WGCNA简介
- WGCNA(Weighted Gene Co-Expression Network Analysis, 加权基因共表达网络分析),鉴定表达模式相似的基因集合(module),解析基因集合与样品表型之间的联系,绘制基因集合之间的调控网络并鉴定关键调控基因
- WGCNA适用于复杂的转录组数据(样本数目较多)
- 研究不同器官/组织类型和不同阶段的发育调控、生物和非生物胁迫的不同时间响应机制
WGCNA原理
原理概要
1.构建基因共表达网络:先构建基因共表达网络,通常利用两两基因之间的表达模式来计算它们之间的一个相关系数,然后基于相关系数来构建基因的网络;
2.识别module:构建好基因的关系后,通过阈值来划定那些基因关系比较紧密,我们就把关系紧密的划分为一个module
3.将module与外部信息相关联:对module来做一些特征分析,包括给它赋予特征值,对module内的基因进行GO富集来探索其功能
4.研究module之间的关系:通过module的表达模式和模块的功能来筛选和生物学问题比较相关的关键module
5.在关键module中识别调控基因:对关键module的内部基因进行分析,包括看内部注释基因的功能以及它们调控层次的一个关系等来鉴定module中比较关键的一些调控基因
构建基因关系网络
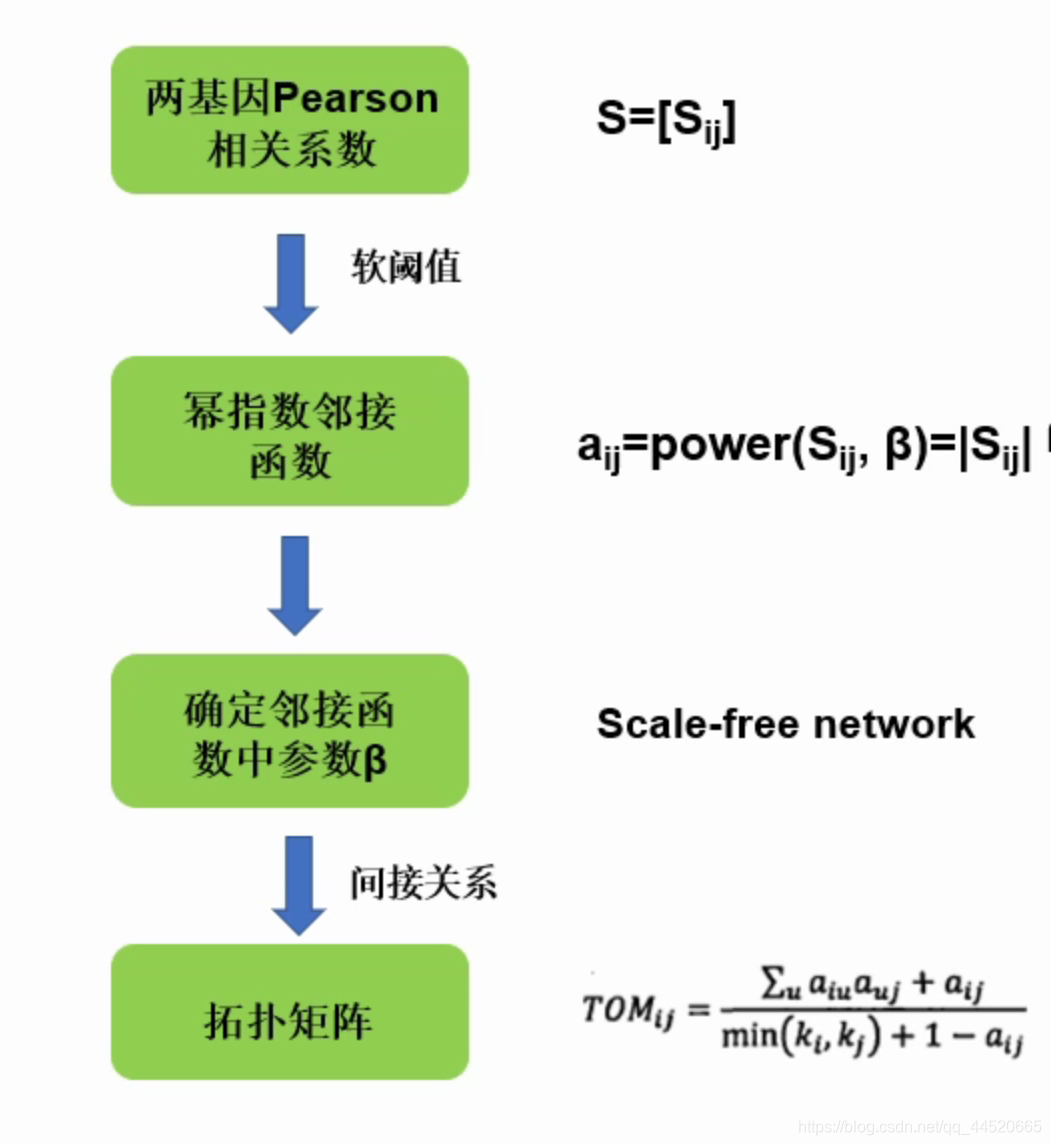
计算基因间相关关系
- 基因间相似性(similarity):依据基因在不同样品中的表达情况,计算任意两个基因间的相关关系,用Pearson相关系数
- 基因共表达相似矩阵:S =[ Sij]( Sij表示基因i与基因j的Pearson相关系数)
- 硬阈值:一刀切,判断两个基因是否相似,设置一个阈值,如阈值为0.8,则相关系数大于0.8的为相似,0.79为不相似,一刀切的方法对于研究生物学问题是不合适的,因为0.79和0.81在生物学上差别并不大
- 软阈值:通过加权函数(邻接函数)将相关系数变换,形成邻接矩阵(Adjacency Matrix),矩阵中元素连续化
- 邻接函数:power函数(幂指数函数)
aij = power(Sij, β) = lSijlβ
重点需要确定邻接函数的参数(β),依据为无尺度网络原则,即基因表达网络符合无尺度网络的幂函数分布
幂指数函数可以使矩阵里的元素符合无尺度网络原则
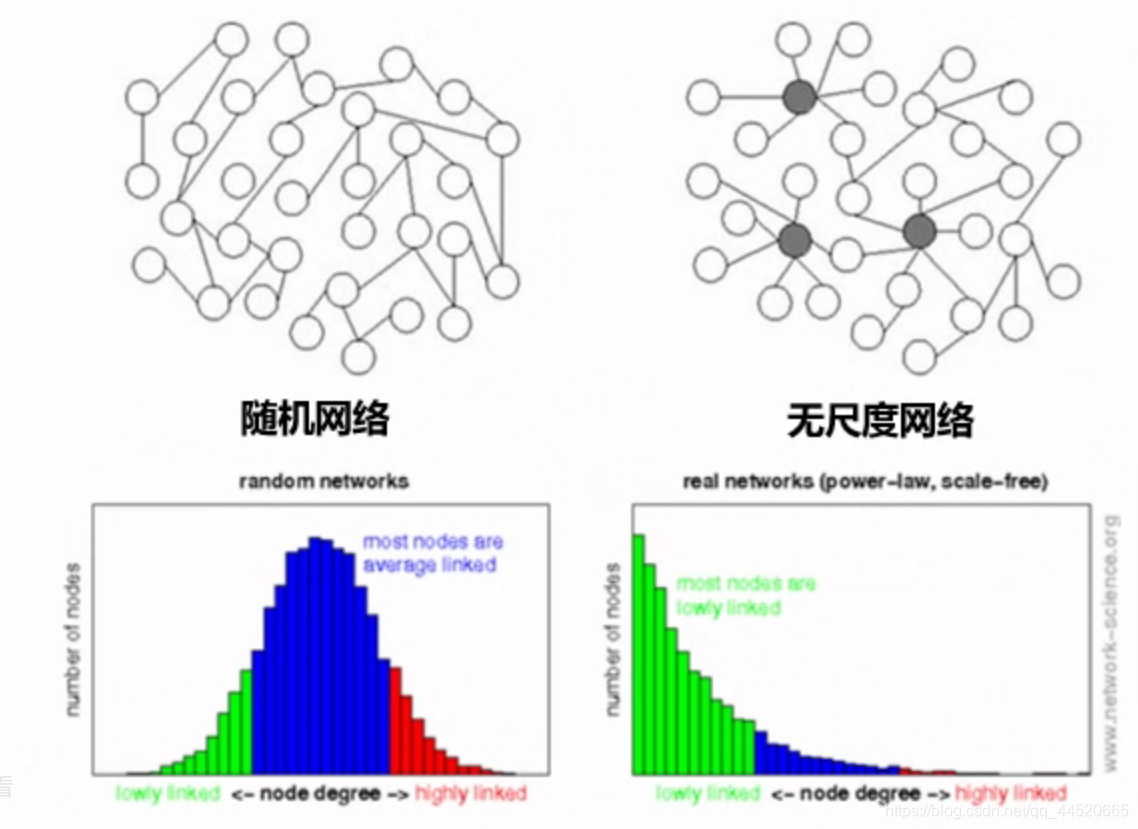
无尺度网络(幂指数函数符合生物学意义)
- 数学中的网络:网络图中的点指的是网中的每个节点,度degree指的是跟点相连的遍数(连接数)
- 随机网络:Random network:每一个节点的度相对平均,随机网络中每个节点的连接数符合泊松分布,大部分节点的连接数居中,把这个中值称为随机网络的尺度
- 无尺度网络:Scale-free network,少数节点具有明显高于一般点的度,这些点称为hub,由少数hub与其他节点关联,最终构成整个网络,我们可以看到,无尺度网络有主次和重要之分的,hub就是其重要的一些节点,生活中的很多网络都是属于无尺度网络,如航班的航线
- 在生物体调控网络中,有少数的一些基因起到非常重要的一些调控作用,而其他的基因没有它们的调控层次高,这种网络带来的好处是如果只是不重要的边缘基因发生破坏的话,生物体主要的功能也不会遭到破坏,这种就是在面对一些胁迫或者外界损伤时,生物体在一定时间内有能力应对
- 邻接函数的建立会让基因表达矩阵符合无尺度网络,
-== 无尺度网络的特点及邻接函数的为什么会使基因表达矩阵符合无尺度网络原则???==
【1】无尺度网络的幂律分布:节点连接数为k的节点数h,k与h成反比,负相关,大多数点只有很少的连接,少数点有很多的连接,该网络没有一个尺度来衡量网络中节点的距离
【2】基因相关关系,幂函数处理后,少数强相关性不受影响或者影响较小,而相关性弱的取n次幂后,相关性明显下降
【3】无尺度:随机网络中每个节点的连接数符合泊松分布,大部分节点的连接数居中,把这个中值称为随机网络的尺度,无尺度网络大多数点只有很少的连接,少数点有很多的连接,该网络没有一个尺度来衡量网络中节点的距离
确定关键参数β
-
寻找合适的参数β,使得基因表达关系符合无尺度网络,度数高的节点数少,度数少的节点数多
-
节点度数k与具有该度数节点的个数h服从幂律分布
幂律分布;某个具有分布性质的变量,只要其分布密布函数是幂函数(由于分布密度函数必然满足“归一律”,所以这里的幂函数,一般规定小于负1),都可以称其满足幂律分布规律。这种分布是自然界中的一种常见现象。譬如地震的大小,通常震级越小发生的频率越大,震级越大发生的频率就越小。以震级为自变量,以其发生的频率(或概率)为因变量,符合(负)幂函数。 -
WGCNA有一个模型,可以尝试β的值,从1开始尝试,β=1,2.。。。。时,幂函数是怎么样的,一个一个用模型算,算完之后判断哪个β比较好,
-
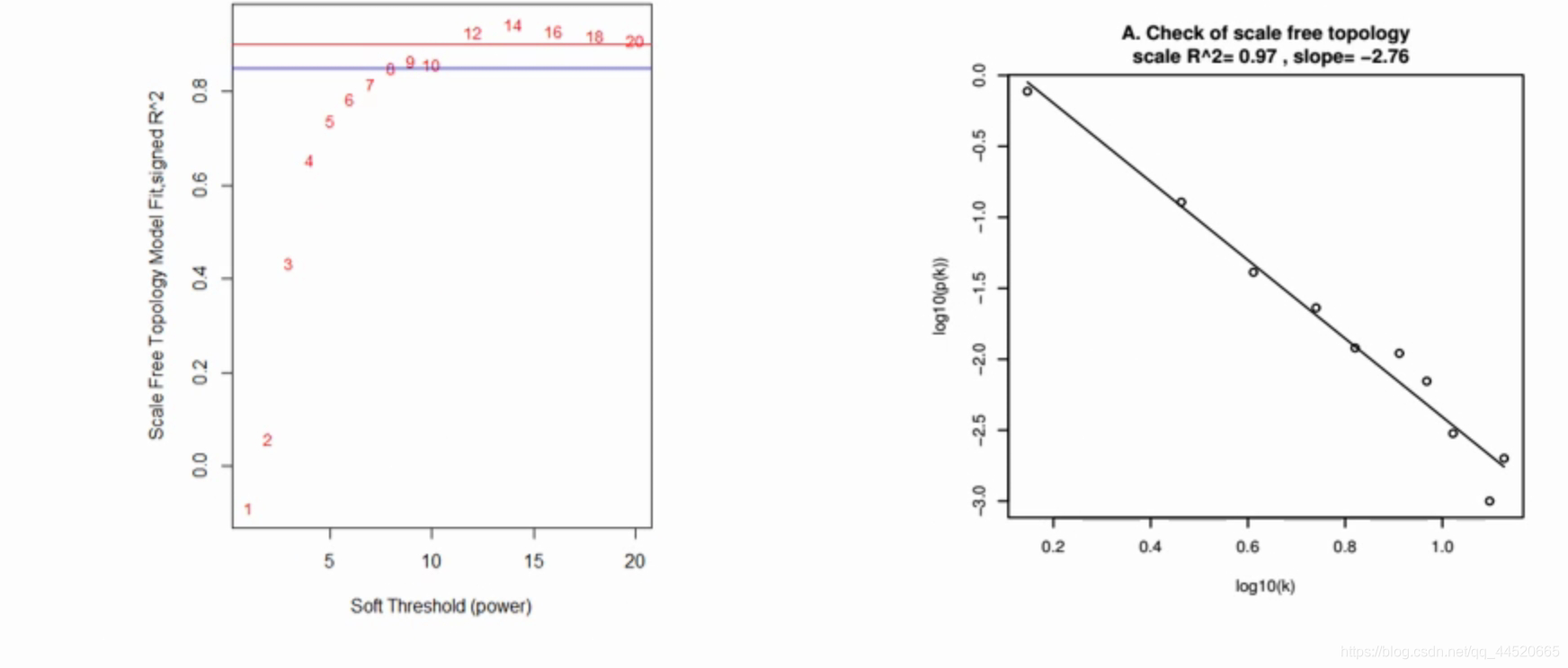
判断β合适的方法
在取了一定的β参数之后,具体计算度数为k的节点个数的对数值log(k),与该节点出现的概率的对数log(p(k))呈现负相关,一般会设置相关系数大于0.8
β参数设为8时,节点和度数是比较符合无尺度网络
为了检测设置的参数β是否满足无尺度网络,对log10(p(k))作图,同时为更好评估,对两者之间的相关系数做平方,即R2,如果模型R2接近1,则两者之间为很好的线性关系
计算基因间表达关系(间接关系)
- 之前我们只考虑了基因两两之间的关系
- 生物体内基因间的关系:直接关系+间接关系
- TOM:用拓扑重叠(topological overlap measure, TOM)来计算基因之间关联程度,除了分析两个基因之间的关系,还考虑这两个基因与其他基因之间的连接,这样更就有生物学意义
- 建立TOM矩阵,在邻接函数的基础上除了考虑两两基因之间的直接关系,还考虑了间接的关系
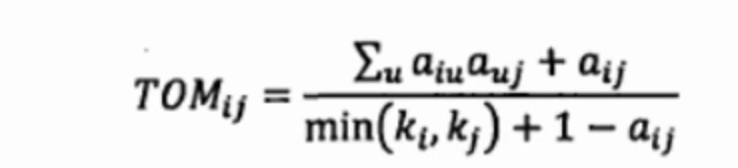
TOM公式中,计算基因i和j的关系,不仅考虑了i和j的直接关系,还考虑了第三个基因u的间接关系
构建基因模块
在Tom值的基础上,采用动态建树的方法,建立基因的模块
层次聚类建树
- 基因模块的划分基于基因间的连接稀疏性(理解为基因间亲疏的程度),将TOM矩阵(Similarity)转化为相异度矩阵(Dissimilarity):dijw = 1 - wij(为了画矩阵的方便性)
- 利用基于TOM值的相宜度层次聚类建树
- 简述方法:静态剪切树和动态剪切树(动态树法和动态混合剪切法)WGCNA一般采用动态剪切树,R包用的是动态混合剪切法
静态剪切树:通过定义的固定高度将聚类树上的一个连续分支截止为一个单独的群集(cluster),对于基因模块的识别,特异性较好,但是敏感性较低,容易遗漏基因模块边缘的基因
动态树法:“自上而下”,由静态法得到几个较大模块,通过不断的分解和组合(反复迭代计算过程),鉴定出最终模块
动态混合剪切法:
【1】识别满足设定条件的初级模块
(1)满足模块预定义的最低基因数目
(2)距离cluster过远的基因,即使与cluster处于同一分支,也去除
(3)每个cluster与其他周围的cluster显著不同
(4)处在树分枝尖端的每个群集的核心基因紧密相连
【2】测试步骤
(1)将未分配的基因进行测试,如果足够接近某个初级cluster,则分配进去
(2)通常WGANA使用动态混合剪切法建树
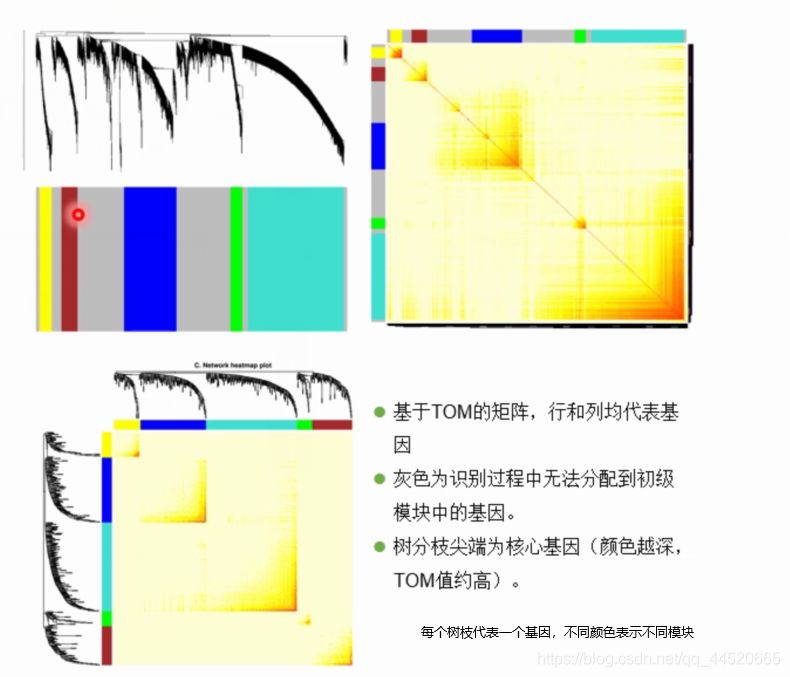
建树过程的参数
- 模块最少基因数目(miniModuleSize)
- 合并模块最小距离(minicutHeight):计算模块的特征值,利用模块特征值建树,合并距离很近的模块,如Height值<0.2
- 模块特征值(Epigengene):模块内所有基因进行主成分分析(PCA),第一主成分的值即为Epigengene,它代表该模块内基因表达的整体水平(表达模式),可以把模块看成基因,那么模块特征值就可以看作这个基因的表达值
会用每个模块的特征值来构建一个树,来构建模块之间的相关性,根据模块之间的Height值合并模块
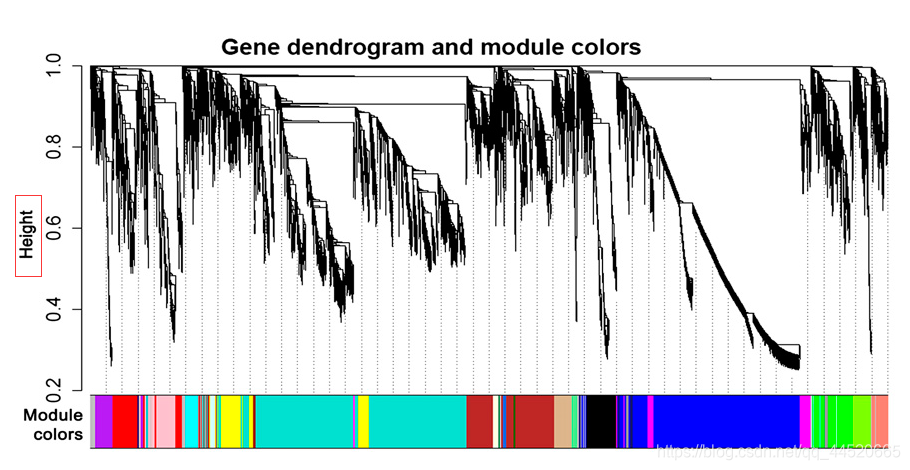
筛选基因模块
方法一:表达模式分析-分析各个模块在所有样品中的表达模式
方法二:表型关联分析-对基因模块与表型数据进行关系分析(计算两者之间的相关系数)
方法三:富集分析-对模块内基因进行GO和KEGG功能富集分析
方法四:目标基因-依据感兴趣的目标基因筛选其所在的模块
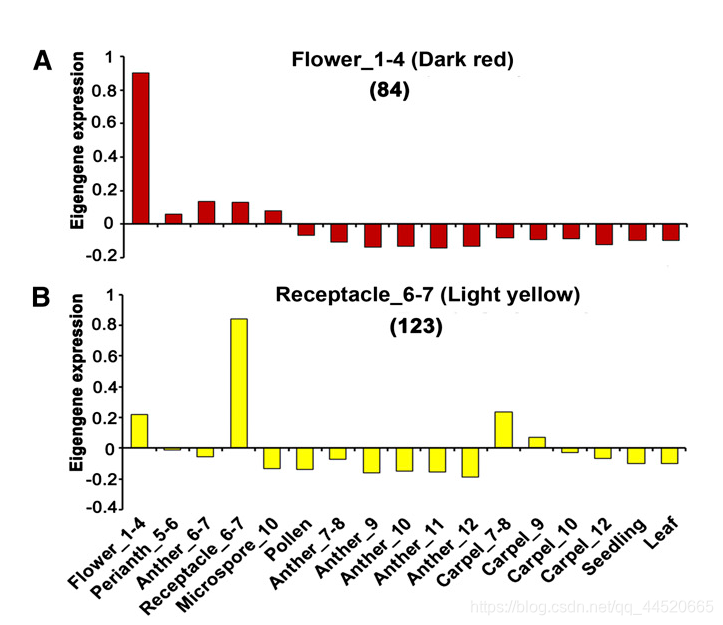
方法一:模块特征值表达模式分析
-
模块表达模式分析:模块特征值在各个样品中的丰度
-
模块特征值(Epigengene):模块内所有基因进行主成分分析(PCA),第一主成分的值即为Epigengene,它代表该模块内基因表达的整体水平(表达模式),可以把模块看成基因,那么模块特征值就可以看作这个基因的表达值
-
如果模块在样品中特征值正或负表达较高,说明该模块与这个样品密切相关
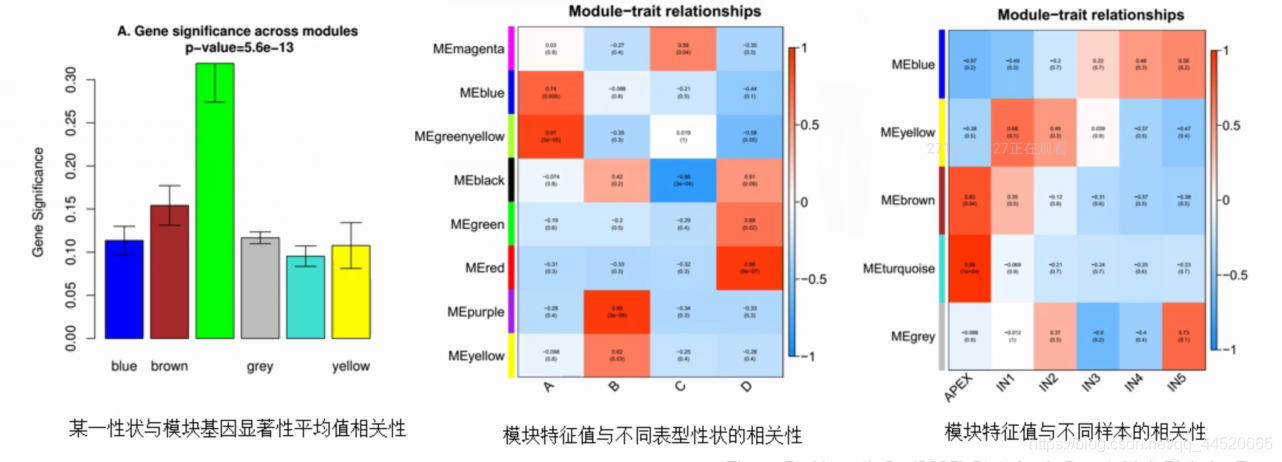
方法二:模块与表型性状关联分析
- 模块显著性值(Module significance, MS):模块内所有基因的基因显著性值的平均值
- 基因显著性值(Gene significance, GS):基因表达水平与因变量水平的相关系数,可理解为这个基因的表达水平跟某个表型的相关系数。用T检验计算每个基因在不同表型样品组间的差异表达显著性检验P值(Pearson相关系数),通常将P值取以10为底对数定义为基因显著性GS
- 计算各模块与某一表型性状的MS值,如一个模块的MS值显著高于其他模块,则这一模块与该性状存在关联关系
- 模块特征值显著性(Epigengene significance, ES):模块特征值与某一性状的相关系数,筛选与性状关联度最高的模块
方法三:模块基因功能富集分析
- 对各个模块都进行GO和KEGG功能富集分析,找出与我们研究性状相关通路相关性最强的模块进行深入挖掘
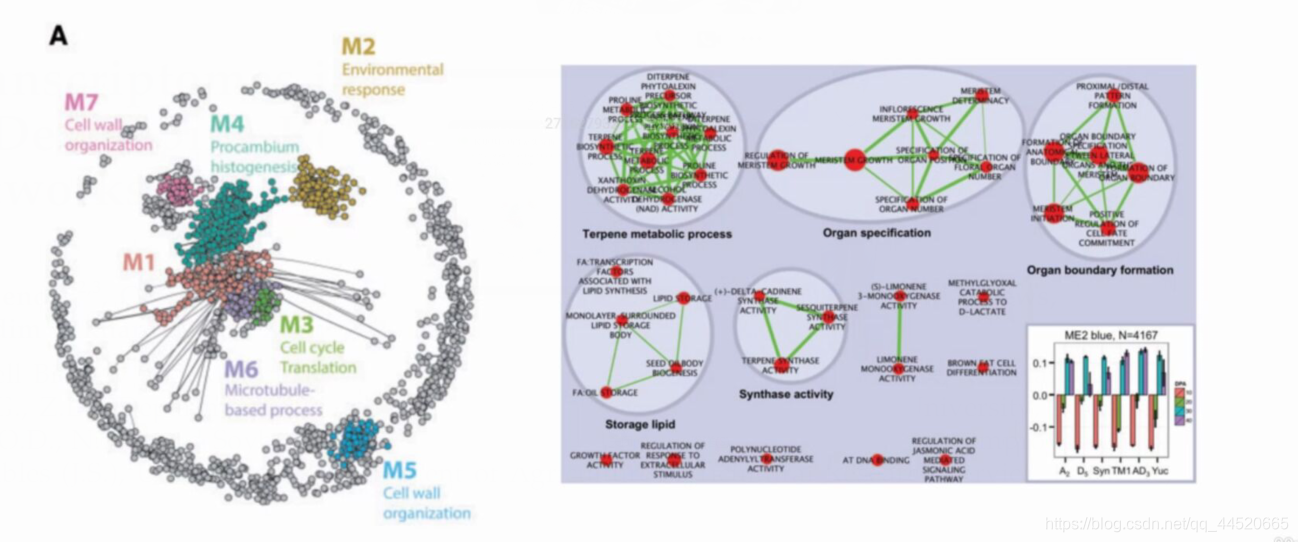
方法四:依据目标基因筛选模块
- 依据研究目的、前期研究结果和已发表文献,有重点关注的目标基因,可直接筛选目标基因所在的基因模块重点进行下一步分析
鉴定关键基因
方法一:模块内部基因连接度分析
方法二:特定功能(类型)基因分析
方法三:目标基因关联分析
方法一:模块内部基因连接度分析
- Connectivity(degree)连接度:与某个基因连接的所有其他基因的总和(直接连接+间接连接),及描述一个基因与其他基因的关联程度,一般用K值表示
- Intramodular connectivity模块内部连接度IC:某个模块中的基因与该模块中其他基因的关联程度(共表达程度),用KIM值表示,可用来衡量模块身份(module membership, MM)
- Module Menbership MM 或Epigengene-bsaed connectivity KME:模块身份,用一个基因在所有样本中的表达谱与某个模块特征值的表达谱的相关性,来衡量这个基因在这个模块中的身份
- KME 值接近0,说明这个基因不是该模块的成员;KME接近1或-1,说明这个基因与该模块密切相关(正相关或负相关)
- 可以对所有基因计算相对某个模块的KME值,并不一定要是该模块的成员
- KME与KIM的区别:IC衡量基因在特定模块中的身份,MM衡量基因在全局网络中的位置
- KME与KIM高度相关:某个模块中KIM值高的hub基因一定与该模块的KME也很高
筛选关键基因:
【1】
- TOM值(模块调控关系表中的weight值)大于阈值(默认是0.15)的两个基因才认为是相关的,然后计算每个基因的连接度,即先筛选有足够强度的关系,然后计算连接度
- 模块内部连接度的基因,模块内排名前30%或者10%(KME或KIM)
- Cytoscape中一般用weight值(TOM值)来绘制网络图
【2】 - 将该基因模块身份MM相对于基因显著性GS做散点图,选择右上角MM和GS均高的基因进一步分析
- 基因显著性值(Gene significance, GS):基因表达水平与因变量水平的相关系数,衡量基因与表型性状的关联程度,GS越高,说明与表型越相关,越具有生物学意义,GS可正可负(正相关或负相关)
方法二:特定功能(类型)基因分析
- 高连通性的基因一般位于调控网络的上游;低连通性的基因一般位于调控网络的下游
- 调控网络上游一般是调控因子,如转录因子;下游一般是功能性的酶或蛋白质分子
- 重点关注具有调控功能的基因,典型的为转录因子,这些基因往往是关键基因
方法三:目标基因关联分析
- 依据研究目的,选取跟目标基因关系紧密的基因,如筛选与目标基因的TOM值排名前10,或者TOM值大于0.2(可设置阈值)的基因
- 可准确筛选与目标基因存在上下游调控关系的候选基因
- 当目标基因连接度不高时,可筛选与目标基因TOM很高,且自身连接度也很高的基因