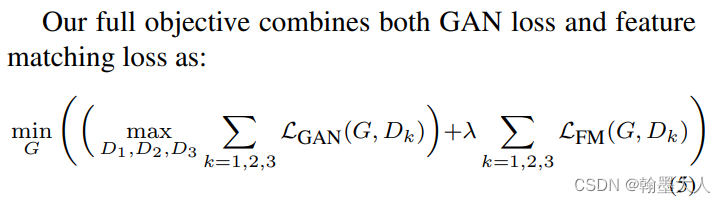High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
pix2pixHD提出了一个模型用于从label map中生成真实的photo。
pix2pixHD都是使用的CGAN的思想,不同的是本文可以产生更加高清的图像,pix2pix生成的是256x256,pix2pixHD可以产生2048x1024大小的图片。这个新的方法包括:一个创新的对抗损伤,多尺度生成器和辨别器。同时结合物体的实例分割,可以对图片的物体进行增删改等,同时给定一个相同的输入,可以产生不同的输出。

本文讨论一种新的方法用于从语义标签中生成高分辨率图片,这种方法应用十分广泛,例如用合成的数据用于训练视觉识别算法,使用语义分割方法可以将图片转换为标签,编辑标签里面的物体,可以将标签再转换为图片。使用pix2pix可以进行图像到图像之间的翻译,但是pix2pix被认为在训练时候不够稳定,并且不能产生高分辨率图片。
这里我们解决两个问题,(1)通过GAN生成高分辨率图片,(2)高分辨率图片缺少细节和真实的纹理。首先通过对抗训练获得我们的结果,然后我们展示添加感知损失可以在一些情况下提升结果。为了支持交互式的语义控制,我们首先使用instance-level的分割信息,他可以将相同的类别的不同物体分离开。接着提出一个方法用于给定形同的标签产生不同的结果。
相关工作:
(1)GAN,之前已经介绍过了。
(2)Image to image translation,对抗学习是广为使用的方法,相比于L1损失更容易产生模糊的边界,对抗损失是一个比较普遍的选择。因为辨别器可以学习一个可训练的损失函数,可以自动用于产生的图片和真实的图片之间。
(3)深度视觉控制,作者专注于物体级别的语义编辑,允许用户可以和整个场景进行交互,并且控制图片中的单独物体。
实例层次的合成:
首先回顾一下pix2pix,接着展示如何让图片更加真实,然后使用额外的实例层次的物体语义分割进一步提升图片的质量,最后引入实例层次的特征编码去更好处理图片合成的多模态特征。
(1)pix2pix baseline
回忆一下,pix2pix没有使用噪声,生成器使用的UNet,在decoder前三层使用的Dropout来增加随即性,且在验证时候不能使用model.eval,否则会关闭dropout和bn。辨别器采用的patchGAN,就是一个全卷积网络。
(2)提高图片真实性和分辨率
使用一个coarse to fine的生成器和多尺度辨别器以及一个坚固的对抗损失函数。
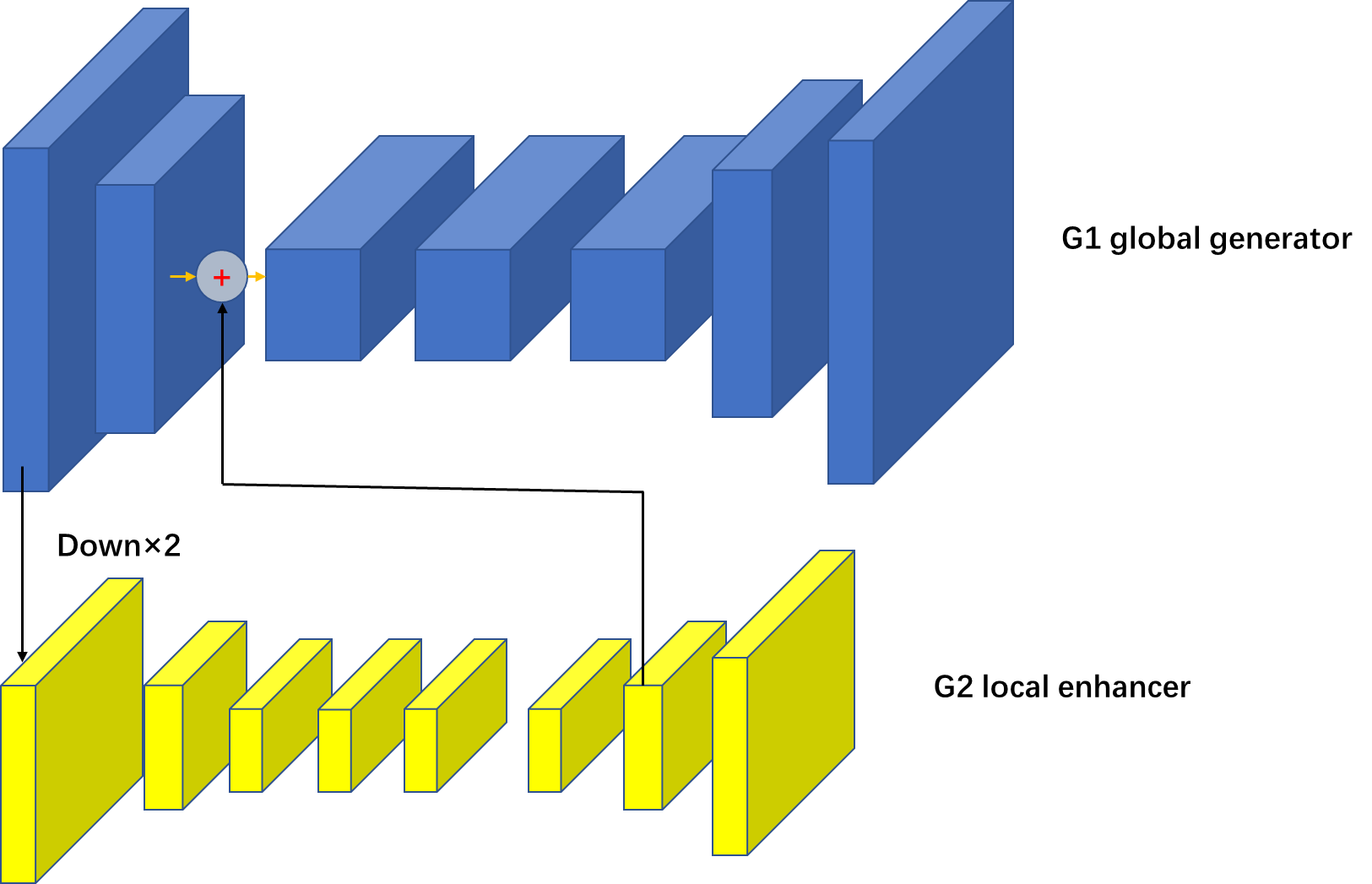
首先看生成器:看到coarse to fine首先就想到了cascade psp网络。生成器由两个子网络G1,G2组成,我们将G1叫做全局生成网络。G2叫做局部增强网络。G1输入为512x1024,G2输出的图片为1024x2048.
对于G1输入是512x1024,输出是512x1024。G2的输入是1024x2048,G2F和G1B的特征图逐像素相加输入到G2R。
在训练时候,首先训练全局生成器,再训练局部增强器,最后共同finetune两个网络。我们使用这种生成器可以有效的聚合全局和局部信息,这样多分辨率的pipline两个分辨率就够了。
多尺度辨别器:为了分辨高分辨率图片,辨别器需要有一个更大的感受野,为了减少参数且预防过拟合,这里使用了多尺度辨别器,三个具有相同结构的辨别器作用于三个不同的尺寸,具体表现在下采样真实的和合成的高分辨率2倍和4倍,这样就有三个尺寸的真实图片和三个尺寸的合成图片。作用于最粗糙尺度的辨别器具有最大的感受野,他对图片有一个全局视角可以引导生成器生成全局的连续图片。作用于最精细尺度的辨别器鼓励生成器产生更精细的细节。
新的目标函数变为一个多任务问题:
(3)提高对抗损失
在辨别器上增加了一个特征匹配损失,具体体现在提取辨别器的多层特征,并且学习去匹配这些中间层的特征。
最终的目标函数:
使用示例图:
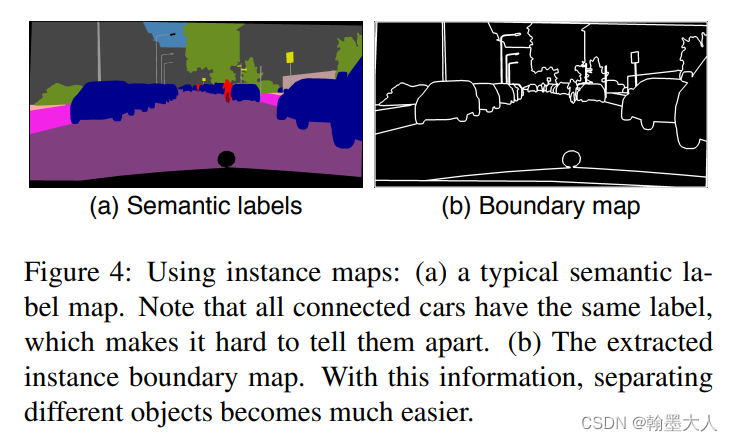
仅仅使用语义分割图无法辨别那些相同种类的物体,一个实例语义图对每一个单独的物体都有一个特别的ID,如何结合示例图,方法一可以直接输入到网络中,或者将它编码成独热编码,但是因为每个类别都包含有许多的物体。作者认为实例图提供最有用的信息是物体的边界。如何两个相同类别的物体是紧挨着的话,语义图是无法将他们分辨开的。实例图就可以。
因此提取边界信息,如果它和周围的四个临近ID不相同,那么它就为1,否则为0.(之前写过)。经过边界提取后再和经过one-hot编码的语义标签图concat1在一起。两个图都是由0,1组成的二值图,Ciityscape有19类,编码后19个通道,加实例边缘图一共20个通道。
学习实例层的特征编码:
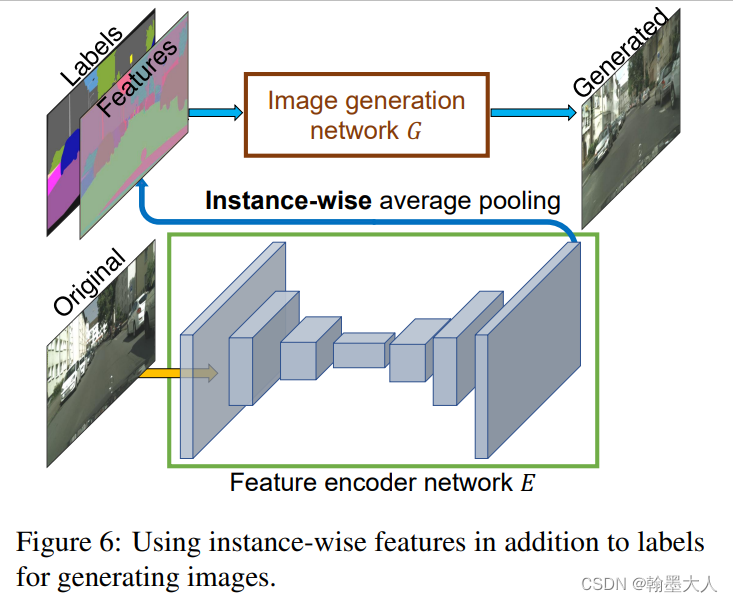
一个理想的图像合成算法可以产生多种多样,且真实的图片,作者提出添加一个额外的低维特征通道作为生成器的输入。通过控制这些特征,我们可以灵活控制图像和合成进程。为了产生低位特征,我们训练一个encoder网络E去寻找与真实GT对应的低维特征向量。为了保证实例特征都是连续的,我们在encoder输出添加一个逐实例平均池化层去计算实例的平均特征。
平均特征然后广播到实例的所有像素。
我们首先共同训练生成器,辨别器和encoder,接着将所有训练的实例输入到训练好的encoder中,然后对每一个语义种类使用K-means聚类,每一个聚类将特征编码为一个特别的风格。在推理阶段,随机挑选一个聚类来编码特征。这些特征和标签图拼接在一起用作生成器的输入。对每一个实例,我们呈现k种模式可供选择。
结果: