一、研究意义
随着人们生活水平的不断提高,经济的快速增长,人工智能技术的突飞猛进,人们对特定领域的关注越来越多样化。自然语言处理是近年来发展迅速的一门语言学、数学和计算机科学交叉的学科,主要研究如何让计算机准确处理、理解人类的语言文本。作为一种高效的文本信息处理方式,自然语言处理技术在桌游文本信息处理领域应用前景广阔。狼人杀是近些年来在年轻人中逐渐兴起的一种桌游,其独特的玩法和社交性使其蓬勃发展并在如今的桌游市场占据了可观的市场。狼人杀游戏中的语法、词汇相对于通常的对话而言更加复杂,且有着大量的专有词汇,给自然语言处理带来了机遇和挑战。现有的自然语言处理任务大都是在现代文数据集的基础上进行的,如今狼人杀桌游领域的数据集极少,相关的研究也较少。本文在分析狼人杀文本特点的基础上,采用面向自然语言处理的感知器和隐马尔科夫模型,对狼人杀对话文本分词、词性标注等问题作了深入研究。
二、数据描述
数据获取途径:通过网络爬虫获取狼人杀领域相关的文本数据然后保存到本地txt文件中
数据内容组成:数据主要由网页爬取的狼人杀领域的专有名词的解释以及狼人杀游戏中的文字对话内容组成
数据预处理过程:首先对爬取的数据进行除噪,将数据中多余的空格和换行删除;然后对数据进行分词与词性标注处理;接下来用[]将自己定义的领域名词合并,[]后用/标注自己定义的词性。最后处理完成的数据格式:单词与词性之间使用“/”分割,如华尔街/nsf,且任何单词都必须有词性,包括标点等;单词与单词之间使用空格分割,如美国/nsf 华尔街/nsf 股市/n;用[]将多个单词合并为一个复合词,如[纽约/nsf 时报/n]/nz,复合词也必须遵守1和2两点规范。
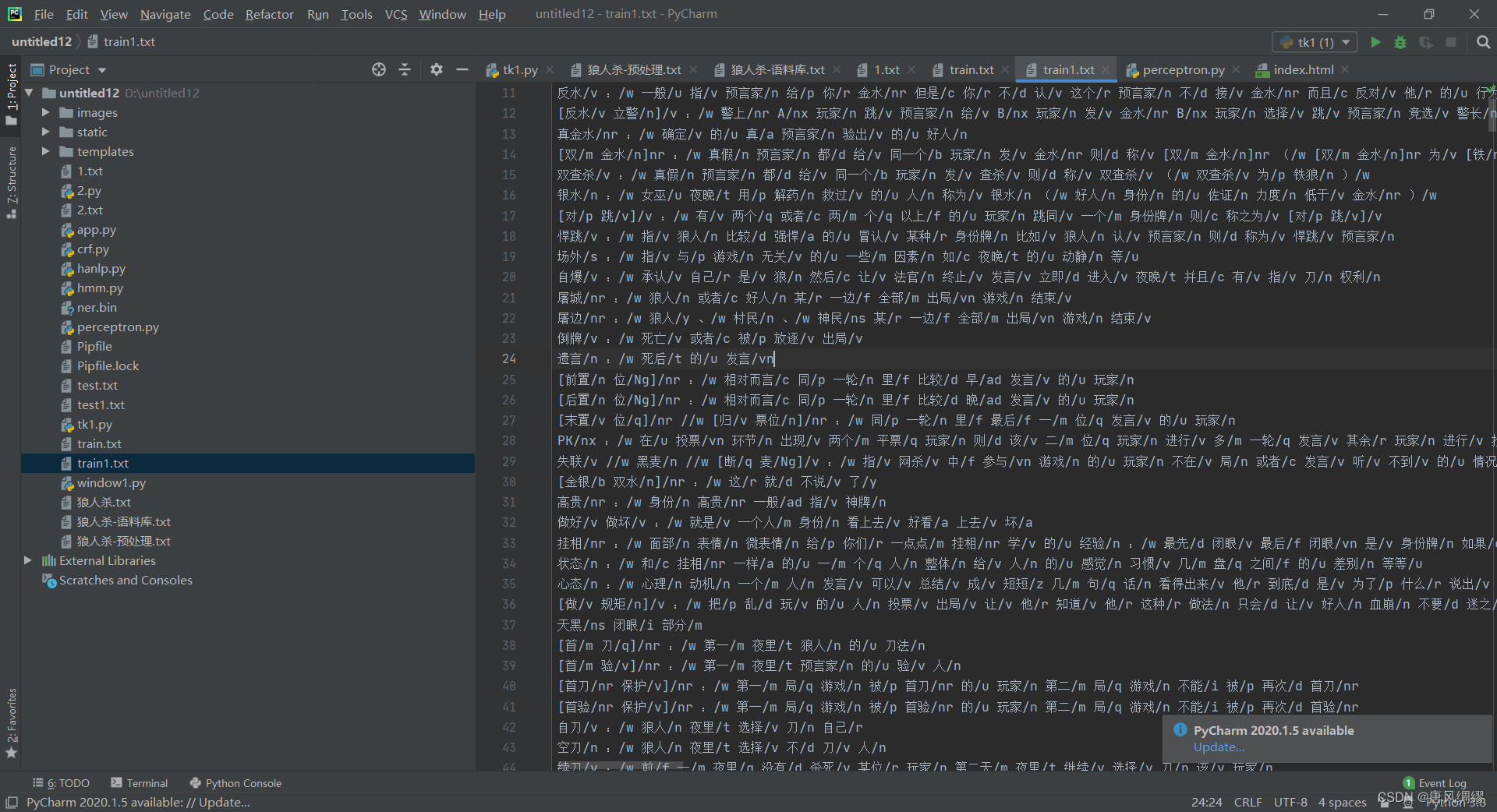
最后经过预处理完成后的训练数据如下图所示:
三、模型描述
我们使用了隐马尔科夫模型、感知机和条件随机场模型进行了我们的模型训练并且分别使用三种模型训练的模型进行我们的数据测试,最后我们应用感知机模型在我们的领域词性标注的系统框架中。下面介绍一下我们的算法原理。
隐马尔科夫模型:
描述两个时序序列联合分布p(x,y) 的概率模型。x
序列外界可见,称为观测序列(显状态)。y
序列外界不可见,称为状态序列(隐状态)。
NLP中,x为单词,y为词性。
隐马尔可夫模型:它的马尔可夫假设作用于状态序列(隐状态)
假设①当前状态yt仅仅依赖于前一个状态yt-1,连续多个状态构成隐马尔可夫链yt
假设②任意时刻的观测xt只依赖于该时刻的状态yt,与其他时刻的状态或观测独立无关。
隐马尔可夫模型利用三个要素来模拟时序序列的发生过程:
初始状态概率向量;状态转移概率矩阵;发射概率矩阵(亦称观测概率矩阵)
隐马尔可夫模型的三个基本用法:
样本生成:给定模型λ=(π,A,B) ,生成满足模型的样本
模型训练:给定训练集,生成模型参数λ=π,A,B
序列预测:已知模型λ=π,A,B 和观测序列x,求最大概率y
其他实际问题:
字符映射:字符作为观测变量,必须是整型才被隐马尔科夫模型接受。因此需要从字符串形式到整型的映射
语料转换:将语料转换为(𝒙,𝒚)二元组才能训练隐马尔可夫模型,因此需要将一个句子转换为二元组
感知机分类:
1.读入训练样本(x(i),y(i)) ,执行预测y=sign(w⋅x(i))

2.如果y≠y(i) ,则更新参数w←w+y(i)x(i)
如果数据本身线性不可分,感知机算法是不会收敛的,每次迭代参数会剧烈震荡,解决方案有:
1将样本映射到更高维空间,使其线性可分
2切换其他训练算法,比如支持向量机等
3使用投票感知机与平均感知机
(1)投票感知机:储存多个模型,预测时每个模型都给出各自的结果,加权取平均:准确率(权重)*模型结果
(2)平均感知机是取多个模型的权重的平均,不需要保存多个模型,只需要保留平均后的模型
条件随机场:
概率图模型:用来表示与推断多维随机变量联合分布𝑝(𝒙,𝒚)的强大框架
利用节点𝑉表示随机变量,边𝐸连接有关联的随机变量
可以将图可以分解为子图,分布、简化分析
有向概率图:可以表示事件因果
某一节点发生概率为其所有前驱节点概率之积: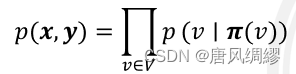
表示节点v
的所有前驱节点)
无向概率图:不在意因果关系,仅在意是否有关
最大团:满足所有节点相互连接的最大子图,图中最大团是全部的三个节点
无向图模型定义了一些虚拟的因子节点,使最大团变小。
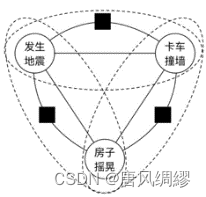
无向图模型将多维随机变量的联合分布分解为一系列最大团中的因子之积
条件随机场是用来标注和划分序列结构数据的概率化结构模型(图模型)。结合了最大熵模型和隐马尔可夫模型的特点,是一种无向图模型。
用于序列标注时,条件随机场特例化为线性链条件随机场
条件随机场的特征函数
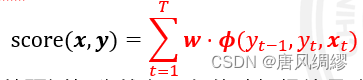
结构化感知机与条件随机场的异同
相同点:特征函数、权重向量、打分函数、预算算法都相同,都属于结构化学习。
差异:最大的不同点在于训练算法,也是两者准确率差异的唯一原因。感知机算法属于在线学习,每次参数更新只使用一个训川练实例,并没有考虑整个数据集:条件随机场的每次的参数更新是考虑全局的:感知机奖励正确答案对应的特征函数,但仅仅惩罚错的厉害的那一个特征函数:条件随机场不但奖励正确答案对应的特征函数,还同时惩罚所有的答案。
四、算法实现
HMM算法:

def estimate_transition_and_initial_probs(self, train_dict):
"""
(tag的)转移概率矩阵A 和初始pi的参数估计(bigram)二元模型
estimate p(Y_t+1 | Y_t)
:param train_dict:
:return:
"""
print("(tag的)转移概率矩阵A 和初始pi的参数估计(bigram)二元模型...")
for dict in tqdm(train_dict):
# 遍历每一条训练数据
for i, tag in enumerate(dict["label"][:-1]):
if i == 0:
# 统计每条数据的起始标签 看看数据集中7种标签作为起始的各有多少个
self.pi[self.tag2idx[tag]] += 1
# print(self.pi)
# 取当前跟下个tag的index
curr_tag = self.tag2idx[tag]
next_tag = self.tag2idx[dict["label"][i + 1]]
self.transition[curr_tag, next_tag] += 1
# 遍历完所有训练数据后计算分子/分母
self.transition[self.transition == 0] = self.epsilon # 分子
self.transition /= np.sum(self.transition, axis=1, keepdims=True) # 分子/分母 (行里每个元素/按行求和)
self.pi[self.pi == 0] = self.epsilon
self.pi /= np.sum(self.pi)
print('ok')
def estimate_emission_probs(self, train_dict):
"""
发射概率矩阵(tag->vocab)参数估计
:param train_dict:
:return:
"""
print("发射概率矩阵(tag->vocab)参数估计...")
for dict in tqdm(train_dict):
# 遍历每一条训练数据
for char, tag in zip(dict["text"], dict["label"]):
# print(char, tag)
# print(self.char2idx[char])
# print(self.tag2idx[tag])
self.emission[self.tag2idx[tag], self.char2idx[char]] += 1
# 遍历完所有训练数据后计算分子/分母
self.emission[self.emission == 0] = self.epsilon # 分子
self.emission /= np.sum(self.emission, axis=1, keepdims=True) # 分子/分母 (行里每个元素/按行求和)
print('ok')
def viterbi_decode(self, text):
"""
传入text文本 使用维特比算法输出最有可能的隐状态路径
:param text: str
:return:
"""
# 按字切分的序列长度
seq_len = len(text)
# 初始化T1和T2表格
T1_table = np.zeros([seq_len, self.tag_size]) # 保存tag1转移到tag2转移概率
T2_table = np.zeros([seq_len, self.tag_size]) # 保存这个位置是从哪个tag转移过来的
# 求第1时刻的发射概率
start_p_Obs_State = self.get_p_Obs_State(text[0]) # 计算P(Obs_vocab|State_tag)
# 计算第一步初始概率, 填入表中
T1_table[0, :] = self.pi + start_p_Obs_State
T2_table[0, :] = np.nan
for i in range(1, seq_len):
# 维特比算法在每一时刻计算落到每一个隐状态的最大概率和路径
# 并把他们暂存起来
# 这里用到了矩阵化计算方法, 详见视频教程
p_Obs_State = self.get_p_Obs_State(text[i])
p_Obs_State = np.expand_dims(p_Obs_State, axis=0)
prev_score = np.expand_dims(T1_table[i - 1, :], axis=-1)
# 广播算法, 发射概率和转移概率广播 + 转移概率
curr_score = prev_score + self.transition + p_Obs_State
# 存入T1 T2中
T1_table[i, :] = np.max(curr_score, axis=0)
T2_table[i, :] = np.argmax(curr_score, axis=0)
# 回溯
best_tag_id = int(np.argmax(T1_table[-1, :]))
best_tags = [best_tag_id, ]
for i in range(seq_len - 1, 0, -1):
best_tag_id = int(T2_table[i, best_tag_id])
best_tags.append(best_tag_id)
return list(reversed(best_tags))
感知机:

def ganzhiqi(x):
# 加上偏置值 b
y = np.dot(w, x) + b
if y > 0:
return 1
else:
return -1
# 绘制当前数据集和当前的直线
def paint():
plt.scatter(X1[Y],X2[Y],c='r')
plt.scatter(X1[Y_0],X2[Y_0],c='g')
xx = np.linspace(0,1,100)
yy = -b/w[1] - (w[0]/w[1])*xx
plt.plot(xx, yy)
plt.show()
T = 250
t = 0
k = 0
N = len(D)
while (t < T):
# 均方误差
mse = 0
for i in range(N):
xi = D[i]
yi = y[i]
# 加上真实值与预测值的平方
mse += abs(yi - np.dot(w, xi) - b) ** 2
print(i, xi, yi)
if yi * ganzhiqi(xi) < 0:
w = w + yi * xi
# 修改偏置值 b
b = b + yi
k = k + 1
print('更新:', k, w, b)
t = t + 1
# 绘制数据集和当前的直线
paint()
# 打印当前的均方误差
print("均方误差:", mse / N)
条件随机场:
def process_big_seq(self, words): # 数据序列发生器
pro_words = []
index = 0
temp = ''
while True:
word = words[index] if index < len(words) else ''
if '[' in word:
temp += re.sub(pattern='/[a-zA-Z]*', repl='', string=word.replace('[', ''))
elif ']' in word:
w = word.split(']')
temp += re.sub(pattern='/[a-zA-Z]*', repl='', string=w[0])
pro_words.append(temp + '/' + w[1])
temp = ''
elif temp:
temp += re.sub(pattern='/[a-zA-Z]*', repl='', string=word)
elif word:
pro_words.append(word)
else:
break
index += 1
return pro_words
def initialize(self): # 初始化
pro_corpus = self.read_corpus("./data/pro_corpus.txt")
corpus_list = [line.strip().split(' ') for line in pro_corpus if line.strip()]
del pro_corpus
self.init_sequence(corpus_list)
def init_sequence(self, corpus_list): # 字序列、词性序列、标记序列的初始化
words_seq = [[word.split('/')[0] for word in words] for words in corpus_list]
pos_seq = [[word.split('/')[1] for word in words] for words in corpus_list]
tag_seq = [[self.pos_2_tag(p) for p in pos] for pos in pos_seq]
self.pos_seq = [[[pos_seq[index][i] for _ in range(len(words_seq[index][i]))]
for i in range(len(pos_seq[index]))] for index in range(len(pos_seq))]
self.tag_seq = [[[self.perform_tag(tag_seq[index][i], w) for w in range(len(words_seq[index][i]))]
for i in range(len(tag_seq[index]))] for index in range(len(tag_seq))]
self.pos_seq = [['un'] + [self.perform_pos(p) for pos in pos_seq for p in pos] + ['un'] for pos_seq in
self.pos_seq]
self.tag_seq = [[t for tag in tag_seq for t in tag] for tag_seq in self.tag_seq]
self.word_seq = [['<BOS>'] + [w for word in word_seq for w in word] + ['<EOS>'] for word_seq in words_seq]
print("-> 完成字序列、词性序列、标记序列的初始化")
def feature_extractor(self, word_grams): # 特征提取器
features, features_list = [], []
for index in range(len(word_grams)):
for i in range(len(word_grams[index])): # 一个字一个字得进行分析
word_gram = word_grams[index][i]
feature = {
"w-1": word_gram[0],
"w": word_gram[1],
"w+1": word_gram[2],
"w-1:w": word_gram[0] + word_gram[1],
"w:w+1": word_gram[1] + word_gram[2],
"bias": 1.0
}
features.append(feature)
features_list.append(features)
features = []
return features_list
五、运行结果及分析
| 图一:感知机预测结果 图二:tkinter界面及文本预测 图三:自定义单词及词性 图四:自定义单词输出结果 图五:flask框架 |

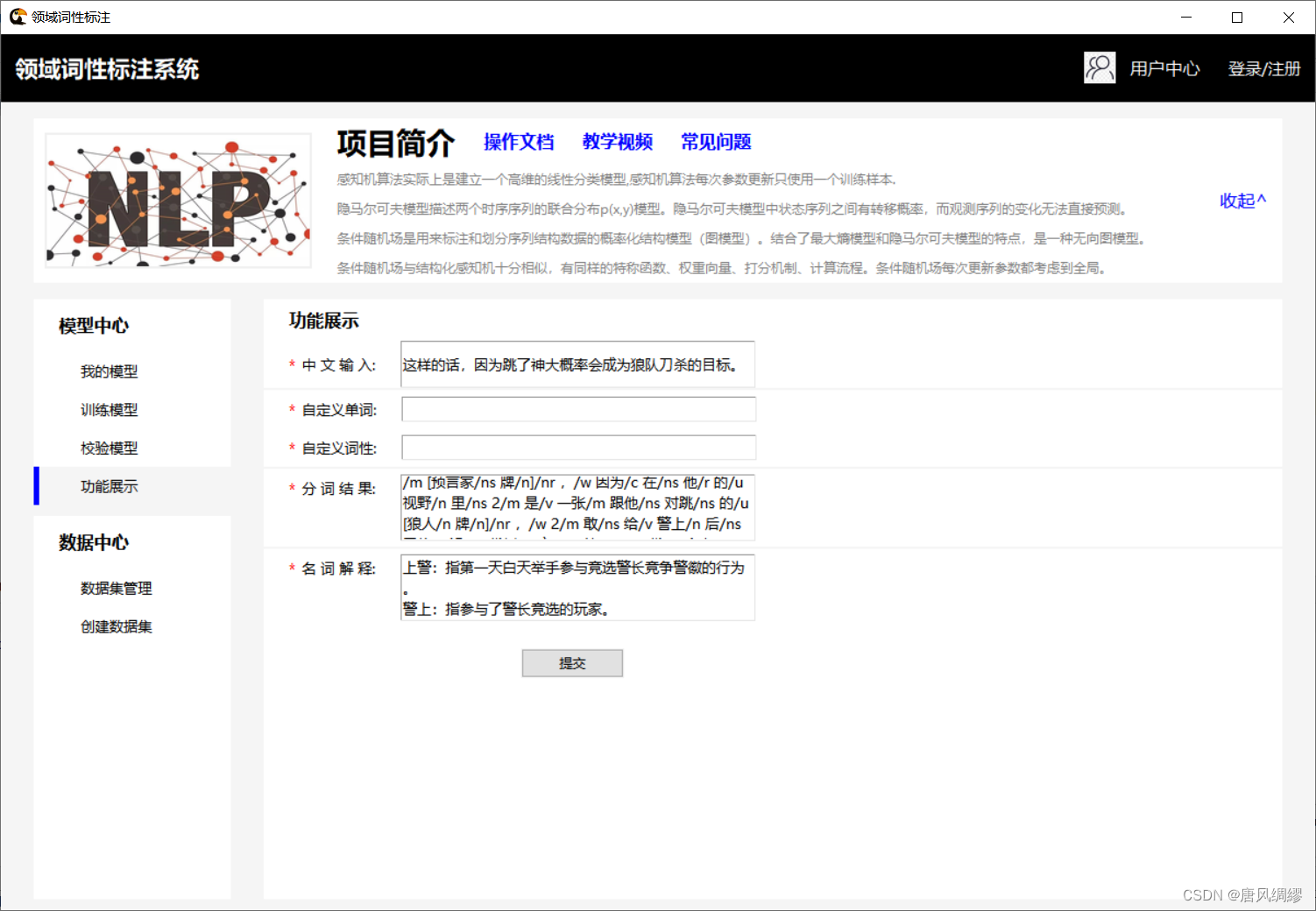
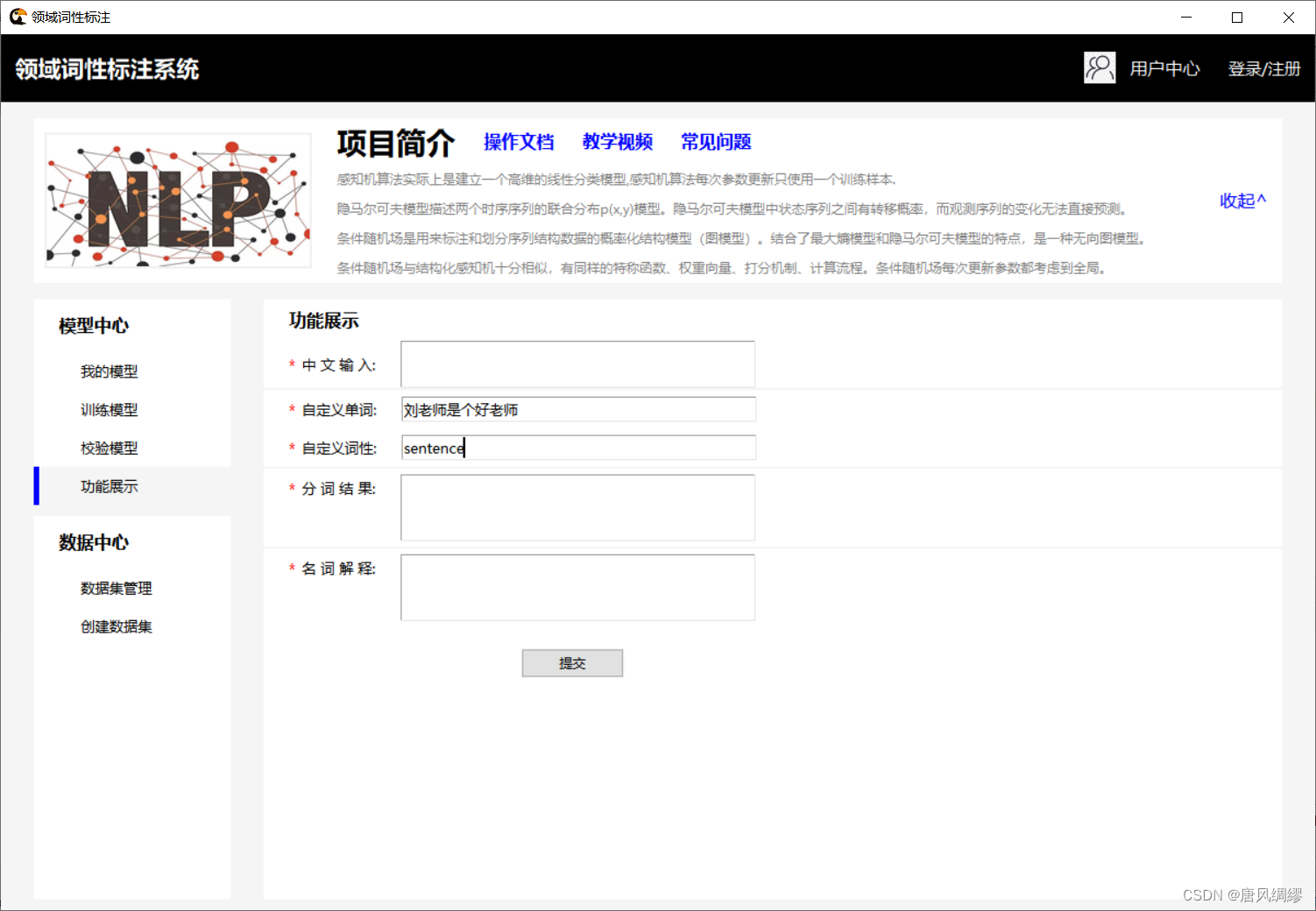
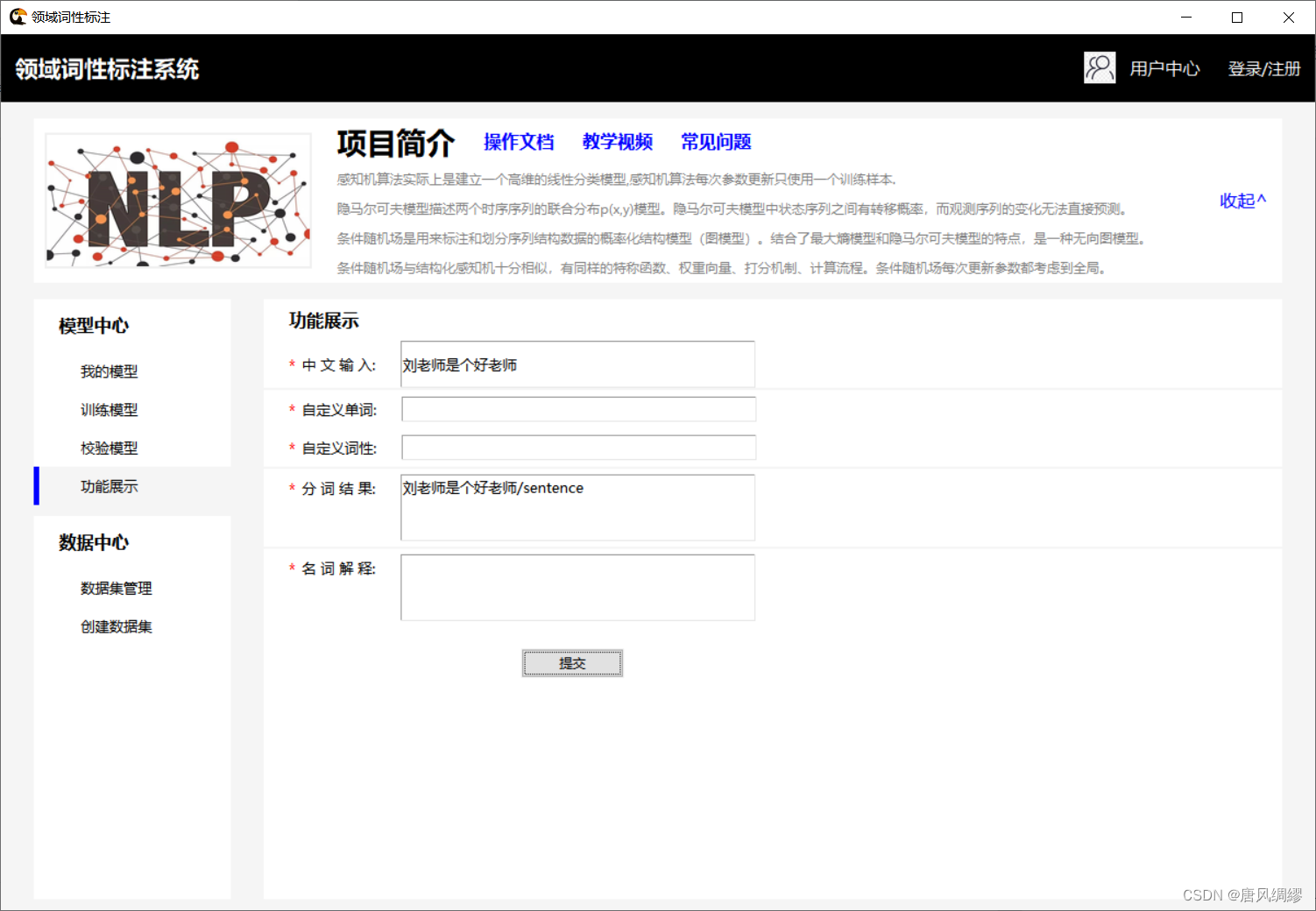

六、总结
感知机算法属于机器学习中相对容易的算法,原理简单而且模型准确率高。其流程为:在训练集上运行多个迭代,每次读入一个样本,执行预测,将预测结果与正确答案进行对比,计算误差,根据误差更新模型参数,再次进行训练,直到误差最小为止。
该领域在网络上没有已经标注好的数据集,所以我们在网上爬取了大量真实的狼人杀游戏对话内容,然后通过人民日报语料库训练的模型对文本进行粗略的分词,然后手动修改错误。然而在程序设计过程中,出现了预测准确率一直为零的情况,之后检查发现是因为在标注数据集时词性标注不规范导致验证时无法匹配。之后通过规范词性标注解决该问题。
课程收获:通过该课程的学习,了解了自然语言处理的各种方向和技术以及一些当今较为火热的应用。并且对hanlp的使用有了一定的经验。为之后进一步的应用自然语言处理技术提供了基础。