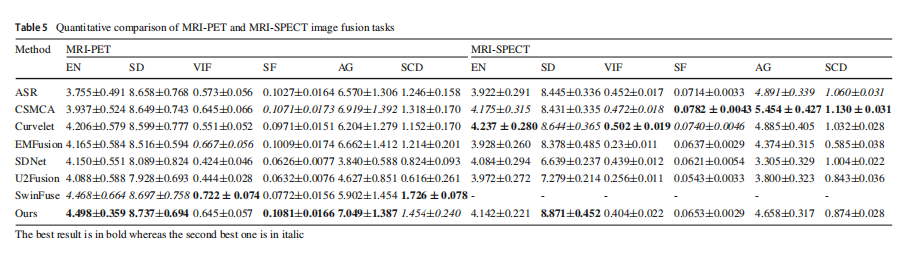
定性比较
在图20中展示了典型MRI-PET图像的可视化比较。得益于多尺度注意力机制,提出的方法能够准确保留不同模态中的高价值信息。此外,使用MRI分割掩膜的对比学习,成功解决了MRI图像信息被其他模态强度信息覆盖的问题,防止了有效细节的丢失。三种传统方法表现相似,它们专注于MRI细节的保留,但忽略了另一模态中颜色信息的恢复(第一和第二组图像的框架部分)。SDNet和U2Fusion难以有效提取和保存信息,导致细节和颜色的严重丢失,而EMFusion造成了严重的颜色失真(最后一组图像的框架部分)。SwinFusion很好地保留了颜色信息,但没有解决MRI细节被覆盖的问题。总之,提出的方法在保留颜色和细节信息之间取得了平衡,并实现了最佳的视觉效果。
定量比较
为了更好地了解CoCoNet在MIF任务上的性能,我们提供了所有方法在上述部分讨论的指标上的评价结果。结果在表5的左侧显示。显然,提出的方法在EN、SD、SF、AG上取得了最高结果,并在SCD上达到了最先进的水平。SwinFusion以其特征突出的可视化效果,取得了最高的VIF和SCD结果。
4.6.2 MRI-SPECT融合任务
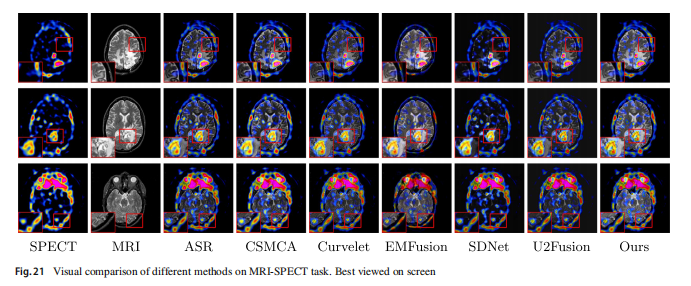
定性比较
在图21中展示了典型MRI-SPECT图像的可视化比较。与PET不同,SPECT图像的强度信息更加稀疏。使用的MRI分割掩膜对比学习可以更好地保留MRI图像的细节,减少干扰。其他深度学习方法在不同程度和模态上遭受信息丢失:SDNet和U2Fusion可以保存MRI图像的细节,而EMFusion在颜色信息上有严重缺陷(第一组和最后一组图像的框架部分)。传统方法保留了强度信息,但遭受了MRI部分变暗的问题(第一和第二组图像的框架部分)。

定量比较
所有方法在指标上的评价结果在表5的右侧显示。所有深度学习方法在六个指标上的表现都是灾难性的,但我们在所有深度学习方法中都取得了最先进的性能。基于实际分析,原因如下:由于SPECT图像的原始分辨率较低,图像在参与融合之前需要上采样。在这个过程中,引入了许多不均匀的像素噪声,而卷积神经网络可以更好地处理它们以产生平滑的结果。在指标计算中,噪声干扰产生了对深度学习方法不利的结果,如EN、SF和AG。我们的方法更好地保留了两种模态的信息,因此在指标上优于其他深度学习方法。
4.7 任务驱动评估
利用融合图像不仅增强了基础视觉观察,而且在提升其后续高级视觉任务的性能方面发挥了关键作用。遗憾的是,大多数现有评估方法主要关注于评估图像质量及相关统计指标。在本节中,我们提倡一种超越传统评估范式局限的任务驱动评估。为了实现这一目标,我们采用了两方面的方法,包括将对象检测和语义分割任务应用于融合图像。这种方法使我们能够比较分析各种红外和可见光图像融合技术对于其后续高级视觉任务的影响。
4.7.1 在对象检测上的评估
对象检测是一个传统且被广泛研究的高级计算机视觉任务。随着多模态数据集的不断发展,其在评估多模态图像融合技术中反映语义信息的能力变得越来越突出。在本小节中,我们重点讨论图像融合对对象检测的影响。
实施细节
我们在最新的M3FD数据集上进行了实验,使用了最先进的检测器YOLOv5。为确保公平比较,我们使用了YOLOv5s模型,并直接将各种方法的融合结果输入检测器进行重新训练。然后我们在相同的随机划分测试集上测试了重新训练的模型。检测器的所有设置遵循原始配置,定量结果由其测试代码直接输出。
定量比较
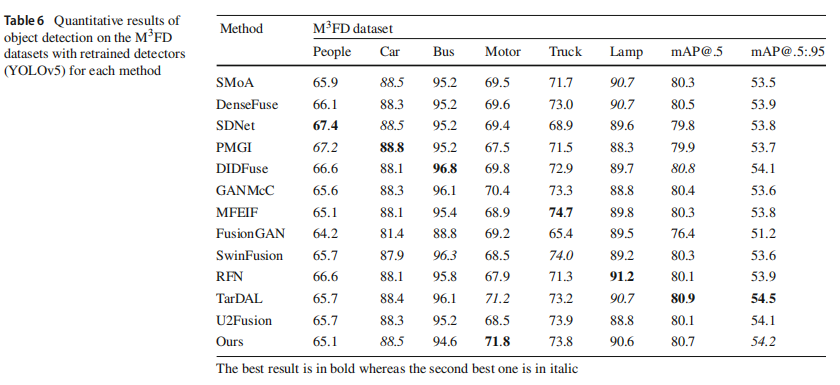
实验获得的定量结果在表6中显示。[email protected]表示当mIoU为0.5时的平均精度均值,[email protected]:.95表示在不同IoU阈值(从0.5到0.95,以0.05为步长)下所有mAP值的平均值,其他值表示相应类别的AP(平均精度)。我们与前面部分相同的基准方法进行了横向比较。在最受关注的指标[email protected]方面,提出的方法并未获得前两名的结果,但表现仍然良好(排名第三)。TarDAL针对对象检测进行了优化,取得了最佳结果,而DIDFuse能够生成融合良好的图像,排名第二。关于更全面的指标[email protected]:.95,它反映了不同IoU下的性能,CoCoNet排名第二,展示了其在常见融合方法中的检测优势。此外,不同方法在各自的类别AP中表现出偏好性。
定性比较
为了说明我们提出的方法在促进下游检测任务方面的优势,我们在图22中提供了两个视觉示例,突出显示了置信度大于0.6的检测结果。场景1展示了阴天条件下的行人检测场景。提出方法的融合结果突出了行人,创造了适合检测网络的高对比度视觉效果,实现了最佳的检测性能。相反,如FusionGAN和U2Fusion之类的方法产生的人形轮廓模糊,导致检测置信度低。场景2展示了驾驶检测场景,更好地反映了融合方法在保留和利用可见信息方面的差异。我们的融合结果在保留丰富的可见信息的同时,实现了最佳的检测性能,满足了这一特殊场景的要求。
对比学习的消融
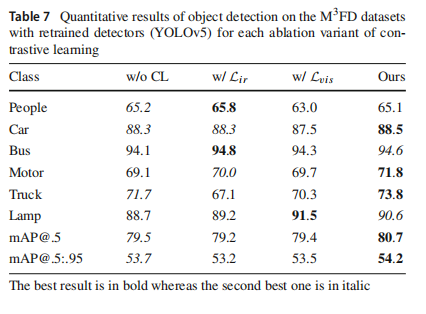
为了进一步研究采用的对比学习对对象检测任务的影响,我们还对三个消融变体(w/o CL:无对比正则化,w/ Lir:仅目标约束,w/ Lvis:仅细节约束)进行了相应的对象检测实验,定量结果如表7所示。在mAP方面,提出的方法具有明显优势,其次是没有对比学习的变体。同时,分别添加对象或细节约束对整体检测结果有负面影响。此外,值得注意的是,仅具有对象约束的变体确实对场景中的显著对象表现出更强的敏感性,因此在人和公共汽车等类别上取得了优秀的APs。然而,仅具有细节约束的变体无法适应后续的检测任务。完整方法通过目标-细节耦合实现了两个约束的优秀整合和利用。
4.7.2 在语义分割上的评估
在评估图像融合技术时,语义分割能够更准确地评估其反映不同语义类别的能力。其像素级分类方法更加强调了语义信息的丰富性和准确性。在本节中,我们重点讨论图像融合对语义分割的影响。
实施细节
我们在MFNet数据集上进行了实验,使用了最先进的语义分割模型SegFormer。为了公平比较,我们加载了预训练的权重mb1,并在所有融合结果上进行了相同次数的微调。MFNet的训练/验证/测试集的划分遵循了源数据集的惯例。
定量比较
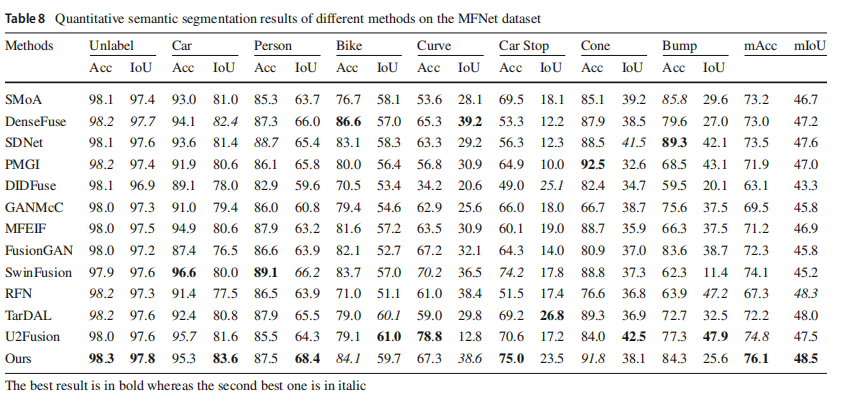
我们使用像素交并比(IoU)和准确度(Acc)来反映分割表达。表8报告了具体的评估结果。可以看出,提出的方法在主要对象类别(即汽车和行人)上实现了最高的IoU,并在mIoU和mAcc上排名第一。我们认为这种优势有两个原因。一方面,我们的融合网络在对比约束下移除了不同模态之间的冗余信息,保留了有助于更好理解整体场景的有用互补信息。另一方面,所提出的MAM有效地将高级网络中的语义特征整合到融合过程中,使得我们的融合图像包含丰富的语义信息。
定性比较
我们在图23中提供了白天和夜晚场景的可视化分割结果。可见光图像在白天能更好地描述显著的大型目标,但会忽略与背景颜色相似的远处行人。相反,红外图像在夜间有效区分行人并支持出色的结果。分割模型在提出方法产生的融合图像上生成了更准确的结果,无论是主要目标还是背景对象,如白天场景中红框内的行人和夜间场景中绿框内的停车车辆。
对比学习的消融
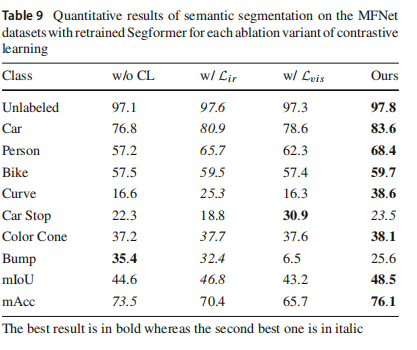
同样,我们还对三个变体(w/o CL、w/ Lir和w/ Lvis)进行了语义分割实验,IoU的定量结果如表9所示。可以看出,没有对比约束的变体整体性能较差。在两个具有单侧约束的变体中,w/ Lir的目标改进了整体分割质量,比w/ Lvis的细节更有益,因为在处理使用的数据集中更多夜间场景时,提取、学习和逼近红外显著内容更为有利。提出的完整对比约束在多个类别和两个平均指标上实现了最佳性能,展示了同时使用两个约束的卓越性能。
4.8 扩展到其他融合任务
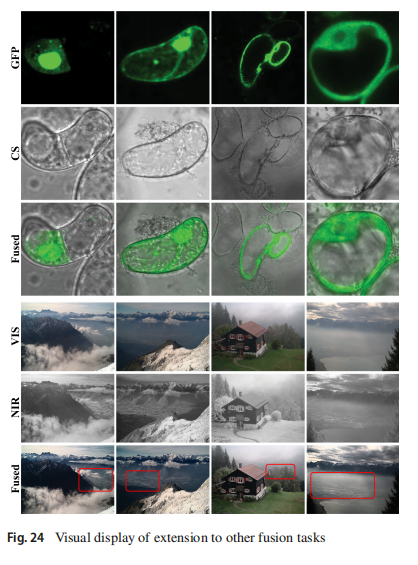
为了展示我们方法的广泛适用性,我们将CoCoNet扩展到处理其他多模态图像融合问题。例如,我们将它应用于绿色荧光蛋白(GFP)和相差(PC)图像的融合,以及近红外(NIR)和可见光(VIS)图像的融合。在GFP和PC图像融合中,GFP代表强度和颜色信息,类似于PET/SPECT图像的角色,而PC代表结构和细节信息,类似于MRI图像的角色。同样,NIR图像提供了丰富的背景信息,而VIS图像提供了清晰的前景内容。因此,所提出的方法能够胜任这些任务。
定性结果在图24中展示,证明了所提出的CoCoNet生成的融合图像具有有希望的视觉结果。具体来说,CoCoNet在保持相差图像的边缘信息的同时,引入了绿色荧光蛋白的颜色信息,且几乎没有退化。在第二个任务中,CoCoNet在保持NIR图像的丰富纹理信息的同时实现了高对比度(详见红框区域的细节)。
关于泛化的进一步讨论
值得注意的是,我们直接在预训练模块上测试了上述所有任务,而没有进行微调,因为它们尚未适用于所提出的耦合对比学习策略。如上所述,GFP和PC图像融合倾向于类似于MRI和PET图像融合,但PC图像缺乏可以提供MRI分割掩膜的信息内容,因为它们主要捕获线条上的梯度细节而不是稍大的像素区域。同时,NIR和VIS图像是来自不同但接近波段的自然图像,具有近似的整体场景特征和纹理信息。它们的模态差异的小幅度为设计适当的掩膜以符合耦合对比学习的限制带来了挑战。我们认为,为了适当地转移和应用CCL到其他图像融合任务,有必要考虑目标多模态图像是否足以生成可解释和有意义的对比学习掩膜。这不仅构成了其泛化能力的关键障碍,而且是确保其有效性的重要前提。我们打算在未来的工作中更深入地研究这个问题,目的是改进CCL并可能提出新的方法。
5 结论
本文提出了一种新颖的对比学习网络,该网络集成了多级特征用于融合红外和可见光图像。我们开发了双重对比约束来保留典型特征,并在融合过程中避免冗余特征。结果上,双重对比约束能够以柔和的方式实现更好的视觉效果,即显著的热目标和丰富忠实的细节。我们还设计了多级注意力机制在我们的网络中,以学习丰富的层次化特征表示和更好的传输集成。此外,设计了自适应权重来克服损失函数中手动权衡权重的限制。定性和定量结果表明,所提出的方法以高效率实现了最先进的性能。此外,消融实验验证了我们方法的有效性。进一步地,我们将CoCoNet扩展到医学图像融合领域,与其他最先进的方法相比,它也能实现卓越的性能。
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理