文章目录
前言
最近有个需求,就是需要在项目中,初始添加的信息后,将详情页面导出为word文档,下载下来可以继续编辑。一开始考虑word的样式,字体等问题,使用开源的Apache POI,在保存为word内容时候,样式基本上会丢失,导致导出后的文档样式和在页面上看的不太一样,会出现错位等情况,希望使用商业版的word处理工具,比如Aspose Words或者Spire.Doc for Java(Spire.Doc for Java 中文教程)非常专业,功能非常强大。但是付费商业方案被否了,后来推荐直接导出为PDF格式,这样后端基本上也不用处理,导出PDF后,使用Adobe Acrobat在转换成Word即可,最后给了一个方案就是页面保存为markdown格式内容到数据库,然后下载时候,后端将markdown转换为word即可。
首先添加java处理的相关依赖:
<!-- excel工具 练习的项目自身的依赖-->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.2</version>
</dependency>
<!-- 新添加的依赖-->
<!-- markdown格式转换为html -->
<dependency>
<groupId>org.commonmark</groupId>
<artifactId>commonmark</artifactId>
<version>0.21.0</version>
</dependency>
<!-- poi-tl和poi-tl-plugin-markdown是处理markdown格式转换为word格式,处理只处理markdown转换为html,只需要commonnark依赖即可-->
<dependency>
<groupId>com.deepoove</groupId>
<artifactId>poi-tl</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>com.deepoove</groupId>
<artifactId>poi-tl-plugin-markdown</artifactId>
<version>1.0.3</version>
</dependency>
编写工具类
import com.deepoove.poi.XWPFTemplate;
import com.deepoove.poi.config.Configure;
import com.deepoove.poi.data.style.*;
import com.deepoove.poi.plugin.markdown.MarkdownRenderData;
import com.deepoove.poi.plugin.markdown.MarkdownRenderPolicy;
import com.deepoove.poi.plugin.markdown.MarkdownStyle;
import lombok.experimental.UtilityClass;
import lombok.extern.slf4j.Slf4j;
import org.apache.poi.xwpf.usermodel.XWPFTable;
import org.apache.poi.xwpf.usermodel.XWPFTableCell;
import org.commonmark.node.Node;
import org.commonmark.parser.Parser;
import org.commonmark.renderer.html.HtmlRenderer;
import org.springframework.core.io.ClassPathResource;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Map;
/**
* @author xiaomifeng1010
* @version 1.0
* @date: 2024-08-24 17:23
* @Description
*/
@UtilityClass
@Slf4j
public class MarkdownUtil {
/**
* markdown转html
*
* @param markdownContent
* @return
*/
public String markdownToHtml(String markdownContent) {
Parser parser = Parser.builder().build();
Node document = parser.parse(markdownContent);
HtmlRenderer renderer = HtmlRenderer.builder().build();
String htmlContent = renderer.render(document);
log.info(htmlContent);
return htmlContent;
}
/**
* 将markdown格式内容转换为word并保存在本地
*
* @param markdownContent
* @param outputFileName
*/
public void toDoc(String markdownContent, String outputFileName) {
log.info("markdownContent:{}", markdownContent);
MarkdownRenderData code = new MarkdownRenderData();
code.setMarkdown(markdownContent);
MarkdownStyle style = MarkdownStyle.newStyle();
style = setMarkdownStyle(style);
code.setStyle(style);
// markdown样式处理与word模板中的标签{{md}}绑定
Map<String, Object> data = new HashMap<>();
data.put("md", code);
Configure config = Configure.builder().bind("md", new MarkdownRenderPolicy()).build();
try {
// 获取classpath
String path = MarkdownUtil.class.getClassLoader().getResource("").getPath();
log.info("classpath:{}", path);
//由于部署到linux上后,程序是从jar包中去读取resources下的文件的,所以需要使用流的方式读取,所以获取流,而不是直接使用文件路径
// 所以可以这样获取 InputStream resourceAsStream = MarkdownUtil.class.getClassLoader().getResourceAsStream("");
// 建议使用spring的工具类来获取,如下
ClassPathResource resource = new ClassPathResource("markdown" + File.separator + "markdown_template.docx");
InputStream resourceAsStream = resource.getInputStream();
XWPFTemplate.compile(resourceAsStream, config)
.render(data)
.writeToFile(path + "out_markdown_" + outputFileName + ".docx");
} catch (IOException e) {
log.error("保存为word出错");
}
}
/**
* 将markdown转换为word文档并下载
*
* @param markdownContent
* @param response
* @param fileName
*/
public void convertAndDownloadWordDocument(String markdownContent, HttpServletResponse response, String fileName) {
log.info("markdownContent:{}", markdownContent);
MarkdownRenderData code = new MarkdownRenderData();
code.setMarkdown(markdownContent);
MarkdownStyle style = MarkdownStyle.newStyle();
style = setMarkdownStyle(style);
code.setStyle(style);
// markdown样式处理与word模板中的标签{{md}}绑定
Map<String, Object> data = new HashMap<>();
data.put("md", code);
Configure configure = Configure.builder().bind("md", new MarkdownRenderPolicy()).build();
try {
fileName=URLEncoder.encode(fileName, StandardCharsets.UTF_8.name());
//由于部署到linux上后,程序是从jar包中去读取resources下的文件的,所以需要使用流的方式读取,所以获取流,而不是直接使用文件路径
// 所以可以这样获取 InputStream resourceAsStream = MarkdownUtil.class.getClassLoader().getResourceAsStream("");
// 建议使用spring的工具类来获取,如下
ClassPathResource resource = new ClassPathResource("markdown" + File.separator + "markdown_template.docx");
InputStream resourceAsStream = resource.getInputStream();
response.setHeader("Content-Disposition", "attachment; filename=" + URLEncoder.encode(fileName, "UTF-8") + ".docx");
// contentType不设置也是也可以的,可以正常解析到
response.setContentType("application/vnd.openxmlformats-officedocument.wordprocessingml.document;charset=utf-8");
XWPFTemplate template = XWPFTemplate.compile(resourceAsStream, configure)
.render(data);
template.writeAndClose(response.getOutputStream());
} catch (IOException e) {
log.error("下载word文档失败:{}", e.getMessage());
}
}
/**
* 设置转换为word文档时的基本样式
* @param style
* @return
*/
public MarkdownStyle setMarkdownStyle(MarkdownStyle style) {
// 一定设置为false,不然生成的word文档中各元素前边都会加上有层级效果的一串数字,
// 比如一级标题 前边出现1 二级标题出现1.1 三级标题出现1.1.1这样的数字
style.setShowHeaderNumber(false);
// 修改默认的表格样式
// table header style(表格头部,通常为表格顶部第一行,用于设置列标题)
RowStyle headerStyle = new RowStyle();
CellStyle cellStyle = new CellStyle();
// 设置表格头部的背景色为灰色
cellStyle.setBackgroundColor("cccccc");
Style textStyle = new Style();
// 设置表格头部的文字颜色为黑色
textStyle.setColor("000000");
// 头部文字加粗
textStyle.setBold(true);
// 设置表格头部文字大小为12
textStyle.setFontSize(12);
// 设置表格头部文字垂直居中
cellStyle.setVertAlign(XWPFTableCell.XWPFVertAlign.CENTER);
cellStyle.setDefaultParagraphStyle(ParagraphStyle.builder().withDefaultTextStyle(textStyle).build());
headerStyle.setDefaultCellStyle(cellStyle);
style.setTableHeaderStyle(headerStyle);
// table border style(表格边框样式)
BorderStyle borderStyle = new BorderStyle();
// 设置表格边框颜色为黑色
borderStyle.setColor("000000");
// 设置表格边框宽度为3px
borderStyle.setSize(3);
// 设置表格边框样式为实线
borderStyle.setType(XWPFTable.XWPFBorderType.SINGLE);
style.setTableBorderStyle(borderStyle);
// 设置普通的引用文本样式
ParagraphStyle quoteStyle = new ParagraphStyle();
// 设置段落样式
quoteStyle.setSpacingBeforeLines(0.5d);
quoteStyle.setSpacingAfterLines(0.5d);
// 设置段落的文本样式
Style quoteTextStyle = new Style();
quoteTextStyle.setColor("000000");
quoteTextStyle.setFontSize(8);
quoteTextStyle.setItalic(true);
quoteStyle.setDefaultTextStyle(quoteTextStyle);
style.setQuoteStyle(quoteStyle);
return style;
}
public static void main(String[] args) {
String markdownContent = "# 一级标题\n" +
"## 二级标题\n" +
"### 三级标题\n" +
"#### 四级标题\n" +
"##### 五级标题\n" +
"###### 六级标题\n" +
"## 段落\n" +
"这是一段普通的段落。\n" +
"## 列表\n" +
"### 无序列表\n" +
"- 项目1\n" +
"- 项目2\n" +
"- 项目3\n" +
"### 有序列表\n" +
"1. 项目1\n" +
"2. 项目2\n" +
"3. 项目3\n" +
"## 链接\n" +
"[百度](https://www.baidu.com)\n" +
"## 图片\n" +
"\n" +
"## 表格\n" +
"| 表头1 | 表头2 | 表头3 |\n" +
"|-------|-------|-------|\n" +
"| 单元格1 | 单元格2 | 单元格3 |\n" +
"| 单元格4 | 单元格5 | 单元格6 |";
toDoc(markdownContent, "test23");
}
}
这个代码是初步版本,导出的文档直接保存在了本地,初步测试成功。如果运行main方法测试报错,比如这样:

提示找不到xx方法,是因为新添加的poi-tl依赖的版本问题,因为项目是使用的ruoyi脚手架的版本比较古老,项目本身依赖的poi版本比较旧是4.X版本,所以将poi-tl版本降低一点就行了,比如使用1.10.1版本,然后再次运行就成功了

转换markdown到word过程中,首先需要一个word模板,实际上还是用markdown内容经过markdown渲染器渲染后的内容去填充word模版中的占位符{{md}}
word模版可以从poi-tl项目的官方github仓库下载:
https://github.com/Sayi/poi-tl/tree/master/poi-tl-plugin-markdown/src/test/resources
将这个markdown文件夹放在本项目的resources目录下就可以了
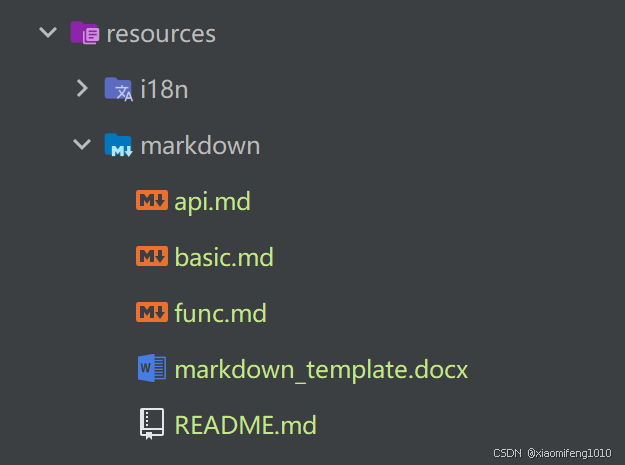
里边有5个文件,其中4个md文件主要是为了测试使用的,word文件是用于渲染的模版
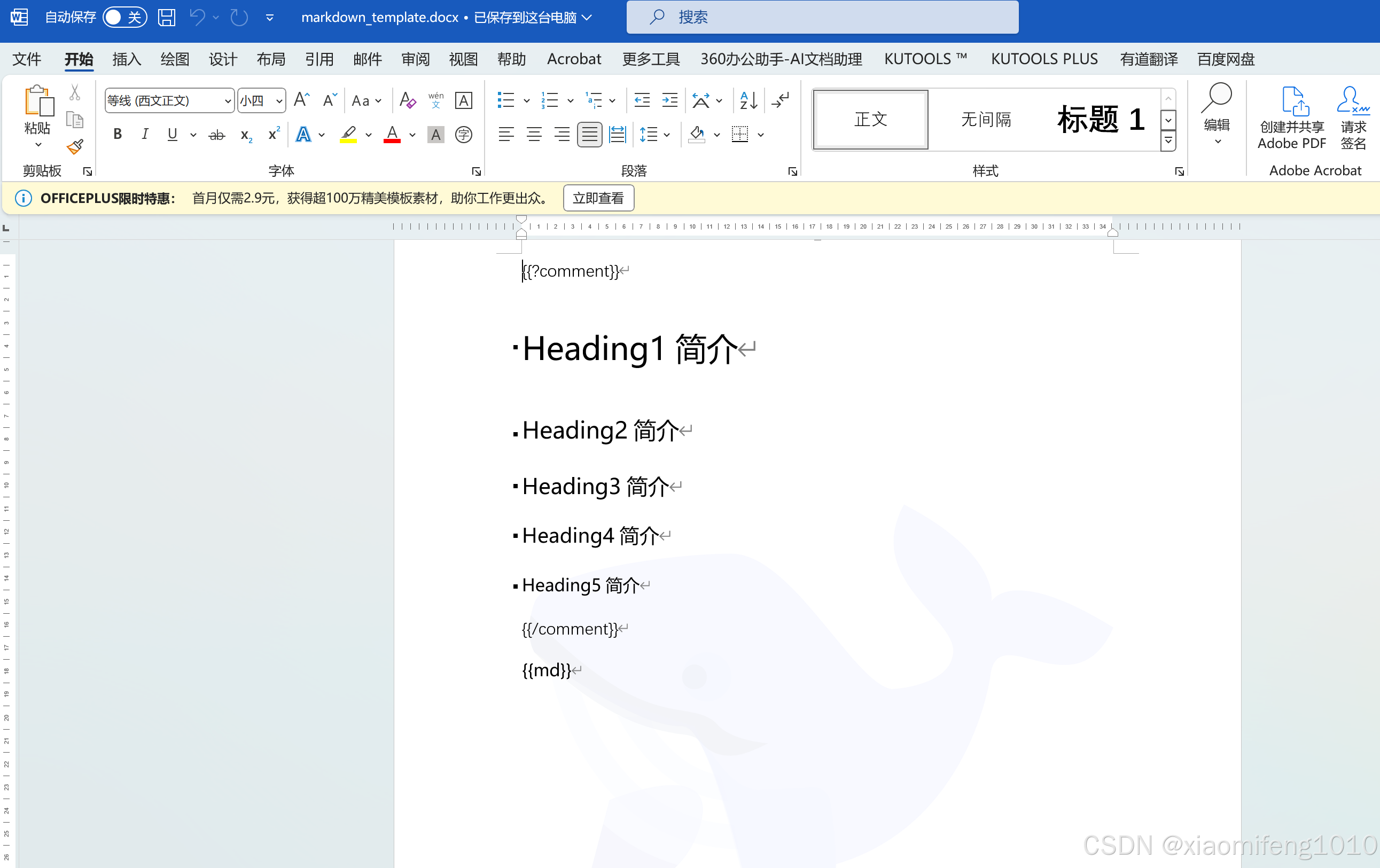
内容是这样的:
然后执行刚才工具类中main方法成功后,在项目target下就会生成一个新的渲染markdown内容填充后的word文档
内容为这样:
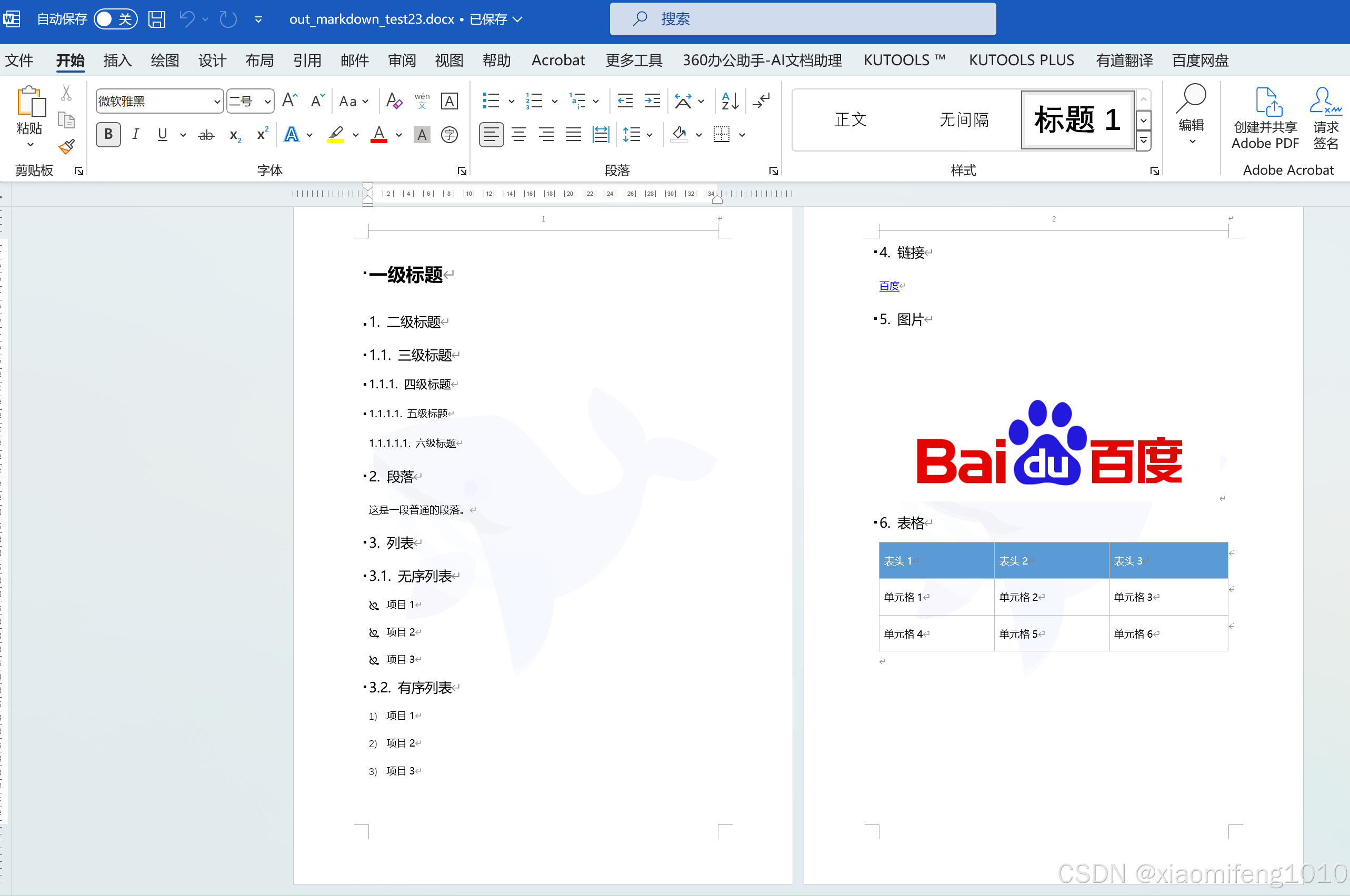
生成的效果还不错。
如果你直接用md文件测试,而不是使用一段md格式的字符串,测试方法可以参考官方的测试方法:
package com.deepoove.poi.plugin.markdown; import java.nio.file.Files;import java.nio.file.Paths;import java.util.HashMap;import java.util.Map; import com.deepoove.poi.XWPFTemplate;import com.deepoove.poi.config.Configure; public class MarkdownTest { public static void testMarkdown(String name) throws Exception { MarkdownRenderData code = new MarkdownRenderData(); byte[] bytes = Files.readAllBytes(Paths.get("src/test/resources/markdown/" + name + ".md")); String mkdn = new String(bytes); code.setMarkdown(mkdn); MarkdownStyle style = MarkdownStyle.newStyle(); style.setShowHeaderNumber(true); code.setStyle(style); Map<String, Object> data = new HashMap<>(); data.put("md", code); Configure config = Configure.builder().bind("md", new MarkdownRenderPolicy()).build(); XWPFTemplate.compile("src/test/resources/markdown/markdown_template.docx", config) .render(data) .writeToFile("target/out_markdown_" + name + ".docx"); } public static void main(String[] args) throws Exception { testMarkdown("api"); testMarkdown("func"); testMarkdown("README"); } }
实际项目中是需要web导出下载word文件的,所以在接口调用的时候,需要修改成输出流的方式就可以了。具体使用方法可以参考官方中文文档:Poi-tl Documentation
不过今天访问不了了,网站挂掉了,昨天还是可以正常访问的

现在直接提示这个,不知道什么原因,可能过几天就可以正常访问了 ,还有就是模版文件中有个海豚的背景,项目中使用不想要这个背景,可以在word文档中去掉
通过菜单栏【设计】->【水印】->【删除水印】即可
如果出现错误 No valid entries or contents found, this is not a valid OOXML (Office Open XML) file
Unexpected record signature: 0X9|
在pom.xml的中添加这一部分。
<build>
<resources>
<!--
这段配置的作用是将 src/main/resources 目录下的所有文件复制到构建目录中,
但排除了 .xlsx、.xls、.zip 和 .pdf 文件,并在复制过程中启用了资源过滤。
-->
<resource>
<directory>src/main/resources</directory>
<!-- 表示将包含哪些文件 **/* 表示所有子目录及所有文件 -->
<includes>
<include>**/*</include>
</includes>
<!-- 表示将排除哪些文件 -->
<excludes>
<exclude>**/*.xlsx</exclude>
<exclude>**/*.xls</exclude>
<exclude>**/*.zip</exclude>
<exclude>**/*.pdf</exclude>
</excludes>
<!-- 开启资源过滤 -->
<filtering>true</filtering>
</resource>
<!--
这段配置的作用是将 src/main/resources 目录下的 .xlsx、.xls、.zip 和 .pdf 文件,复制到构建目录中并在复制过程中关闭资源过滤。
-->
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.xlsx</include>
<include>**/*.xls</include>
<include>**/*.zip</include>
<include>**/*.pdf</include>
</includes>
<!-- 关闭资源过滤 -->
<filtering>false</filtering>
</resource>
</resources>
</build>
或者使用maven-resources-plugin插件来帮我们在进行资源过滤时,不要对指定扩展名的文件进行过滤。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<!--排除的不需要资源过滤的文件后缀名列表-->
<nonFilteredFileExtensions>
<nonFilteredFileExtension>xlsx</nonFilteredFileExtension>
<nonFilteredFileExtension>xls</nonFilteredFileExtension>
<nonFilteredFileExtension>zip</nonFilteredFileExtension>
<nonFilteredFileExtension>pdf</nonFilteredFileExtension>
</nonFilteredFileExtensions>
</configuration>
</plugin>