对比学习论文阅读:
对比学习论文阅读 simCLR A Simple Framework for Contrastive Learning of Visual Representations-CSDN博客
对比学习论文阅读 MOCO Momentum Contrast for Unsupervised Visual Representation Learning-CSDN博客
对比学习论文阅读 BYOL Bootstrap Y our Own LatentA New Approach to Self-Supervised Learning-CSDN博客
对比学习论文阅读 SimSiam Exploring Simple Siamese Representation Learning-CSDN博客
无监督视觉表征学习的动量对比
无监督学习在NLP应用广泛,但在CV领域一般。原因可能是二者的信息类型不同,nlp的信息是浓缩的语义信息,而cv的信息是高维连续的。
以往的对比学习方法也都可以看作一个字典查询任务,但以往方法无法同时兼顾大字典和一致性两方面。
动量的含义:这里的m是超参数, Yt是这一时刻你想要改变的输出,Y{t-1}为上一时刻的输出,Xt是当前时刻的输入,实质就是不想当前时刻的输出完全依赖于当前时刻的输入,也希望继承之前的输出的信息。
对比学习字典需满足的两个特性:1、字典要尽可能大2、在训练的时候要保证字典的一致性。 MOCO的解决方式:
1. 字典要尽可能大->用队列存储字典
2. 字典特征一致性->动量编码器
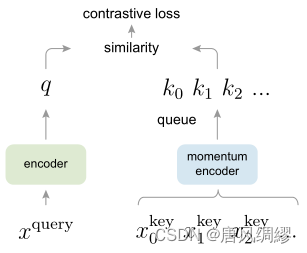
通过列表存储key值(其中正样本为k0),字典应尽可能大,以往方法若希望字典中有n个值,就需要内存中同时有n张图像,对内存占用太大。 moco提出队列存储图像,每次提取minibatch张图像特征,新的batch进入队列时,旧的batch出列。以此满足字典要尽可能大的要求。 同时,队列每次出列的特征也都是队列中使用最老编码器的特征(因为每次出入列,编码器都迭代一次),与队列中其他特征的一致性也最差,进一步维持了字典特征一致性。
每个batch都会更新编码器,为满足字典特征一致性,采用特征编码器:首先设置左边的编码器设置为 ,则右边的编码器为
,这样右边的动量编码器更新会很慢,从而保证右边每批次用的编码器相似,保持
的一致性,文章使用m=0.999。
损失函数:
只有一个key是跟query配对的即互为正样本对,我们称之为key positive(k+/k0), 可以理解为一个图片通过两种变化得到两个图片其中一个作为基准图片,另一个作为正样本对。我们的对比学习的目标函数需要满足以下两个要求:
1: 当query q和唯一的哪个正样本相似的时候, 损失函数的值应该比较低
2: 当query q和其他所有的key不相似的时候,损失函数的值也应该较低
于是提出InfoNCE: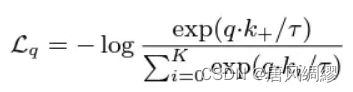
中括号里面是softmax函数。把one-hot向量当作ground-truth,加上前面的-log,就是交叉熵损失函数。这里的K表示数据集的类别数,在一个任务上是固定的数字。对比学习中理论上是可以使用cross entropy来当作目标函数的,但是在很多代理任务的具体实现上是行不通的,比如使用个体判别代理任务,类别数k就变成了字典中的样本数,是一个很大的数字,softmax在有巨量类别时,是工作不了的,同时exp指数操作在向量维度是几百万时,计算复杂度会很高,耗费时间。
于是有了NCEloss,NCE的思路就是把这么多类别问题简化成一个二分类问题,数据类别data sample和噪声类别 noise sample,然后每次拿数据样本和噪声样本做对比。
但如果字典的大小是整个数据集,计算复杂度还是没有降下来,为了解决这个问题,思路就是从整个数据集中选一些负样本进行loss计算,来估计整个数据集上的loss。负样本如果选少了,近似的结果偏差就大了,所以字典的大小也就成了影响模型性能的一个因素,即字典越大,提供更好的近似,模型效果会越好,这也是moco强调字典要足够大的原因之一。总结就是NCE把一个超级多分类问题转成一个二分类问题,使softmax操作能够继续进行。
InfoNCE是对NCE的一个简单变体,思路是,如果只看作二分类问题,只有数据样本和噪声样本,对模型学习不是那么友好,因为噪声样本很可能不是一个类,所以把噪声样本看作多个类别会比较合理,最终NCE就变成了InfoNCE。
infoNCE和交叉熵损失很像,代码中也是调用交叉熵损失来构建infoNCE的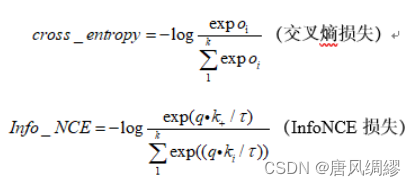
q*k称为一个logit;τ称为温度差参数用来控制分布的形状;K是负样本数量;k0是正样本。
流程:
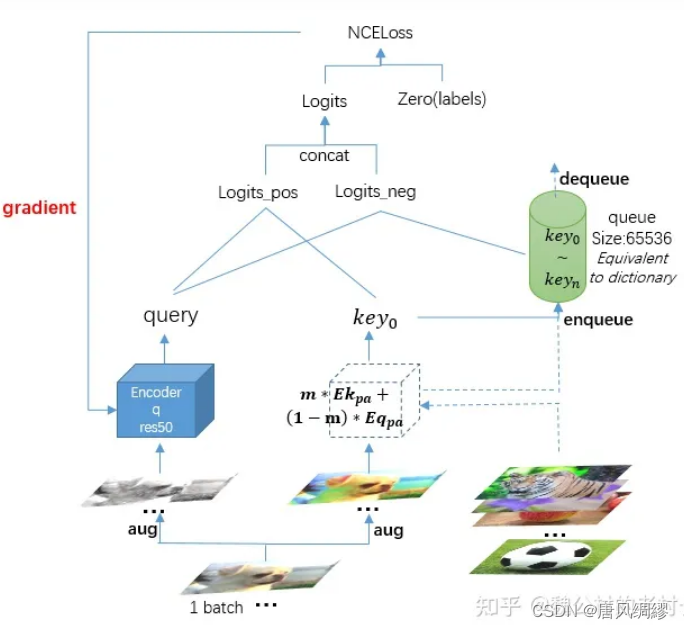
伪代码:

我们先拿第一个batch(N个样本)的图像队列,分别做两次不同的数据增强,扔给经初始化的编码器q和编码器k(一开始的encoder k由encoder q复制而来),得到各自特征query(N*128)和key0(N*128),计算logits_pos,此时的队列是空的,所以总的logits就只有logits_pos,最后计算NCEloss,更新encoder q的参数,encoder k的参数等于当前encoder k和encoder q的加权移动平均(Enk’=m*Enk+(1-m)*Enq),这里的动量m设置为很大的一个数0.999,这就导致了编码器k的更新更多的都是依赖于上一时刻k的参数,而由于1-m是趋于0的一个数,所以对编码器q的依赖是相当少的,两者相加,最后缓慢地更新编码器k的参数,这样就巧妙地保证了字典里key的一致性。最后将key0入队列,第一次迭代就完成了。
第二次迭代与第一次相同,唯一不同的是,此时队列里已经有了key0,就可以计算logits_neg,总的logits(NX(1+K))就是将logits_neg和logits_pos拼接,接着计算loss,更新编码器q的参数,直到所有的负样本特征输出完全入队列,这里的队列大小为65536,因为batchsize设置为256,所以要迭代65536/256=256次才能将队列占满。
在第257次迭代,key0就被dequeue。
通过使用队列这种数据结构,巧妙地解除了端对端训练方式里batchsize受限于显存的问题,256的batchsize是我们大多数显卡可以支持的;通过动量这个参数来缓慢地加权移动更新编码器k的参数,又解决了字典里key特征不一致的问题。
该文章通过linear classification protocol的方式进行了很多下游任务。 训练一个下游任务模型时,发现最优学习率30,比较怪异,可见有监督学习和无监督学习学到的特征是有很大差异的
另外,训练MOCO的数据集从1M提升到1B,准确率提升并不大,作者认为可能是因为没有充分利用数据。
在大部分视觉任务上,比imagenet有监督训练的模型要好,但是在实例分割,语义分割上效果不好,可能是对比学习对这些像素级别的任务不适合。
Moco V2
重写了损失函数: 把分母正负样本分开,形式变了内容不变
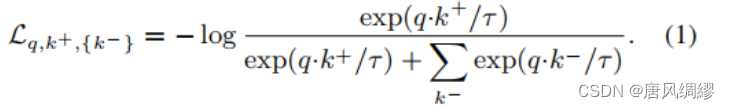
借鉴simCLR添加了MLP预测头和更多的数据增强
MLP预测头:
MoCo V1 的 Encoder 简单使用了 ResNet50,然后输出通过 L2-norm 处理得到最后的输出。在 MoCo V2 中把 ResNet 中输出与1000分类相关的FC层换成了两层的 FC + Relu,隐藏层为2048维。
将对比学习视作字典查询任务:
端到端的方法 如simCLR
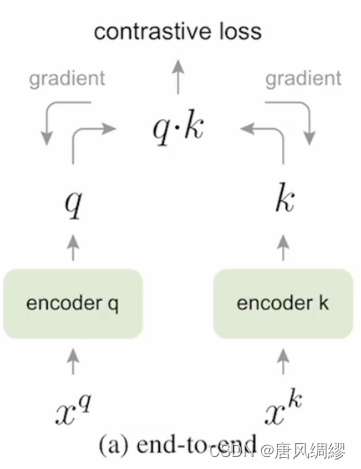
batch大小{xk}=队列大小{k},两个编码器都可以通过梯度回传的方法更新参数,因此特征一致性可以保障,但字典大小受限制(batch太大硬件受不了)
memory bank方法:
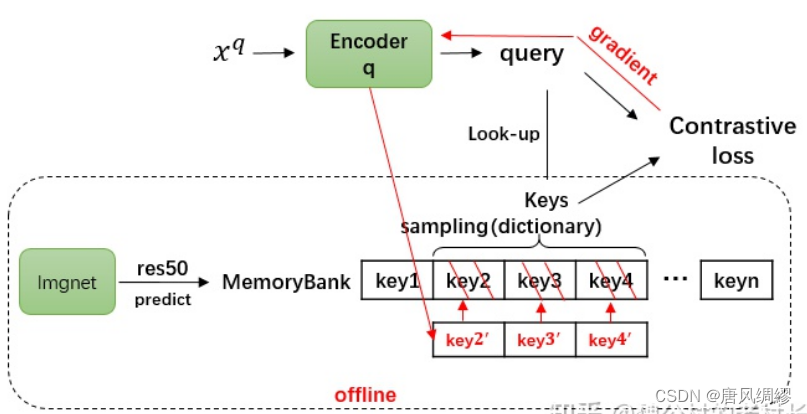
先将图像提取特征(128维),特征放进memory bank,memory bank里面随机抽样(为啥要随机抽样),计算损失,编码器q梯度回传。
当第一次更新完编码器q的参数后,会根据当前参数重新前向运算,新的特征值会将先前字典里的keys覆盖(编码器q怎么计算出新的k值?),当训练完成一个epoch后,整个memorybank才会完成一次特征更新,而以前得到的keys和后面更新的keys早已经不是由同一套编码器参数计算得来的了,这就导致字典里特征不具备一致性。
moco方法:
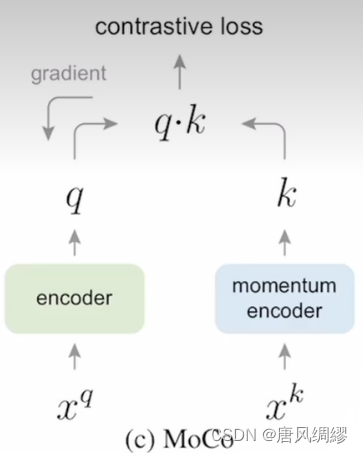
效果:
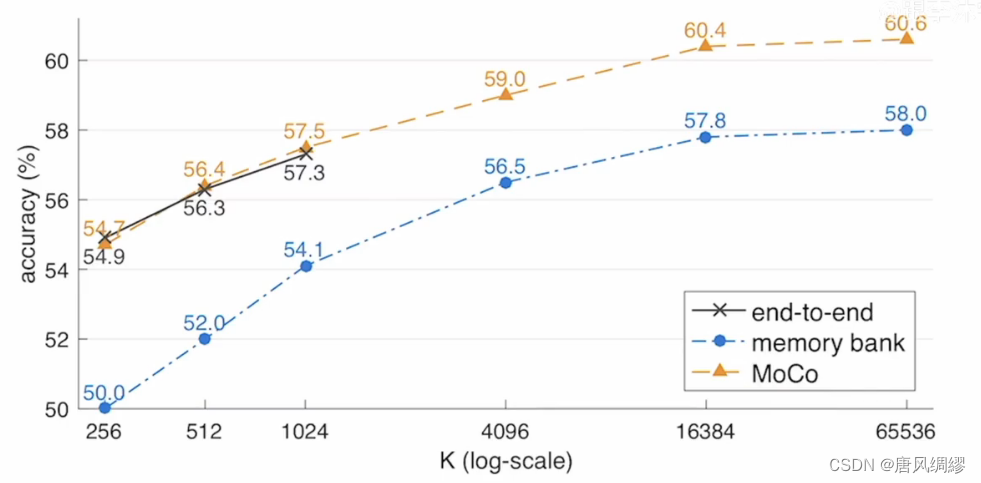
端到端对数据量有限制;memory bank因为特征不一致导致准确率低
线性分类协议:
linear classification protocol,即将训练的特征提取网络权值(主干网络backbone)冻住,只把它当作一个特征提取器。然后训练一个全连接层充当分类头