用友Java面试汇总
昨天晚上接到了用友的电话,让我订时间,约好今天1点30
1点40开始电话面试
(1)自我介绍,根据情况进行一些简单提问,例如问了我做项目的感受是什么,进入状态
(2)直接上来分布式锁,不会
(3)问了一些线程安全的集合类,太紧张了,说的语无伦次。。
(4)concurrenthashmap,不多说,面试必问
JAVA7时:
ConcurrentHashMap引入Segment 的概念,目的是将map拆分成多个Segment(默认16个)。操作ConcurrentHashMap细化到操作某一个Segment。在多线程环境下,不同线程操作不同的Segment,他们互不影响,这便可实现并发操作。
ConcurrentHashMap由一个Segment[]数组组成,数组元素是一个数组+链表的结构。
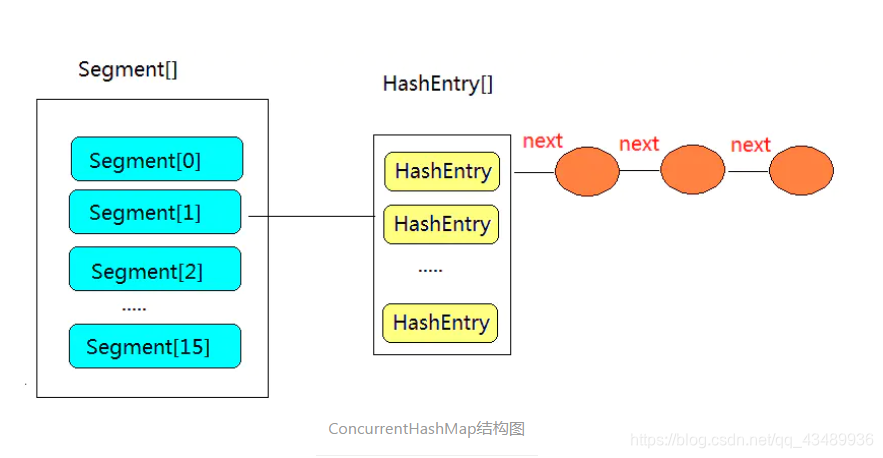
ConcurrentHashMap在进行put操作时,先通过key找到承载的Segment对象位置,然后竞争操作Segment的独占锁,以确保操作线程。获取锁方式很简单,就是tryLock(),如果获取锁失败,执行scanAndLockForPut方法
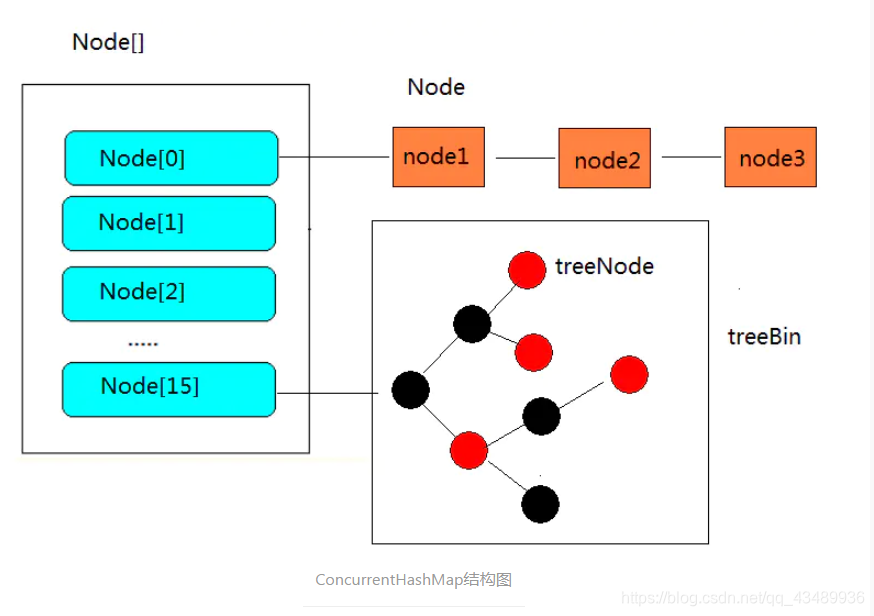
JAVA8以后:
jdk8直接抛弃了Segment的设计,采用了较为轻捷的Node + CAS + Synchronized设计,保证线程安全。
每一个节点,挂载一个链表,当链表挂载数据大于8时,链表自动转换成红黑树
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
//一个死循环,目的,并发情况下,也可以保障安全添加成功
//原理:cas算法的循环比较,直至成功
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
//第一次添加,先初始化node数组
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//计算出table[i]无节点,创建节点
//casTabAt : 底层使用Unsafe.compareAndSwapObject 原子操作table[i]位置,如果为null,则添加新建的node节点,跳出循环,反之,再循环进入执行添加操作
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
else if ((fh = f.hash) == MOVED)
//如果当前处于拓展状态,返回拓展后的tab,然后再进入循环执行添加操作
tab = helpTransfer(tab, f);
else {
//链表中或红黑树中追加节点
V oldVal = null;
//使用synchronized 对 f 对象加锁, 这个f = tabAt(tab, i = (n - 1) & hash) :table[i] 的node对象,并发环境保证线程操作安全
//此处注意: 这里没有ReentrantLock,因为jdk1.8对synchronized 做了优化,其执行性能已经跟ReentrantLock不相上下。
synchronized (f) {
if (tabAt(tab, i) == f) {
//链表上追加节点
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//红黑树上追加节点
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//节点数大于临界值,转换成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
- get方法不加锁;
- put、remove方法要使用锁
jdk7使用锁分离机制(Segment分段加锁)
jdk8使用cas + synchronized 实现锁操作 - Iterator对象的使用,运行一边更新,一遍遍历(可以根据原理自己拓展)
- 复合操作,无法保证线程安全,需要额外加锁保证
- 并发环境下,ConcurrentHashMap 效率较Collections.synchronizedMap()更高
(6)线程池的主要参数有哪些
- corePollSize:核心线程数。在创建了线程池后,线程中没有任何线程,等到有任务到来时才创建线程去执行任务。
- maximumPoolSize:最大线程数。表明线程中最多能够创建的线程数量。
- keepAliveTime:空闲的线程保留的时间。
- TimeUnit:空闲线程的保留时间单位。
- BlockingQueue:阻塞队列,存储等待执行的任务。参数有ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue可选。
- ThreadFactory:线程工厂,用来创建线程
- RejectedExecutionHandler:队列已满,而且任务量大于最大线程的异常处理策略。
(7)redis你都用来干啥,redis语法
- 会话缓存(最常用)
- 消息队列(支付)
- 活动排行榜或计数
- 发布,订阅消息(消息通知)
- 商品列表,评论列表
(8)nginx你都用来干啥
- 反向代理,配置跨域转发
- 负载均衡
- 动静分离
#web服务器
server {
listen 81; # 监听的端口
server_name localhost; # 域名或ip
location / { # 访问路径配置
root index;# 根目录
index index.html index.htm; # 默认首页
}
error_page 500 502 503 504 /50x.html; # 错误页面
location = /50x.html {
root html;
}
}
# 虚拟主机
server {
listen 80;
server_name www.lishaojun.com;
location / {
root cart;
index cart.html;
}
}
server {
listen 80;
server_name abc.lishaojun.com;
location / {
root search;
index search.html;
}
}
#反向代理+负载均衡
upstream tomcat-travel {
server 192.168.177.129:8080;
server 192.168.177.129:8081 weight=2;
server 192.168.177.129:8082;
}
server {
listen 80; # 监听的端口
server_name www.lishaojun.com; # 域名或ip
location / { # 访问路径配置
# root index;# 根目录
proxy_pass http://tomcat-travel; # 别名
index index.html index.htm; # 默认首页
}
error_page 500 502 503 504 /50x.html; # 错误页面
location = /50x.html {
root html;
}
}
(9)消息队列都干啥
- 异步: 使得业务流程中一些非主业务的内容,以消息队列的形式进行通知,使得主业务的相应时间在用户可以接受的范围内。
- 削峰
- 解耦:多线程也能实现异步,但是会每个业务都需要一个接口,导致很强的耦合性
(10)http 3xx代表什么
1、1xx状态码表消息状态码
这一类型的状态码,代表请求已被zhi接受,需要继续处理。dao这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束。由于 HTTP/1.0 协议中没有定义任何 1xx 状态码,所以除非在某些试验条件下,服务器禁止向此类客户端发送 1xx 响应。
2、2xx状态码表成功:
这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。
3、3xx状态码表重定向:
这些状态码用来重定向,后续的请求地址在本次响应的 Location 域中指明。当且仅当后续的请求所使用的方法是 GET 或者 HEAD 时,用户浏览器自动提交所需要的后续请求。
客户端应当自动监测无限循环重定向(例如:A->A,或者A->B->C->A),会导致服务器和客户端大量不必要的资源消耗。按照 HTTP/1.0 版规范的建议,浏览器不应自动访问超过5次的重定向。
4、4xx状态码表请求错误:
如果错误发生时客户端正在传送数据,那么使用TCP的服务器实现应当仔细确保在关闭客户端与服务器之间的连接之前,客户端已经收到了包含错误信息的数据包。
如果客户端在收到错误信息后继续向服务器发送数据,服务器TCP栈向客户端发送一个重置数据包,以清除该客户端所有还未识别的输入缓冲,以免这些数据被服务器上的应用程序读取并干扰后者。
5、5xx状态码表服务器错误:
服务器在处理请求的过程中有错误或者异常状态发生,也可能是服务器意识到以当前的软硬件资源无法完成对请求。除非这是一个HEAD 请求,否则服务器应当包含一个解释当前错误状态以及这个状况是临时的还是永久的解释信息实体。浏览器应当向用户展示任何在当前响应中被包含的实体。
(11)怎么重新部署一个tomcat的一个war
webapps
(12)你阅读过什么源码没?答:spring和springmvc,说了一点
(13)mysql建立索引的原则
- 选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。如果使用姓名的话,可能存在同名现象,从而降低查询速度。 - 为经常需要排序、分组和联合操作的字段建立索引
经常需要 ORDER BY、GROUP BY、DISTINCT 和 UNION 等操作的字段,排序操作会浪费很多时间。如果为其建立索引,可以有效地避免排序操作。 - 为常作为查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,为这样的字段建立索引,可以提高整个表的查询速度。
注意:常查询条件的字段不一定是所要选择的列,换句话说,最适合索引的列是出现在 WHERE 子句中的列,或连接子句中指定的列,而不是出现在 SELECT 关键字后的选择列表中的列。 - 限制索引的数目
索引的数目不是“越多越好”。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。在修改表的内容时,索引必须进行更新,有时还可能需要重构。因此,索引越多,更新表的时间就越长。 - 尽量使用数据量少的索引
如果索引的值很长,那么查询的速度会受到影响。例如,对一个 CHAR(100) 类型的字段进行全文检索需要的时间肯定要比对 CHAR(10) 类型的字段需要的时间要多。 - 数据量小的表最好不要使用索引
由于数据较小,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。 - 尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT 和 BLOG 类型的字段,进行全文检索会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。 - 删除不再使用或者很少使用的索引
- TCP的三次握手?为什么不是两次?TCP是如何进行流量控制的?如何进行拥塞控制的?使用哪几种机制?TCP/IP的五层协议模型和OSI的七层协议模型了解么?简单说一下,TCP协议在哪一层?
如果不采用三次握手,那么只要server发出确认报文,那么server认为新的连接就建立了,并一直等待client发来数据,这样server端的连接资源就被占用浪费了
流量控制:
TCP中的流量控制和拥塞控制不同,它只解决端到端之间的问题。往往是要通过降低发送端发送数据的速率,以便接收端能够处理,而不造成拥塞。
在TCP的首部,有一个标识窗口大小的16位字段,这个字段越大,说明滑动窗口(缓冲区越大),网络的吞吐量也就越大。接收端在收到ACK请求之后,也会把自己的窗口大小填进去,回应发送端,两端取一个最小的窗口尺寸进行数据发送。如果,接收端这边网络拥堵,状况不佳,那么这个窗口就可以动态的减小。如果网络特别通常,也可动态增加。
16位的窗口最大,2^16-1 = 65535字节 约64K。
当然在TCP首部控制位中还有一个CWR,它可以收缩窗口。
总结以下,两个字段,一个是 窗口大小,另一个是CWR(congestion window reduced 拥塞窗口减少)
窗口大小 = min(发送端窗口大小,接收端窗口大小)
拥塞控制:
- 慢开始
- 快重传
- 快恢复
- java里边有哪些集合类?介绍了List、Set和Map,Vector是如何实现线程安全的?Synchronized是如何实现线程安全的?Synchronized这个锁如何实现线程安全的?知道volatile这个关键字么?简单说一下(这部分需要再深入理解一下),volatile的底层如何实现的?
synchronized:
字节码层面,monitorenter指令进入同步块 ,monitorexit指令退出同步块
JAVA中有许多的集合,常用的有List,Set,Queue,Map
volatile:
- 内存可见性:保证了变量的可见性(visibility)。被volatile关键字修饰的变量,如果值发生了变更,其他线程立马可见,避免出现脏读的现象。(不能保证操作的原子性)
- 防止指令重排
3、Spring用过它的AOP么?什么功能使用过AOP?切面是如何实现的?动态***实现AOP(基于类和接口即CGlib和jdk动态***的具体过程?)
4、java里的类加载器有哪些?用的web容器是什么?tomcat的类加载机制是什么?
- 启动类加载器(Bootstrap ClassLoader)
这个类加载器负责将存放在JAVA_HOME/lib下的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的类库加载到虚拟机内存中。启动类加载器无法被Java程序直接引用。 - 扩展类加载器(Extension ClassLoader)
这个加载器负责加载JAVA_HOME/lib/ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器 - 应用程序类加载器(Application ClassLoader)
这个加载器是ClassLoader中getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(Classpath)上所指定的类库,可直接使用这个加载器,如果应用程序没有自定义自己的类加载器,一般情况下这个就是程序中默认的类加载器
当JVM运行过程中,用户需要加载某些类时,会按照下面的步骤(父类委托机制):
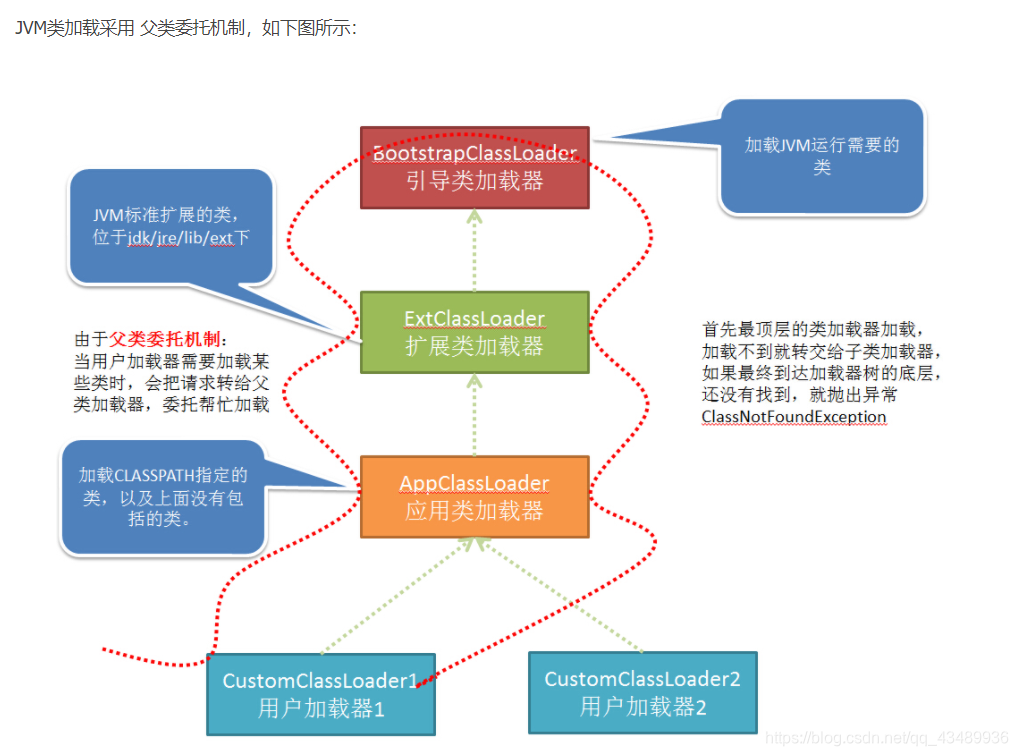
- 用户自己的类加载器,把加载请求传给父加载器,父加载器再传给其父加载器,一直到加载器树的顶层。
- 最顶层的类加载器首先针对其特定的位置加载,如果加载不到就转交给子类。
- 如果一直到底层的类加载都没有加载到,那么就会抛出异常ClassNotFoundException。
因此,按照这个过程可以想到,如果同样在CLASSPATH指定的目录中和自己工作目录中存放相同的class,会优先加载CLASSPATH目录中的文件。
Tomcat:
当应用需要到某个类时,则会按照下面的顺序进行类加载:
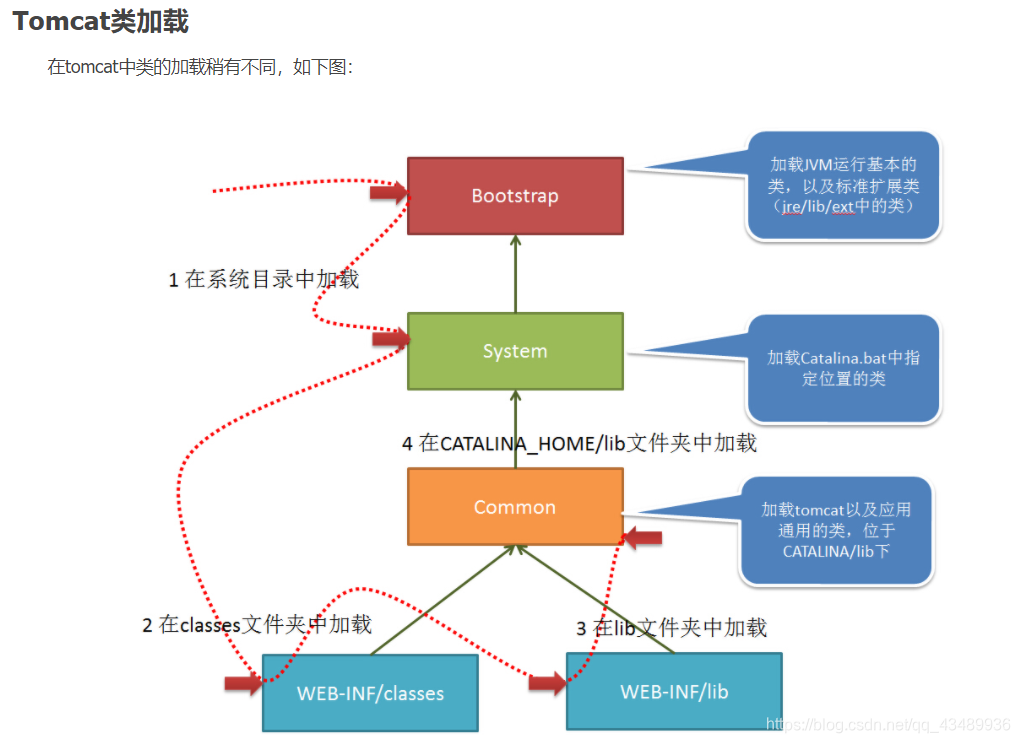
- 使用bootstrap引导类加载器加载
- 使用system系统类加载器加载
- 使用应用类加载器在WEB-INF/classes中加载
- 使用应用类加载器在WEB-INF/lib中加载
- 使用common类加载器在CATALINA_HOME/lib中加载
5、Spring mvc的一个完整请求流程是什么?从输入网址到按下回车整个过程是什么?HTTP和HTTPS的区别是什么?
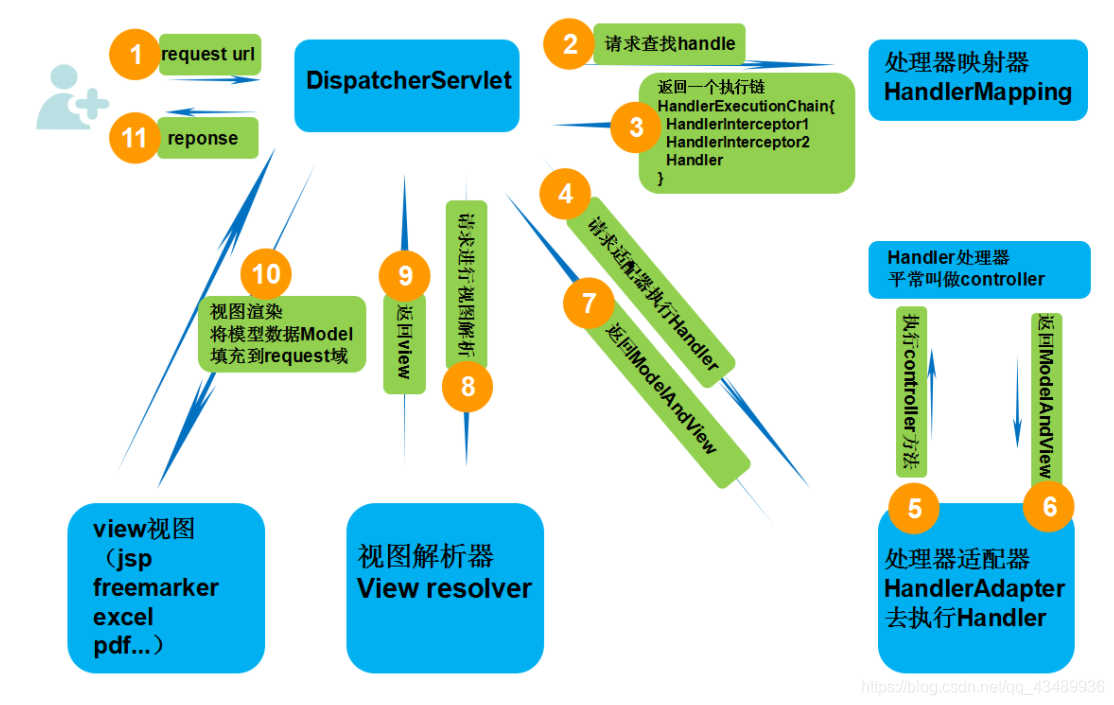
- DispatcherServlet前端控制器接收发过来的请求,交给HandlerMapping处理器映射器
- HandlerMapping处理器映射器,根据请求路径找到相应的HandlerAdapter处理器适配器(处理器适配器就是那些拦截器或Controller)
- HandlerAdapter处理器适配器,处理一些功能请求,返回一个ModelAndView对象(包括模型数据、逻辑视图名)
- ViewResolver视图解析器,先根据ModelAndView中设置的View解析具体视图
- 然后再将Model模型中的数据渲染到View上
这些过程都是以DispatcherServlet为中轴线进行的。
从输入网址到按下回车整个过程是什么?
- 域名解析。(先查找本地DNS缓存列表,没有的话再向默认的DNS服务器发送查询请求并缓存)
- 发起TCP的3次握手。(TCP只能连接,发送数据必须使用HTTP)
- 建立TCP连接后发起http请求。
- 服务器端响应http请求,浏览器得到相应资源。
- 浏览器解析资源,并不断重复上述请求过程,直到所有资源请求完毕。
- 浏览器对页面进行渲染呈现。
HTTP和HTTPS的区别?
- https 协议需要到 ca 申请证书,目前市面上的免费证书也不少,收费的也都比较贵。
- http 是超文本传输协议,信息是明文传输,https 则是具有安全性的 ssl 加密传输协议。
- http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
- http 的连接很简单,是无状态的;HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全。
6、mysql数据库的隔离级别?mysql的隔离级别是如何实现的??mysql里边有哪几种索引?答的是组合索引、唯一索引、聚集索引、非聚集索引?索引失效的情况?where子句里如果只对A进行大小判断(非like),并且索引只有A,一定会走索引么?
四种隔离基本:
- Read Uncommitted(读取未提交内容)
- Read Committed(读取提交内容)
- Repeatable Read(可重读)
- Serializable(可串行化)
出现的问题:
- 脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
- 不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
- 幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就有几列数据是未查询出来的,如果此时插入和另外一个事务插入的数据,就会报错。
在MySQL中,实现了这四种隔离级别,分别有可能产生问题如下所示:
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
有哪几种索引?
Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE。
索引失效的情况:
1.有or必全有索引;
2.复合索引未用左列字段;
3.like以%开头;
4.需要类型转换;
5.where中索引列有运算;
6.where中索引列使用了函数;
7.如果mysql觉得全表扫描更快时(数据少);
不一定走索引,根据记录的数量判断是否走索引。
7、涉及到的技术栈:Spring boot 、Springcloud、mybatis
一面 60min
自我介绍
hashmap concurrenthashmap
多线程
线程池
aqs
平衡二叉搜索树
项目
spring ioc aop理解
hash算法
一致性hash
分布式 微服务的了解
cap base
二面 20min
自我介绍
项目介绍
让你带团队 要加快进度 项目周期缩短一半怎么做
对代码质量怎么看
职业规划
期望薪资 base 其他offer
下午oc 给了base 薪资相关情况 三天内回复
面的有点久了 都是Java常规问题 当时没记 能想到就这些了
1、自我介绍;
2、说一下怎么学习Collection下的集合类,和IO操作的;
3、代码:读取D盘下字符串文件的第三行;
4、代码:使用深度优先搜索遍历二叉树;
5、代码:使用深度优先搜索遍历D盘下的所有文件夹;
6、上面的代码都不会写,就写了一段快排(快排谢天谢地终于写对了);
7、问了一下项目的问题
如何实现项目的注册问题;
项目如何实现用户唯一性检验:这里回答了在创建MySQL表时,使用unqiue关键字保证用户名的唯一性。使用unique key保证数据的唯一性;
项目的部署;
项目开发中遇到的问题:回答了高并发使用Redis缓存机制;
反问:
需要提升的地方:
基础基础基础
学习能力的展示
对JDK一定要熟悉
8.06 11:40 30min左右
日常自我介绍
盘比赛,参加比赛难点在哪?
数据库了解吗?怎么学习的?除了MySQL还学过什么?
事务隔离级别?可重复度怎么实现的?
varchar和char区别?什么时候使用哪个?
java怎么学习的?有没有完整看过一套教学视频?jdk用的什么版本?
lamda表达式怎么实现的?
Spring IOC好处?
Spring AOP
MyBatis的$和#区别
最近作息时间是怎样的?
了解用友吗?
接受996吗?(太直白了)
然后介绍了一下用友
日常反问。。。。。。。。。。
java基础问的不多
面试官人很好很和蔼,技术问穿插着闲聊,给人很舒服感觉。。。。。。
1.问项目,问项目,问项目,项目太烂 没办法 ps 只写了部分题目
2.spring boot的启动类
3. mybatis的底层原理
4. spring的aop
用友Java开发
- 自我介绍
- 针对简历内容的提问
- 说说Java GC
- 如何减少Full GC的次数
- 对Java集合类熟悉吗?说说set , HashMap这些的应用场景
- 对多线程了解? 如果有一个线程要等待其他线程都结束,怎么做?
- 缓存,说说redis的哨兵机制;平时怎么用redis的?存在redis和HashMap的区别?
- SSM框架,Spring中怎么实现事务控制的?
- 写题:约瑟夫问题
剑指 Offer 62. 圆圈中最后剩下的数字
0,1,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
class Solution {
public int lastRemaining(int n, int m) {
int ans = 0;
// 最后一轮剩下2个人,所以从2开始反推
for (int i = 2; i <= n; i++) {
ans = (ans + m) % i;
}
return ans;
}
}
- 反问
全程30分钟左右,面试官态度很nice,面试过程比较轻松,问题属于想到什么问什么的那种~
第一次在牛客上发面经的帖子,开始攒rp啦😀
乱序 只记得这么多了
1.自我介绍 介绍项目
2java反射 class.forName()加载类和使用classLoader加载类的区别
(Class.forName加载类是将类进行了初始化,而ClassLoader的loadClass并没有对类进行初始化,只是把类加载到了虚拟机中。)
在java中Class.forName()和ClassLoader都可以对类进行加载。ClassLoader就是遵循双亲委派模型最终调用启动类加载器的类加载器,实现的功能是“通过一个类的全限定名来获取描述此类的二进制字节流”,获取到二进制流后放到JVM中。Class.forName()方法实际上也是调用的CLassLoader来实现的。
3mysql索引 项目中用了哪些
4redis在秒杀项目中作用
5 如何保证redis中数据都是热点数据(内存淘汰机制)
6redis集群
7Mybatis与Hibernate有哪些不同
8Mybatis和JDBC编程对比
9# 和$符号区别
10mybatis动态sql
11springboot启动原理?
12hashmap底层实现 hashcode equals方法 不重写equals会怎样
重写了equals方法,不重写hashCode方法时,可能会出现equals方法返回为true,而hashCode方法却返回不同的结果。
反问
求个二面
1.介绍自己(我在这简单的讲了讲我的项目,可能项目太简单,我就只是说了一下逻辑,面试官也没细问)
2.说一下JVM相关的东西(GC)了解新生代老生代吗
3了解HashMap吗,HashSet呢
4.讲一下进程线程
进程是资源分配的最小单位,线程是CPU调度的最小单位
5.怎么样能让两个线程依次进行完,在进行其他操作
- 使用join:
join作用是:如果某个线程调用join方法,优先执行完该线程,才能够执行其它线程。 - 使用单线程池:
6.一个数组排序给了一个表,学生姓名和学生成绩,按成绩排序,java中有没有现成的方法
因此我们需要去重写一个compareTo方法,重写这个方法的时候应该要继承一个接口Comparable。
Arrays.sort(array, new Comparator<Person3>(){
//传入的时候由用户自己选
@Override
public int compare(Person3 o1, Person3 o2) {
// TODO Auto-generated method stub
int age1 = o1.getAge();
int age2 = o2.getAge();
return age1 > age2 ? age1:(age1==age2) ? 0:-1;
}
});
问的问题都很泛,感觉完全要看自己知道的有多深,浅层的内容大部分都能说出来。全程大概30分钟,面试官人也好nice~
面试官人很好 没有让我撕代码
许愿二面😉
项目介绍(id token)
数据库索引
索引失效的情况
char—varchar 除了索引失效还有什么问题
线程池使用的注意事项
你所知道的设计模式
spring的设计模式
spring用到了那些代理模式
那些类设计为单例模式
突然接到电话,看了下用友。然后加了qq 说面试。我赶紧开了电脑 插上耳机等候。第一次面试挺紧张。
1.自我介绍:巴拉巴拉 介绍了在校做的三个项目。从由来以及项目解决的问题聊了聊。
2.说一下缓存的
3.微服务的理解 从为什么项目的模块划分入手谈了谈。以及微服务解决的问题。
4.本地缓存与分布式缓存的区别
本地缓存相对于分布式缓存较少了网络IO 和磁盘IO) 这块我问了面试官 可以说一下自己对缓存的理解吗。从前端缓存->正向代理缓存->反向代理缓存->本地缓存->分布式缓存->sql query cache 说了一遍。
5.JVM内存模型
线程私有和线程共享 两个方面入手。
6.垃圾回收算法
垃圾回收算法 对象被标记为垃圾的标志。1.引用计数 2.可达性分析
垃圾回收算法 1.标记清除 2.标志整理 3.复制算法 4.分代收集(这块具体说了说)
7.类加载机制
类加载机制 忘了Bootstrap appStrap classStrap 有点紧张 忘了appStrap 。
分析了一下如果 我们自定义java.lang.String的带来的问题。这个应该加分了
8.算法题
1.一个正整数 n,将其拆分为至少两个正整数的和,返回这些整数的最大乘积。
利用动态规划的思路。用一个数组dp[n + 1]保存每个数字拆分后乘积最大的值。然后 dp[i] 应该等于每一次试探的最大值。意思就是:每一个数字都应该为dp[i - j] * j 或者 j * (i - j)中较大的那个。因为得走很多趟,因此还要记录每一趟得最大值,因此代码中用了两个max函数。代码如下:
class Solution {
public int integerBreak(int n) {
int[] dp = new int[n + 1];
dp[2] = 1;
for (int i = 2; i <= n; i++) {
for (int j = 1; j < i; j++) {
dp[i] = Math.max(dp[i], Math.max(j * dp[i - j], j * (i - j)));
}
}
return dp[n];
}
}
dp做
2.给定一组 互不相同 的单词, 找出所有不同 的索引对(i, j),使得列表中的两个单词, words[i] + words[j] ,可拼接成回文串。
https://leetcode-cn.com/problems/palindrome-pairs/solution/hui-wen-dui-by-leetcode-solution/
都是力扣原题。只说了暴力解思路。dp和trie 我承认我菜。
9.加班接收吗,原则上接收。
10.反问 算法需要加强。
11.接受实习刚开始只做业务方面的事情吗,我说没问题。因为技术本来就是服务于业务的,业务去创造价值。
12.平时怎么学习的,对于一个默认的技术,我一般不会盲目学习,我会先去看一下这个技术是什么,然后了解一下 为什么会出现这个技术 解决了那些问题,然后看博客简单上手,然后看书籍。
春招实习 参考意义不大
数据结构中的堆是什么?有什么用途?
树的中序遍历如果不用递归用什么数据结构实现?
关键路径知道吗,说说?
数据库中的范式有哪些?
数据库事务是什么?事务的实现有哪些(例如Spring中实现事务?)
Java中的集合类有哪些了解?
HashMap的原理?怎么通过key找到value的值?Hash的应用?
Java中的类加载顺序?
Java中的多态?
讲一下你简历中的一个项目吧?
在项目中遇到的最大问题是什么?
有什么需要问我的吗?
1、压缩字符串
比如“aaabbbcaaa” ,压缩成“a3b3c1a3”;
如果压缩后的长度不是小于等于原字符串长度,就返回原字符串
class Solution {
public int compress(char[] chars) {
int anchor = 0, write = 0;
for (int read = 0; read < chars.length; read++) {
if (read + 1 == chars.length || chars[read + 1] != chars[read]) {
chars[write++] = chars[anchor];
if (read > anchor) {
for (char c: ("" + (read - anchor + 1)).toCharArray()) {
chars[write++] = c;
}
}
anchor = read + 1;
}
}
return write;
}
}
2、上下反转二维数组
比如
{[1,2,3],[4,5,6],[7,8,9]}
反转后为{[7,8,9],[4,5,6],[1,2,3]}
3.
787. K 站中转内最便宜的航班
有 n 个城市通过 m 个航班连接。每个航班都从城市 u 开始,以价格 w 抵达 v。
现在给定所有的城市和航班,以及出发城市 src 和目的地 dst,你的任务是找到从 src 到 dst 最多经过 k 站中转的最便宜的价格。 如果没有这样的路线,则输出 -1。
https://leetcode-cn.com/problems/cheapest-flights-within-k-stops/solution/k-zhan-zhong-zhuan-nei-zui-bian-yi-de-hang-ban-b-2/