前言
万字长文,欢迎指正。
Excel作为我们在日常工作中使用的工具,用途广泛且功能强大。本文简单介绍使用openpyxl操作Excel。
官方文档地址:https://openpyxl.readthedocs.io/en/stable/#
一、openpyxl是什么?
openpyxl是一个Python库,用于读取/写入 Excel 2010 xlsx/xlsm/xltx/xltm 文件。基于PHPExcel。
注意:openpyxl不支持xls文件!!!
默认情况下,openpyxl不防范XML攻击,建议使用defusedxml软件包进行防范。
defusedxml 是纯Python软件包,带有所有stdlib XML解析器的修改后的子类,可防止任何潜在的恶意操作。建议对解析不受信任的XML数据的任何服务器代码使用此包。该软件包还附带示例漏洞利用程序和有关更多XML漏洞利用程序的扩展文档,例如XPath注入。
二、简单操作使用
1 工作簿(WorkBook)
1.1 新建工作簿
基于openpyxl中的Workbook类
from openpyxl import Workbook
# 新建一个工作簿对象
wb = Workbook()
1.2 加载已有的工作簿
与新建的方式类似,使用openpyxl.load_workbook()加载已有的工作簿
from openpyxl import load_workbook
# 根据指定文件路径加载文件
wb = load_workbook('./test.xlsx')
1.3 保存工作簿
- 保存到文件
# 保存,save(必须要写文件名(绝对地址)默认 py 同级目录下,只支持 xlsx 格式)
wb.save('openpyxl_test1.xlsx')
此操作将在没有警告的情况下覆盖现有文件。
- 保存为文件流
使用tempfile下的NamedTemporaryFile()
tempfile:临时文件模块。大量临时数据放在内存中会占用大量资源,可以使用临时文件来进行储存
# 保存为文件流
with NamedTemporaryFile('w+b', delete=False) as tmp:
wb.save(tmp.name)
tmp.seek(0)
stream = tmp.read() # 二进制文件流
| 系统 | with NamedTemporaryFile(‘w+b’, delete=False) as tmp: | with NamedTemporaryFile(‘w+b’) as tmp: |
|---|---|---|
| Windows | 正常运行,运行结束保留临时文件 | 不能运行,不保留临时文件 |
| Linux | 正常运行,运行结束保留临时文件 | 正常运行,运行结束不保留临时文件 |
2 工作表(WorkSheet)
一个工作簿应至少存在一个工作表。
注意:当工作簿创建好之后,默认会创建一个名为"Sheet"的工作表
2.1 新建工作表
格式:workbook.create_sheet([title][,index])
注意:如果不指定名称,则在创建时会自动根据顺序编号(Sheet、Sheet1、Sheet2、…)进行命名
# 创建一个新的sheet
ws1 = wb.create_sheet("Sheet_1") # 在最后插入一个sheet(默认)
ws2 = wb.create_sheet("Sheet_2", 0) # 在第一个位置插入一个sheet
ws3 = wb.create_sheet("Sheet_3", -1) # 在倒数第二个位置插入一个sheet
ws4 = wb.create_sheet() # 默认
2.2 获取所有工作表名称
格式:workbook.sheetnames
获取当前工作簿所有工作表的名称,并以列表的形式返回
wb.sheetnames # ['Sheet_2', 'Sheet', 'Sheet_3', 'Sheet_1', 'Sheet1']
循环所有工作表:
# 循环工作表
for sheet in wb:
print(sheet) # 工作表对象
print(sheet.title) # 工作表名称
2.3 修改工作表名称
格式:worksheet.title = 工作表新名称
# 修改工作表名称
ws2.title = 'New Title'
ws4.title = '新的工作表名称'
print(wb.sheetnames) # ['New Title', 'Sheet', 'Sheet_3', 'Sheet_1', '新的工作表名称']
2.4 获取当前活动工作表
格式:workbook.active
默认为第一个工作表。返回一个工作表对象
ws = wb.active # <Worksheet "New Title">
print(ws.title) # New Title 当前活动工作表标题
2.5 指定工作表
方式1:将工作表名作为键来获取工作表对象
格式:workbook[worksheet_name]
# 方式1: 将工作表名作为键来获取工作表对象
specify_ws = wb['Sheet_3'] # <Worksheet "Sheet_3">
print(specify_ws.title) # Sheet_3
方式2:更改active索引值
格式:workbook.active = worksheet_index
当索引值超出已有工作表数量范围时为None
# 方式2: 更改active索引值
wb.active = 3
specify_ws2 = wb.active # <Worksheet "Sheet_1">
print(wb.active.title) # Sheet_1
wb.active = 10
print(wb.active) # None
2.6 获取工作表的最大、最小行与最大、最小列
工作表最大行:worksheet.max_row,获取存在数据的最大一行索引
工作表最小行:worksheet.min_row,获取存在数据的最小一行索引
工作表最大列:worksheet.max_column,获取存在数据的最大一列索引
工作表最小列:worksheet.min_column,获取存在数据的最小一列索引
# 获取工作表最大、最小行
print(ws.max_row) # 4
print(ws.min_row) # 2
# 获取工作表最大、最小列
print(ws.max_column) # 2
print(ws.min_column) # 1
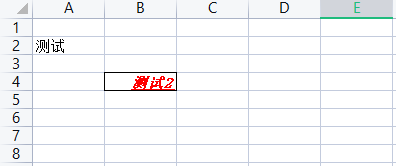
2.7 插入工作表行或列
插入行:worksheet.insert_rows(idx, [,amount]) idx:行索引,从哪一行插入;amount:插入几行,默认一行
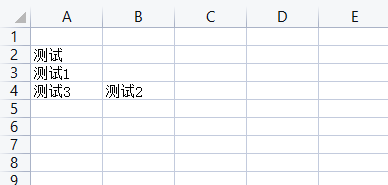
# 插入工作表行
ws.insert_rows(idx=4, amount=2)
插入列:worksheet.insert_cols(idx, [,amount]) idx:列索引,从哪一列插入;amount:插入几行,默认一行
# 插入工作表列
ws.insert_cols(idx=2, amount=2)
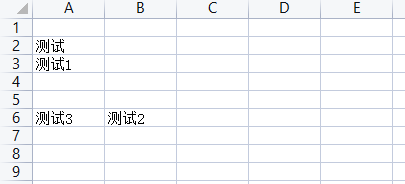
2.8 删除工作表行或列
删除行:worksheet.delete_rows(idx[, amount]) idx:行索引,从哪一行删除;amount:删除几行,默认一行
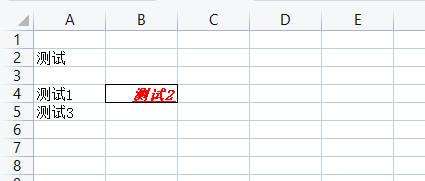
# 删除工作表行
print("删除前A4的值:", ws['A4'].value) # 删除前A4的值: 测试1
ws.delete_rows(idx=3, amount=1)
print("删除后A4的值:", ws['A4'].value) # 删除后A4的值: 测试3
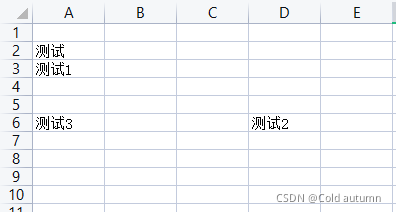
删除列:worksheet.delete_cols(idx[, amount]) idx:列索引,从哪一列删除;amount:删除几列,默认一列

# 删除工作表列
print("删除前B3的值:", ws['B3'].value) # 删除前B3的值: 测试2
ws.delete_cols(idx=2, amount=1)
print("删除后B3的值:", ws['B3'].value) # 删除后B3的值: None

注意:删除行或列后,后面的行或列会自动往前面填充,如上例子所示
2.9 修改工作表标题选项卡背景颜色
默认背景颜色为白色,可以更改为RRGGBB颜色代码
格式:worksheet.sheet_properties.tabColor = color_code
# 修改工作表标题选项卡背景颜色
ws4.sheet_properties.tabColor = '1072BA'
结果如图所示:

2.10 单个工作簿中创建工作表的副本
格式:workbook.copy_worksheet(from_worksheet)
copy_ws1 = wb.copy_worksheet(ws3)
copy_ws1.title = '这是copy的sheet'
效果图:

注意:仅复制单元格(包括值、样式、超链接和注释)和某些工作表属性(包括尺寸、格式和属性)。不会复制所有其他工作簿/工作表属性 - 例如图像、图表。
不能在工作簿之间复制工作表。如果工作簿以只读或只写 模式打开,则无法复制工作表。
3 单元格(cell)
3.1 选择单个单元格
方式1:将单元格作为工作表的键直接访问
格式:worksheet[cell]
# 方式1:将单元格作为工作表的键直接访问
a1 = ws['A1'] # 如果单元格不存在,将创建一个单元格
print(a1) # <Cell 'Sheet_11'.A1>
# 也可以直接对单元格赋值
ws['A2'] = '测试'
方式2:使用worksheet.cell(row, column[, value])方法
# 方式2:使用worksheet.cell()方法
cell2 = ws.cell(row=4, column=2, value='测试2') # column下标从1开始,此处为:B4
print(cell2) # <Cell 'Sheet_11'.B4>
结果示意图:
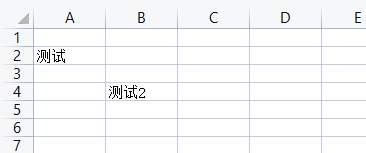
注意:在内存中创建工作表时,它不包含任何单元格。它们是在第一次访问时创建的。
3.2 选择多个单元格
选择一个范围内的多个单元格,返回格式为二维元祖,每一行为一个单独的元祖
格式:worksheet[‘cell1:cell2’]或worksheet[‘cell1’: ‘cell2’]
# 选择多个单元格
cell_range = ws['A1': 'B2']
cell_range2 = ws['A1': 'B2']
print(cell_range) # ((<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>), (<Cell 'Sheet'.A2>, <Cell 'Sheet'.B2>))
print(cell_range2) # ((<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>), (<Cell 'Sheet'.A2>, <Cell 'Sheet'.B2>))
3.3 选择行(row)
可以直接选择单行或多行
格式:
选择单行:worksheet[index]
选择多行:worksheet[begin_index: end_index]或worksheet.iter_rows(min_row, max_row, min_col, max_col, values_only)方法
遍历工作表所有行:worksheet.rows。遍历到文件最后存在数据的行
# 选择行
row = ws[1] # 选择一行
row_range = ws[1: 3] # 选择多行
row_iter = ws.iter_rows(min_row=1, max_col=3, max_row=2, values_only=True) # 选择多行
all_rows = ws.rows # 遍历所有行
print(row) # (<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>)
print(row_range) # ((<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>), (<Cell 'Sheet'.A2>, <Cell 'Sheet'.B2>), (<Cell 'Sheet'.A3>, <Cell 'Sheet'.B3>))
print(row_iter) # <generator object Worksheet._cells_by_row at 0x000001D38AFC28C8>
print(all_rows) # <generator object Worksheet._cells_by_row at 0x000002AAD82024C8>
for _row in row_iter:
"""
values_only=False:
(<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>, <Cell 'Sheet'.C1>)
(<Cell 'Sheet'.A2>, <Cell 'Sheet'.B2>, <Cell 'Sheet'.C2>)
values_only=True:
(None, None, None)
('测试', None, None)
"""
print(_row)
for _row in all_rows:
"""
(<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>)
(<Cell 'Sheet'.A2>, <Cell 'Sheet'.B2>)
(<Cell 'Sheet'.A3>, <Cell 'Sheet'.B3>)
(<Cell 'Sheet'.A4>, <Cell 'Sheet'.B4>)
"""
print(_row)
3.4 选择列(column)
可以直接选择单列或多列
格式:
选择单列:worksheet[index]
选择多列:worksheet[begin_index: end_index]或worksheet.iter_cols(min_col, max_col, min_row, max_row, values_only)方法
遍历工作表所有列:worksheet.columns。遍历到文件最后存在数据的列
# 选择列
column = ws['A'] # 选择一列
column_range = ws['A:B'] # 选择多列
column_iter = ws.iter_cols(min_row=1, max_col=3, max_row=2, values_only=True) # 选择多列
all_column = ws.columns # 遍历工作表所有列
print(column) # (<Cell 'Sheet'.A1>, <Cell 'Sheet'.A2>, <Cell 'Sheet'.A3>, <Cell 'Sheet'.A4>)
print(column_range) # ((<Cell 'Sheet'.A1>, <Cell 'Sheet'.A2>, <Cell 'Sheet'.A3>, <Cell 'Sheet'.A4>), (<Cell 'Sheet'.B1>, <Cell 'Sheet'.B2>, <Cell 'Sheet'.B3>, <Cell 'Sheet'.B4>))
for _col in column_iter:
"""
(<Cell 'Sheet'.A1>, <Cell 'Sheet'.A2>)
(<Cell 'Sheet'.B1>, <Cell 'Sheet'.B2>)
(<Cell 'Sheet'.C1>, <Cell 'Sheet'.C2>)
values_only=True:
(None, '测试')
(None, None)
(None, None)
"""
print(_col)
for _col in all_column:
"""
(<Cell 'Sheet'.A1>, <Cell 'Sheet'.A2>, <Cell 'Sheet'.A3>, <Cell 'Sheet'.A4>)
(<Cell 'Sheet'.B1>, <Cell 'Sheet'.B2>, <Cell 'Sheet'.B3>, <Cell 'Sheet'.B4>)
(<Cell 'Sheet'.C1>, <Cell 'Sheet'.C2>, <Cell 'Sheet'.C3>, <Cell 'Sheet'.C4>)
"""
print(_col)
iter_rows()方法与iter_cols()方法参数:
min_row: 最小行索引,索引值从1开始
max_row: 最大行索引,索引值从1开始
min_col: 最小列索引,索引值从1开始
max_col: 最大列索引,索引值从1开始
values_only: 是否只返回单元格的值,如果是则只返回单元格的值,否则返回单元格对象
注意:出于性能原因,worksheet.iter_cols()方法与worksheet.columns属性在只读模式下不可用。
3.5 获取单元格的值
获取单个单元格的值:cell.value
获取所有单元格的值:worksheet.values。以行为单位,每一行就是一个元祖
# 获取单个单元格的值
print(ws['B4'].value) # 测试2
# 获取所有单元格的值
all_values = ws.values
for val in all_values:
"""
(None, None, None)
('测试', None, None)
(None, None, None)
(None, '测试2', None)
"""
print(val)
3.6 单元格属性
cell = ws['B4']
3.6.1 单元格索引
获取列索引:cell.col_idx或cell.column
获取行索引:cell.row
# 列索引
print(cell.col_idx) # 2
print(cell.column) # 2
# 行索引
print(cell.row) # 4
3.6.2 单元格列名
格式:cell.column_letter,返回英文列名
# 列名
print(cell.column_letter) # B
3.6.3 单元格坐标
格式:cell.coordinate,返回完整的字母数字坐标
# 单元格坐标
print(cell.coordinate) # B4
3.6.4 单元格值类型
格式:cell.data_type,返回n/s/d
n:数值(默认)
s:字符串
d:日期时间
# 单元格值类型
print(cell.data_type) # s
3.6.5 单元格编码格式
格式:cell.encoding,返回具体编码格式,默认为utf-8
# 单元格编码格式
print(cell.encoding) # utf-8
3.6.6 单元格是否有样式
格式:cell.has_style,默认是Normal,如果存在默认样式之外的样式返回True,如果是默认则返回False
# 单元格是否有样式
print(cell.has_style) # True

3.6.7 单元格样式
格式:cell.style,返回单元格样式名
获取单元格样式id:cell.style_id
# 单元格样式
print(cell.style) # 常规
print(cell.style_id) # 2
三、进阶操作
1 合并/取消合并 单元格
- 合并单元格
格式1:worksheet.merge_cells(单元格范围)
格式2:worksheet.merge_cells(start_row=row_index, end_row=row_index, start_column=column_index, end_column=column_index)
ws.merge_cells('C3:D3')
ws.merge_cells(start_row=4, end_row=4, start_column=4, end_column=5)

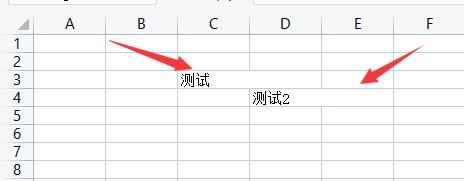
- 取消合并单元格
格式1:worksheet.unmerge_cells(单元格范围)
格式2:worksheet.unmerge_cells(start_row=row_index, end_row=row_index, start_column=column_index, end_column=column_index)
# 取消合并单元格
ws.unmerge_cells('C3:D3')
ws.unmerge_cells(start_row=4, end_row=4, start_column=4, end_column=5)
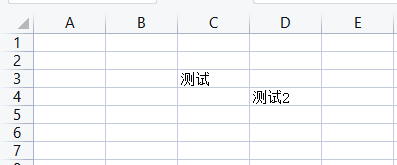
合并后的单元格,只会保留最左上角单元格的值,其余的单元格值都将被删除(变为None)
取消合并后的单元格,如果存在值,则最终也会保留在最左上角单元格
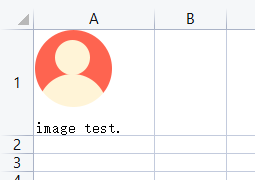
2 插入图片
插入图片到单元格中。使用openpyxl.drawing.image模块下的Image对象
格式:worksheet.add_image(img=img_object, anchor=cell_index)
from openpyxl.drawing.image import Image
# 插入图片
ws['A1'] = 'image test.'
img = Image('test.png')
ws.add_image(img=img, anchor='A1')
3 设置样式
样式设置来自于openpyxl下的styles模块
3.1 Color(颜色)
格式:Color(index=color_index) 或 Color(rgb=color_rgb)
from openpyxl.styles import Color
color = Color(index=2) # Color对象索引方式
color = Color(rgb='af94ff') # Color对象rgb值方式

COLOR_INDEX = (
'00000000', '00FFFFFF', '00FF0000', '0000FF00', '000000FF', #0-4
'00FFFF00', '00FF00FF', '0000FFFF', '00000000', '00FFFFFF', #5-9
'00FF0000', '0000FF00', '000000FF', '00FFFF00', '00FF00FF', #10-14
'0000FFFF', '00800000', '00008000', '00000080', '00808000', #15-19
'00800080', '00008080', '00C0C0C0', '00808080', '009999FF', #20-24
'00993366', '00FFFFCC', '00CCFFFF', '00660066', '00FF8080', #25-29
'000066CC', '00CCCCFF', '00000080', '00FF00FF', '00FFFF00', #30-34
'0000FFFF', '00800080', '00800000', '00008080', '000000FF', #35-39
'0000CCFF', '00CCFFFF', '00CCFFCC', '00FFFF99', '0099CCFF', #40-44
'00FF99CC', '00CC99FF', '00FFCC99', '003366FF', '0033CCCC', #45-49
'0099CC00', '00FFCC00', '00FF9900', '00FF6600', '00666699', #50-54
'00969696', '00003366', '00339966', '00003300', '00333300', #55-59
'00993300', '00993366', '00333399', '00333333', #60-63
)
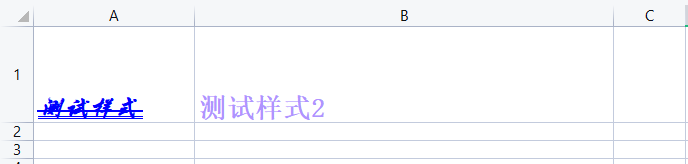
3.2 Font(字体)
主要用于设置单元格中的文字样式:加粗、斜体、字体、大小、颜色等。
| 属性 | 作用 | 值 |
|---|---|---|
| name | 设置字体 | 字体名称 eg.仿宋、行楷 |
| sz/size | 设置字体大小 | 字体大小值 eg.12、15 |
| b/bold | 是否加粗 | True/False |
| i/italic | 是否斜体 | True/False |
| strike/strikethrough | 是否添加删除线 | True/False |
| u/underline | 下划线 | single:单下划线 singleAccounting:充满整个单元格的单下划线 double:双下划线 doubleAccounting:充满整个单元格的双下划线 |
| color | 字体颜色 | rgb值 或 Color对象 eg.000000FF Color(rgb=‘00000000’)/Color(index=0) |
from openpyxl.styles import Font, Color
# 设置字体样式
font_style = Font(name='华文行楷', sz=18, b=True, i=True, strike=True, underline='double', color='000000FF')
ws['A1'].font = font_style
# color = Color(index=2) # Color对象索引方式
color = Color(rgb='af94ff') # Color对象rgb值方式
font_style2 = Font(name='方正楷体', sz=20, b=True, color=color)
ws.cell(row=1, column=2).font = font_style2
3.3 PatternFill(图案填充)
设置图案或颜色渐变
| 属性 | 作用 | 值 |
|---|---|---|
| patternType/fill_type | 填充类型。必须设置,如果不设置其它属性将不会起作用 | 见如下代码 |
| fgColor/start_color | 前景色 | rgb值 或 Color对象 eg.000000FF Color(rgb=‘00000000’)/Color(index=0) |
| bgColor/end_color | 背景色 | rgb值 或 Color对象 eg.000000FF Color(rgb=‘00000000’)/Color(index=0) |
patternType = ('darkDown', 'darkUp', 'lightDown', 'darkGrid', 'lightVertical',
'solid', 'gray0625', 'darkHorizontal', 'lightGrid', 'lightTrellis',
'mediumGray', 'gray125', 'darkGray', 'lightGray', 'lightUp',
'lightHorizontal', 'darkTrellis', 'darkVertical')
from openpyxl.styles import PatternFill, Color
# 设置填充
ws['A1'].fill = PatternFill(patternType='solid', fgColor='af94ff')
ws['B1'].fill = PatternFill(patternType='gray125', bgColor=Color(rgb='ddeaff'))

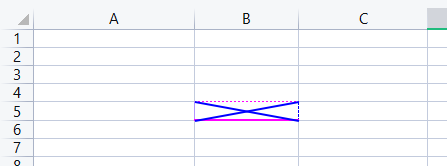
3.4 Border(边框)
设置单元格边框样式
Border属性表:
| 属性 | 作用 | 值 |
|---|---|---|
| left | 左边框 | Side() |
| right | 右边框 | Side() |
| top | 上边框 | Side() |
| bottom | 下边框 | Side() |
| diagonal | 对角线 | Side() |
| diagonalUp | 是否显示左下角到右上角对角线,需已设置diagonal属性 | True/False |
| diagonalDown | 是否显示左上角到右下角对角线,需已设置diagonal属性 | True/False |
Side属性表
| 属性 | 作用 | 值 |
|---|---|---|
| style/border_style | 边框样式 | 见如下代码 |
| color | 边框颜色 | rgb值 或 Color对象 eg.000000FF Color(rgb=‘00000000’)/Color(index=0) |
# style可选项
border_style = ('dashDot','dashDotDot', 'dashed','dotted',
'double','hair', 'medium', 'mediumDashDot', 'mediumDashDotDot',
'mediumDashed', 'slantDashDot', 'thick', 'thin')
# medium 中粗
# thin 细
# thick 粗
# dashed 虚线
# dotted 点线
from openpyxl.styles import Color, Border, Side
border = Border(
left=Side(border_style='thin', color='af94ff'),
right=Side(border_style='dashed', color='000000FF'),
top=Side(style='dotted', color=Color(index=33)),
diagonal=Side(style='medium', color=Color(rgb='000000FF')),
diagonalDown=True,
diagonalUp=True,
bottom=Side(style='medium', color=Color(index=33))
)
ws['B5'].border = border
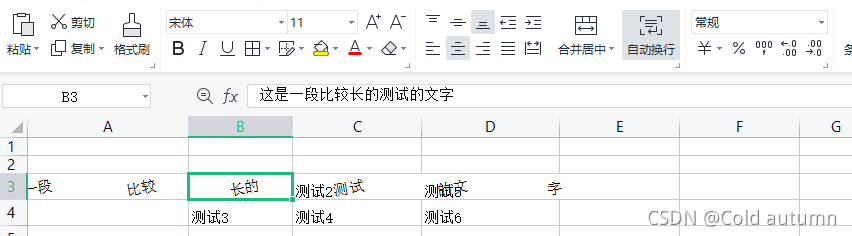
3.5 Alignment(对齐)
设置单元格中的内容对齐方式
| 属性 | 作用 | 值 |
|---|---|---|
| horizontal | 水平对齐方式 | 见如下代码 |
| vertical | 垂直对齐方式 | 见如下代码 |
| text_rotation/textRotation | 文字旋转 | -99—100度 |
| wrapText/wrap_text | 自动换行 | True/False |
| shrinkToFit/shrink_to_fit | 缩小字体填充 | True/False |
| indent | 缩进 | 0-15 |
| readingOrder | 文字方向 | 0:根据内容 1:总是从左向右 2:总是从右向左 |
horizontal_alignments = (
"general", "left", "center", "right", "fill", "justify", "centerContinuous",
"distributed", )
vertical_aligments = (
"top", "center", "bottom", "justify", "distributed",
)
from openpyxl.styles import Alignment
alignment = Alignment(horizontal='center', vertical='bottom', text_rotation=10, wrap_text=True, indent=0,
readingOrder=2)
ws['B3'].alignment = alignment
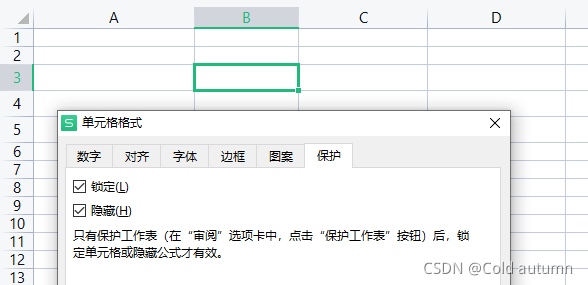
3.6 Protection(保护)
| 属性 | 作用 | 值 |
|---|---|---|
| locked | 锁定 | True/False |
| hidden | 锁定 | True/False |
注意:只有保护工作表(在“审阅”选项卡中,点击“保护工作表”按钮)后,锁定单元格或隐藏公式才有效
from openpyxl.styles import Protection
# 保护
protection = Protection(locked=True, hidden=True)
ws['B3'].protection = protection
3.7 设置单元格样式
import datetime
# 设置单元格样式
# 设置工作薄自动识别单元格样式
wb.guess_types = True
ws['A1'] = '2021-09-28'
print(ws['A1'].value) # 2021-09-28
print(ws['A1'].data_type) # s
print(ws['A1'].number_format) # General
ws['B1'] = datetime.datetime.now()
print(ws['B1'].value) # 2021-09-30 16:38:59.079366
print(ws['B1'].data_type) # d
print(ws['B1'].number_format) # yyyy-mm-dd h:mm:ss
# 使用内建样式
ws['C1'] = 55555
ws['C1'].number_format = '#,##0'
print(ws['C1'].data_type) # n
# 自定义样式
ws['D1'].number_format = 'yyyy-mm-dd'
ws['D1'] = datetime.datetime.now()
print(ws['D1'].value) # 2021-09-30 16:49:43.743952
print(ws['D1'].data_type) # d

内建样式:
BUILTIN_FORMATS = {
0: 'General', # 默认样式
1: '0',
2: '0.00',
3: '#,##0',
4: '#,##0.00',
5: '"$"#,##0_);("$"#,##0)',
6: '"$"#,##0_);[Red]("$"#,##0)',
7: '"$"#,##0.00_);("$"#,##0.00)',
8: '"$"#,##0.00_);[Red]("$"#,##0.00)',
9: '0%',
10: '0.00%',
11: '0.00E+00',
12: '# ?/?',
13: '# ??/??',
14: 'mm-dd-yy',
15: 'd-mmm-yy',
16: 'd-mmm',
17: 'mmm-yy',
18: 'h:mm AM/PM',
19: 'h:mm:ss AM/PM',
20: 'h:mm',
21: 'h:mm:ss',
22: 'm/d/yy h:mm',
37: '#,##0_);(#,##0)',
38: '#,##0_);[Red](#,##0)',
39: '#,##0.00_);(#,##0.00)',
40: '#,##0.00_);[Red](#,##0.00)',
41: r'_(* #,##0_);_(* \(#,##0\);_(* "-"_);_(@_)',
42: r'_("$"* #,##0_);_("$"* \(#,##0\);_("$"* "-"_);_(@_)',
43: r'_(* #,##0.00_);_(* \(#,##0.00\);_(* "-"??_);_(@_)',
44: r'_("$"* #,##0.00_)_("$"* \(#,##0.00\)_("$"* "-"??_)_(@_)',
45: 'mm:ss',
46: '[h]:mm:ss',
47: 'mmss.0',
48: '##0.0E+0',
49: '@', }
3.8 命名样式
当您想一次将格式应用于多个单元格时,这会非常有用
from openpyxl.styles import Font, Color, PatternFill, Border, Side, Alignment, Protection, NamedStyle
# 命名样式
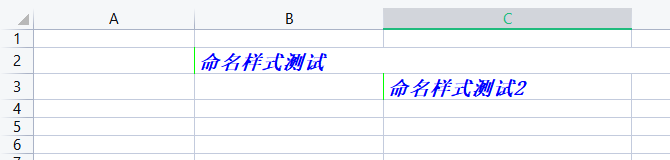
ws.merge_cells('B2:D2')
ws['B2'].value = '命名样式测试'
ws['C3'].value = '命名样式测试2'
# 设置样式
style = NamedStyle(
name='test_style',
border=Border(left=Side(border_style='thin', color=Color(index=3)))
)
style.font = Font(sz=15, b=True, i=True, color=Color(rgb='000000FF'))
# 将样式注册到工作簿
wb.add_named_style(style=style)
# 注册后,直接使用样式名称分配样式
ws['B2'].style = 'test_style'
ws['C3'].style = 'test_style'
4 行高和列宽
行高:worksheet.row_dimensions[row_index].height = num
列宽:worksheet.column_dimensions[column_index].width = num
# 设置行高、列宽
ws.row_dimensions[2].height = 30 # 设置第二行行高为30
ws.column_dimensions['B'].width = 50 # 设置B列列宽为50
5 冻结窗格
冻结单元格所设置的参数为一个单元格,这个单元格上侧和左侧的所有行 / 列会被冻结
worksheet.freeze_panes = 单元格地址
# 设置冻结窗格
ws.freeze_panes = 'B1' # 冻结首列
ws.freeze_panes = 'A2' # 冻结首行
ws.freeze_panes = 'B2' # 冻结首行与首列
6 筛选
worksheet.auto_filter.ref = 列范围
# 设置筛选
ws.auto_filter.ref = "A:C"
7 worksheet与pandas互转
worksheet转换为pandas:
import pandas
# 将worksheet转换为pandas
df = pandas.DataFrame(ws.values)
pandas转换为worksheet:
from openpyxl.utils.dataframe import dataframe_to_rows
# 将pandas写入worksheet
for _row in dataframe_to_rows(df=df, index=False, header=False):
ws.append(_row)
8 优化模式
openpyxl功能丰富,单与其他库和应用程序相比,内存使用量相当高,大约是原始文件的50倍,例如,50 MB Excel 文件需要 2.5 GB。
在实际使用过程中,读取、写入都是分开进行的操作,这时可使用优化模式进行操作。优化模式能够使您能够以(接近)恒定内存消耗读取和写入无限量的数据。
只读模式
openpyxl.worksheet._read_only.ReadOnlyWorksheet
from openpyxl import load_workbook
# 只读模式
wb = load_workbook(filename='./test.xlsx', read_only=True)
ws = wb.active
for row in ws.rows:
for cell in row:
print(cell.value)
wb.close() # 关闭工作簿
openpyxl.worksheet._read_only.ReadOnlyWorksheet 是只读的
与普通工作簿不同,只读工作簿将使用延迟加载。必须使用该close()方法显式关闭工作簿
返回的单元格不是常规的openpyxl.cell.cell.Cell而是 openpyxl.cell._read_only.ReadOnlyCell
只写模式
openpyxl.worksheet._write_only.WriteOnlyWorksheet
from openpyxl import Workbook
# 只写模式
wb = Workbook(write_only=True)
ws = wb.create_sheet() # 只写模式必须使用create_sheet方法新建工作表
for irow in range(100):
ws.append(['%d' % i for i in range(200)])
wb.save('write_only_on.xlsx')
如果您想要具有样式或注释的单元格,请使用 openpyxl.cell.WriteOnlyCell()
from openpyxl import Workbook
from openpyxl.styles import Font
from openpyxl.cell import WriteOnlyCell
from openpyxl.comments import Comment
# 单元格带样式的只写模式
wb = Workbook(write_only=True)
ws = wb.create_sheet()
cell = WriteOnlyCell(ws=ws, value='hello world')
cell.font = Font(name='Courier', size=36)
cell.comment = Comment(text="A comment", author="Author's Name")
ws.append([cell, 3.14, None])
wb.save('write_only_two.xlsx')
与普通工作簿不同,新创建的只写工作簿不包含任何工作表;必须使用该create_sheet()方法专门创建工作表
在只写工作簿中,行只能用 append()
它能够导出无限量的数据(甚至超过 Excel 实际可以处理的数据量),同时将内存使用量保持在 10Mb 以下。
只写工作簿只能保存一次。之后,每次尝试将工作簿或 append() 保存到现有工作表都会引发openpyxl.utils.exceptions.WorkbookAlreadySaved 异常
在实际单元格数据之前出现在文件中的所有内容都必须在添加单元格之前创建,因为它必须在此之前写入文件。例如,应在添加单元格之前设置freeze_panes
总结
本文仅介绍了openpyxl的部分常用操作,更多操作请自行查找方法。码字不易,欢迎指正。