Hive函数、运算符使用
Hive内置运算符
概述
-
整体上,Hive支持的运算符可以分为三大类:关系运算、算术运算、逻辑运算。
-
官方参考文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
-
也可以使用下述方式查看运算符的使用方式。
-- 显示所有的函数和运算符 show functions; -- 查看运算符或者函数的使用说明 describe function count; -- 使用extended可以查看更加详细的使用说明 describe function extended count;
关系运算符
关系运算符是二元运算符,执行的是两个操作数的比较运算。
每个关系运算符都返回boolean类型结果(TRUE或FALSE)。

算术运算符
算术运算符操作数必须是数值类型。分为一元运算符和二元运算符:
一元运算符只有一个操作数;二元运算符有两个操作数,运算符在两个操作数之间。

逻辑运算符

Hive函数入门
分类标准
Hive的函数分为两大类:内置函数(Built-in Functions)、用户定义函数UDF (User-Defined Functions ) :
内置函数可分为:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等;
用户定义函数根据输入输出的行数可分为3类:UDF、UDAF、UDTF。
用户定义函数UDF分类标准
根据函数输入输出的行数:
UDF (User-Defined-Function)普通函数,一进一出
UDAF (User-Defined Aggregation Function)聚合函数,多进一出
UDTF (User-Defined Table-Generating Functions)表生成函数,一进多出

UDF分类标准扩大化
UDF分类标准本来针对的是用户自己编写开发实现的函数。UDF分类标准可以扩大到Hive的所有函数中:包括内置函数和用户自定义函数。
因为不管是什么类型的函数,一定满足于输入输出的要求,那么从输入几行和输出几行上来划分没有任何问题。千万不要被UD (User-Defined)这两个字母所迷惑,照成视野的狭隘。
比如Hive官方文档中,针对聚合函数的标准就是内置的UDAF类型。
内置函数
-
内置函数(build-in)指的是Hive开发实现好,直接可以使用的函数,也叫做内建函数。
-
官方文档地址: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
-
内置函数根据应用归类整体可以分为8大种类型:字符串函数、日期函数、数学函数、条件函数、数据脱敏函数、集合函数、类型转换函数、其它杂项函数
字符串函数
------------String Functions字符串函数------------
-- 字符串连接函数: concat(str1, str2, ... strN),不可以指定分隔符;任意一个元素为null,结果就为null
select concat("angela", "baby"); -- angelababy
-- 带分隔符字符串连接函数:concat_ws(separator,[string / array(string)]),可以指定分隔符;任意一个元素不为null,结果就不为null
select concat_ws('.','www',array('aiw', 'com')); -- www.aiw.com
-- 字符串截取函数: substr(str,pos[,len])或者substring(str,pos[,len]),pos是从1开始的索引,如果为负数则倒着数
select substr("angelababy",-2); -- by
select substr("angelababy",2,2); -- ng
-- 正则表达式替换函数: regexp_replace(str,regexp,rep)
select regexp_replace('100-200', '(\\d+)', 'num'); --num-num
-- 正则表达式解析函数: regexp_extract(str, regexp[,idx])提取正则匹配到的指定组内容
select regexp_extract('100-200', '(\\d+)-(\\d+)',1); -- 100
select regexp_extract('100-200', '(\\d+)-(\\d+)',2); -- 200
-- URL解析函数: parse_url 注意要想一次解析出多个可以使用parse_url_tuple这个UDTF函数
select parse_url('http://www.aiw.com/path/p1.php?query=1','HOST'); -- www.aiw.com
-- 分割字符串函数: split(str,regex)
select split('apache hive', '\\s+'); -- ["apache","hive"]
-- json解析函数: get_json_object(json_txt,path),用于解析JSON字符串,可以从JSON字符串中返回指定的某个对象列的值;
-- 特点:每次只能返回JSON对象中一列的值
-- $表示json对象;通过$.columnName的方式来指定path
select get_json_object('[{"website":"www.aiw.cn","name":"allenwoon"}]','$.[0].website'); -- www.aiw.cn
-- 字符串长度函数: length(str / binary)
select length("angelababy"); -- 10
-- 字符串反转函数: reverse
select reverse ("angelababy"); -- ybabalegna
-- 字符串转大写函数: upper,ucase
select upper("angelababy"); -- ANGELABABY
select ucase("angelababy"); -- ANGELABABY
-- 字符串转小写函数: lower,lcase
select lower("ANGELABABY"); -- angelababy
select lcase("ANGELABABY"); -- angelababy
-- 去空格函数: trim去除左右两边的空格
select trim(" angelababy "); -- angelababy
-- 左边去空格函数: ltrim
select ltrim(" angelababy"); -- angelababy
-- 右边去空格函数: rtrim
select rtrim("angelababy "); -- angelababy
-- 空格字符串函数:space(n),返回n个空格的字符串
select space(3);
-- 重复字符串函数:repeat(str,n),重复str为n次。
select repeat('aiw',2); -- aiwaiw
-- 首字符ascii函数:ascii(str),返回 str 的第一个字符的数值。
select ascii('aiw'); -- 97
-- 左补足函数
select lpad('aiw',5,'@'); -- @@aiw
-- 右补足函数
select rpad('aiw',5,'@'); -- aiw@@
-- 集合查找函数
select find_in_set('ab','abc,b,ab,c,def'); -- 3
日期函数
------------Date Functions日期函数------------
-- 获取当前日期: current_date
select current_date(),current_date; -- 2024-08-25 2024-08-25
-- 获取当前时间:current_timestamp
-- 同一查询中对current_timestamp的所有调用均返回相同的值。
select current_timestamp(),current_timestamp; -- 2024-08-25 15:56:21.820 2024-08-25 15:56:21.820
-- 获取当前UNIX时间戳函数:unix_timestamp,默认获取的是UTC时间戳
select unix_timestamp(); -- 1724572684
-- 日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp ('2011-12-07 13:01:03'); -- 1323262863
-- 指定格式日期转UNIX时间戳函数:unix_timestamp
select unix_timestamp ('20111207 13:01:03', 'yyyyMMdd HH:mm:ss'); -- 1323262863
-- UNIX时间戳转日期函数:from_unixtime
select from_unixtime(1724572684, 'yyyy-MM-dd HH:mm:ss'); -- 2024-08-25 07:58:04
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss'); -- 1970-01-01 00:00:00
select from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss'); -- 2024-08-25 08:01:27 默认是UTC时间,比北京时间少8个小时
SELECT from_unixtime(cast(unix_timestamp() as bigint) + 8 * 3600, 'yyyy-MM-dd HH:mm:ss'); -- 2024-08-25 16:06:08 转化为北京时间
-- 日期比较函数: datediff日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'
select datediff('2012-12-08','2012-05-09'); -- 213
-- 日期增加函数: date_add
select date_add('2012-02-28',10); -- 2012-03-09
-- 日期减少函数: date_sub
select date_sub('2012-01-1',10); -- 2011-12-22
-- 抽取日期函数: to_date
select to_date('2009-07-30 04:17:52'); -- 2009-07-30
-- 日期转年函数: year
select year('2009-07-30 04∶17:52'); -- 2009
-- 日期转月函数;month
select month('2009-07-30 04∶17:52'); -- 7
-- 日期转天函数:day
select day('2009-07-30 04:17:52'); -- 30
-- 日期转小时函数: hour
select hour('2009-07-30 04:17:52'); -- 4
-- 日期转分钟函数: minute
select minute('2009-07-30 04:17:52'); -- 17
-- 日期转秒函数:second
select second('2009-07-30 04:17:52'); --52
-- 日期转周函数: weekofyear返回指定日期所示年份第几周
select weekofyear('2009-07-30 04:17:52'); -- 31
数学函数
------------Mathematical Functions数学函数------------
-- 取整函数: round返回double类型的整数值部分(遵循四舍五入)
select round(3.1415926); -- 3
-- 指定精度取整函数: round(double a, int d)返回指定精度d的double类型
select round(3.1415926,4); -- 3.1416
-- 向下取整函数:floor
select floor(3.1415926); -- 3
select floor(-3.1415926); -- -4
-- 向上取整函数: ceil
select ceil(3.1415926); -- 4
select ceil(-3.1415926); -- -3
-- 取随机数函数: rand每次执行都不一样返回一个0到1范围内的随机数
select rand(); -- 0.05960270647504262
-- 指定种子取随机数函数:rand(int seed)得到一个稳定的随机数序列,比如上下均获取同一个随机数值
select rand(2); -- 0.7311469360199058
-- 二进制函数:bin(BIGINT a),将数字转化为二进制格式
select bin(6); -- 110
-- 绝对值函数
select abs(-9); -- 9
-- 进制转化函数
select conv(6,10,2); -- 110,将6从10进制转化为2进制
select conv(110,2,10); -- 6,将110从2进制转化为10进制
集合函数
------------Collection Functions集合函数------------
-- 集合元素size函数: size(Array<T>)、size(Map<K.V>)
select size(array(11,22,33)); -- 3
select size(map("id",10086,"name","zhangsan","age",18)); -- 3
-- 取map集合keys函数: map_keys (Map<K.V>)
select map_keys(map("id",10086,"name","zhangsan","age",18)); -- ["id","name","age"]
-- 取map集合values函数: map_values(Map<K.V>)
select map_values(map("id",10086,"name","zhangsan","age",18)); -- ["10086","zhangsan","18"]
-- 判断数组是否包含指定元素: array_contains(Array<T>, value)
select array_contains(array(11,22,33),11); -- true
select array_contains(array(11,22,33),66); -- false
-- 数组排字函数: sort_array(Array<T>),只能升序
select sort_array(array(12,2,32)); -- [2,12,32]
-- 将一列中的多行合并为一行,并进行去重
with tmp as (select 2 as col union all select 3 as col union all select 2 as col)
select collect_set(t.col) from tmp t; -- [2,3]
-- 将一列中的多行合并为一行,不进行去重
with tmp as (select 2 as col union all select 3 as col union all select 2 as col)
select collect_list(t.col) from tmp t; -- [2,3,2]
条件函数
------------Conditional Functions条件函数------------
-- if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1=2,100,200); -- 200
select if(sex ='男','M','W') from student limit 1; -- M
-- 空判断函数: isnull(a)
select isnull("allen"); -- false
select isnull(null); -- true
-- 非空判断函数: isnotnull(a)
select isnotnull("allen"); -- true
select isnotnull(null); -- false
-- 空值转换函数: nvl(T value, T default_value)
select nvl("allen", "itcast"); -- allen
select nvl(null,"itcast"); -- itcast
-- 非空查找函数:COALESCE(T v1, T v2, ...)
-- 返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL
select COALESCE(null,11,22,33); -- 11
select COALESCE(null, null,null,33); -- 33
select COALESCE(null,null,null); -- NULL
-- 条件转换函数:CASE a WHEN b THEN c [WHEN d THEN e]*[ELSE f] END,当 a = b 时,返回 c;当 a = d 时,返回 e;else 返回 f。
select case sex when '男' then 'male' when '女' then 'female' else 'other' end from student limit 3;
-- 条件转换函数:CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END,当 a = true 时,返回 b;当 c = true 时,返回 d;else 返回 e。
select case when true then 'male' when false then 'female' else 'other' end;
-- nullif( a, b ),如果a = b,则返回NULL,否则返回一个
select nullif(11,11); -- NULL
select nullif(11,12); -- 11
-- assert_true (condition),如果condition不为真,则引发异常,否则返回null
SELECT assert_true(11 >= 0); -- NULL
SELECT assert_true(-1 >= 0); -- SQL 错误: java.io.IOException: org.apache.hadoop.hive.ql.metadata.HiveException: ASSERT_TRUE(): assertion failed.
类型转换函数
------------Type Conversion Functions类型转换函数------------
-- 任意数据类型之间转换: cast,转换不成功,则返回 null
select cast(12.14 as bigint); -- 12
select cast(12.14 as string); -- 12.14
select cast('520' as int); -- 520
select cast('2024-05-20' as date); -- 2024-05-20
数据脱敏函数
主要完成对数据脱敏转换功能,屏蔽原始数据
------------Data Masking Functions数据脱敏函数------------
-- mask(string str[, string upper[, string lower[, string number]]])
-- 将查询回的数据,大写字母转换为X,小写字母转换为x,数字转换为n。
select mask( "abc123DEF"); -- xxxnnnXXX
select mask( "abc123DEF",'-','.','^'); --自定义替换的字母,查询结果:...^^^---
-- mask_first_n(string str[, int n])
-- 对前n个进行脱敏替换
select mask_first_n("abc123DEF",4); -- xxxn23DEF
-- mask_last_n(string str[, int n])
-- 对后n个进行脱敏替换
select mask_last_n("abc123DEF",4); -- abc12nXXX
-- mask_show_first_n(string str, int n])
-- 除了前n个字符,其余进行掩码处理
select mask_show_first_n("abc123DEF",4); -- abc1nnXXX
-- mask_show_last_n(string str[, int n])
-- 除了后n个字符,其余进行掩码处理
select mask_show_last_n("abc123DEF",4); -- xxxnn3DEF
-- mask_hash(string|char|varchar str)
-- 返回字符串的hash编码
select mask_hash("abc123DEF"); -- 86fedeec79b202032b34464c8794279912e31b532d631475ee739de99e3c1983
其它杂项函数
------------Misc. Functions其他杂项函数------------
-- hive调用javα方法: java_method(class,method [, arg1[, arg2..]])
select java_method("java.lang.Math", "max" ,11,22); -- 22
-- 反射函数: reflect(class, method[, arg1[, arg2..]])
select reflect("java.lang.Math", "max",11,22); -- 22
-- 取哈希值函数: hash
select hash("allen"); -- 92905994
-- current_user()、logged_in_user()、current_database()、version()
select current_user(); -- root
select logged_in_user(); -- root
select current_database(); -- db_test
select version(); -- 3.1.2 r8190d2be7b7165effa62bd21b7d60ef81fb0e4af
-- SHA-1加密: sha1(string/binary)
select sha1("allen"); -- a4aed34f4966dc8688b8e67046bf8b276626e284
-- SHA-2家族算法加密: sha2(string/binary, int)(SHA-224,SHA-256,SHA-384,SHA-512)
select sha2("allen",224); -- 792eef8d0e63eeda80738ea8e521502f9158dd2e2ceccea5f20bf686
select sha2("allen",512); -- 43ecb6c485484d5b4179cab6fb9cc8f6d0e1adb902b92719be806bb3649967402ccc27d5e917b212523329c83946435228d9706d5c042a07a31a72e27fd58131
-- crc32加密:
select crc32("allen"); -- 3771531426
-- MD5加密: md5(string/ binary)
select md5("allen"); -- a34c3d45b6018d3fd5560b103c2a00e2
用户定义函数
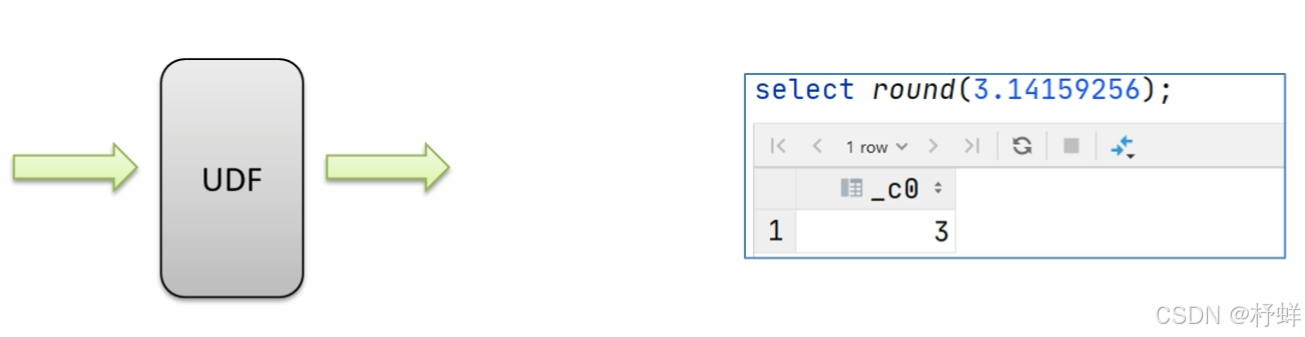
UDF普通函数
特点是一进一出,也就是输入一行输出一行。
比如round这样的取整函数,接收一行数据,输出的还是一行数据。
UDAF聚合函数
UDAF聚合函数,A所代表的单词就是Aggregation聚合的意思。多进一出,也就是输入多行输出一行。
比如count、sum这样的函数。

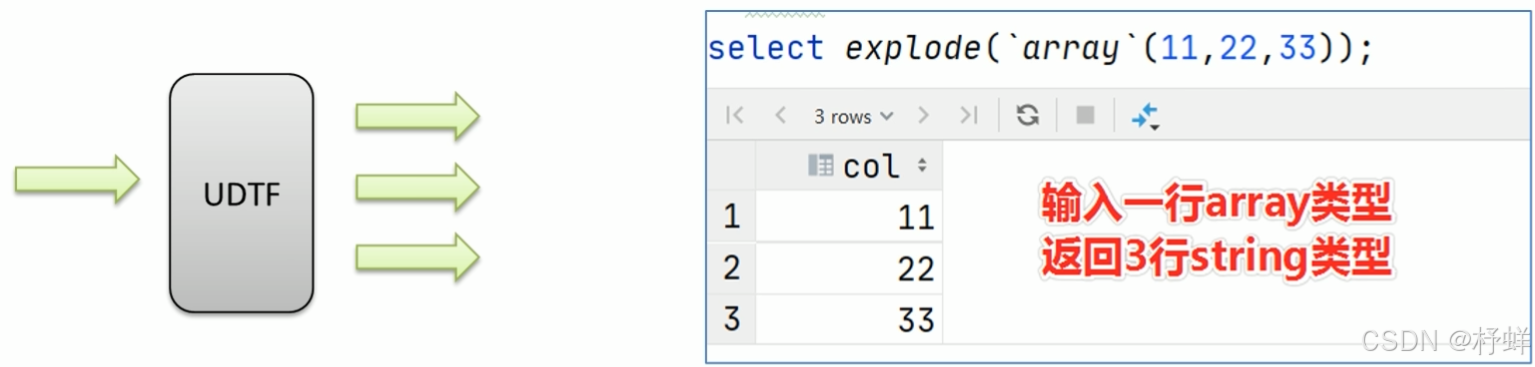
UDTF表生成函数
UDTF表生成函数,T所代表的单词是Table-Generating表生成的意思。特点是一进多出,也就是输入一行输出多行。
这类型的函数作用返回的结果类似于表,同时,UDTF函数也是我们接触比较少的函数。
比如explode函数。
UDTF函数问题
Hive中的一对多的UDTF函数可以实现高效的数据转换,但是也存在着一些使用中的问题,UDTF函数对于很多场景下有使用限制,例如:select时不能包含其他字段、不能嵌套调用、不能与group by等放在一起调用等等。
UDTF函数的调用方式,主要有以下两种方式:
方式一︰直接在select后单独使用
方式二︰与lateral view放在一起使用
UDF函数实现步骤
- 写一个java类,
继承UDF,并重载evaluate方法,方法中实现函数的业务逻辑; - 重载意味着可以在一个java类中实现多个函数功能;
- 程序打成jar包,上传Hive Server 2服务器本地或者HDFS;
- 客户端命令行中添加jar包到Hive的classpath: hive>add jar /xxxx/udf. jar;
注册成为临时函数(给UDF命名):create temporary function函数名as ‘UDF类全路径’;- HQL中使用函数。
Hive函数高阶
explode函数
explode接收map、array类型的数据作为输入,然后把输入数据中的每个元素拆开变成一行数据,一个元素一行。
explode执行效果正好满足于输入一行输出多行,所有叫做UDTF函数。
一般情况下,explode函数可以直接单独使用即可;也可以根据业务需要结合lateral view侧视图一起使用。
-- 查看函数说明
describe function extended explode;
/*
* A
B
C
*/
select explode(array('A','B','C'));
/*
* 0 A
1 B
2 C
*/
select posexplode(array('A','B','C')); -- 该函数参数只能是array类型
/*
id 1001
name Aiw
age 20
*/
select explode(map('id',1001,'name','Aiw','age','20'));
UDTF函数结果可以起别名,使用()来一一对应结果列:
select explode(map('id',1001,'name','Aiw','age','20')) as (col1,col2);
Lateral View侧视图
概念
Lateral View是一种特殊的语法,主要搭配UDTF类型函数一起使用,用于解决UDTF函数的一些查询限制的问题。
一般只要使用UDTF,就会固定搭配lateral view使用。
原理
将UDIF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了UDTF的使用限制问题。
使用lateral view时也可以对UDIF产生的记录设置字段名称,产生的字段可以用于group by、order by , limit等语句中,不需要再单独嵌套一层子查询。
官方链接︰https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Lateralview

-- lateral view侧视图基本语法如下
select... from table1 A lateral view UDTF(xxx) 别名 as col1,col2,col...;
-- 1、建表
create table t_lateral_view(
user_id int,
group_ids array<int>
);
-- 2、插入数据
insert into table t_lateral_view values(100,array(1)),(101,array(2,3));
-- 查看表数据
select * from t_lateral_view;
-- 3、使用侧视图
/*
100 1
101 2
101 3
*/
select a.user_id,b.group_id from t_lateral_view a lateral view explode(group_ids) b as group_id;
-- 分组聚合
/*
100 1
101 2
*/
select a.user_id,count(1) as num from t_lateral_view a lateral view explode(group_ids) b as group_id
group by a.user_id order by a.user_id nulls last;
-- 如果UDTF函数不产生数据时,这时侧视图与原表关联的结果为空;即查询结果为空
select a.user_id,b.col from t_lateral_view a lateral view explode(array()) b as col;
-- 如果加上outer关键字以后,则会保留原表数据,类似于outer join
select a.user_id,b.col from t_lateral_view a lateral view outer explode(array()) b as col;
/* 查询结果
user_id col
100 NULL
101 NULL
*/
聚合函数
概念
聚合函数的功能是:对一组值执行计算并返回单一的值。
聚合函数是典型的输入多行输出一行,使用Hive的分类标准,属于UDAF类型函数。
通常搭配Group By语法—起使用,分组后进行聚合操作。
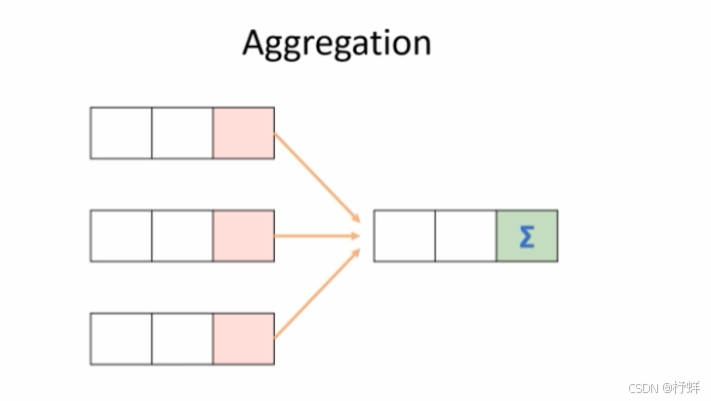
基础聚合
HQL提供了几种内置的UDAF聚合函数,例如max(...),min(...)和avg(...)。这些我们把它称之为基础的聚合函数。
通常情况下聚合函数会与GROUP BY子句一起使用。如果未指定GROUP BY子句,默认情况下,它会汇总所有行数据。
-- 场景1:无group by子句的聚合操作
-- count(*):所有行进行统计,包括NULL行
-- count(1):所有行进行统计,包括NULL行
-- count(column):对column中非NULL进行统计
-- count(distinct column):对column中非NULL并去重进行统计
select count(*),count(1),count(num),count(distinct num) from student;
-- 场景2:带有group by子句的聚合操作
select sex,count(1) as cnt from student group by sex;
-- 场景3:select时多个聚合函数一起使用
select count(1),avg(age) from student;
-- 场景4:聚合函数、条件函数搭配使用
-- 使用sum+case when/if搭配数字(1、0)可以实现同时求取多个统计值;如下为同时求取男女人数各多少
select sum(case sex when '男' then 1 else 0 end) as s1,sum(if(sex='女',1,0)) as s2 from student;
-- 场景5:聚合参数不支持嵌套聚合函数
select avg(count(1)) from student;
-- 场景6:聚合操作时针对null的处理
CREATE TABLE tmp_1 (val1 int, val2 int);
INSERT INTO TABLE tmp_1 VALUES (1,2),(null,2),(2,3);
select * from tmp_1;
-- 第二行数据(null,2)在进行sum(val1 + val2)的时候会被忽略
select sum(val1), sum(val1 + val2) from tmp_1; -- 3 8
-- 可以使用coalesce/nvl函数解决
select sum(coalesce(val1,0)),sum(coalesce(val1,0) + val2)from tmp_1;
-- 场景7:配合distinct关键字去重聚合
-- 此场景下,会编译期间会自动设置只启动一个reduce task处理数据﹑可能造成数据拥堵
select count(distinct sex) as cnt1 from student;
-- 可以先去重在聚合通过子查询完成
-- 因为先执行distinct的时候可以使用多个reducetask来跑数据
select count(1) as gender_uni_cnt from (select distinct sex from student) a;
-- 场景8:找出student中男女学生年龄最大的及其名字
-- 这里使用了struct来构造数据然后针对struct应用max找出最大元素然后取值
-- struct是一种复杂的数据类型,它允许你将多个字段组合成一个结构
/* 查询结果:
女 22 王敏
男 23 孙庆
*/
select sex,max(struct(age,name)).col1 as age,max(struct(age,name)).col2 as name from student group by sex;
-- 等同如下:
select sex,age,name from student where age=(select max(age) from student where sex='男')
union all
select sex,age,name from student where age=(select max(age) from student where sex='女');
select struct(age,name) from student; -- {"col1":20,"col2":"李勇"}...
select struct(age,name).col1 from student;
-- 当max函数应用于struct类型时,它将根据结构的第一个字段进行排序,然后选择该字段最大值对应的整个结构
-- 如果age字段有多个相同的最大值,max函数将返回这些最大值中的第一个遇到的struct(age,name)
select max(struct(age,name)) from student; -- {"col1":23,"col2":"孙庆"}
增强聚合
增强聚合包括grouping_sets、cube、rollup这几个函数;主要适用于OLAP多维数据分析模式中,多维分析中的维指的分析问题时看待问题的维度、角度。
下面通过案例更好的理解函数的功能含义。数据中字段含义:月份、天、用户标识cookieid。
cookie_info.txt
2018-03,2018-03-10,cookie1
2018-03,2018-03-10,cookie5
2018-03,2018-03-12,cookie7
2018-04,2018-04-12,cookie3
2018-04,2018-04-13,cookie2
2018-04,2018-04-13,cookie4
2018-04,2018-04-16,cookie4
2018-03,2018-O3-10,cookie2
2018-03,2018-03-10,cookie3
2018-04,2018-04-12,cookie5
2018-04,2018-04-13,cookie6
2018-04,2018-04-15,cookie3
2018-04,2018-04-15,cookie2
2018-04,2018-04-16,cookie1
数据准备
create table cookie_info(
month string,
day string,
cookie_id string
)row format delimited fields terminated by ',';
load data local inpath '/root/hivedata/cookie_info.txt' into table cookie_info;
select * from cookie_info;
grouping sets
grouping sets是一种将多个group by逻辑写在一个sql语句中的便利写法。等价于将不同维度的GROUP BY结果集进行UNION ALL。GROUPING__ID表示结果属于哪一个分组集合。
-- grouping__id表示这一组结果属于哪个分组集合
-- 根据grouping sets中的分组条件month,day,1是代表month,2是代表day,3是代表month,day
select
month,
day,
count(distinct cookie_id) as nums,
grouping__id
from cookie_info
group by month,day
grouping sets (month,day,(month,day))
order by grouping__id;
-- 等价于
select month,null,count(distinct cookie_id) as nums,1 as grouping__id from cookie_info group by month
union all
select null,day,count(distinct cookie_id) as nums,2 as grouping__id from cookie_info group by day;
union all
select month,day,count(distinct cookie_id) as nums,3 as grouping__id from cookie_info group by month,day;
cube
cube表示根据GROUP BY的维度的所有组合进行聚合。
对于cube来说,如果有n个维度,则所有组合的总个数是:2n
比如cube有 a, b,c 3个维度,则所有组合情况是:(a,b,c), (a,b), (b, c), (a,c), (a), (b), ©, ()
select
month,
day,
count(distinct cookie_id) as nums,
grouping__id
from cookie_info
group by month,day
with cube
order by grouping__id;
-- 等价于
select month,day,count(distinct cookie_id) as nums,0 as grouping__id from cookie_info
union all
select month,null,count(distinct cookie_id) as nums,1 as grouping__id from cookie_info group by month
union all
select null,day,count(distinct cookie_id) as nums,2 as grouping__id from cookie_info group by day;
union all
select month,day,count(distinct cookie_id) as nums,3 as grouping__id from cookie_info group by month,day;
rollup
cube的语法功能指的是:根据GROUP BY的维度的所有组合进行聚合。
rollup是cube的子集,以最左侧的维度为主,从该维度进行层级聚合。
比如rollup有 a, b, c 3个维度,则所有组合情况是:(a, b, c), (a,b), (a), ()
-- 比如,以month维度进行层级聚合
select
month,
day,
count(distinct cookie_id) as nums,
grouping__id
from cookie_info
group by month,day
with rollup
order by grouping__id;
-- 等价于
select month,day,count(distinct cookie_id) as nums,0 as grouping__id from cookie_info
union all
select month,null,count(distinct cookie_id) as nums,1 as grouping__id from cookie_info group by month
union all
select month,day,count(distinct cookie_id) as nums,3 as grouping__id from cookie_info group by month,day;
-- 把month和day调换顺序,则以day维度进行层级聚合
select
day,
month,
count(distinct cookie_id) as nums,
grouping__id
from cookie_info
group by day,month
with rollup
order by grouping__id;
-- 等价于
select day,month,count(distinct cookie_id) as nums,0 as grouping__id from cookie_info
union all
select null,day,count(distinct cookie_id) as nums,1 as grouping__id from cookie_info group by day
union all
select day,month,count(distinct cookie_id) as nums,3 as grouping__id from cookie_info group by day,month;
窗口函数
概述
窗口函数(Window functions )也叫做开窗函数、OLAP函数,其最大特点是:输入值是从SELECT语句的结果集中的一行或多行的“窗口”中获取的。
如果函数具有OVER子句,则它是窗口函数。
窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
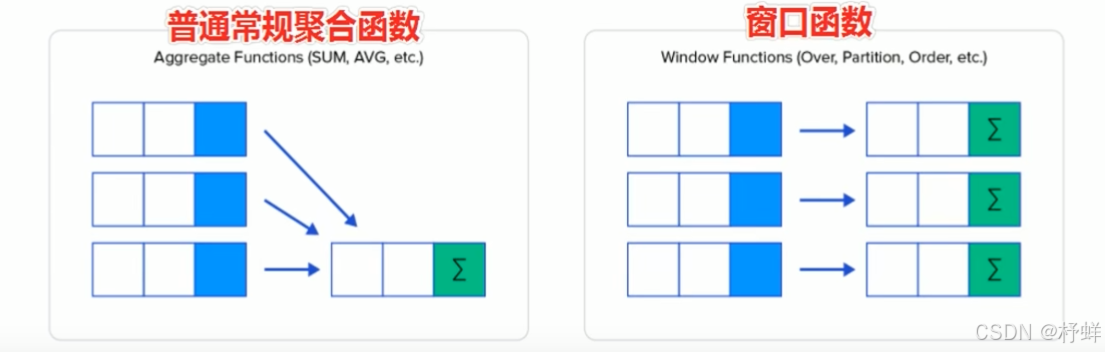
-- 1、sum+group by普通常规聚合操作;每组不管多少条数据,sum聚合之后返回一行
/*查询结果:
女 191
男 235
*/
select sex,sum(age) as total from student group by sex;
-- 2、sum+窗口函数聚合操作
-- 分组后组内聚合,但是聚合之后的结果还可以和分组内的每一行数据进行交互(如可以和其它非分组列一起查询),并没有像普通聚合过程那样直接最终输出一行(只能和分组列进行查询)
/*查询结果:
95002 刘晨 女 19 IS 191
95019 邢小丽 女 19 IS 191
95018 王一 女 19 IS 191
95022 郑明 男 20 MA 235
95021 周二 男 17 MA 235
95020 赵钱 男 21 IS 235
*/
select s.*,sum(age) over(partition by sex) as total from student s;
语法规则
Function(arg1,...,argn) OVER([PARTITION BY <...>] [ORDER BY <...> [ASC/DESC] [NULLS LAST/FIRST]] [<window_expression>])
-- 其中Function(argl ,..., argn)可以是下面分类中的任意一个
-- 聚合函数:比如sum、max、avg等
-- 排序函数:比如rank、row_number、dense_rank、ntile
-- 分析函数:比如lead、lag、first_value、last_value
-- OVER([PARTITION BY <...>])类似于group by用于指定分组每个分组你可以把它叫做窗口
-- 如果没有PARTITION BY 那么整张表的所有行就是一组
-- [ORDER BY <...> [ASC/DESC] [NULLS LAST/FIRST]]用于指定每个分组内的数据排序规则,支持ASC、DESC,支持指定NULL值排序规则
-- [<window expression>]用于指定每个窗口中操作的数据范围默认是窗口中所有行
窗口表达式
在sum(…) over(partition by… order by …)语法完整的情况下,进行累积聚合操作,默认累积聚合行为是:从第一行聚合到当前行。
Window expression窗口表达式给我们提供了一种控制行范围的能力,比如向前2行,向后3行。
语法如下:
关键字是rows between,包括下面这几个选项
- preceding: 往前
- following: 往后
- current row: 当前行
- unbounded: 边界
- unbounded preceding: 表示从前面的起点
- unbounded following: 表示到后面的终点
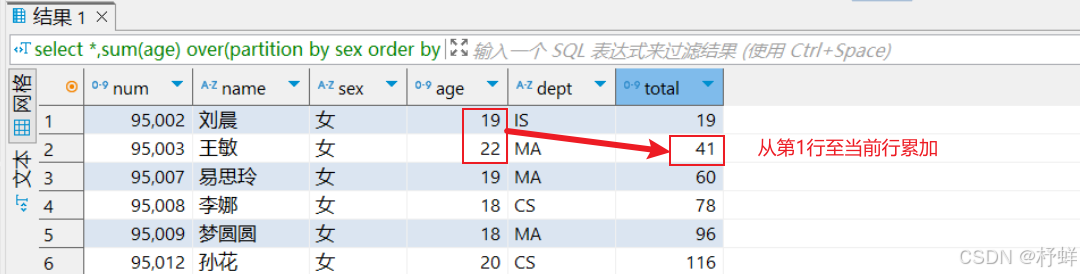
示例1:
-- 默认从一行至当前行
select *,sum(age) over(partition by sex order by num) as total from student;
-- 第一行至当前行,默认行为,上下写法等价
select *,sum(age) over(partition by sex order by num rows between unbounded preceding and current row) as total from student;
运行结果:
示例2:
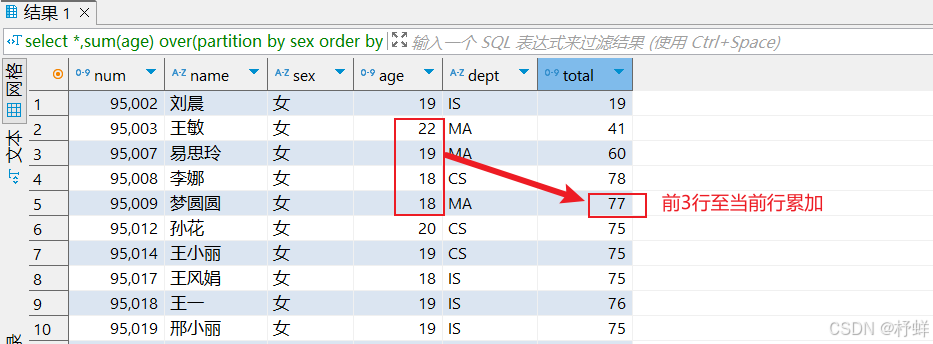
-- 向前3行至当前行
select *,sum(age) over(partition by sex order by num rows between 3 preceding and current row) as total from student;
运行结果:
示例3:
-- 向前3行至向后1行
select *,sum(age) over(partition by sex order by num rows between 3 preceding and 1 following) as total from student;
运行结果:
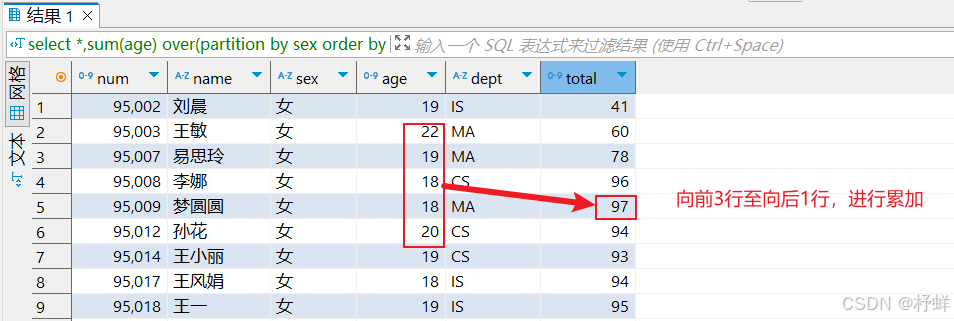
示例4:
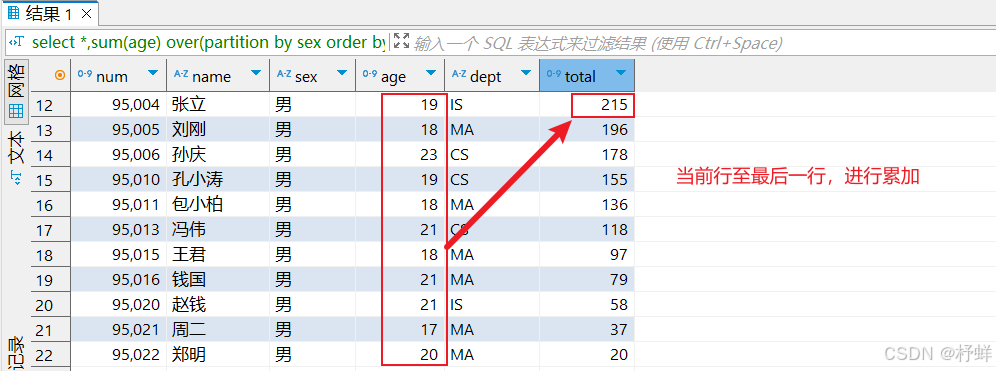
-- 当前行至最后一行
select *,sum(age) over(partition by sex order by num rows between current row and unbounded following) as total from student;
运行结果:
窗口排序函数
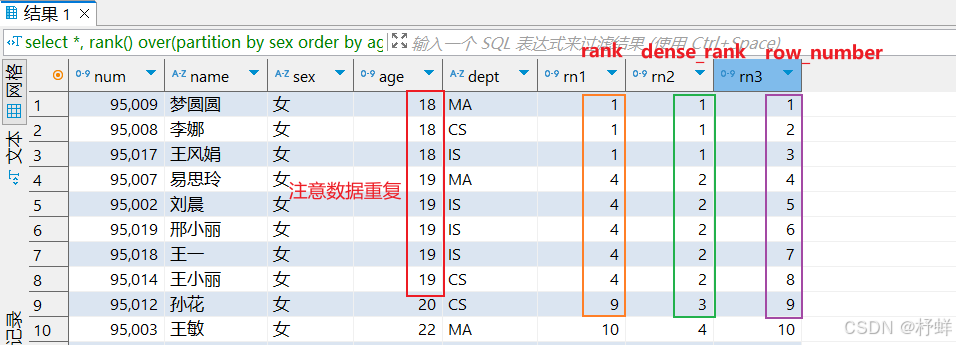
row_number、rank、dense_rank
row_number:在每个分组中,为每行分配一个从1开始的唯一序列号,递增,不考虑重复;
rank:在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;
dense_rank:在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;
示例:
select *,
rank() over(partition by sex order by age) as rn1,
dense_rank() over(partition by sex order by age) as rn2,
row_number() over(partition by sex order by age) as rn3
from student;
运行结果:
一般使用row_number进行数据的去重
-- 若table_xx表中同一个id存在多条记录,可以根据id进行分组,取业务时间create_time最新的一条;即可对多个id进行去重 select * from ( select *,row_number() over(partition by id order by create_time desc nulls last) as rn from table_xx ) t where t.rn=1;
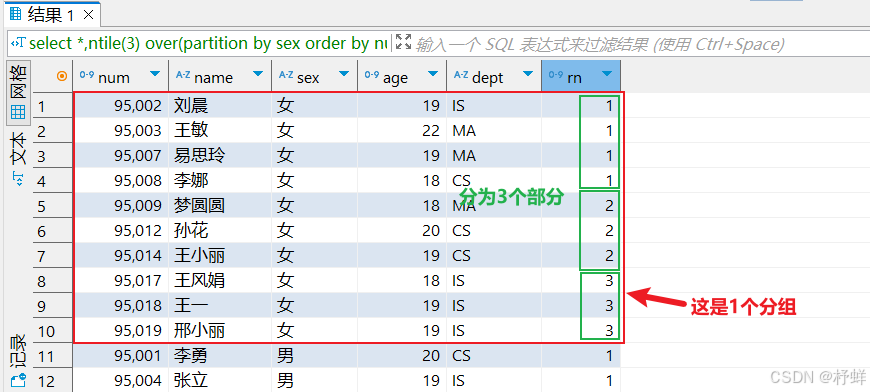
ntile
将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号。
如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的1/3数据拿出来呢?NTILE函数即可以满足。
示例:
-- 把每个分组内的数据分为3桶
select *,ntile(3) over(partition by sex order by num) as rn from student;
运行结果:
窗口分析函数
LAG(col, n, DEFAULT)用于统计窗口内往上第n行值;第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL) ;
LEAD(col, n, DEFAULT)用于统计窗口内往下第n行值;第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL) ;
FIRST_VALUE取分组内排序后,截止到当前行,第一个值
LAST_VALUE取分组内排序后,截止到当前行,最后一个值
示例1:
select *,
row_number() over(partition by sex order by age) as rn1,
lag(name,1) over(partition by sex order by age) as lg1,
lag(name,1,'Aiw') over(partition by sex order by age) as lg2,
lead(name,1) over(partition by sex order by age) as ld1,
lead(name,1,'Tom') over(partition by sex order by age) as ld2
from student;
运行结果:可以看到数据错位显示

示例2:
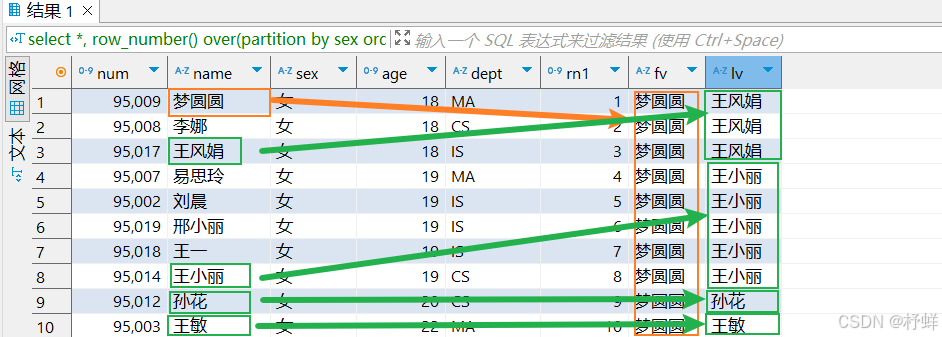
select *,
row_number() over(partition by sex order by age) as rn1,
first_value(name) over(partition by sex order by age) as fv,
last_value(name) over(partition by sex order by age) as lv
from student;
运行结果:
抽样函数
在HQL中,可以通过三种方式采样数据:随机采样、存储桶表采样和块采样
Random 随机采样
随机抽样使用rand()函数来确保随机获取数据,LIMIT来限制抽取的数据个数。
优点是随机,缺点是速度不快,尤其表数据多的时候。
-
推荐
DISTRIBUTE+SORT,可以确保数据也随机分布在mapper和reducer之间,使得底层执行有效率。 -
ORDER BY语句也可以达到相同的目的,但是表现不好,因为ORDER BY是全局排序,只会启动运行一个reducer。
-- 随机抽取2个学生的情况进行查看
select * from student distribute by rand() sort by rand() limit 2;
-- 使用order by+rand也可以实现同样的效果,但是效率不高
select * from student order by rand() limit 2;
Block 基于数据块抽样
Block块采样允许随机获取n行数据、百分比数据或指定大小的数据。
采样粒度是HDFS块大小。
优点是速度快,缺点是不随机。
-- 根据行数抽样
select * from student tablesample(2 rows);
-- 根据数据大小百分比抽样
select * from student tablesample(30 percent);
-- 根据数据大小抽样
-- 支持数据单位:b/B、k/K、m/M、g/G
select * from student tablesample(1k);
Bucket table 基于分桶表抽样
这是一种特殊的采样方法,针对分桶表进行了优化。优点是既随机速度也很快。
语法:TABLESAMPLE(BUCKET x OUT OF y [ON colname])
-- 语法表示,根据colname分为y个桶,抽取第x个桶的数据
-- 1、y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
-- 例如,table总共分了4份(4个bucket),当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
-- 2、x表示从哪个bucket开始抽取。
-- 例如,table总bucket数为4,tablesample(bucket 1 out of 4),表示总共抽取〈4/4=)1个bucket的数据,抽取第1个bucket的数据。
-- 注意:x的值必须小于等于y的值,否则FAlLED:Nurnerator should not be bigger than denominator in sarnple clause for table sto buck
-- 3、ON colname表示基于什么抽
-- ON rand()表示随机抽
-- ON 分桶字段,表示基于分桶字段抽样,效率更高,推荐
示例:
-- 分桶表创建DDL
-- 开启分桶的功能,从Hive2.0开始不再需要设置
set hive.enforce.bucketing=true;
create table t_usa_covid19_bucket(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int
)clustered by (state) sorted by (cases desc) into 5 buckets;
-- 根据整行数据进行抽样
select * from t_usa_covid19_bucket tablesample(bucket 1 out of 5 on rand());
-- 根据分桶字段进行抽样,效率更高
desc formatted t_usa_covid19_bucket; -- Num Buckets: 5 Bucket Columns: [state]
select * from t_usa_covid19_bucket tablesample(bucket 1 out of 5 on state);
Hive函数重要应用案例
Hive中多字节分隔符处理
默认规则
Hive默认序列化类是LazySimpleSerDe,其只支持使用单字节分隔符(char)来加载文本数据,例如逗号、制
表符、空格等等,默认的分隔符为”\001”。根据不同文件的不同分隔符,我们可以通过在创建表时使用row format delimited来指定文件中的分割符,确保正确将表中的每一列与文件中的每一列实现一一对应的关系。

解决方案一:替换分隔符
提前将数据中的多字节分隔符替换为单字节分隔符

解决方案二:RegexSerDe正则解析
除了使用最多的LazySimpleSerDe,Hive该内置了很多SerDe类
官网地址: https://cwiki.apache.org/confluence/display/Hive/SerDe
多种SerDe用于解析和加载不同类型的数据文件,常用的有ORCSerDe、RegexSerDe、JsonSerDe等

RegexSerDe用来加载特殊数据的问题,使用正则匹配来加载数据。根据正则表达式匹配每一列数据。
官方示例:Apache Hive - RegEx

分析数据格式,构建正则表达式

解决方案三:自定义InputFormat
Hive中也允许使用自定义InputFormat来解决以上问题,通过在自定义InputFormat,来自定义解析逻辑实现读取每一行的数据。

步骤一:MapReudce中自定义InputFormat一致,继承TextInputFormat

步骤二:与MapReudce中自定义RecordReader一致,实现RecordReader接口,实现next方法
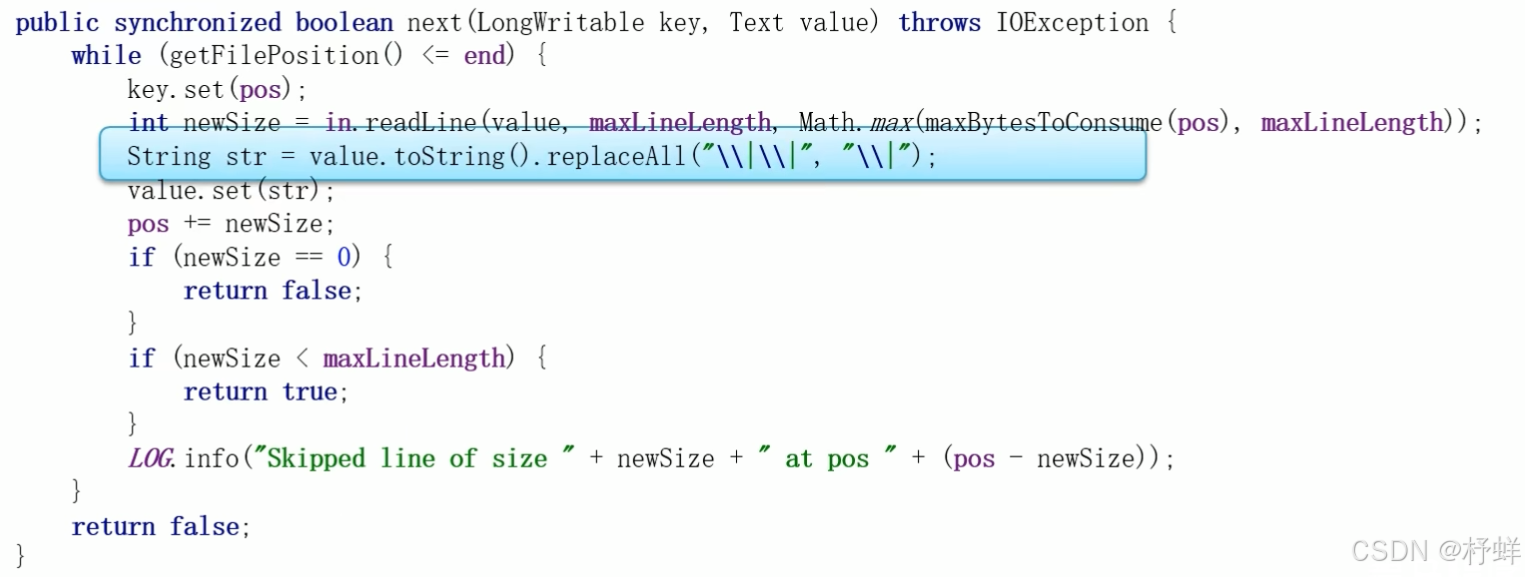
步骤三:打成jar包,添加到Hive的classpath中
-- 在任意Hive连接客户端执行
add jar /export/server/hive-3.1.2-bin/lib/HiveUserInputFormat.jar;
示例:
create table singer(
id string,
name string,
country string,
gender string
)
-- 指定使用分潴符为
row format delimited fields terminated by '|'
-- 指定使用自定义的类实现解析
stored as
inputformat 'com.aiw.com.hive.mr.UserInputFormat'
outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat '
总结
当数据文件中出现多字节分隔符或者数据中包含了分隔符时,会导致数据加载与实际表的字段不匹配的问题,基于这个问题我们提供了三种方案︰
- 替换分隔符
- RegexSerDe正则解析
- 自定义InputFormat
其中替换分隔符无法解决数据字段中依然存在分隔符的问题,自定义InputFormat的开发成本较高,所以整体推荐使用正则解析的方式来实现对于特殊数据的处理。
URL解析函数
Hive中为了实现对URL的解析,专门提供了解析URL的函数parse_url和parse_url_tuple
parse_url函数
parse_url函数是Hive中提供的最基本的url解析函数,可以根据指定的参数,从URL解析出对应的参数值进行返回,函数为普通的一对一函数类型,即通常所说的UDF函数类型。
-- 语法
parse_url(url, partToExtract[, key])
Parts: HOST,PATH,QUERY,REF,PROTOCOL,AUTHORITY,FILE,USERINFO key
示例:
select parse_url('http://www.aiw.com/page/info.html?id=101','HOST'), -- www.aiw.com
parse_url('http://www.aiw.com/page/info.html?id=101','PATH'), -- /page/info.html
parse_url('http://www.aiw.com/page/info.html?id=101&name=Tom','QUERY'), -- id=101&name=Tom
parse_url('http://www.aiw.com/page/info.html?id=101','PROTOCOL'), -- http
parse_url('http://www.aiw.com/page/info.html?id=101&name=Tom','QUERY','name'); -- Tom
parse_url_tuple函数
parse_url_tuple函数是Hive中提供的基于parse_url的url解析函数,可以通过一次指定多个参数,从URL解析出多个参数的值进行返回多列,函数为特殊的一对多函数类型,即通常所说的UDTF函数类型。
-- 语法
parse_url_tuple(url, partname1, partname2,..., partnameN)
It takes a URL and one or multiple partnames, and returns a tuple.
示例:
select parse_url_tuple('http://www.aiw.com/page/info.html?id=101','HOST','PATH','QUERY','PROTOCOL') as (host,path,query,protocol);
-- 输出结果:www.aiw.com /page/info.html id=101 http
parse_url_tuple函数+lateral View侧视图
-- 1、数据准备
create table t_url(id int,url string);
insert into table t_url values
(1,'http://www.aiw.com/page/info.html?id=101'),
(2,'http://baidu.com/index.html'),
(3,'http://douyin.com/welcom.html');
-- 2、测试
select parse_url_tuple(url,'HOST','PATH') as (host,path) from t_url;
select id,parse_url_tuple(url,'HOST','PATH') as (host,path) from t_url; -- 报错
-- 3、parse_url_tuple+lateral view
select a.id,b.host,b.path from t_url a lateral view parse_url_tuple(url,'HOST','PATH') b as host,path;
/* 查询结果
id host path
1 www.aiw.com /page/info.html
2 baidu.com /index.html
3 douyin.com /welcom.html
*/
-- 4、多个lateral view
select a.id,b.host,b.path,c.query,c.protocol
from t_url a
lateral view parse_url_tuple(url,'HOST','PATH') b as host,path
lateral view parse_url_tuple(url,'QUERY','PROTOCOL') c as query,protocol;
行列转换应用与实现
多行转多列
行转列通常意味着将一个列的不同值转换为多个列,这通常涉及到聚合操作,且需要知道所有可能的值。
-- 数据准备
create table t_row_or_col(col1 string,col2 string,col3 int);
insert into table t_row_or_col values
('a','c','1'),
('a','d','2'),
('a','e','3'),
('b','c','4'),
('b','d','5'),
('b','e','6');
-- 多行转多列
select
col1,
max(case when col2 = 'c' then col3 end) as c,
max(case when col2 = 'd' then col3 end) as d,
max(case when col2 = 'e' then col3 end) as e
from t_row_or_col
group by col1;

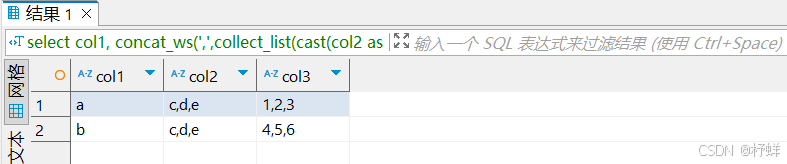
多行转单列
-- 多行转单列
select
col1,
concat_ws(',',collect_list(cast(col2 as string))) as col2, -- concat_ws只接收string 或 array(string)
concat_ws(',',collect_list(cast(col3 as string))) as col3
from t_row_or_col
group by col1;
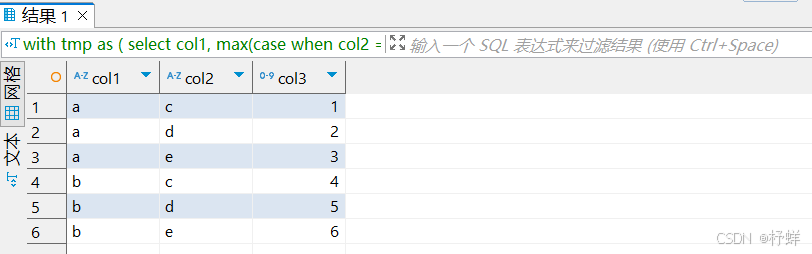
多列转多行
-- 多列转多行
-- 此处CTE的select为多行转多列,计划基于此数据再逆转回来
with tmp as (
select
col1,
max(case when col2 = 'c' then col3 end) as c,
max(case when col2 = 'd' then col3 end) as d,
max(case when col2 = 'e' then col3 end) as e
from t_row_or_col
group by col1)
select col1,'c' as col2,c as col3 from tmp
union all
select col1,'d' as col2,d as col3 from tmp
union all
select col1,'e' as col2,e as col3 from tmp
order by col1;
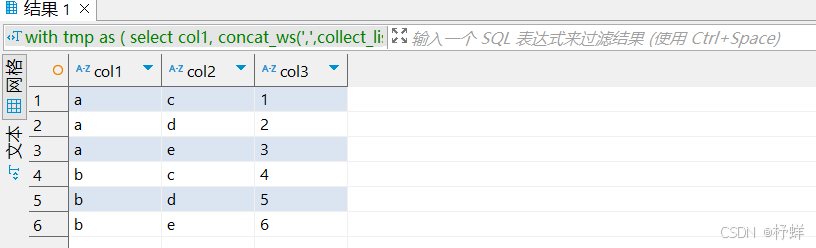
单列转多行
-- 单列转多行
-- 此处CTE的select为多行转单列,计划基于此数据再逆转回来
with tmp as (
select
col1,
concat_ws(',',collect_list(cast(col2 as string))) as col2,
concat_ws(',',collect_list(cast(col3 as string))) as col3
from t_row_or_col
group by col1)
select col1,lv.col2,split(col3, ',')[cast(row_number() over (partition by col1 order by lv.col2) as int) - 1] as col3
from tmp lateral view explode(split(col2,',')) lv as col2;
JSON数据处理
方式一:使用JSON函数处理
-- get_json_object(json_txt,path):用于解析JSON字符串,可以从JSON字符串中返回指定的某个对象列的值;
-- 特点:每次只能返回JSON对象中一列的值
-- $表示json对象;通过$.columnName的方式来指定path
select get_json_object('{"website":"www.aiw.cn","name":"allenwoon"}','$.website'), -- www.aiw.cn
get_json_object('{"website":"www.aiw.cn","name":"allenwoon"}','$.name'), -- allenwoon
get_json_object('[{"website":"www.aiw.cn","name":"allenwoon"}]','$.[0].website'), -- www.aiw.cn
get_json_object('[{"website":"www.aiw.cn","name":"allenwoon"}]','$.[0].name'), -- allenwoon
get_json_object('[{"website":"www.aiw.cn","name":"allenwoon"},{"website":"www.test.com","name":"Tom"}]','$.[1].name'); -- Tom
-- json_tuple(json_txt,path1,path2,...,pathn):用于实现JSON字符串的解析,可以通过指定多个参数来解析JSON返回多列的值
-- 特点:功能类似于get_json_object,但是可以调用一次返回多列的值,属于UDTF类型函数,一般搭配lateral view使用
-- 返回的每一列都是字符串类型
-- 单独使用
select json_tuple('{"website":"www.aiw.cn","name":"allenwoon"}','website','name') as (website,name); -- www.aiw.cn allenwoon
-- json_tuple函数并不直接支持JSON数组
select json_tuple('[{"website":"www.aiw.cn","name":"allenwoon"}','website','name'); -- null null
-- 搭配侧视图使用
select t.now,jt.website,jt.name from (select current_date as now) t
lateral view json_tuple('{"website":"www.aiw.cn","name":"allenwoon"}','website','name') jt as website,name; -- 2024-09-08 www.aiw.cn allenwoon
方式二:JSON Serde加载数据
上述解析JSON的过程中是将数据作为一个JSON字符串加载到表中,再通过JSON解析函数对JSON字符串进行解析,灵活性比较高,但是对于如果整个文件就是一个JSON文件,在使用起来就相对比较麻烦。
Hive中为了简化对于JSON文件的处理,内置了一种专门用于解析JSON文件的Serde解析器,在创建表时,只要指定使用JSONSerde解析表的文件,就会自动将JSON文件中的每一列进行解析。
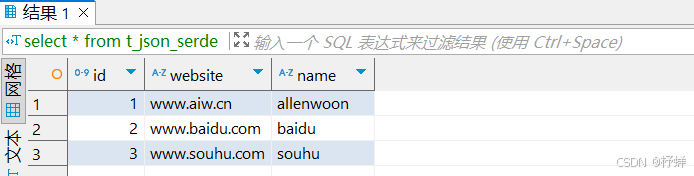
json文件:test_json.json,上传到/root/hivedata下
{"id":1,"website":"www.aiw.cn","name":"allenwoon"}
{"id":2,"website":"www.baidu.com","name":"baidu"}
{"id":3,"website":"www.souhu.com","name":"souhu"}
具体Hive SQL:
-- JsonSerDe
create table t_json_serde(id int,website string,name string)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe'
stored as textfile;
load data local inpath '/root/hivedata/test_json.json' into table t_json_serde;
select * from t_json_serde;
查询结果:
窗口函数应用实例
案例1:连续登录用户统计
需求:统计连续N次登录的用户
数据文件:login.txt
A 2024-03-22
B 2024-03-22
C 2024-03-22
A 2024-03-23
C 2024-03-23
A 2024-03-24
B 2024-03-24
准备工作:
create table t_login(user_id string,login_time string)
row format delimited fields terminated by '\t';
load data local inpath '/root/hivedata/login.txt' into table t_login;
select * from t_login;
具体SQL:
-- 连续两天登录用户
/* 输出结果
user_id
A
C
*/
with t1 as (
select user_id,login_time,lead(login_time,1,0) over(partition by user_id order by login_time) as next_login from t_login
)
select distinct user_id from t1 where date_add(login_time,1)=next_login;
-- 连续三天登录用户
/* 输出结果
user_id
A
*/
with t1 as (
select user_id,login_time,lead(login_time,2,0) over(partition by user_id order by login_time) as next_login from t_login
)
select distinct user_id from t1 where date_add(login_time,2)=next_login;
-- 规律:连续N天登录用户
with t1 as (
select user_id,login_time,lead(login_time,N-1,0) over(partition by user_id order by login_time) as next_login from t_login
)
select distinct user_id from t1 where date_add(login_time,N-1)=next_login;
注意:若同一个用户一天登录多次,需先根据(user_id和login_time)进行去重,否则计算结果不对
案例2:级联累加求和场景
需求:统计每个用户每个月的消费总金额以及当前累计消费总金额
数据文件:money.txt
A 2024-01 5
A 2024-01 15
B 2024-01 5
A 2024-01 8
B 2024-01 25
A 2024-01 5
A 2024-02 4
A 2024-02 6
B 2024-02 10
B 2024-02 5
A 2024-03 7
B 2024-03 9
A 2024-03 11
B 2024-03 6
准备工作:
create table t_money(user_id string,`month` string,money int)
row format delimited fields terminated by '\t';
load data local inpath '/root/hivedata/money.txt' into table t_money;
select * from t_money;
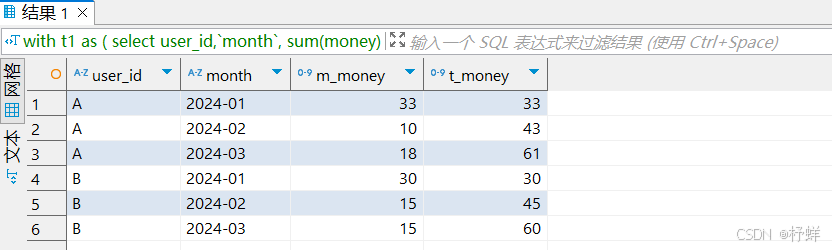
具体SQL:
with t1 as (
select user_id,`month`,
sum(money) over(partition by user_id,`month`) as m_money, -- 每个月的消费总金额
sum(money) over(partition by user_id order by `month`) as t_money -- 当前累计消费总金额
from t_money
)
select distinct * from t1;
运行结果:
案例3:分组TOP N问题
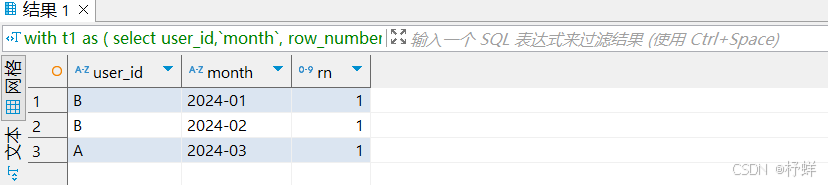
需求:统计查询每个月消费金额最高的用户信息
具体SQL:
with t1 as (
select user_id,`month`,
row_number() over(partition by `month` order by money desc) as rn
from t_money
)
select * from t1 where rn = 1; -- 取TOP 1
-- 规律:分组TOP N
with t1 as (
select user_id,`month`,
row_number() over(partition by `month` order by money desc) as rn
from t_money
)
select * from t1 where rn <= N;
运行结果:
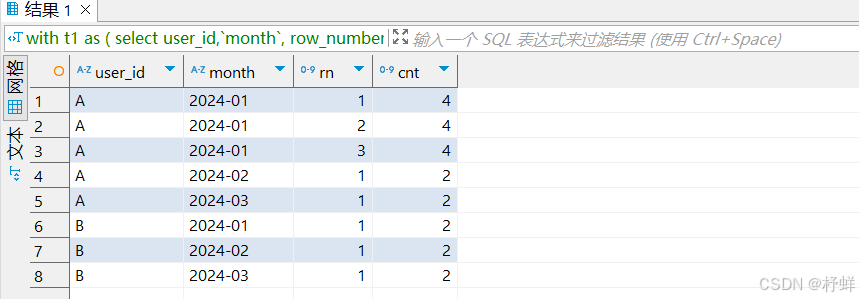
案例4:分组留N条数问题
需求:每个用户每个月各自留1条消费最少的数据,其余的查询出来
具体SQL:
with t1 as (
select user_id,`month`,
row_number() over(partition by user_id,`month` order by money desc) as rn,
count(1) over(partition by user_id,`month`) as cnt
from t_money
)
select * from t1 where rn <= cnt - 1 order by user_id,`month`,rn;
-- 规律:分组留N条数问题
with t1 as (
select user_id,`month`,
row_number() over(partition by user_id,`month` order by money desc) as rn,
count(1) over(partition by user_id,`month`) as cnt
from t_money
)
select * from t1 where rn <= cnt - N order by user_id,`month`,rn;
运行结果: