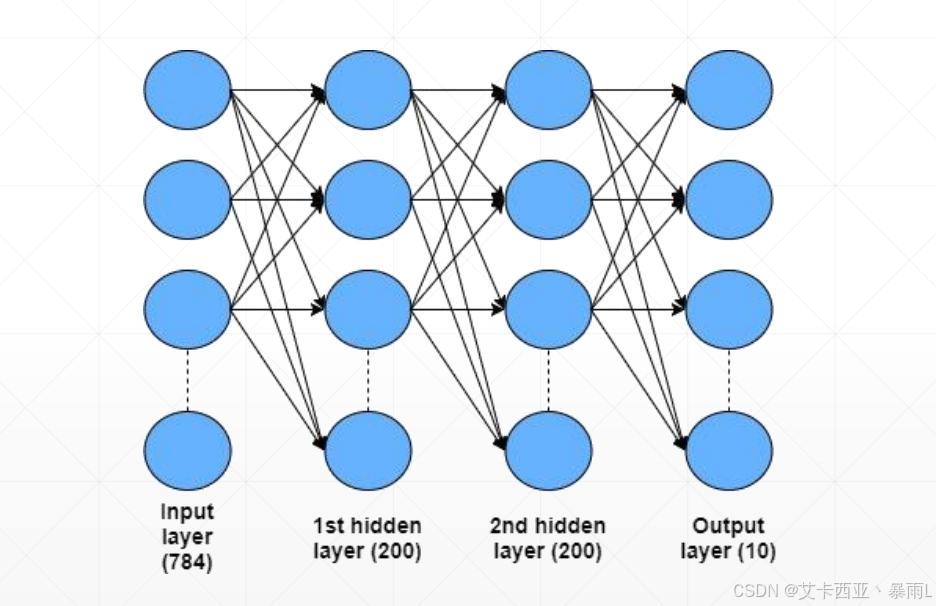
网络结构以及示例
该网络的输出不是一层或两层的,而是一个十层的代表有十分类
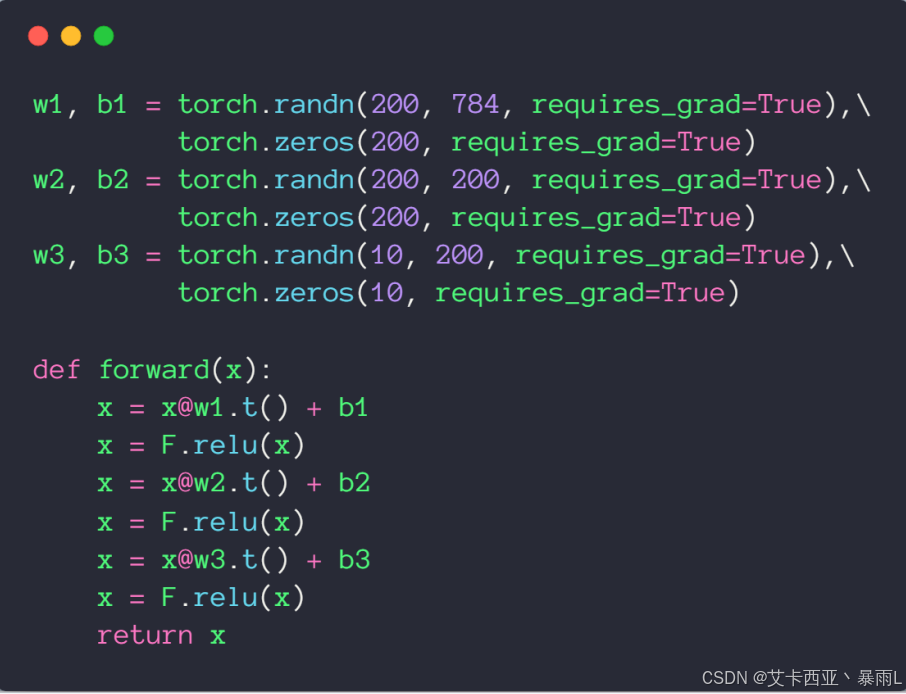
新建三个线性层,每个线性层都有w和b的tensor
首先输入维度是784,第一个维度是ch_out,第二个维度才是ch_in(由于后面要转置),没有经过softmax函数和sigmoid,即logits
上图已经完成了网络的参数的定义和网络的前向传播过程
nn.CrossEntropyLoss()与F.cross_entropy()是一样的功能,都包含softmax和log和F.nll_loss
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size = 200
learning_rate = 0.01
epochs = 10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
w1, b1 = torch.randn(200, 784, requires_grad=True), \
torch.zeros(200, requires_grad=True)
w2, b2 = torch.randn(200, 200, requires_grad=True), \
torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True), \
torch.zeros(10, requires_grad=True)
def forward(x):
x = x @ w1.t() + b1
x = F.relu(x)
x = x @ w2.t() + b2
x = F.relu(x)
x = x @ w3.t() + b3
x = F.relu(x)
return x
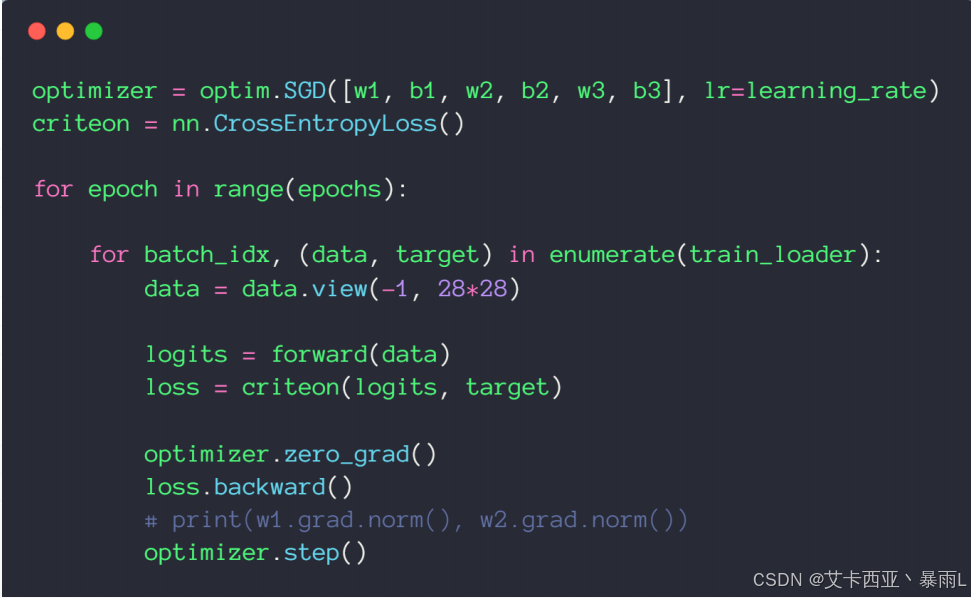
# train
optimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate)
criten = nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28 * 28)
logits = forward(data)
loss = criten(logits, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = forward(data)
test_loss += criten(logits, target).item()
# 每一行的最大值对应的索引
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
创建的loss一直不变,为什么会出现这个问题,这个网络的结构层次并不深,数据集也比较简单,但这里出现了梯度弥散的情况,因为loss长时间得不到更新,因为梯度信息几乎接近于0
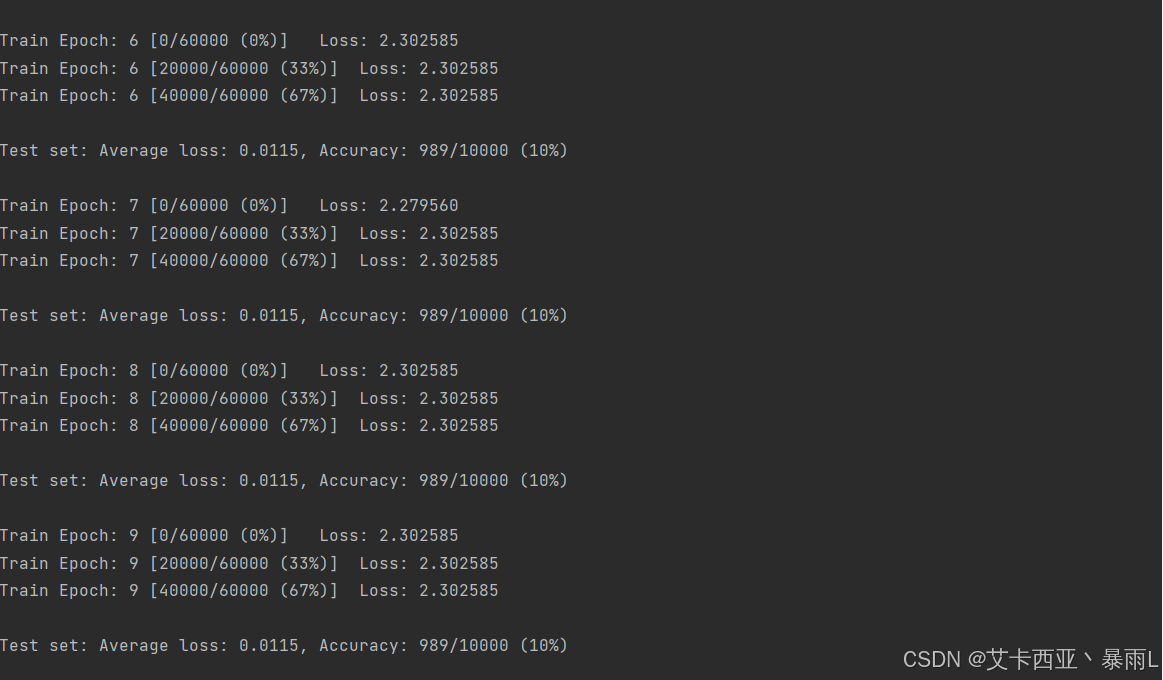
为什么会出现梯度为0?
影响训练的因素,除了有loss,学习率过大,还有初始化的问题,把初始化代码加上
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
为什么b不初始化,因为已经初始化为0了
但是w也初始化,只是它们使用的是高斯分布进行初始化,即使是用高斯分布初始化后,结果也不满意,所以用了何凯明的初始化
可以看出loss直接到0.4了,准确率也达到了80%,而且这里还没运行完,运行完效果会更好
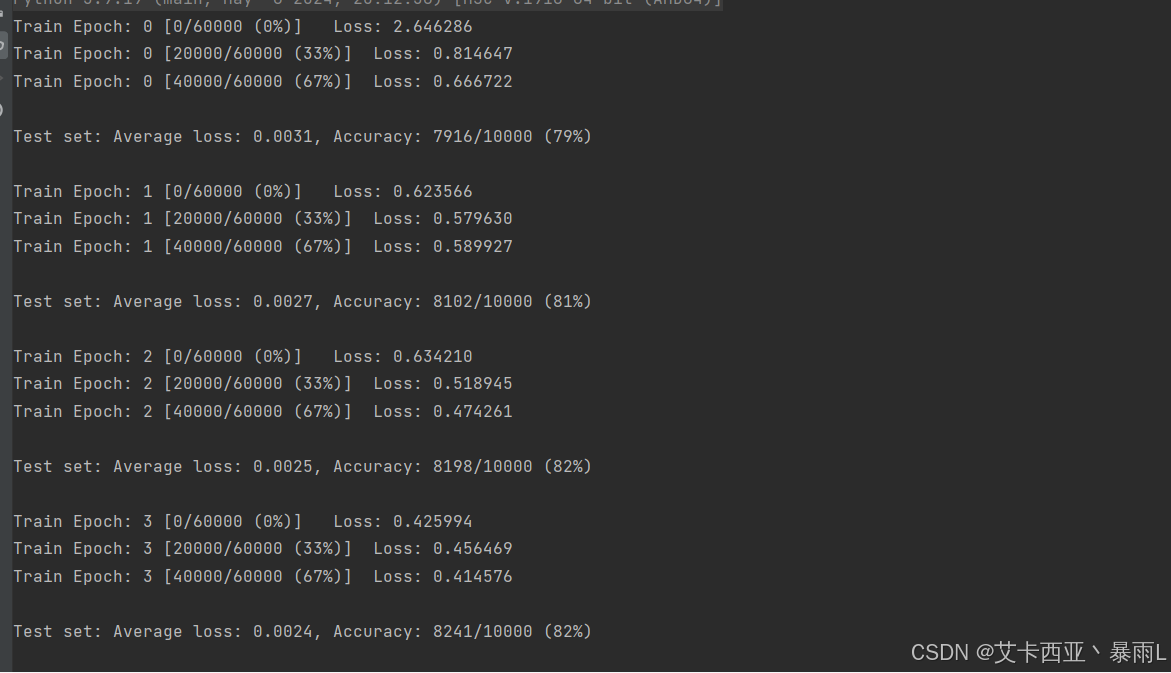
可以看出对于分类问题,初始化参数非常关键