文章目录
一、初识Zookeeper
Zookeeper是大数据生态中的分布式协调服务,用于配置管理、分布式锁、集群管理和生成分布式唯一ID等
1.1、基本概念
Zookeeper 是 Apache Hadoop 项目下的一个子项目,是一个树形目录服务。
Zookeeper 翻译过来就是动物园管理员,他是用来管 Hadoop(大象)、Hive(蜜蜂)、Pig(小猪)的管理员。简称zk。
1.2、应用场景
1.2.1、维护配置信息
Java编程经常会遇到配置项,例如数据库的user、password等,通常配置信息会放在配置文件中,再把配置文件放在服务器上。当需要修改配置信息时,要去服务器上修改对应的配置文件,但在分布式系统中很多服务器都需要使用该配置文件,因此必须保证该配置服务的高可用性和各台服务器上配置的一致性。通常会将配置文件部署在一个集群上,但一个集群涉及的服务器数量是很庞大的,如果一台台服务器逐个修改配置文件是效率很低且危险的,因此需要一种服务可以高效快速且可靠地完成配置项的更改工作。
zookeeper就可以提供这种服务,使用Zab一致性协议保证一致性。在开源消息队列Kafka中,也使用zookeeper来维护broker的信息。在dubbo中也广泛使用zookeeper管理一些配置来实现服务治理。
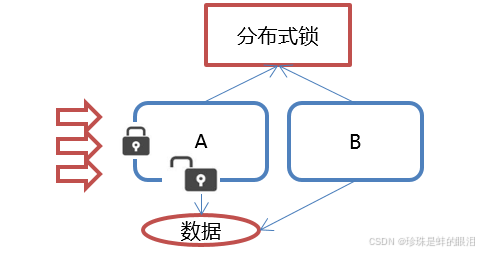
1.2.2、分布式锁服务
一个集群是一个分布式系统,由多台服务器组成。为了提高并发度和可靠性,在多台服务器运行着同一种服务。当多个服务在运行时就需要协调各服务的进度,有时候需要保证当某个服务在进行某个操作时,其他的服务都不能进行该操作,即对该操作进行加锁。
1.2.3、集群管理
zookeeper会将服务器加入/移除的情况通知给集群中其他正常工作的服务器,以及即使调整存储和计算等任务的分配和执行等,此外zookeeper还会对故障的服务器做出诊断并尝试修复。
1.2.4、生成分布式唯一ID
在过去的单库单表系统中,通常使用数据库字段自带的auto_increment属性自动为每条记录生成一个唯一的id。但分库分表后就无法依靠该属性来标识一个唯一的记录。此时可以使用zookeeper在分布式环境下生成全局唯一性id。每次要生成一个新id时,创建一个持久顺序结点,创建操作返回的结点序号,即为新id,然后把比自己结点小的删除。
二、Zookeeper基础
2.1、Zookeeper数据模型
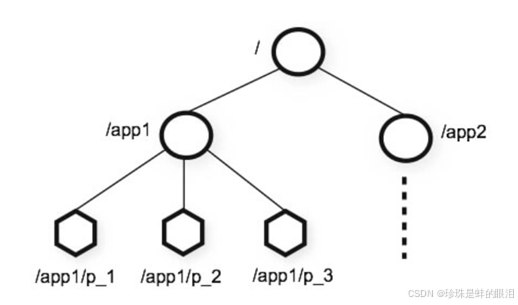
ZooKeeper 是一个树形目录服务,其数据模型和Unix的文件系统目录树很类似,拥有一个层次化结构。这里面的每一个节点都被称为: ZNode,每个节点上都会保存自己的数据和节点信息,这与UNIX有所不同。下图是UNIX的文件系统结构,它的目录结点上只能存储文件,文件中才能存储数据。
下面是zookeeper数据模型示例图:
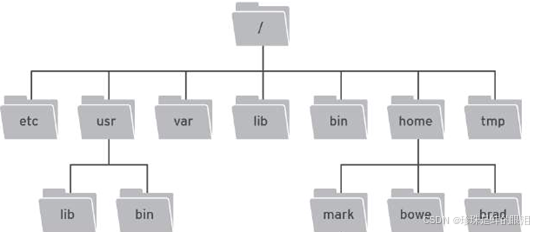
- 节点可以拥有子节点,同时也允许少量(1MB)数据存储在该节点之下。
2.2、Zookeeper节点类型
ZooKeeper中的节点类型主要分为四种:持久节点(Persistent)、持久顺序节点(Persistent Sequential)、临时节点(Ephemeral)、临时顺序节点(Ephemeral Sequential)。
- 持久节点(Persistent)
这是最常见的节点类型。创建后,除非显示删除,否则该节点将一直存在于ZooKeeper中。即使创建节点的客户端断开连接,节点也不会被删除。这种类型的节点适合存储永久性数据,例如配置信息、系统参数等。 - 持久顺序节点(Persistent Sequential)
这种节点类型与持久节点类似,但会在节点名称后面自动添加一个单调递增的序号,用于保持节点的顺序。这种类型的节点在创建后也不会被自动删除,除非显式删除。持久顺序节点常用于分布式系统中的节点注册,保持节点的顺序。 - 临时节点(Ephemeral)
临时节点的生命周期与创建它的客户端会话(session)绑定。如果创建临时节点的客户端会话结束(例如客户端与ZooKeeper服务器的连接断开),那么这个节点就会被自动删除。临时节点适合用于表示临时状态或临时任务。 - 临时顺序节点(Ephemeral Sequential)
这种节点类型结合了临时节点和顺序节点的特点。它会在节点名称后面自动添加一个单调递增的序号,并且在创建它的客户端会话结束后自动删除。这种类型的节点常用于实现分布式队列或者分布式锁。
2.3、Zookeeper操作命令
2.3.1、Zookeeper客户端操作
一般可以利用客户端或JavaAPI操作zookeeper,服务端和客户端都有一些操作命令(比如创建结点,修改结点,删除结点,查看结点等),可以点击学习。
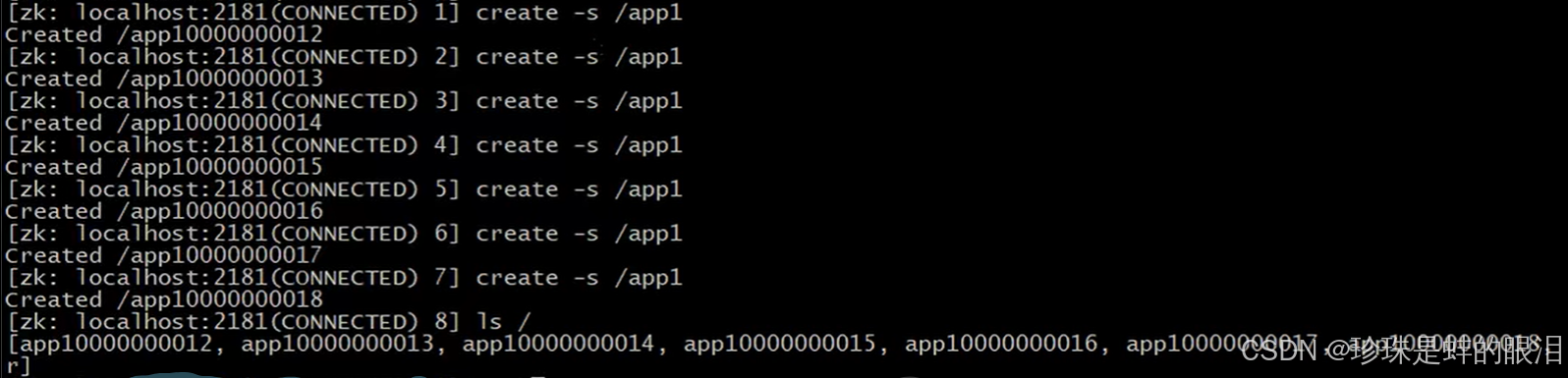
创建有序结点及效果:
2.3.2、Java API 操作
常见的ZooKeeper Java API :
- 原生Java API
- ZkClient
- Curator
Curator 项目的目标是简化 ZooKeeper 客户端的使用。Curator 最初是 Netfix 研发的,后来捐献了 Apache 基金会,目前是 Apache 的顶级项目。目前还没有zookeeper编码的需要,后续再点击学习。
三、Zookeeper进阶
3.1、Watch事件监听
ZooKeeper 允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
ZooKeeper 中引入了Watcher机制来实现了发布/订阅功能,能够让多个订阅者同时监听某一个对象(一个或多个结点),当一个对象自身状态变化时,会通知所有订阅者。
Curator引入了 Cache 来实现对 ZooKeeper 服务端事件的监听。ZooKeeper提供了三种Watcher:
- NodeCache : 只是监听某一个特定的节点。
- PathChildrenCache : 监控一个ZNode的子节点(不包括此ZNode)。
- TreeCache : 可以监控整个树上的所有节点(从某个结点起的:此结点+此结点的所有子结点),类似于PathChildrenCache和NodeCache的组合。
3.2、分布式锁
在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized或者Lock的方式来解决多线程间的代码同步问题,这时多线程的运行都是在同一个JVM之下,没有任何问题。
但当我们的应用是分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题(A1加锁对A2是不起作用的)。
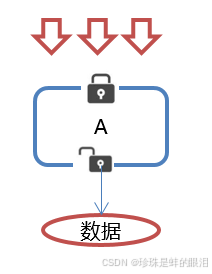
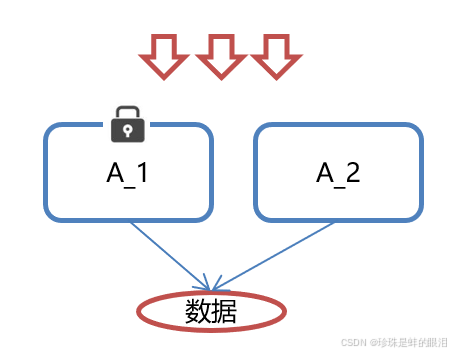
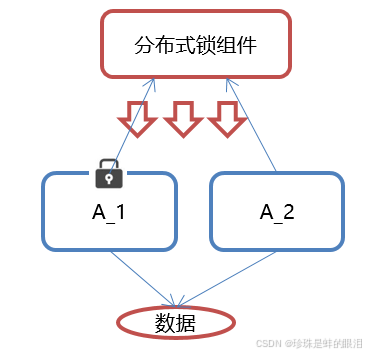
那么就需要一种更加高级的锁机制,来处理这种跨机器的进程之间的数据同步问题——这就是分布式锁(说白了就是利用公共资源实现锁)。
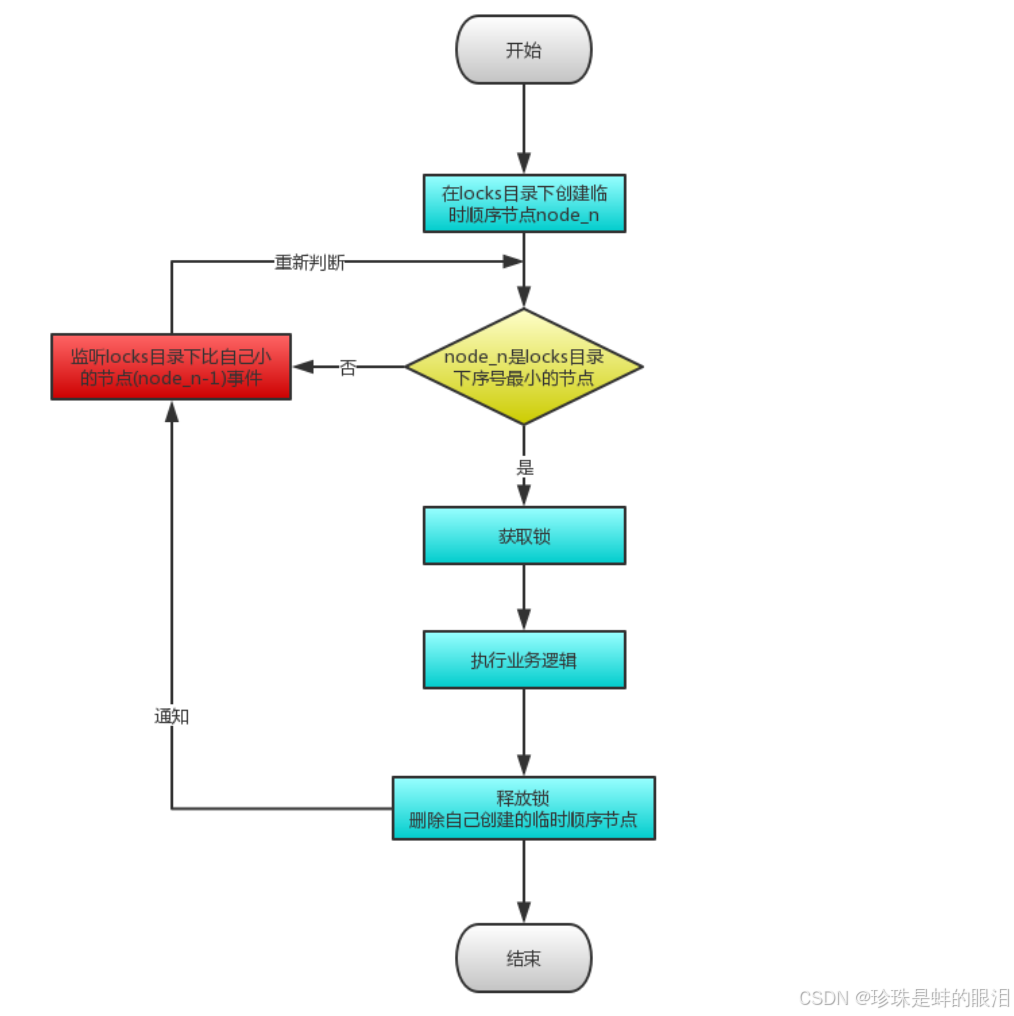
ZooKeeper分布式锁原理,核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点。
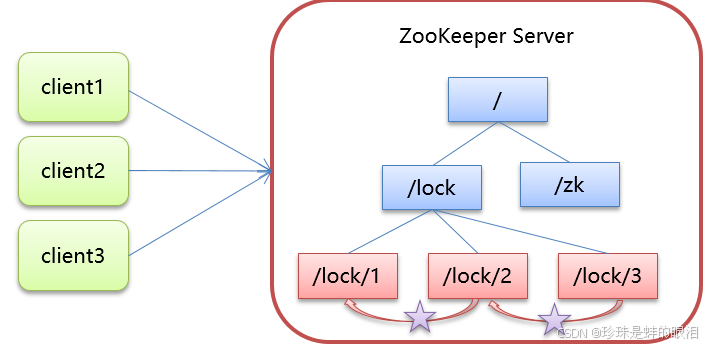
- 多个客户端获取锁时,在lock节点下创建临时顺序节点。
- 然后获取lock下面的所有子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
- 如果发现自己创建的节点并非lock所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小且紧邻的那个节点,同时对其注册事件监听器,监听删除事件。
- 如果发现比自己小的那个节点被删除,则客户端的 Watcher会收到相应通知,此时再次判断自己创建的节点 是否是lock子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的且紧邻一个节点 并注册监听。
比如client1、client2、client3对应的结点分别是/lock/1、/lock/2和/lock/3,则client1会拿到锁,client2会监视/lock/1的删除事件,client3会监视/lock/2的删除事件。
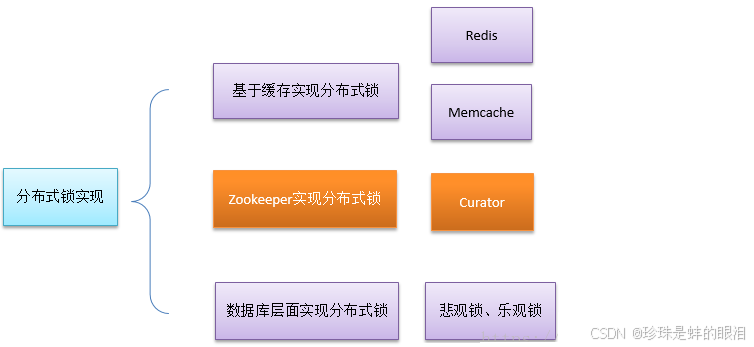
当然实现分布式锁可以有以下几种方式:
3.3、Zookeeper集群
目前工作中还未接触Zookeeper的应用,后续有需要再学习。