前言
在前面的文章中,我们系统的介绍了线性表的顺序存储实现——顺序表。紧接着我们要介绍线性表的链式存储实现——链表。而链表中又有许多的链表:
- 单链表
- 双链表
- 循环链表
- 静态链表
这一篇文章中,我们先来介绍单链表。
单链表的定义
什么是单链表
要想知道什么是单链表,我们就可以使用我们学习过的顺序表来对比学习(对比学习有助于你的记忆,使用学习过的知识去学习未知的知识,也未尝不是一种好方法)
物理地址可以不相邻
我们都知道顺序表是申请一大块连续的区域,并且使用物理地址相邻的方法来表示逻辑上的相邻。而链表逻辑上相邻的元素在内存中可以是不相邻存放的。
结点存放数据值和下一结点地址
那么如果链表中的元素在内存中不是相邻存放的,那我们如何知道下一个元素的位置呢?于是,就提出了在一个结点中我们同时存入数据元素值和存放下一个元素的结点。
换句话来说可就是,一个柜子里放入我们需要放入的东西(元素的值)并且放入存放下一个元素的柜子序号(存放下一元素结点的地址),如下图所示:
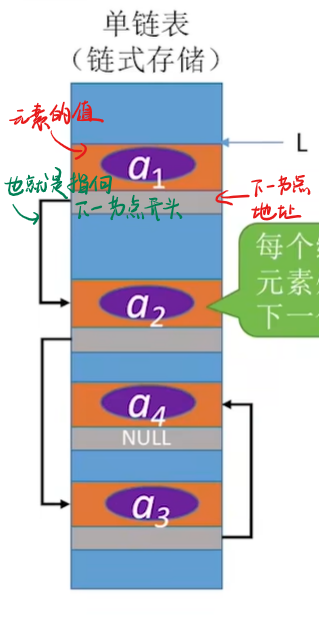
这里说句题外话:赋给指针一个地址,可以理解为指针指向了这个地址。给指针地址,就是让指针指向。(希望这能更有助于你去理解指针的含义)
优点:不要求大片连续空间,改变容量方便
由于指针不需要通过物理地址相邻来表示逻辑相邻,因此也就不要求大片连续的空间。因此改变链表的容量就会变得很方便。
缺点:不可随机存取,要消耗一定空间存放指针
不可随机存取
顺序表可以通过知道元素的大小和开头的元素地址,从而快速的找到所需要位置的元素。但是链表不行,由于链表结点在内存中是分散存储的,所以导致不能直接找到元素,需要通过遍历元素来寻找。
比如我要找a3这个元素,我就需要先进入到a1,从a1存储的a2的地址找到a2。再访问a2通过a2存放的a3的地址找到a3。
消耗一定空间存放指针
由于链表是通过结点中存放的下一结点的地址,来寻找下一结点,从而使各个分散在内存中的结点联系起来。所以一个结点中就必须分为两部分:一部分存放数据据元素,而另一部分存放下一结点的地址。
用代码定义一个单链表
从上述对于单链表的粗略介绍,我们都知道链表中的结点需要有两部分:一部分存放数据元素,一部分存放下一结点的地址。
那么我们就大概知道了如何去定义一个结构体代表一个结点。
struct LNode{ // 定义单链表结点类型
ElemType data; // 每个结点存放一个数据元素
struct LNode *next; // 指针指向下一个结点
};
以上就是一个链表的结点。
如果我们想扩展链表的容量就可以使用之前使用过的malloc()函数。
struct LNode *p = (struct LNode *)malloc(sizeof(struct LNode)),但是到这里有一个问题,就是我们会发现在我们每次去使用我们定义的这个结构体的时候都需要写成struct LNode...,这对于懒癌患者的我们是不被允许的。为此,我们可以使用typedef来给一些关键字“起外号”。
typedef <数据类型> <别名>:给某个数据类型起一个别名,在后面我们可以使用别名。举个例子:
typedef int zhengshu; // 给int起一个外号叫做zhengshu
int i 等价 zhengshu i // 此时使用int i可以声明一个整型的变量,使用zhengshu i同样可以
typedef int *zhengshuzhizhen;
int *i 等价 zhegnshuzhizhen i
因此我们可以通过typedef struct LNode LNode来简化,不需要再写struct LNode只用写LNode。当然typedef有两种写法:
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
// 等价于
struct LNode{
ElemType data;
struct LNode *next;
};
typedef struct LNode LNode; // 强调是一个结点
typedef struct LNode *LinkList; // 强调是一个单链表
在单链表中,我们要表明单链表是在哪个位置该如何表示?很简单我们只需要有一个指针指向链表的第一个结点,通过这个指针就可以知道链表所在的位置了,这个指针我们就称为头指针。
头指针声明应该是LNode *L,但是由于我们上面已经给LNode起了个外号叫做LinkList,所以直接使用其声明即可LinkList L。可能有小伙伴会觉得这多此一举,但是这可以增加代码的可读性。我们来举例解释。
LNode * GetElem(LinkList L,int i){
...
}
我们可以看到上述这段代码,既使用了LNode *也使用了LinkList。因为在GetElem()这个函数中(主要功能使获取某个元素),我们想要强调的是从一个单链表中(LinkList L)获取某个元素,并且返回的是一个结点(LNode *)。
从这里我们就可以看出来,虽然说LNode *和LinkList实现的效果是一样的,但是对于直接字面的意思理解LNode是链表的结点的意思,而LinkList字面意思是单链表。这无疑是增加了代码的可读性。
两种实现
不带头结点
我们首先来实现一下不带头结点(第一个结点)的单链表
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool InitList(LinkList &L){
L = NULL; // 表示空表,暂时没有任何结点(防止脏数据)
return true;
}
void test(){
LinkList L; // 声明一个指向单链表的指针
// 初始化一个空表
InitList(L);
}
代码分析
- 首先我们在这里看
test()函数,使用LinkList L来声明一个指向单链表的头指针。使用LinkList而不是LNode是想强调这里的L是一个单链表。 - 紧接着进入
InitList()初始化函数,将L设置为NULL值初始化防止脏数据,并且通过L中的NULL来表示是空表。并且返回true表示成功。这里使用&L引用,是因为我们要将改变的L带回test()函数中的L,如果不使用引用在InitList()改变的L的值将不会对test()中产生影响
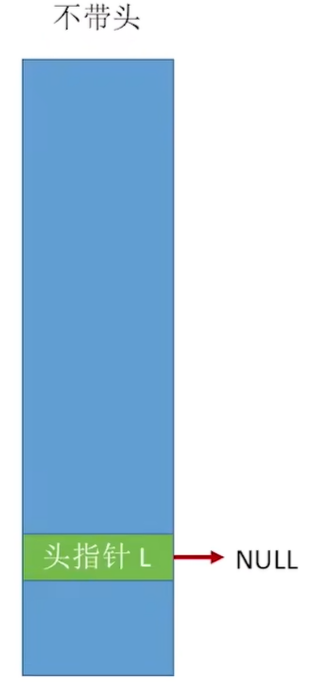
判断单链表是否为空
我们在上面说了,我们将L的值设置为NULL来表示空表,那么我们就可以通过L中的值是否为NULL来判断单链表是否为空表
bool Empty(LinkList L){
if(L==NULL)
return true;
else
return false;
}
// 简化
bool Empty(LinkList L){
return (L==NULL);
}
代码分析
我们通过判断L的值是否为NULL来判断单链表是否为空这非常简单,因此不在解释。这里的简化,我来做一个解释,首先a == b这种运算产生的结果为布尔值(true、false),而我们刚好就是需要L==NULL返回true,否则返回false,正好这个比较的结果返回的也是true或者false,因此可以这样简化。
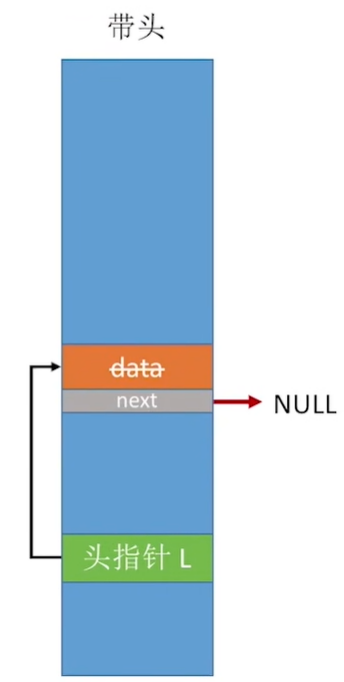
带头结点
带头结点的实现起始跟不带头结点的实现就是相差了一个是创建一个新的结点。
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool InitList(LinkList &L){
L = (LNode *)malloc(sizeof(LNode)); // 分配一个头结点
if(L==NULL) // 内存不足分配失败
return false;
L->next = NULL; // 头结点之后没有结点
return true;
}
void test(){
LinkList L; // 声明一个指向单链表的指针
// 初始化一个空表
InitList(L);
}
代码分析
上述的代码我着重分析一下InitList()函数
- 首先使用
malloc()函数创建一个新的结点并且将头指针L指向新节点,并且为了代码的健壮性,我们做一个判断,若L==NULL,则代表内存中已经没有空间了,所以分配失败 - 如果创建成功,则将新节点指向下一节点的指针设置为NULL,返回true
判断单链表是否为空
bool Empty(LinkList L){
if(L->next==NULL)
return true;
else
return false;
}
在带头结点的单链表中,我们通过头结点的指针是否为NULL来判断链表是否为空。
不带头结点 vs 带头结点
首先不带头结点的实现,对于第一个数据结点和后续数据节点的处理需要使用不同的代码来处理(处理逻辑不同),反之。总而言之就是带头结点的实现方法是比较推荐的,因为比较方便。
结束语
已同步更新至个人博客:https://www.hibugs.net/index.php/linklistdf/
本人菜鸟一枚,仅分享学习笔记和经验。若有错误欢迎指出!共同学习、共同进步 😃
如果您觉得我的文章对您有所帮助,希望可以点个赞和关注,支持一下!十分感谢~(若您不想也没关系,只要文章能够对您有所帮助就是我最大的动力!)
下一篇文章传送门:正在更新,敬请期待…