线性回归
1.基本概念
线性回归是无监督学习中的一种算法,根据用户输入的特征数据进行预测,比如根据房子的尺寸来预测房价,在训练这个模型时,我们需要提前得到一个可靠的数据集作为训练数据集,比如如图提供的数据集。
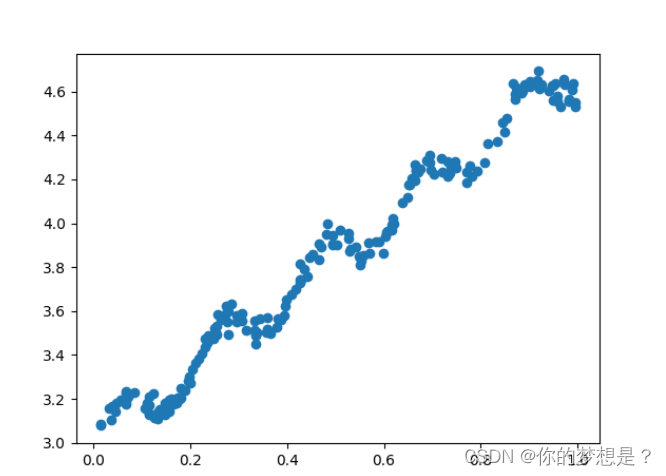
可以根据散点图得到横轴与纵轴有很大的线性关系。我们通过下面公式1的线性公式尝试进行拟合
f
(
x
(
i
)
)
=
θ
1
x
1
(
i
)
+
θ
2
x
2
(
i
)
+
.
.
.
+
θ
j
x
j
(
i
)
(
1.1
)
f(x^{(i)})=\theta_1x_1^{(i)}+\theta_2x_2^{(i)}+...+\theta_jx_j^{(i)}\quad(1.1)
f(x(i))=θ1x1(i)+θ2x2(i)+...+θjxj(i)(1.1)
这里我用上标
i
i
i表示第
i
i
i个样本,用
j
j
j表示特征维度,在机器学习中,我们可以定义均方误差函数来定义预测值与实际值的差距,均方误差函数定义如,预测值与实际值十分接近时,均方误差也很小,所以我们只需找出最佳的所有
θ
\theta
θ使均方误差最小即可
J
(
θ
1
,
θ
2
,
.
.
.
,
θ
j
)
=
1
m
∑
i
=
1
n
(
f
(
x
(
i
)
)
−
y
(
i
)
)
2
(
1.2
)
J(\theta_1,\theta_2,...,\theta_j)=\frac{1}{m}\sum_{i=1}^{n}(f(x^{(i)})-y^{(i)})^2\quad(1.2)
J(θ1,θ2,...,θj)=m1i=1∑n(f(x(i))−y(i))2(1.2)
为了求解最佳的
θ
1
,
θ
2
\theta_1,\theta_2
θ1,θ2来准确拟合直线,这里提供两种方式,分别梯度下降法,最小二乘法。
2.最小二乘法
在最小二乘法中,
X
X
X,
Y
Y
Y和
θ
\theta
θ矩阵分别为
X
=
[
x
1
(
1
)
x
1
(
2
)
.
.
.
x
1
(
j
)
x
2
(
1
)
x
2
(
2
)
.
.
.
x
2
(
j
)
.
.
.
x
i
(
1
)
x
i
(
2
)
.
.
.
x
i
(
j
)
]
θ
=
[
θ
1
θ
2
.
.
.
θ
j
]
(
2.1
)
Y
=
[
y
1
y
2
.
.
.
y
j
]
X=\begin{bmatrix}x_1^{(1)}&x_1^{(2)}&...&x_1^{(j)}\\x_2^{(1)}&x_2^{(2)}&...&x_2^{(j)}\\.\\.\\.x_i^{(1)}&x_i^{(2)}&...&x_i^{(j)} \end{bmatrix}\\\theta=\begin{bmatrix} \theta_1 \theta_2&.&.&.\theta_j \end{bmatrix}\quad\quad\quad(2.1)\\ Y=\begin{bmatrix} y_1 \\y_2\\.\\.\\.\\y_j \end{bmatrix}
X=
x1(1)x2(1)...xi(1)x1(2)x2(2)xi(2).........x1(j)x2(j)xi(j)
θ=[θ1θ2...θj](2.1)Y=
y1y2...yj
我们首先将公式1.2转化为矩阵形式,
f
(
x
(
i
)
)
=
θ
1
x
1
(
i
)
+
θ
2
x
2
(
i
)
+
.
.
.
+
θ
j
x
j
(
i
)
=
>
f
(
x
(
i
)
)
=
[
θ
1
θ
2
.
.
.
θ
j
]
∗
[
x
1
(
i
)
x
2
(
i
)
.
.
.
x
j
(
i
)
]
(
2.2
)
=
>
f
(
x
(
i
)
)
=
θ
T
X
f(x^{(i)})=\theta_1x_1^{(i)}+\theta_2x_2^{(i)}+...+\theta_jx_j^{(i)}\\=>f(x^{(i)})=\begin{bmatrix} \theta_1 \\\theta_2\\.\\.\\.\\\theta_j \end{bmatrix}*\begin{bmatrix}x_1^{(i)}&x_2^{(i)}&...&xj^{(i)} \end{bmatrix}\quad(2.2)\\=>f(x^{(i)})=\theta^TX
f(x(i))=θ1x1(i)+θ2x2(i)+...+θjxj(i)=>f(x(i))=
θ1θ2...θj
∗[x1(i)x2(i)...xj(i)](2.2)=>f(x(i))=θTX
将其带入到均值方差中
1
m
(
θ
T
X
−
Y
)
T
∗
(
θ
T
X
−
Y
)
(
2.3
)
\frac{1}{m}(\theta^TX-Y)^T*(\theta^TX-Y)\quad(2.3)
m1(θTX−Y)T∗(θTX−Y)(2.3)
要是均值方差最小,等价于求均值方差的极值点,对公式2.3求导并令其等于0,我们可以得到
θ
\theta
θ解
θ
=
(
X
T
X
)
−
1
∗
X
T
Y
(
2.4
)
\theta=(X^TX)^{-1}*X^TY\quad(2.4)
θ=(XTX)−1∗XTY(2.4)
利用公式2.4编程,代码如下
#导入科学计算包
from numpy import *
#导入matplotlib绘图库
import matplotlib.pyplot as plt
#读取数据文件
def loadDataset(file_name):
#数据集获取特征数目
num_feature=len(open(file_name).readline().split('\t'))-1
#定义并初始化数据集,标签集
data=[]
label=[]
#打开文本文件
f=open(file_name)
#对文件按行读取,并迭代每一行
for line in f.readlines():
#定义并初始化行列表
line_list=[]
#读取文件的每一行数据按按制表符划分
cur_line=line.strip().split('\t')
#对划分后的每一个数据迭代加入到行列表中
for i in range(num_feature):
line_list.append(float(cur_line[i]))
#将行列表数据加入到数据集中
data.append(line_list)
#将数据标签加入到标签数据集中
label.append(float(cur_line[-1]))
return data,label
#求解最佳系数w拟合直线方程
def search_best_w(x_list,y_list):
#将list数据转换为矩阵
x_mat=mat(x_list)
#将矩阵转置
y_mat=mat(y_list).T
# print(shape(x_mat))
# print(shape(y_mat))
#计算出x的转置*x
xTx=x_mat.T*x_mat
#判断行列式值是否为0,为0则矩阵不可逆
if linalg.det(xTx)==0.0:
print("矩阵不可逆")
return
#计算系数w的公式
w=xTx.I*(x_mat.T*y_mat)
return w
#打印出散点图
def ploter(x_mat,y_mat,w):
#绘制散点图
plt.scatter(x_mat[:,1].tolist(),y_mat.tolist())
#绘制拟合直线图
plt.plot(x_mat[:,1].tolist(),x_mat*w.tolist(),color='red')
plt.show()
#测试
if __name__=='__main__':
x,y=loadDataset("D:/学习资料/机器学习实战/《机器学习实战》源代码/machinelearninginaction/Ch08/ex0.txt")
w=search_best_w(x,y)
ploter(mat(x),mat(y),w)
print(w)
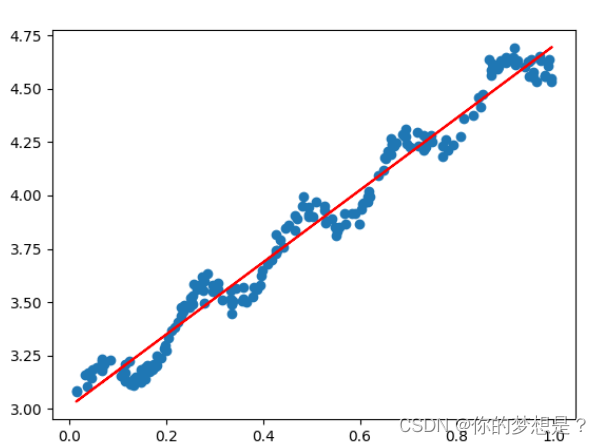
拟合直线如图所示。
3.梯度下降法
前面考量实际值与预测值过程中,我们使用的是均方误差
j
(
θ
)
j(\theta)
j(θ)表示预测值与实际值的差距,而且利用了矩阵的计算方式,并且求出了最优解。但是这种方式存在一个缺陷就是当训练集数据很大,特征维度很多时,可能要花费大量时间在矩阵计算过程中。为了优化这个问题提出了,梯度下降法来求最优解。为了求导方便定义损失函数如下
J
(
θ
1
,
θ
2
,
.
.
.
,
θ
j
)
=
1
2
∗
m
∑
i
=
1
n
(
f
(
x
(
i
)
)
−
y
(
i
)
)
2
(
3.1
)
J(\theta_1,\theta_2,...,\theta_j)=\frac{1}{2*m}\sum_{i=1}^{n}(f(x^{(i)})-y^{(i)})^2\quad(3.1)
J(θ1,θ2,...,θj)=2∗m1i=1∑n(f(x(i))−y(i))2(3.1)
要求损失函数最小,等价于求极值点,对公式3.1分别对
θ
1
,
θ
2
.
.
.
θ
j
\theta_1,\theta_2...\theta_j
θ1,θ2...θj求偏导。
α
J
α
θ
1
=
1
n
∑
i
=
1
n
(
f
(
x
(
i
)
−
y
(
i
)
)
x
(
i
)
α
J
α
θ
2
=
1
n
∑
i
=
1
n
(
f
(
x
(
i
)
−
y
(
i
)
)
x
(
i
)
(
3.2
)
.
.
.
α
J
α
θ
j
=
1
n
∑
i
=
1
n
(
f
(
x
(
i
)
−
y
(
i
)
)
x
(
i
)
\frac{\alpha J}{\alpha \theta_1}=\frac{1}{n}\sum_{i=1}^{n}(f(x^{(i)}-y^{(i)})x^{(i)}\\\frac{\alpha J}{\alpha \theta_2}=\frac{1}{n}\sum_{i=1}^{n}(f(x^{(i)}-y^{(i)})x^{(i)}\quad(3.2)\\.\\.\\.\\\frac{\alpha J}{\alpha \theta_j}=\frac{1}{n}\sum_{i=1}^{n}(f(x^{(i)}-y^{(i)})x^{(i)}
αθ1αJ=n1i=1∑n(f(x(i)−y(i))x(i)αθ2αJ=n1i=1∑n(f(x(i)−y(i))x(i)(3.2)...αθjαJ=n1i=1∑n(f(x(i)−y(i))x(i)
所谓的梯度就是损失函数在个特征维度上的偏导向量,简单点说就是切线,举个例子,从山上下坡,最快下坡的路线就是沿着切线的方向下坡。梯度下降法有三个步骤
1.从当前出发点找到梯度,也就是找到合适方向
2.根据方向向下挪动一小步
3.挪动后,重新寻找梯度,并再次挪动,并反复迭代步骤23
按照这种思想,我们可以反复不断的迭代找到最优参数
θ
\theta
θ使损失函数值最小,更新
θ
\theta
θ要同时进行
θ
1
n
e
w
=
θ
1
o
l
d
−
β
α
J
o
l
d
α
θ
1
θ
2
n
e
w
=
θ
2
o
l
d
−
β
α
J
o
l
d
α
θ
2
(
3.2
)
.
.
.
θ
j
n
e
w
=
θ
j
o
l
d
−
β
α
J
o
l
d
α
θ
j
\theta_1^{new}=\theta_1^{old}-\beta\frac{\alpha J^{old}}{\alpha \theta_1}\\\theta_2^{new}=\theta_2^{old}-\beta\frac{\alpha J^{old}}{\alpha \theta_2}\quad(3.2)\\.\\.\\.\\\theta_j^{new}=\theta_j^{old}-\beta\frac{\alpha J^{old}}{\alpha \theta_j}
θ1new=θ1old−βαθ1αJoldθ2new=θ2old−βαθ2αJold(3.2)...θjnew=θjold−βαθjαJold
代码实现如下
#导入科学计算包
from numpy import *
#导入matplotlib绘图库
import matplotlib.pyplot as plt
#获取文本文件处理数据
#读取数据文件
def loadDataset(file_name):
#数据集获取特征数目
num_feature=len(open(file_name).readline().split('\t'))-1
#定义并初始化数据集,标签集
data=[]
label=[]
#打开文本文件
f=open(file_name)
#对文件按行读取,并迭代每一行
for line in f.readlines():
#定义并初始化行列表
line_list=[]
#读取文件的每一行数据按按制表符划分
cur_line=line.strip().split('\t')
#对划分后的每一个数据迭代加入到行列表中
for i in range(num_feature):
line_list.append(float(cur_line[i]))
#将行列表数据加入到数据集中
data.append(line_list)
#将数据标签加入到标签数据集中
label.append(float(cur_line[-1]))
return data,label
# 代价函数对应的梯度函数,
def gradient_function(theta, data, label,m):
diff = dot(data, theta)- label
# print(shape(diff))
return (1/m)*dot(diff.T,data)
#计算损招函数
def cal_loss(data,label,theta,m):
diff=dot(data,theta)-label
return (1/2*m)*dot(diff.T,diff)
# 梯度下降迭代
def gradient_descent(data,label,alpha,epochs):
m,n=shape(data)
theta = ones((n,1))#自定义theta值,
gradient = gradient_function(theta,data,label,m)#梯度下降值
#定义存储损失值列表
loss_list=list()
lose=cal_loss(data,label,theta,m)
#/20000使损失图形显得更直观
loss_list.append(lose.tolist()[0][0]/20000)
for i in range(epochs):#迭代次数
theta = theta - alpha * gradient.T
# print(shape(lose))
lose = cal_loss(data,label,theta, m)
loss_list.append(lose.tolist()[0][0]/20000)
gradient = gradient_function(theta,data,label,m)
return theta,loss_list
#绘制散点图
def ploter(data,label,theta,loss,epochs):
# 绘制散点图
plt.scatter(data[:, 1].tolist(), label.tolist())
# 绘制拟合直线图
index = data.A[:, 1].argsort()
plt.plot(data[:, 1].A[index], (data * theta).A[index], color='red')
plt.show()
# 绘制损失函数图
plt.plot(range(epochs+1),loss)
plt.show()
#测试
if __name__=='__main__':
data,label=loadDataset("D:/学习资料/机器学习实战/《机器学习实战》源代码/machinelearninginaction/Ch08/ex0.txt")
epochs=200
m=shape(data)[1]
#特征维度标准化
x_mat = mat(data)
y_mat = mat(label).T
y_mean = mean(y_mat, 0)
x_mean = mean(x_mat, 0)
x_var = var(x_mat, 0)
x_mat = (x_mat - x_mean) / (max(x_mat)-min(x_mat))
y_mat = y_mat - y_mean
x_mat[:, 0] = 1
theta,loss_list=gradient_descent(x_mat,y_mat,0.1,epochs)
print(loss_list)
ploter(x_mat,y_mat,theta,loss_list,epochs)
print(theta)
这里的特征维度标准化,是为了使消除各个特征维度间数据差异过大导致带来的误差。损失值与迭代次数关系图,及拟合图如下
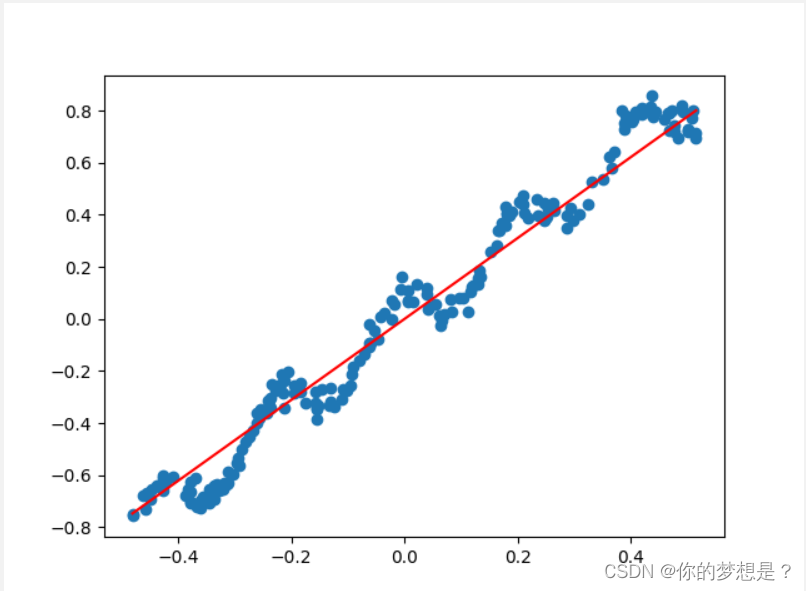
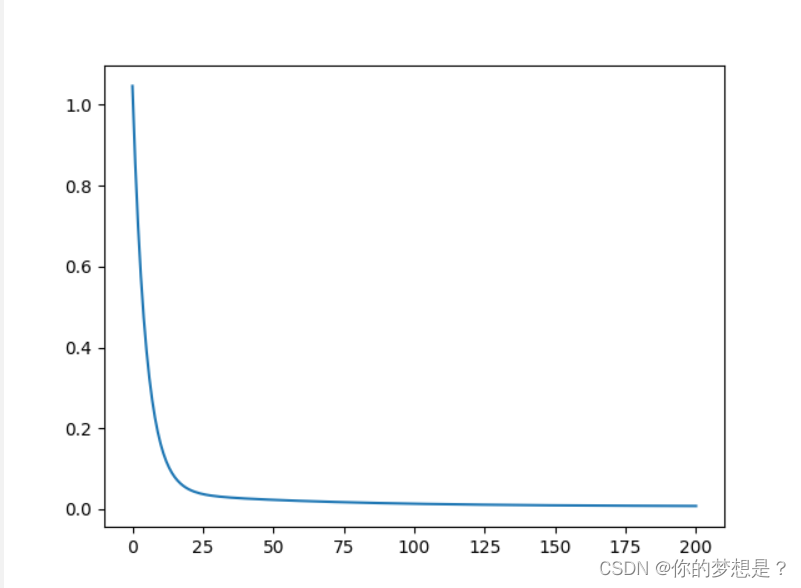
在损失图中可以看到迭代20次后损失值开始趋近于0
4.总结
最小二乘法求解参数过程中对于数据集相对小且特征维度不多的情况下挺适合,对于数据集较大,特征维度较多时推荐使用最梯度下降法或者其它方法
梯度下降法的唯一缺点就是无法很好的找到合适的步长,步长太小,可能会导致需要迭代很多次才能找到最优参数,步长太大,可能会导致反复跌打一直找不到最优参数。需要多长尝试步长大小
4.代码及数据集文件
链接:https://pan.baidu.com/s/1DLzwScyk2yekAsP0nhrliQ
提取码:nhfy