目录
1. Shufflenet V2
shufflenet v2 论文中提出衡量轻量级网络的性能不能仅仅依靠FLOPs计算量,还应该多方面的考虑,例如MAC(memory access cost),还应该比较在不同的硬件设备下的性能等等

因此,基于多方面的考虑。shufflenet v2 通过大量的实验和测试总结了轻量化网络的四个准则,然后根据这四条准则搭建了shufflenet v2网络

- 输入输出通道个数相同的时候,内存访问量MAC最小
- 分组卷积的分组数过大会增加MAC
- 碎片化操作会并行加速并不友好
- element-wise 操作带来的内存和耗时不可以忽略
每条原则的具体解释参考:ShuffleNet V2 迁移学习对花数据集训练_shufflenetv2进行预训练的效果-CSDN博客

2. 甲状腺结节检测
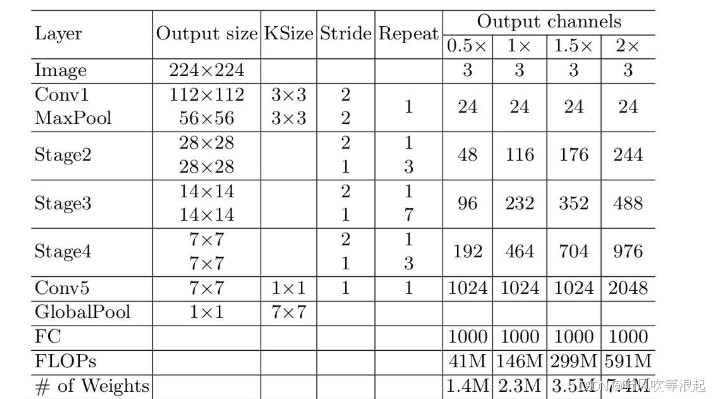
Shufflenet V2 实现的model部分代码如下面所示,这里如果采用官方预训练权重的话,会自动导入官方提供的最新版本的权重

这里提供了4种网络结构,分别对应output channels参数
2.1 数据集
数据集文件如下:

标签如下:
{
"0": "0",
"1": "1"
}其中,训练集的总数为5103,验证集的总数为2185
2.2 训练参数
训练的参数如下:
parser.add_argument("--model", default='x0_5', type=str,help='x0_5,x1_0,x1_5,x2_0')
parser.add_argument("--pretrained", default=True, type=bool) # 采用官方权重
parser.add_argument("--freeze_layers", default=True, type=bool) # 冻结权重
parser.add_argument("--batch-size", default=8, type=int)
parser.add_argument("--epochs", default=10, type=int)
parser.add_argument("--optim", default='SGD', type=str,help='SGD,Adam,AdamW') # 优化器选择
parser.add_argument('--lr', default=0.01, type=float)
parser.add_argument('--lrf',default=0.001,type=float) # 最终学习率 = lr * lrf
parser.add_argument('--save_ret', default='runs', type=str) # 保存结果
parser.add_argument('--data_train',default='./data/train',type=str) # 训练集路径
parser.add_argument('--data_val',default='./data/val',type=str) # 测试集路径需要注意的是网络分类的个数不需要指定,摆放好数据集后,代码会根据数据集自动生成!
网络模型信息如下:
{
"train parameters": {
"model": "x0_5",
"pretrained": true,
"freeze_layers": true,
"batch_size": 8,
"epochs": 10,
"optim": "SGD",
"lr": 0.01,
"lrf": 0.001,
"save_folder": "runs"
},
"dataset": {
"trainset number": 5103,
"valset number": 2185,
"number classes": 2
},
"model": {
"total parameters": 343842.0,
"train parameters": 2050,
"flops": 43550112.0
},2.3 训练结果
所有的结果都保存在 save_ret 目录下,这里是 runs :
weights 下有最好和最后的权重,在训练完成后控制台会打印最好的epoch

这里只展示部分结果:可以看到网络没有完全收敛,增大epoch会得到更好的效果
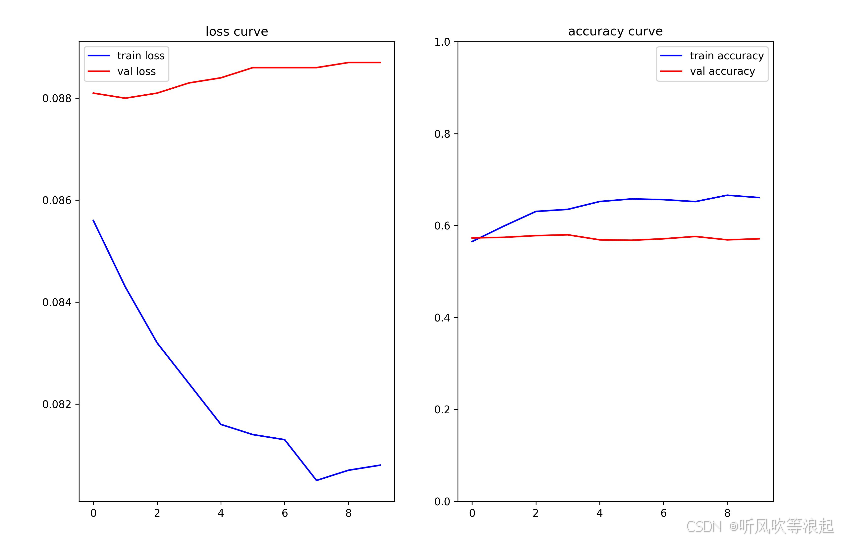
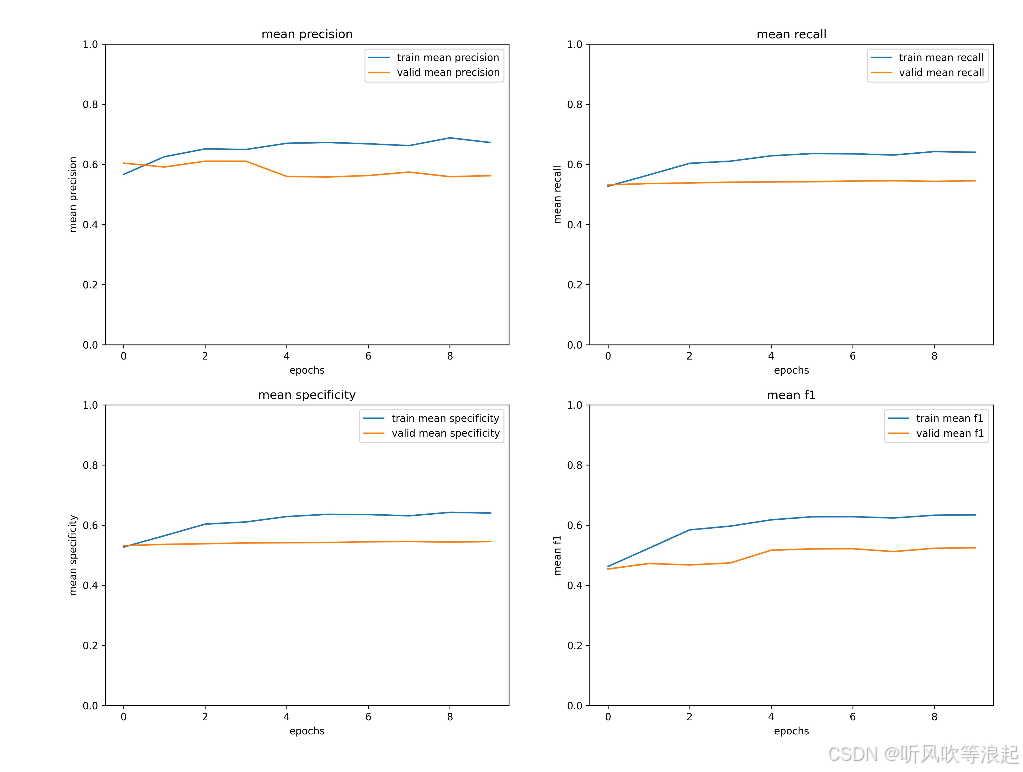
训练日志:
"epoch:9": {
"train info": {
"accuracy": 0.6607877718975881,
"0": {
"Precision": 0.6989,
"Recall": 0.4334,
"Specificity": 0.8471,
"F1 score": 0.535
},
"1": {
"Precision": 0.646,
"Recall": 0.8471,
"Specificity": 0.4334,
"F1 score": 0.733
},
"mean precision": 0.67245,
"mean recall": 0.64025,
"mean specificity": 0.64025,
"mean f1 score": 0.634
},
"valid info": {
"accuracy": 0.5711670480523059,
"0": {
"Precision": 0.5455,
"Recall": 0.2866,
"Specificity": 0.8043,
"F1 score": 0.3758
},
"1": {
"Precision": 0.5791,
"Recall": 0.8043,
"Specificity": 0.2866,
"F1 score": 0.6734
},
"mean precision": 0.5623,
"mean recall": 0.54545,
"mean specificity": 0.54545,
"mean f1 score": 0.5246
}
}
训练集和测试集的混淆矩阵:
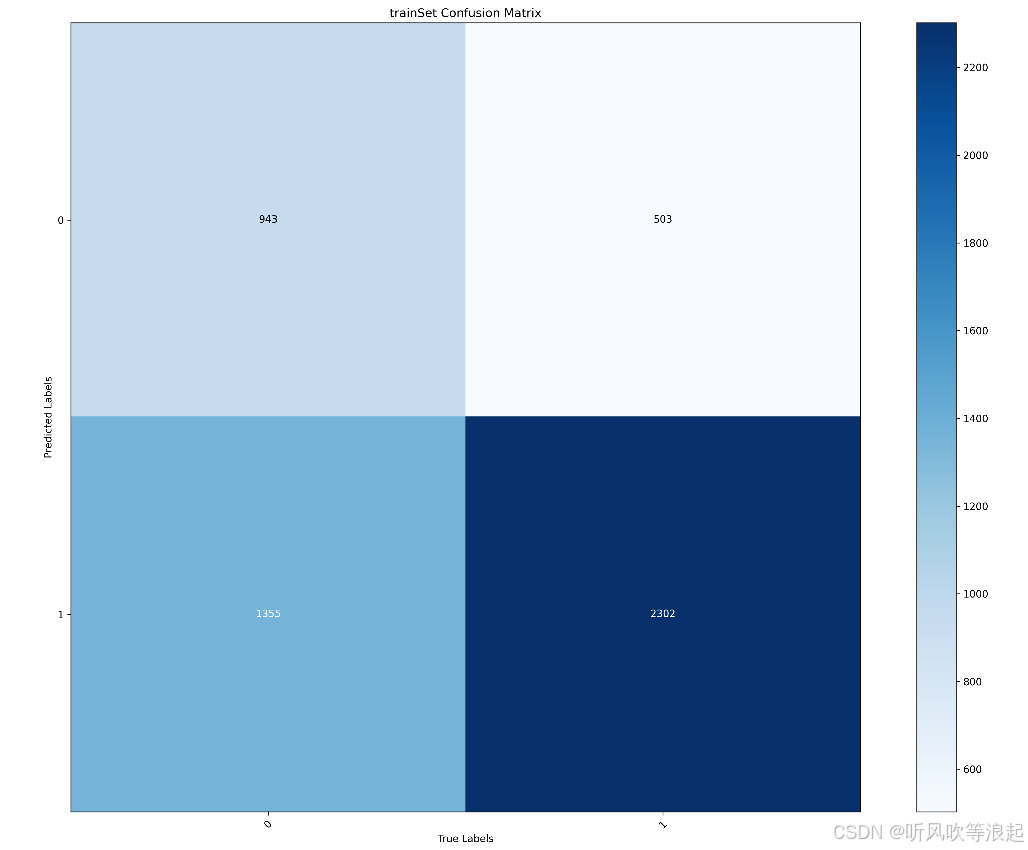
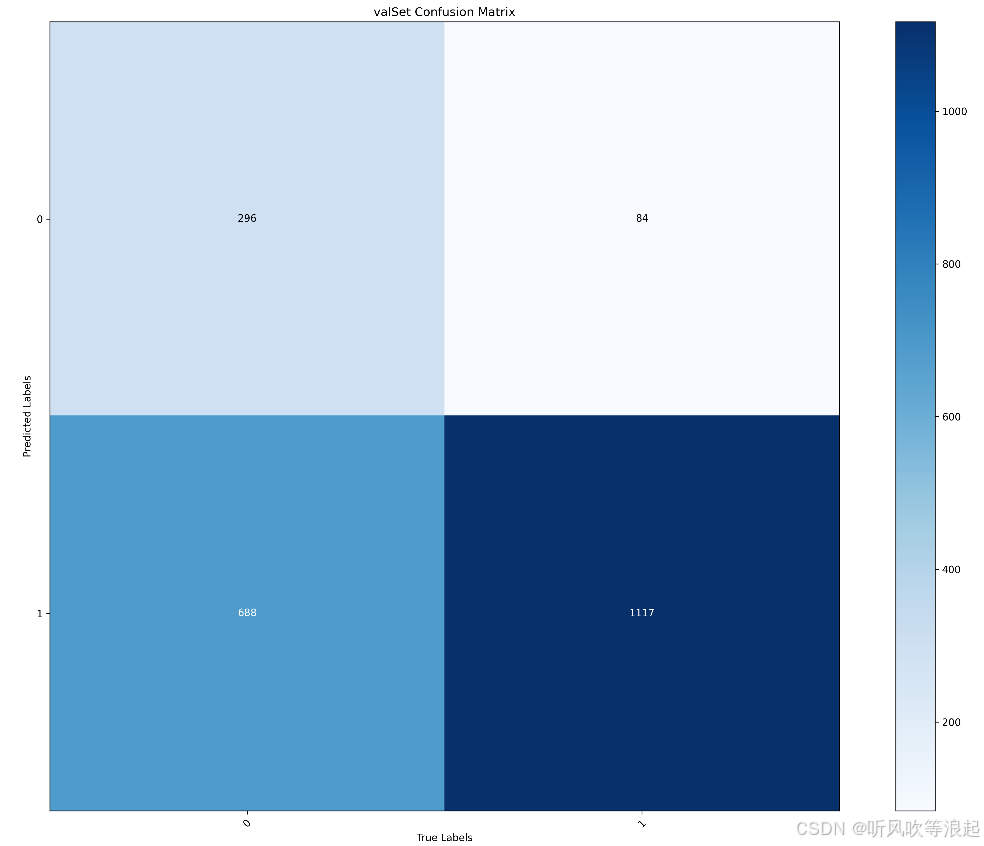
2.4 可视化网页推理
推理是指没有标签,只有图片数据的情况下对数据的预测,这里使用了网页推理
值得注意的是,如果训练了自己的数据集,需要对infer脚本进行更改,如下:

- 都需要绝对路径,这个是代码自动生成的类别文件,在runs下
- IMAGE_PATH 是默认展示的demo图片位置
在控制台输入下面命令即可:
streamlit run D:\project\shufflenetV2\infer.py

3. 下载
关于本项目代码和数据集、训练结果的下载:
计算机视觉项目:计算机视觉项目:ShufflenetV2模型实现的图像识别项目:甲状腺结节识别资源-CSDN文库
关于Ai 深度学习图像识别、医学图像分割改进系列:AI 改进系列_听风吹等浪起的博客-CSDN博客
神经网络改进完整实战项目:改进系列_听风吹等浪起的博客-CSDN博客