python找出Excel文件大于2048个字符长度的数据
需求:在一份Excel文件上找出它每个列中字符长度大于2048的内容并把该对应内容的第一个、第二个列数据打印出来和大于2048列的内容
python代码实现
import pandas as pd
import time
start_time = time.time()
print("程序开始时间:", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(start_time)))
def check_row_length(excel_file):
df = pd.read_excel(excel_file)
any_cell_exceeds = False
for index, row in df.iterrows():
for col_name, cell in row.items():
if len(str(cell)) > 2048:
any_cell_exceeds = True
first_col_name = df.columns[0]
second_col_name = df.columns[1]
first_col_value = row[first_col_name]
second_col_value = row[second_col_name]
print(f"\033[91m行索引: {index + 1}, 超过2048字符长度的列名: {col_name}, 单元格长度: {len(str(cell))}\033[0m")
print(f"第一列: {first_col_name}, 第一列值: {first_col_value}")
print(f"第二列: {second_col_name}, 第二列值: {second_col_value}")
print(f"超过 2048 字符的数据内容: {cell}\n")
if not any_cell_exceeds:
print("没有单元格长度超过 2048 字符。")
check_row_length('FamilyComplaintsGx20241127085330947.xlsx')
end_time = time.time()
print("程序结束时间:", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(end_time)))
run_time = end_time - start_time
print("程序运行耗时:%0.2f" % run_time, "s")
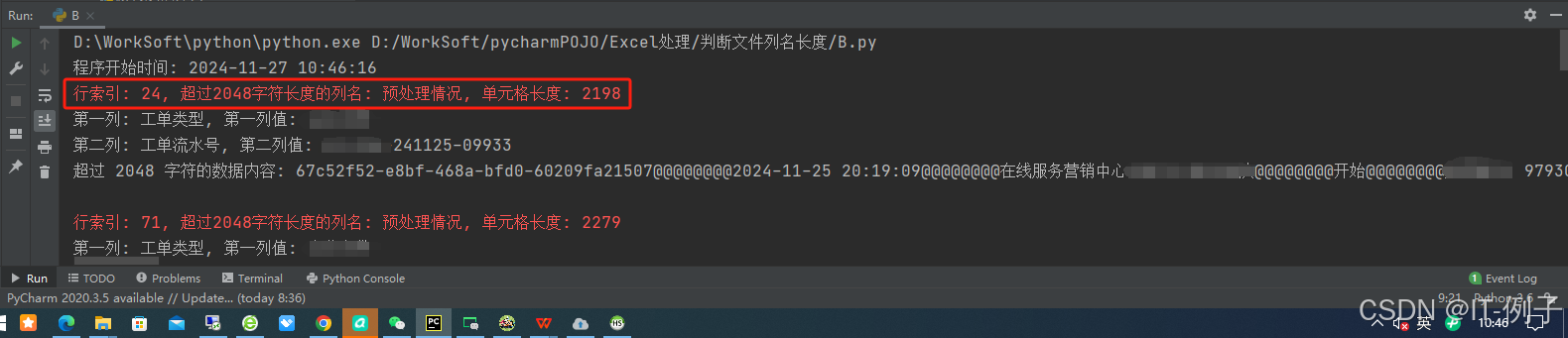
运行截图效果