python基本语法
pycharm常用快捷键
ctrl+alt+s:打开软件设置
ctrl+d:复制当前行代码
shift+alt+上/下:将当前行代码向上或向下移动
ctrl+shift+f10:运行当前代码文件
shift+f6:重命名文件
ctrl+f:搜索
python基础语法
一,注释
单行注释:#
多行注释:“”“我是多行注释”“”
二,变量与print输出函数
变量的定义格式:变量名=变量值
如:
num=100
print()是输出函数
如:
print("helloWorld")
print()如何输出多份内容格式
print(内容1,内容2...,内容n)
三,数据类型
常见的数据类型
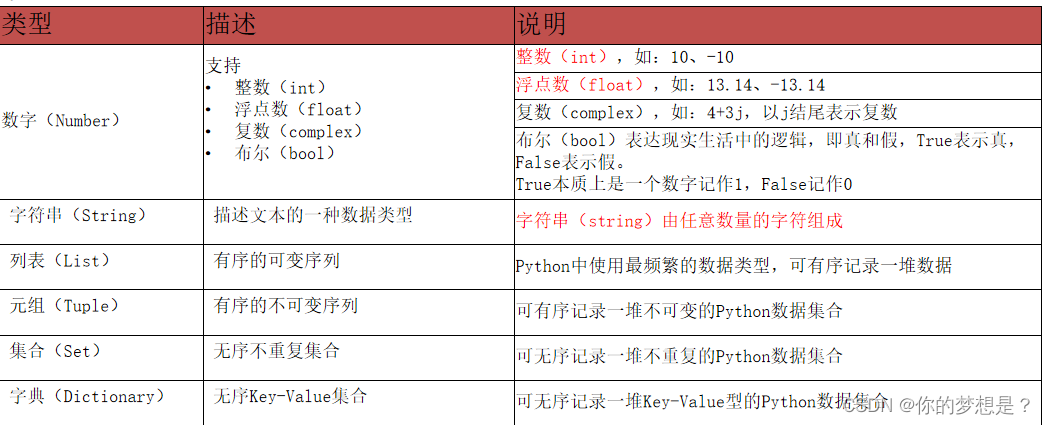
type()函数用来查看数据类型
如:
name="张三"
print(type(name))
四,数据类型转换
字符串,整数,浮点型数据类型转换语句分别
int(x),float(x),str(x),
note:1,任何数据类型都可以转换成字符串
2,字符串转换为数字有限制
3,浮点型转换为整数需注意丢失精度问题
五,标识符
标识符命名规则:
1.由字母数字下划线组成
2.第一个字符必须是字母或者是下划线
3.标识符不能以数字开头
4.标识符区分大小写
5.不能与关键字重名
常见关键字

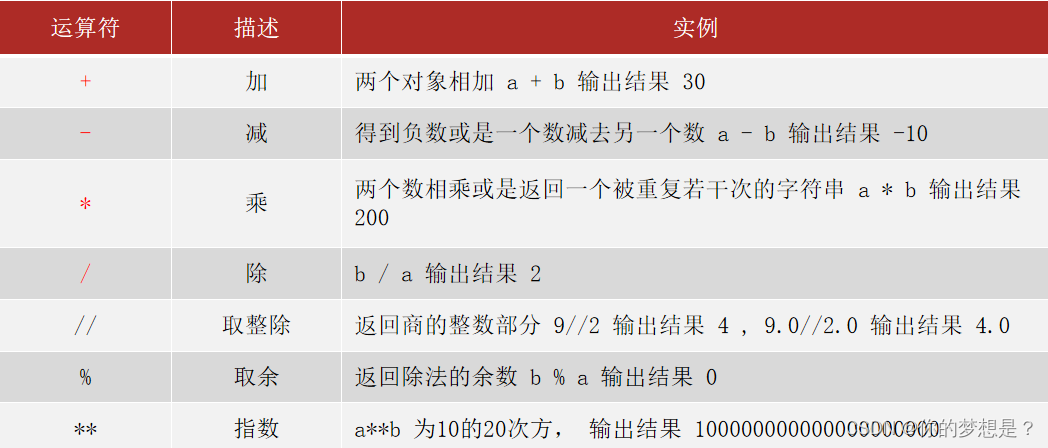
六,运算符
常见数学运算符
赋值运算符:=
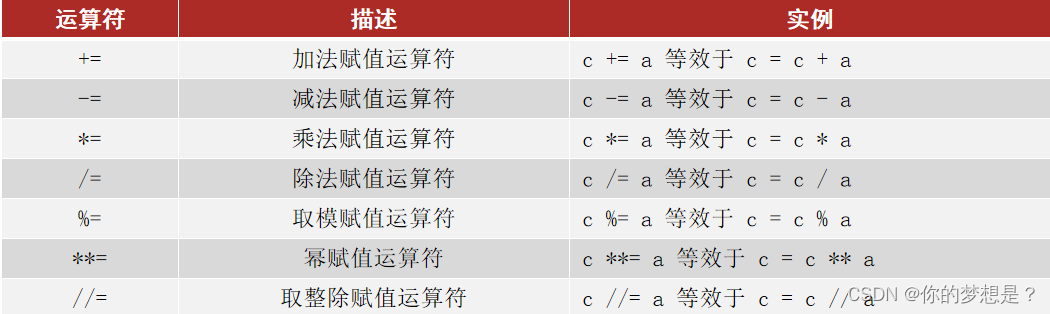
常见复合赋值运算符
七,字符串
字符串定义方法三种
1.单引号方式
2.双引号方式
3.三引号方式
引号的嵌套使用转义字符\
如
print("\"helloworld\"")
print('\"helloworld\"')
print('\'helloworld\'')
字符串的拼接:
字符串的拼接使用+链接字符串变量或者字符串字面量
如
neme="张三"
print("我是"+name+",毕业于家里蹲大学")
注意无法和非字符串类型进行拼接
字符串的格式化1语法为:”%占位符“ %变量
如
name="张三"
print("我是%s"% name)
常用占位符有%s:字符串,%d:整数,%f:浮点类型
字符串格式化2语法 f“内容{变量}”,这种方式不会做精度的控制
如
name="张三"
age=10
print(f"我是{name},今年{age}岁")
格式化精度控制
使用”m.n"来控制数据的宽度合精度,m用来控制数据的宽度,若设置的宽度小于数字自身的宽度,不生效,n用来控制数据的精度,会进行小数的四舍五入,m和.n均可省略
如
%5.2f表示数据宽度设置为5位,小数精度设置为2位
%.2f表示不设置宽度,只设置小数的精度
表达式的格式化
基于字符串有两种格式化方式,表达式也有两种格式化方式
如
print("1*1=%d" % (1*1))
print(f"1*1的结果是{1*1}")
数据输入函数input()
input()函数用来获取键盘输入,括号内可以用来设置提示信息,注意无论键盘输入什么类型的数据,通过input()函数得到的都是字符串类型
如
var1=input("请输入一个字符串")
var2=input("请输入一个整数")
var3=input("请输入一个浮点类型")
var4=input("请输入一个布尔类型")
print(f"输入的字符串,变量类型是{type(var1)},内容是{var1}")
print(f"输入的整数,变量类型是{type(var2),内容是{var2}")
print(f"输入的是浮点数,变量类型是{type(var3),内容是{var3}")
print(f"输入的是布尔类型,变量类型是{type(var4)},内容是{var4}")
八,判断语句
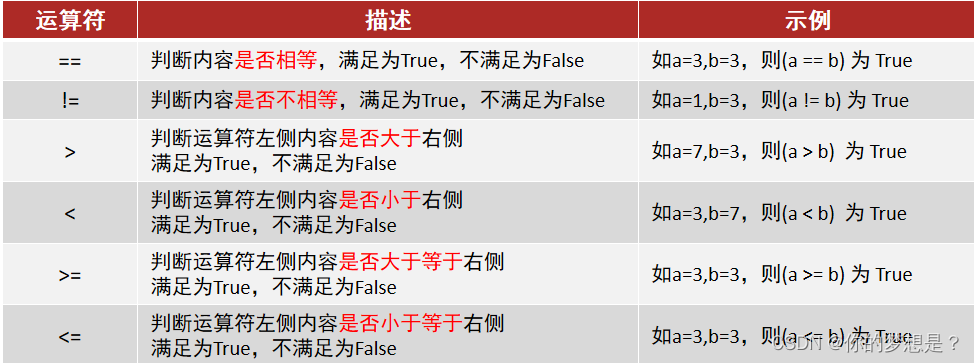
一,布尔类型与比较运算符
布尔类型字面量:True:真,False:假
定义方式:变量名称=布尔类型字面量
常见比较运算符
二,if语句
if…else语句
语法格式:
if 条件:
满足条件时要做的事
else
不满足条件时要做的事
如
age=int(input("请输入你的年龄"))
if age>18:
print("您已成年,需支付10元票价")
else:
print("您未成年,可以免费游玩")
if …elif…esle语句
语法格式:
if 条件1:
满足条件1要做的事
elif: 条件2:
满足条件2要做的事
else
不满足所有条件要做的事
如
height=int(input("请输入您的身高(cm)"))
vip_level=int(input("请输入您的vip等级(1-5)"))
if height<120:
print("您的身高低于120cm,可以免费游玩")
elif vip_level>3:
print("您的vip级别大于3,可以免费游玩")
else
print("您所有优惠条件都不满足,需支付门票")
if语句的嵌套使用
语法格式:
if 条件1:
满足条件1做的事
if 条件2:
满足条件2做的事
如
if(input(“请输入您的身高:”))>120
print("您的身高大于120,不可以免费")
print(“不过若您的vip等级高于3,可以免费游玩”)
if(input("请输入您的vip等级:"))>3
print("恭喜您,您的vip级别大于3,可以免费游玩")
else:
print("您不满足所有的优惠条件,需支付门票")
else:
print("小朋友,您可以免费游玩")
使用and检查多个条件,使用and必须两者的关系都为真,判断结果才会为真,若至少有一个假,则结果为假
age_0=22
age_1=18
if age_0 >= 21 and age_1>=21:
print("满足情况1")
elif age_0<21 and age_1<21:
print("满足情况2")
elif age_0>=21 and age_1<21:
print("满足情况3")
else:
print("满足情况4")
使用or检查多个条件,使用or必须两者的关系都为假,判断结果才会为假,若至少有一个真,则结果为真
age_0=22
age_1=18
if age_0 >= 21 or age_1>=21:
print("满足情况1")
elif age_0<21 or age_1<21:
print("满足情况2")
elif age_0>=21 or age_1<21:
print("满足情况3")
else:
print("满足情况4")
九,循环语句
1.while循环语句
基本语法格式:
while 条件:
条件满足时,要做的事情1
条件满足时,要做的事情2
...
注意:条件需提供布尔类型,注意循环终止条件,避免不必要的死循环
案例一
#向小美表白100次
i=0
while i<100:
print("小美,我喜欢你")
i+=1
案例二
"""
设置一个范围1-100的随机整数变量,通过while循环,配合input语句,判断输入的数字是否等于随机数
无限次机会,直到猜中为止
每一次猜不中,会提示大了或小了
猜完数字后,提示猜了几次
"""
import random
num = random.randint(1, 100)
count=0
while True:
var=int(input("输入您想猜的数字"))
if var<num:
print("猜小了,请重新猜测")
elif var>num:
print("猜大了,请重新猜测")
else:
print("恭喜你猜对了")
#break语句用来终止while循环语句
break
2.while循环的嵌套
基本语法:
while 条件1:
条件1满足时,做的事情1
条件1满足时,做的事情2
...
while 条件2:
条件2满足时,做的事情1
条件2满足时,做的事情2
...
案例
#向小美表白100次
i=1
while i<=100:
print(f"今天是第{i}天",准备表白...)
j=1
while j<=10:
print(f"送给小美第{j}支玫瑰花")
j+=1
print("小美,我喜欢你")
i+=1
print(f"坚持到第{i-1}天,表白成功")
3.for循环
基本语法:
for 临时变量 in 待处理数据集:
循环满足条件时执行的代码
案例
#遍历字符串
name="zhangsan"
for x in name:
print(x)
与while循环不同,for循环是无法定义循环条件的,只能从被处理的数据集中,以此取出内容进行处理
语法中的待处理数据集包括字符串,列表,元组等
range语句:
range(num)
获取一个从0开始,到num结束的数字序列(不含num本身)
如range(5)取得的数据是【0,1,2,3,4】
range(num1,num2)
获得一个从num1开始,到num2结束的数字序列(不含num2本身)
range(num1,num2,step)
获得从num1开始,到num2结束的数字序列(不含num2本身)数字之间的步长,以step为准(step默认为1)
案例
#for循环处理字符串
for i range(5)
print(i)
4.变量的作用域
for循环中的的临时变量,作用域限定为循环内部,被称作局部变量,在for循环外部访问临时变量:实际上是可以访问的到的,但在编程规范上,是不允许,不建议这么做
5.for循环的嵌套使用
基本语法:
for 临时变量 in 待处理数据集(序列):
循环满足条件时应做的事情1
循环满足条件时应做的事情2
for 临时变量 in 待处理数据集:
循环满足条件时应做的事情1
循环满足条件时应做的事情2
案例
#向小美表白for循环嵌套改进
i=1
for i in range(1,101):
print(f"今天向小美表白的第{i}天,坚持。")
for j in range(1,11):
print(f"送给小美的第{i}朵玫瑰花")
print(f"小美,我喜欢你(第{i}天的表白结束)")
print(f"第{i}天,表白成功")
同时,for循环也可以与while循环嵌套使用
6.break与continue关键字
continue:可以控制它所在的循环临时中断
break:可以直接结束所在的循环
十,函数
函数:是组织好,可重复使用的,用来实现特定功能的代码段,如input(),print(),str(),int()等
优点:功能已经被封装好了,可以重复使用,提高代码的复用性,减少重复代码,提高开发效率
1.函数的定义:
def 函数名(传入参数):
函数体
return 返回值
在使用函数时,先定义函数,在调用函数,参数可以省略,返回值不需要时,也可以省略
2.函数的参数
语法解析:
#定义两数相加函数
def add(x,y):
result=x+y
print(f"{x}+{y}的结果是:{result}")
#调用函数
add(5,6)
函数定义中提供的x和y被称作形式参数(形参),表示函数将要使用的2个参数,参数之间使用逗号分隔
函数调用过程中,提供的5和6,被称作实际参数(实参),表示函数执行时真正使用的参数值,参数之间使用逗号隔开,实参与形参之间两者一一对应
3.函数的返回值
基本语法格式:
def 函数名(参数...):
函数体
return 返回值
变量=函数(参数)
变量能接收到函数return返回的数据,需注意,函数在return之后就结束了,所以写在return之后的代码就不会执行
无返回值的函数可以省略return,也可以return None,两者使用变量接受后都是NoneType类型。
4.函数说明文档
在调用函数时,我们需要了解函数需要的参数以及作用,这就离不开函数说明文档
def func(x,y):
"""
:param x: 说明参数x的作用
:param y: 说明参数y的作用
:return: 返回值的说明
"""
注意注释应写在函数中,函数体之前,这样在调用函数时,鼠标放在调用函数上面就会显示说明文档内容
5.函数的嵌套使用
函数的嵌套使用是指一个函数里面又调用了另外一个函数
案例
def func_a():
print("函数a")
def func_b():
print("调用函数a")
print("函数b")
func_b()
执行顺序先是执行函数b,在执行函数b过程中调用了函数a,此时函数b停止向下继续执行,执行函数a,打印输出,函数a执行完成后,再回到函数b继续执行函数b接下来的操作语句,打印输出函数b
6.变量的作用域
局部变量:在函数体内部,临时变量,当函数调用完成后,销毁局部变量
全局变量:在函数体内部,函数外部,都能生效的变量
案例
#定义全局变量
num=100
def testA():
print(num)
def testB()
print(num)
testA()
testB()
print(f"全局变量{num}")
global关键字
如果要在函数内定义全局变量,需要在函数中使用global关键字
案例
#定义全局变量
num=100
def testA():
print(num)
def testB()
global num
num=200
print(num)
testA() #100
testB() #200
print(f"全局变量{num}") #200
十一,数据容器
数据容器是一种可以存储多个元素的python的数据类型,常见的数据容器有list(列表),tuple(元组),str(字符串),set(集合),dict(字典)
1.list列表
列表定义的基本语法:
#字面量
[元素1,元素2,元素3,元素4,...]
#定义变量
变量名称=[元素1,元素2,元素3,元素4...]
#定义空列表
变量名称=[]
变量名称=list()
列表中的每一个数据称之为元素,以[]作为标识,每个元素之间用,逗号隔开
案例
name_list=['ittheima','itcast','python']
print(name_list)
print(type(name_list))
my_list=['itheima','666',True]
print(my_list)
print(type(my_list))
list=[[1,2,3],[4,5,6]]
print(list)
print(type(list))
列表的下标索引

按照下标索引,即可取得对应位置的元素
案例一
name_list=['Tom','Lily','Rose']
print(name_list[0])
print(name_list[1])
print(name_list[2])
反向索引,下标索引从-1开始依次递减
name_list=['Tom','Lily','Rose']
print(name_list[-1])
print(name_list[-2])
print(name_list[-3])
案例二
#嵌套列表根据索引获取元素
my_list=[[1,2,4],[4,5,6]]
#获取内层第一个list
print(my_list[0]) #结果:[1,2,3]
#获取内层第一个list的第一个元素
print(my_list[0][0]) #结果:1
注意下标索引的取值超出范围将无法取出元素,并且报错
列表的查询功能
查找指定元素的在列的下标,如果找不到,报错ValueError
语法:列表.index(元素)
案例
my_list=["iteima","itcast","python"]
print(my_list.index("itcast")) #结果:1
修改特定位置的元素值
根据下标索引对列表元素值的修改
语法:列表[下标]=值
#正向下标
my_list=[1,2,4]
my_list[0]=5
print(my_list)
#反向下标
my_list=[1,2,4]
my_lsit[-3]=5
print(my_list)
插入元素
在指定的下标位置,插入指定的元素
语法:列表.insert(下标,元素)
my_list=[1,3,4]
my_list.insert(1,"iteima")
print(my_list) #结果:[1,ithema,3,4]
追加元素
将指定元素追加到列表的尾部
语法1:列表.append(元素)
my_list=[1,2,3]
my_list.append(4)
print(my_list) #结果:[1,2,3,4]
#嵌套列表
my_list=[1,2,3]
my_list.append([4,5,6])
print(my_list) #结果:[1,2,3,[4,5,6]]
语法2:列表.extend(其他数据容器),将其他数据容器的内容取出,依次追加到列表的尾部
my_list=[1,2,3]
my_list.extend([4,5,6])
print(my_list) #结果:[1,2,3,4,5,6]
删除元素
根据索引下标删除指定元素
语法1:del 列表[下标]
语法2:列表.pop(下标)
案例
my_list=[1,2,3]
#方式1
del my_list[0] #结果[2,3]
print(my_list)
#方式2
my_list=[1,2,3]
my_list.pop(0)
print(my_list) #结果[2,3]
列表的修改功能
删除某元素在列表中的第一个匹配项
语法:列表.remove(元素)
my_list=[1,2,3,2,3]
my_list.remove(2)
print(my_list) #结果:[1,3,2,3]
清空列表元素
语法:列表.clear()
my_list=[1,2,3]
my_list.clear()
print(my_list) #结果:[]
统计某元素在列表内的数量
语法:列表.count(元素)
my_list=[1,1,1,1,2,3]
print(my_list.count(1)) #结果:3
统计列表内,有多少元素
语法:len(列表)
可以得到一个int数字,表示列表内的元素数量
my_list=[1,2,3,4,5]
print(len(my_list)) #结果5
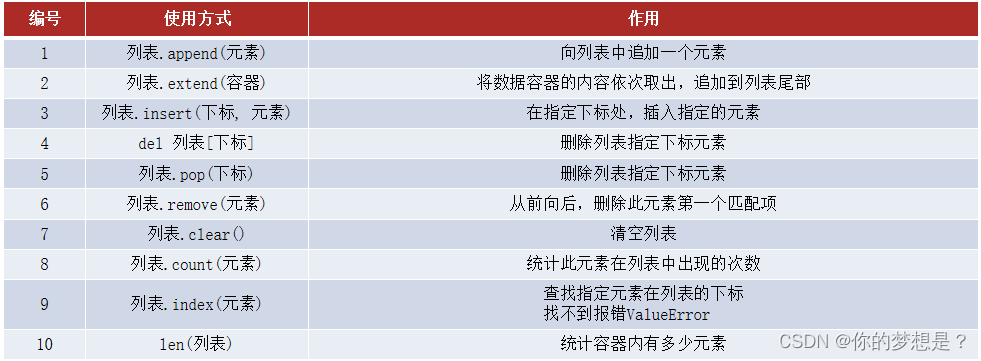
列表的方法总结
列表的特点
可以容纳多个元素
可以容纳不同类型的元素
数据是有序的
允许重复数据存在
允许对数据进行修改
列表的遍历
while循环遍历方式
语法格式:
index=0
while index<len(列表):
元素=列表[index]
对元素进行处理
index+=1
for循环遍历方式
语法格式:
for 临时变量 in 数据容器:
对临时变量进行处理
两者的区别:
在循环控制上,while循环可以自定义循环条件,并且自行控制
for循环不可以自定义循环条件,只可以一个个从容器中取出数据
在无限循环上,while可以通过条件控制做到无限循环,for循环理论上不可以,因为被遍历的容器容量不是无限的
2.tuple(元组)
元组定义的语法格式:
#定义字面量元组
(元素,元素,...,元素)
#定义元组变量
变量名称=(元素,元素,...,元素)
#定义空元组
变量名称=()
变量名称=tuple()
#定义嵌套元组
t1=((1,2,3),(1,2,3))
print(t1[0][0])
元组的相关操作

案例
#根据下标(索引)取出数据
t1=(1,2,'hello')
print(t1[2]) #结果是hello
#根据index()方法查找特定元素的下标索引
t1=(1,2,'hello',3,4,'hello')
print(t1.index('hello')) #结果是2
#统计某个数据在元组内出现的次数
t1=(1,2,4)
print(len(t1))
元组的具有不可修改性,一旦定义完成,就不可修改,故元组不存在修改的操作
元组的遍历和列表的遍历方式相似,既有while()循环,for()循环遍历方式。
案例
#while循环遍历
my_tuple=(1,2,3)
index=0
while index<len(my_tuple):
print(my_tuple[index])
index+=1
#for循环遍历
for i in my_tuple:
print(i)
元组的特点:
可以容纳多个数据
可以容纳不同类型的数据
数据是有序的
允许重复数据存在
支持for()循环
3.字符串
字符串是字符的容器,一个字符串可以存放任意数量的字符,如“itheima”

字符串的下标索引和集合list类似,从前开始,下标从0开始,从后开始,下标从-1开始。与元组类似,字符串是一个无法修改的数据容器
字符串的常用操作:
查找特定字符串的下标索引
语法:字符串.index(字符串)
my_str="itcast and itheima"
print(my_str.index("and")) #结果 7
字符串的替换:将字符串的全部:字符串1,替换为字符串2,注意不是修改字符串本身,而是得到了一个新的字符串
语法:字符串.replace(字符串1,字符串2)
案例
name="zhangsan"
new_name=name.replace("zhang","lisi")
print(name) #zhangsan
print(new_name) #lisisan
字符串的规整操作:对字符串指定字符去除操作
案例
#字符串去前后空格
my_str=" zhangsan "
print(my_str.strip()) #zhangsan
#去前后指定字符串
my_str="12zhangsna and lisi21"
print(my_str.strip("12")) #zhangsan and lisi
#注意传入的12,其实就是‘1’,‘2’都会移除
统计字符串中某字符串出现的次数
语法:字符串.count(字符串)
my_str="zhangsan and lisi"
print(my_str.count("li")) #结果 1
统计字符串的长度
语法:len(字符串)
my_str="1234 abcd !@#$ zhangsan"
print(len(my_str)) #23
划分字符串
split() 方法是用来将字符串分割成一个字符串数组的函数。它的基本语法如下:
str.split(sep=None, maxsplit=-1),返回值是list集合
#划分字符串
str="hello world zhangsan lisi wanger"
str_list=str.split()#以空格划分
print(str_list)
#["hello","world","zhangsan","lisi","wanger"]
sep 参数是指定分隔符(默认为空格), maxsplit 参数是指定最大分割次数(默认为-1,表示分割所有出现的分隔符)。
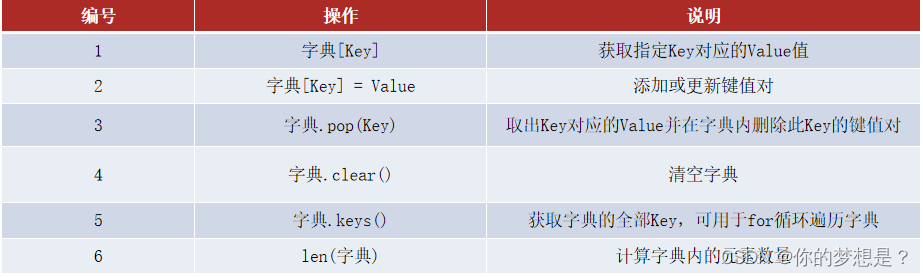
字符串常用操作汇总
字符串的遍历同列表,元组一样,字符串也支持while循环和for循环进行遍历
字符串的特点
只可以存放字符串
长度任意
支持下标索引
允许重复出现
不可修改
支持for循环
4.数据容器(序列)的切片
序列:指内容连续,有序,有下标索引的一类数据容器
列表,元组,字符串均可视为序列
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iVw33ZYg-1687933698793)(D:\学习资料\python\课件\截图\序列.png)]
序列的常用操作:切片
切片是指从一个序列中取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列,起始下标可以留空,留空表示从头开始,结束下标表示何处结束,可以留空,留空视作取到结尾,步长表示,依次取元素的间隔,步长1表示1个个去元素,步长2表示每次跳过一个元素去,步长N表示每次跳过N-1个元素取,步长为负数反向取(注意,起始下标和结束下标也要反向标记)
案例
my_list=[1,2,3,4,5]
new_list=my_list[1:4] #下标1开始,下标4(不含)结束,步长1
print(new_list) #结果[2,3,4]
my_tuple=(1,2,3,4)
new_tuple=my_tuple[:] #从头开始,到最后结束,步长为1
print(new_tuple) 结果(1,2,3,4)
my_str="12345"
new_str=my_str[::2] #从头开始,到最后结束,步长为2
print(new_str) #结果[1,3,5]
5.set(集合)
集合的基本定义
语法:
#定义集合字面量
{元素1,元素2,元素3...,元素4}
#定义集合变量
变量名称={元素,元素,元素...,元素}
#定义空集合
变量名称=set()
案例:
names={"zhangsan","lisi","wanger","zhaoliu","zhangsan"}
print(names)
#结果:lisi,wanger,zhangsan,zhaoliu
集合的特点是去重且无序
集合的常用操作:
添加新元素
语法:集合.add(元素),将指定元素添加到集合内,集合本身被修改,添加了新元素
案例
my_set={"hello","world"}
my_set.add("zhangsan")
print(my_set)
#结果:{hello,zhangsan,world}
移除元素
语法:集合.remove(元素),将指定元素从集合内移除,集合本身被修改,移除了元素
案例
my_set={"hello","world","zhangsan"}
my_set.remove("hello")
print(my_set)
#结果:{"world","zhangsan"}
随机取出元素
语法:集合.pop(),从集合中随机取出一个元素,同时集合本身被修改,被取出的元素被移除集合
案例
my_set={"hello","world","zhangsan"}
element=my_set.pop()
print(my_set)
print(element)
清空集合
语法:集合.clear(),清空所有的集合中的元素,得到一个空集合
案例
my_set={"hello","world","张三"}
my_set.clear()
print(my_set)
取出两个集合的差集
语法:集合1.difference(集合2),取出集合1和集合2的差集(集合1有而集合2没有)
set1={1,2,3}
set2={1,5,6}
set3=set1.difference(set2)
print(set1) #结果: {1,2,3}
print(set2) #结果: {1,5,6}
print(set3) #结果: {2,3}
消除两个集合的差集
语法:集合1.difference_update(集合2)对比集合1和集合2,删除和集合2相同的元素,集合1改变,集合2不变
set1={1,2,3}
set2={1,5,6}
set1.difference_update(set2)
print(set1) #结果: {2,3}
print(set2) #结果: {1,5,6}
两个集合的合并
语法:集合1.union(集合2),将集合1和集合2组合成新集合,得到新集合,集合1与集合2不变
案例
set1={1,2,3}
set2={1,5,6}
set3=set1.union(set2)
print(set1) #结果: {1,2,3}
print(set2) #结果: {1,5,6}
print(set3) #结果: {1,2,3,6,5}
查看集合元素的数量
语法:len(集合),统计集合内有多少个元素,得到一个整数结果
案例
set1={1,2,3}
print(len(set1)) #结果3
集合支持for循环遍历,由于集合不支持下标索引,故不支持使用while循环。
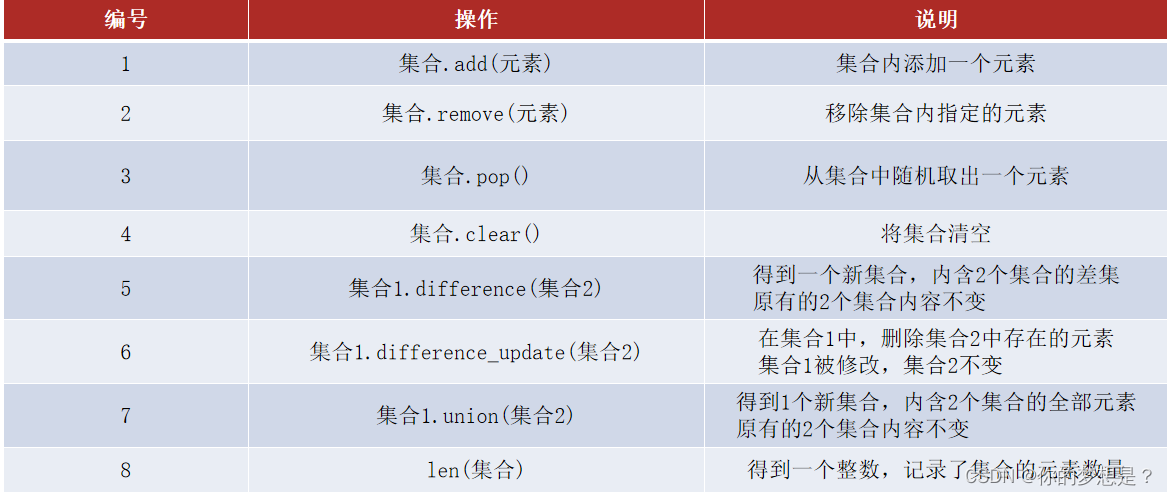
集合的常用操作方法
集合的特点:
可以容纳多个元素
可以容纳多个不同类型的元素
数据是无序存储的
不允许重复数据存在
可以被修改
支持for循环,但不支持while循环
6.字典
字典的定义:使用{}存储,每一个键对应一个元素,key与value之间使用:分隔,键值对之间使用逗号分隔,key与value之间使用任意类型,键key不可重复定义,若重复定义会对原数据覆盖
案例
#定义字典字面量
{key:value,key:value,...,key:value}
#定义字典变量
my_dict={key:value,key:value,...,key:value}
#定义空字典
my_dict={}
my_dict=dict()
#记录学生的成绩
stu_score={"张三":90,"李四":25,"赵一":89}
字典数据的获取,字典和集合一样,不可以使用下标索引,但是字典可以通过key值来获取对应的value
案例
stu_score={"张三":90,"李四":25,"赵一":89}
print(stu_score["张三"])
print(stu_score["李四"])
print(stu_score["赵一"])
字典的嵌套
案例:打印学生考试成绩表
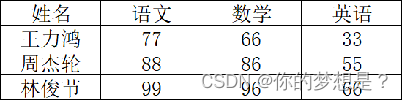
stu_score={
"王力鸿”:{"语文":77,"数学":66,"英语":33},
"周杰轮":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":89,"英语":66}
}
print(stu_score)
#嵌套列表的取值
print(stu_score["王力鸿"])
print(stu_score["王力鸿"]["语文"])
print(stu_score["王力鸿"]["数学"])
字典新增元素
语法:字典[Key]=Value,结果:字典被修改,新增了元素
案例
stu_score={
"王力鸿":77
"周杰轮":88
"林俊节":89
}
stu_score['张三']=89
print(stu_score)
删除元素
语法:字典.pop(Key),结果:获得指定Key的Value,同时字典被修改,指定Key的数据被修改
stu_score={
"王力鸿":77
"周杰轮":88
"林俊节":89
}
value=stu_score.pop("王力鸿")
print(value)
print(stu_score)
清空字典
语法:字典.clear(),结果:字典被修改,元素被清空
stu_score={
"王力鸿":77
"周杰轮":88
"林俊节":89
}
stu_score.clear()
print(stu_score)
获取全部的key
语法:字典.key(),结果:得到字典中的全部的key
stu_score={
"王力鸿":77
"周杰轮":88
"林俊节":89
}
keys=stu_score.keys()
print(keys) 结果:dict_keys{["王力鸿","周杰轮","林俊节"]}
字典的遍历和集合相同,由于不支持下标索引,所以也不能使用while循环遍历
计算字典内部的全部元素(键值对)的数量
语法:len(字典) 结果得到一个整数,表示字典内元素(键值对)的数量
stu_score={
"王力鸿":77
"周杰轮":88
"林俊节":89
}
print(len(stu_score))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bPQWBhG2-1687933698794)(D:\学习资料\python\课件\截图\字典常用操作.png)]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuLzc3Zjc0MzQzMWYwMzQ3NDU5NDhkNWU1NDU5Y2IwZjlkLnBuZw%3D%3D)
字典的特点:
可以容纳多个不同数据类型的元素
每一份数据都是Key–value键值对
可以通过key获取到value,但key不能重复
不支持下标索引,可以修改数据,支持for循环遍历,不支持while循环遍历
7.各个数据容器之间的对比
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xDVzkQcL-1687933698795)(D:\学习资料\python\课件\截图\各个数据容器之间的对比.png)]
8.各个数据容器之间的通用操作
len():统计容器中元素的个数
max():统计数据容器中的最大元素
min():统计数据容器中的最小元素
list():将指点容器转换成列表
str():将指定容器转换为字符串
tuple():将指定容器转换为元组
set():将指定容器转换为集合
sorted(容器,[reverse=True]):将指定容器进行排序,reverse值默认为False,可省略,表示是否降序排序
字符之间的比较大小是通过比价ASXII码表,同时字符串的比较是通过按位比较字符的大小
十二,函数进阶
1,多个返回值的函数
如果需求函数要有多个函数返回值,基本语法为return 返回值1,返回值2,同时接受返回值也要按位接受
案例
def test_return():
return 1,2
x,y=test_retun()
print(x)
print(y)
2,函数的多种传参方式
位置参数:调用函数时根据函数定义的参数位置来传递参数,需注意传递的参数和定义的顺序及个数须保持一致
案例
def user_info(name,age,gender):
print(f"您的名字是{name},年龄是{age},性别是{gender}")
user_info("TOM",20,"男")
关键字传参:函数调用时通过“键=值”形式传递参数,这样可以使函数更加清晰,容易使用,同时也清除了参数的顺序要求
案例
def user_info(naem,age,gender):
print(f"您的名字是{name},年龄是{age},性别是{gender}")
user_info(name="张三",age=56,gender="男")
缺省参数:缺省参数也叫做默认参数,用于定义函数,为参数提供默认参数,调用函数时可不传该默认参数的值(所有位置参数必须出现在默认参数前,包括函数定义和调用),这样当调用函数时没有传入参数,就会使用默认参数对应的值
案例
def user_info(name age,gender="男"):
print(f"您的名字是{name},年龄是{age},性别是{gender}")
user_info("TOM",45)
不定长参数:不定长参数也叫做可变参数,用于不确定调用的时候会传递多少个参数,当调用函数时不确定参数的个数时,可以使用不定长参数,不定长参数类型分为位置传递和关键字传递
案例一:位置传递
def user_info(*args):
print(args)
user_info("TOM")
user_info("TOM",45)
#需要注意。传进去的参数会被args变量收集,他会根据传进的参数的位置合并为一个元组
案例二:关键字传递
def user_info(**kwarges):
print(kwarges)
user_info{name="TOM",age=56,id=1001}
#使用关键字传递参数是以“键=值”形式传参,所有的“键=值”都会被keargs接受,同时组成字典
函数作为参数传递:这是一种,计算逻辑的传递,而非数据的传递。不仅仅是相加,相见、相除、等任何逻辑都可以自行定义并作为函数传入。
案例
def test_fucntion(compute):
result=compute(1,2)
print(result)
def compute(x,y):
return x+y
test_func(compute)
3.匿名函数
在函数定义上存在两个不同的关键字
def关键字:可以定义带有名称的函数
lamda关键字:可以定义匿名函数
有名称的函数,可以基于名称重复使用
无名称的匿名函数,只可以临时使用一次
匿名函数的定义语法:
lambda 传入参数:函数体(一行代码)
传入参数表示匿名函数的形式参数,如x,y表示接受2个形式参数
函数体,就是函数的执行逻辑,只能写一行
案例
def test_func(compute):
result=compute(1,2)
print(result)
#传入一个一次性使用的lambda匿名函数,函数作为参数传递的是计算逻辑
test_func(lambda x,y:x+y)
十三,文件操作
1.文件编码
编码就是一种规则集合,记录了内容和二进制间进行相互转换的逻辑。编码有许多中,我们最常用的是UTF-8编码
2.打开文件
基本语法:open(name,mode,encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):r只读、w写入、a追加等。
encoding:编码格式(推荐使用UTF-8)
#`f`是`open`函数的文件对象,对象是Python中一种特殊的数据类型,拥有属性和方法,可以使用对象.属性或对象.方法对其进行访问,
f=open("D:/123.txt","r",encoding="UTF-8")
常见三种基本访问模式

3.读文件
基本语法:文件对象.read(num)/readlines()
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。返回值为字符串
readlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。同时换行符\n也会被读入
f = open("D:/学习资料/python/123.txt")
content = f.readlines()
print(content)
print(type(content))
f.close()
readline()方法:一次读取一行内容,需注意他会记录上次读取行的位置,再次使用readline()方法会从上次读取的位置开始读取下一行,返回值是字符串
f = open("D:/学习资料/python/123.txt")
content = f.readline()
print(f"第一行{content}")
print(type(content))
content = f.readline()
print(f"第二行{content}")
print(type(content))
f.close()
for循环读取文件行
for line in open("D:/学习资料/python/123.txt", "r"):
print(line)
close() 关闭文件对象,不关闭文件对象,可能会一直占用文件资源
with open 语法,这种方式可以避免使用close()方法,执行完with open中的内容后它会自动关闭文件资源
with open("D:/学习资料/python/123.txt", "r") as f:
print(f.readlines())
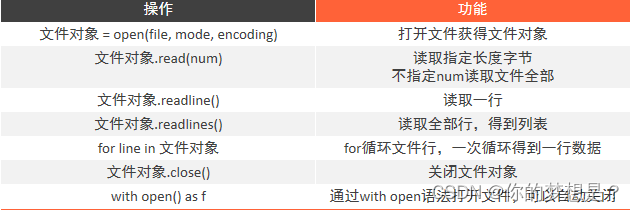
文件的操作汇总
4.文件的写入
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区,调用flush后,内容会真正写入文件,文件如果不存在,使用”w”模式,会创建新文件,文件如果存在,使用”w”模式,会将原有内容清空
# 打开文件
f=open("D:/学习资料/python/123.txt","w")
# 文件的写入
f.write("helloWorld")
# 内容的刷新
f.flush()
f.close()
5.文件的追加,a模式,文件不存在会创建文件,a模式,文件存在会在最后,追加写入文件,可以使用”\n”来写出换行符
#打开文件
f=open("D:/学习资料/python/123.txt","a")
#文件追加写入
f.write("zhangsan")
#内容的刷新
f.flush()
#关闭文件
f.close()
十四,异常,模块,包
1.异常
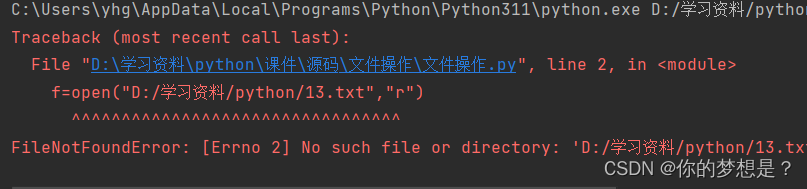
所谓的“异常”, 也就是我们常说的BUG,例如:以r方式打开一个不存在的文件。
f=open("D:/学习资料/python/13.txt","r")
2.异常的捕获方法
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。
"""
基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码
"""
#尝试以`r`模式打开文件,如果文件不存在,则以`w`方式打开。
try:
f = open('linux.txt', 'r')
except:
f = open('linux.txt', 'w')
上面是捕获常规异常,除了这种方式外还可以捕获指定异常,如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。 一般try下方只放一行尝试执行的代码
"""
基本语法:
try:
print(name)
except NameError as e:
print('name变量名称未定义错误')
"""
捕获多个异常:捕获多个异常时,可以把要捕获的异常类型的名字,放到except 后,并使用元组的方式进行书写。如除零异常
try:
print(1/0)
except (NameError, ZeroDivisionError):
print('ZeroDivision错误...')

当捕获到异常时,我们还可以要求输出异常描述信息
try:
print(num)
except (NameError, ZeroDivisionError) as e:
print(e)

除零异常,文件不存在异常都是异常的分支,所以就存在捕获所有异常的方式
try:
print(name)
except Exception as e:
print(e)
异常else:表示的是如果没有异常要执行的代码
try:
print(1)
except Exception as e:
print(e)
else:
print('我是else,是没有异常的时候执行的代码')
异常的finally:表示的是无论是否异常都要执行的代码,例如关闭文件。
try:
f = open('test.txt', 'r')
except Exception as e:
f = open('test.txt', 'w')
else:
print('没有异常,真开心')
finally:
f.close()
3.异常的传递
异常具有传递性,当函数func01中发生异常, 并且没有捕获处理这个异常的时候, 异常会传递到函数func02, 当func02也没有捕获处理这个异常的时候main函数会捕获这个异常, 这就是异常的传递性.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g5eNaP4D-1687933698797)(C:\Users\yhg\AppData\Roaming\Typora\typora-user-images\image-20230626150738278.png)]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuLzZkNGUyYmQ3ZTZhZjQ0ZGE5N2YzMDVmZGIzYjk0MzhhLnBuZw%3D%3D)
4.模块
模块(Module),是一个 Python 文件,以 .py 结尾. 模块能定义函数,类和变量,模块里也能包含可执行的代码.
模块的导入方式:
import 模块名
"""
基本语法
import 模块名
import 模块名1,模块名2
模块名.功能名()
"""
#导入time模块
# 导入时间模块
import time
print("开始")
# 让程序睡眠1秒(阻塞)
time.sleep(1)
print("结束")
from 模块名 import 功能名
"""
基本语法:
from 模块名 import 功能名
功能名()
"""
# 导入时间模块中的sleep方法
from time import sleep
print("开始")
# 让程序睡眠1秒(阻塞)
sleep(1)
print("结束")
from 模块名 import *
"""
from 模块名 import *
功能名()
"""
# 导入时间模块中所有的方法
from time import *
print("开始")
# 让程序睡眠1秒(阻塞)
sleep(1)
print("结束")
as定义别名
"""
# 模块定义别名
import 模块名 as 别名
# 功能定义别名
from 模块名 import 功能 as 别名
"""
# 模块别名
import time as tt
tt.sleep(2)
print('hello')
# 功能别名
from time import sleep as sl
sl(2)
print('hello')
自定义模块:每个Python文件都可以作为一个模块,模块的名字就是文件的名字. 也就是说自定义模块名必须要符合标识符命名规则
__main__,在实际开发中,当一个开发人员编写完一个模块后,开发人员会在模块中添加一些测试方法,此时,无论是当前文件,还是其他已经导入了该模块的文件,在运行的时候都会自动执行测试方法,__main__就是为了解决这个问题
def test(a, b):
print(a + b)
# 只在当前文件中调用该函数,其他导入的文件内不符合该条件,则不执行test函数调用
if __name__ == '__main__':
test (1, 1)
注意:当导入多个模块的时候,且模块内有同名功能. 当调用这个同名功能的时候,调用到的是后面导入的模块的功能
__all__如果一个模块文件中有__all__变量,当使用from xxx import *导入时,只能导入由__all__变量定义的变量或方法
__all__=['testA']
def testA():
print("testA")
def testB():
print("testB")
---------------------
from moudle1 import *
testA()
此时只能使用testA()方法
5.包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个 __init__.py 文件,该文件夹可用于包含多个模块文件
从逻辑上看,包的本质依然是模块,没有__init__.py 文件就不能叫做包,这个文件控制着包的导入行为。
导入包
"""
方式1
import 包名.模块名
包名.模块名.目标
方式二:from 包名 import *
"""
第三方包:在Python程序的生态中,有许多非常多的第三方包(非Python官方),可以极大的帮助我们提高开发效率,如:
科学计算中常用的:numpy包
数据分析中常用的:pandas包
大数据计算中常用的:pyspark、apache-flink包
图形可视化常用的:matplotlib、pyecharts
人工智能常用的:tensorflow
PyCharm也提供了安装第三方包的功能:
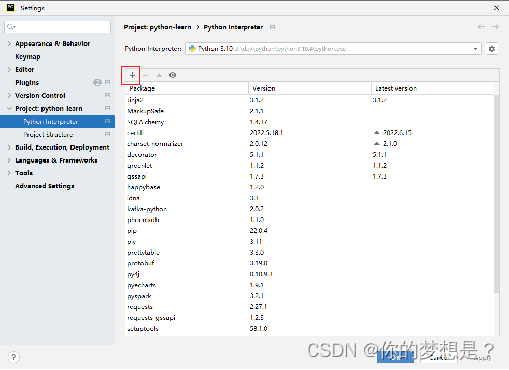
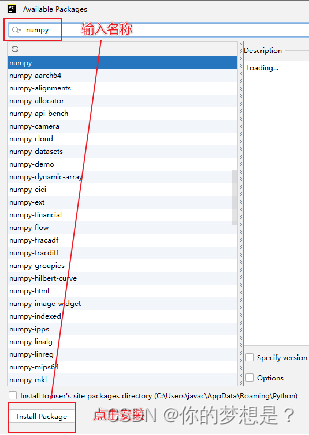
十五,面向对象
1.初始对象
我们发现在编写程序过程中使用变量记录数据太乱了,程序也可以和生活一样可以设计表格,打印表格,填写表格一样
在程序中设计表格:也就是称作设计类(class)
class Student:
name=none #记录学生的姓名
在程序中打印表格:也就是称作创建对象
#基于类创建对象
stu_1=Student()
stu_2=Student()
在程序中填写表格,也就是称作为对象属性赋值
stu_1.name="zhangsan"
stu_2.name="李四"
2.类的定义
基本语法
class:
类的属性 #类的属性即定义在类中的变量
类的行为 #类的行为即定义在类中函数,也称做方法,注意写在类外面的函数不能叫方法
#创建类对象的语法
对象.类名称()
案例
class Student:
name=none
age=none
#定义方法,与传统函数定义不同,参数中必须要写self关键 #字,表示自身的意思,在方法内部访问类成员的变量,必须也 #要使用self.成员变量,在传参的过程中不用理会self,它是 #透明的
def say_hi(self):
print(f"helloworld,我是(self.name)")
#新建类对象
stu=Student()
#为类属性赋值
stu.name="张三"
#调用类方法
stu.say_hi()
3.类和对象
现实世界的事物可以归纳为类和属性
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6leB5uLz-1687933698798)(D:\学习资料\python\课件\截图\现实事物.png)]
在程序中创建对象的语法:对象名=类名称(),类是程序中的”设计图纸“,要基于图纸的对象才能正常完成工作,这种模式称之为:面向对象编程。如闹钟的生产:
#设计闹钟
class Clock:
#设计属性
id=None
price=None
#设计响铃行为
def ring(self):
import winsound
winsound.Beep(2000,3000)
#基于类创建对象
clock1=Clock()
clock1.id=1001
clock1.price=19.00
print("闹钟id是{clock1.id},价格是{clock1.price}")
clock1.ring()
#基于类创建对象
clock2=Clock()
clock2.id=1001
clock2.price=19.00
print("闹钟id是{clock2.id},价格是{clock2.price}")
clock2.ring()
4.构造方法
在前面创建对象及为对象属性赋值都是使用的对象变量=类()和对象变量.属性=字面量,这种方式显得繁琐,为了简化过程,可以使用构造方法为对象属性赋值。——init()——被称为构造方法,在创建类对象时,会将参数自动传递给构造方法构造使用且执行
class Student:
#这一部分可以省略,构造方法会根据参数申明成员变量并赋值
name=None
age=None
tel=None
def __init__(self,name,age,tel):
self.name=name
self.age=age
self.tel=tel
print("student类创建了一个类对象")
stu=Student("zhangsan",15,111110)
5.其它内置方法
——init()——构造方法是类内置方法,除此之外还有其它类内置方法
——str()——字符串方法,在定义好类对象后,直接print类对象输出的是类对象的存放地址,内存地址并没什么多大用处,通过这个方法可以控制类转换为自定义的字符串,使直接print类对象输出自定义的字符串
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
#定义__str()__方法
def __str()__(self):
return f"student类对象,name={self.name},age={self.age}"
student=Student("zhangsna",21)
print(student) #结果:student类对象,name=zhangsna,age=21
print(str(student)) #结果:student类对象,name=zhangsna,age=21
——lt——小于符号比较方法,由于对象中的属性太多,无法直接进行比较,通过——lt——()方法可以自定义对象之间通过比较什么属性来决定大小,注意只能实现大于和小于两种比较,返回值为True或者False
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __lt__(self,other):
return self.age<other.age
stu1=student("张三",11)
stu2=student("李四",25)
print(stu1<stu2) 结果:True
print(stu1>stu2) 结果:False
——le——大于等于比较符号方法,与——lt——方法类似,只不过比较符号不相同而已
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __le__(self,other):
return self.age<=other.age
stu1=student("张三",11)
stu2=student("李四",25)
print(stu1<=stu2) 结果:True
print(stu1>=stu2) 结果:False
——eq——相等比较方法,它与——lt——和——le——方法一样都是定义对象比较方法,不过——eq——是判断是否相等,相等返回True,否则False
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __eq__(self,other):
return self.age==other.age
stu1=student("张三",11)
stu2=student("李四",25)
print(stu1==stu2) 结果:True
print(stu1==stu2) 结果:False
类内置方法总结

6.封装的概念
将现实世界中事物在类中描述为属性和方法
对于不愿意公开的属性和行为可以定义为私有属性 ,被定义私有属性后不能够被直接使用,但是可以被我们类中其它成员使用
私有成员的意义:仅供内部使用,不对外开发
#私有成员变量:__变量名
#私有成员方法:__方法名
class Phone:
IMEI=None #序列号
price=None #价格
__current_voltage=None #私有成员变量,当前电压
#私有成员方法
def __keep_single_core(self):
print("单核模式运行")
def call_by_5g(self):
if self.__current_voltage>=1:
print("开启5G")
else:
__keep_single_core()
print("电量不足,不能开启5G")
phone=Phone("1001",10)
phone.call_by_5g()
7.继承
在现实生活中手机的版本更新都是基于旧版本之上的修改,在编程过程中同样存在着程序的更新,也是基于之前旧版版本的修改,如手机类中有手机序列号属性,版本更新了面部识别属性,在新类中重新定义序列号属性就显得麻烦,为了解决这个问题,就需要使用到继承
单继承基本语法:
class 类名(父类):
子类新添加的内容
案例
#单继承 继承表示从父类那里继承(复制)成员变量和成员方法
class Phone:
IMEI=None #序列号
producer="HM" #厂商
def call_by_4g(self):
print("4g通话")
class Phone2022(Phone):
face_id=True #面部识别
def call_by_5g(self):
print("2022最新5g通话")
phone=Phone2022()
print(phone.producer)
phone.call_by_4g()
phone.call_by_5g()
多继承基本语法:
class 类名(父类1,父类2,...,父类N):
子类新添加的内容
案例
#手机基本信息
class Phone:
IMEI=None #序列号
producer="HM" #厂商
def call_by_5g(self):
print("5g通话")
#NFC读卡
class NFCReader:
nfc_type="第五代"
producer="HM"
def read_card(self):
print("读取NFC")
def write_card(self):
print("写入NFC")
#红外遥控
class RemoteControl:
rc_type="红外遥控"
def control(self):
print("红外遥控开启")
#我的手机
class MyPhone(Phone,NFCReader,RemoteControl):
pass #pass关键字用于子类继承后不想添加新内容,但语法有要求写些什么的替代
phone=MyPhone()
phone.call_by_5g()
phone.read_card()
phone.write_card()
phone.control()
print(phone.producer) #在输出同名属性时,继承在前面的被输出
8.复写父类方法
子类在继承父类的成员属性和成员方法后,如果对其不满意,可以进行复写,在子类中中重新定义同名的属性或方法即可
案例
class Phone:
IMEI=None #序列号
producer="HM" #厂商
def call_by_5g(self):
print("5g通话")
class MyPhone(Phone):
producer="HW"
def call_by_5g():
print("子类复写的5g通话")
phone=MyPhone()
phone.call_by_5g()
print(phone.producer)
#如果在子类中有特殊要求需要调用被复写的父类变量或父类方法
"""
方式1:父类名.成员变量
父类名.成员方法(self)
方式2:super().成员变量
super().成员方法()
"""
9.类型注解
在python3.5版本引入了类型注解,以方便静态类型检查工具,IDE等第三方工具,帮助第三方工具对代码进行类型推断,协助做代码提示,支持变量的类型注解函数(方法)参数列表或返回值的类型注解,基本语法:变量:类型
案例
#基础数据类型注解
var_1:int=10
var_2:float=3.1415926
var_1:str=abc
#类对象类型注解
class Student:
pass
stu:Student=Student()
#基础数据容器类型注解
my_list:list=[1.2,3]
my_tuple:tuple=(1,2,3)
my_set:set={1,2,3}
my_dict:dict={"zhangsan":20}
#基础容器类型详细注解,元组类型设置详细注解,需要将每一个元素都标记出来,字典类型设置类型详细注解,需要2个类型,第一个时key,第二个时value
my_list:list[int]=[1,2,3]
my_tuple:tuple[int]=(1,2,3)
my_set:set[int]={1,2,3}
my_dict:dict[str,int]={"zhangsan":20}
#函数(方法)的类型注解 基本语法:
"""
def 函数(方法)名(形参名:类型,形参名:类型):
pass
"""
def add(x:int,y:int):
return x+y
def func(data:list):
pass
#函数 (方法)返回值添加注解
"""
基本语法:
def 函数(方法)名(形参名:类型,形参名:类型)->返回值类型:
pass
"""
一般,无法直接看出变量类型之时会添加变量的类型注解
Union类型 ,对于混合类型字典或集合一般不好直接添加类型注解,这时就需要使用Union类型添加混合类型注解
"""
基本语法:Union[类型,类型...]
"""
#使用Union类型需要导入相关包
from typing import Union
my_list:list[Union[str,int]]=[1,2,"zhangsan"]
my_dict:dict[str,Union[str,int]]={"name":"zhangsan","age":23}
def func(data:Union[int,str])->Union[int,str]:
pass
10.多态
多态指完成某个行为时,使用不同的对象会得到不同状态
多态常用在继承关系上
比如:函数(方法)形参声明接受父类对象,而实际传入的父类的子类对象进行工作,即以父类做定义声明,以子类做实际工作,用以获得同一行为,不同状态
案例
class Animal:
def speak(self):
pass
class Dog(Animal):
def speak(self):
print("汪汪汪")
class Cat(Animal):
def speak(self):
print("喵喵喵")
def make_noise(animal:Animal):
animal.speak()
dog=Dog()
cat=Cat()
make_noise(dog)
make_noise(cat)
多态还应用于抽象类(接口),抽象类:含有抽象方法的类称之为抽象类,抽象方法:方法体是空实现的(pass)称之为抽象方法。举一个很现实的例子,空调制造标准需要制冷,制热,摆风,但是对于不同的生产厂商拥有自己核心制造技术。第一层的空调制造标准并不提供核心技术,在编程就等同于提供空实现方法,而每个厂商都拥有自己的核心制造技术就等同于子类来通过不同内容实现父类方法。
"""
抽象类+多态完成
抽象的父类设计
具体的子类来实现
"""
#定义空调标准
class AC:
#制冷
def cool_wind(self):
pass
#制热
def hot_wind(self):
pass
#摆风
def swing(self):
pass
#美的生产厂商
class Midea_AC(AC):
def cool_wind(self):
print("美的核心制冷技术")
def hot_wind(self):
print("美的核心制热技术")
def swing(self):
print("美的核心摆风技术")
#格力生产厂商
class GEREE_AC(AC):
def cool_wind(self):
print("格力核心制冷技术")
def hot_wind(self):
print("格力核心制热技术")
def swing(self):
print("格力核心摆风技术")
def make_cool(ac:AC):
ac.cool_wind()
midea=Midea_AC()
geree=GEREE_AC()
make_cool(midea)
make_cool(geree)
十六,高阶技巧
1.闭包
在开发过程中,如银行程序开发,常常面临着安全问题,如用户余额值定义为全局变量存在着被篡改的危险,但定义为局部变量面临着用户存款或者取款余额不变的问题,闭包就能很好的解决这类问题
"""
在函数嵌套的前提下,内部函数使用了外部函数的变量,
并且外部函数返回了内部函数,我们把这个使用外部函
数变量的内部函数称为闭包。
"""
#外部函数
def outer(logo):
#内部函数
def inner(msg):
print(f"<{msg}><{logo}><{msg}>")
#返回内部函数
return inner
#定义fn1变量为inner函数,
# 同时对于inner函数"logo"变量为"张三",该值很能直接被修改
fn1=outer("张三")
#李四为msg的参数
fn1("李四")
如果要在内部函数中修改外部函数的变量的值需要在内部函数中使用nonlocal关键字
def outer(num1):
def inner(num2):
nonlocal num1
num1+=num2
print(num1)
return inner
fn=outer(10)
fn(10)
fn(10)
使用闭包的优点:无需定义全局变量即可实现通过函数,持续的访问、修改某个值。闭包使用的变量的所用于在函数内,难以被错误的调用修改
闭包的缺点:由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放,一直占用内存
2.装饰器
装饰器其实也是一种闭包, 其功能就是在不破坏目标函数原有的代码和功能的前提下,为目标函数增加新功能。
"""
定义一个闭包函数, 在闭包函数内部:
执行目标函数
并完成功能的添加
"""
import random
import time
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我起床了")
return inner
def sleep():
print("睡眠中")
time.sleep(random.randint(1,5))
fn=outer(sleep)
fn()
装饰器的注释写法,这种方式简化了代码,注意两者的区别,后者直接调用目标函数,不需要再声明目标函数是外部函数的添加功能。
"""
使用@outer
定义在目标函数sleep之上
"""
import random
import time
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我起床了")
return inner
@outer
def sleep():
print("睡眠中")
time.sleep(random.randint(1,5))
sleep()
3.单例模式
创建类的实例后,就可以得到一个完整的、独立的类对象。
它们的内存地址是不相同的,即两个完全独立的对象。某些场景下, 我们需要一个类无论获取多少次类对象,都仅仅提供一个具体的实例
定义: 保证一个类只有一个实例,并提供一个访问它的全局访问点
适用场景:当一个类只能有一个实例,而客户可以从一个众所周知的访问点访问它时。
#在一个文件中定义一个类对象
class StrTools:
pass
#定义了一个类对象
str_tool=StrTools()
-----------------------
#在另一个文件中导入第一个文件中类对象
from 单例模式 import str_tool
s1=str_tool
s2=str_tool
print(s1)
print(s2)
#此时s1和s2的地址是一样的,说明就是同一个对象
优点:节省内存,节省创建对象的开销
4.工厂模式
需要大量创建一个类的实例的时候, 可以使用工厂模式。
即,从原生的使用类的构造去创建对象的形式迁移到,基于工厂提供的方法去创建对象的形式。
"""
使用工厂类的get_person()方法去创建具体的类对象
优点:
大批量创建对象的时候有统一的入口,易于代码维护
当发生修改,仅修改工厂类的创建方法即可
符合现实世界的模式,即由工厂来制作产品(对象)
"""
class Person:
pass
class Worker(Person):
pass
class Teacher(Person):
pass
class Student(Person):
pass
#定义工厂类
class Factory:
def getperson(self,p_type):
if p_type=='w':
return Worker()
elif p_type=='s':
return Student()
else:
return Teacher()
factory=Factory()
worker=factory.getperson('w')
student=factory.getperson('s')
teacher=factory.getperson('t')
5.多线程
进程: 就是一个程序,运行在系统之上,那么便称之这个程序为一个运行进程,并分配进程ID方便系统管理。
线程:线程是归属于进程的,一个进程可以开启多个线程,执行不同的工作,是进程的实际工作最小单位。
进程之间是内存隔离的, 即不同的进程拥有各自的内存空间。 这就类似于不同的公司拥有不同的办公场所。
线程之间是内存共享的,线程是属于进程的,一个进程内的多个线程之间是共享这个进程所拥有的内存空间的。
进程和线程都可以并行执行
Python的多线程可以通过threading模块来实现。
import threading
"""
thread_obj=threading.Thread([group[,target[,name[,arg[,args[,kwargs]]]]])
group:无意义,未来功能预留参数
target:执行的目标任务名
args:以元组的方式给执行任务传参
kwargs:以字典的方式给任务传参
name:线程名,一般不用设置
启动线程
thread_obj.start()
"""
def sleep():
while True:
print("我在睡觉,zzzz")
def sing():
while True:
print("我在唱歌,啦啦啦啦")
sing_thread=threading.Thread(target=sing)
sleep_thread=threading.Thread(target=sleep)
sleep_thread.start()
sing_thread.start()
带参数的线程启动
import threading
def dance(msg):
while True:
print(msg)
#args通过元组传参
dance_thred=threading.Thread(target=dance,args=("我在跳舞,哈哈哈哈",))
dance_thred.start()
#kwarges通过字典传参
dance_thread=threading.Thread(target=dance,kwargs={"msg":"我想跳舞"})
dance_thread.start()
6.网络编程
socket (简称 套接字) 是进程之间通信一个工具,负责进程之间的网络数据传输。
Socket服务端:等待其它进程的连接、可接受发来的消息、可以回复消息
Socket客户端:主动连接服务端、可以发送消息、可以接收回复
服务端
"""
主要分为如下几个步骤:
1. 创建socket对象
2. 绑定socket_server到指定IP和地址
3. 服务端开始监听端口
4. 接收客户端连接,获得连接对象
5. 客户端连接后,通过recv方法,接收客户端发送的消息
6. 通过conn(客户端当次连接对象),调用send方法可以回复消息
7. conn(客户端当次连接对象)和socket_server对象调用close方法,关闭连接
"""
import socket
# 创建socket对象
socket_server = socket.socket()
# 绑定socket_server到指定IP和地址,bind(IP地址,端口号)
socket_server.bind(("192.168.50.196", 8888))
# 服务端开始监听端口linsten()中传入允许连接的数量,不填会默认设置一个合理值
socket_server.listen(1)
# 接收客户端连接,获得连接对象
conn, address = socket_server.accept()
#accept()方法是阻塞方法,会一直等待执行,需传入缓冲区大小
print(f"接受到客户端连接,来自:{address}")
#客户端连接后,通过recv方法,接收客户端发送的消息
while True:
data=conn.recv(1024).decode("UTF-8")
#recv()方法是阻塞方法,会一直等待执行,需传入缓冲区大小
if data=='exit':
break
print(f"接受客户端发来的的数据{data}")
#通过conn(客户端当次连接对象),调用send方法可以回复消息
conn.send(input("请输入要发送的数据").encode("UTF-8"))
#conn(客户端当次连接对象)和socket_server对象调用close方法,关闭连接
conn.close()
socket_server.close()
客户端
"""
主要分为如下几个步骤:
1. 创建socket对象
2. 连接到服务端
3. 发送消息
4. 接收返回消息
5. 关闭链接
"""
import socket
#创建socket对象
socket_client=socket.socket()
#连接到服务端
socket_client.connect(("192.168.50.196",8888))
#发送消息
while True:
send_msg=input("要发送的消息")
if send_msg=='exit':
break
socket_client.send(send_msg.encode("UTF-8"))
#接收返回消息
recv_data=socket_client.recv(1024).decode("UTF-8")
#recv()方法是阻塞方法,会一直等待执行,需传入缓冲区大小
print(f"服务端返回的数据{recv_data}")
#关闭链接
socket_client.close()
7.正则表达式
正则表达式,又称规则表达式(Regular Expression),是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索、替换那些符合某个模式(规则)的文本。
1.re.match(匹配规则, 被匹配字符串)
从被匹配字符串开头进行匹配, 匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空。
import re
s='zhangsan lisi wanger zhaoliu tangyi'
result=re.match('zhangsan',s)
print(result) #<re.Match object; span=(0, 8), match='zhangsan'>
print(result.span()) #(0, 8)
print(result.group()) #zhangsan
result1=re.match('lisi',s)
print(result1) #None
2.search(匹配规则, 被匹配字符串)
全局匹配,搜索整个字符串,找出匹配的。从前向后,找到第一个后,就停止,不会继续向后
import re
s='1zhangsan5555lisi565'
result=re.search('zhangsan',s)
print(result) #<re.Match object; span=(1, 9), match='zhangsan'>
print(result.span()) #(1, 9)
print(result.group()) #zhangsan
result2=re.search('python',s)
print(result2) #None
3.findall(匹配规则, 被匹配字符串)
全局匹配,匹配整个字符串,找出全部匹配项,返回类型为list集合类型
import re
s='1zhangsan66666lisi78787zhangsan999zhangsan'
result=re.findall('zhangsan',s)
print(result)
print(type(result))
4.元字符匹配
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CigXK1AZ-1687933698799)(D:\学习资料\python\课件\截图\元字符匹配.png)]
import re
s='zhangsan9090@#@lisizhangsan'
#找出全部非单词字符
result=re.findall(r'\W',s)
print(result)
print(type(result))
#找出全部英文字母
result1=re.findall(r'[a-zA-Z]',s)
print(result1)
[]内可以写:[a-zA-Z0-9] 这三种范围组合或指定单个字符如[aceDFG135]
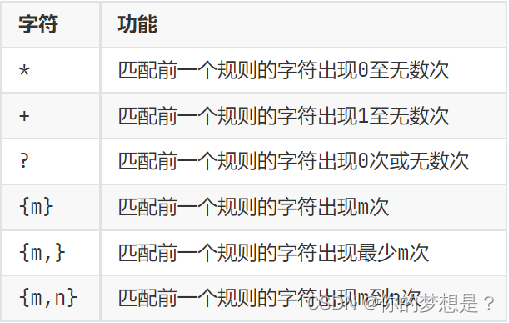
数量匹配
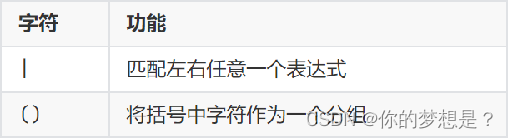
边界匹配

分组匹配
8.递归
递归在编程中是一种非常重要的算法
递归: 即方法(函数)自己调用自己的一种特殊编程写法
"""
def func()
if...:
func()
return ...
"""
注意退出的条件,否则容易变成无限递归
注意返回值的传递,确保从最内层,层层传递到最外层
os模块的3个方法
os.listdir,列出指定目录下的内容
os.path.isdir,判断给定路径是否是文件夹,是返回True,否返回False
os.path.exists,判断给定路径是否存在,存在返回True,否则返回False
十七,pymysql基础
数据定义:DDL(Data Definition Language)
库的创建删除、表的创建删除等
数据操纵:DML(Data Manipulation Language)
新增数据、删除数据、修改数据等
数据控制:DCL(Data Control Language)
新增用户、删除用户、密码修改、权限管理等
数据查询:DQL(Data Query Language)
基于需求查询和计算数据
1.DDL


2.DML



3.DQL



4.pymysql
首先安装pymysql第三方库
pip install pymysql
连接到mysql数据库
from pymysql import Connection
#获取到mySQL数据库的连接对象
conn=Connection(
host='localhost',
port=3306,
user='root',
password='123456'
)
#打印MySQL数据库软件信息
print(conn.get_server_info())
#关闭连接
conn.close()
使用pymysql创建表
#导入第三方包
from pymysql import Connection
#获取sql连接对象
conn=Connection(
host='localhost',
port=3306,
user='root',
password='123456'
)
#获取游标对象
cursor=conn.cursor()
#选择要使用的数据库
conn.select_db("test")
#使用游标对象执行sql语句
cursor.execute("create table test_py_mysql(id int,info varchar(255))")
#关闭数据库连接
conn.close()
插入数据
#导入第三方包
from pymysql import Connection
#获取sql连接对象
conn=Connection(
host='localhost',
port=3306,
user='root',
password='123456',
autocommit=True #设置自动提交
)
#获取游标对象
cursor=conn.cursor()
#选择要使用的数据库
conn.select_db("test")
#使用游标对象执行sql语句
cursor.execute("insert into user values ('周杰轮',23,'123456','男')")
#在执行sql数据插入或其它生产数据更改的sql语句时,需要通过提交才能完成更改行为
#提交修改
conn.commit()
#关闭数据库连接
conn.close()
十八,pyspark基础
什么是spark?
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据
pyspark的编程模型
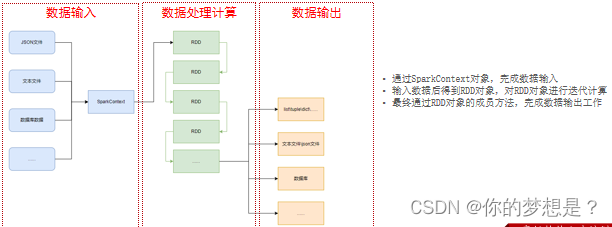
模型归纳为:
准备数据到RDD -> RDD迭代计算 -> RDD导出为list、文本文件等
即:源数据 -> RDD -> 结果数据
数据输入
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)PySpark针对数据的处理,都是以RDD对象作为载体,即:数据存储在RDD内,各类数据的计算方法,也都是RDD的成员方法
pyspark支持通过SparkContext对象的parallelize成员方法将python数据容器转换为RDD对象
#导入第三方包
from pyspark import SparkConf,SparkContext
#获取Spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
#基于Spark类对象获取SparkContext对象
sc=SparkContext(conf=conf)
#进行数据容器转换
list=[1,2,3,4,5,6,7,8]
#parallelize()方法中传入数据容器对象,返回值是list
rdd=sc.parallelize(list)
#输出rdd内容
print(rdd.collect())
#关闭PySpark程序
sc.stop()
将文件转换问rdd对象
#导入第三方包
from pyspark import SparkConf,SparkContext
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
#通过conf类对象获取sparkContext对象
sc=SparkContext(conf=conf)
#将文件转换为rdd,textFile()方法中传入文件路径,返回值是列表
rdd=sc.textFile("D:/学习资料/python/123.txt")
#打印rdd对象
print(rdd.collect())
#关闭PySpark程序
sc.stop()
RDD内置方法(算子)
map方法:将rdd的数据一条条处理,处理逻辑是基于map算子中接受的处理函数,返回新的rdd对象,注意使用rdd内置方法需要配置Spark读取到python解释器,否则就无法使用rdd内置方法
"""
map(func)
func:f:(T)->U
(T)->(U)表示传入一个任意参数,返回一个任意参数
拓展
(A)->(A)表示传入一个参数,返回一个与传入参数类型一致的参数
""""""
map(func)
func:f:(T)->U
(T)->(U)表示传入一个任意参数,返回一个任意参数
拓展
(A)->(A)表示传入一个参数,返回一个与传入参数类型一致的参数
"""
#导入第三方包
from pyspark import SparkConf,SparkContext
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#测试
if __name__=="__main__":
#获取Spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SprkContext对象
sc=SparkContext(conf=conf)
#设置rdd对象
rdd=sc.parallelize([1,2,3,4,5])
#定义需要作为参数的方法 还可以使用lamba匿名函数定义
def map_func(data):
return data*10
#输出map算子处理后的结果
print(rdd.map(map_func).collect())
#关闭spark程序
sc.stop()
flatMap算子:对rdd执行map操作,然后进行解除嵌套操作,它比map算子多了一个解除嵌套的功能,解除的方向是从内向外
#导入第三方包
from pyspark import SparkConf,SparkContext
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SparkContext对象
sc=SparkContext(conf=conf)
#设置rdd对象
rdd=sc.parallelize(["a b c","e f g","h i j"])
#按照空格切分数据后,解除嵌套
print(rdd.flatMap(lambda x:x.split(" ")).collect())
#关闭spark程序
sc.stop()
reductBykey算子,争对KV型rdd,自动按照key分组,然后更具提供的聚合逻辑,完成组内的数据的聚合操作
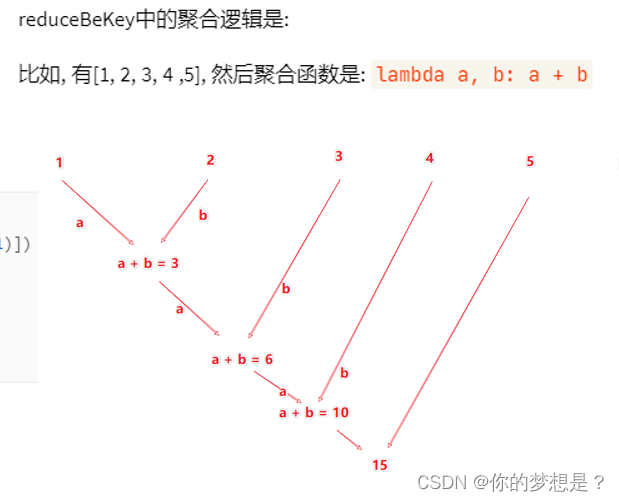
"""
rdd.reduceByKey(func)
#func:(V,V)->V
#接受2个传入参数(类型要一致),返回一个返回值,类型和传入要求一致
reduceByKey中接受的函数只负责聚合,不负责分组,分组是自动by Key来分组的
"""
#导入第三方包
from pyspark import SparkConf,SparkContext
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SparkContext对象
sc=SparkContext(conf=conf)
#设置rdd对象
rdd=sc.parallelize([('a',1),('a',1),('b',1),('b',1),('a',1)])
#reduceByKey()算子处理rdd
result=rdd.reduceByKey(lambda a,b:a+b)
#输出处理结果
print(result.collect())
#关闭spark程序
sc.stop()
filter算子,过滤想要的数据进行保留
"""
rdd.filter(func)
func:(T)->bool
传入一个任意类型的参数,返回值为False或者True
"""
#导入第三方包
from pyspark import SparkConf,SparkContext
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SparkContext对象
sc=SparkContext(conf=conf)
#获取rdd对象
rdd=sc.parallelize([1,2,3,4,5])
#使用filter方法保留奇数
print(rdd.filter(lambda x:x%2==1).collect())
#关闭spark程序
sc.stop()
distict算子:对rdd数据进行去重返回新的rdd
"""
语法:rdd.distinct() 无需传参
"""
#导入第三方包
from pyspark import SparkConf,SparkContext
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SparkContext对象
sc=SparkContext(conf=conf)
#获取rdd对象
rdd=sc.parallelize([1,2,3,2,3,1,3,2,1])
#对rdd对象进行去重操作
print(rdd.distinct().collect())
#关闭spark程序
sc.stop()
sortBy算子:对rdd数据进行排序,基于自定义的排序依据
rdd.sortBy(func,ascending=False,numPartitons=1)
"""
func:(T)->U 告知按照rdd中的哪个数据进行排序
ascending True表示升序
nunPatition 表示用多少分区排序
"""
数据输出
collect算子:将rdd对象各个分区内的数据,统一收集到Driver,形成一个list集合对象
用法:rdd.collect()
reduce算子:对rdd数据集按照自定义的逻辑进行聚合,聚合模式
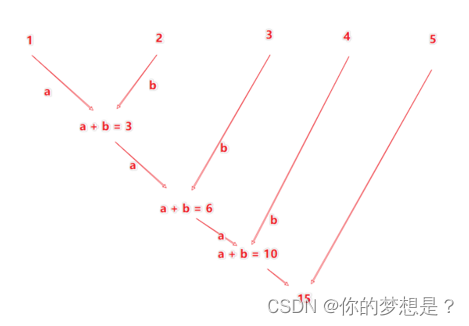
"""
rdd.reduce(func)
func:(T,T)->T
2个参数传入,1个返回值,返回值的参数要求和传入的参数保持一致
"""
#导入第三方包
from pyspark import SparkConf,SparkContext
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SparkContext对象
sc=SparkContext(conf=conf)
#获取rdd对象
rdd=sc.parallelize(range(1,10))
#将rdd数据进行累加求和
print(rdd.reduce(lambda a,b:a+b))
take算子:将rdd的前N个元素组成list返回
#导入第三方包
from pyspark import SparkConf,SparkContext
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SparkContext对象
sc=SparkContext(conf=conf)
#获取rdd对象
rdd=sc.parallelize([3,2,1,5,7,8])
#返回前4个数据
print(rdd.take(4))
count算子:计算rdd中有多少个算子
#导入第三方包
from pyspark import SparkConf,SparkContext
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SparkContext对象
sc=SparkContext(conf=conf)
#获取rdd对象
rdd=sc.parallelize([3,2,1,4,5,6])
#返回rdd对象中有多少个数据
print(rdd.count())
数据输出和数据输入一样有两种方式,不但可以直接打印输出,还可以将数据保存到文件中
saveAsTextFile算子:将rdd中的数据写入文本文件中,支持本地写出,hdfs等文件系统,注意:将rdd中的数据写入到文件中时需要安装hadoopx相关依赖,否则会报错
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jrJQ76wX-1687933698803)(D:\学习资料\python\课件\截图\注意事项.png)]
修改rdd分区
"""
修改rdd分区的方式有两种,
方式1:SparkConf().setMaster("local[*]").setAppName("test_spark")
设置默认分区为1个
conf.set("spark.default.parallelism","1")
方式2:创建rdd的时候设置(parallelize方法传入numSlices参数为1)
rdd=sc.parallelize([1,2,3,4],numSlice=1)
"""
十九,数据可视化基础
JSON:JSON是一种轻量级的数据交互格式。可以按照JSON指定的格式去组织和封装数据
JSON本质上是一个带有特定格式的字符串
安装pyspark第三方库
pip install pyspark或pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
获取PySpark执行环境入口对象,注意PySpark需要安装jdk才能使用
#导入第三方包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
#基于SparkConf类对象创建SparkContext类对象
sc=SparkContext(conf=conf)
#打印pyspark的运行版本
print(sc.version)
#关闭PySpark程序
sc.stop()
1.JSON数据格式
# json数据的格式可以是:
{"name":"admin","age":18}
# 也可以是:
[{"name":"admin","age":18},{"name":"root","age":16},{"name":"张三","age":20}]
# 导入json模块
import json
# 准备符合格式json格式要求的python数据
data = [{"name": "老王", "age": 16}, {"name": "张三", "age": 20}]
# 通过 json.dumps(data) 方法把python数据转化为了 json数据
data = json.dumps(data,ensure_ascii=False)
#ensure_ascii=False表明不使用ascii码转换
print(data)
print(type(data))
# 通过 json.loads(data) 方法把json数据转化为了 python数据
data1 = json.loads(data)
print(data1)
print(type(data))
2.pyecharts模块
Echarts 是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可. 而 Python 是门富有表达力的语言,很适合用于数据处理.
要使用pyecharts模块首先需要导入第三方包,
基础折线图
#导入折线图功能
from pyecharts.charts import Line
#得到折线图对象
line=Line()
#添加x轴数据
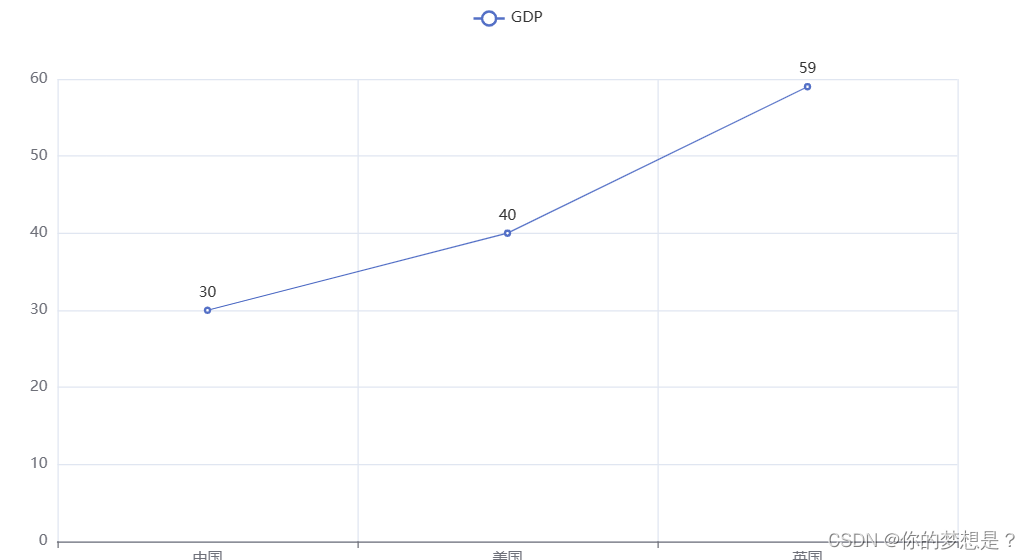
line.add_xaxis(["中国","美国","英国"])
#添加y轴数据
line.add_yaxis("GDP",[30,40,59])
#生成图标,注意它会生成一个前端页面
line.render("折线图.html")
set_global_opts全局配置方法
#导入折线图功能
from pyecharts.charts import Line
#使用全局设置需要导入相关包
from pyecharts.options import *
#得到折线图对象
line=Line()
#全局配置,全局设置过程中各个属性的设置需要用逗号隔开
line.set_global_opts(
#配置图表标题
title_opts=TitleOpts(title="测试",pos_left="center",pos_bottom="1%"),
#设置图例配置表
legend_opts=LegendOpts(is_show=True),
#工具箱配置表
toolbox_opts=ToolboxOpts(is_show=True),
#视觉映射配置项
visualmap_opts=VisualMapOpts(is_show=True),
#提示框配置项
tooltip_opts=TooltipOpts(is_show=True)
)
#添加x轴数据
line.add_xaxis(["中国","美国","英国"])
#添加y轴数据
line.add_yaxis("GDP",[30,40,59])
#生成图标,注意它会生成一个前端页面
line.render("折线图.html")
数据处理
网上下载过来的数据有些不符合JSON格式规范,我们就需要将他进行数据处理,转换为JSON格式的数据
#导入json模块
import json
#打开要处理的数据文件
f=open("D:/学习资料/python/课件/课件/资料/资料/可视化案例数据/折线图数据/美国.txt","r",encoding="UTF-8")
data=f.readlines()
print(data)
# 把不符合json数据格式的 "jsonp_1629350871167_29498(" 去掉
data = data.replace("jsonp_1629350871167_29498(")
# 把不符合json数据格式的 ");" 去掉
data = data[:-2]
# 数据格式符合json格式后,对数据进行转化
data = json.loads(data)
# 获取美国的疫情数据
data = data["data"][0]['trend’]
# x1_data存放日期数据
x1_data = data['updateDate’]
# y1_data存放人数数据
y1_data = data['list'][0]["data"]
# 获取2020年的数据
x1_data = data['updateDate'][:314]
# 获取2020年的数据
y1_data = data['list'][0]["data"][:314]
基本地图
# 导入第三方包
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
# 获取map对象
map = Map()
# 设置数据,这些地区名称必须要按照地图显示的设置,否则地图上会没有数据,而且数据必须元组
data = [
("北京市",99),
("上海市", 156),
("湖南省", 589),
("台湾省", 778),
("安徽省", 899),
("广州省", 1089),
("湖北省", 9)
]
map.add("地图", data, "china")
#设置视觉映射器
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min":1,"max":9,"label":"1-9","color":"#CCFFFF"},
{"min":10,"max":99,"label":"10-99","color":"#FFFF99"},
{"min":99,"max":499,"label":"99-499","color":"#FF9966"},
{"min":500,"max":999,"label":"500-999","color":"#FF6666"},
{"min":1000,"max":9999,"label":"1000-9999","color":"#CC3333"}
]
)
)
# 生成地图
map.render("基本地图.html")
基本柱状图
#导入柱状图
from pyecharts.charts import Bar
from pyecharts.options import *
#新建柱状图
bar=Bar()
#添加数据
bar.add_xaxis(["中国","美国","英国"])
bar.add_yaxis(
"GDP",[20,30,10],
#设置数值标签在右侧
label_opts=LabelOpts(
position="right"
)
)
#反转xy轴
bar.reversal_axis()
#生成图表
bar.render("基本柱状图.html")
时间线-Timeline():建一个
一维的x轴,轴上每一个点就是一个图表对象
二十,课后练习案例
pymysql综合案例
读取1月和2月数据集并且存储到数据库中
#数据处理文件
#导入json
import json
#读取文件
f=open("D:/学习资料/python/课件/课件/第13章资料/2011年1月销售数据.txt","r",encoding="UTF-8")
pydata=f.readlines()
f1=open("D:/学习资料/python/课件/课件/第13章资料/2011年2月销售数据JSON.txt","r",encoding="UTF-8")
data1=f1.readlines()
——————————————————————————————————————————————————
#导入pymysql第三方包
from pymysql import Connection
#导入处理过后的数据集
import 销售数据处理文件 as data
#导入json
import json
#获取连接对象
conn=Connection(
host='localhost',
port=3306,
user='root',
password='123456',
autocommit=True
)
#获取游标对象
cusor=conn.cursor()
#选择数据库
conn.select_db("test")
#执行sql语句
# cusor.execute("create table sale_data(year varchar(255),order_id varchar(255),sum int,location varchar(255))")
for str in data.pydata:
year=str.split(",")[0]
order_id=str.split(",")[1]
sum=int(str.split(",")[2])
location=str.split(",")[3]
cusor.execute(f"insert sale_data values('{year}','{order_id}',{sum},'{location}')")
for dict in data.data1:
singal_data=json.loads(dict.strip("\n"))
year=singal_data["date"]
order_id=singal_data["order_id"]
sum=int(singal_data["money"])
location=singal_data["province"]
cusor.execute(f"insert sale_data values('{year}','{order_id}',{sum},'{location}')")
#关闭连接
conn.close()
pyspark案例
1.使用学习到的内容,完成:读取文件,统计文件内,单词的出现数量
#导入第三方包
from pyspark import SparkConf,SparkContext
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SparkContext对象
sc=SparkContext(conf=conf)
#将文件转化为为rdd对象
rdd=sc.textFile("D:/学习资料/python/课件/课件/第15章资料/资料/hello.txt")
#将所有的单词都取出来
words=rdd.flatMap(lambda x:x.split(" "))
#将所有单词都加上1作为value
words_one=words.map(lambda x:(x,1))
#对单词分组并求和
result=words_one.reduceByKey(lambda a,b:a+b)
#打印输出的的结果
print(result.collect())
#关闭spark程序
sc.stop()
2.使用Spark读取文件进行计算:各个城市销售额排名,从大到小
全部城市,有哪些商品类别在售卖,北京市有哪些商品类别在售卖
#导入第三方包
from pyspark import SparkConf,SparkContext
import json
#配置Spark读取到python解释器
import os
os.environ['PYSPARK_PYTHON']="D:/学习工具/python.exe"
#获取spark对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#获取SparkContext对象
sc=SparkContext(conf=conf)
#获取rdd对象
items=sc.textFile("D:/学习资料/python/课件/课件/第15章资料/资料/orders.txt")
#按照|划分
items_split=items.flatMap(lambda x:x.split("|"))
#将每个json字符串转换为字典对象
items_dict=items_split.map(lambda x:json.loads(x))
#统计各个城市的销售额
items_city_sum=items_dict.map(lambda x:(x["areaName"],int(x["money"])))
items_city_sum=items_city_sum.reduceByKey(lambda a,b:a+b)
#对城市销售额进行排序
items_city_sum.sortBy(lambda x:x[1],ascending=False,numPartitions=1)
#输出排序结果
print(f"销售额排名为{items_city_sum.collect()}")
#统计各个城市所卖的商品
items_sale=items_dict.map(lambda x:x["category"])
#对所卖的商品进行去重
items_sale=items_sale.distinct()
#所卖的商品类别有
print(f"所卖的商品类别有{items_sale.collect()}")
#统计北京市所卖的商品
items_beijin=items_dict.map(lambda x:(x["areaName"],x["category"]))
#过滤保留北京数据
items_beijin=items_beijin.filter(lambda x:x[0]=="北京")
#对北京的商品进行去重
items_distinct_beijin=items_beijin.map(lambda x:x[1]).distinct()
#北京所卖的商品类别有
print(f"北京所卖的商品类别有{items_distinct_beijin.collect()}")
数据可视化综合案例
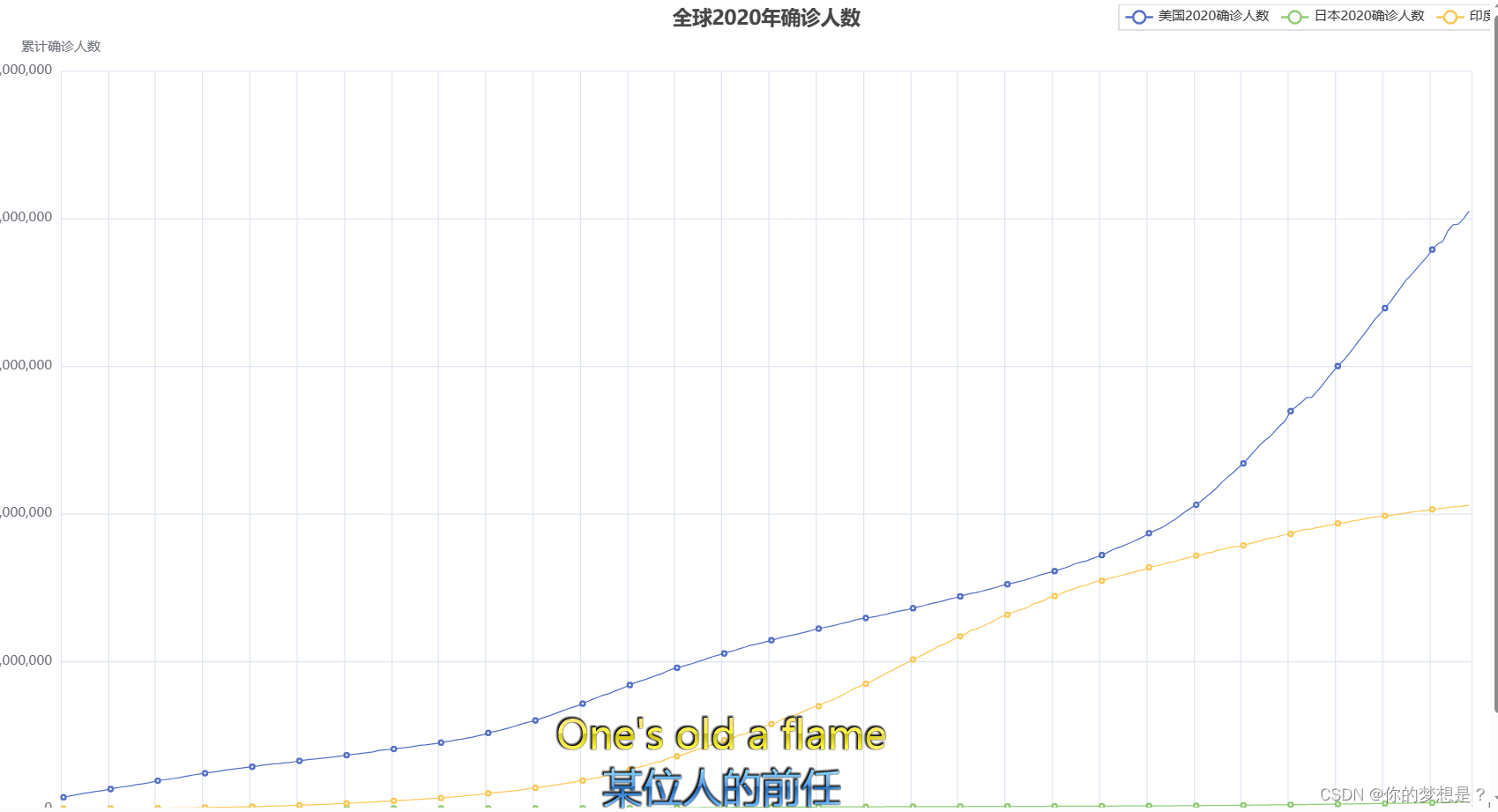
1.全球2020年确诊人数统计图
#美国数据处理
import json
#打开要处理的数据文件
f=open("D:/学习资料/python/课件/课件/资料/资料/可视化案例数据/折线图数据/美国.txt","r",encoding="UTF-8")
us_data=f.read()
print(us_data)
# 把不符合json数据格式的 "jsonp_1629350871167_29498(" 去掉
data = us_data.replace("jsonp_1629344292311_69436(","")
# 把不符合json数据格式的 ");" 去掉
data = data[:-2]
# 数据格式符合json格式后,对数据进行转化为python数据格式
data = json.loads(data)
# 获取美国的疫情数据
pydata = data["data"][0]["trend"]
# 获取2020年的数据
x1_data = pydata["updateDate"][45:314]
# 获取2020年的数据
y1_data = pydata["list"][0]["data"][45:314]
---------------------------------------------
#日本数据处理
import json
#打开要处理的数据文件
f=open("D:/学习资料/python/课件/课件/资料/资料/可视化案例数据/折线图数据/日本.txt","r",encoding="UTF-8")
jp_data=f.read()
print(jp_data)
# 把不符合json数据格式的 "jsonp_1629350871167_29498(" 去掉
data = jp_data.replace("jsonp_1629350871167_29498(","")
# 把不符合json数据格式的 ");" 去掉
data = data[:-2]
# 数据格式符合json格式后,对数据进行转化
data=json.loads(data)
# 获取美国的疫情数据
pydata=data["data"][0]["trend"]
# 获取2020年的数据
x1_data =pydata["updateDate"][46:314]
# 获取2020年的数据
y1_data = pydata["list"][0]["data"][46:314]
-----------------------------------------------
#印度数据处理
import json
#打开要处理的数据文件
f=open("D:/学习资料/python/课件/课件/资料/资料/可视化案例数据/折线图数据/印度.txt","r",encoding="UTF-8")
in_data=f.read()
print(in_data)
# 把不符合json数据格式的 "jsonp_1629350871167_29498(" 去掉
data = in_data.replace("jsonp_1629350745930_63180(","")
# 把不符合json数据格式的 ");" 去掉
data = data[:-2]
# 数据格式符合json格式后,对数据进行转化
data = json.loads(data)
# 获取美国的疫情数据
pydata = data["data"][0]["trend"]
# 获取2020年的数据
x1_data = pydata["updateDate"][:269]
# 获取2020年的数据
y1_data = pydata["list"][0]["data"][:269]
----------------------------------------------
#全球折线图生成
#导入折线图模块
from pyecharts.charts import Line
#导入全局配置选项模块
import pyecharts.options as opts
#导入json
import json
#导入处理后的数据
import 美国数据处理 as us_data
import 日本数据处理 as jp_data
import 印度数据处理 as id_data
#创建折线图
l=Line(init_opts=opts.InitOpts(width="1600px",height="800px"))
#图表全局设置
l.set_global_opts(
# 设置图标题和位置
title_opts=opts.TitleOpts(title="全球2020年确诊人数",pos_left="center"),
# x轴配置项
xaxis_opts=opts.AxisOpts(name="时间"), # 轴标题
# y轴配置项
yaxis_opts=opts.AxisOpts(name="累计确诊人数"), # 轴标题
# 图例配置项
legend_opts=opts.LegendOpts(pos_left='70%'), # 图例的位置
)
#添加数据
l.add_xaxis(xaxis_data=us_data.x1_data)
l.add_yaxis(y_axis=us_data.y1_data,series_name="美国2020确诊人数",label_opts=opts.LabelOpts(is_show=False))
l.add_yaxis(y_axis=jp_data.y1_data,series_name="日本2020确诊人数",label_opts=opts.LabelOpts(is_show=False))
l.add_yaxis(y_axis=id_data.y1_data,series_name="印度2020确诊人数",label_opts=opts.LabelOpts(is_show=False))
#生成图表
l.render("全球疫情折现图.html")
2.国内疫情地图
#国内疫情地图数据处理文件
import json
#读取文件
f=open("D:\学习资料\python\课件\课件\资料\资料\可视化案例数据\地图数据\疫情.txt","r",encoding="UTF-8")
data=f.read()
#将json数据转换为python数据格式
data=json.loads(data)
pydata=data["areaTree"][0]["children"]
location=list()
for dict in pydata:
if dict["name"]=="北京"or dict["name"]=="上海"or dict["name"]=="天津"or dict["name"]=="重庆":
location.append((dict["name"]+"市",dict["total"]["confirm"]))
elif dict["name"]=="香港"or dict["name"]=="澳门":
location.append((dict["name"] + "特别行政区", dict["total"]["confirm"]))
elif dict["name"]=="内蒙古"or dict["name"]=="西藏":
location.append((dict["name"]+"自治区",dict["total"]["confirm"]))
elif dict["name"]=="广西":
location.append((dict["name"]+"壮族自治区",dict["total"]["confirm"]))
elif dict["name"]=="宁夏":
location.append((dict["name"] + "回族自治区", dict["total"]["confirm"]))
elif dict["name"]=="新疆":
location.append((dict["name"] + "维吾尔自治区", dict["total"]["confirm"]))
else:
location.append((dict["name"]+"省",dict["total"]["confirm"]))
#测试
if __name__=='__main__':
print(location)
_________________________________________________
#生成地图文件
#导入第三方包
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
#导入处理后的数据
import 国内疫情地图数据处理 as china_data
#创建地图对象
map=Map()
#添加数据
map.add("国内疫情地图",china_data.location,"china")
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min":1,"max":9,"label":"1-9","color":"#CCFFFF"},
{"min":10,"max":99,"label":"10-99","color":"#FFFF99"},
{"min":99,"max":499,"label":"99-499","color":"#FF9966"},
{"min":500,"max":999,"label":"500-999","color":"#FF6666"},
{"min":1000,"max":9999,"label":"1000-9999","color":"#CC3333"},
{"min":9999,"label":"1000以上","color":"#990033"}
]
)
)
#生成地图
map.render("国内疫情地图.html")

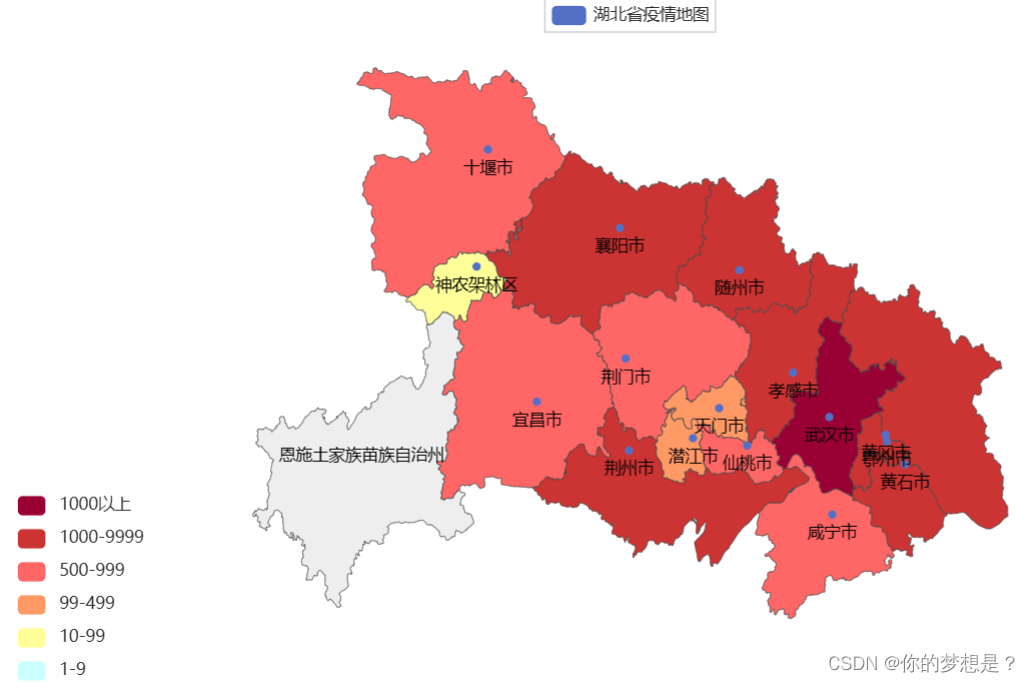
3.省内疫情地图
#湖北省疫情数据处理文件
#导入json
import json
#读取数据文件
f=open("D:\学习资料\python\课件\课件\资料\资料\可视化案例数据\地图数据\疫情.txt","r",encoding="UTF-8")
#数据处理
data=f.read()
data=json.loads(data)
pydata=data["areaTree"][0]["children"][6]["children"]
location=list()
for dict in pydata:
if dict["name"]=="神农架":
location.append((dict["name"]+"林区", dict["total"]["confirm"]))
elif dict["name"]=="恩施州":
location.append((dict["name"][:2]+"土家族苗族自治区", dict["total"]["confirm"]))
else:
location.append((dict["name"]+"市",dict["total"]["confirm"]))
#测试
if __name__=='__main__':
print(location)
________________________________________________
#生成地图文件
#导入第三方包
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
#导入处理后的数据
import 省内疫情地图数据处理 as data
#新建地图对象
map=Map()
#添加数据
map.add("湖北省疫情地图",data.location,"湖北")
#设置视觉映射器
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True, # 表示展示数据的标注值是否显示在色块上面,如果该值为True,标注值将被绘制出来。
is_piecewise=True, # 表示数据是否需要分段区分(例如分段颜色显示),如果该值为True,则绘制类似于深浅不同的颜色块表示数据的分段程度,如果该值为False,则表示将具体值用具体颜色表示。
pieces=[
{"min": 1, "max": 9, "label": "1-9", "color": "#CCFFFF"}, # 颜色分区
{"min": 10, "max": 99, "label": "10-99", "color": "#FFFF99"},
{"min": 99, "max": 499, "label": "99-499", "color": "#FF9966"},
{"min": 500, "max": 999, "label": "500-999", "color": "#FF6666"},
{"min": 1000, "max": 9999, "label": "1000-9999", "color": "#CC3333"},
{"min":9999,"label":"1000以上","color":"#990033"}
]
)
)
#生成地图
map.render("湖北省疫情地图.html")
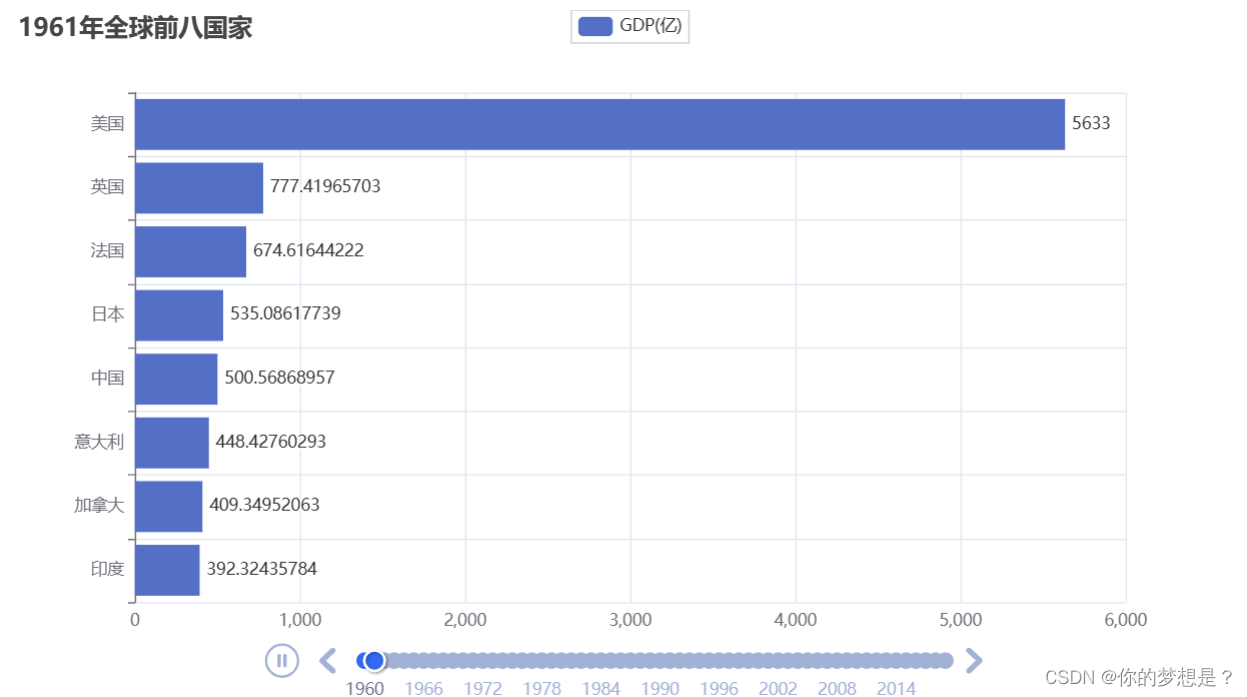
3.动态柱状图
#动态柱状图的数据处理文件
#导入json
import json
#读取文件
f=open("D:/学习资料/python/课件/课件/资料/资料/可视化案例数据/动态柱状图数据/1960-2019全球GDP数据.csv","r",encoding="GB2312")
data=f.readlines()
#处理数据
#删除首行元素
data.pop(0)
#以逗号划分
#构建嵌套字典{年份:[(国家:GDP)]}
dict=dict()
for str in data:
year=int(str.split(",")[0])
country=str.split(",")[1]
GDP=float(str.split(",")[2])
try:
dict[year].append([country,GDP])
except:
dict[year]=[]
dict[year].append([country,GDP])
#每一年
year=dict.keys()
# year=sorted(year)
print(year)
#排序每一年的GDP前八个国家
def choose_key(element):
return element[1]
for i in year:
dict[i].sort(key=choose_key,reverse=True)
————————————————————————————————————————————————
#动态柱状图的生成
#导入相关包
from pyecharts.charts import Bar,Timeline
from pyecharts.options import *
#导入处理好的数据
import GDP动态柱状图数据处理 as data
#新建一个时间线
line=Timeline()
#新建柱状图
for i in data.year:
countrys=[]
gdps=[]
#取出GDP前八的国家
pydata=data.dict[i][0:8]
#准别xy轴额数据
for country_gdp in pydata:
countrys.append(country_gdp[0])
gdps.append(country_gdp[1]/100000000)
bar=Bar()
#反转数据,大的数据在上,小的在下
countrys.reverse()
gdps.reverse()
#设置标题
bar.set_global_opts(title_opts=TitleOpts(title=f"{i}年全球前八国家"))
#添加xy轴数据
bar.add_yaxis("GDP(亿)",gdps,label_opts=LabelOpts(position="right"))
bar.add_xaxis(countrys)
#反转xy轴
bar.reversal_axis()
line.add(bar,str(i))
#设置自动播放
line.add_schema(
play_interval=1000, #自动播放时间间隔
is_timeline_show=True, #是否在播放的时候显示时间线
is_auto_play=True, #是否自动播放
is_loop_play=True #是否循环播放
)
#生成柱状图
line.render("GDP动态柱状图.html")