MNIST手写数据集识别练习:
- MNIST数据集是在进行深度学习分类时最常用的一个数据集,是手写的0-9十个数,图像大小为(1, 28, 28)。
- MNIST数据集都是灰度图所以,通道数为1。
- MNIST数据集大概有7w多张图片(6w训练,1w测试)
这段时间观看b站up主 刘二大人 的关于深度学习的讲解,让我获益匪浅。在网络中添加残差模块,使得测试精度再次提升,下面是视频地址。
https://www.bilibili.com/video/BV1Y7411d7Ys?p=11&share_source=copy_web
下面为相关代码:
文中绘制相关曲线使用的是visdom库,优点是根据运行计算出的损失值,实时的进行绘制。
visdom的安装和使用可以浏览下列连接的博客。
https://blog.csdn.net/qq_42962681/article/details/116271548
为了能更加了解网络的结构和参数的传递,标记了大量的注释。
import torch
import torch.nn as nn
from torch.utils.data import DataLoader # 我们要加载数据集的
from torchvision import transforms # 数据的原始处理
from torchvision import datasets # pytorch十分贴心的为我们直接准备了这个数据集
import torch.nn.functional as F # 激活函数
import torch.optim as optim
import time
import visdom
batch_size = 64
# 我们拿到的图片是pillow,我们要把他转换成模型里能训练的tensor也就是张量的格式
# transform = transforms.Compose([transforms.ToTensor()])
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # 你均值和方差都只传入一个参数,就报错了.
# 这个函数的功能是把输入图片数据转化为给定均值和方差的高斯分布,使模型更容易收敛。图片数据是r,g,b格式,对应r,g,b三个通道数据都要转换。
])
# 加载训练集,pytorch十分贴心的为我们直接准备了这个数据集,注意,即使你没有下载这个数据集
# 在函数中输入download=True,他在运行到这里的时候发现你给的路径没有,就自动下载
train_dataset = datasets.MNIST(root='../datasets/fashion-mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size)
# 同样的方式加载一下测试集
test_dataset = datasets.MNIST(root='../datasets/fashion-mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(dataset=test_dataset, shuffle=False, batch_size=batch_size)
#为了使预测精度更高,我在这里添加了残差网络模块
# 残差网络示意
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
#这里输入通道与输出通道相等,且经过kernel=3的卷积核,由于w,h填充1,所以图像尺寸不变
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 定义了我们第一个要用到的卷积层,因为图片输入通道为1,第一个参数就是1
# 输出的通道为16,kernel_size是卷积核的大小,这里定义的是5x5的
# 我们输入的图像为[64,1,28,28]通过卷积层后为[64,1,24,24]
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
# 看懂了上面的定义,下面这个你肯定也能看懂
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
# 再定义一个池化层
self.mp = nn.MaxPool2d(2)
# 调用残差网络
# 输入残差网络中不改变图像尺寸大小,只改变维度
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
# 最后是我们做分类用的线性层
self.fc = nn.Linear(512, 10)
# 下面就是计算的过程
def forward(self, x):
# 输入的x尺寸 (64, 1, 28, 28)
batch_size = x.size(0) # 这里面的0是x大小第1个参数,自动获取batch大小
#经过卷积层后(64, 16,24, 24)再经过最大池化(64, 16,12, 12)
x = F.relu(self.mp(self.conv1(x)))
#经过残差网络通道和图像尺寸不变还是(64, 16,12, 12)
x = self.rblock1(x)
#经过卷积层后(64, 32,8, 8)再经过最大池化(64, 32,4, 4)
x = F.relu((self.mp(self.conv2(x))))
经过残差网络通道和图像尺寸不变
x = self.rblock2(x)
# 为了给我们最后一个全连接的线性层用(64,32*4*4)
x = x.view(batch_size, -1) # flatten
# 经过线性层,确定他是0~9每一个数的概率
#全连接层后(64,32*4*4)变为(64,10)
x = self.fc(x)
return x
model = Net() # 实例化模型
# 把计算迁移到GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
# 定义一个损失函数,来计算我们模型输出的值和标准值的差距
criterion = nn.CrossEntropyLoss()
# 定义一个优化器,训练模型咋训练的,就靠这个,他会反向的更改相应层的权重
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.5) # lr为学习率
# 全局运行步数
global_step = 0.0
global_step2 = 0.0
# 为训练添加环境变量,之后程序产生的所有数据都会出现在这个环境变量中,visdom就可以监听数据实现可视化
# 而且在visdom中还可以按照环境变量名选择性监听,便于分类管理
viz = visdom.Visdom(env='train-mnist')
# 创建线图初始点。loss是差值图,acc是精度图
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([0.], [0.], win='acc', opts=dict(title='test acc'))
# 设置迭代次数
epochs = 2
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader, 0):
data, target = data.to(device), target.to(device)
logits = model(data)
loss = criterion(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
total = 0.0
correct = 0.0
test_loss = 0.0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
outputs = model(data)
test_loss += criterion(outputs, target).item()
# test_loss /= len(test_loader.dataset)
# 我们取概率最大的那个数作为输出
_, pred = torch.max(outputs.data, dim=1)
total += target.size(0)
# 计算正确率
correct += (pred == target).sum().item()
global_step2 = global_step2 + 1
acc = correct / total
# 打印训练周期数epoch,预测差值loss,精度acc
# 精度可视化显示
viz.line([acc], [global_step2], win='acc', update='append')
# 再加载一次测试集,用于可视化输出每次预测的结果
x, label = iter(test_loader).next()
viz.images(x, nrow=16, win='test_x', opts=dict(title='test_x'))
x, label = x.to(device), label.to(device)
pred = model(x).argmax(dim=1)
# 可视化显示预测
viz.text(str(pred.detach().cpu().numpy()), win='predicted label', opts=dict(title='predicted label'))
# 可视化显示真实值
viz.text(str(label.detach().cpu().numpy()), win='groundtruth label', opts=dict(title='groundtruth label'))
test_loss /= len(test_loader.dataset)
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
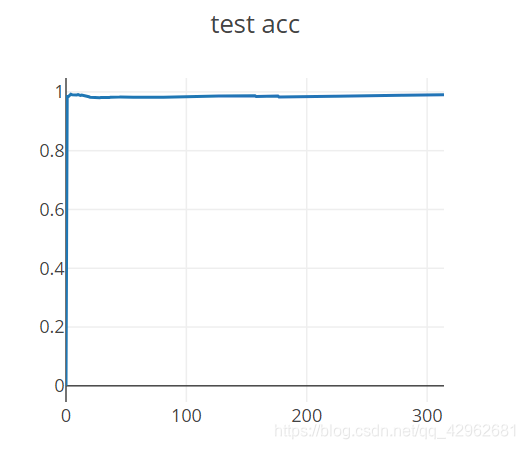
这里为测试的准确度,已经达到了99%的准确率,效果已经比较好了,并且网络只迭代了两次
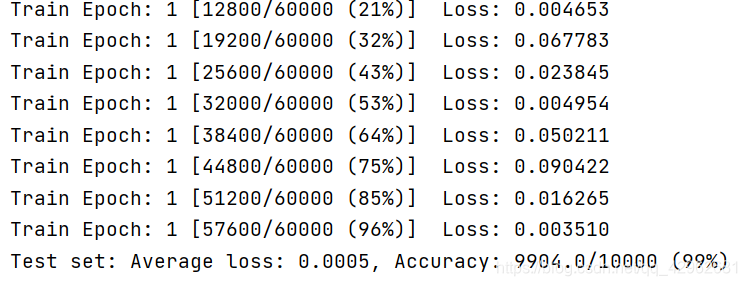
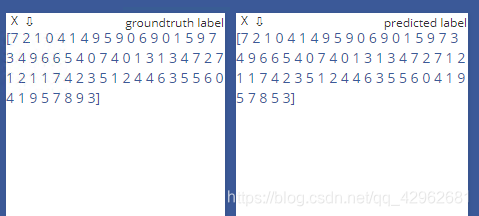
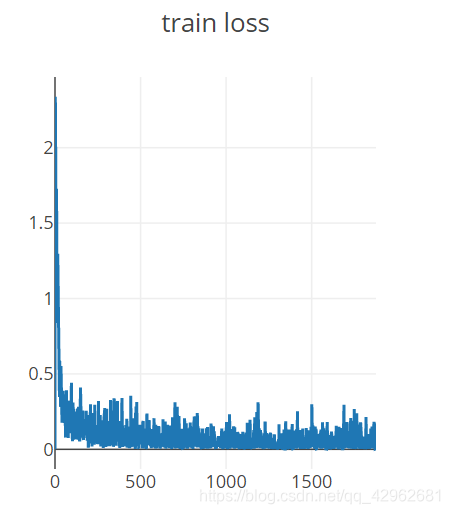
visdom绘制的结果示意:
这是测试时的结果,左侧为标签数值,右侧是通过网络的预测值,通过对比可以看出我们的网络精度还是比较高的。
这是训练的损失函数,这里取得是单独的batch的损失进行绘制,而不是使用迭代次数epoch
这是测量的精度
遇到的问题:
使用visdom.images()命令显示图片时,不能成功显示。也查询了很多方法没能解决,有了解的朋友,希望可以告知。共同进步!