8.1 简介
DQN算法敲开了深度强化学习的大门,但是作为先驱性的工作,其本身存在着一些问题以及一些可以改进的地方。于是,在DQN之后,学术界涌现出了非常多的改进算法。本章将介绍其中两个非常著名的算法:Double DQN 和Dueling DQN,这两个算法的实现非常简单,只需要在DQN的基础上稍加修改,他们能在一定程度上改善DQN的效果。如果读者想要了解更多、更详细的DQN改进方法,可以阅读Rainbow模型的论文机器引用文献。
8.2 Double DQN
普通的DQN算法通常会导致对Q值的过高估计。传统DQN优化的TD误差目标为,其中
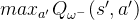
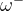
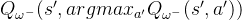
换句话说,max操作实际可以被拆解为两部分:首先选取状态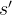
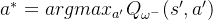
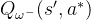
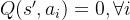
, 但是由于神经网络拟合的误差通常会出现某些动作的估算有正误差的情况,即存在某个动作
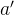
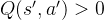
为了解决这一个问题,Double DQN算法提出利用两个独立训练的神经网络估算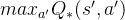
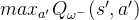
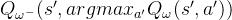
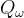
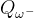
在传统的DQN算法中,本来就存在两套Q函数的神经网络--目标网络和训练网络,只不过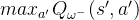
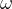

.
8.3 Double DQN代码实践
显然,DQN与Double DQN的差别只是在于计算状态
DQN的优化目标可以写为,动作的选取依靠目标网络
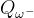
Double DQN的的优化目标为,动作的选取依靠训练网络
Double DQN的的代码实现可以直接在DQN的基础上进行,无需做过多修改。
本节采用的环境时倒立摆,该环境下有一个处于随机位置的倒立摆,如下图所示。环境的状态包括倒立摆角度的正弦值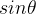
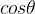
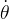
,倒立摆向上保持直立不动时奖励为0,倒立摆在其他位置时奖励为负数。环境本身没有终止状态,运行200步后游戏会自动结束。

| 标号 | 名称 | 最小值 | 最大值 |
|---|---|---|---|
| 0 | | -1.0 | 1.0 |
| 1 | 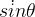 | -1.0 | 1.0 |
| 2 | | -8.0 | 8.0 |
| 标号 | 动作 | 最小值 | 最大值 |
|---|---|---|---|
| 0 | 力矩 | -2.0 | 2.0 |
力矩大小是在[-2,2]范围内的连续值。由于DQN只能处理离散动作环境,因此我们无法直接使用DQN来处理倒立摆环境,但倒立摆环境可以比较方便地验证DQN对Q值的过高估计:倒立摆环境下Q值的最大估计应为0(倒立摆向上保持直立时能选取的最大Q值),Q值出现大于0的情况则出现了过高估计。为了能够应用DQN,我们采用离散化动作的技巧。例如,下面的代码将连续的动作空间离散为11个动作。动作![[0,1,2,3,...,9,10]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUIwJTJDMSUyQzIlMkMzJTJDLi4uJTJDOSUyQzEwJTVE)
![[-2,-1.6,-1.2,...,1.2,1.6,2]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUItMiUyQy0xLjYlMkMtMS4yJTJDLi4uJTJDMS4yJTJDMS42JTJDMiU1RA%3D%3D)
接下来我们给出完整代码。
# -*- coding: utf-8 -*-
"""
@File : DoubleDQN.py
@Author : Administrator
@Time : 2024-09-05 9:07
@IDE : PyCharm
@Version :
@comment : ···
"""
import random
import gym
import numpy as np
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import rl_utils
from tqdm import tqdm
class Qnet(torch.nn.Module):
'''只有一层隐藏层的Q网络'''
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
class DQN:
'''DQN算法,包括Double DQN'''
def __init__(self, state_dim, hidden_dim, action_dim,
learning_rate, gamma, epsilon, target_update,
device, dqn_type = 'VanillaDQN'):
self.action_dim = action_dim
self.q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device)
self.target_q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device)
self.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=learning_rate)
self.gamma = gamma
self.epsilon = epsilon
self.target_update = target_update
self.count = 0
self.dqn_type = dqn_type
self.device = device
def take_action(self, state):
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
#直接将状态转换为张量并调整形状
state = torch.tensor([state], dtype=torch.float).unsqueeze(0).to(self.device)
action = self.q_net(state).argmax().item()
return action
def max_q_value(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
return self.q_net(state).max().item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions) #Q值
#下个状态的最大Q值
if self.dqn_type == 'DoubleDQN': #DQN与Double DQN的区别
max_action = self.q_net(next_states)
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)
else:#DQN的情况
max_next_q_values = self.target_q_net
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones) #TD误差目标
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets))#均方误差损失函数
self.optimizer.zero_grad() #Pytorch中默认梯度会累积,这里需要显式将梯度置为0
dqn_loss.backward() #反向传播更新参数
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict()) #更新目标网络
self.count += 1
def dis_to_con(discrete_action, env, action_dim):#离散动作转回连续的函数
action_lowbound = env.action_space.low[0] #连续动作的最小值
action_upbound = env.action_space.high[0] #连续动作的最大值
return action_lowbound + (discrete_action / (action_dim - 1)) * (action_upbound - action_lowbound)
def train_DQN(agent, env, num_episodes, replay_buffer, minimal_size, batch_size):
return_list = []
max_q_value_list = []
max_q_value = 0
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state, _ = env.reset()
done = False
while not done:
state = state[0]
action = agent.take_action(state)
max_q_value = agent.max_q_value(state) * 0.005 + max_q_value * 0.995 #平滑处理
max_q_value_list.append(max_q_value) #保存每个状态的最大Q值
action_continuous = dis_to_con(action, env, agent.action_dim)
next_state, reward, done, is_end, _ = env.step([action_continuous])
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'dones':b_d
}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
return return_list, max_q_value_list
if __name__ == '__main__':
#接下来设置相应的超参数,并实现将倒立摆环境中的连续动作转化为离散动作的函数
lr = 1e-2
num_episodes = 200
hidden_dim = 128
gamma = 0.98
epsilon = 0.01
target_update = 50
buffer_size = 5000
minimal_size = 1000
batch_size = 64
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
env_name = 'Pendulum-v1'
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = 11 #将连续动作分成11个离散动作
#接下来我们首先训练DQN并打印出学习过程中最大Q值的情况
random.seed(0)
np.random.seed(0)
#env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon, target_update, device)
return_list, max_q_value_list = train_DQN(agent, env, num_episodes, replay_buffer, minimal_size, batch_size)
episodes_list = list(range(len(return_list)))
mv_return = rl_utils.moving_average(return_list, 5)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
frames_list = list(range(len(max_q_value_list)))
plt.plot(frames_list, max_q_value_list)
plt.axhline(0, c='orange', ls='--')
plt.axhline(10, c='red', ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('DQN on {}'.format(env_name))
plt.show()
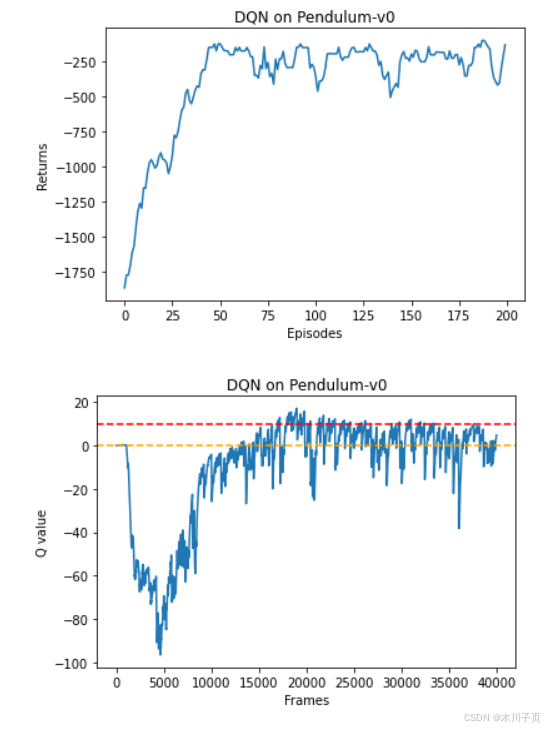
根据代码运行结果我们可以发现,DQN 算法在倒立摆环境中能取得不错的回报,最后的期望回报在-200 左右,但是不少Q值超过了 0,有一些还超过了 10,该现象便是 DQN 算法中的值过高估计。我们现在来看一下 Double DQN 是否能对此问题进行改善。
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device, 'DoubleDQN')
return_list, max_q_value_list = train_DQN(agent, env, num_episodes,
replay_buffer, minimal_size,
batch_size)
episodes_list = list(range(len(return_list)))
mv_return = rl_utils.moving_average(return_list, 5)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Double DQN on {}'.format(env_name))
plt.show()
frames_list = list(range(len(max_q_value_list)))
plt.plot(frames_list, max_q_value_list)
plt.axhline(0, c='orange', ls='--')
plt.axhline(10, c='red', ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('Double DQN on {}'.format(env_name))
plt.show()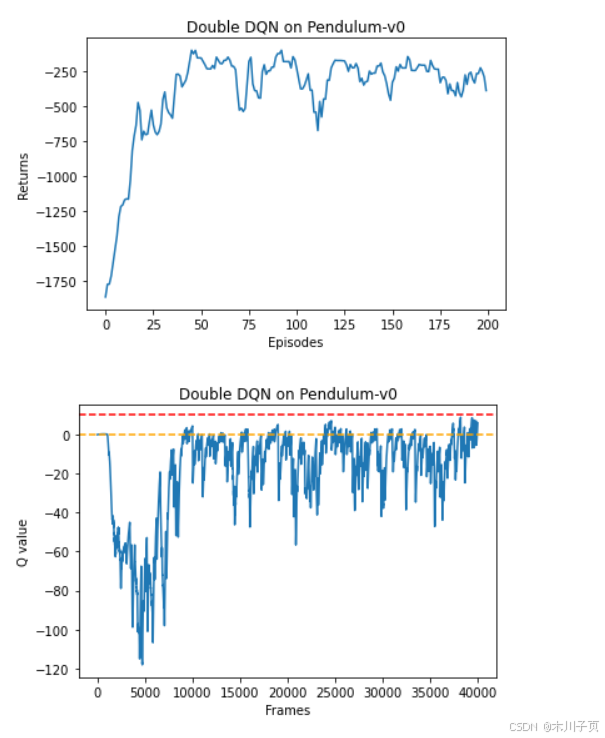
我们可以发现,与普通的 DQN 相比,Double DQN 比较少出现Q值大于 0 的情况,说明Q值过高估计的问题得到了很大缓解。