1. 聚类概念与意义介绍:
目的: 聚类分析将数据划分成有意义的或有用的组(簇)。如果目标是划分成有意义的组 ,则簇应当捕获数据的自然结构。然而,在某种意义下,聚类分析只是解决其他问题的起点。
- 旨在理解的聚类 : 在对世界的分析和描述中,类,或在概念上有意义的具有公共特性的对象组,扮演者重要的角色。
- 旨在实用的聚类: 聚类分析提供由个别数据对象到数据对象所指派的簇的抽象。此外,一些聚类技术使用簇原型(代表簇中其他对象的数据对象,就像一个小队的队长一样具有代表性,进而代表这个小队)来刻画簇特征。这些簇原型可以用作大量数据分析和数据处理的基础。
实用聚类用途介绍
- 汇总 很多数据分析技术,如回归和PCA ,都有O(m2)或更高的时间或空间复杂度,所以针对大型数据,它们并不是很理想,这时,可以将算法用于仅包含簇原型的数据集(就是找些有代表性的样本,减少对象数量),而不是整个数据集,依赖分析类型、原型个数和原型代表数据的精度,汇总结果可以与使用所有数据得到的结果向媲美
- 压缩 簇原型可以用于数据压缩,即簇原型构成一个数据集,要找对象,先找到它的簇原型,再找到它。
- 有效地发现最近邻 针对点与点之间的距离
什么是聚类分析?
聚类分析仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组。其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的,组内的相似性越大,组间差别越大,聚类就越好。
簇的定义是不精确的,最好的定义依赖于数据的特性和期望的结果。
不同的聚类类型
- 层次的与划分的: 划分聚类(partitional clustering)简单地将数据对象集划分为不重叠的子集,使得每个数据对象恰在一个子集中。
层次聚类(hierarchical clustering):层次聚类是嵌套簇的集族,组织成一棵树。即层次聚类是嵌套的,子簇又可以分簇。 - 互斥的、重叠的和模糊的 顾名思义,当一个点可以划分到多个簇中时,它就是重叠的(overlapping)和非互斥的(non-exclusive), 模糊聚类:每一个对象以 0 到 1之间的隶属权值属于每个簇。
- 完全的与部分的 完全聚类将每个对象指派到一个簇上,而部分聚类,即只聚类其中最有价值的一部分。
不同的簇类型
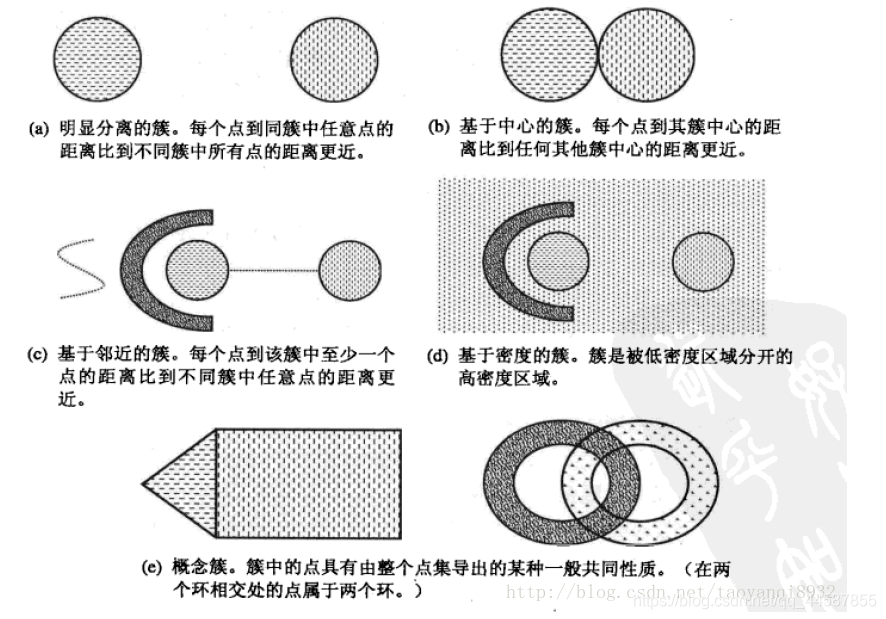
- 明显分离的 如下图(a)其中每个对象到同簇中每个对象的距离比到不同簇中任意对象的距离都近。
- 基于原型的 如下图(b)其中每个对象到定义该簇的原型(比如下图圆心)的距离比到其他簇原型的距离近。对于具有连续属性的数据,簇的原型通常是质心。当质心没有意义时(例如数据具有分类属性时),原型通常是中心点。
- 基于图的 如果数据用图表示 ,如下图(c),其中结点代表对象,边代表对象之间的联系,则簇可以定义为连通分支(connected component),即互相连通但不与组外对象连通的对象组。
- 基于密度的 簇是对象的稠密区域,被低密度的区域环绕,当簇不规则或互相盘绕,并且有噪声的和离群点是,常常使用基于密度的簇定义。
- 共同性质的(概念簇) 对于复杂的簇要非常具体的簇概念来成功的检测出这些簇。
下面将使用三种简单但重要的技术来介绍聚类分析涉及的一些概念。