Go工程基础
前言
记录Go工程基础知识。
一、Go 包管理
go有三类型的包,
- 标准库的包,在go程序中可以直接使用。
- 用户自定义包,开发者自行引用。
- 第三方包,非标准库/非自定义包,而是第三者开发并分享到开源仓库的包,开发者可以通过包管理工具进行下载和安装。
所以,包管理就是用来管理项目对第三方包的依赖关系。
1、技术演进
包管理技术的演进过程,
- go path
项目的目录结构如下,
| 文件夹 | 作用 |
|---|---|
| src | 存项目源码 |
| pkg | 存项目编译的中间产物 |
| bin | 存项目编译的二进制文件 |
所有项目的包都存在src下,当两个项目依赖同一个包的不同版本时,两个项目都是无法通过编译的,因为src不允许同时存在一个包的两个版本。
- go vendor
所有项目的依赖包存入src文件中,才出现了项目无法编译通过的问题,所以为每个项目独立开辟一个“src”这样的包文件,两个项目所依赖同一个包的不同版本就会出现在不同的“src”中,就不会出现冲突导致无法通过编译。这里的“src”就是vendor子目录。
注:如果当前项目存在vendor目录,会优先使用该目录下的依赖,如果该目录下没有,则会从go path中寻找。
问题所在,vendor子目录也是不允许同时放一个包的两个版本,但是存在项目不同包用到了同一个第三方包的不同版本,此时项目无法通过编译。 - go module
- go mod组成的四部分,
| 配置/工具 | 作用 |
|---|---|
| go get/go mod | 通过下载、更新等方式管理依赖包 |
| go.mod 文件 | 管理依赖包版本 |
| go.sum 文件 | 校验哈希值防止包被篡改 |
| 环境变量 | 控制开关及私有化设置 |
注:在 Go 1.16 之前,go get可以用来下载、更新和安装第三方库,包括二进制文件;在 Go 1.16 之后,go get 只用来修改 go.mod 文件的依赖项,并下载到 $GOPATH/pkg/mod 目
录下。编译和安装的工作则交给go install完成。
2、go mod
- go mod相关命令,如下,
| Go Mod 命令 | 作用 |
|---|---|
| go mod init | 生成go.mod文件 |
| go mod download | 下载go.mod文件中指明的所有依赖 |
| go mod tidy | 整理现有的依赖,增加需要的依赖,删除不需要的依赖(因为迭代) |
| go mod graph | 查看现有的依赖结构 |
| go mod edit | 编辑go.mod文件 |
| go mod vendor | 导出项目所有依赖到vendor文件中 |
| go mod verify | 检验一个模块是否被篡改过 |
| go mod why | 查看为什么需要依赖某模块 |
- Go mod环境变量,
| 变量名 | 作用 | 可选值 | 私有化仓库设置 |
|---|---|---|---|
| GO111MODULE | go module是否启用的开关 | auto:有mod文件就启用; on:启用; off:禁用; | 一般为on,有些旧项目或分支会设置成auto |
| GOPROXY | 设置go模块下载的代理 | https://proxy.golang.org, https://goproxy.cn, https://mirrors.aliyun.com/goproxy/, direct(源站) | https://mirrors.company.cn/go |
| GONOPROXY | 不需要代理的模块,配合私有仓库。 | 通常跟随GOPRIVATE的值 | / |
| GOSUMDB | 设置go checksum database的地址,保证模块没有被篡改 | sum.golang.org off : 关闭 | off |
| GONOSUMDB | 不用校验的模块,配合私有仓库 | 通过跟随GOPRIVATE的值 | / |
| GOPRIVATE | 设置私有仓库地址或者匹配规则 | / | https://git.company.com/private |
- go mod 文件结构,
1.module 路径,表示module
2.go 版本号
3.依赖项:用module路径 + 版本号来唯一标识。
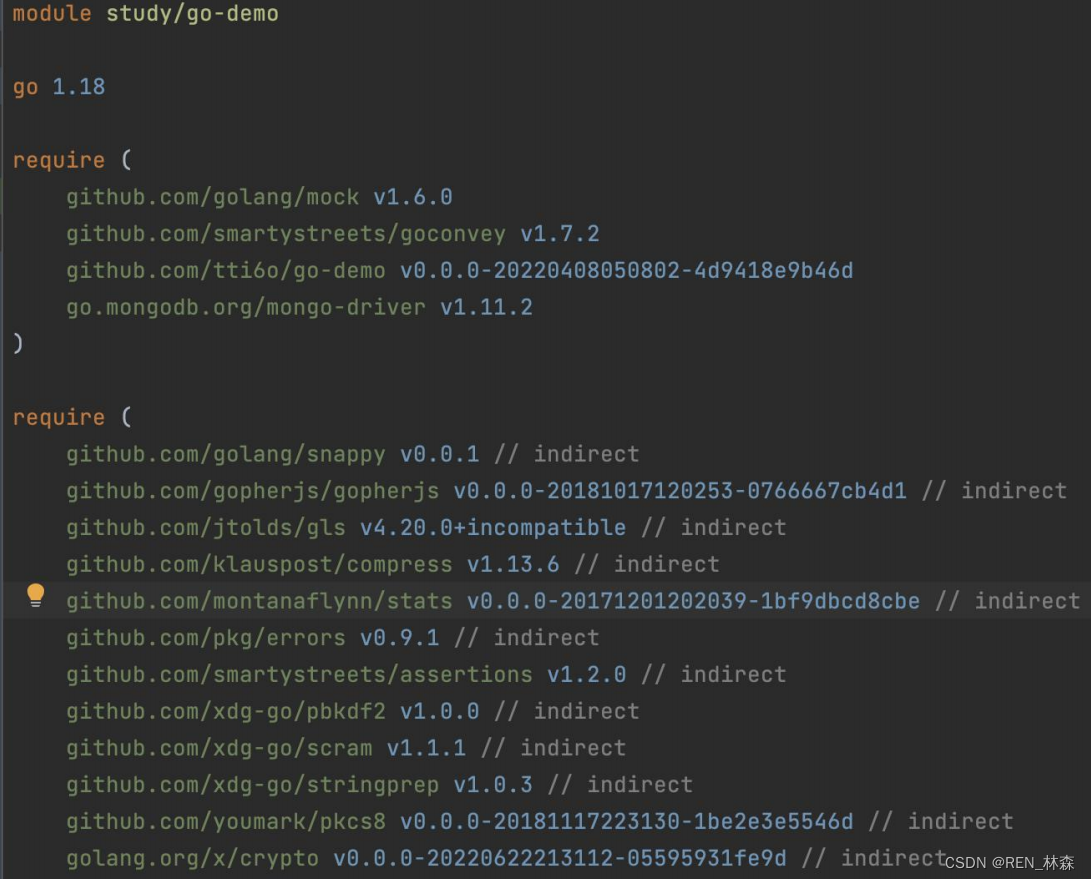
| 关键字 | 作用 |
|---|---|
| require | 项目所依赖项模块,带有indirect注释代表非直接依赖。 |
| replace | 可替换依赖项模块,用于解决一些依赖包无法拉取,或者需要使用本地或远程修改过的模块。 |
| exclude | 可忽略依赖项模块,用于避免一些有问题或者不兼容的依赖包版本。 |
- 依赖版本号,
- 语义化版本,清晰、简洁、一致的版本号约定,使开发者和用户能够更好地理解软件版本之间的差异和兼容性。major.minor.patch-pre-release+metadata
| 类别 | 含义 | 示例 |
|---|---|---|
| 主版本号(major) | 1.不兼容的API修改时需要更新 2.major>1时还可以体现在模块路径中避免兼容性问题 | v.9.0.2 module路径:https://github.com/redis/go-redis/tree/v9 |
| 次版本号(minor) | 向下兼容的新功能增加时 | v1.1.0 |
| 修订号(patch) | 向下兼容的问题修正时 | v1.0.1 |
| 预发布标识符(pre-release) | 表示预发布版本(如alpha、beta、rc等) | v1.0.0-alpha |
| 元数据(meta-data) | 表示与版本相关的附加信息 | v1.0.0+build-123 |
- 伪版本,当依赖包的仓库中没有任何语义化版本使用伪版本,v0.0.0-yyyymmddhhmmss-abcdefabcdef
| 类别 | 含义 | 示例 |
|---|---|---|
| yyyymmddhhmmss | 提交时间戳(年月日时分秒) | 20220622213112 |
| abcdefabcdef | 提交哈希值 | 05595931fe9d |
- 私有库版本,版本号:v1.0.0-company
- go sum文件
go.sum文件记录了当前项目所有模块版本和哈希值,包括直接或间接依赖的。哈希值用于检测依赖包是否被篡改。
go.sum文件中每行记录由 module名、版本和哈希组成。
第一个hash 是 Go modules 将目标模块版本的 zip 文件解压缩后,针对所有包内文件依次进行 hash,然后再把它们的 hash 结果按照固定格式和算法组成总的 hash 值。
第二个hash,仅仅是把go.mod文件进行hash。
第二个hash必然存在,当 Go认为肯定用不到某个模块版本的时候就会省略第一
个hash

二、Go测试
控制软件复杂性的有效手段,即代码评审+测试。
1、单元测试
在Go中,测试文件以后缀名_test.go结尾。
单元测试是通过编写测试函数来实现的,这些函数以“Test”开头,并接受一个“*testing.T”类型的参数,
它提供了许多有用的断言函数,例如“t.Errorf”和“t.Fatalf”,用来输出不符合预期的异常情况。
通过“go test -v -run FuncName”命令来运行这些测试函数,该命令将自动查找和运行测试函数并生成测试报告
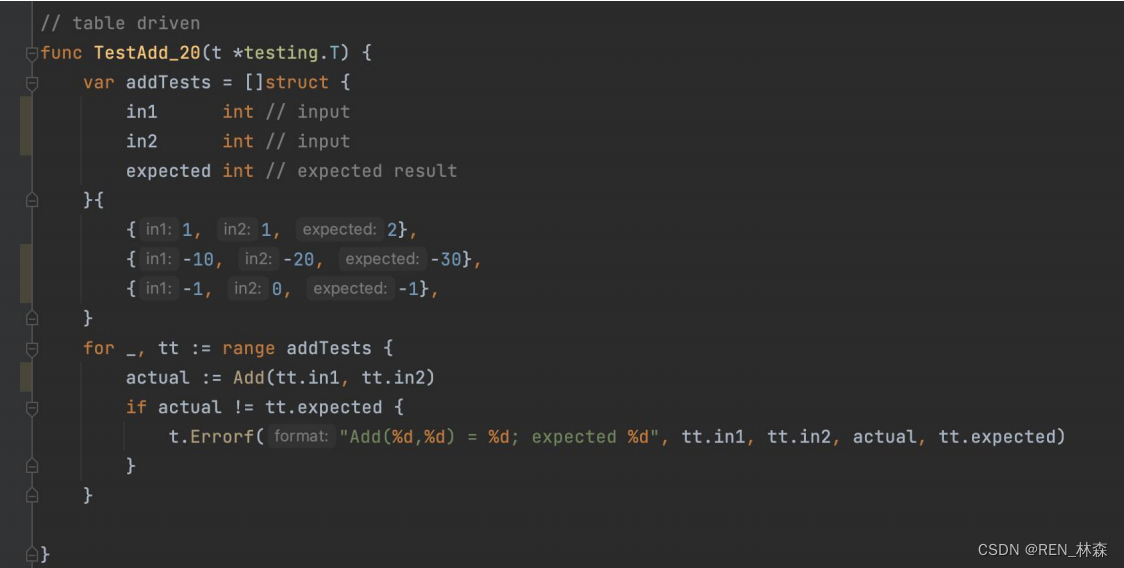
- 表驱动写法
让你的测试代码更简洁,也可以让你更容易地添加新的测试用例。
- 测试覆盖率
对程序的测试程度一般通过测试覆盖率来衡量,通常指代码行数、分支数、函数数等统计数据中被测试用例覆盖到的比例。
在运行“go test”命令时,可以使用“-cover”选项输出测试覆盖率。
如果需要显示详细的测试覆盖率报告,可以通过下面的方式,
go test -coverprofile=c.out
go tool cover -html=c.out
2、测试框架
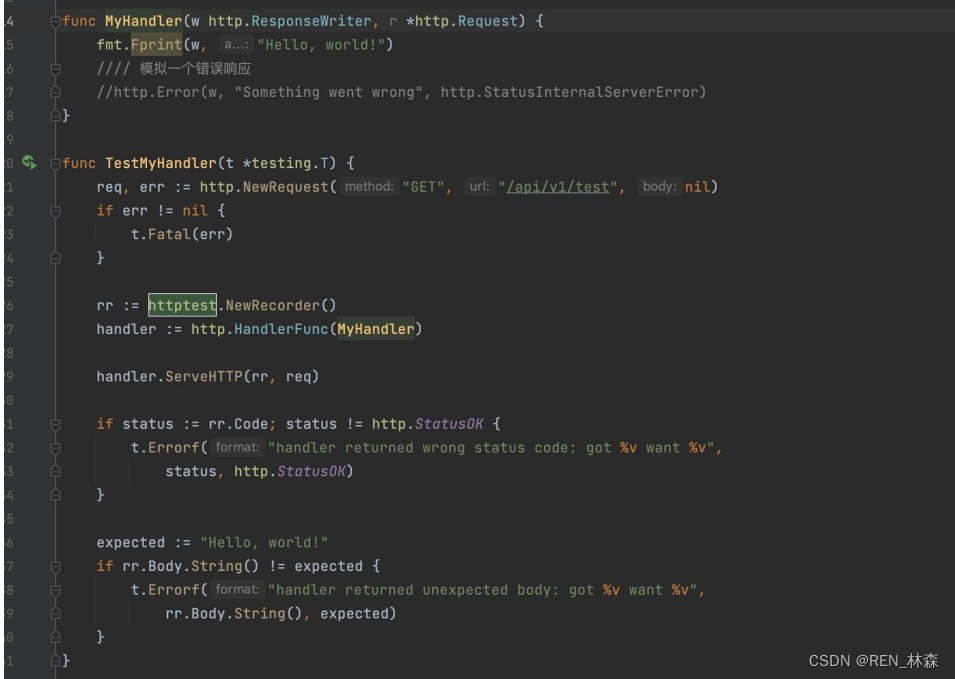
- HttpTest,http自带。
针对 http 开发的场景,可以使用httptest包轻松地编写HTTP单元测试,它可以模拟请求和响应,而不需要实际连接到远程HTTP服务器。
使用httptest.NewRecorder()来测试服务器的HTTP响应。
httptest.NewRecorder()是一个实现了http.ResponseWriter接口的类型,可以用来记录处理器写入响应的数据,并在测试中进行检查。
你可以使用它来创建一个响应记录器,并将其传递给你的处理器函数,然后从记录器中获取响应结果并与预期输出进行比较。
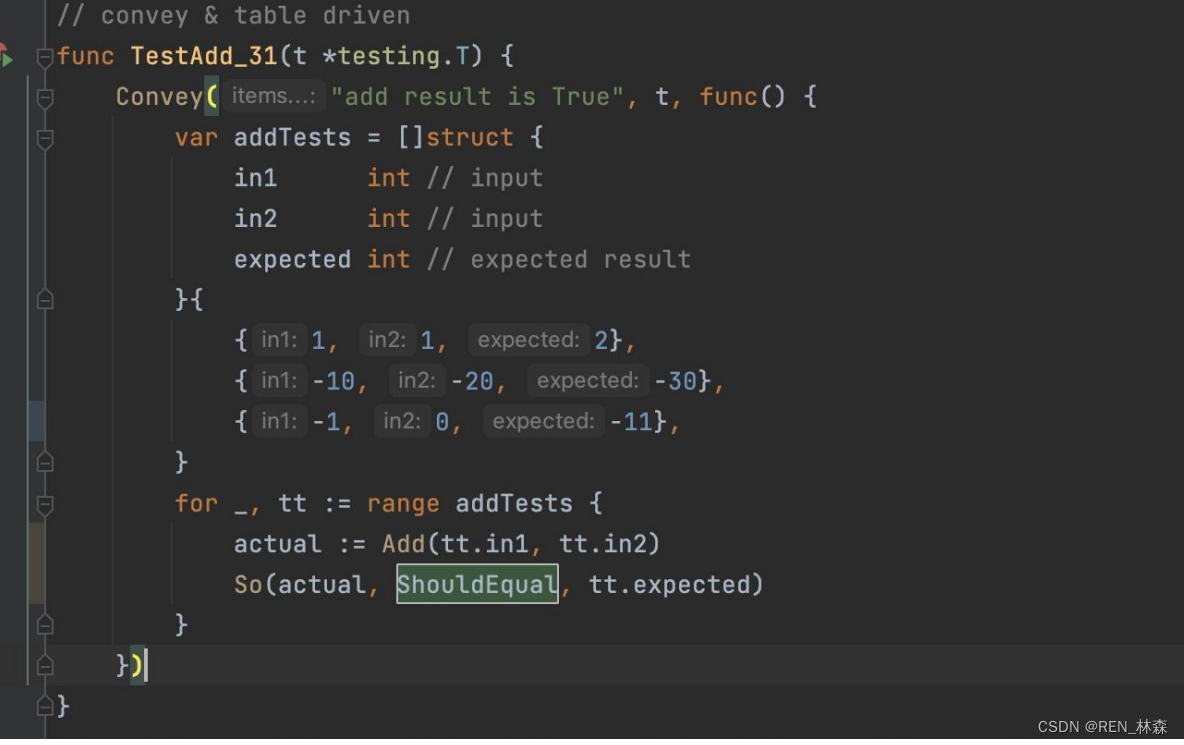
- Convey
Convey是Go语言中的一种测试框架,它可以用于编写可读性强、可维护性强的测试代码。
Convey可以在测试代码中使用自然语言来表达测试条件和结果,并提供了一组易于使用的API,用于编写测试代码。
使用ShouldEqual函数检查两个值是否相等
使用ShouldNotBeNil函数检查值是否不为空
使用ShouldPanicWith函数检查代码是否会抛出异常等
Convey()函数用于描述测试的上下文,例如测试的功能或特性
So()函数用于描述测试的条件和结果,并在测试失败时提供详细的错误信息
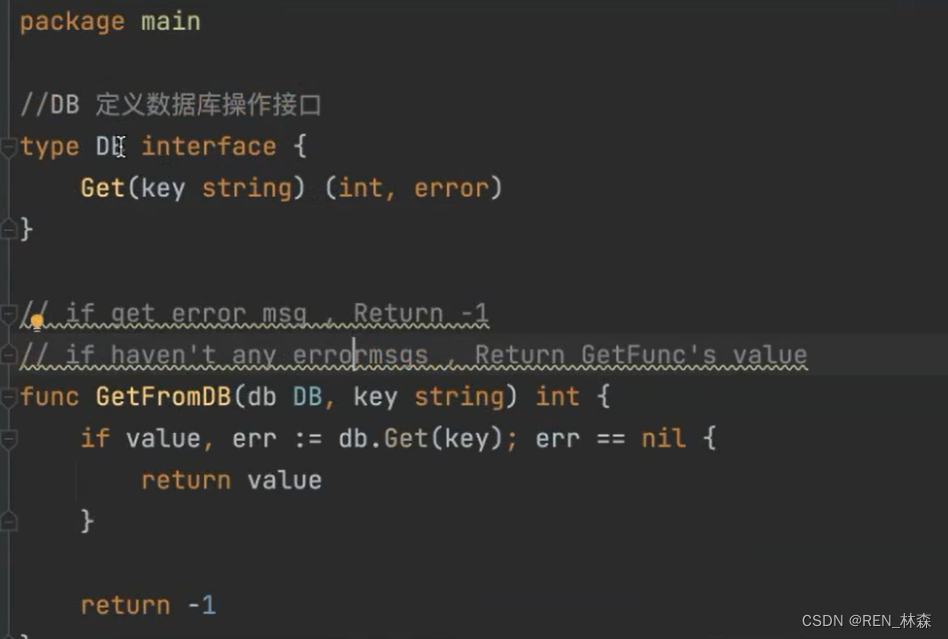
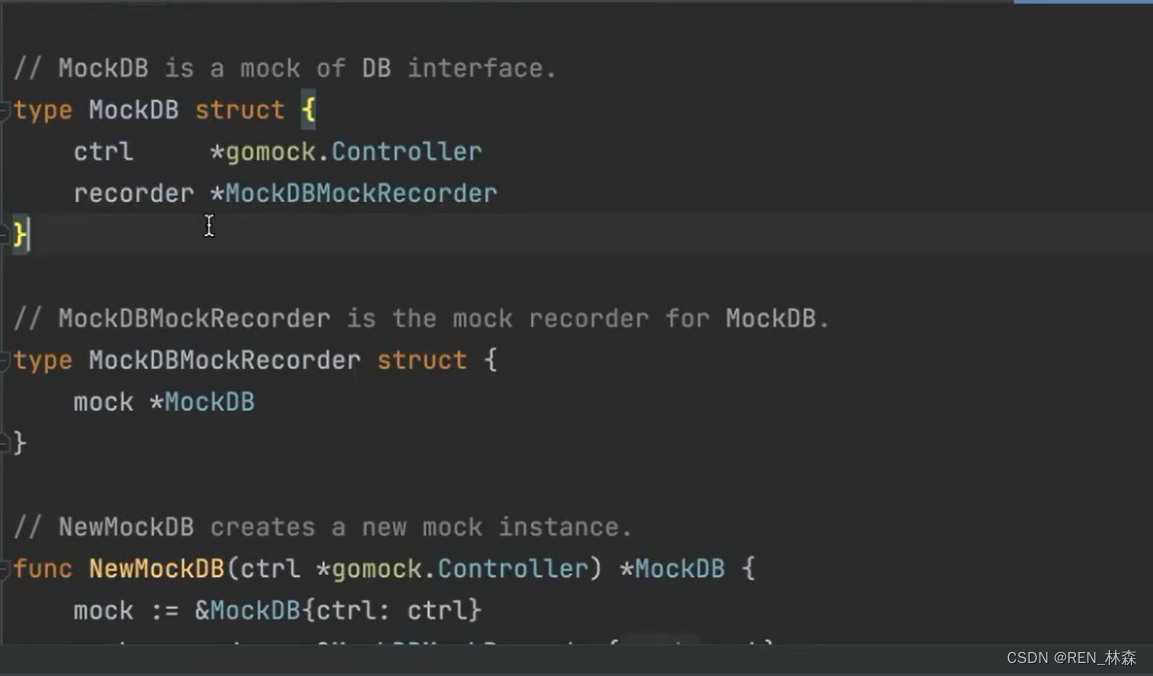
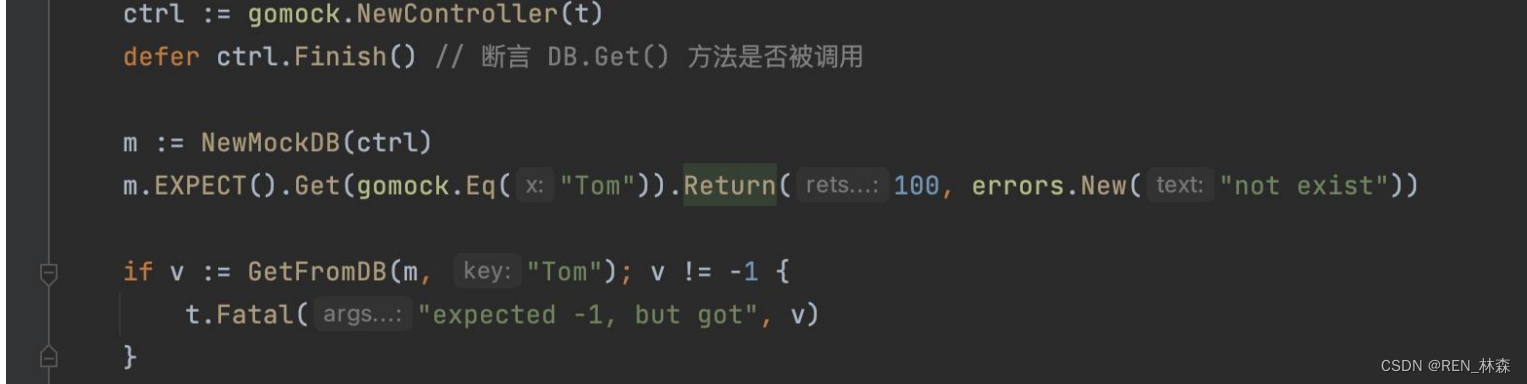
- GoMock
对于外部依赖的情况,我们往往采用两种办法来解决,一种是Mock(模拟) ,一种是Stub(桩)。
Mock:是模拟的意思,指的是在测试包中创建一个对象,满足某个外部依赖的接口 interface{}。
Stub: 是桩的意思,指的是在测试包中创建一个模拟方法,用于替换生成代码中的方法。
| 区别项 | Mock | Stub |
|---|---|---|
| 实现原理不同 | 替换的是实现接口的对象 | 替换的是方法 |
| 侵入性不同 | mock没有侵入性 | stub的侵入性比较强 |
| 实现复杂度 | mock复杂度高,需要提前实现各个对象 | stub一个函数即可,更灵活 |
gomock 是基于 interface 的 mock 工具,可以为 interface 生成 mock 对象,并对其行为进行预设和验证。
gomock包含:gomock库和辅助代码生成工具mockgenmockgen的安装及使用
go install github.com/golang/mock/[email protected]
mockgen -source=db.go -destination=db_mock.go -package=main
| 类别 | 用法 | 说明 |
|---|---|---|
| 参数 | Eq(value) | 表示与 value 等价的值 |
| - | Any() | 可以用来表示任意的入参 |
| - | Not(value) | 用来表示非 value 以外的值 |
| - | Nil() | 表示 None 值 |
| 返回值 | Return | 返回确定的值 |
| - | Do | Mock 方法被调用时,要执行的操作,忽略返回值 |
| - | DoAndReturn | 可以动态地控制返回值 |
| 调用次数 | Times() | 断言 Mock 方法被调用的次数 |
| - | MaxTimes() | 最大次数 |
| - | MinTimes() | 最小次数 |
| -AnyTimes() | 任意次数(包括 0 次) | |
| 调用顺序 | InOrder | 控制预设行为的执行顺序 |

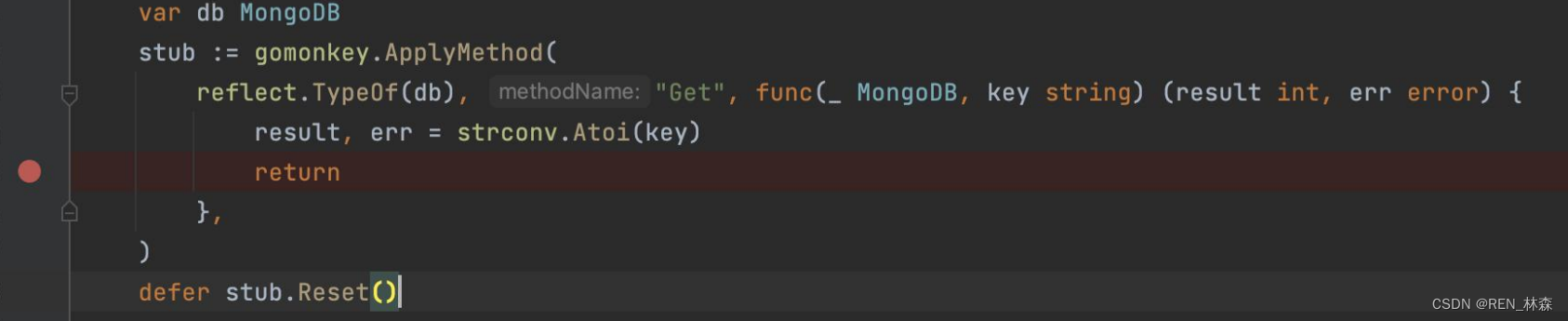
- GoMonkey
gomonkey 是 golang 的一款打桩框架,目标是让用户在单元测试中低成本的完成打桩,从而将精力聚焦于业务功能的开发。
它不仅可以为函数/接口打桩,也可以为全局变量、私有成员方法、结构体成员方法等打桩。
具体使用
ApplyFunc:为函数打桩。
ApplyMethod:为结构体成员方法打桩。
ApplyGlobalVar:为全局变量打桩
ApplyPrivateFunc:为私有函数打桩
ApplyPrivateMethod:为私有成员方法打桩
3、基准测试
a.基本概念
基准测试是测量一个程序在固定工作负载下的性能的方法。
基准测试叫基准测试,是因为它需要选定一个或多个基准,作为测试的参照物。
基准可以是某个程序或系统的性能指标,也可以是某个行业或领域的标准。
基准测试就是通过对比不同程序或系统与基准之间的差异,来评估其优劣和改进方向。
基准测试可以帮助我们优化程序性能,比较不同算法或实现方式的效率,发现程序中存在的性能瓶颈或内存泄漏等问题。
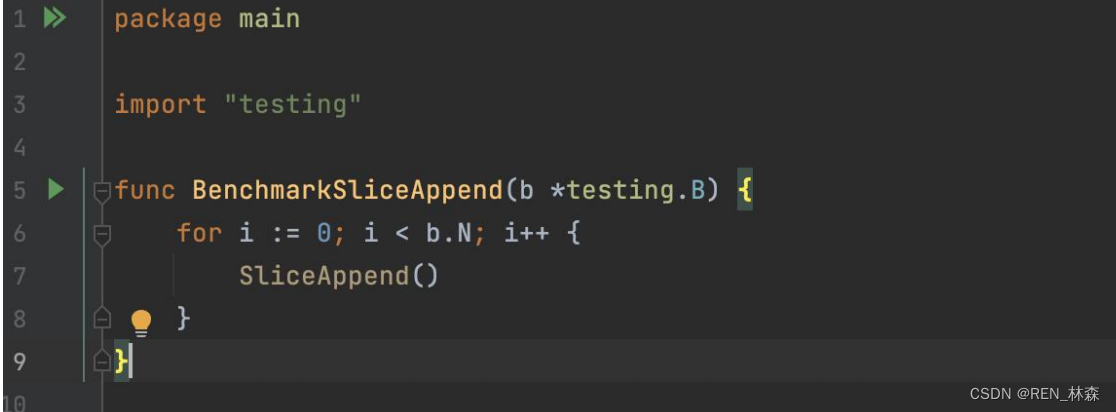
b.编写基准测试函数
基准测试函数和普通测试函数写法类似,但是以Benchmark为前缀名,并且带有一个*testing.B类型的参数。
testing.B参数除了提供和testing.T类似的方法,还有额外一些和性能测量相关的方法,它还提供了一个整数N用于指定操作执行的循环次数。
c.运行基准测试函数
运行基准测试需要使用go test命令,并加上-bench=表达式,用来匹配基准测试的函数。
重要指标
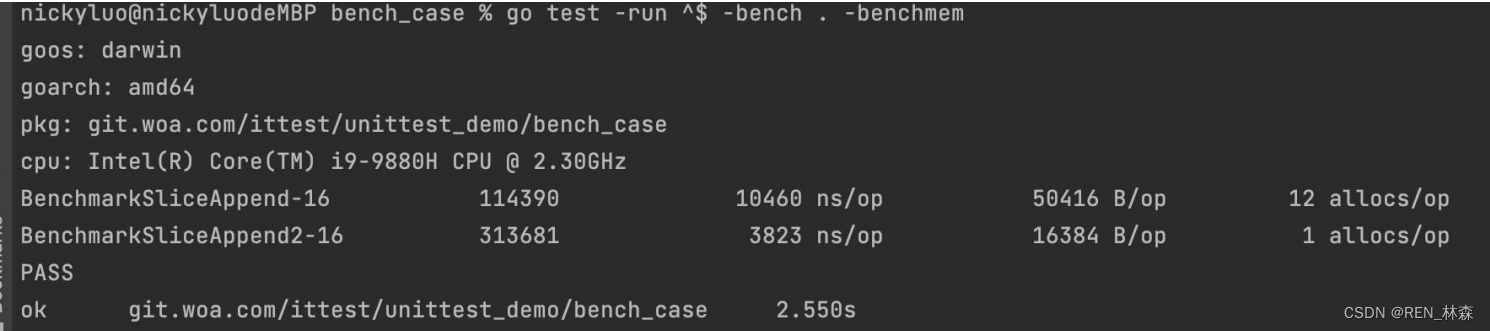
- 每次操作执行的平均时间(ns/op)
- 每次操作分配的内存字节数(B/op)
- 分配对象的次数(allocs/op)
d.基准测试样例演示
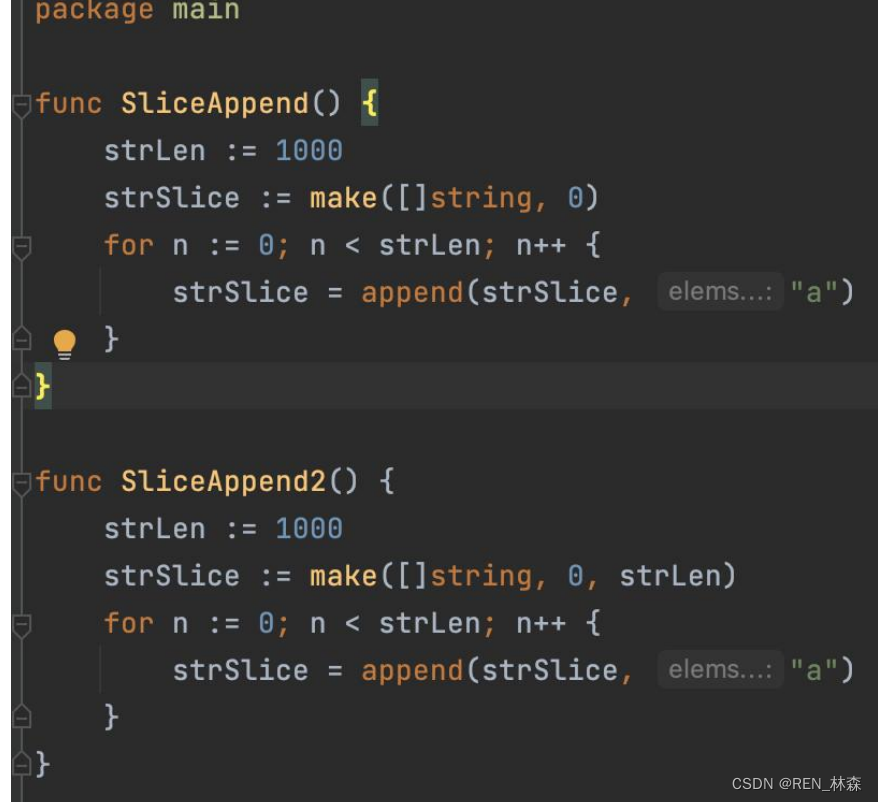
三、编码规范
- 命名规范,
- 普通变量,在尽量表达上下文(配合注释把上下文解释清楚)的时候,让变量更短;或者常识标识符,如for中的i而不是index;
- 函数变量,尽量表达上下文的同时让标识符变短,注意不要上下文重复,比如包已经包含信息了,毕竟包和函数成对出现。如http.Serve(),而不是http.ServeHTTP().
- package,尽量表达上下文的同时让标识符更短,注意不要和标准库同名,同时只用小写字母来标识。
1.不使用常用变量名,如bufio而不是buf;
2.使用单数而不是复数,除法冲突,如encoding,而不是encodings;
3.谨慎使用缩写,除法该缩写不破坏上下文,比如fmt就是format的缩写。
小结:核心目的就是提高代码可阅读性,方便维护和debug。所以命名在考虑上下文的基础上来做到尽量简短,做不到的可以配合注释来提高代码阅读性,降低阅读成本。
- 控制流程,
- 避免嵌套,利用return立刻返回的特点,减少else,让流程更线性,让代码更加易读。
- 特殊情况先行,比如错误处理/continue/break的情况,先提前表达让其先行,剩下的主代码保持最小缩减,保持函数的逻辑清晰性。
小结:提高代码的阅读性,才能提高代码的可维护性和降低debug成本(故障大多出现在复杂的嵌套或循环语句中)。所以保持逻辑的线性原理,让其走直线,避免复杂嵌套,保持代码的逻辑简洁性,而非复杂。
- 错误和异常处理
- 简单错误,仅出现一次的错误,且在其它地方不需要捕获该错误。优先使用error.New(string),如有格式要求,使用fmt.Errorf()
- 错误的wrap和unwrap,包装返回的error,形成一个error跟踪链,采用fmt.Errorf(string,error),%w + err来将当前错误关联其中。
- 错误判定,判定返回的错误是否为一个特定错误,使用error.Is(error,错误类型),比‘==’号的功能强大,可以判定错误链中是否包含指定错误。
- 错误获取,从错误链中获取特定种类的错误,使用error.As(error,错误类型接收变量),可获取特定类型错误的全部信息。
- panic,导致业务代码直接奔溃,如果该调用函数没有采用recover的话。能error则尽量error,必须panic终止程序,就panic,比如数据库都连不上,直接panic。一般在init和main中panic。
- recover,只能在defer的函数中启用,嵌套无法生效,当前goroutine生效。在recover后可log记录当前调用栈,记录更多上下文信息。
debug.Stack();err := fmt.Errorf("%v\n%s",recover的结果,debug.Stack());
小结:error尽可能提供简明的上下文信息,方便定位bug;panic用于异常;recover用于捕获panic,生效范围只在当前goroutine的被defer的函数中生效。
四、性能优化与实战
1、常见性能优化
- Benchmark,该工具可测函数单次运行时间,分配内存,分配次数等,
go test -bench=. -benchmem - slice,尽量使用make()初始化切片时提供的容量信息,扩容会浪费时间。注意多个slice可公用一个底层数组,所以尽量从copy,第一防止操作错误,第二方式小slice引用大array,内存得不到释放。
- Map,同理发生扩容带来的内容拷贝和rehash操作,可以预估一下需要的空间。
- strings.Builder,string是固定的,每次拼接会产生新字符串。同时可以用Grow(int)来分配底层byte数组的长度。和slice通用的扩容道理。
- 空结构体,节省内存,其不占任何内存空间,作为一个占位符。
- atomic包,atomic.AddInt32()这些方法比sync.Mutex加锁性能好的多。atomic是通过硬件实现,Mutex是操作系统实现,所以atomic效率高。Mutex应该将一段分散的逻辑变为原子逻辑,保护变量实在很亏。对于非数值操作,可以使用atomic.Value,能承载一个interface{}
小结:性能陷阱+内存陷阱,但普通的代码不要一味的追求程序的性能,越高级的优化手段越容易出现问题,也越复杂难理解,满足正确可靠、简洁清晰的质量要求的前提下来提高程序性能。
常见优化手段,
- 串行改并行
- 减少大量对象创建
- 锁尽早释放,降低锁粒度
- 同步调用改异步调用
- JSON序列化使用第三方库代替系统库
- sync.Pool进行堆对象分配的重用
- 多个小对象合成1个大对象
- 合并对象数,指针对象变成值对象(不需要gc去扫描了)
- 善用空结构
- 尝试降低gc频率以提高整体性能
- unsafe转换例如:string和[]byte互相转
2、性能调优实战
- 原则,
- 要依靠数据而不是猜测,环境和一些细节和我们想象的不一样。
- 要定位最大瓶颈而不是细枝末节。
- 不要过早优化,迭代快,各个阶段情况不一样,甚至有废掉的API。
- 不要过度优化,越复杂越能出问题,而且不便于维护,而且迭代快,优化手段是否能够兼容。
- pprof分析工具
什么地方耗费了多少CPU、Memory,pprof可以可视化这些数据。
总结
1)Go的包管理演进,以及Go mod的使用。
2)单元测试、Mock测试、基准测试。
3)常见性能优化