论文题目
免验证的对于复制鲁棒性的基于量的数据估值
1. 本文具体贡献
- 通过数据的体积形式化了数据多样性的度量,并在理论上和实证上证明了体积对数据估值的适用性;
- 形式化了复制鲁棒性的概念,并设计了一种基于稳健体积(RV)度量的数据估值方法,并在理论上保证了复制鲁棒性
- 与基线方法进行了广泛的实证比较,以证明我们的方法在无需验证的情况下具有一致的估值结果,具有复制鲁棒性,并且可以灵活地适应处理诸如各种神经网络等复杂的机器学习模型
2. 问题设置和符号(想要看懂的话认真看)
考虑两个带估值的数据子矩阵
X
S
X_S
XS和
X
S
′
X_{S'}
XS′,分别包含了
s
s
s和
s
′
s'
s′行的d维输入特征向量。
设
P
S
:
=
[
X
S
T
0
]
T
∈
R
n
×
d
P_S :=[X^T_S 0]^T \in \mathbb R^{n \times d}
PS:=[XST0]T∈Rn×d是
X
S
∈
R
n
×
d
X_S \in \mathbb R^{n \times d}
XS∈Rn×d的零填充版本。
我们沿着行将数据子矩阵连接起来形成完整的数据矩阵
X
S
∈
R
n
×
d
,
i
.
e
.
,
X
:
=
[
X
S
T
X
S
′
T
]
T
X_S \in \mathbb R^{n \times d},i.e.,X := [X^T_S X^T_{S'}]^T
XS∈Rn×d,i.e.,X:=[XSTXS′T]T并且
n
=
s
+
s
′
n=s+s'
n=s+s′(别担心,这里的T是转置矩阵,用两个T是为了验证行进行拼接)
我们将对应的标签表示为:
y
:
=
[
y
S
T
y
S
′
T
]
∈
R
n
×
1
y:=[y^T_Sy^T_{S'}]\in \mathbb R^{n\times 1}
y:=[ySTyS′T]∈Rn×1
OLS的最小二乘解为:
w
:
=
X
+
y
=
a
r
g
m
i
n
β
∣
∣
y
−
X
β
∣
∣
2
w:=X^{+}y=argmin_\beta||y-X\beta||^2
w:=X+y=argminβ∣∣y−Xβ∣∣2
X
+
:
=
(
X
T
X
)
−
1
X
T
X^{+}:=(X^TX)^{-1}X^T
X+:=(XTX)−1XT是
X
X
X的伪逆
相似的,我们用
X
S
+
X^+_S
XS+作为
X
S
X_S
XS的伪逆,
w
S
:
=
X
S
+
y
S
w_S:=X^{+}_Sy_S
wS:=XS+yS
同时为了简化公式:令
V
:
=
V
o
l
(
X
)
V := Vol(X)
V:=Vol(X)和
V
S
:
=
V
o
l
(
X
S
)
V_S := Vol(X_S)
VS:=Vol(XS)
Vol()的定义如下,
∣
A
∣
代表
A
的行列式
|A|代表A的行列式
∣A∣代表A的行列式,X的左Gram矩阵为
G
:
=
X
T
X
∈
R
d
×
d
G:=X^TX\in \mathbb R^{d\times d}
G:=XTX∈Rd×d,所以对于数据子矩阵
X
S
X_S
XS,
G
S
:
=
X
S
T
X
S
∈
R
d
×
d
G_S:=X^T_SX_S\in \mathbb R^{d\times d}
GS:=XSTXS∈Rd×d
Definition 1 (Volume). 对于一个满秩的矩阵
X
∈
R
n
×
d
X \in \mathbb{R}^{n \times d}
X∈Rn×d,其中
n
≥
d
n \geq d
n≥d,定义其体积为
V
o
l
(
X
)
:
=
∣
(
X
>
X
)
∣
=
∣
G
∣
Vol(X) := \sqrt{|(X>X)|} = \sqrt{|G|}
Vol(X):=∣(X>X)∣=∣G∣。我们采用上述对体积的定义有以下几个原因:
(a) 通常,数据的输入特征空间是由数据收集过程中预先确定和固定的。但是,新的数据可以不断涌入,因此
n
n
n 可以无限增长,而
d
d
d 保持不变。
(b) 通过利用体积与学习性能之间的形式联系(第3节),我们可以设计一个无需验证的基于体积的数据估值方法,将更大的价值分配给导致更好学习性能的数据。
© 这为体积和多样性之间提供了直观的解释:向数据集添加一个数据点可以增加多样性/体积,具体取决于数据集中已有的数据点(引理1)。
在实践中,我们进行预处理,比如主成分分析,以减少输入特征空间的维度,以确保这一假设得到满足。这一假设是为了确保没有冗余特征,即可以使用其他特征进行精确重构的特征。例如,如果数据集已经包含了月薪,那么年薪将是冗余的。
概念性讲解
OLS(Ordinary Least Squares,普通最小二乘)
OLS是一种常用的线性回归方法,用于拟合线性模型到数据中。在OLS中,我们试图找到一组系数,使得模型的预测值与实际观测值之间的残差平方和最小化。
对于给定的数据集,假设有一个包含n个样本的数据矩阵X,其中每行表示一个样本,每列表示一个特征。同时,有一个长度为n的目标向量y,表示每个样本的观测值。
OLS的目标是找到一个系数向量w,使得模型的预测值
X
w
X_w
Xw与观测值y之间的残差的平方和最小化。数学上,这可以表示为以下最小化问题:
w
O
L
S
=
a
r
g
w
m
i
n
∣
∣
y
−
X
w
∣
∣
2
2
w_{OLS}=arg_wmin||y-Xw||^2_2
wOLS=argwmin∣∣y−Xw∣∣22
向量的二范数
向量的二范数,也称为欧几里得范数(Euclidean Norm),是指向量中各个元素的平方和再开方得到的结果。对于一个n维向量v,其二范数表示为:
∣
∣
v
∣
∣
2
=
v
1
2
+
v
2
2
+
.
.
.
+
v
n
2
||v||_2=\sqrt{v^2_1+v^2_2+...+v^2_n}
∣∣v∣∣2=v12+v22+...+vn2
伪逆
伪逆(Pseudoinverse)是一种广义逆的概念,在线性代数和矩阵计算中经常用到。伪逆是针对非方阵或奇异矩阵的情况而提出的,因为对于这些矩阵来说,它们没有逆矩阵。
广义逆有几种不同的定义,其中最常见的是 Moore-Penrose 广义逆。给定一个矩阵
A
A
A,它的 Moore-Penrose 广义逆通常表示为
A
+
A^+
A+。广义逆满足以下四个性质:
[
A
A
+
A
=
A
A
+
A
A
+
=
A
+
(
A
A
+
)
T
=
A
A
+
(
A
+
A
)
T
=
A
+
A
]
[ \begin{align*} AA^+A &= A \\ A^+AA^+ &= A^+ \\ (AA^+)^T &= AA^+ \\ (A^+A)^T &= A^+A \end{align*} ]
[AA+AA+AA+(AA+)T(A+A)T=A=A+=AA+=A+A]
3 更大的数据量意味着更好的学习性能
通过普通最小二乘(OLS)框架来正式化这一说法。具体来说,我们将研究两个学习性能的度量指标
(a)由偏差表示的伪逆质量
b
i
a
s
S
:
=
∣
∣
P
S
+
−
X
+
∣
∣
bias_S:=||P^+_S-X^+||
biasS:=∣∣PS+−X+∣∣,因为准确估计
X
+
X^+
X+ 对于达到较小的均方误差(MSE)是重要的,其中
P
S
+
:
=
(
X
S
T
X
S
)
−
1
P
S
T
P^+_S:=(X^T_SX_S)^{-1}P^T_S
PS+:=(XSTXS)−1PST
(b)作为MSE表示的均方误差:
L
(
w
S
)
:
=
∣
∣
y
−
X
w
S
∣
∣
2
L(w_S):=||y-Xw_S||^2
L(wS):=∣∣y−XwS∣∣2
3.1 更大量的数据意味着更小的偏差
命题1(数据量VS偏差对于d=1)。对于 x ∈ R n × 1 x \in \mathbb R^{n\times 1} x∈Rn×1的非零 X S , X S ′ X_S,X_{S'} XS,XS′,有 V S ≥ V S ′ ⟺ b i a s S − b i a s S ′ ≤ 0 V_S\ge V_{S'} \Longleftrightarrow bias_S-bias_{S'} \le 0 VS≥VS′⟺biasS−biasS′≤0
命题2(一般情况下的体积 vs. 偏差)。对于
X
∈
R
n
×
d
X \in \mathbb{R}^{n \times d}
X∈Rn×d 的满秩的
X
S
X_S
XS、
X
S
′
X_{S'}
XS′,有
b
i
a
s
S
2
−
b
i
a
s
S
′
2
=
1
V
S
4
∥
Q
S
X
S
T
∥
2
−
1
V
S
′
4
∥
Q
S
′
X
S
′
T
∥
2
+
2
⟨
1
V
2
Q
X
T
,
1
V
S
′
2
Q
S
′
P
S
′
T
−
1
V
S
2
Q
S
P
S
T
⟩
\begin{align*} &bias^2_S - bias^2_{S'} \\ &= \frac{1}{V^4_S} \left\| Q_S X^T_S \right\|^2 - \frac{1}{V^4_{S'}} \left\| Q_S' X^T_{S'} \right\|^2 \\ &\quad + 2 \left\langle \frac{1}{V^2} QX^T, \frac{1}{V^2_{S'}} Q_{S'} P^T_{S'} - \frac{1}{V^2_S} Q_S P^T_S \right\rangle \end{align*}
biasS2−biasS′2=VS41
QSXST
2−VS′41
QS′XS′T
2+2⟨V21QXT,VS′21QS′PS′T−VS21QSPST⟩
其中
Q
:
=
∑
l
=
1
k
(
λ
l
σ
l
)
−
1
∏
j
=
1
,
j
≠
l
k
(
G
−
λ
j
I
)
,
{
λ
l
}
l
=
1
k
表示矩阵
X
的左 Gram 矩阵
G
的
k
个唯一特征值
,
Q
S
,
Q
S
′
相应地定义于
G
S
,
G
S
′
,
P
S
和
P
S
′
分别是
X
S
和
X
S
′
的零填充版本
,
σ
l
:
=
∑
g
=
1
k
(
−
1
)
g
+
1
λ
k
−
g
l
[
∑
H
⊂
{
1
,
.
.
.
,
k
}
∖
{
l
}
,
∣
H
∣
=
g
−
1
(
∏
h
∈
{
1
,
.
.
.
,
k
}
∖
H
λ
h
−
1
)
]
.
\begin{align*} Q &:= \sum_{l=1}^{k}(\lambda_l\sigma_l)^{-1} \prod_{j=1,j \neq l}^{k}(G - \lambda_j I), \\ \{\lambda_l\}_{l=1}^{k} &\text{ 表示矩阵 } X \text{ 的左 Gram 矩阵 } G \text{ 的 } k \text{ 个唯一特征值}, \\ Q_S, Q_S' &\text{ 相应地定义于 } G_S, G_S', \\ P_S \text{ 和 } P_S' &\text{ 分别是 } X_S \text{ 和 } X_S' \text{ 的零填充版本}, \\ \sigma_l &:= \sum_{g=1}^{k}(-1)^{g+1}\lambda_{k-g}^{l} \left[ \sum_{H \subset \{1,...,k\}\setminus \{l\},|H|=g-1} \left( \prod_{h \in \{1,...,k\}\setminus H} \lambda_h^{-1} \right) \right]. \end{align*}
Q{λl}l=1kQS,QS′PS 和 PS′σl:=l=1∑k(λlσl)−1j=1,j=l∏k(G−λjI), 表示矩阵 X 的左 Gram 矩阵 G 的 k 个唯一特征值, 相应地定义于 GS,GS′, 分别是 XS 和 XS′ 的零填充版本,:=g=1∑k(−1)g+1λk−gl
H⊂{1,...,k}∖{l},∣H∣=g−1∑
h∈{1,...,k}∖H∏λh−1
.
本文通过经验验证结论第3节的方法,检验第3.1节最后一段描述的附加假设是否成立,即通过检查
V
S
≥
V
S
′
⟺
b
i
a
s
S
−
b
i
a
s
S
′
≤
0
V_S\ge V_{S'} \Longleftrightarrow bias_S-bias_{S'} \le 0
VS≥VS′⟺biasS−biasS′≤0成立的百分比次数。
实验设置如下:
在500次独立试验中随机且相同地抽样相同大小的XS、XS’,并计算更大的体积导致更好的学习性能的百分比(纵轴)与XS、XS’大小(横轴)的关系。
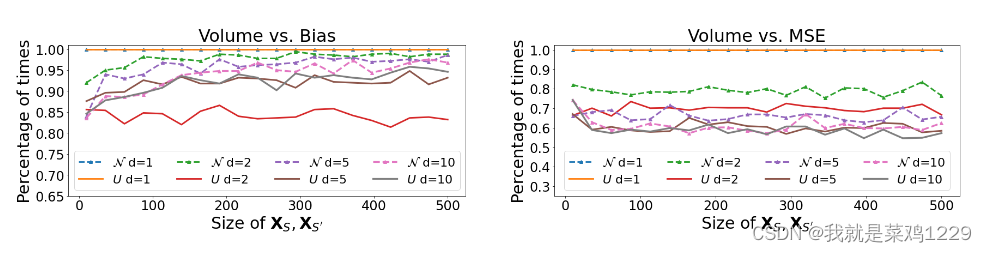
3.2 更大量的数据意味着均方误差越小
命题3(d = 1 时的体积 vs. 均方误差)。对于
X
∈
R
n
×
1
X \in \mathbb{R}^{n \times 1}
X∈Rn×1 的非零
X
S
X_S
XS、
X
S
′
X_{S'}
XS′,有
V
S
≥
V
S
′
⇔
L
(
w
S
)
−
L
(
w
S
′
)
≤
0
V_S \geq V_{S'} \Leftrightarrow L(w_S) - L(w_{S'}) \leq 0
VS≥VS′⇔L(wS)−L(wS′)≤0。
不幸的是,以上结果不适用于d > 1的情况。