主干网络论文阅读(按论文时间顺序):
论文阅读 LeNET CONVOLUTIONAL NEURAL NETWORKS FOR ISOLATED CHARACTER RECOGNITION-CSDN博客
论文阅读 AlexNet ImageNet Classification with Deep ConvolutionalNeural Networks-CSDN博客
论文阅读 VGGNet VERY DEEP CONVOLUTIONALNETWORKSFORLARGE-SCALEIMAGERECOGNITION-CSDN博客
论文阅读 GoogleNet(Inception) Going deeper with convolutions-CSDN博客
论文阅读 ResNet Deep Residual Learning for Image Recognition-CSDN博客
论文阅读 ResNext Aggregated Residual Transformations for Deep Neural Networks-CSDN博客
Googlenet(inception)+resnet
论文在网络的深度宽度之外,又提出了一个新的维度:基数(cardinality、C)。增加基数也可以提高分类精度。增加容量时,增加基数比深入或更广泛更有效。
Vgg和resnet说明了构建非常深的网络的简单而有效的策略:堆叠相同形状的构建块,这个简单的规则减少了对超参数的自由选择
Inception模型:过滤器的数量和大小是为每个单独的转换量身定制的,并且模块是逐步定制的。尽管这些组件的精心组合产生了出色的神经网络配方,但设计太复杂
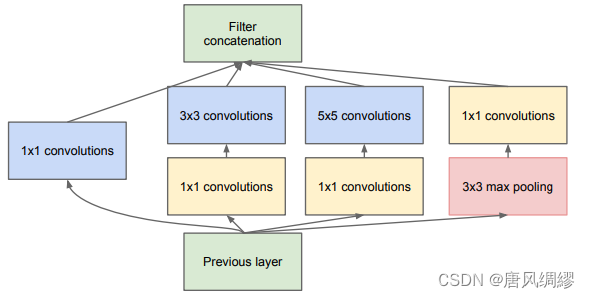
Resnext不需要人工设计复杂的Inception结构细节
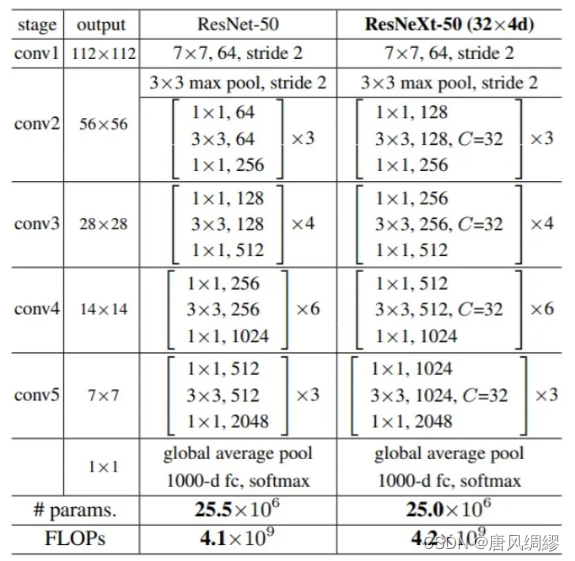
左:resnet 右:resnext(C=32)
原始的ResNet-50具有256·64 + 3·3·64·64 + 64·256≈70k参数;Resnext-50有:C·(256·d + 3·3·d·d + d + d·256)参数。当C = 32和d = 4时,等式(4)≈70k。(虽然后者上下两个1*1的卷积层参数多于前者,但3*3的卷积层参数少)


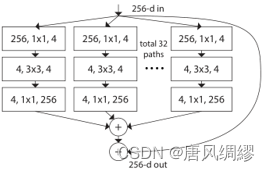
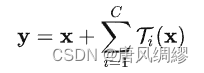
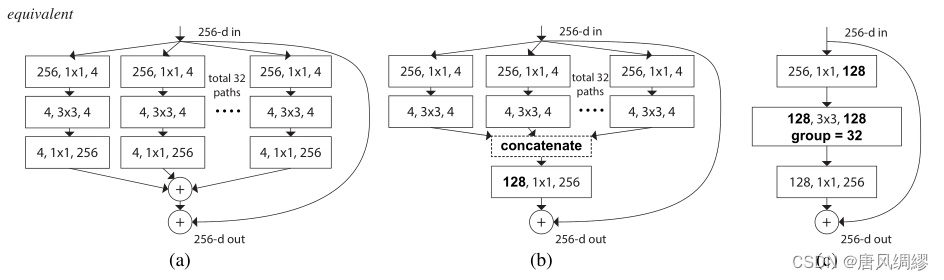
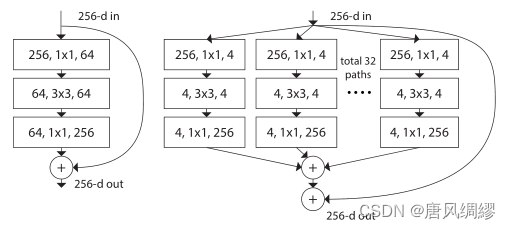
a等效于b,看起来像Inception+ResNet。(concatenate是Inception里面的内容,可以理解为把特征图摞起来)但不同的是,我们在多个路径之间共享相同的拓扑结构。我们的模块需要最少的额外工作来设计每个路径。
这种结构用分组卷积的表示法变得更加简洁---图c。分组卷积层执行32组卷积,其输入和输出通道为4维。分组的卷积层将它们连接起来作为该层的输出。图c与原始resnet相似但图c是一个较宽但连接稀疏的模块。
结论:
Resnext结合了Googlenet和resnet。采用了Inception模块,但设计复杂度低于Inception;相比resnet,ResNeXt 在不明显增加参数的情况下提升了准确率。
作者提出了split-transform-merge 模式---一个很通用的抽象程度很高的标准范式:
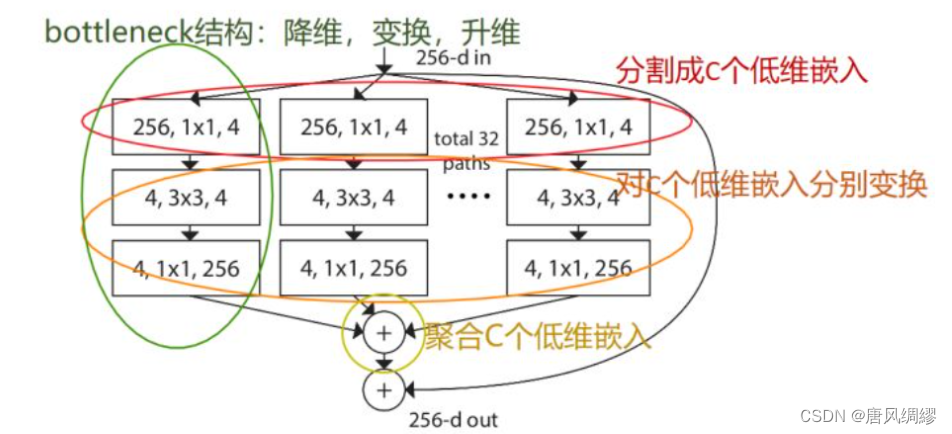
作者直接废除了Inception的囊括不同感受野的特性仿佛不是很合理,在更多的环境中我们发现Inception V4的效果是优于ResNeXt的(但ResNeXt速度肯定更快)