本人以光速紧接着上篇CP 和NMF 分解后日夜兼程 完成了这篇张量分解的续集,希望大家多多点赞,这一期我们将学习举足轻重的奇异值分解的相关知识和张量的压缩与Tucker分解,难度依然不小,后期也会为大家附上代码,希望大家能潜心钻研!
Tensor decomposition
一 . 奇异值分解原理
奇异值分解是一个有着很明显的物理意义的一种方法,它可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性!
特征值分解和奇异值分解两者有着很紧密的关系,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征,但奇异值分解是特征分解在任意矩阵上的推广,我们我们还是要先来看看这个特征分解吧~~
A
v
=
λ
v
\boldsymbol{A} v=\lambda v
Av=λv
这里的
v
v
v就是矩阵
A
\boldsymbol{A}
A 的特征向量,
λ
\lambda
λ 也就是特征值了,这个求出来的特征向量相互之间也都是相互正交的,线代必备警告!
那特征值分解就是将原来的矩阵
A
\boldsymbol{A}
A 分解成如下:
A
=
Q
Σ
Q
−
1
A=Q \Sigma Q^{-1}
A=QΣQ−1
同济线代上其实是有这个知识点的,不知道大家能不能调出尘封已久的记忆,这里的
Q
Q
Q 矩阵是前面特征向量
v
v
v 组成的,
Σ
\Sigma
Σ 是由
A
\boldsymbol{A}
A 的特征值组成的对角矩阵 !
在前面量子计算中我们就曾深入的探讨过各种矩阵,矩阵其实就是一种算子,一种线性变换的工具,如果某个矩阵乘以一个向量得到的新向量,其实就是相当于对原始向量做出了某种变换!在这里,我们依然采用这种方法,通过线性变化去理解它的意义所在:
有个对角矩阵: M = [ 3 0 0 1 ] M=\left[\begin{array}{ll}3 & 0 \\ 0 & 1\end{array}\right] M=[3001] ,乘以平面中的一个向量,如下:
结果为:
[
3
0
0
1
]
[
x
y
]
=
[
3
x
y
]
\left[\begin{array}{ll}3 & 0 \\ 0 & 1\end{array}\right]\left[\begin{array}{l}x \\ y\end{array}\right]=\left[\begin{array}{l}3 x \\ y\end{array}\right]
[3001][xy]=[3xy] ,相当于一个X轴方向上的拉伸,当你改变主对角线上的数字的时候,拉伸或伸缩的效果也是不同,问题又来了,如果不是对角矩阵作用又会是怎样?
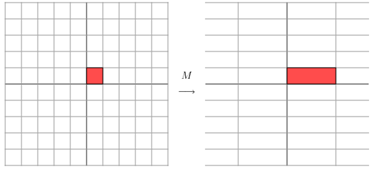
当
M
=
[
1
1
0
1
]
M=\left[\begin{array}{ll}1 & 1 \\ 0 & 1\end{array}\right]
M=[1011] 时,效果如下:
显然这个有点不一样,它其实是将整个平面方格图 沿着蓝色箭头的方向拉伸得到的结果,所以,不同的拉伸方向效果都是来源于不同的矩阵作用,我们只需要通过矩阵直接描述这个变换(拉伸或缩短的)的主要方向就好了!
我们要知道通过特征分解得到的 Σ \Sigma Σ 矩阵中主对角线上特征值的排列顺序是和 Q Q Q 矩阵中的特征向量的排列有着一一对应的关系!
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变化可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。而特征值就像是权重,哪个最大,哪个对应的特征向量方向就占比越大!
总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵(马上就会解决这个问题!)
是不是感觉世界都清晰了,当时理解了这个之后,我TM直接正道的光!我再一次认识到:线性代数是我见过最美妙牛逼的数学,没有之一,不接受反驳,不服来杠 |ू•ૅω•́)ᵎᵎᵎ

简单说了一下特征值分解,我们趁热打铁,直接上奇异值分解的车:
前面说特征值分解虽好,难免有局限性,比如只能是方阵,但是现实应用中强制是方阵明显就是在扯淡,所以,此时奇异值分解就闪亮登场!
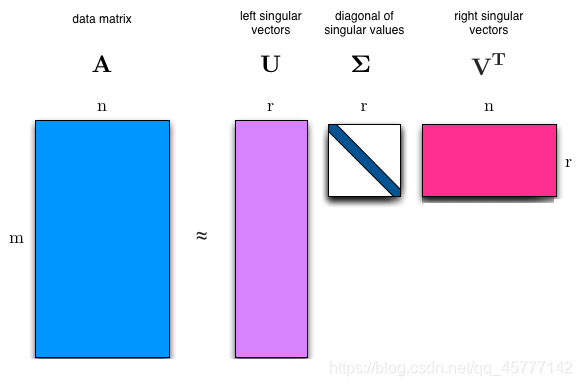
A
=
U
Σ
V
T
A=U \Sigma V^{T}
A=UΣVT
类比思想就很重要!假设
A
\boldsymbol{A}
A 是个
n
×
m
n\times m
n×m 的矩阵,那么得到的
U
\boldsymbol{U}
U 就是一个
n
×
n
n\times n
n×n 的方阵(其中向量相互正交,且称其为左奇异向量) ,
Σ
\boldsymbol{\Sigma}
Σ 是一个
n
×
m
n\times m
n×m 的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),
V
T
\boldsymbol{V}^{T}
VT (V矩阵的转置)是一个
n
×
n
n\times n
n×n 的矩阵,里面的各个向量也是相互正交的!
有小伙伴就问了,上面的介绍的不同向量可以理解,这个奇异值是什么东西,和前面的特征值有啥关系吗,唉,你猜对了,关系大了去了:
A
A
T
\boldsymbol{A}\boldsymbol{A}^{T}
AAT会得到一个方阵,在对这个方阵求特征值可以得到:
(
A
T
A
)
v
i
=
λ
i
v
i
\left(A^{T} A\right) v_{i}=\lambda_{i} v_{i}
(ATA)vi=λivi
这里的
v
i
v_{i}
vi 就是上面刚说的右奇异向量,且:
σ
i
=
λ
i
u
i
=
1
σ
i
A
v
i
\begin{array}{l} \sigma_{i}=\sqrt{\lambda_{i}} \\ u_{i}=\frac{1}{\sigma_{i}} A v_{i} \end{array}
σi=λiui=σi1Avi
这里的 σ i \boldsymbol{\sigma_{i}} σi 就是上面说的奇异值, u i \boldsymbol{u_{i}} ui就是上面说的左奇异向量! 这样我们就算是将特征值与奇异值分解联通起来了!
为了让大家更好的理解和使用,在我的纠结下,我还是和大家一块证明一下这个奇异值分解吧!
该部分是从几何层面上去理解二维的SVD:对于任意的 2 x 2 矩阵,通过SVD可以将一个相互垂直的网格图变换到另外一个相互垂直的网格图:
首先选择两个相互正交的单位向量 v 1 \boldsymbol{v_{1}} v1 和 v 1 \boldsymbol{v_{1}} v1 ,向量 M v 1 \boldsymbol{Mv_{1}} Mv1 和 M v 2 \boldsymbol{Mv_{2}} Mv2 正交!
u
1
\boldsymbol{u_{1}}
u1 和
u
2
\boldsymbol{u_{2}}
u2 分别是
M
v
1
\boldsymbol{Mv_{1}}
Mv1 和
M
v
2
\boldsymbol{Mv_{2}}
Mv2 的单位向量(这是另一组正交基)
因为
M
v
1
=
σ
1
u
1
M
v
2
=
σ
2
u
2
\begin{array}{l} M v_{1}=\sigma_{1} u_{1} \\ M v_{2}=\sigma_{2} u_{2} \end{array}
Mv1=σ1u1Mv2=σ2u2
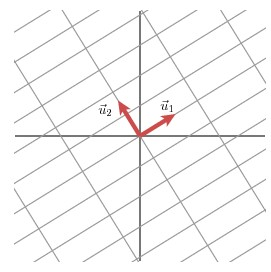
则 σ 1 , σ 2 \sigma_{1},\sigma_{2} σ1,σ2 分别为 M v 1 \boldsymbol{Mv_{1}} Mv1 和 M v 2 \boldsymbol{Mv_{2}} Mv2 的模(也称为矩阵 M \boldsymbol{M} M 的奇异值)。
对于任意向量 x \boldsymbol{x} x 有: x = ( v 1 ⋅ x ) v 1 + ( v 2 ⋅ x ) v 2 \boldsymbol{x}=\left(v_{1} \cdot \boldsymbol{x}\right) v_{1}+\left(v_{2} \cdot \boldsymbol{x}\right) v_{2} x=(v1⋅x)v1+(v2⋅x)v2
别懵,这只是一个数学技巧而已,例如:
当 x = [ 3 2 ] x=\left[\begin{array}{l}3 \\ 2\end{array}\right] x=[32] 时, x = ( [ 1 0 ] [ 3 2 ] ) [ 1 0 ] + ( [ 0 1 ] [ 3 2 ] ) [ 0 1 ] \quad x=\left(\left[\begin{array}{l}1 \\ 0\end{array}\right]\left[\begin{array}{ll}3 & 2\end{array}\right]\right)\left[\begin{array}{l}1 \\ 0\end{array}\right]+\left(\left[\begin{array}{l}0 \\ 1\end{array}\right]\left[\begin{array}{ll}3 & 2\end{array}\right]\right)\left[\begin{array}{l}0 \\ 1\end{array}\right] x=([10][32])[10]+([01][32])[01]
整个推导,就这个转化技巧最关键!之后我们运用这个得到:
M
x
=
(
v
1
⋅
x
)
M
v
1
+
(
v
2
⋅
x
)
M
v
2
M
x
=
(
v
1
⋅
x
)
σ
1
u
1
+
(
v
2
⋅
x
)
σ
2
u
2
\begin{array}{l} M x=\left(v_{1} \cdot x\right) M v_{1}+\left(v_{2} \cdot x\right) M v_{2} \\ M x=\left(v_{1} \cdot x\right) \sigma_{1} u_{1}+\left(v_{2} \cdot x\right) \sigma_{2} u_{2} \end{array}
Mx=(v1⋅x)Mv1+(v2⋅x)Mv2Mx=(v1⋅x)σ1u1+(v2⋅x)σ2u2
因为向量的内积可用向量的转置来表示,所以结合上面的推导:
M
x
=
v
1
T
x
σ
1
u
1
+
v
1
T
x
σ
2
u
2
M x=v_{1}^{T} x \sigma_{1} u_{1}+v_{1}^{T} x \sigma_{2} u_{2}
Mx=v1Txσ1u1+v1Txσ2u2
同时去掉
x
x
x:
M
x
=
v
1
T
σ
1
u
1
+
v
1
T
σ
2
u
2
M x=v_{1}^{T} \sigma_{1} u_{1}+v_{1}^{T} \sigma_{2} u_{2}
Mx=v1Tσ1u1+v1Tσ2u2即:
M
=
U
Σ
V
T
M=U \Sigma V^{T}
M=UΣVT
证明就算是完成了!
既然大差不差的搞懂了,我们做个题目来实现SVD 的计算:
- 矩阵 A \boldsymbol{A} A为: A = ( 0 1 1 1 1 0 ) \mathbf{A}=\left(\begin{array}{ll}0 & 1 \\ 1 & 1 \\ 1 & 0\end{array}\right) A=⎝⎛011110⎠⎞
- 首先求出
A
T
A
\boldsymbol{A^{T}A}
ATA 和
A
A
T
\boldsymbol{AA^{T}}
AAT
A T A = ( 0 1 1 1 1 0 ) ( 0 1 1 1 1 0 ) = ( 2 1 1 2 ) A A T = ( 0 1 1 1 1 0 ) ( 0 1 1 1 1 0 ) = ( 1 1 0 1 2 1 0 1 1 ) \begin{array}{l} \mathbf{A}^{\mathbf{T}} \mathbf{A}=\left(\begin{array}{lll} 0 & 1 & 1 \\ 1 & 1 & 0 \end{array}\right)\left(\begin{array}{ll} 0 & 1 \\ 1 & 1 \\ 1 & 0 \end{array}\right)=\left(\begin{array}{ll} 2 & 1 \\ 1 & 2 \end{array}\right) \\ \mathbf{A} \mathbf{A}^{\mathbf{T}}=\left(\begin{array}{ll} 0 & 1 \\ 1 & 1 \\ 1 & 0 \end{array}\right)\left(\begin{array}{lll} 0 & 1 & 1 \\ 1 & 1 & 0 \end{array}\right)=\left(\begin{array}{lll} 1 & 1 & 0 \\ 1 & 2 & 1 \\ 0 & 1 & 1 \end{array}\right) \end{array} ATA=(011110)⎝⎛011110⎠⎞=(2112)AAT=⎝⎛011110⎠⎞(011110)=⎝⎛110121011⎠⎞ - 进而分别求出 A T A \boldsymbol{A^{T}A} ATA 和 A A T \boldsymbol{AA^{T}} AAT 的特征值和特征向量:
A
T
A
\boldsymbol{A^{T}A}
ATA :
λ
1
=
3
;
v
1
=
(
1
/
2
1
/
2
)
;
λ
2
=
1
;
v
2
=
(
−
1
/
2
1
/
2
)
\lambda_{1}=3 ; v_{1}=\left(\begin{array}{c}1 / \sqrt{2} \\ 1 / \sqrt{2}\end{array}\right) ; \lambda_{2}=1 ; v_{2}=\left(\begin{array}{c}-1 / \sqrt{2} \\ 1 / \sqrt{2}\end{array}\right)
λ1=3;v1=(1/21/2);λ2=1;v2=(−1/21/2)
A
A
T
\boldsymbol{AA^{T}}
AAT :
λ
1
=
3
;
u
1
=
(
1
/
6
2
/
6
1
/
6
)
;
λ
2
=
1
;
u
2
=
(
1
/
2
0
−
1
/
2
)
;
λ
3
=
0
;
u
3
=
(
1
/
3
−
1
/
3
1
/
3
)
\lambda_{1}=3 ; u_{1}=\left(\begin{array}{c}1 / \sqrt{6} \\ 2 / \sqrt{6} \\ 1 / \sqrt{6}\end{array}\right) ; \lambda_{2}=1 ; u_{2}=\left(\begin{array}{c}1 / \sqrt{2} \\ 0 \\ -1 / \sqrt{2}\end{array}\right) ; \lambda_{3}=0 ; u_{3}=\left(\begin{array}{c}1 / \sqrt{3} \\ -1 / \sqrt{3} \\ 1 / \sqrt{3}\end{array}\right)
λ1=3;u1=⎝⎛1/62/61/6⎠⎞;λ2=1;u2=⎝⎛1/20−1/2⎠⎞;λ3=0;u3=⎝⎛1/3−1/31/3⎠⎞
利用
A
v
i
=
σ
i
u
i
,
i
=
1
,
2
A v_{i}=\sigma_{i} u_{i}, i=1,2
Avi=σiui,i=1,2 求奇异值:
(
0
1
1
1
1
0
)
(
1
/
2
1
/
2
)
=
σ
1
(
1
/
6
2
/
6
1
/
6
)
⇒
σ
1
=
3
(
0
1
1
1
1
0
)
(
−
1
/
2
1
/
2
)
=
σ
2
(
1
/
2
0
−
1
/
2
)
⇒
σ
2
=
1
\begin{array}{l} \left(\begin{array}{ll} 0 & 1 \\ 1 & 1 \\ 1 & 0 \end{array}\right)\left(\begin{array}{l} 1 / \sqrt{2} \\ 1 / \sqrt{2} \end{array}\right)=\sigma_{1}\left(\begin{array}{c} 1 / \sqrt{6} \\ 2 / \sqrt{6} \\ 1 / \sqrt{6} \end{array}\right) \Rightarrow \sigma_{1}=\sqrt{3} \\ \left(\begin{array}{cc} 0 & 1 \\ 1 & 1 \\ 1 & 0 \end{array}\right)\left(\begin{array}{c} -1 / \sqrt{2} \\ 1 / \sqrt{2} \end{array}\right)=\sigma_{2}\left(\begin{array}{c} 1 / \sqrt{2} \\ 0 \\ -1 / \sqrt{2} \end{array}\right) \Rightarrow \sigma_{2}=1 \end{array}
⎝⎛011110⎠⎞(1/21/2)=σ1⎝⎛1/62/61/6⎠⎞⇒σ1=3⎝⎛011110⎠⎞(−1/21/2)=σ2⎝⎛1/20−1/2⎠⎞⇒σ2=1
也可以用 σ i = λ i \sigma_{i}=\sqrt{\lambda_{i}} σi=λi 直接求!
最终得到A的奇异值分解为:
A
=
U
Σ
V
T
=
(
1
/
6
1
/
2
1
/
3
2
/
6
0
−
1
/
3
1
/
6
−
1
/
2
1
/
3
)
(
3
0
0
1
0
0
)
(
1
/
2
1
/
2
−
1
/
2
1
/
2
)
A=U \Sigma V^{T}=\left(\begin{array}{ccc} 1 / \sqrt{6} & 1 / \sqrt{2} & 1 / \sqrt{3} \\ 2 / \sqrt{6} & 0 & -1 / \sqrt{3} \\ 1 / \sqrt{6} & -1 / \sqrt{2} & 1 / \sqrt{3} \end{array}\right)\left(\begin{array}{cc} \sqrt{3} & 0 \\ 0 & 1 \\ 0 & 0 \end{array}\right)\left(\begin{array}{cc} 1 / \sqrt{2} & 1 / \sqrt{2} \\ -1 / \sqrt{2} & 1 / \sqrt{2} \end{array}\right)
A=UΣVT=⎝⎛1/62/61/61/20−1/21/3−1/31/3⎠⎞⎝⎛300010⎠⎞(1/2−1/21/21/2)
奇异值 σ \boldsymbol{\sigma} σ跟特征值类似,在 Σ \boldsymbol{\Sigma} Σ 矩阵中也是从大到小排列,而且 σ \boldsymbol{\sigma} σ的减少的特别快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了!
也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵,即:
A
m
×
n
=
U
m
×
m
Σ
m
×
n
V
n
×
n
T
≈
U
m
×
k
Σ
k
×
k
V
k
×
n
T
A_{m \times n}=U_{m \times m} \Sigma_{m \times n} V_{n \times n}^{T} \approx U_{m \times k} \Sigma_{k \times k} V_{k \times n}^{T}
Am×n=Um×mΣm×nVn×nT≈Um×kΣk×kVk×nT
其中k要比n小很多,也就是一个大的矩阵A可以用三个小的矩阵表示即可:
由于这个重要的性质,SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。
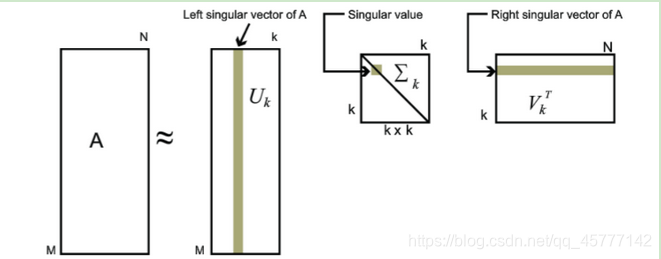
我们上面说推导和证明的奇异值分解方法都是完全奇异值分解,但是实际在图像处理算法中使用的的是奇异值分解的紧凑形式和截断形式。紧奇异值分解是与原始矩阵等秩的奇异值分解,截断奇异值分解是比原始矩阵低秩的奇异值分解,我们简单了解一下就可以了:
- 紧奇异值分解定义: 对于
m
×
n
m\times n
m×n 的实矩阵
A
\boldsymbol{A}
A ,秩为:
r
a
n
k
(
A
)
=
r
⩽
m
i
n
(
m
,
n
)
rank(\boldsymbol{A})= r \leqslant min(m,n)
rank(A)=r⩽min(m,n),那么矩阵
A
\boldsymbol{A}
A 的 紧奇异值分解 为:
A = U r Σ r V r T \boldsymbol{A}= \boldsymbol{U_{r}} \boldsymbol{\Sigma_{r}}\boldsymbol{V_{r}^{T}} A=UrΣrVrT
其实就是就是在列的方向上只取前 r r r 列 即可; - 截断奇异值分解定义: 对于
m
×
n
m\times n
m×n 的实矩阵
A
\boldsymbol{A}
A ,秩
r
a
n
k
(
A
)
=
r
rank(\boldsymbol{A}) =r
rank(A)=r ,d但是
0
<
k
<
r
0<k<r
0<k<r,则截断奇异值分解为:
A ≈ U k Σ k V k T \boldsymbol{A}\approx \boldsymbol{U_{k}} \boldsymbol{\Sigma_{k}}\boldsymbol{V_{k}^{T}} A≈UkΣkVkT
比较二者的公式应该就能明白了,只不过一个是等于号,一个是约等于!
注意:紧奇异值分解还原后等于原矩阵,截断奇异值分解近似还原原矩阵。因此在对矩阵数据进行压缩时,紧奇异值分解对应无损压缩,截断奇异值分解对应有损压缩。
这里为大家附上代码链接:特征值,奇异值分解及其应用
前面的所有所有,都在解释矩阵的奇异值是怎么得到的,包括证明等等,但是奇异值到底是个什么东西,它与矩阵之间有什么千丝万缕的联系么?我们似乎还是有点蒙!
无论是特征值分解还是奇异值分解,都是为了让人们对矩阵(或者线性变换)的作用有一个直观的认识。这是因为我们拿过来一个矩阵,很多情况下只能看到一堆排列有序的数字,而看不到这些数字背后的真实含义,特征值分解和奇异值分解告诉了我们这些数字背后的真实含义,换句话说,它告诉了我们关于矩阵作用的本质信息!
对于奇异值来说,其实他反映的是一个矩阵的“奇异程度”。
这就又让我想到了大一线代课上老师说过:非满秩的方阵就是奇异矩阵,换句话说就是该方阵的行列式为0,但是有没有量化的标准衡量哪个矩阵更不满秩,或者更奇异呢?比如同样两个满秩矩阵,能否看出哪个更“满”,或者两个非满秩且同为秩r的矩阵,哪个更“奇异”呢?
奇异的程度在我看来 秩越低越奇异(目前可以这么理解),相同秩情况下,上图都是秩为2,但我们可以看出A矩阵更接近秩为一!
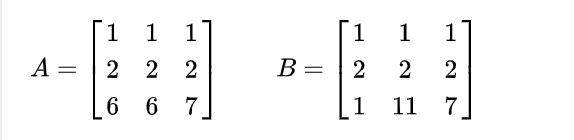
看看这两个矩阵的奇异值:
猜的没错,第一个矩阵更奇异!
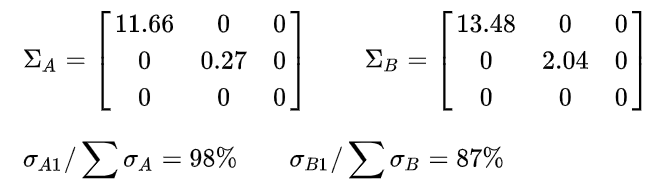
这意味着:一个矩阵越“奇异”,其越少的奇异值蕴含了越多的矩阵信息,矩阵的信息熵越小(这也符合我们的认知,矩阵越“奇异”,其行(或列)向量彼此越线性相关,越能彼此互相解释,矩阵所携带的信息自然也越少)。这些奇异值就是刚才我们所谈论的“本质信息”,而从矩阵中也能得到矩阵的“奇异程度”。
说了那么多,我们最后再来看看奇异值的几个性质:
-
奇异值对矩阵扰动的不敏感性:
在数学上可以证明,奇异值的变化不会超过相应矩阵的变化,即对任何的相同阶数的实矩阵A、B的按从大到小排列的奇异值 α i \boldsymbol{\alpha_{i}} αi 和 w \boldsymbol{w} w
∑ ∣ α i − w i ∣ ≤ ∥ A − B ∥ 2 \sum\left|\boldsymbol{\alpha_{i}}-\boldsymbol{w}_{i}\right| \leq\|A-B\|_{2} ∑∣αi−wi∣≤∥A−B∥2
这个性质通常应用于人脸识别中,使用合适的分类器就可以把同一个人的不同姿态,表情的图像矩阵归为一个,具有高容错性! -
奇异值的比例不变性:
α A \alpha\boldsymbol{A} αA 的奇异值是 A \boldsymbol{A} A 奇异值的 ∣ α ∣ \left | \alpha \right | ∣α∣ 倍!
矩阵进行数乘变换,奇异值也成比例变化。同一个人脸在光线明暗不同情况的图像识别中,它们的矩阵奇异值是成比例变化的。奇异值向量归一化后可以视为一类!
-
奇异值的旋转不变性:
即若 P \boldsymbol{P} P是正交阵, P A \boldsymbol{PA} PA的奇异值与 A \boldsymbol{A} A的奇异值相同!
奇异值的比例和旋转不变性特征在数字图象的旋转、镜像、平移、放大、缩小等几何变化方面有很好的应用.
好这一期博客学习就到这里,下期再见!