系列文章目录
1.用python进行分析的用户流失预测实操,以电信行业为例
2.用python进行分析电信行业的用户流失预测(二)–数据可视化
3.用python进行分析电信行业的用户流失预测(三)—数据预处理
4.用python进行分析电信行业的用户流失预测(四)—构建模型
这里就是电信产业用户流失的模型构建过程,属于最后一个章节内容。是我第一次学习机器学习的项目案例,全部的流程走下来还是有点吃力的,毕竟涉及到算法和python的数据分析库!!我在学习的过程中也遇到很多报错提示,最终还是解决了。

本次项目基于python3.7,以及CatBOOst,sklearn,xgboost等算法。
1、建立训练数据集和测试数据集
# #我们需要将数据集拆分为训练集和测试集以进行验证。
# #由于我们所拥有的数据集是不平衡的,所以最好使用分层交叉验证来确保训练集和测试集都包合每个类样本的保留人数。
#
# #交叉验证是指在给定的建模样本中,拿出其中的大部分样本进行模型训练,生成模型,留小部分样本用刚建立的模型进行预测,
# # 并求这小部分样本的预测误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预测了一次而且仅被预测一次,
# # 比较每组的预测误差,选取误差最小的那一组作为训练模型。
#
# # 交叉验证函数StratifiedShuffleSplit,功能是从样本数据中随机按比例选取训练数据(trsin)和测试数据(test)
# # 参数 n_splits是将训练数据分成train/test对的组数,可根据需要进行设置,默认为10
# #
# # 参数test_size和train_size是用来设置train/test对中train和test所占的比例。例如:
# # 1.提供10个数据num进行训练和测试集划分
# # 2.设置train_size=0.8 test_size=0.2
# # 3.train_num=num*train_size=8 test_num=num*test_size=2
# # 4.即10个数据,进行划分以后8个是训练数据,2个是测试数据
# #
# # 注*:train_num≥2,test_num≥2 ;test_size+train_size可以小于1*
# #
# # 参数 random_state控制是将样本随机打乱
X=telconvar
y=telcon['Churn'].values
sss=StratifiedShuffleSplit(n_splits=5,test_size=0.2,random_state=0)
print(sss)
print('训练数据和测试数据被分成的组数:',sss.get_n_splits(X,y))
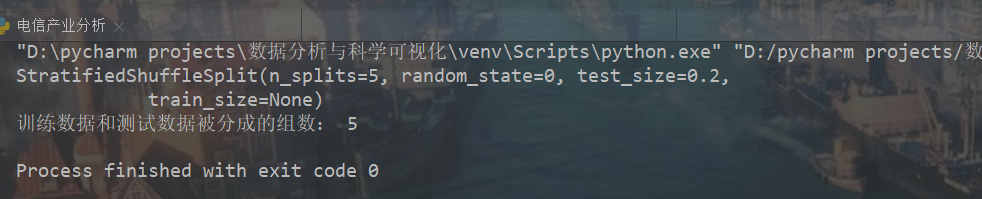
建立训练数据和测试数据
for train_index,test_index in sss.split(X, y):
print('train', train_index, 'test', test_index)
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y[train_index], y[test_index]
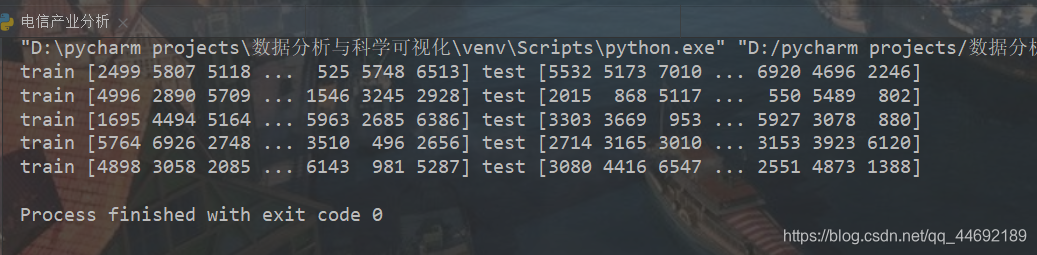
输出数据集大小
print('原始数据特征:',X.shape,
'训练数据特征:',X_train.shape,
'测试数据特征:',X_test.shape)
print('原始数据标签:',y.shape,
'训练数据标签:',y_train.shape,
'测试数据标签:',y_test.shape)

2、选择机器学习算法
#使用分类算法,这里采用了10种算法
classifiers=[['Random Forest',RandomForestClassifier()],
['support Vector Machine',SVC()],
['LogisticRegression',LogisticRegression()],
['KNN',KNeighborsClassifier(n_neighbors=5)],
['Navie Bayes',GaussianNB()],
['DecisionTree',DecisionTreeClassifier()],
['AdaBoostClassifier',AdaBoostClassifier()],
['GradientBoostingClassifier',GradientBoostingClassifier()],
['XGB',XGBClassifier()],
['CatBoost',CatBoostClassifier(logging_level='Silent')]
]
3、训练模型
Classify_result= []
names= []
prediction= []
f1score = []
for name, classifier in Classifiers:
classifier=classifier
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
recall = recall_score(y_test, y_pred)
precision = precision_score(y_test,y_pred)
f1score = 2 * (recall * precision) / (recall + precision)
class_eva = pd.DataFrame([recall, precision, f1score])
Classify_result.append(class_eva)
name = pd.Series(name)
names.append(name)
y_pred = pd.Series(y_pred)
4、评估模型
召回率(recall)的含义是:原本为对的当中,预测为对的比例(值越大越好,1为理想状态)
精确率、精度(precision)的含义是:预测为对的当中,原本为对的比例(值越大越好,1为理想状态)
F1分数(F1-Score)指标综合了Precision与Recall的产出的结果
F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
names = pd.DataFrame(names)
names = names[0].tolist()
result = pd.concat(Classify_result, axis=1)
result.columns = names
# F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
result.index = ['recall', 'precision', 'f1score']
print(result)
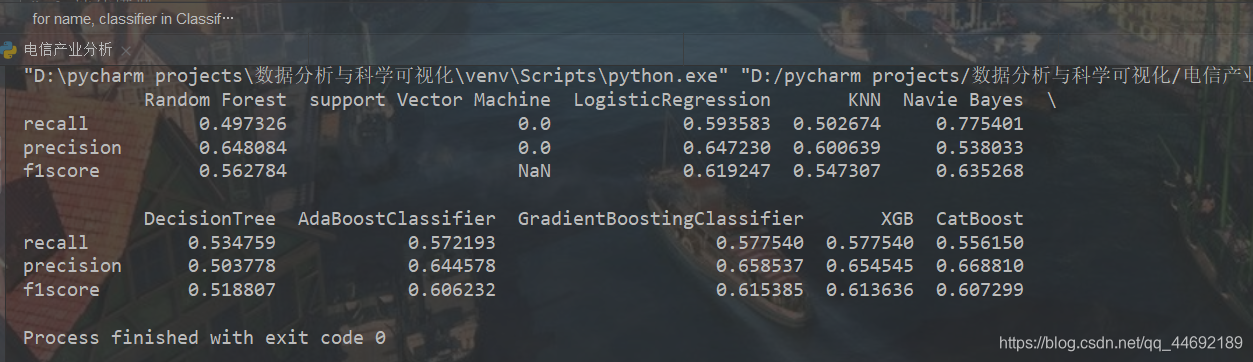
综上所述,在10种分类算法中朴素贝叶斯(Naive Bayes)的F1分数最大为63.52%,所以使用朴素贝叶斯模型效果最好。
5、实施方案
# 预测数据集特征(由于没有提供预测数据集,这里选取后10行作为需要预测的教据集)
pred_X = telconvar.tail(10)
# 提取customerID
pre_id = telcon_id.tail(10)
# 使用朴素贝叶斯方法,对预测数据集中的生存情况进行预测
model = GaussianNB()
model.fit(X_train, y_train)
pred_y = model.predict(pred_X)
# 预测结果
6.结论
通过上述分析,我们可以大致勾勒出容易流失的用户特征:
老年用户与未婚且经济未独立的青少年用户更容易流失。
电话服务对用户的流失没有直接的影响。
提供的各项网络服务项目能够降低用户的流失率。
签订合同越久,用户的留存率越高。
采用electronic check支付的用户更易流失。
针对上述诊断结果,可有针对性的对此提出建议:
推荐老年用户与青少年用户采用数字网络,且签订2年期合同(可以各种辅助优惠等营销手段来提高2年期合同的签订率),若能开通相关网络服务可增加用户粘性,因此可增加这块业务的推广,同时考虑改善电子账单支付的用户体验。
提前完成这个构建模型的过程,哈哈哈哈!!!
