Ollama 官方版
Ollama 官方版: https://ollama.com/
若你的显卡是在Linux上面 可以使用如下命令安装
curl -fsSL https://ollama.com/install.sh | sh
ollama命令查看
root@heyu-virtual-machine:~# ollama -h
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
root@heyu-virtual-machine:~#
拉取deepseek模型
查看
ollama list
当然Ollama不只是可以启动deepseek模型,也可以启动其他的模型
详情链接:https://ollama.com/search
# 模型的安装命令
# 1.5B Qwen DeepSeek R1
# 所需空间大约 1.1G
ollama run deepseek-r1:1.5b
# 7B Qwen DeepSeek R1
# 所需空间大约 4.7G
ollama run deepseek-r1:7b
# 8B Llama DeepSeek R1
# 所需空间大约 4.9G
ollama run deepseek-r1:8b
# 14B Qwen DeepSeek R1
# 所需空间大约 9G
ollama run deepseek-r1:14b
# 32B Qwen DeepSeek R1
# 所需空间大约 20G
ollama run deepseek-r1:32b
# 70B Llama DeepSeek R1
# 所需空间大约 43G
ollama run deepseek-r1:70b
# 671B Llama DeepSeek R1
# 所需空间大约 404G
ollama run deepseek-r1:671b

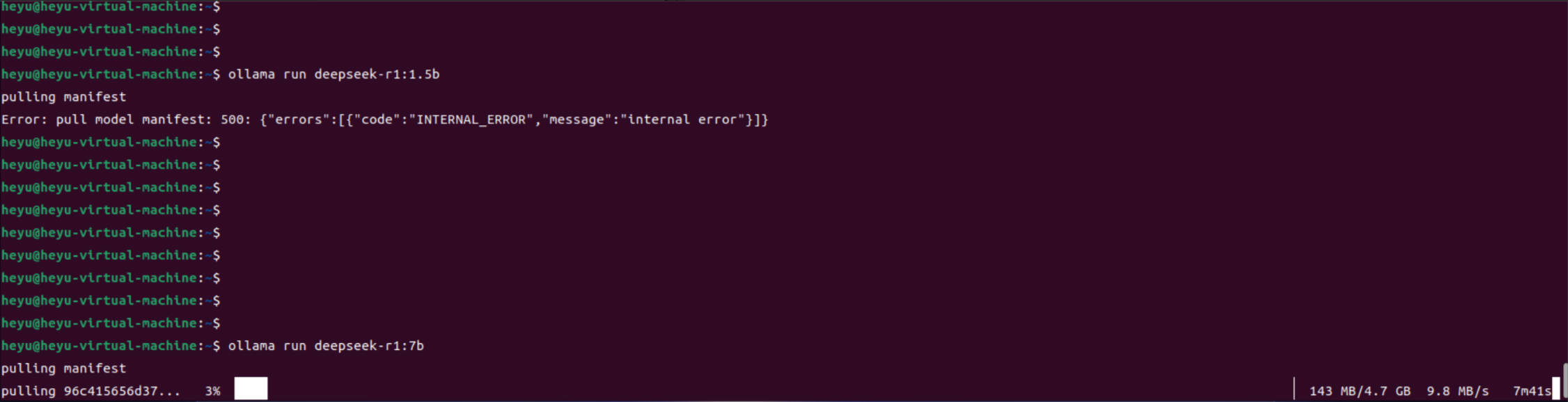
我的个人电脑性能一般,就只能先使用7b的模型了
ollama run deepseek-r1:7b
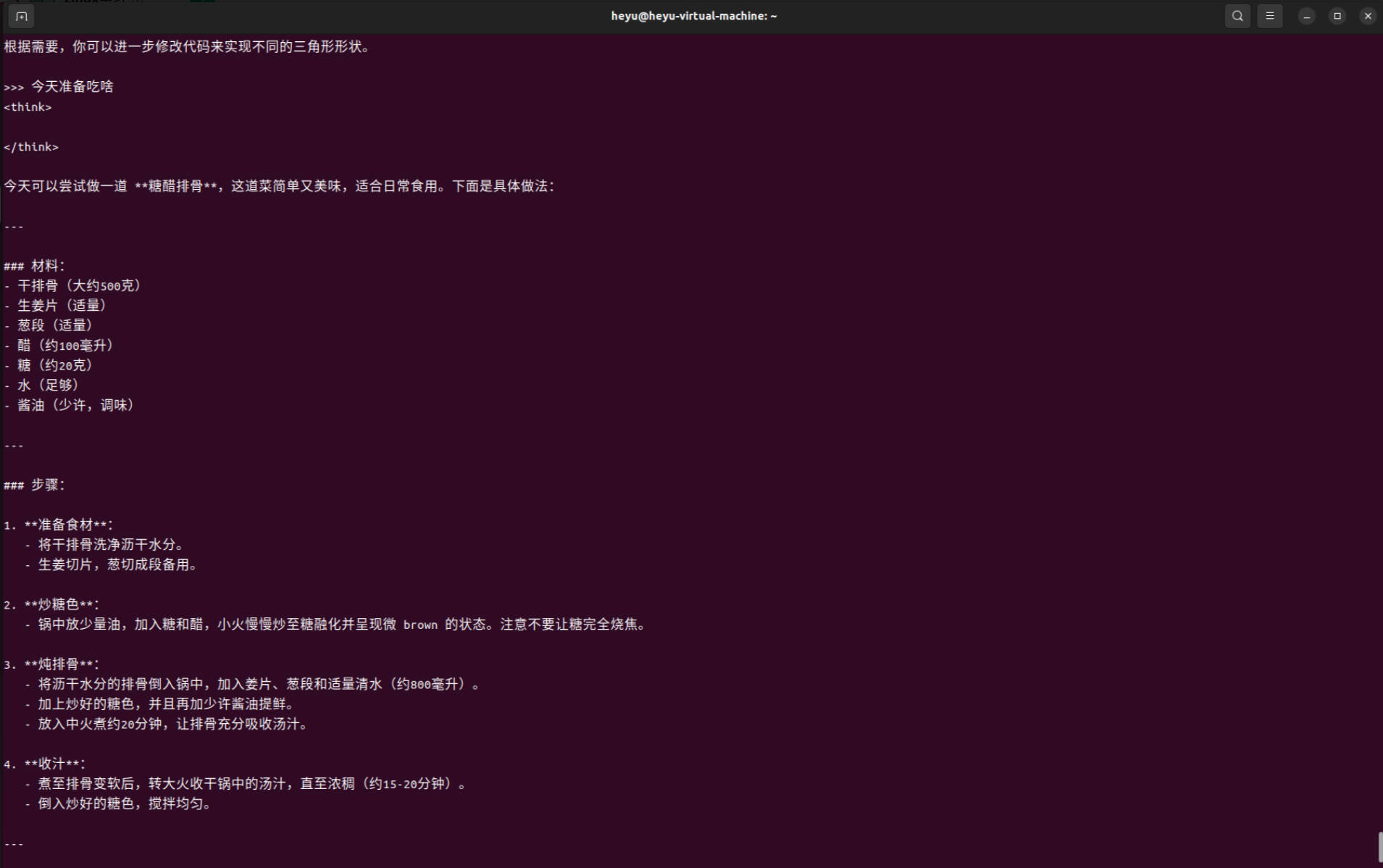
使用大模型
可以在命令行中输入提问的信息
cpu负载信息
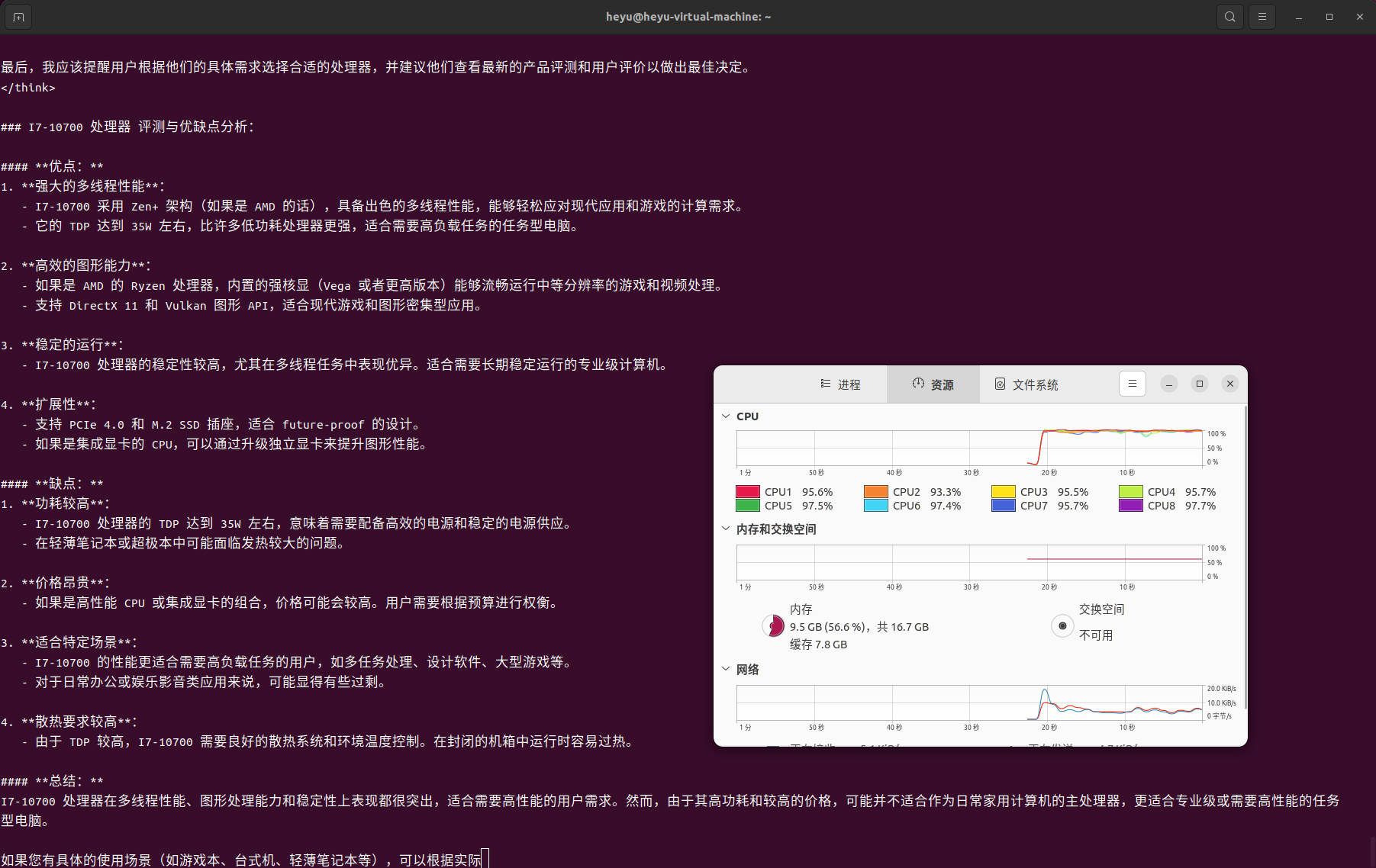
以上是在Ubuntu虚拟机中用CPU跑的性能视图,CPU基本上占用很高。如果有高端的GPU显卡,可以运行的更好。
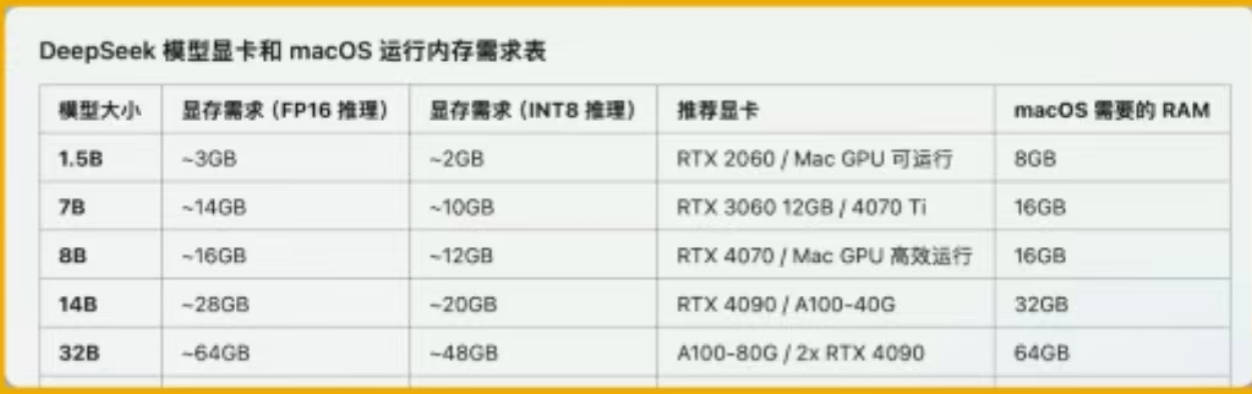
以下是参考配置:
命令行窗口启用模型
可能由于工作或者是下班了,我们不小心关闭命令行窗口后,还想打开命令提示符窗口,只需要再次在命令符提示窗口中输入上面复制的指令即可
ollama run deepseek-r1:7b
FQA
拉取模型时报错 500
pulling manifest
Error: pull model manifest: 500: {“errors”:[{“code”:“INTERNAL_ERROR”,“message”:“internal error”}]}
这个错误表明在拉取模型清单(manifest)时,服务器返回了 500 内部错误。这通常是由服务器端的问题引起的,但你可以尝试以下步骤来排查和解决问题:
检查网络连接
● 确保你的网络连接正常,尤其是访问目标服务器时没有防火墙或代理的限制。
● 如果你使用了代理,请确保代理配置正确。
可以检查一下网络,稍后再执行命令下载。