目录
1 正则表达式概述
正则表达式,又称规则表达式。(Regular Expression),在代码中常简写为regex、regexp或RE。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式不只有一种,而且Linux中不同的程序可能会使用不同的正则表达式,工具:grep、sed、awk、egrep
1.1 正则表达式定义
正则表达式,又称正规表达式、常规表达式
使用字符串来描述、匹配一系列符合某个规则的字符串
1.1.1 正则表达式组成
- 普通字符:大小写字母、数字、标点符号及一些其他符号
- 元字符:在正则表达式中具有特殊意义的专用字符
元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
2 基础正则表达式元字符
| 常见的元字符 | |
| \ | 转义字符,\!、\n等 |
| ^ | 匹配字符串开始的位置 |
| $ | 匹配字符串结束的位置 |
| . | 匹配除\n之外的任意的一个字符 |
| * | 匹配前面子表达式0次或多次 |
| [ ] | 匹配列表中的一个字符 |
| [^ ] | 匹配任意不在列表中的一个字符(取反) |
| \{n,m\} | 匹配前面的子表达式n到m次,有\{\n}、\{n,\}、\{n,m\}三种格式 |
| + | 匹配前面子表达式1次以上 |
| ? | 匹配前面子表达式0次或者1次 |
| () | 将括号中的字符串作为一个整体 |
| | | 以或的方式匹配字条串 |
3 常见管道命令
3.1 grep
grep [选项] … 查找条件 目标文件
| 常用选项 | |
| -E | 开启扩展(Extend)的正则表达式 |
| -c | 计算找到 “搜寻字符串” 的次数 |
| -i | 忽略大小写的不同,所有大小写视为相同 |
| -o | 只显示被模式匹配到的字符串 |
| -v | 反向选择(反向查找,输出与查找条件不相符的行) |
| -n | 顺序输出行号 |
例1
方法一

方法二

例2

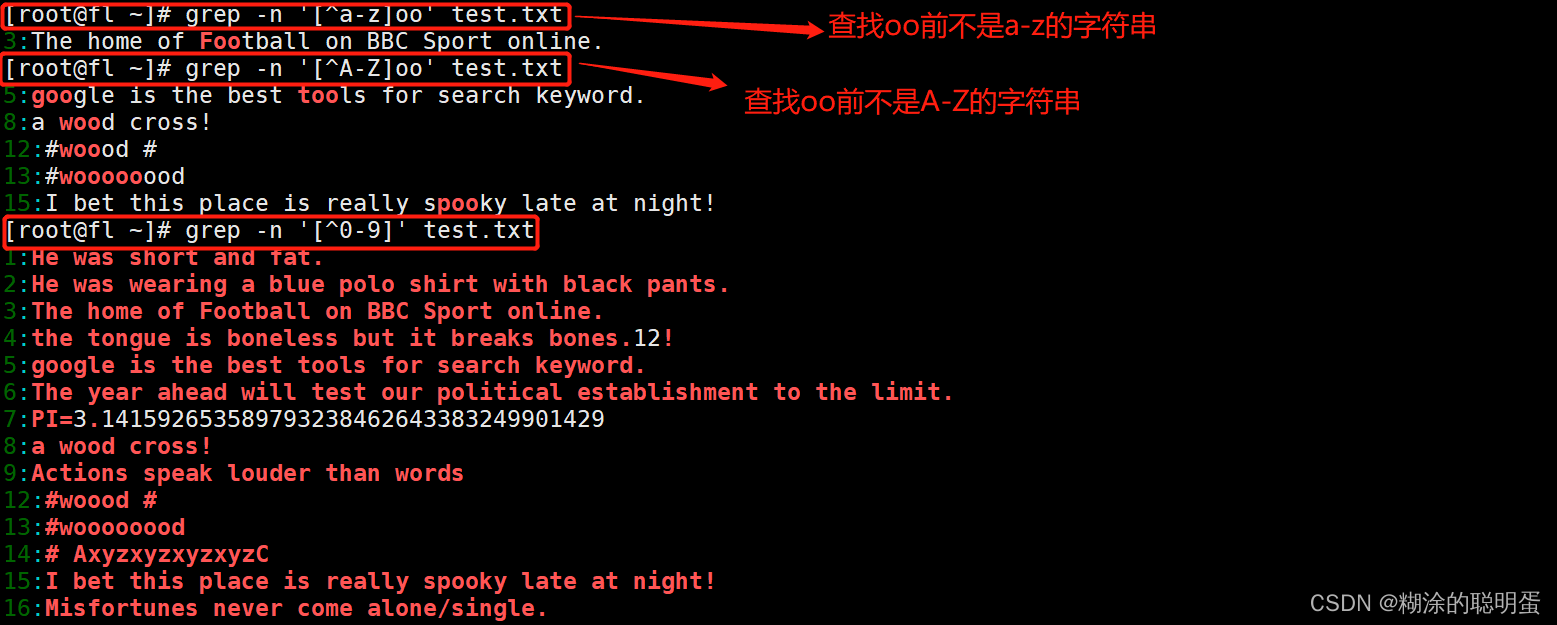
例3

例4

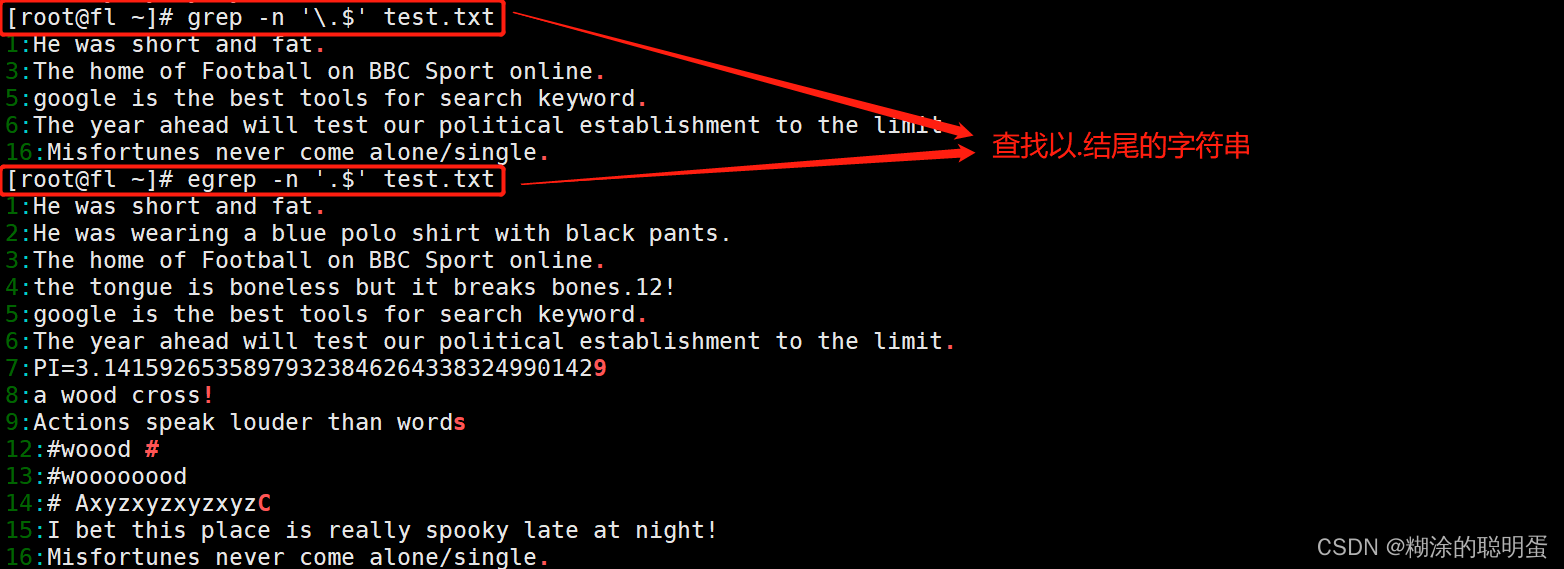
例5

例6


例7



3.2 cut(列截取工具)
cut命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字串写至标准输出
格式:cut [选项] 参数
| 常用选项 | |
| -b | 按字节截取 |
| -c | 按字符截取,常用于中文 |
| -d | 指定以什么为分隔符截取,默认为制表符 |
| -f | 通常和-d一起 |
例1
方法一

方法二


例2

例3


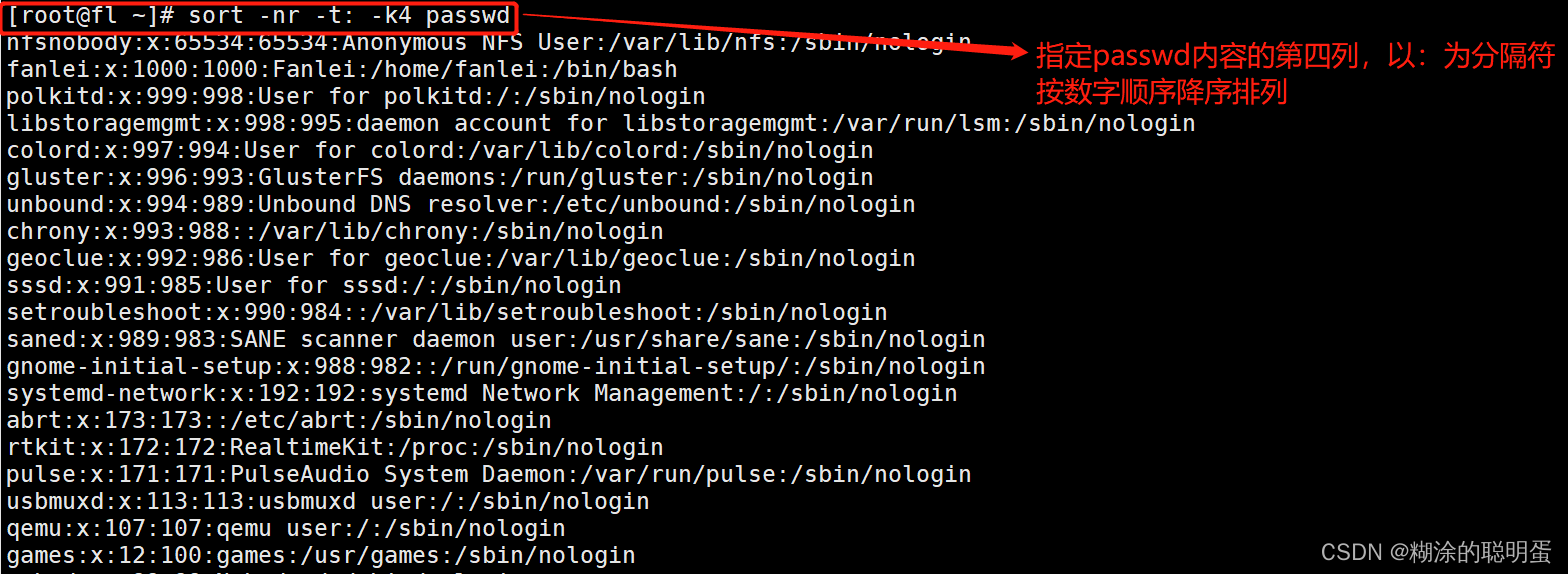
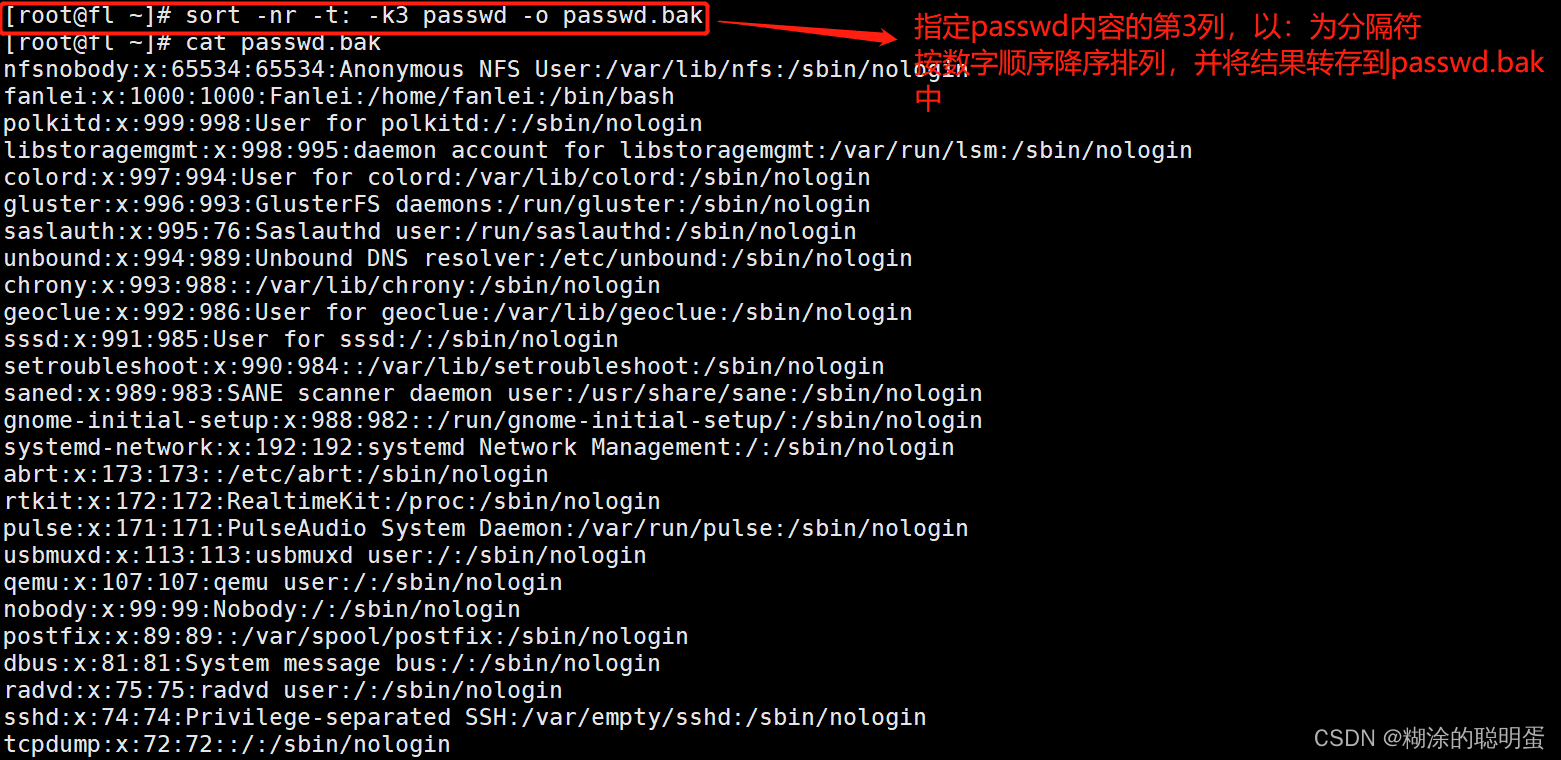
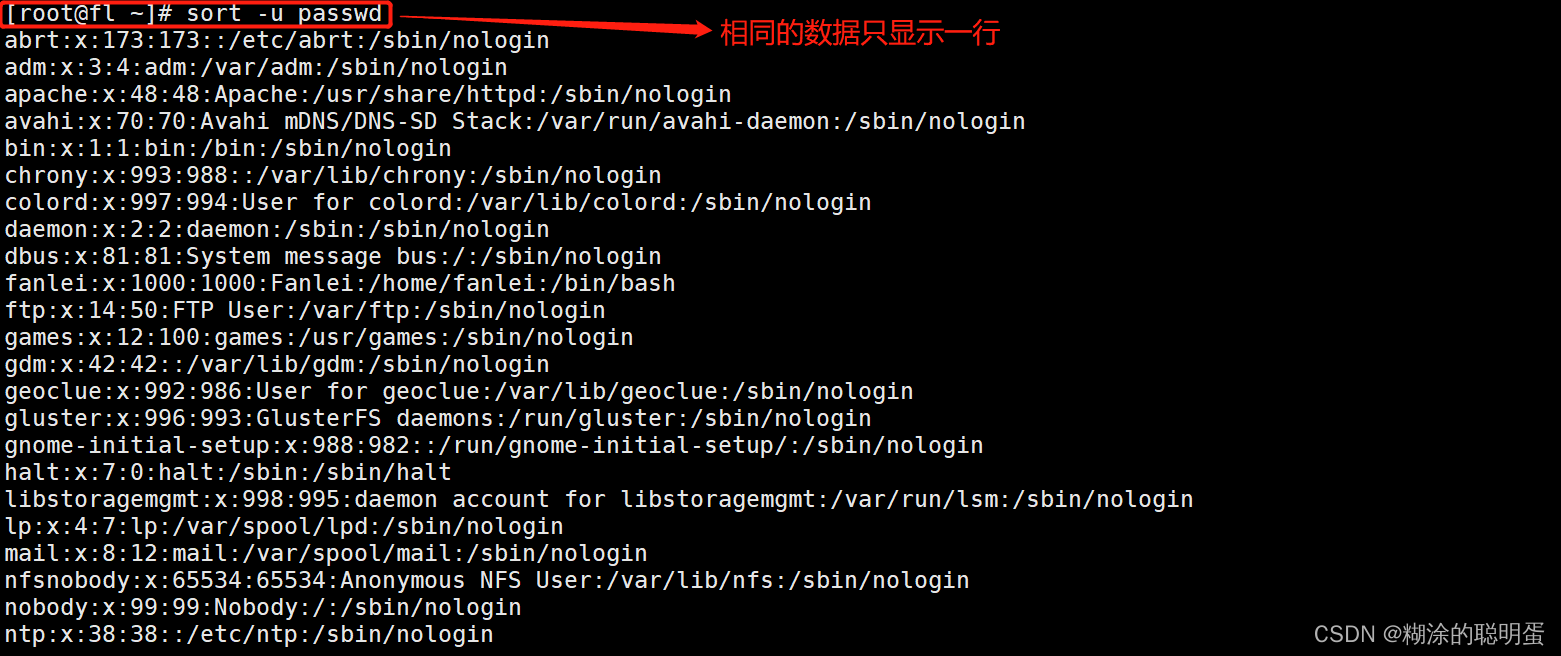
3.3 sort
sort是一个以行为单位对文件内容进行排序的工具
格式:sort [选项] 参数
| 常用选项 | |
| -t | 指定分隔符,默认使用[Tab]键或空格分割 |
| -k | 指定排序区域 |
| -n | 按照数字进行排序,默认是以文字形式排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行。(注意:如果行尾有空格去重就不成功) |
| -r | 反向排序,默认是升序,-r是降序 |
| -o | 将排序后的结果转存至指定文件 |
例1
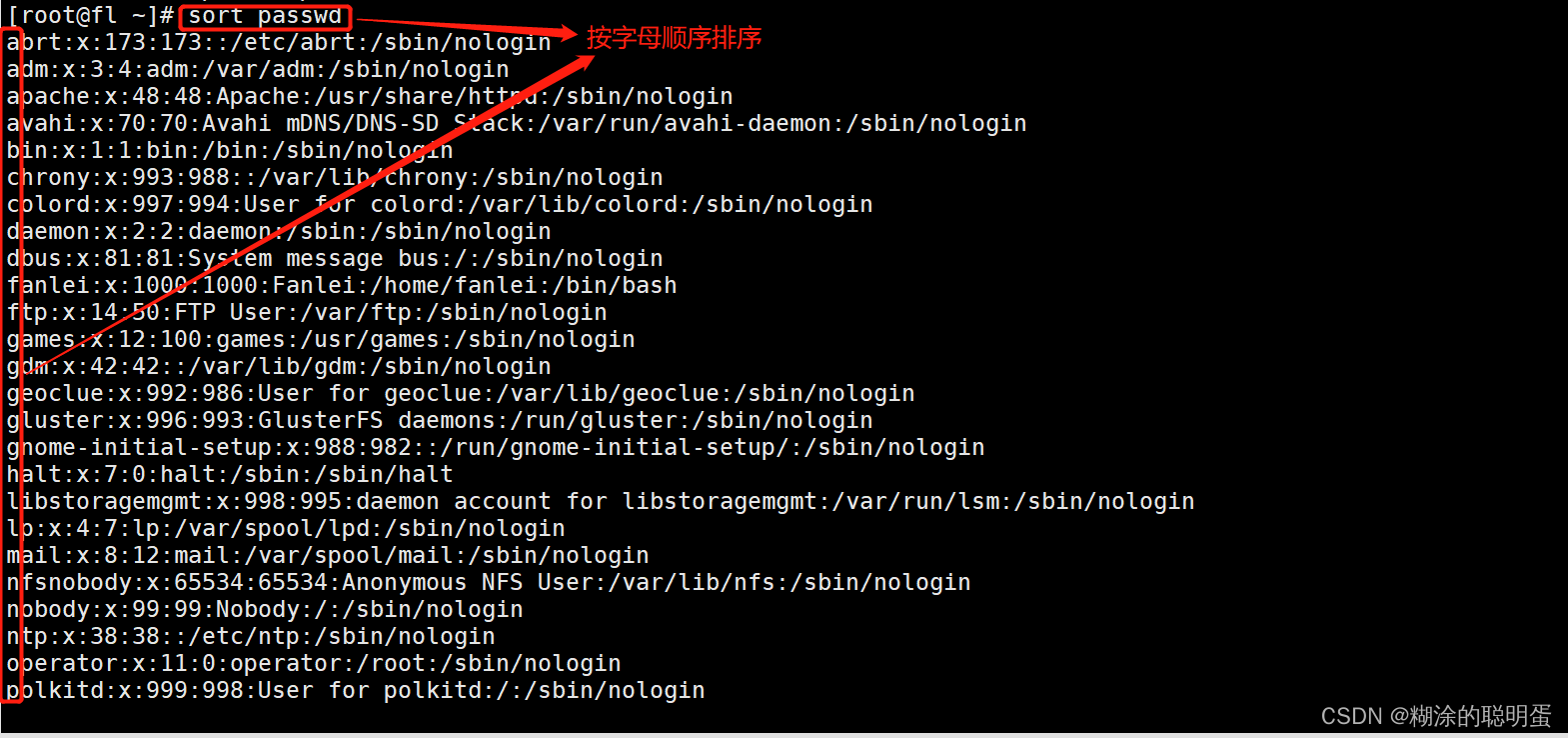
例2
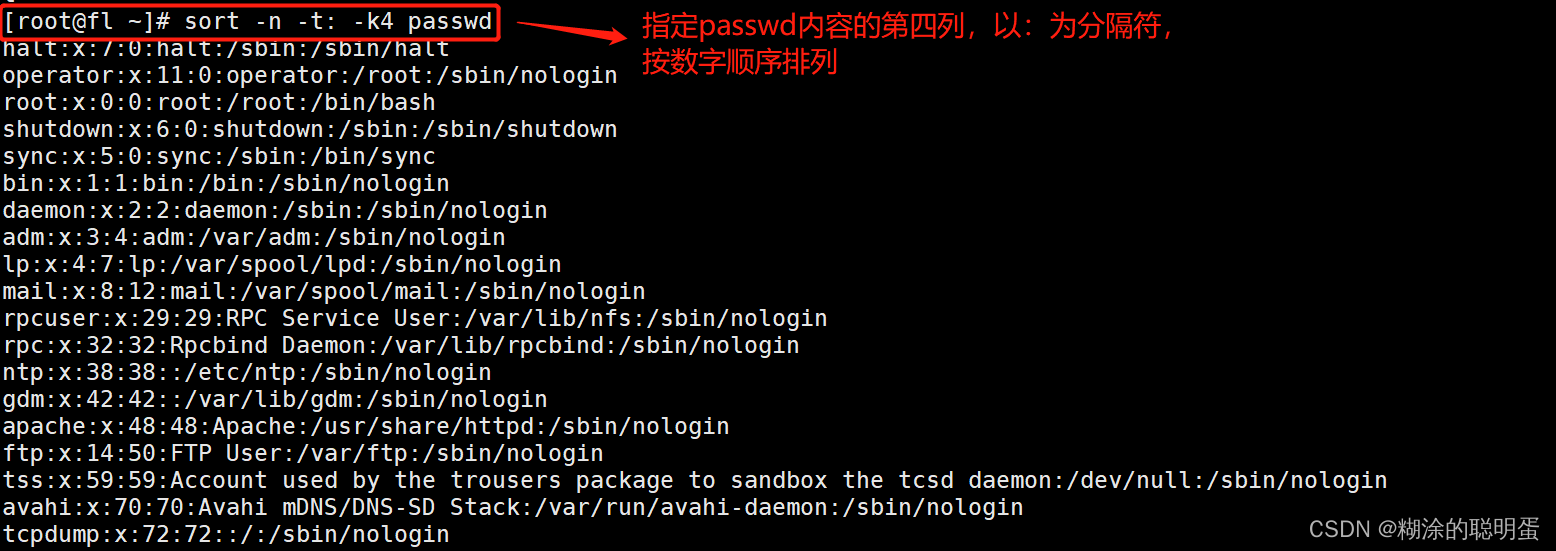
例3
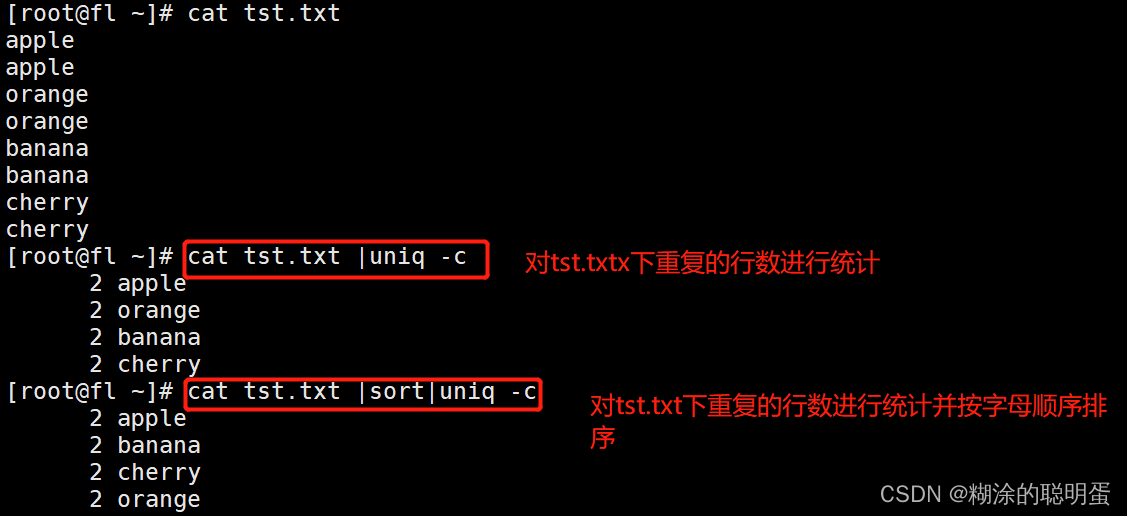
3.4 uniq
uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用
格式:uniq [选项] 参数
| 常用选项 | |
| -c | 对重复的行数进行计数 |
| -d | 仅显示重复行 |
| -u | 仅显示出现一次的行 |
例1

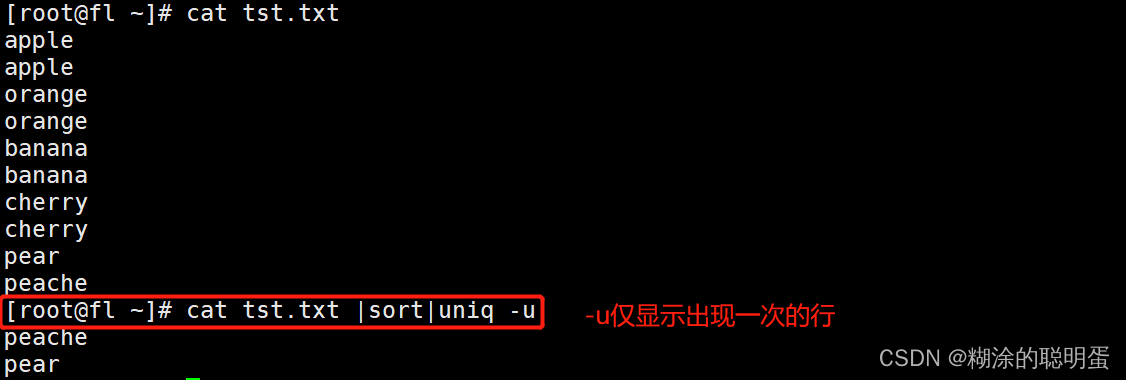
例2

3.5 tr
常用来对来自标准输入的字符进行替换、压缩和删除。
格式:tr [选项] [参数]
| 常用选项 | |
| -d | 删除字符 |
| -s | 删除所有重复出现的字符,只保留一个 |
例1

例2

例3


例4

例5

