MixFormerV2: Efficient Fully Transformer Tracking
论文地址:https://arxiv.org/pdf/2305.15896
动机:
这篇论文的研究动机是为了解决目前基于Transformer的跟踪器在实际应用中的效率问题,特别是在GPU和CPU平台上的推理效率仍然是一个难题。为了解决这个问题,该论文提出了一种名为MixFormerV2的全Transformer跟踪框架,没有任何密集卷积操作和复杂的得分预测模块。其关键设计是引入四个特殊的预测tokens,并将它们与目标模板和搜索区域的tokens连接起来,然后在这些混合tokens序列上应用统一的Transformer骨干网络。这些预测tokens能够通过混合注意力捕捉目标模板和搜索区域之间的复杂相关性。基于它们,我们可以通过简单的MLP头轻松预测跟踪框并估计其置信度分数。
贡献
- 提出了第一个不需要任何卷积运算的完全变压器跟踪框架,称为MixFormerV2,产生了更统一和更高效的跟踪器。
- 提出了一种新的基于蒸馏的模型简化范式,使MixFormerV2更加有效和高效,可以在具有GPU或CPU的平台上实现高性能跟踪。
主要内容
本文提出了一种名为MixFormerV2的高效全Transformer跟踪框架,它不仅能够保持高精度,而且能够在GPU和CPU平台上实现高效部署。其核心设计是引入四个特殊的预测tokens,并将它们与目标模板和搜索区域的tokens连接起来,然后在这些混合的tokens序列上应用统一的Transformer骨干。这些预测tokens能够通过混合的注意力机制来捕捉目标模板和搜索区域之间的复杂关系。此外,本文还提出了一种基于蒸馏的模型压缩范式,包括稠密到稀疏的蒸馏和深到浅的蒸馏,前者旨在将知识从基于密集头的MixViT转移到我们的fully transformer跟踪器上,而后者则用于修剪骨干的一些层,以进一步提高MixFormerV2的效率。
实现细节
为了避免密集角点头和复杂的分数预测模块,提出了一种新的全变压器跟踪框架MixFormerV2,无需任何密集卷积运算。MixFormerV2产生了一个非常简单高效的体系结构,它由混合tokens序列上的Transformer主干和可学习预测tokens上的两个简单的MLP头组成。具体来说,引入了四个特殊的可学习预测标记,并将它们与目标模板和搜索区域的原始标记连接起来。就像标准ViT中的CLS令牌一样,这些预测标记能够捕获目标模板和搜索区域之间的复杂关系,作为后续回归和分类的紧凑表示。基于它们,我们可以通过简单的 MLP 头轻松预测目标框和置信度分数,从而产生高效的完全Transformer跟踪器。MLP 头直接回归四个框坐标的概率分布,在不增加开销的情况下提高了回归精度。
为了进一步提高MixFormerV2的效率,提出了一种新的基于蒸馏的模型约简范式,包括密集到稀疏蒸馏和深到浅蒸馏。密集到稀疏蒸馏旨在将知识从基于密集头的MixViT转移到我们的fully transformer跟踪器。由于 MLP 头基于分布的回归设计,可以很容易地采用 logits 模仿策略将 MixViT 跟踪器蒸馏到我们的 MixFormerV2。基于表2中的观察,还利用了从深到浅的蒸馏来修剪MixFormerV2。
我们设计了一种新的渐进式深度剪枝策略,遵循一个关键原则,即限制学生和教师跟踪器的初始分布尽可能相似,从而增强知识传递的能力。具体地说,在冻结的教师模型的指导下,复制的教师模型的某些特定层被逐渐删除,我们使用修剪后的模型作为我们的学生初始化。对于CPU实时跟踪,我们进一步引入了一个中间教师模型,以弥补大教师和小学生之间的差距,并根据所提出的蒸馏范式修剪MLP的隐性凹陷。
基于提出的模型简化范例,我们实例化了两种类型的MixFormerV2跟踪器,MixFormerV2- B和MixFormerV2- S。如图1所示,MixFormerV2比以前的跟踪器在跟踪精度和推理速度之间实现了更好的权衡。

具体实现
1、Fully Transformer Tracking: MixFormerV2
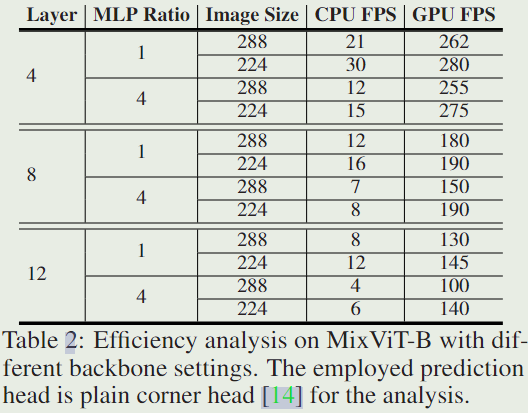
所提出的MixFormerV2是一个fully transformer跟踪框架,没有任何卷积运算和复杂的分数预测模块。它的主干是一个关于三种类型的混合标记序列的普通Transformer:目标模板标记、搜索区域标记和可学习预测标记。然后,将简单的MLP头放置在顶部,以预测盒子坐标的概率分布和对应的目标质量分数。MixFormerV2首次有效地删除了定制的卷积分类和回归头,从而简化了跟踪流程,从而产生了更统一、更高效和更灵活的跟踪器。总体架构如图2所示。
通过输入模板标记、搜索区域标记和可学习预测标记,MixFormerV2以端到端的方式预测目标边界框和质量分数。
Prediction-Token-Involved Mixed Attention
与MixViT中原有的slimming mixed attention相比,关键的区别在于引入了特殊的可学习预测tokens,用于捕捉目标模板和搜索区域之间的相关性。这些预测标记可以逐步压缩目标信息,并用作后续回归和分类的紧凑表示。具体来说,给定多个模板、搜索和四个可学习的预测标记的串联标记,我们将它们传入N层预测标记参与的混合注意力模块(P-MAM)。我们使用
q
t
q_t
qt、
k
t
k_t
kt 和
v
t
v_t
vt 来表示注意力、
q
s
q_s
qs、
k
s
k_s
ks 和
v
s
v_s
vs 的模板元素(即查询、键和值)来表示搜索区域,
q
e
q_e
qe、
k
e
k_e
ke 和
v
e
v_e
ve 来表示可学习的预测标记。P-MAM 可以定义为:
k
t
s
e
=
C
o
n
c
a
t
(
k
t
,
k
s
,
k
e
)
,
v
t
s
e
=
C
o
n
c
a
t
(
v
t
,
v
s
,
v
e
)
,
A
t
t
e
n
t
=
S
o
f
t
m
a
x
(
q
t
k
t
T
d
)
v
t
,
A
t
t
e
n
s
=
S
o
f
t
m
a
x
(
q
s
k
t
s
e
T
d
)
v
t
s
e
,
A
t
t
e
n
e
=
S
o
f
t
m
a
x
(
q
e
k
t
s
e
T
d
)
v
t
s
e
\begin{aligned} k_{t s e}=\mathrm{Concat}(k_{t},k_{s},k_{e}),\\ v_{t s e}=\mathrm{Concat}(v_{t},v_{s},v_{e}), \\ \mathrm{Atten}_{t}=\mathrm{Softmax}({\frac{q_{t}k_{t}^{T}}{\sqrt{d}}})v_{t},\\ \mathrm{Atten}_{s}=\mathrm{Softmax}({\frac{q_{s}k_{t s e}^{T}}{\sqrt{d}}})v_{t s e},\\ \mathrm{Atten}_{e}=\mathrm{Softmax}({\frac{q_{e}k_{t s e}^{T}}{\sqrt{d}}})v_{t s e} \end{aligned}
ktse=Concat(kt,ks,ke),vtse=Concat(vt,vs,ve),Attent=Softmax(dqtktT)vt,Attens=Softmax(dqsktseT)vtse,Attene=Softmax(dqektseT)vtse
其中
d
d
d 表示每个元素的维度,
A
t
t
e
n
t
Atten_t
Attent、
A
t
t
e
n
s
Atten_s
Attens 和
A
t
t
e
n
e
Atten_e
Attene 分别是模板、搜索和可学习预测标记的注意力输出。与原始MixFormer类似,使用非对称混合注意方案进行有效的在线推理。与标准VIT中的CLS标记一样,可学习预测标记在跟踪数据集上自动学习,以压缩模板和搜索信息。
Direct Prediction Based on Tokens
在Transformer 主干网后,我们直接使用预测标记对目标位置进行回归,并估计其可靠评分。具体地说,我们利用了基于分布的回归,该回归基于四个特殊的可学习预测标记。从这个意义上讲,我们回归的是四个包围盒坐标的概率分布,而不是它们的绝对位置。由于预测标记可以通过预测标记涉及的混合注意力模块来压缩目标感知信息,我们可以简单地用同一个MLP头来预测四个盒子的坐标,如下所示:
P
^
X
(
x
)
=
MLP
(
tokes
X
)
,
X
∈
{
T
,
L
,
B
,
R
}
.
\hat{P}_X(x)=\operatorname{MLP}(\operatorname{tokes}_X),X\in\{\mathcal{T},\mathcal{L},\mathcal{B},\mathcal{R}\}.
P^X(x)=MLP(tokesX),X∈{T,L,B,R}.
在实现中,我们在四个预测标记之间共享MLP权重。对于预测的目标质量评估,我们平均输出预测标记,然后使用它用 MLP 头估计目标置信度分数。这些基于标记的头极大地降低了盒估计和质量分数估计的复杂性,从而导致更简单和统一的跟踪体系结构。
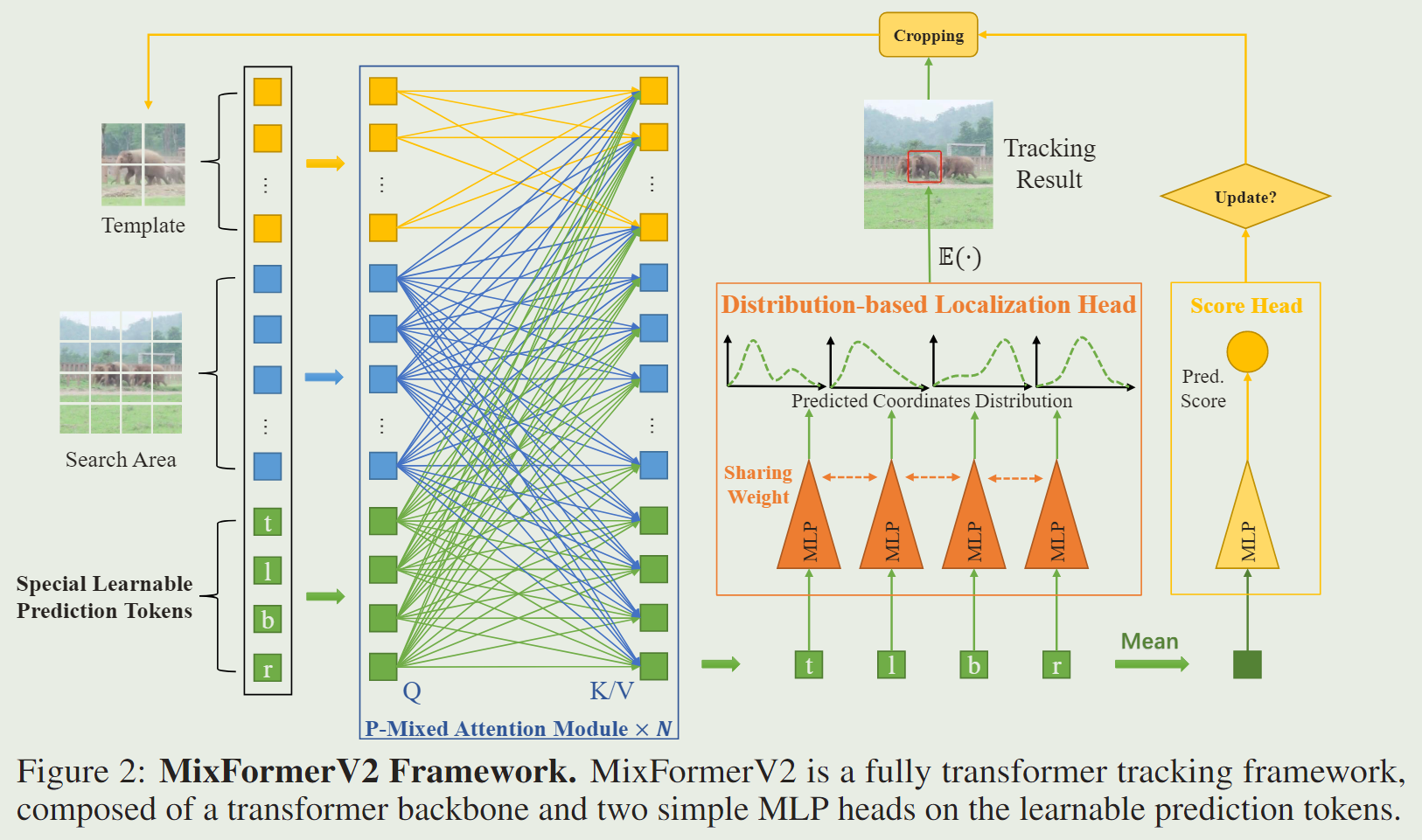
2、Distillation-Based Model Reduction
为了进一步提高MixFormerV2的效率和有效性,提出了一种基于蒸馏的模型缩减范式,如图3所示,它首先执行密集到稀疏蒸馏以获得更好的基于标记的预测,然后深到浅蒸馏进行模型修剪。
2.1、Dense-to-Sparse Distillation
在MixFormerV2中,我们根据预测标记直接将目标边界框回归到四个随机变量
T
,
L
,
B
,
R
∈
R
\mathcal{T}, \mathcal{L}, \mathcal{B}, \mathcal{R}\in\mathbb{R}
T,L,B,R∈R的分布,这四个随机变量分别代表盒子的上、左、下、右坐标。具体来说,我们预测每个坐标的概率密度函数
X
∼
P
~
X
(
x
)
,
where
X
∈
{
T
,
L
,
B
,
R
}
X\sim\tilde{P}_X(x),\text{where}X\in\{\mathcal{T},\mathcal{L},\mathcal{B},\mathcal{R}\}
X∼P~X(x),whereX∈{T,L,B,R}。最终边界框坐标
B
B
B 可由回归概率分布上的期望得到:
B
X
=
E
P
^
X
[
X
]
=
∫
R
x
P
^
X
(
x
)
d
x
.
B_X=\mathbb{E}_{\hat{P}_X}[X]=\int_{\mathbb{R}}x\hat{P}_X(x)\mathrm{d}x.
BX=EP^X[X]=∫RxP^X(x)dx.
由于原始MixViT的密集卷积角头预测二维概率图,即左上角和右下角的联合分布 P T L ( x , y ) P_\mathcal{TL}(x, y) PTL(x,y)和 P B R ( x , y ) P_\mathcal{BR}(x, y) PBR(x,y),因此通过边缘分布可以很容易地推导出一维版本的盒坐标分布:
P
T
(
x
)
=
∫
R
P
T
(
x
,
y
)
d
y
,
P
L
(
y
)
=
∫
R
P
T
(
x
,
y
)
d
x
P
B
(
x
)
=
∫
R
P
B
R
(
x
,
y
)
d
y
,
P
R
(
y
)
=
∫
R
P
B
R
(
x
,
y
)
d
x
.
\begin{gathered} P_{\mathcal{T}}(x)=\int_{\mathbb{R}}P_{\mathcal{T}}(x,y)\mathrm{d}y,\quad P_{\mathcal{L}}(y)=\int_{\mathbb{R}}P_{\mathcal{T}}(x,y)\mathrm{d}x \\ P_{\mathcal{B}}(x)=\int_{\mathbb{R}}P_{\mathcal{B R}}(x,y)\mathrm{d}y,\quad P_{\mathcal{R}}(y)=\int_{\mathbb{R}}P_{\mathcal{B R}}(x,y)\mathrm{d}x. \end{gathered}
PT(x)=∫RPT(x,y)dy,PL(y)=∫RPT(x,y)dxPB(x)=∫RPBR(x,y)dy,PR(y)=∫RPBR(x,y)dx.
在此,这种建模方法可以弥补密集角预测和我们基于稀疏标记的预测之间的差距,也就是说,原始MixViT的回归输出可以被视为密集到稀疏蒸馏的软标签。具体来说,我们使用MixViT的输出
P
X
P_X
PX,如式4所示来监督MixFormerV2的四个坐标估计
P
^
X
\hat{P}_X
P^X,应用KL-Divergence损失如下:
L
l
o
c
=
∑
X
∈
{
T
,
L
,
B
,
R
}
L
K
L
(
P
^
X
,
P
X
)
L_{\mathrm{loc}}=\sum\limits_{X\in\{\mathcal{T},\mathcal{L},\mathcal{B},\mathcal{R}\}}L_{\mathrm{KL}}(\hat{P}_X,P_X)
Lloc=X∈{T,L,B,R}∑LKL(P^X,PX)
通过这种方式,将定位知识从MixViT的密集角头转移到MixFormerV2的基于token的稀疏头。
2.2、Deep-to-Shallow Distillation
为了进一步提高效率,我们把重点放在修剪Transformer骨架上。然而,设计一个新的轻量级骨干网并不适合快速单流跟踪。单流跟踪器的新主干通常高度依赖于大规模的预训练来获得良好的性能,这需要大量的计算量。因此,我们求助于基于特征模仿和 logits 蒸馏直接缩小 MixFormerV2 主干的某些层,如图 3:Stage2 所示。设
F
i
S
,
F
j
T
∈
R
h
×
w
×
c
F^S_i, F^T_j\in \mathcal{R}^{h×w×c}
FiS,FjT∈Rh×w×c表示来自student和teacher的feature map,下标表示层的索引。对于logits蒸馏,我们使用KL-Divergence损失。对于特征模仿,我们采用L2损耗:
L
f
e
a
t
=
∑
(
i
,
j
)
∈
M
L
2
(
F
i
S
,
F
j
T
)
,
L_{\mathrm{feat}}=\sum\limits_{(i,j)\in\mathcal{M}}L_2(F_i^S,F_j^T),
Lfeat=(i,j)∈M∑L2(FiS,FjT),
其中
M
\mathcal{M}
M 是需要监督的匹配层对的集合。具体来说,我们设计了一种渐进式模型深度剪枝策略进行蒸馏。
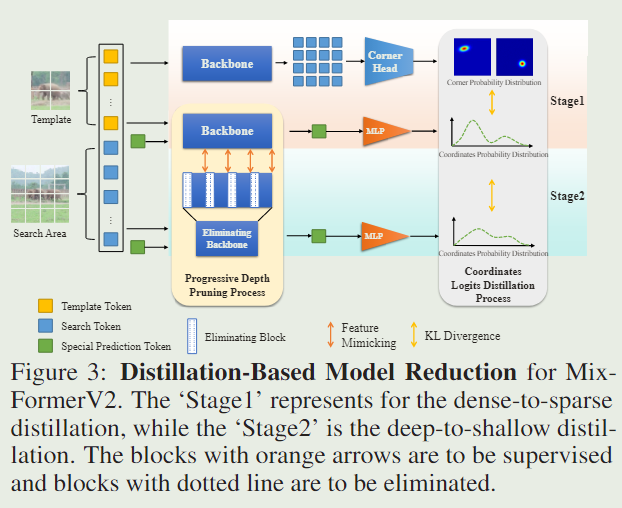
Progressive Model Depth Pruning
渐进模型深度修剪旨在通过减少Transformer层的数量来压缩MixFormerV2主干。由于直接删除某些层可能会导致不一致和不连续性,我们探索了一种基于特征和 logits 蒸馏的模型深度修剪的渐进式方法。具体来说,我们不是让教师从头开始监督较小的学生模型,而是让原始学生模型成为教师模型的完整副本。然后,我们将逐步消除学生的某些层次,并在教师的监督下使剩余的层次在训练中模仿教师的表现。这种设计允许学生和教师的初始表示尽可能保持一致,提供平滑的过渡方案并减少特征模仿的难度。
形式上,设
x
i
x_i
xi 表示 MixFormerV2 主干的第
i
i
i 层的输出,注意块的计算可以表示如下(等式省略了层归一化操作):
x
i
′
=
ATTN
(
x
i
−
1
)
+
x
i
−
1
,
x
i
=
FFN
(
x
i
′
)
+
x
i
′
=
FFN
(
ATTN
(
x
i
−
1
)
+
x
i
−
1
)
+
ATTN
(
x
i
−
1
)
+
x
i
−
1
,
\begin{aligned} &x_i' =\operatorname{ATTN}(x_{i-1})+x_{i-1}, \\ &x_{i} =\operatorname{FFN}(x_i')+x_i' \\ &=\operatorname{FFN}(\operatorname{ATTN}(x_{i-1})+x_{i-1})+\operatorname{ATTN}(x_{i-1})+x_{i-1}, \end{aligned}
xi′=ATTN(xi−1)+xi−1,xi=FFN(xi′)+xi′=FFN(ATTN(xi−1)+xi−1)+ATTN(xi−1)+xi−1,
令
E
\mathcal{E}
E 为学生网络中要消除的层集,我们对这些层的权重应用衰减率
γ
\gamma
γ:
x
i
=
γ
(
F
F
N
(
A
T
N
(
x
i
−
1
)
+
x
i
−
1
)
+
A
T
T
N
(
x
i
−
1
)
)
+
x
i
−
1
,
i
∈
E
.
x_{i}=\gamma\big(\mathrm{FFN}\big(\mathrm{ATN}(x_{i-1})+x_{i-1}\big)+\mathrm{ATTN}(x_{i-1})\big)+x_{i-1},i\in{\mathcal{E}}.
xi=γ(FFN(ATN(xi−1)+xi−1)+ATTN(xi−1))+xi−1,i∈E.
在学生网络训练的前
m
m
m个epoch中,
γ
\gamma
γ会以余弦函数的方式从1逐渐减小到0:
γ
(
t
)
=
{
0.5
×
(
1
+
cos
(
t
m
)
)
,
t
≤
m
,
0
,
t
>
m
.
\gamma(t)=\left\{\begin{array}{l l}{0.5\times\left(1+\cos\left(\frac{t}{m}\right)\right),}&{t\le m,}\\ {0,}&{t>m.}\\ \end{array}\right.
γ(t)={0.5×(1+cos(mt)),0,t≤m,t>m.
这意味着学生网络中的这些层级被逐渐消除,最后变成身份转换,如图4所描述。
修剪后的学生模型可以通过简单地删除 E \mathcal{E} E 中的层并保留剩余的块来获得。
Intermediate Teacher
对于极浅模型(4 层 MixFormerV2)的蒸馏,我们引入了一个中间教师(8 层 MixFormerV2)来桥接深度教师(12 层 MixFormerV2)和浅层教师。通常,教师的知识可能过于复杂,小学生模型无法学习。因此,我们引入了一个中间角色作为教学助手来缓解极端知识蒸馏的难度。从这个意义上说,我们将教师和学生之间的知识蒸馏问题划分为几个蒸馏子问题。
MLP Reduction
如表2所示,影响跟踪器在CPU设备上推理延迟的一个关键因素是Transformer块中MLP的隐藏特征dim。
换句话说,它成为限制 CPU 设备上实时速度的瓶颈。为了利用这一问题,我们基于提出的蒸馏范式,即特征模仿和logits蒸馏,进一步对MLP的hidden dim进行了修剪。具体来说,设原始模型中的线性权值形状为 w ′ ∈ R d 1 × d 2 w'\in \mathbb{R}^{d1\times d2} w′∈Rd1×d2,剪枝学生模型中对应的线性权值形状为 w ′ ∈ R d 1 ′ × d 2 ′ w'\in \mathbb{R}^{d'_1 ×d'_2} w′∈Rd1′×d2′,其中 d 1 ′ ≤ d 1 , d 2 ′ ≤ d 2 d'_1≤d_1,d'_2≤d_2 d1′≤d1,d2′≤d2,我们将学生模型的权值初始化为: w ′ = w [ : d 1 ′ , : d 2 ′ ] w'= w[: d'_1,:d'_2] w′=w[:d1′,:d2′]。然后,我们应用蒸馏监督进行训练,让修剪后的MLP模拟原来的重型MLP。
2.3、Training of MixFormerV2
整个训练管道如图3所示,执行从密集到稀疏的蒸馏,然后从深到浅的蒸馏,最终得到我们高效的MixFormerV2跟踪器。然后,我们训练基于MLP的得分头50次。特别是,对于CPU实时跟踪,我们使用中间教师基于提出的蒸馏生成一个较浅的模型(4层MixFormerV2)。此外,我们还使用所设计的MLP减少策略来进一步修剪CPU实时跟踪器。使用学生 S 和教师 T 进行蒸馏训练的总损失计算为:
L
=
λ
1
L
1
(
B
S
,
B
g
t
)
+
λ
2
L
c
i
o
u
(
B
S
,
B
g
t
)
+
λ
3
L
d
i
s
t
(
S
,
T
)
L=\lambda_{1}L_{1}(B^{S},B^{g t})+\lambda_{2}L_{c i o u}(B^{S},B^{g t})+\lambda_{3}L_{d i s t}(S,T)
L=λ1L1(BS,Bgt)+λ2Lciou(BS,Bgt)+λ3Ldist(S,T)
其中前两个项与原始MixFormer的位置损失完全相同,由地面真值边界框标签监督,其余项用于上述蒸馏。