萌新:使用xpath和正则表达式解析网页内容
代码如下:
import sqlite3
import re
import requests
from lxml import html
findlink = re.compile(r'<a href="(.*?)"') # 创建正则表达式对象,表示规则(字符串的模式)
findname = re.compile(r'<a href=".*?">(.*?)</a>')
findname2 = re.compile(r'<td style="outline: 0px !important;">(.*?)</td>')
findname3 = re.compile(
r'<td style="outline: 0px !important;"><p style="line-height: 1.8; outline: 0px !important;">(.*?)</p></td>')
findname4 = re.compile(
r'<td style="outline: 0px !important;"><p style="line-height: 1.8; outline: 0px !important;"><a href=".*?">(.*?)</a>.*?</p></td>')
findaddres = re.compile(r'<td style="outline: 0px !important;">(.*?)</td>')
findadress1 = re.compile(r'<td style="outline: 0px !important;"><a href=".*?">(.*?)</a></td>')
'''
通过findall找到所有table里面的tr
然后对tr里面的内容进行解析,如果没有链接,则data添加信息为空,有链接调用函数来解析链接网页
再向数据库传输解析内容
'''
def main():
basicurl = "http://www.qianmu.org/ranking/1528.htm"
datalist = getData(basicurl)
for data in datalist:
print(data)
saveDatadb(datalist,"university.db")
# 得到一个指定的网页内容
def askURL(url):
et = html.etree
respon = requests.get("http://www.qianmu.org/ranking/1528.htm")
selector = et.HTML(respon.text)
return selector
# 爬取主网页,将网页的tr提取出来进行分析
def getData(basicurl):
datalist = []
selector = askURL(basicurl)
# 找出每个tr,对每个tr解析
trs = selector.xpath('//div[@class="rankItem"]//tr[position()>1]')
# names = selector.xpath('//div[@class="rankItem"]//tr[position()>1]/td/a/text() | //div[@class="rankItem"]//tr['
# 'position()>1]/td[2]/text()')
# links = selector.xpath('//div[@class="rankItem"]//tr[position()>1]/td/a/@href')
# 获得了每一个tr内容
for tr in trs:
data = []
tr = html.tostring(tr, encoding='utf-8').decode('utf-8')
name = re.findall(findname, tr)
name1 = re.findall(findname2, tr)
if len(name) == 0:
name = name1[1]
else:
name = name[0]
data.append(name)
# 获取英文名字
if len(re.findall(findname4, tr)) > 1 or len(re.findall(findname4, tr)) == 1:
english = ''.join(re.findall(findname4, tr)[0])
else:
english = re.findall(findname3, tr)[1]
data.append(english)
if len(re.findall(findadress1, tr)) > 1:
address = ''.join(re.findall(findadress1, tr)[1])
else:
address = re.findall(findaddres, tr)[3]
data.append(address)
link = re.findall(findlink, tr)
# if len(link) > 1:
# link = link[0]
# elif len(link) == 0:
# link = ' '
# else:
# link = ''.join(link)
# 开始对link进行分析
if len(link) > 1:
link = link[0]
elif len(link) == 0:
link = ' '
else:
link = ''.join(link)
data.append(link)
datalist.append(data)
return datalist
# 保存数据
def saveDatadb(datalist, dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor() # 获取游标
# print("我执行了")
for data in datalist:
for index in range(len(data)):
data[index] = '"' + str(data[index]) + '"' # '"'+data[index]+'"'
sql = '''
insert into university(
name, ename, address, link)
values (%s)''' % ",".join(data)
# print(sql)
cur.execute(sql)
conn.commit() # 提交
cur.close()
conn.close() # 关闭链接
# 创建数据库
def init_db(dbpath):
sql = '''
create table university(
id integer primary key autoincrement,
name text ,
ename text ,
address text ,
link text
);
'''
conn = sqlite3.connect(dbpath) # 建表
cursor = conn.cursor() # 游标
cursor.execute(sql) # 执行sql语句建表
conn.commit() # 提交
conn.close() # 关闭
if __name__ == "__main__": # 当程序执行时,调用函数 这样写的目的是严格控制函数执行的主流程
main()
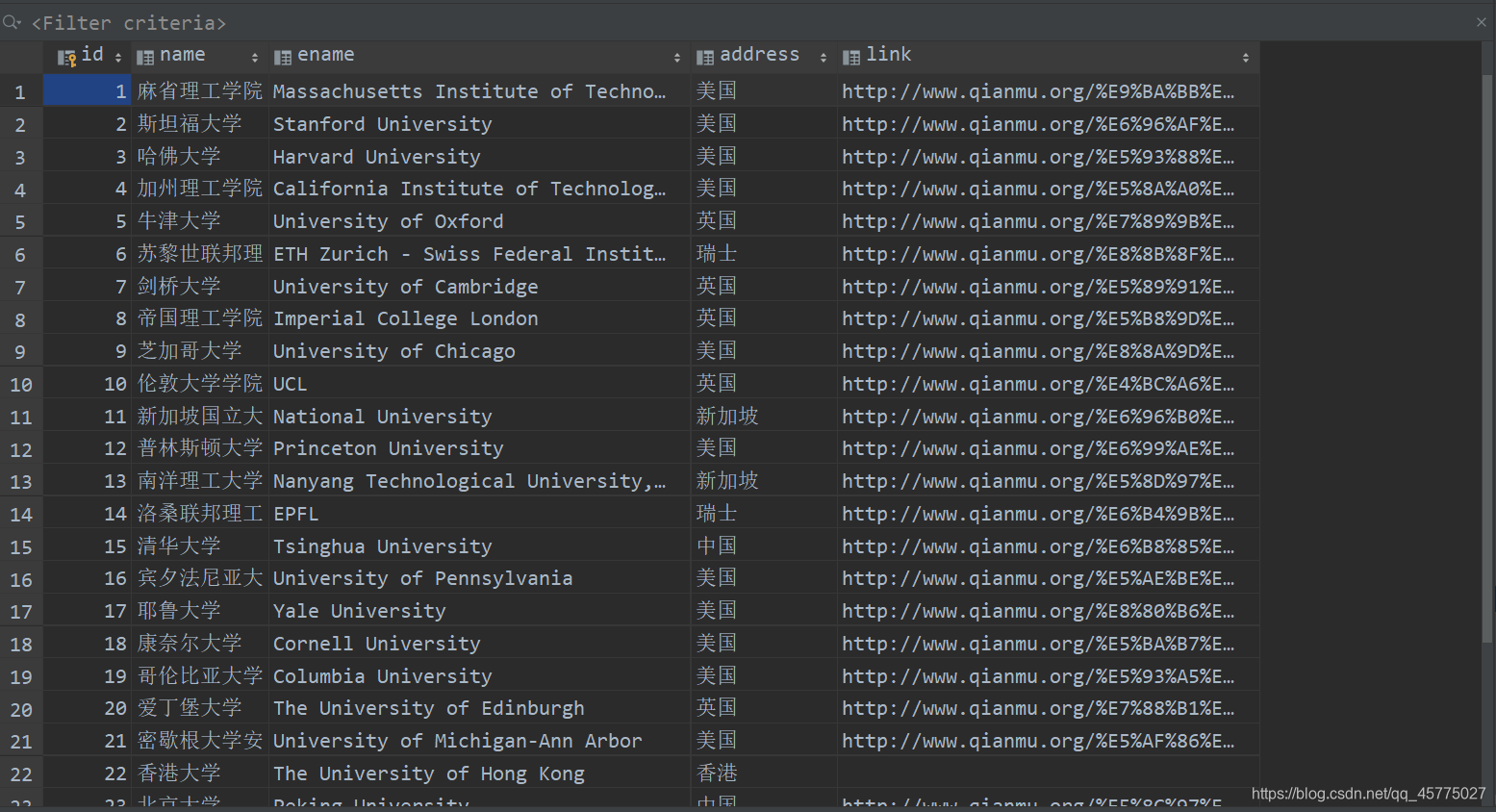
执行后保存的数据结果:
因有几个name正则表达式未处理妥当,可能会出现错误,可以自行调试,谅解,我懒。