1.创建Source
spark 2.0中初步提供了一些内置的source支持。
Socket source (for testing): 从socket连接中读取文本内容。
File source: 以数据流的方式读取一个目录中的文件。支持text、csv、json、parquet等文件类型。
Kafka source: 从Kafka中拉取数据,与0.10或以上的版本兼容,后面单独整合Kafka
1.1.读取Socket数据
●首先在linux服务器上安装nc工具
yum install -y nc
●启动一个服务端并开放9999端口,等一下往这个端口发数据
nc -lk 9999
发送数据
hadoop spark sqoop hadoop spark hive hadoop
●代码演示
package cn.itcast.structedstreaming
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
//设置日志级别
sc.setLogLevel("WARN")
//2.接收数据
val dataDF: DataFrame = spark.readStream
.option("host", "node01")
.option("port", 9999)
.format("socket")
.load()
//3.处理数据
import spark.implicits._
val dataDS: Dataset[String] = dataDF.as[String]
//对数据进行拆分
val wordDS: Dataset[String] = dataDS.flatMap(_.split(" "))
//计算单词的数量 DSL(类似sql)计算 (计算得到的结果映射为另一张表.)
val result: Dataset[Row] = wordDS.groupBy("value").count().sort($"count".desc)
//result.show()
//Queries with streaming sources must be executed with writeStream.start();
//4 计算结果输出
result.writeStream
.format("console")//往控制台写
.outputMode("complete")//每次将所有的数据写出
.trigger(Trigger.ProcessingTime(0))//触发时间间隔,0表示尽可能的快
//.option("checkpointLocation","./ckp")//设置checkpoint目录,socket不支持数据恢复,所以第二次启动会报错,需要注掉
.start()//开启
.awaitTermination()//等待停止
}
}
1.2.读取目录下文本数据
spark应用可以监听某一个目录,而web服务在这个目录上实时产生日志文件,这样对于spark应用来说,日志文件就是实时数据
Structured Streaming支持的文件类型有text,csv,json,parquet
准备工作
在people.json文件输入如下数据:
{"name":"json","age":23,"hobby":"running"}
{"name":"charles","age":32,"hobby":"basketball"}
{"name":"tom","age":28,"hobby":"football"}
{"name":"lili","age":24,"hobby":"running"}
{"name":"bob","age":20,"hobby":"swimming"}
注意:文件必须是被移动到目录中的,且文件名不能有特殊字符
- 需求
使用Structured Streaming统计年龄小于25岁的人群的爱好排行榜
代码演示
package cn.itcast.structedstreaming
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* {"name":"json","age":23,"hobby":"running"}
* {"name":"charles","age":32,"hobby":"basketball"}
* {"name":"tom","age":28,"hobby":"football"}
* {"name":"lili","age":24,"hobby":"running"}
* {"name":"bob","age":20,"hobby":"swimming"}
* 统计年龄小于25岁的人群的爱好排行榜
*/
object WordCount2 {
def main(args: Array[String]): Unit = {
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
//设置日志级别
sc.setLogLevel("WARN")
//读取数据 设置数据的结构
val Schema: StructType = new StructType()
.add("name","string")
.add("age","integer")
.add("hobby","string")
//2.接收数据
import spark.implicits._
// Schema must be specified when creating a streaming source DataFrame.
val dataDF: DataFrame =spark.readStream.schema(Schema).json("D:\\data\\spark\\data")
//3.处理数据 计算数据 统计年龄小于25岁的人群的爱好排行榜
val result: Dataset[Row] = dataDF.filter($"age" < 25).groupBy("hobby").count().sort($"count".desc)
//4.输出结果
result.writeStream
.format("console")//往控制台写
.outputMode("complete")//每次将所有的数据写出
.trigger(Trigger.ProcessingTime(0))//触发时间间隔,0表示尽可能的快
.start()//开启
.awaitTermination()//等待停止
}
}
2.计算操作
获得到Source之后的基本数据处理方式和之前学习的DataFrame、DataSet一致
3.输出
计算结果可以选择输出到多种设备并进行如下设定
- 1.output mode:以哪种方式将result table的数据写入sink
- 2.format/output sink的一些细节:数据格式、位置等。
- 3.query name:指定查询的标识。类似tempview的名字
- 4.trigger interval:触发间隔,如果不指定,默认会尽可能快速地处理数据
- 5.checkpoint地址:一般是hdfs上的目录。
注意:Socket不支持数据恢复,如果设置了,第二次启动会报错 ,Kafka支持
3.1output mode
每当结果表更新时,我们都希望将更改后的结果行写入外部接收器。
这里有三种输出模型:
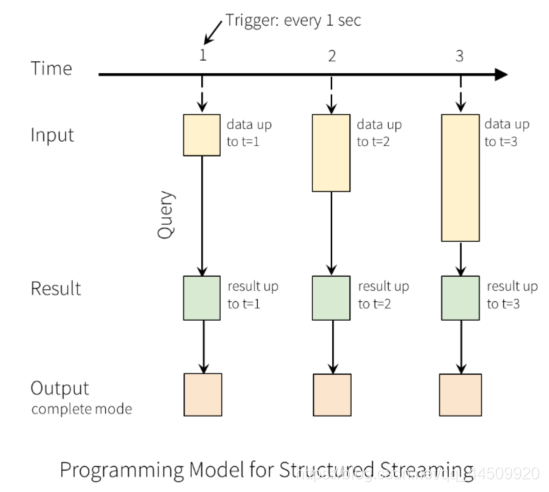
- 1.Append mode:输出新增的行,默认模式。每次更新结果集时,只将新添加到结果集的结果行输出到接收器。仅支持添加到结果表中的行永远不会更改的查询。因此,此模式保证每行仅输出一次。例如,仅查询select,where,map,flatMap,filter,join等会支持追加模式。不支持聚合
- 2.Complete mode: 所有内容都输出,每次触发后,整个结果表将输出到接收器。聚合查询支持此功能。仅适用于包含聚合操作的查询。
- 3.Update mode: 输出更新的行,每次更新结果集时,仅将被更新的结果行输出到接收器(自Spark 2.1.1起可用),不支持排序
3.2output sink
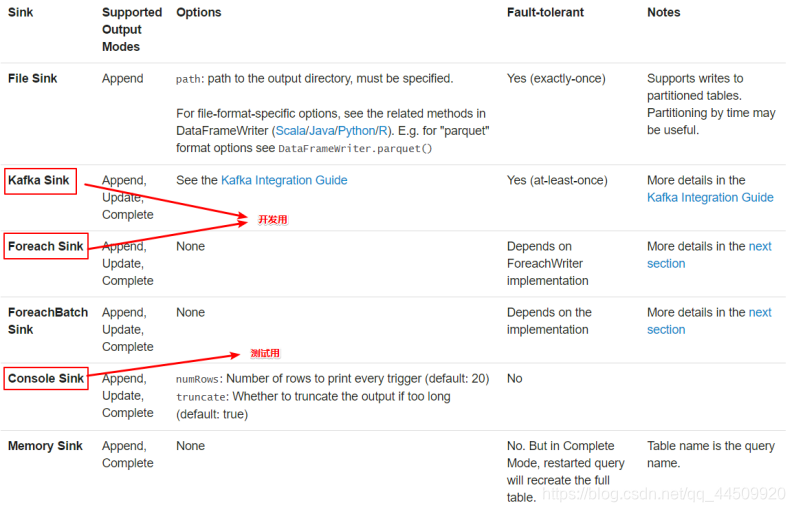
- 使用说明
File sink 输出到路径
支持parquet文件,以及append模式
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()
Kafka sink 输出到kafka内的一到多个topic
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
Foreach sink 对输出中的记录运行任意计算。
writeStream
.foreach(...)
.start()
Console sink (for debugging) 当有触发器时,将输出打印到控制台。
writeStream
.format("console")
.start()
Memory sink (for debugging) - 输出作为内存表存储在内存中.
writeStream
.format("memory")
.queryName("tableName")
.start()
●官网示例代码
// ========== DF with no aggregations ==========
val noAggDF = deviceDataDf.select("device").where("signal > 10")
// Print new data to console
noAggDF.writeStream.format("console").start()
// Write new data to Parquet files
noAggDF.writeStream.format("parquet").option("checkpointLocation", "path/to/checkpoint/dir").option("path", "path/to/destination/dir").start()
// ========== DF with aggregation ==========
val aggDF = df.groupBy("device").count()
// Print updated aggregations to console
aggDF.writeStream.outputMode("complete").format("console").start()
// Have all the aggregates in an in-memory table
aggDF.writeStream.queryName("aggregates").outputMode("complete").format("memory").start()
spark.sql("select * from aggregates").show() // interactively query in-memory table